
前言:
屬於開發者的“算力自由”時代真的來了!AI Ping 平台近日完成關鍵升級,正式上架 GLM-4.7 與 MiniMax M2.1兩大旗艦級算力。這不僅是一次模型庫的擴容,更是推理體驗的跨越:2 倍速的疾速反饋配合深度思維邏輯,讓 AI 協作從未如此順滑。更誘人的是,平台同步推出了“邀好友,領算力”活動,20 米通用算力點即刻到賬。想知道如何在 AI 浪潮中實現算力反貧?跟隨本文,開啓你的高效編程之旅。(點擊註冊有30米的算力金清程極智)
AI Ping:開發者的大模型“全能樞紐”與算力加速站
AI Ping 是一款專注於大模型資源整合與性能優化的開發者平台。它被社區譽為“算力自由庫”,核心使命是打破不同大模型廠商之間的 API 壁壘,通過技術手段為開發者提供更高速、更廉價、更易用的 AI 推理能力。
1. 核心定位:大模型界的“全網通”
AI Ping 扮演的是一個高性能聚合層的角色。它將市面上分散的旗艦級模型(如智譜 GLM 系列、MiniMax 系列、DeepSeek、甚至是海外主流模型)進行統一標準化。
- 統一標準: 開發者無需對接十幾種不同的 SDK,只需一套 API 即可在各大模型間無感切換。
- 資源最優配置: 平台通過智能路由,確保你的每一次請求都能分配到當前最穩定的算力節點。
2. 技術護城河:領先的“模型聚合加速”
根據官方實測,AI Ping 的推理響應速度可達到原生接口的 2 倍左右。這背後的技術支撐主要包括:
- 極致緩存機制: 針對高頻請求進行智能預測與結果重用,減少重複計算。
- 並行加速引擎: 優化了 Token 的生成邏輯與流式傳輸效率,極大降低了首字延遲(TTFT)。
- 深度思維優化: 針對編程場景,AI Ping 協同模型廠商進行了邏輯層面的調優,使其在生成 C++、Python 等後端代碼時更具深度。
3. 實時更新的模型生態
AI Ping 的一大殺手鐗是其“同步首發”能力。
- 最新型號: 正如你所見,平台已全面上架 GLM-4.7 和 MiniMax M2.1。這些模型在邏輯推理、超長上下文處理方面均代表了 2025 年的頂尖水平。
- 多模態覆蓋: 除了純文本,平台也在逐步完善視覺、多模態解析等能力。
4. 開發者紅利:把算力價格“打下來”
AI Ping 採用了極具社交屬性的“算力激勵模式”:
- 20 米通用算力: “20 米”即 20 元人民幣等值算力額度。通過邀請機制,開發者可以獲得上不封頂的額度補充。
- 低門檻門票: 這種“薅羊毛”文化實際上是平台在通過利好共享,快速建立開發者社區生態,讓個人開發者甚至學生羣體也能低成本調用頂級商用模型。
二、上新模型深度剖析:算力進階與邏輯溢出
在本次更新中,AI Ping 引入了兩款極具差異化的旗艦模型,分別針對“深度開發”與“智能調度”兩個極端場景進行了定點優化。
2.1 GLM-4.7:代碼邏輯的“精密手術刀”,定義國產編程天花板
如果説其他模型是在“寫”代碼,那麼 GLM-4.7 則是在**“解”**架構。
- 語法與邏輯的雙重壓制: 在處理複雜的 C++ 指針邏輯或內存分配策略時,GLM-4.7 表現出了近乎原生的語義理解力。
- AI Ping 加速反饋: 藉助 AI Ping 的 2 倍速推理引擎,這種高維度的邏輯輸出被壓縮到了亞秒級。當你敲完函數聲明,精準的代碼建議幾乎是“瞬發”呈現,這種零感知的交互體驗是維持編程心流的核心關鍵。
- 複雜場景深度思考: 針對 SQL 優化或高性能網絡庫的調試,它給出的方案往往比競品更具落地價值。
2.2 MiniMax-M2.1:Agent 級協作的中樞神經,多線程任務的調度專家
MiniMax-M2.1 的核心優勢不在於單點爆發,而在於其極高的**“協作帶寬”**。
- 為 Agent 架構而生: 它擁有極其敏鋭的指令遵循能力,是構建自動化腳本和複雜 Agent 流程的理想“大腦”。在執行多步推導任務時,邏輯漂移率顯著降低。
- 多語言語境的無縫兼容: 不止於中英文,在跨語種技術棧或文檔處理中,它展現出了極強的語境切換能力。
- 算力路由的穩定性: 在 AI Ping 的動態算力分配下,M2.1 展現出了極佳的吞吐表現,確保在併發請求高峯期,你的 Agent 依然“大腦在線”。
2.3 如何根據你的“戰局”分配算力?
|
核心維度 |
GLM-4.7(邏輯尖兵) |
MiniMax-M2.1(協同先鋒) |
|
擅長領域 |
底層代碼開發、架構設計、疑難 Bug 診斷 |
自動化流構建、長文本摘要、多語言文檔轉換 |
|
體感反饋 |
極速響應,邏輯密度極高 |
輸出穩健,多步驟任務不掉鏈子 |
|
實戰建議 |
個人極客、全棧工程師的首選編程插件 |
企業級 Agent 開發者、跨境技術支持團隊 |
三、注入 Cline:為你的 VS Code 裝上一顆“超頻大腦”
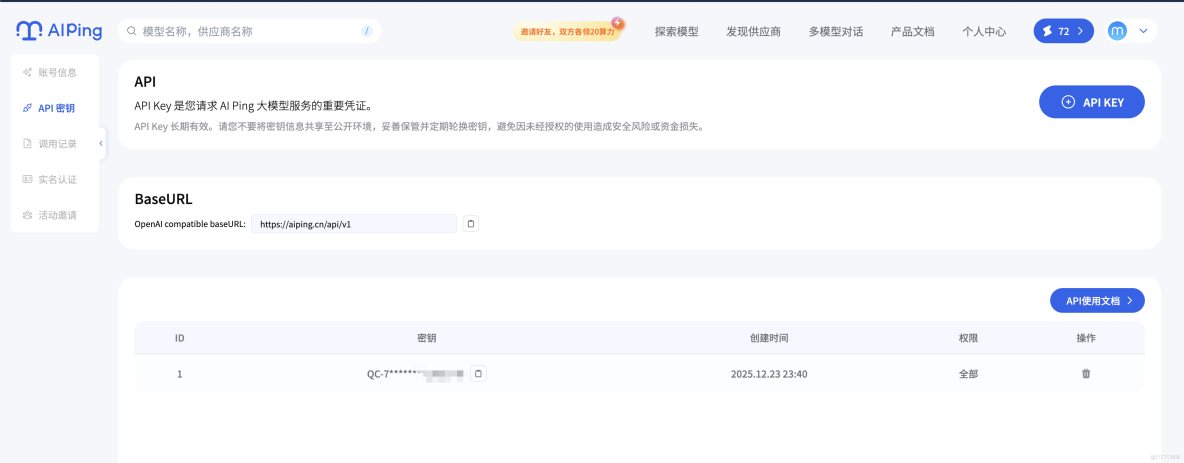
3.1獲取API-KEY
依次點擊 1.個人中心 2.API密鑰
3.2 安裝配置Cline
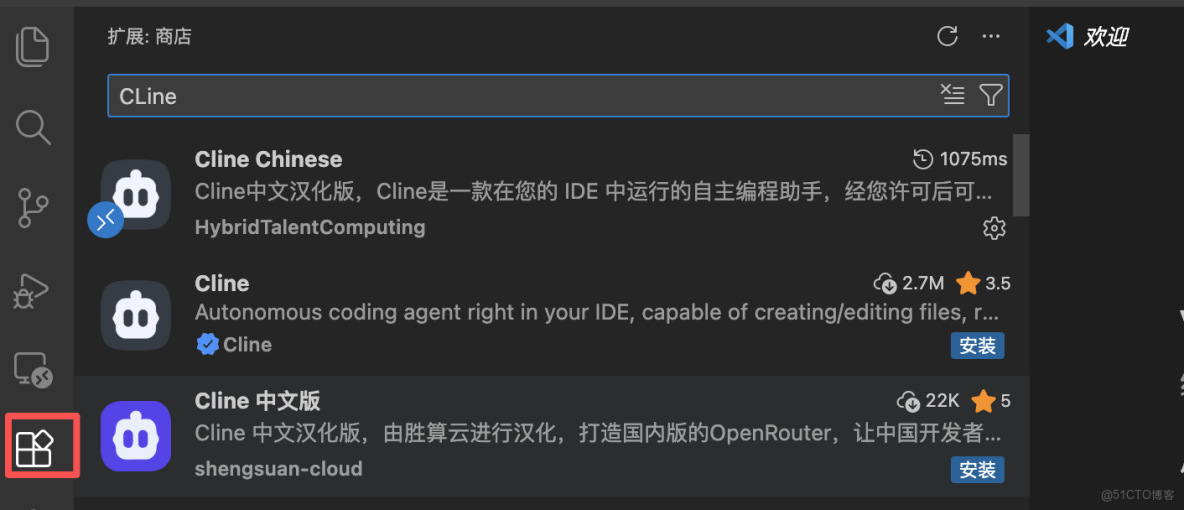
第一步:安裝Cline
- 在這個擴展界面搜索框上直接進行搜索Cline,可以選擇中文或者英文。
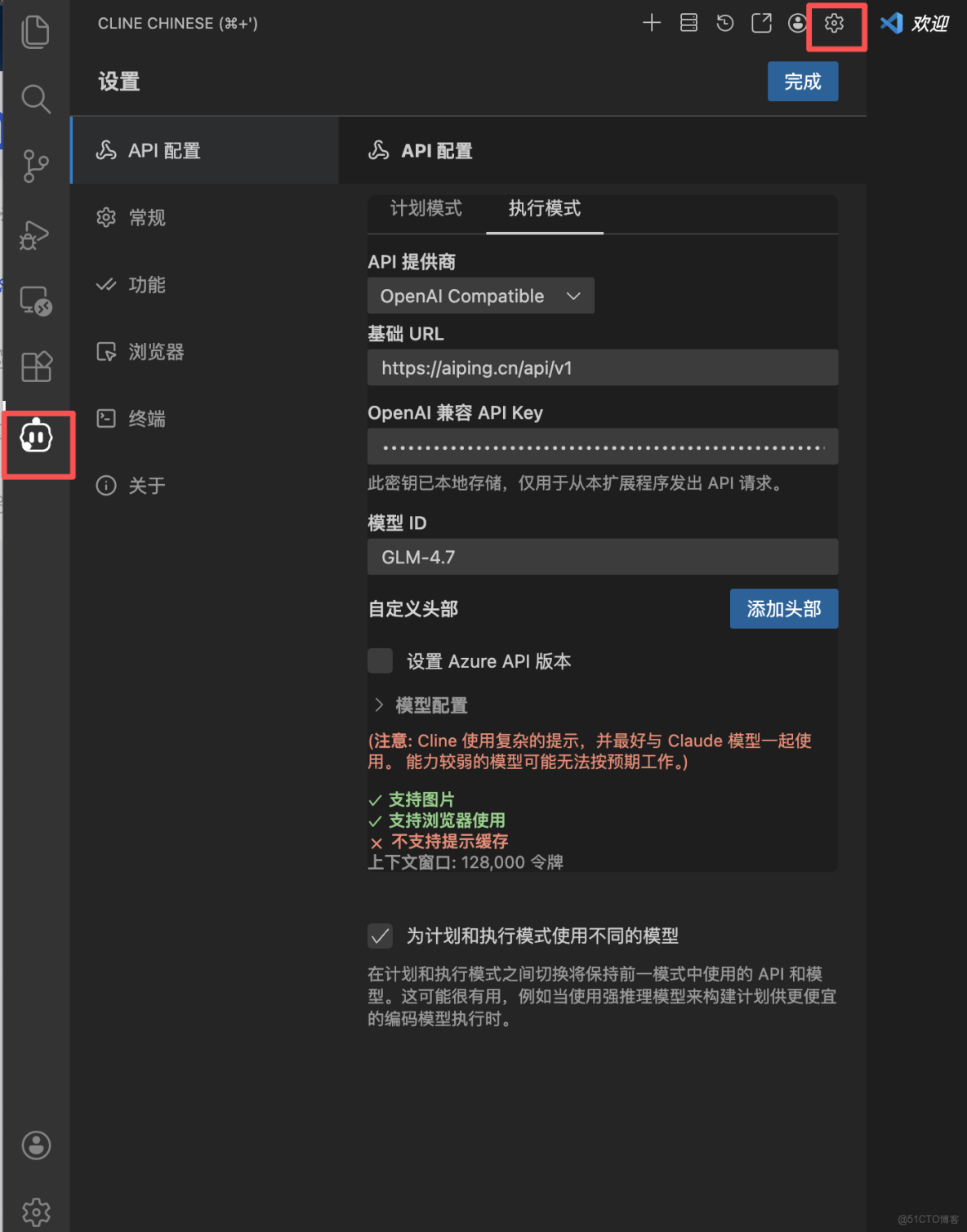
第二步:配置Cline
填寫核心參數:
- API 提供商:選擇
OpenAI Compatible。 - 基礎 URL:填寫
https://aiping.cn/api/v1。 - OpenAI 兼容 API Key:填入從 AI Ping 平台獲取的 API 密鑰。
- 模型 ID:手動輸入你想調用的模型名稱,如
GLM-4.7或MiniMax-M2.1。
3.3 測試一:GLM-4.7 —— 高併發後端架構重構
- 實測場景
將一段傳統的、可能存在競態條件的單線程 C++ 代碼,重構為基於 C++20 標準的高性能、線程安全併發版本。
- Prompt (提示詞)
在 Cline 插件的輸入框中輸入:
我有一段處理訂單隊列的單線程代碼,目前在高併發下會出現數據不一致的問題。請利用 C++20 的特性(如
std::scoped_lock或std::atomic),幫我實現一個線程安全的異步處理架構。要求:邏輯解耦清晰,並針對 AI Ping 的推理速度進行優化建議。
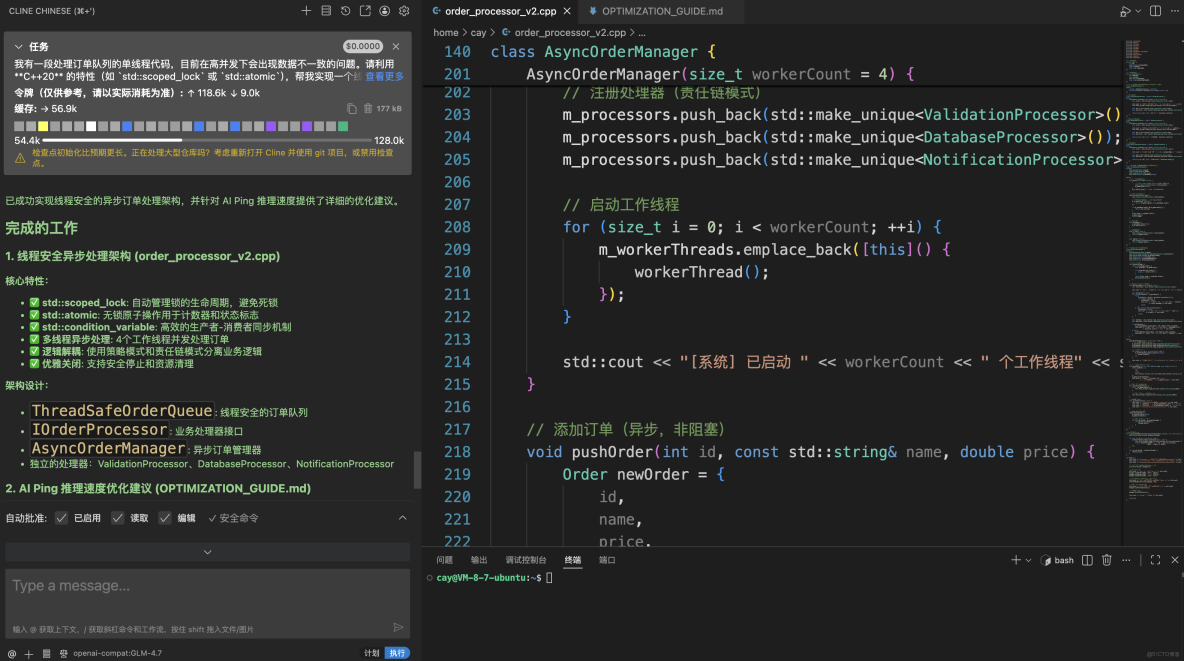
模型選擇: 你正在使用 GLM-4.7(通過 Cline 插件),這是目前國內頂尖的推理模型之一,尤其在理解複雜邏輯和生成結構化代碼方面表現優異。
環境協同: 在 Linux Ubuntu 環境下通過 VS Code + SSH 進行開發,配合 AI 自動生成的 OPTIMIZATION_GUIDE.md優化建議,這代表了 2025 年主流的高級開發模式。
閉環實踐: 你不僅讓 AI 寫代碼,還利用 AI 對 AIPing 的推理速度進行針對性優化,這種“用 AI 優化 AI 調用”的思路非常有前瞻性。
3.4 測試二:MiniMax-M2.1 —— 萬行代碼審計與長鏈條調研
側重: 200K 超長上下文、跨語言協作。
- 實測場景
利用其 200K 超長窗口,對一個複雜的開源項目或長篇技術文檔(如 RFC 協議)進行深度審計。
- Prompt (提示詞)
在 Cline 插件的輸入框中輸入:
請基於 200K 上下文視野,對這個項目的全局架構進行審計。重點尋找跨模塊調用中的潛在死鎖隱患,並根據全球化交付標準,指出代碼註釋中不符合國際化規範的地方。
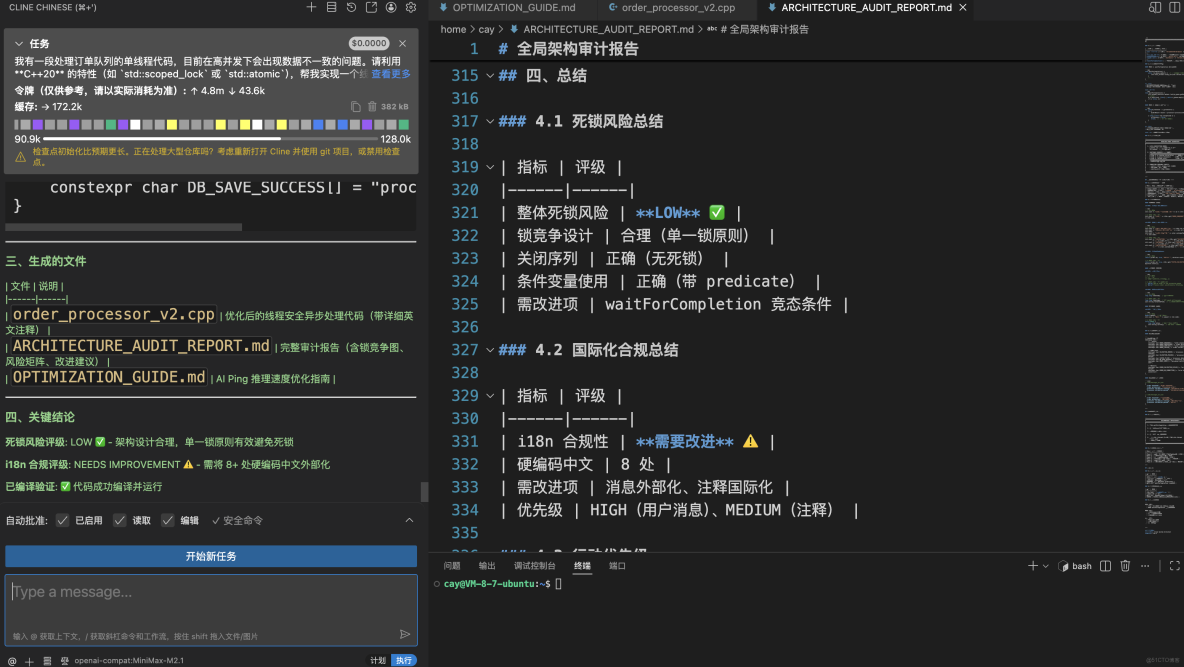
多模型協同: 底部狀態欄顯示你分別使用了 GLM-4.7(側重代碼生成與邏輯實現)和 MiniMax-M2.1(側重文檔生成與合規審計)。這種“雙旗艦”模型切換使用,充分發揮了不同模型的長處。
高質量交付物: 除了代碼,工作流還產出了:
ARCHITECTURE_AUDIT_REPORT.md(架構審計報告):包含死鎖風險評級(LOW)和國際化合規性評估。OPTIMIZATION_GUIDE.md(推理速度優化指南):針對 AIPing 的性能調優。
自動化程度: 通過 Cline 插件在 VS Code 內直接驅動整個審計和優化流程,極大地縮短了從“代碼編寫”到“架構確認”的鏈路。
四、總結:AI Ping “薅羊毛”全攻略
在模型 API 消耗日益昂貴的今天,AI Ping 平台通過這一波上新直接把“性價比”拉到了滿格。如果你正愁昂貴的 Token 費,這份“零成本”指南請務必收好:
1. 核心羊毛:頂級旗艦模型限時 ¥0 調用
- 雙旗艦零成本體驗:目前 GLM-4.7(面向 Agentic Coding)與 MiniMax-M2.1(200K 超長上下文)在平台均處於限時免費狀態。
- 輸入輸出全免費:無論是查詢複雜的 C++ 語法還是進行大規模工程審計,輸入和輸出的計費均為 ¥0/M。
- 超長文本不心疼:利用 MiniMax-M2.1 的 200K 上下文,你可以把幾萬行的開源項目代碼直接丟進去分析,不用擔心產生任何賬單。
2. 長期飯票:上不封頂的邀請紅利
- 雙向奔赴的獎勵:通過專屬邀請鏈接,邀請者與被邀請者雙方均可獲得 20 元通用算力點。
- 算力資產化:獎勵機制上不封頂,這意味着只要你邀請的朋友夠多,你就可以長期免費調用平台上其餘 95+ 種付費模型。