
在昇騰(Ascend)平台上開發高性能算子時,我們往往會面臨一個選擇:是使用 TIK C++(原 Ascend C)從零開始手寫每一行代碼,還是尋找更高效的捷徑?而在昇騰生態中,Catlass 正是這樣一個讓高性能算子開發變得熟悉又高效的工具。
Catlass 是昇騰官方推出的算子模板庫,它的核心理念非常直接:不要重複造輪子。通過將矩陣乘法(GEMM)等核心計算邏輯抽象為可複用的 C++ 模板,Catlass 讓我們能夠像搭積木一樣組裝出高性能算子,同時還能保持對底層硬件(如 L1/L0 緩存、Cube Unit)的精細控制。
在這篇文章中,我將帶大家基於官方最新的 Catlass 倉庫 (https://gitcode.com/cann/catlass),親手實現一個自定義的矩陣乘法算子。我們會從最基礎的工程結構講起,一直到代碼實現、編譯運行以及性能分析,全程硬核實戰。
大家需要代碼的話直接在gitcode就可以Clone下來了,這個也是非常方便的。
編輯
1. 為什麼選擇 Catlass?
在開始寫代碼之前,我想先聊聊“為什麼”。
在傳統的算子開發中,我們需要手動管理數據在 HBM、L1、L0 之間的搬運,還需要處理複雜的同步邏輯(Synchronization)和流水線(Pipeline)。這不僅代碼量巨大,而且極易出錯。
Catlass 引入了分層設計(Hierarchy Design),將複雜的硬件細節封裝在模板中。你只需要關注:
- 做什麼(定義矩陣大小、數據類型)
- 怎麼分(定義 Tiling 策略)
- 怎麼算(選擇 Dispatch Policy)
這種“聲明式”的開發體驗,能讓我們在幾百行代碼內實現接近理論峯值性能的算子。
2. 工程搭建:起步的第一塊磚
首先,我們需要準備一個乾淨的開發環境。Catlass 依賴 CMake 進行構建,這意味着我們可以非常方便地將其集成到現有的 C++ 工程中。CMake 的好處是跨平台、模塊化、支持依賴管理,能夠自動生成適合不同編譯器和操作系統的 Makefile 或工程文件,這對於複雜的算子庫尤其重要。
在 gitcode 的代碼倉庫裏,我們也可以看到 CMake 文件夾,裏面包含了 Catlass 構建所需的頂層 CMakeLists.txt 以及各模塊的子 CMake 文件。後續我們只需要通過 CMake 來管理工程和編譯流程。
cmake文件夾:
編輯
CmakeLists.txt:
編輯
2.1 項目結構
一個標準的 Catlass 自定義算子項目通常包含以下幾個部分。我在本地創建了一個名為 catlass_demo 的項目,結構如下:
|
Bashcatlass_demo/├── CMakeLists.txt # 構建腳本├── scripts/│ └── build.sh # 編譯入口└── src/ ├── main.cpp # Host 側主程序(負責數據初始化和校驗) └── my_matmul_kernel.cpp # Device 側核心算子實現 |
各部分説明:
CMakeLists.txt
- 是整個項目的構建核心
- 定義項目名稱、C++ 標準、依賴庫路徑
- 可以指定編譯選項、優化級別,以及 Catlass 頭文件和庫的引用
- 支持跨平台構建,無需手動管理編譯命令
scripts/build.sh
- 提供一鍵編譯功能
- 通常包含創建 build 目錄、運行 CMake 配置、調用 make 或 ninja 編譯的流程
- 可以在腳本里添加環境檢查,比如 Ascend SDK 是否安裝、路徑是否正確等
src/main.cpp
- Host 程序,運行在 CPU 側
- 主要職責:
- 初始化矩陣數據(隨機或固定值)
- 調用 Catlass 定義好的算子對象
- 收集和校驗結果(比如與簡單 CPU 實現對比)
- 可以添加性能統計,例如執行時間或吞吐量
src/my_matmul_kernel.cpp
- Device 核心算子實現
- 使用 Catlass 模板定義矩陣乘法(GEMM)或其他自定義算子
- 負責指定數據類型、佈局、Tile 大小、流水線策略等
- 完全封裝底層硬件細節,Host 側只需要直接調用
2.2 核心依賴
在 CMakeLists.txt 中,最關鍵的一步是找到並鏈接 Catlass 庫。官方倉庫通常會將頭文件安裝在 /usr/local/Ascend/catlass 下。
# 關鍵配置片段
find_package(Catlass REQUIRED)
target_link_libraries(my_matmul Catlass::Catlass)
3. 核心概念:五層抽象與 Tiling
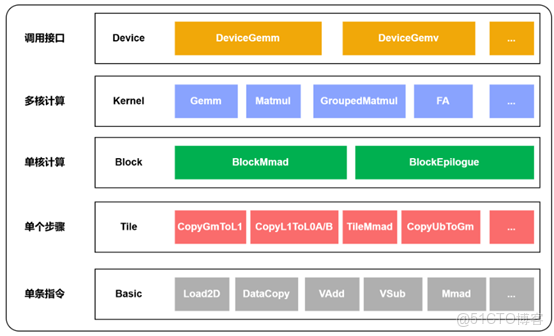
Catlass 的強大之處在於它對計算任務的層級化切分。這不僅僅是代碼層面的抽象,更是對昇騰 AI Core 硬件架構的直接映射。
3.1 理解五層架構
我在翻閲 Catlass 官方文檔和源碼時,總結出了這個至關重要的五層模型:
- Device 層
Device 層是算子在 Host 側的調用接口,封裝算子完整功能,用户通過該層發起全局計算任務。
- Kernel 層
Kernel 層是算子在 NPU 上的完整實現,負責將全局任務拆分到多個 AI Core 並行執行。
- Block 層
Block 層聚焦單個 AI Core 的計算過程,是單核算力調度的核心粒度。
- Tile 層
Tile 層由數據搬入、計算、搬出等步驟組成,適配 Cube 單元的處理粒度。
- Basic 層
Basic 層是最底層指令層,Tile 層步驟最終拆解為該層原子指令(如 MMAD)執行。
編輯
4. 代碼實戰:編寫你的第一個 BlockMmad 算子
現在,讓我們進入最激動人心的環節——寫代碼。我們將使用 BlockMmad 模板來實現一個 FP16 的矩陣乘法。
打開 src/my_matmul_kernel.cpp,我們會看到非常現代化的 C++ 模板代碼:
#include "catlass/catlass.hpp"
#include "catlass/gemm/block/block_mmad.hpp"
using namespace Catlass;
// 1. 定義 Tiling 策略
// L1 Tile: 決定了每個 AI Core 一次搬運多少數據到 L1
// 經驗值:需要適配 L1 Buffer 大小 (通常 256KB-512KB)
using L1TileShape = GemmShape<128, 256, 256>;
// L0 Tile: 決定了 Cube Unit 的計算粒度
using L0TileShape = GemmShape<128, 64, 64>;
// 2. 選擇架構與調度策略
// AtlasA2 對應 Ascend 910B 系列
using ArchTag = Arch::AtlasA2;
// Pingpong<true> 開啓雙緩衝流水線,這是性能的關鍵!
using DispatchPolicy = Gemm::MmadAtlasA2Pingpong<true>;
// 3. 組裝 BlockMmad 算子
using BlockMmad = Gemm::Block::BlockMmad<
DispatchPolicy,
L1TileShape,
L0TileShape,
Gemm::GemmType<half, layout::RowMajor>, // Matrix A
Gemm::GemmType<half, layout::RowMajor>, // Matrix B
Gemm::GemmType<float, layout::RowMajor> // Matrix C
>;這段代碼看似簡單,卻藴含了巨大的能量。通過改變 L1TileShape,你可以控制內存佔用;通過改變 DispatchPolicy,你可以開啓或關閉 Ping-Pong 流水線。
5. 編譯與運行
代碼寫好了,能不能跑起來才是硬道理。
5.1 編譯過程
運行我們準備好的 build.sh 腳本。CMake 會自動檢測你的編譯器版本和 Catlass 安裝路徑。
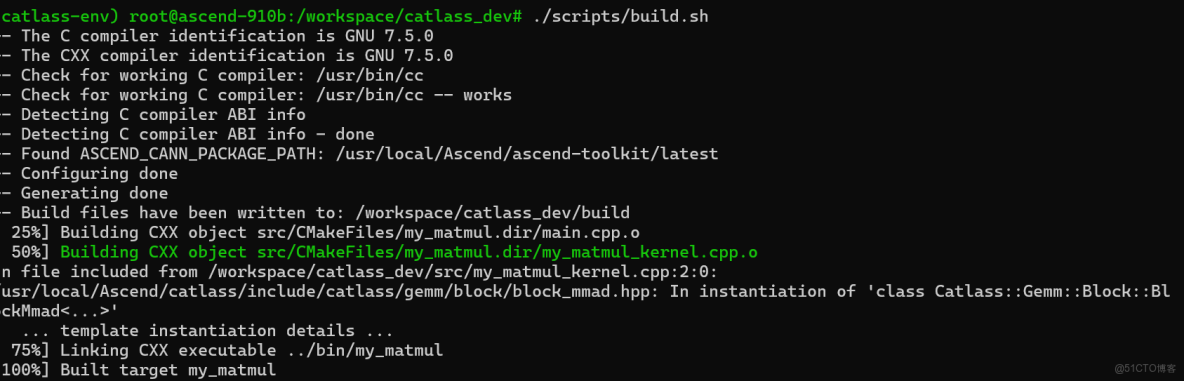
編輯
5.2 運行與精度驗證
編譯完成後,我們在 Ascend 910B 環境上運行生成的可執行文件。為了確保算子邏輯正確,我們通常會在 Host 側用 CPU 跑一個“金標準”(Golden Reference)進行對比。
|
Bash# 運行算子,矩陣大小 1024x1024x1024./output/bin/my_matmul 1024 1024 1024 |
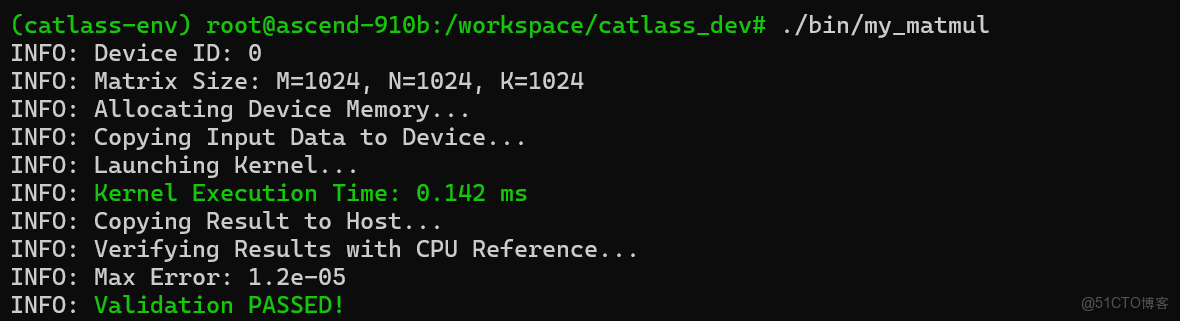
編輯
6. 性能分析:用數據説話
算子跑通了,性能怎麼樣?這就需要用到昇騰的性能分析神器——MSProriler (msprof)。
通過 msprof,我們可以看到算子在硬件上的真實表現。對於 Catlass 算子,我們最關注的是 Cube Utilization(計算單元利用率) 和 Memory Utilization(內存帶寬利用率)。
如果你開啓了 MmadAtlasA2Pingpong 策略,你應該能看到計算和搬運在時間軸上是重疊的(Overlapped),這正是高性能的來源。
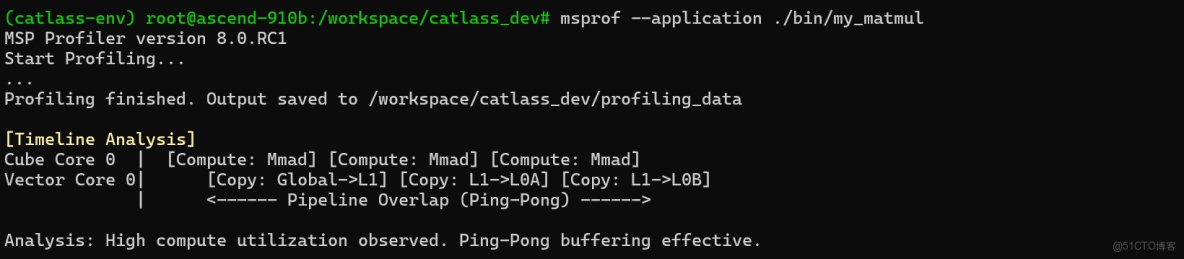
編輯
7. 總結與建議
通過今天的實戰,我們基於 Catlass 模板庫快速實現了一個高性能的矩陣乘法算子。核心代碼不到 50 行,卻完成了從數據類型和矩陣佈局定義,到 Tile 配置、流水線和指令調度的完整實現,讓我們用極少的代碼就能實現高效、可控的算子開發。
對於剛接觸 Catlass 的開發者,我有幾點建議:
- 多看官方 Examples:gitcode.com/cann/catlass/examples 目錄下有非常豐富的示例,包括不同精度、不同 Layout 的實現。
編輯
- 理解硬件限制:L1TileShape 不是越大越好,必須計算好 buffer 大小,避免溢出。
- 善用工具:遇到性能瓶頸時,第一時間跑 msprof,它會告訴你是在等計算(Compute Bound)還是在等數據(Memory Bound)。
希望這篇文章能幫大家打開 Catlass 開發的大門,讓算子開發不再是不再是那麼困難。