

引言
一直以來,真正限制大模型落地的,往往不是“能不能用”,而是算力成本和穩定性。尤其是在需要反覆測試、對比不同模型和供應商的階段,算力消耗幾乎是硬門檻。
AI Ping 這次的做法比較直接:隨着 GLM-4.7 和 MiniMax M2.1 兩款旗艦模型上線,平台同步開放了算力激勵機制,把“體驗成本”壓到了接近零。通過模型聚合與加速調度,同一套接口即可調用多家供應商節點,在保證性能的同時,降低了試錯成本。
如果你正處在模型選型或 Agent 測試階段,這個機制的價值其實很明確:
- 可以無壓力跑對比測試,而不是隻看文檔和參數
- 能在真實負載下驗證吞吐、延遲和穩定性
對於想低成本體驗 GLM-4.7 的工程交付能力,或 MiniMax M2.1 的長鏈 Agent 表現的開發者來説,這是一個幾乎沒有試錯成本的窗口期。
一、AI ping平台介紹
在實際工程中,使用大模型往往面臨一個被低估的問題:模型本身並不是唯一變量,供應商、網絡、負載與調度策略同樣決定最終體驗。同一模型在不同雲廠商上的吞吐、延遲和穩定性,差異往往超過模型之間的差異。
AI Ping 正是圍繞這一現實問題而設計的模型聚合與評測平台。
平台定位:為工程選型服務,而不是“多接幾個模型”
AI Ping 的核心定位並非簡單地“接入更多模型”,而是把模型能力放在真實工程環境中進行橫向對比。平台目前已對接多家主流模型廠商與雲服務商,在統一入口下提供:
- 同一模型 × 多供應商 的並行接入
- 統一 OpenAI 兼容接口,避免重複適配 SDK
- 面向工程的關鍵指標:吞吐、P90 延遲、上下文長度、價格與可靠性
這意味着,開發者在選型階段關注的不是“模型參數有多大”,而是在自己業務負載下,哪種組合最穩定、最划算、最可控。
統一調用接口:降低接入與切換成本
在沒有聚合平台的情況下,每更換一個模型或供應商,往往需要:
- 重新對接 API
- 調整鑑權方式
- 修改返回結構解析
- 重新做限流與錯誤處理
AI Ping 通過 OpenAI 兼容接口 把這些成本壓縮到最低。對應用側而言:
- 切換模型 = 改一個
model參數 - 切換供應商 = 修改或交由平台自動路由
- 代碼結構保持不變
這在需要快速 A/B 測試模型表現或根據成本、峯值負載動態調整的工程場景中尤為重要。
性能可視化:用數據而不是感覺做決策
AI Ping 將平台內各模型、各供應商的關鍵性能指標進行持續監測與展示,包括:
- 吞吐量(tokens/s)
- P90 / P95 延遲
- 上下文支持能力
- 單位輸入/輸出成本
- 歷史穩定性與可用率
這些數據並非一次性 benchmark,而是貼近真實調用環境的持續觀測結果。對於需要做模型選型評審、成本評估或 SLA 設計的團隊來説,這類數據比單點跑分更有參考價值。
多供應商與智能路由:應對不穩定是常態
在高併發或流量波動場景下,模型調用的不穩定往往來自供應商層面,而非模型本身。AI Ping 提供的智能路由能力,可以:
- 在多個可用供應商之間自動切換
- 在高峯或異常時優先選擇更穩定、延遲更低的節點
- 降低單點故障對業務的影響
對於長鏈 Agent 或需要持續運行的後台任務,這種供應商級的容錯與調度能力往往比單模型能力更關鍵。

二、GLM-4.7 模型解析
如果把 GLM-4.7 放進真實項目中觀察,它更像是一個“可控、穩定、偏交付導向”的工程型模型,而不是追求極限生成能力的展示型模型。它的優勢並不體現在某一個單點指標上,而體現在複雜任務從輸入到交付的完整閉環。
面向複雜工程的一次性交付能力
GLM-4.7 的核心設計目標之一,是減少多步驟工程任務中的不確定性。在實際使用中,這種特性通常體現在:
- 對複雜需求的拆解更加剋制,不容易在中途“發散”
- 對任務邊界的理解更明確,生成結果更接近“可直接使用”
- 在前端頁面、交互邏輯、配置文件等產物上,完整度高、返工成本低
這使得 GLM-4.7 特別適合用於:
- 項目初始化階段的整體架構設計
- 前端頁面或交互原型的快速生成
- 需要一次性產出完整結果的工程任務
與強調持續輸出的模型相比,GLM-4.7 更像是“一次把事做對”的工具。
可控推理:穩定性優先於生成長度
在多步任務中,模型是否“聰明”往往不如是否“可控”重要。GLM-4.7 在推理層面的一個顯著特徵是可控思考機制:
- 推理路徑相對穩定,不容易在長任務中偏離原始目標
- 對工具調用、接口約束的遵循度更高
- 在需要嚴格結構輸出(如 JSON、配置文件)時出錯率較低
在工程實踐中,這直接影響:
- Agent 工作流是否能穩定執行到最後一步
- 工具鏈(數據庫、CI、外部 API)調用是否可預測
- 自動化流程是否需要頻繁人工兜底
對於希望降低人工干預成本的團隊來説,這是 GLM-4.7 的一個關鍵優勢。
編碼與 Artifacts 生成的實際表現
在編碼能力上,GLM-4.7 並不刻意追求“覆蓋所有語言”,而是更強調結構正確性與整體完成度:
- 前端組件、頁面佈局和樣式的整體一致性較好
- 對工程目錄結構、模塊劃分有較強的整體意識
- 在生成 Artifacts(如頁面、文檔、腳手架代碼)時,視覺與結構完成度高
這也是為什麼在 Agentic Coding 或 前端相關任務 中,GLM-4.7 往往能減少多輪修改。
需要注意的是,在極端偏後端、強類型、性能敏感的場景(如複雜 C++/Rust 底層邏輯),GLM-4.7 並非最激進的選擇,但在“端到端交付”任務中表現穩定。
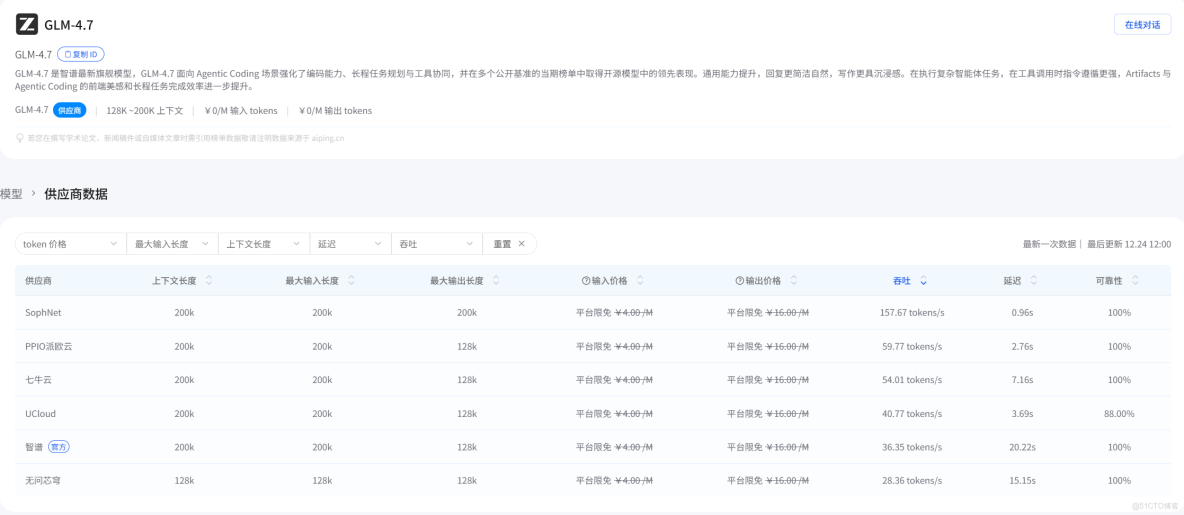
性能與調用表現(基於 AI Ping 實測)
根據 AI Ping 平台的實測數據
適合使用 GLM-4.7 的典型場景
綜合能力與表現,GLM-4.7 更適合以下類型的任務:
- 複雜工程的一次性交付(前端、原型、架構文檔)
- 對輸出結構、完整性要求高的任務
- Agent 工作流中的“關鍵決策節點”
- 需要可控推理、低漂移的自動化流程
如果你的目標是儘快得到一個可用、可維護、結構清晰的結果,而不是持續不斷地產出內容,GLM-4.7 往往是更穩妥的選擇。
三、MiniMax M2.1 模型解析
如果説 GLM-4.7 更像一個“工程交付型選手”,那麼 MiniMax M2.1 的定位則非常明確:為長時間運行的 Agent 與持續編碼任務服務。它關注的不是單次輸出是否“驚豔”,而是在多輪、多任務、長上下文條件下,是否還能保持穩定、可控和高效。
面向長鏈 Agent 的設計取向
MiniMax M2.1 的核心優勢之一,是對長鏈任務與持續運行場景的針對性優化。在實際使用中,這種優勢主要體現在:
- 長時間對話中上下文銜接更自然,不易“遺忘”早期約束
- 多輪任務執行過程中,推理路徑更收斂,較少出現無關發散
- 連續編碼、反覆修改同一模塊時,狀態保持能力較強
這類特性對於構建常駐 Agent(如自動運維、代碼巡檢、持續數據處理)尤為重要。
高效 MoE 架構與持續吞吐能力
MiniMax M2.1 採用高效的 MoE(Mixture of Experts)架構,這在工程層面的直接收益是:
- 低激活參數:單次推理調用消耗更可控
- 更高吞吐:在併發和長時間運行場景下表現穩定
- 更好的性價比:適合需要持續調用的大規模任務
從 AI Ping 平台的實測數據來看,MiniMax M2.1 在部分供應商節點上吞吐接近 90–100 tokens/s,在同類模型中處於較高水平。這使它在需要長時間持續輸出的場景中更具優勢。
多語言後端工程的實際表現
與偏重前端和整體交付的模型不同,MiniMax M2.1 在多語言後端工程中表現得更加“務實”:
- 對 Rust / Go / Java / C++ 等強類型語言的結構理解更穩
- 生成的代碼更貼近真實工程約束(包結構、依賴管理、接口定義)
- 在迭代修改同一模塊時,前後邏輯銜接度較高
在需要頻繁與現有代碼庫交互、反覆增量修改的場景下,這種特性可以顯著減少“推倒重來”的情況。
長上下文帶來的工程價值
MiniMax M2.1 支持 最高 200k 上下文,這一點在工程實踐中的意義,往往被低估:
- 可以一次性加載更完整的代碼倉庫或配置文件
- 減少切片帶來的語義斷裂
- 在長流程 Agent 中避免頻繁“重新講背景”
對於需要處理大型項目、複雜業務邏輯或跨模塊依賴的任務,這種上下文優勢會直接轉化為效率提升。
穩定性與供應商表現(基於 AI Ping)
在 AI Ping 平台的實測中,MiniMax M2.1 在多個供應商節點上表現出:
- 較低的 P90 延遲
- 高吞吐下仍保持 100% 可用率
- 在長時間運行測試中,性能波動相對較小
這使得它非常適合作為:
- 後台 Agent 的默認執行模型
- 高併發、長時間運行任務的主力模型
MiniMax M2.1 的使用邊界
需要客觀看待的是,MiniMax M2.1 並不是為所有場景而生:
- 在強調一次性高質量交付(尤其是前端/UI)的任務中,可能需要更多人工校正
- 對極複雜、強約束的單次決策問題,其優勢不如持續型任務明顯
因此,將它放在“持續執行”而非“一次定稿”的位置,往往能發揮更大價值。
四、註冊與快速上手指南
如果只是“註冊成功”,並不能説明你已經真正用上了模型。真正的上手標準只有一個:在自己的環境裏,把模型請求跑通,並能穩定復現結果。下面按照這個目標,給出最短、可執行的路徑。
註冊與獲取 API Key
- 打開 AI Ping 官網(aiping.cn),完成註冊並登錄。
- 進入控制枱或個人中心,找到 API Key 管理頁面。

- 創建並複製 API Key(建議只用於測試環境,生產環境單獨創建)。
實際建議:
- 不要把 Key 直接寫在代碼裏,使用環境變量或配置文件。
- 如果後續要接入多個項目,提前規劃 Key 的用途,方便權限與成本管理。
用最小示例驗證調用是否成功
AI Ping 提供 OpenAI 兼容接口,因此你可以用最熟悉的 SDK 直接測試。以下示例以 Python 為例,目標只有一個:確認請求能通、響應穩定。
from openai import OpenAI
client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="YOUR_API_KEY"
)
resp = client.chat.completions.create(
model="GLM-4.7", # 或 MiniMax-M2.1
messages=[
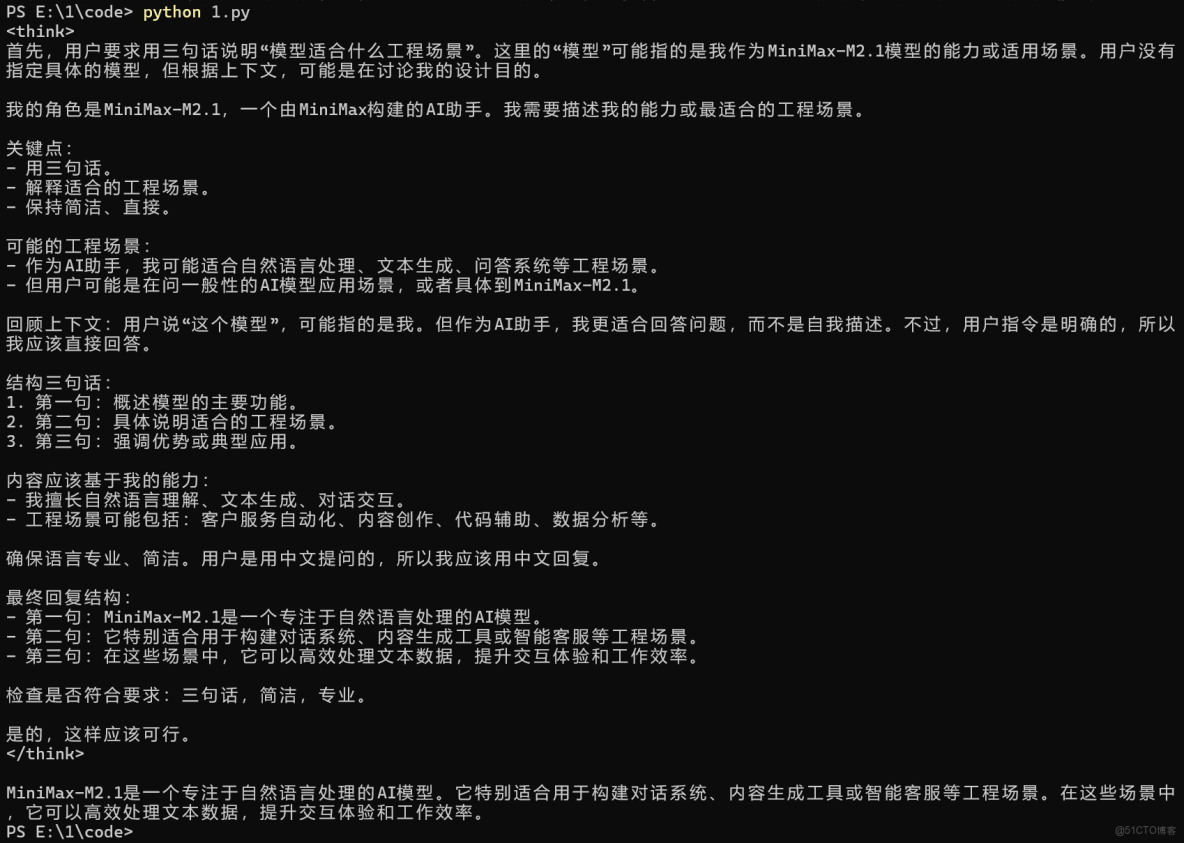
{"role": "user", "content": "用三句話説明這個模型適合什麼工程場景。"}
]
)
print(resp.choices[0].message.content)如果你能穩定看到返回內容

説明:
- 網絡連通正常
- Key 權限有效
- 模型與默認供應商可用
這一步非常關鍵,不要跳過。
切換模型與對比測試(工程必做)
在 AI Ping 上切換模型不需要改代碼結構,只需改一個參數:
model="MiniMax-M2.1"
建議在真實項目前,至少做一次對比測試:
- 同一個 Prompt
- 不同模型(GLM-4.7 / MiniMax M2.1)
- 觀察輸出穩定性、響應時間與可讀性
這樣你很快就能感受到兩者在“交付 vs 持續執行”上的差異。
在本地工具中直接使用(可選但很實用)
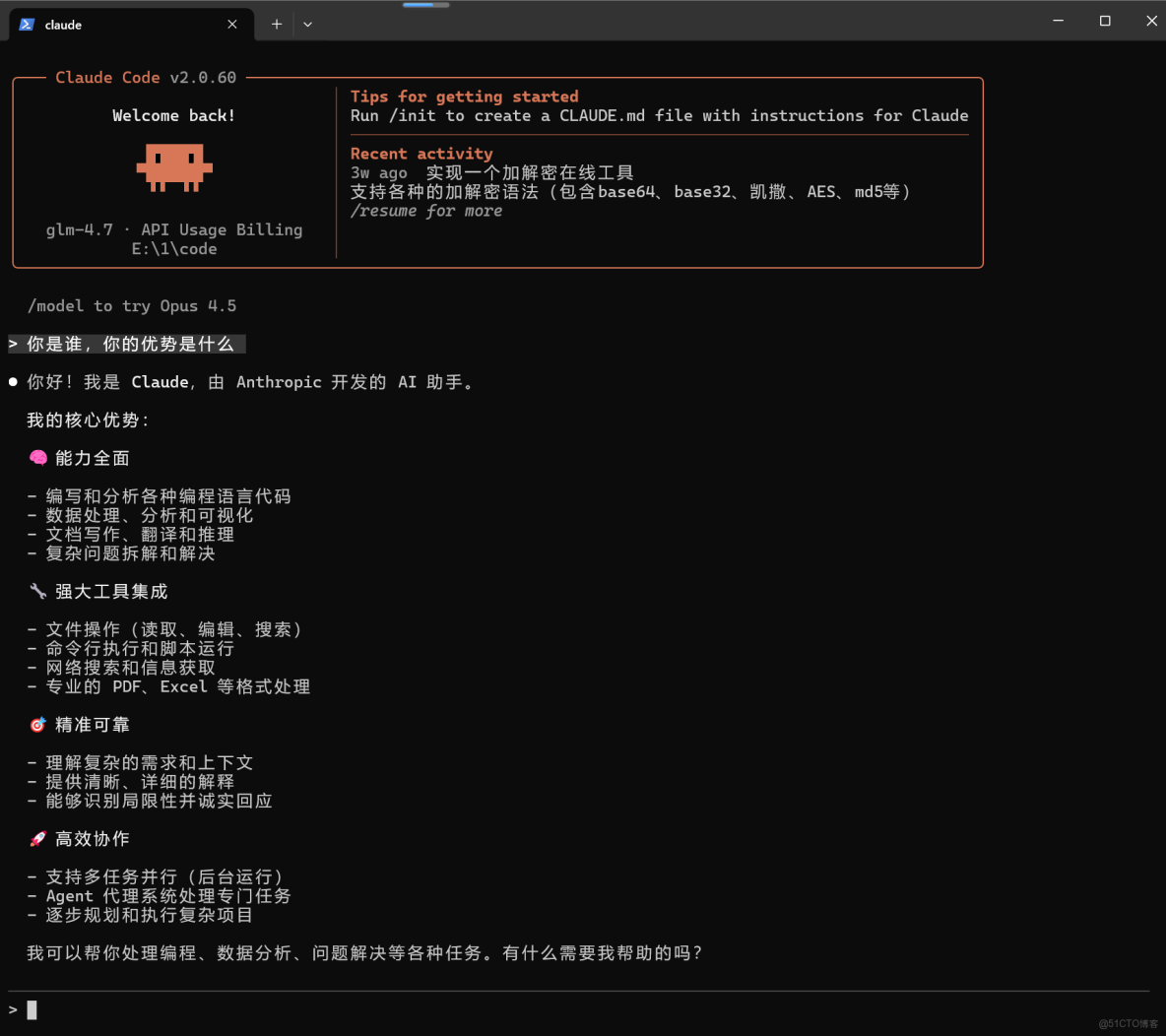
Claude Code 中使用 GLM-4.7
如果你習慣在本地用 Claude Code 做工程任務,可以通過環境變量直接把模型切到 AI Ping:
- 設置
ANTHROPIC_BASE_URL為 AI Ping 的 Anthropic 兼容地址 - 把
ANTHROPIC_AUTH_TOKEN替換為你的 API Key - 將默認模型指向
GLM-4.7
這樣可以無縫複用原有工作流,非常適合做複雜工程交付。
現在我們開始code開發,我們需要先前往C盤下面的users裏面的administrator文件夾下面進入.claude目錄,然後創建json文件添加:
{
"env": {
"ANTHROPIC_BASE_URL": "https://aiping.cn/api/v1/anthropic",
"ANTHROPIC_AUTH_TOKEN": "your API KEY",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_MODEL": "GLM-4.7",
"ANTHROPIC_SMALL_FAST_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "GLM-4.7"
}
}
然後在終端輸入claude即可
Coze 中使用 MiniMax M2.1
如果你在做 Bot 或 Agent 工作流,Coze 是更合適的入口:
- 在插件市場安裝 AI Ping 官方插件
- 在工作流中配置模型為
MiniMax-M2.1 - 設置
stream、temperature與max_tokens - 通過試運行驗證長鏈任務是否穩定
這套方式尤其適合測試 持續運行型 Agent。
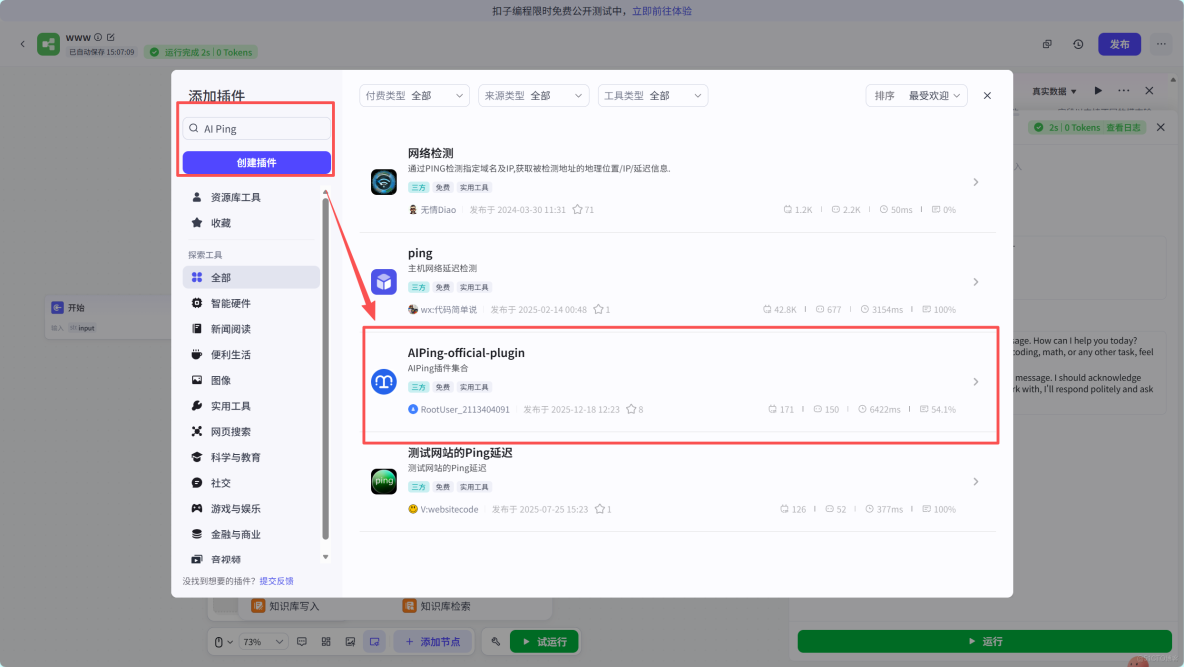
點擊添加節點,然後單擊插件進來,搜索AI Ping找到圖中對應的節點進行添加即可。
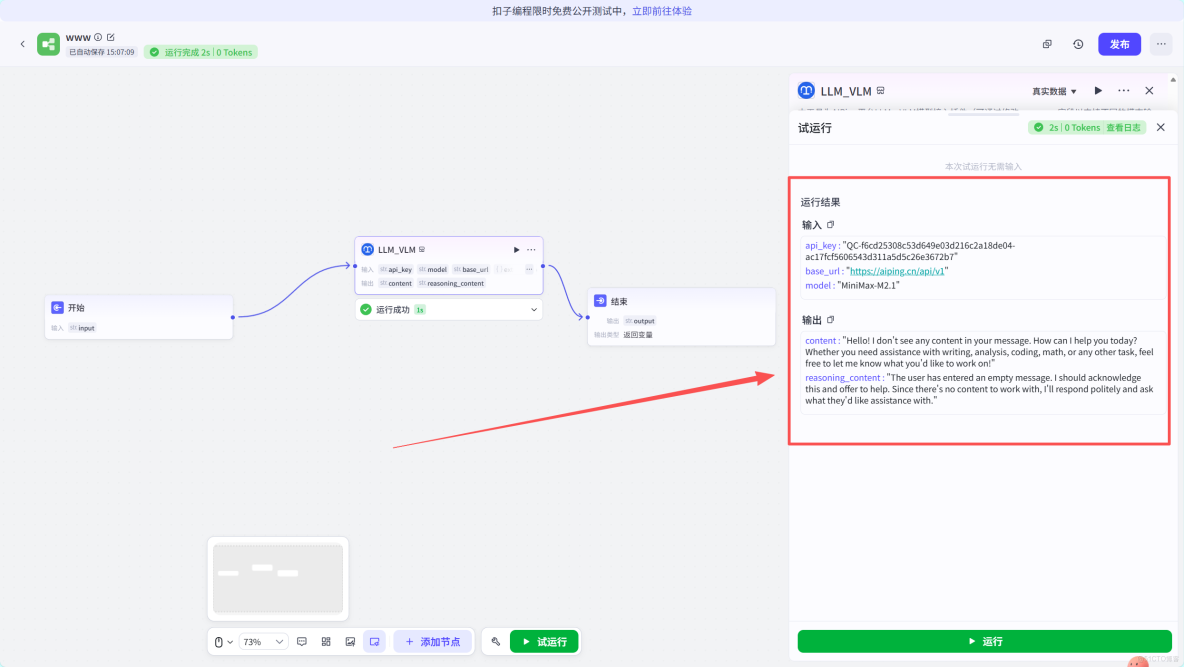
這裏進行測試節點是否可用,出現這個提示就説明是可用的哈。
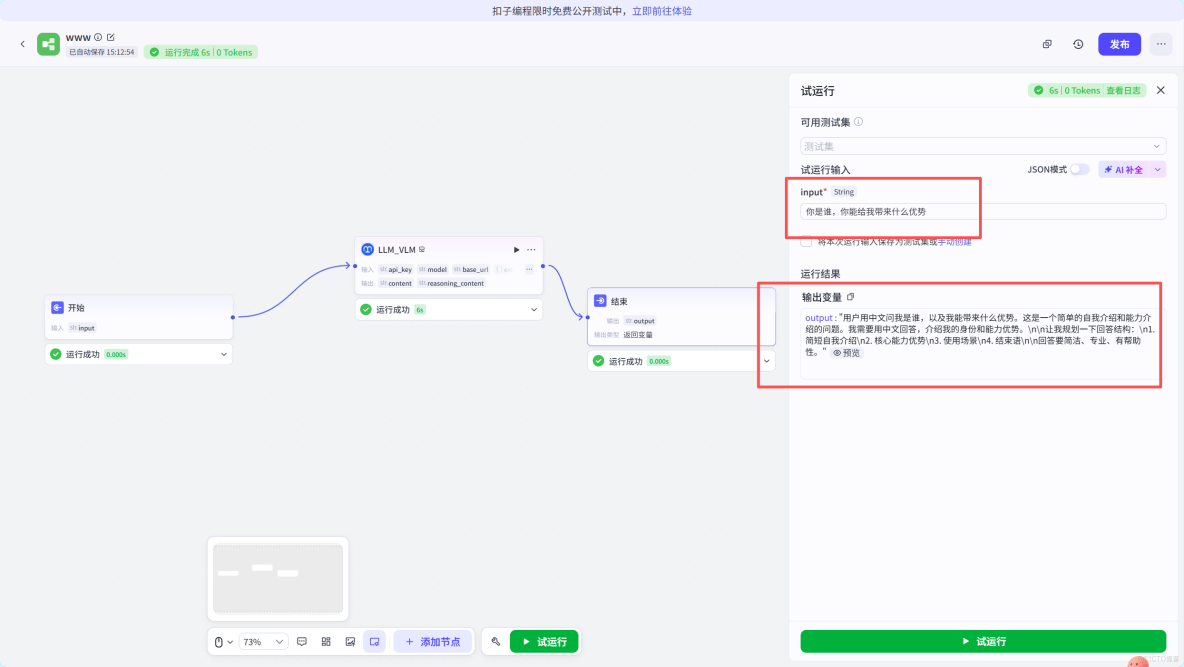
然後進行集中測試。確實夠簡潔

問了一個專業知識就得到了以下
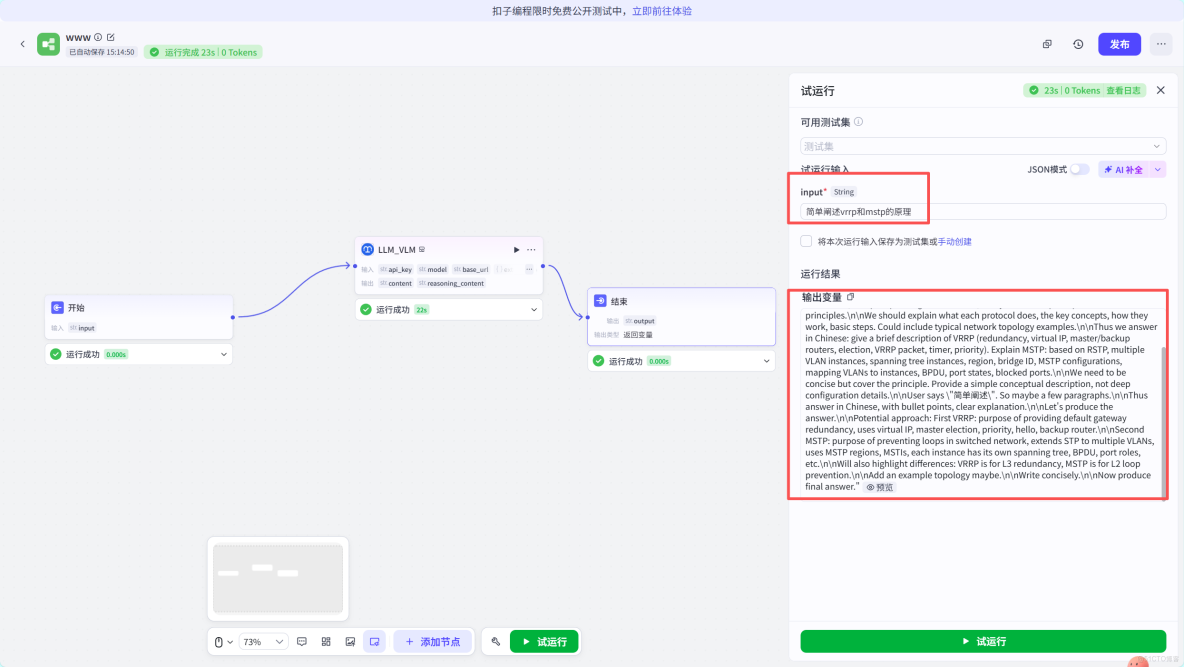
我給大家翻譯一下

總結
回到工程本身,其實很難用一句話去評價 GLM-4.7 或 MiniMax M2.1 的“優劣”。它們更像是被放在了不同工程位置上的工具。
- GLM-4.7 更適合作為“關鍵節點模型”: 用在架構設計、前端原型、一次性交付型任務或 Agent 工作流中的決策階段,它強調的是可控、完整、低返工率。當你希望一次輸出就儘量接近可用結果,而不是反覆拉扯時,它往往更穩。
- MiniMax M2.1 則更像“持續執行引擎”: 面向長鏈 Agent、後台任務、持續編碼和多語言後端工程,它的優勢在於高吞吐、長上下文與運行穩定性。在需要長時間運行、反覆迭代同一任務的場景下,它更容易把成本和性能控制在可預期範圍內。
而 AI Ping 的價值,並不在於“讓你多用幾個模型”,而是通過多供應商實測、統一接口和智能路由,把“模型 + 供應商”這個原本隱性的變量顯性化。你不再需要憑感覺選型,而是可以基於真實數據,在自己的業務負載下做決定。
如果只能給一個工程層面的建議,那就是: 不要糾結哪個模型更強,先想清楚你的任務是“一次定稿”,還是“長期運行”。 前者優先穩定與可控,後者優先效率與持續性。剩下的,就交給平台和數據去驗證。
當模型真正跑在你的工程裏,而不是停留在評測表格中,結論往往會比任何榜單都清晰。