
項目背景
行業痛點
- 漫劇/短視頻內容生產成本高、週期長(腳本→分鏡→美術→動畫→配音)
- 初創漫劇企業/教育機構缺乏專業動漫製作能力,但有高頻輕量級視頻需求(如營銷廣告、兒童英語啓蒙)
- 現有AIGC工具鏈割裂,依賴人工,缺乏“一致性控制”與“用户干預閉環”
項目定位
打造一個 端到端、可交互、風格一致 的漫劇生成智能體 Demo,支持:
- 輸入一句話創意 → 輸出 30s–60s 動漫短劇(含畫面+配音+字幕)
- 用户在關鍵節點(角色、場景、分鏡)可人工確認或抽卡重新生成
- 支持兩種典型場景:營銷廣告 + 少兒旁白科普課程(磨耳朵學英語場景)
業務價值
- 驗證 Agentic Workflow 在多模態內容生成中的可行性,體現Qoder智能體模式的強大,幫忙推廣Qoder。
- 構建基於 Qwen + Wan + 百鍊的通義全家桶 AIGC 工具鏈,證明在漫劇賽道,通義能對標即夢、可靈、Vidu、Sora等友商。在細節能力上正視差距,推進產品迭代改進。
- 協助沒有智能體搭建經驗的漫劇賽道初創公司進行工程化搭建,彌補在漫劇工具鏈上跟友商的差距,為後續 SaaS 化或嵌入營銷/教育平台提供技術原型。
需求分析與功能定義
系統架構
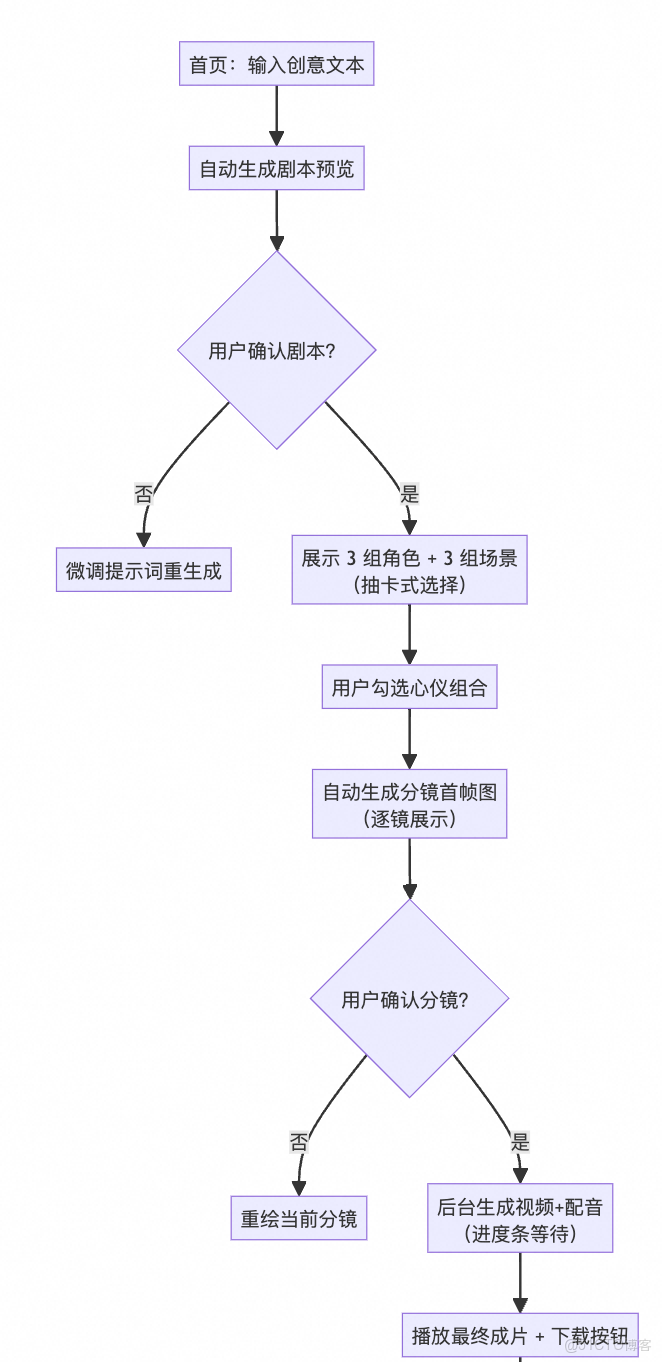
功能模塊
|
模塊名稱 |
輸入 |
輸出 |
是否可交互 |
技術實現 |
|
創意解析器 |
用户創意(文本) |
結構化劇本(JSON) |
否 |
Qwen-Max |
|
角色生成器 |
劇本人物描述 |
多組角色立繪(PNG) |
是(抽卡×3) |
Wan 2.5-t2i-preview |
|
場景生成器 |
劇本場景描述 |
多組背景圖(PNG) |
是(抽卡×3) |
Wan 2.5-t2i-preview |
|
分鏡繪製器 |
(角色+場景+分鏡文本) |
分鏡首幀圖 |
是(逐鏡確認) |
Wan 2.2-i2i-flash |
|
視頻生成器 |
首幀 + 劇本動作描述 |
3–10s 視頻片段(MP4) |
否(自動) |
Wan 2.5-i2v-preview |
|
合成引擎 |
視頻片段 + 音頻 + 字幕 |
最終成片(MP4) |
否 |
FFmpeg + 自定義合成邏輯 |
需求約束
- 一致性保障:同一角色/場景在不同分鏡中保持視覺一致(通過ID綁定+特徵緩存)。
- 生成速度:全流程 ≤ 10 分鐘(Demo 可接受,非實時)。
- 可控性:每個“抽卡”環節提供 ≥3 選項,支持重試。
- 合規性:不生成真人肖像,角色為動漫風格。
交互流程
- 創意輸入:一句話描述想生成的內容。
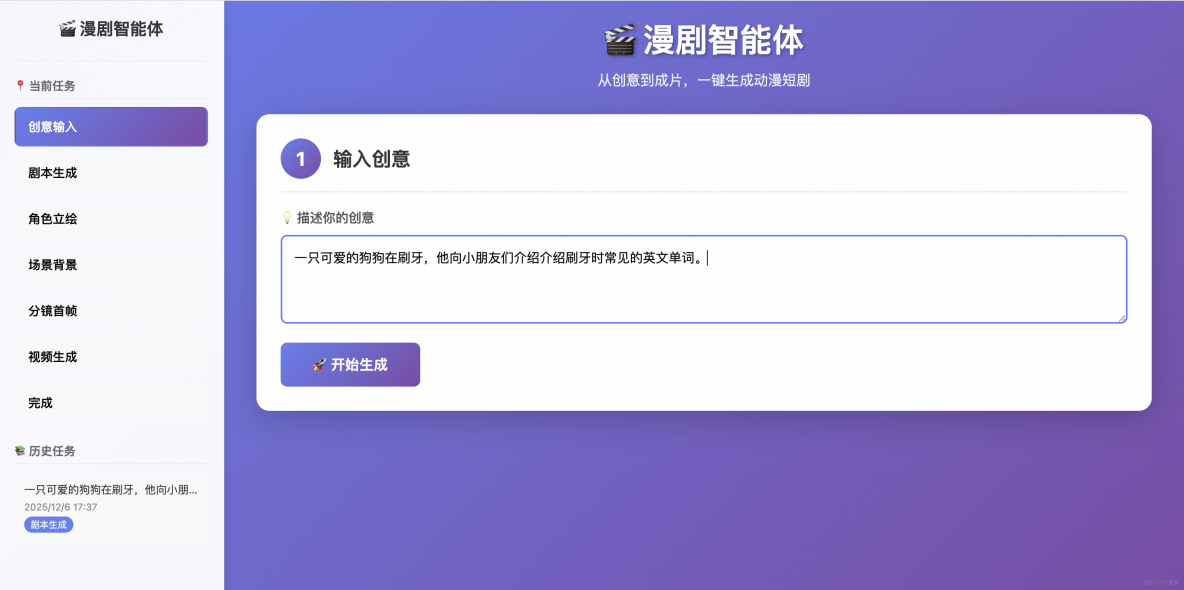
- 劇本生成:根據輸入的創意自動拆解角色/場景/分鏡。基於創意進行劇本的擴寫,分鏡的要素按JSON格式輸出,包括角色,場景,構圖,光線,角色動作,情緒,時長(每個片段3-10s),音效,配音描述(用於控制音色一致性)。

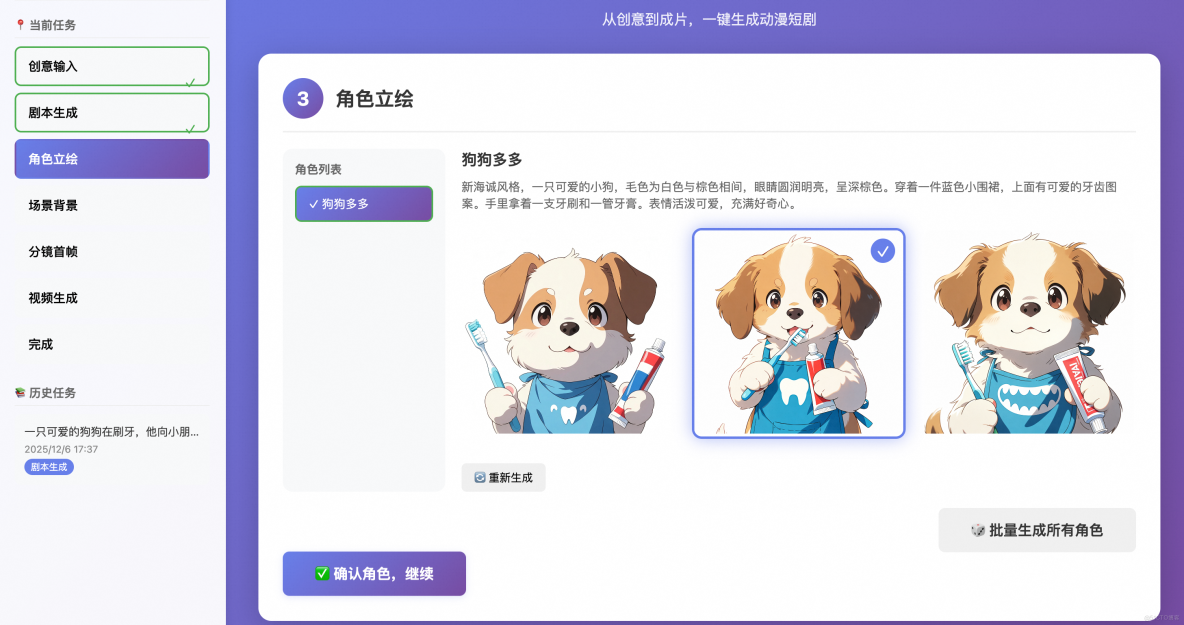
- 角色生成:百鍊調用Wan2.5-t2i-preview生成角色圖,一次三張,可以抽卡重新生成,時間大概20s。
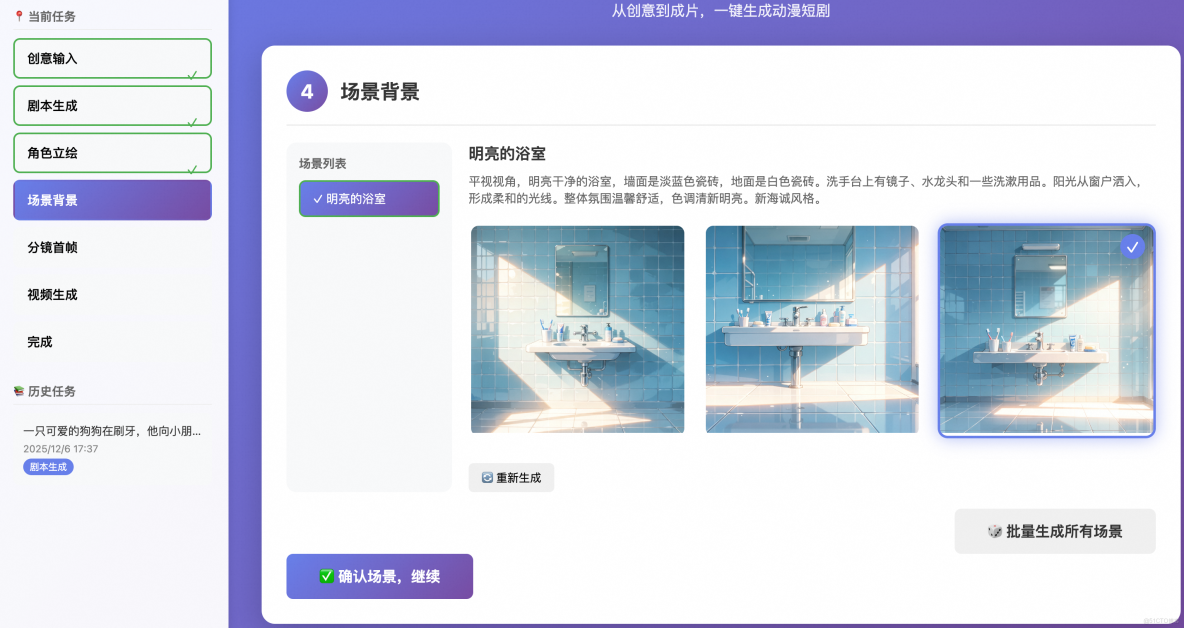
- 場景生成:同上生成場景圖,都是為了控制分鏡主體一致性。
- 分鏡生成:使用Wan2.2-i2i-flash參考角色圖和場景圖,結合詳細分鏡描述按順序生成每個分鏡的首幀,每張大概30s。

- 視頻生成:確認好分鏡圖後,使用Wan2.5-i2v-preview結合劇本描述和台詞同步生成視頻和相應的配音,音畫同步,並且自動完成剪輯拼接,整個過程3~5min。視頻時長根據分鏡多少決定,一般20s~1min。

效果演示
單角色講解場景
- 動漫小狗早晨刷牙
雙角色對話場景
- 3D小魚海底購物
- Q版日常打招呼
搭建工具
全程使用 Qoder自然語言生成+百鍊API調用
1.使用Qoder Quest模式生成初版,把需求和大致思路像老闆一樣指派任務給agent,他會自主先生成產品需求設計,規劃待辦,再進行執行。
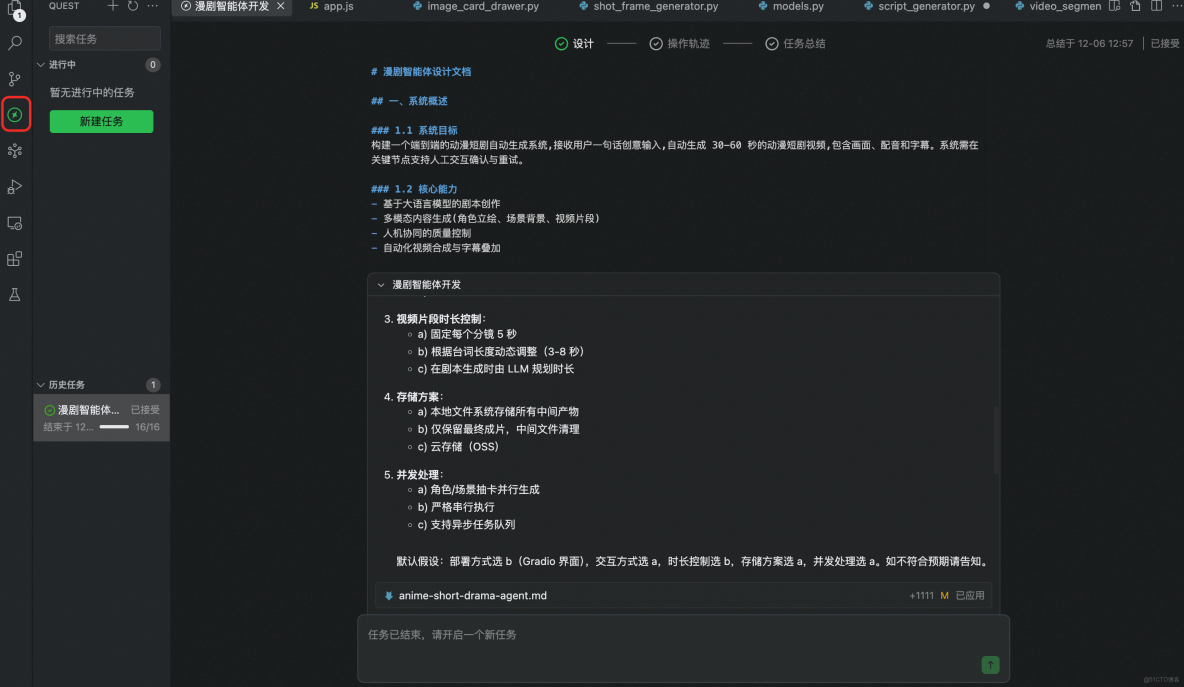
2.需要向他提供自己百鍊API-Key。
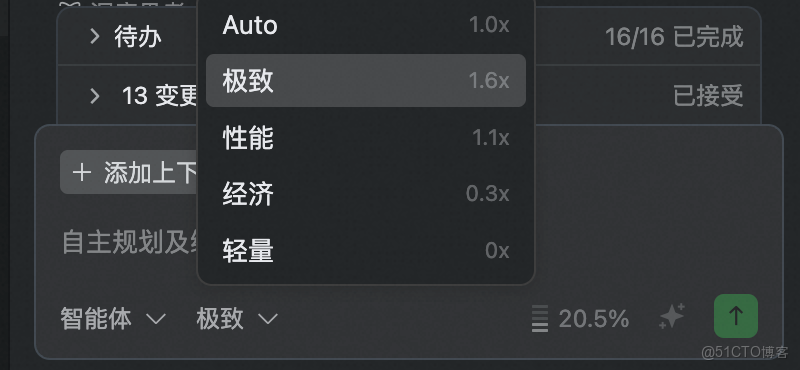
3.在生成完初版項目之後,使用智能體模式進行精調。最好使用極致模式,性能最好但消耗多。
4.明確使用的模型具體名稱,不然會出現調用失敗。提供明確的名稱後會智能體會自行查閲網頁找到合適的接口格式。
目前問題
- 配音直接使用Wan2.5視頻同步生成,好處是可以同步生成環境音效。為了保證音色一致性目前的解決方案是使用提示詞約束,但效果不太好,後續考慮用TTS模型單獨配音再合成。
- 多角色,多場景的分鏡圖合成還是控制的不夠精細,目前最好的情況還是單場景單一角色的介紹,如果在複雜性高的多角色交互,場景切換的任務下還需要優化。
- Qoder目前僅能個人開通PRO版,Credit有限,跑這樣一個 Demo大概就花了一半的用量,希望可以儘快開通企業版內部使用。
效果展示視頻可點擊該鏈接查看