

當 OpenAI 剛推出 API 時,定價模式非常簡單
只有一個按量付費(pay-as-you-go)模型——無論是什麼工作負載,你都只需要按 token 計費。
隨着需求爆發、場景多樣化,這種模式逐漸變得“過於粗糙”。
並不是所有請求都有同樣的緊急程度、規模或業務價值:
- 有些需要毫秒級、可預測的響應;
- 有些則完全可以等幾分鐘,甚至幾個小時——只要能讓成本減半。
為了應對這些差異,OpenAI 推出了服務等級(Service Tiers):Standard、Priority、Flex、Scale。
每一層都代表了成本、速度與可靠性的不同平衡點。
從 OpenAI 的角度,這是為了將有限的算力資源與不同客户需求匹配。
從客户角度,這是主動做取捨:
- 什麼時候值得為速度多付錢?
- 什麼時候應該讓請求排隊以換取更低成本?
對 FinOps 來説,這種變化意義重大
同一個工作負載,如果跑在錯誤的 tier 上,可能會悄悄讓成本翻倍——
或者導致 SLA(服務級別)被打破。
而選擇正確的服務組合,則能在不犧牲用户體驗的前提下帶來顯著節省。
因此,理解這些 tier 不再只是技術細節,而是 AI 成本管理的核心能力。
本文將從 FinOps 視角拆解 OpenAI 的四個定價等級
並提供:
- 各 tier 適用的使用場景
- 如何監控工作負載是否“漂移”到錯誤 tier
- 何時需要重新評估你的策略
幫助你在快速擴張的 AI 成本中保持可見、可控與高性價比。
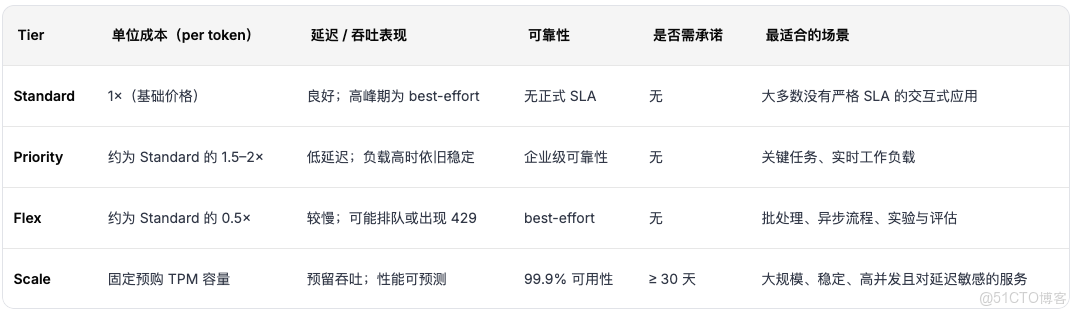
OpenAI 服務等級概覽(Service Tiers Overview)
Standard Tier(標準層)
默認的按量付費模式。
- 計費方式: 基礎 token 單價,無需承諾
- 性能: 穩定但為 best-effort
- SLA: 無正式 SLA
適合一般場景、原型開發、小規模生產流量。
Priority Tier(優先層)
更貴的按量付費模式,換取更快、更穩定的性能。
- 計費方式: token 單價更高
- 性能: 更低延遲、更穩定吞吐
- SLA: 提供企業級 SLA/SLO
適合對延遲敏感的應用,例如實時聊天、客户支持、API 產品。
Flex Tier(彈性層)
節省成本的預算層(約便宜 50%)。
- 計費方式: token 成本約為標準層的一半
- 性能: 延遲較慢,可能排隊或在高負載下失敗
- SLA: 無 SLA
適合批處理任務、異步任務、非時間敏感作業。
Scale Tier(規模層)
按吞吐單位(Throughput Units)預留容量,需 ≥30 天承諾。
- 計費方式: 固定費用(按保留算力付費)
- 性能: 99.9% SLA、穩定低延遲、可預測吞吐
- 場景: 大規模生產流量、企業 AI 平台、關鍵路徑業務
適合追求穩定性、可預測成本以及高吞吐量的團隊。
Standard Tier(按量付費默認層)
成本結構(Cost Structure)
- 採用 OpenAI 的基礎 token 單價(輸入/輸出按列表價計費)
- 無前期費用或承諾
- 支持 Prompt Caching,可對重複輸入降低實際成本
性能與可靠性(Performance & Reliability)
- 正常情況下響應快速
- 在高峯期為 best-effort,無正式延遲或可用性 SLA
- 流量高峯可能出現排隊、延遲波動
適合的場景(Great For)
- 內部工具、PoC、早期原型
- 中等規模、對 SLA 不敏感的用户功能
- 臨時分析、按需報告生成
FinOps 視角(FinOps POV)
- 將 Standard 視為默認基線
- 若在高峯時段出現延遲或 SLA 風險:將關鍵路徑流量提升到 Priority Tier
- 若是穩定、高吞吐量的任務:評估遷移到 Scale Tier 以獲取可預測容量
- 若任務並不時間敏感:下沉到 Flex Tier 以節省成本
Priority Tier(高性能 On-Demand)
成本結構
按量付費,但單價會明顯更高(通常是 Standard 的約 1.5–2 倍),一般只在企業級訪問中提供。無法預購容量;使用多少就按高價付多少。
性能與可靠性
低延遲、穩定吞吐,即使在高峯期也能保持一致的性能。具備企業級可靠性指標。從效果上看,你的請求會“跳過隊列”,幾乎不會遭遇限流。
適用場景
- 大規模實時聊天 / 語音助手
- 對時效性要求極高的任務(如交易、風控)
- 對響應時間 SLA 要求嚴格的企業級 SaaS 功能
- 大規模、波動性強的實時體驗,對延遲極為敏感的場景
FinOps 視角
Priority 是明確用“錢”換確定性的性能。應密切跟蹤該層級的花費,並將其僅用於和收入或 SLA 強綁定的關鍵鏈路。
如果 Priority 的使用量變得穩定且長期,應該開始評估轉向 Scale 層級——在這種情況下,承諾容量通常比長期支付高額 Premium 更划算。
Flex Tier(非緊急任務的成本節省層)
成本結構
按量付費,比 Standard 約便宜 50%,無需任何預付成本。
性能與可靠性
速度較慢,採用“盡力而為”模式。在高峯期請求可能排隊或返回 429。通常需要配合重試、指數退避和更長的超時時間(對於重任務,最長可能達到 ~15 分鐘)。
適用場景
- 批量數據處理、定時分析
- 模型評估、實驗與研發
- 批量內容生成(總結、打標籤、情感分析等),對時效不敏感
- 可異步完成、延遲幾分鐘也不會影響用户體驗的功能
FinOps 視角
Flex 是你的第一道成本優化槓桿。需要監控隊列時延、超時率和 429 頻率;儘量在非高峯期調度大型 Flex 任務,減少競爭。同時建立好工程模式(重試/退避、更長超時等),讓團隊在不犧牲穩定性的前提下真正獲得成本節省。
Scale Tier(企業級的保留容量)
成本結構
按模型預購買 TPM(Tokens Per Minute)容量,最低承諾 30 天。無論實際利用率如何,都按預留容量計費;超出部分按按量付費計算。年度承諾可進一步降低單位成本。
性能與可靠性
提供類似 Priority 的高速體驗,並具備 99.9% 的可用性 SLA。你擁有一部分專屬吞吐,因此即使在高併發場景下,性能也能保持穩定、可預測。
適用場景
- 高併發、持續運行的 SaaS 關鍵功能
- 停機代價極高的核心業務流水線
- 需要可預測容量與低延遲的大型服務
- 從 Priority 遷移而來、使用量已經穩定且高的工作負載
FinOps 視角
將 Scale 視為“固定合同”來管理:
- 嚴格跟蹤利用率,避免浪費
- 對比實際成本與 Standard/Priority 按量付費的對照值
- 在承諾週期結束後若有閒置則縮減容量;若頻繁溢出到按量付費,則應適度增加容量
- 智能組合:用 Scale 承載基準吞吐,用 Priority 處理流量突發,將非緊急任務下沉到 Flex
各服務層級一覽對比
何時重新評估你的服務層級策略
Priority 花費激增。
確認這些調用是否真的受 SLA 約束。將非關鍵路徑下沉到 Standard 或 Flex。
如果 Priority 使用量持續且穩定增長,開始評估切換到 Scale 是否更划算。
Standard 層級出現 SLA 違約。
將關鍵路徑升級到 Priority。
如果這些流量長期可預測且穩定,考慮遷移到 Scale 以獲得更好的成本結構。
批處理作業落在昂貴層級上。
如果任務時間不敏感,將它們遷移到 Flex,可立刻節省約 50% 單位成本。
Token 使用量快速增長。
隨着規模擴大,“Scale + Flex” 的組合通常比全量使用 Priority 更具成本優勢。
預算壓力上升。
將非關鍵工作流下調一個層級(Priority → Standard → Flex),可在不明顯影響用户體驗的前提下降低支出。
跨團隊協作手冊(The Cross-Functional Playbook)
共享數據。
按月彙報每個層級的花費與 Token 使用量,並按功能/團隊進行細分。
共同制定 SLA。
讓產品與工程一起明確:哪些路徑真正需要 Priority 或 Scale,哪些不需要。
大膽試驗。
將一小部分流量切換到 Flex 或 Standard 做 A/B 測試,評估用户體驗與節省幅度,再逐步推廣。
建立治理機制。
讓 SDK 默認使用 Standard;使用 Priority 必須顯式聲明。
為 Priority 突增、Scale 的未充分利用設置告警,避免隱性浪費。
60 秒快速決策流(A 60-Second Decision Flow)
用户可見且對時延敏感?
- 否 → 使用 Flex
- 是 → 繼續判斷
是否需要持續的低延遲 / 高可靠性?
- 否 → 使用 Standard
- 是 → 繼續判斷
吞吐量是否穩定且可預測?
- 否 → 使用 Priority
- 是 → 使用 Scale
結論(Conclusion)
OpenAI 的服務分層既是技術選擇,也是預算策略。
Standard 是默認基線;Priority 是關鍵路徑的“性能加速按鈕”;Flex 是適合可延遲任務的低價選項;Scale 則是當流量高且穩定時最具性價比的容量合約。
對於 FinOps 團隊,目標非常明確:
將每類工作負載映射到在滿足 SLA 的前提下成本最低的層級,持續監控偏移,並及時調整。
做到這一點,你就能同時保護用户體驗與企業利潤率。