
一、初識反應式智能體
前一篇我們詳細瞭解了深思熟慮智能體,今天我們討論智能體的另一種類型,反應式智能體,想象一下,當我們的手不小心觸碰到一個滾燙的杯子時,我們會瞬間縮回。這個過程中,我們的大腦甚至還沒有意識到燙這個概念,手已經完成了動作。這種不經過深思熟慮、直接由刺激引發的快速反應,就是反應式智能體的核心思想。
反應式智能體是一種基於“感知-行動”模式的智能系統。它不依賴複雜的內部世界模型,不進行耗時的推理規劃,而是像生物的條件反射一樣,根據當前的環境輸入直接產生行為輸出。
一個簡單的比喻:
- 反應式智能體:好比蜜蜂採蜜,蜜蜂看到花朵就飛過去,遇到障礙就轉向,整個過程流暢自然
- 深思熟慮智能體:好比棋手下棋,每走一步都需要深思熟慮,考慮各種可能性
這種設計使得反應式智能體在需要快速響應的場景中表現出色,成為機器人學、自動駕駛、工業自動化等領域的基石技術,反應式智能體是一種基礎且強大的智能體範式,它摒棄了複雜的內部世界模型和前瞻性規劃,轉而強調對環境的即時、直接響應。這種“刺激-反應”模式,使其在動態、快速變化的環境中表現出極高的效率和魯棒性。
二、什麼是反應式智能體
反應式智能體的設計源於對自然界(如昆蟲)高效行為的觀察,一隻蜜蜂不需要構建整個花園的認知地圖,它只需根據光線、花朵形狀和氣味等即時感官輸入,就能做出飛向花蜜的決定。
1. 核心概念
反應式智能體是一種不依賴內部世界模型,也不進行復雜推理,其決策和行動直接由當前時刻的感知輸入所決定的智能系統。它
2. 基本工作模式
反應式智能體的的工作模式可以概括為一個極其簡化的公式:感知 → 反應。它的工作流程可以概括為一個極其簡潔的循環:環境感知 → 條件匹配 → 動作執行 → 環境改變
這個循環的關鍵在於沒有中間的思考環節,智能體不需要回答“我在哪裏?”“我要去哪裏?”這樣的哲學問題,它只需要知道“現在該做什麼”。
3. 條件-動作規則
反應式智能體的大腦由一系列簡單的“如果-那麼”規則組成:
規則集 = [
"如果(前方有障礙物) 那麼(向左轉)",
"如果(電量低於20%) 那麼(返回充電)",
"如果(檢測到目標) 那麼(向前移動)",
"如果(無特殊情況) 那麼(隨機探索)"
]
這些規則就像生物的神經反射弧,每個都負責處理特定的情境。當環境提供的感知輸入匹配某個規則的條件時,對應的動作就會被立即觸發。
4. 行為的涌現
單個規則可能很簡單,但多個規則組合起來就能產生複雜的行為表現。這種現象被稱為“涌現”——整體行為大於部分之和。
實例説明:一個掃地機器人只有三個簡單規則:
- 遇到障礙就轉向
- 檢測到灰塵就清掃
- 默認情況下直線前進
單獨看每個規則都很簡單,但組合起來後,機器人就能在房間裏自主移動、避開傢俱、清掃灰塵,表現出相當複雜的智能行為。這種從簡單規則中產生複雜行為的過程,正是反應式智能體的魅力所在。
5. 核心原則
- 緊耦合的感知-行動循環:智能體的行動直接由當前的感知輸入觸發,中間沒有複雜的思考或規劃過程。
- 無內部狀態模型:反應式智能體不維護關於世界歷史的內部模型,它的決策完全基於現在,這簡化了設計並避免了因模型不準確導致的錯誤。
- 行為分解:複雜的行為不是通過一個龐大的程序實現的,而是通過一系列簡單的、並行的行為模式組合而成。
- 涌現行為:智能體整體的、看似複雜的行為,是由多個簡單行為在環境交互中涌現出來的,而非預先編程的。
6. 反應式智能體的優勢
- 速度快: 響應延遲極低,適用於需要快速反應的任務,如避障。
- 魯棒性強: 由於不依賴可能出錯的內部模型,在部分傳感器失效時,剩餘的行為模式仍能保證基本功能。
- 設計簡單: 模塊化設計,易於實現、測試和調試。
7. 反應式智能體的劣勢
- 智能受限: 無法進行需要記憶和規劃的任務,如下棋、複雜決策。
- 可能陷入局部循環: 例如,一個機器人可能會在兩個障礙物之間來回擺動。
8. 一個生活化的比喻:膝跳反射
醫生用小錘敲擊你的膝蓋,你的小腿會不受控制地向前踢出。這個過程:
- 感知:膝蓋肌腱被敲擊。
- 處理:脊髓層面的神經迴路,無需大腦思考。
- 行動:小腿踢出。
這就是一個典型的反應式過程——快速、直接、不經過深思熟慮,反應式智能體正是將這種模式應用在了機器決策上。
三、反應式智能體的架構
1. 行為層次的概念
當多個規則可能同時被激活時,如何決定執行哪個動作?機器人學家羅德尼·布魯克斯提出了包容架構來解決這個問題。
包容架構的核心思想是:將智能體分解為多個行為層,每個層都是一個獨立的“感知-行動”模塊。這些層並行運行,但通過優先級機制進行協調。
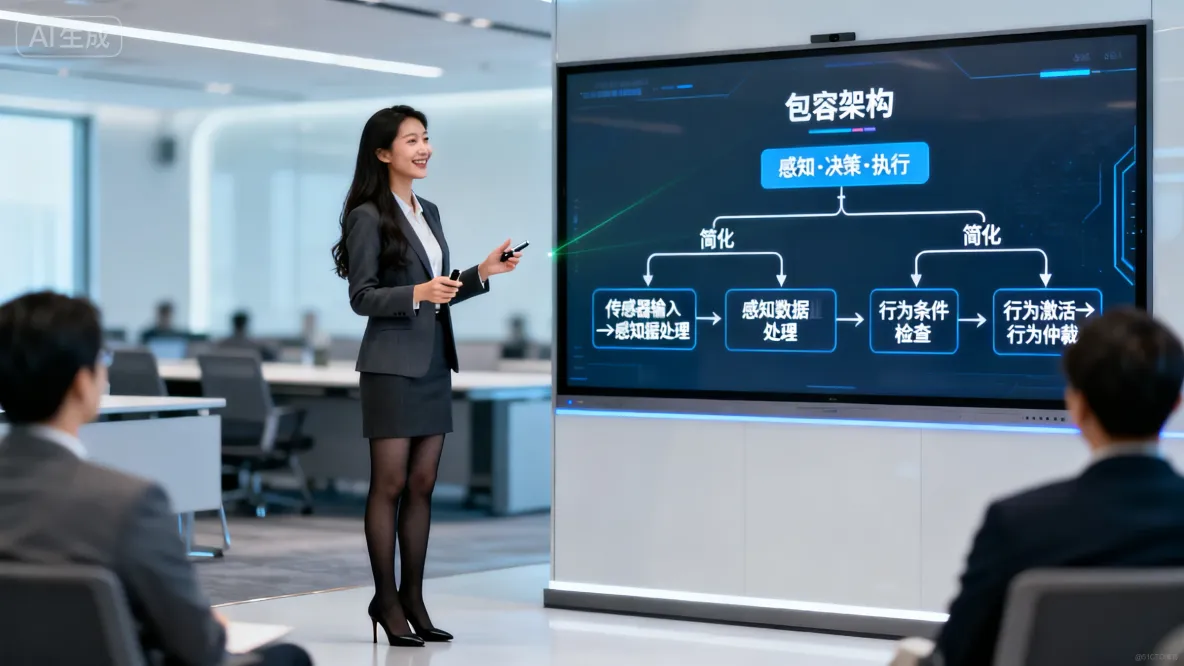
2. 流程詳解
流程説明:
- 1. 感知階段
- 環境傳感器輸入:通過攝像頭、雷達等傳感器收集環境數據
- 感知數據處理:對原始數據進行清洗、分析和理解
- 2. 決策階段
- 行為條件檢查:將處理後的數據與預設的行為條件進行匹配
- 行為激活:滿足條件的行為被激活,生成對應動作
- 行為仲裁:當多個行為衝突時,選擇最高優先級的動作執行
- 3. 執行階段
- 最終動作輸出:執行選定的動作
- 環境影響:動作改變環境,引發新的傳感器輸入
流程總結:
- 循環往復:整個過程形成一個連續的"感知-行動"循環
- 實時響應:不進行復雜思考,直接根據當前環境做出反應
- 並行處理:多個行為條件同時檢查,提高響應速度
3. 關鍵組件
- 感知模塊: 從傳感器(如攝像頭、激光雷達、觸鬚)讀取原始數據,並進行必要的預處理(如過濾噪聲、識別特定特徵)。
- 行為集合: 一系列簡單的“如果-那麼”規則或函數。
- “如果”部分: 感知條件的布爾組合。
- “那麼”部分: 要執行的動作或向量。
- 例如:如果 (前方有障礙物) 那麼 (向左轉)
- 仲裁機制: 當多個行為同時被激活時,仲裁機制決定哪個行為擁有控制權。常見策略包括:
- 固定優先級: 某些行為(如“避障”)永遠比“探索”行為優先級高。
- 抑制結構: 高優先級行為可以抑制低優先級行為的輸出。
- 向量求和: 將所有行為輸出的動作向量(如速度、轉向角)相加,得到最終動作。
在包容架構中,行為層被組織成不同的優先級:
- 高優先級:避障行為 ← 生命安全最重要
- 中優先級:任務行為 ← 完成主要任務
- 低優先級:探索行為 ← 默認行為
仲裁原則:高優先級行為可以抑制低優先級行為。就像在人類行為中,躲避危險的本能會壓制其他所有想法。
4. 實際應用場景
考慮一個自動駕駛汽車的反應式系統:
行為層 = {
# 最高優先級:安全相關
"緊急制動": {"條件": "碰撞 imminent", "動作": "全力剎車"},
# 高優先級:避障
"主動避障": {"條件": "前方有障礙", "動作": "轉向避讓"},
# 中優先級:導航
"車道保持": {"條件": "偏離車道", "動作": "微調方向"},
# 低優先級:舒適性
"平穩駕駛": {"條件": "道路彎曲", "動作": "平滑轉向"}
}
當多個條件同時滿足時,只有最高優先級的動作會被執行,這種設計確保了系統在任何情況下都能做出最安全的選擇。
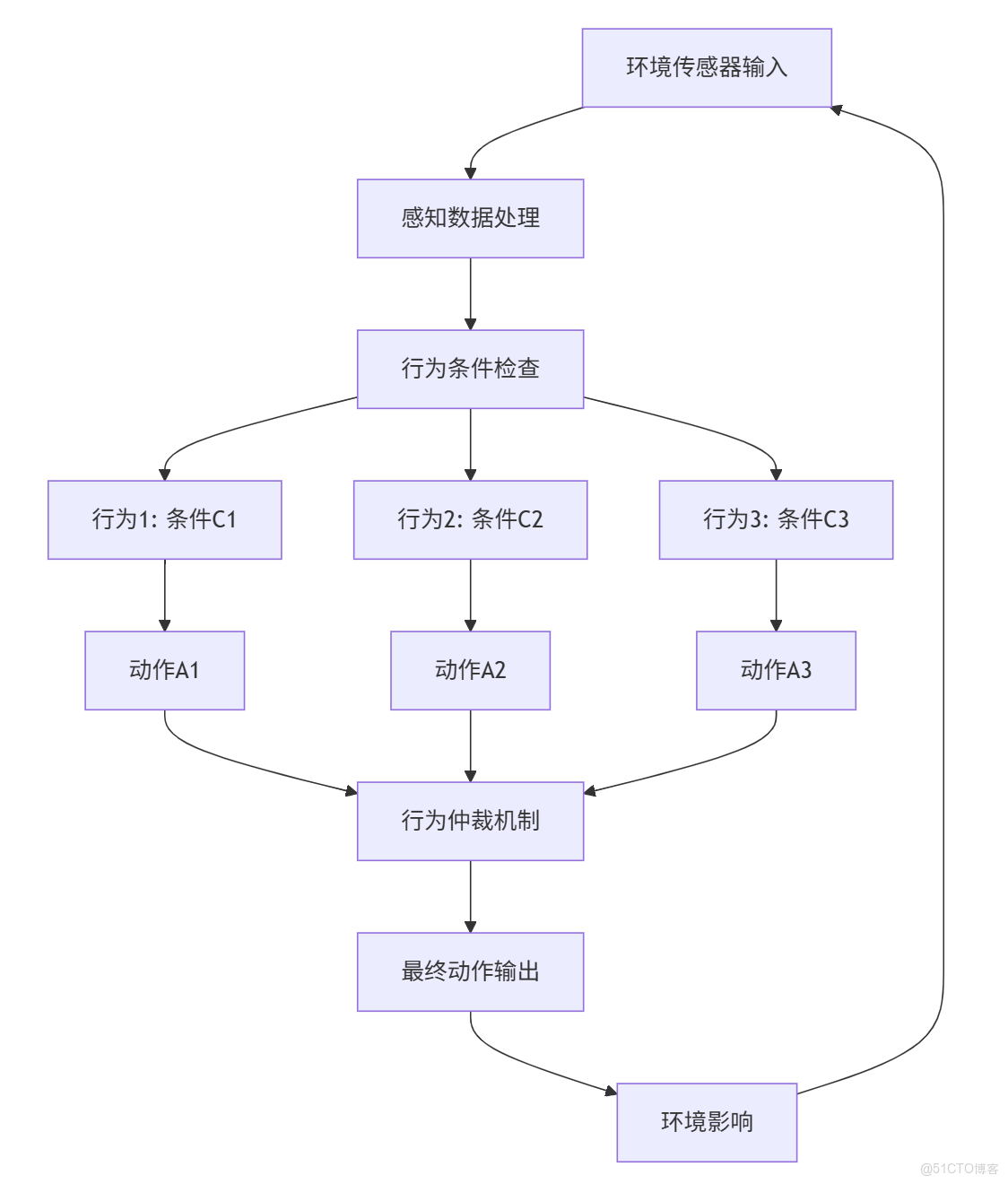
四、反應式智能體的構建 - 包容架構
如何將多個簡單的“條件-動作”規則組合起來,形成複雜的行為?機器人學家羅德尼·布魯克斯提出了經典的 “包容架構”。
1. 核心思想
包容架構將智能體分解為多個行為層,每個層都是一個簡單的“條件-動作”模塊。這些層並行運行,但通過 “抑制” 與 “抑制” 機制進行協調。
- 抑制:高優先級行為可以覆蓋低優先級行為的輸出信號。
- 抑制:高優先級行為可以阻斷低優先級行為接收輸入信號。
2. 一個機器人的行為層設計
假設我們要構建一個室內清掃機器人:
- 層一(最低優先級):充電行為
- 條件:電量 < 10%。
- 動作:向充電樁移動。
- 層二(中優先級):清掃行為
- 條件:檢測到灰塵。
- 動作:啓動刷子並前進。
- 層三(最高優先級):避障行為
- 條件:前方近距離檢測到障礙物。
- 動作:停止,轉向。
仲裁過程:當機器人正在清掃時(層二激活),如果突然前方出現障礙物,避障行為(層三)會立即抑制清掃行為(層二)的輸出,讓機器人先轉向。避開障礙物後,避障行為條件不再滿足,清掃行為重新取得控制權,這保證了機器人的安全。
3. 包容架構流程圖
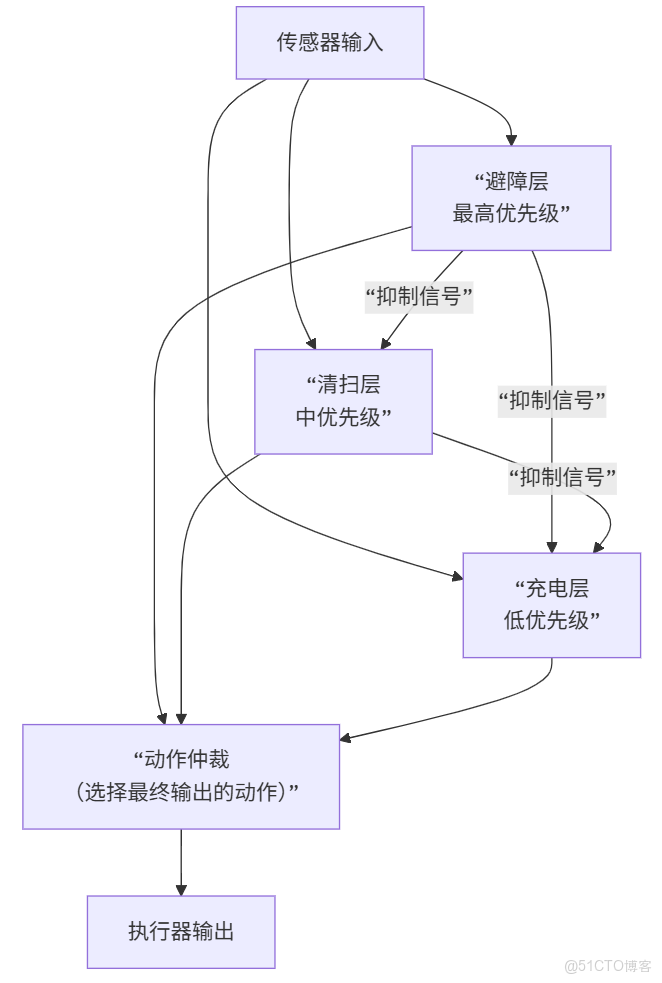
工作過程:
- 傳感器輸入同時傳遞給所有行為層
- 各層獨立判斷是否滿足執行條件
- 抑制機制生效:
- 需要避障時,避障層抑制清掃和充電
- 需要清掃時,清掃層只抑制充電
- 都不需要時,執行充電層
- 動作仲裁選擇最終要執行的動作
核心機制:
- 三層並行處理:避障、清掃、充電三個行為層同時接收傳感器輸入
- 優先級抑制:高優先級行為可以抑制低優先級行為
- 行為仲裁:最終只有一個動作被輸出執行
4. 完整構建步驟
- 1. 定義任務和目標: 明確智能體需要完成什麼。例如:“在房間裏漫遊而不撞到任何東西”。
- 2. 識別相關情境: 列出智能體在執行任務時可能遇到的所有關鍵場景。例如:“前方有障礙物”、“左側有障礙物”、“右側空曠”、“發現目標”。
- 3. 設計行為模式: 為每個情境設計一個簡單的、直接的行為。
- 避障行為: 如果前方近處有障礙,則後退並轉向。
- 沿牆行為: 如果左側有障礙物且距離適中,則保持平行前進。
- 漫遊行為: 如果沒有特定輸入,則隨機或直線前進。
- 4. 設定行為優先級: 確定行為的輕重緩急。通常,生存相關(如避障)的行為優先級最高。
- 5. 實現仲裁機制: 編寫代碼將行為組合起來,確保在任何時刻,最高優先級的有效行為主導智能體的行動。
- 6. 迭代測試與調優: 在模擬或真實環境中反覆測試,調整行為的參數(如探測距離、轉向速度),以優化性能。
五、示例:最簡單的清潔機器人
這是一個簡單的掃地機器人智能控制系統,完美展示了反應式設計。
- 感知: 當前位置的傳感器(髒 或 乾淨)。
- 行為:
- 清潔行為: 如果 (當前位置是髒的) 那麼 (吸塵)
- 移動行為: 如果 (當前位置是乾淨的) 那麼 (隨機移動到一個相鄰格子)
- 仲裁: “清潔行為”的優先級高於“移動行為”。
- 分析: 機器人沒有地圖,不知道哪些地方清潔過。它的行為完全基於當前的局部感知,但長期來看,它最終能清潔整個區域。
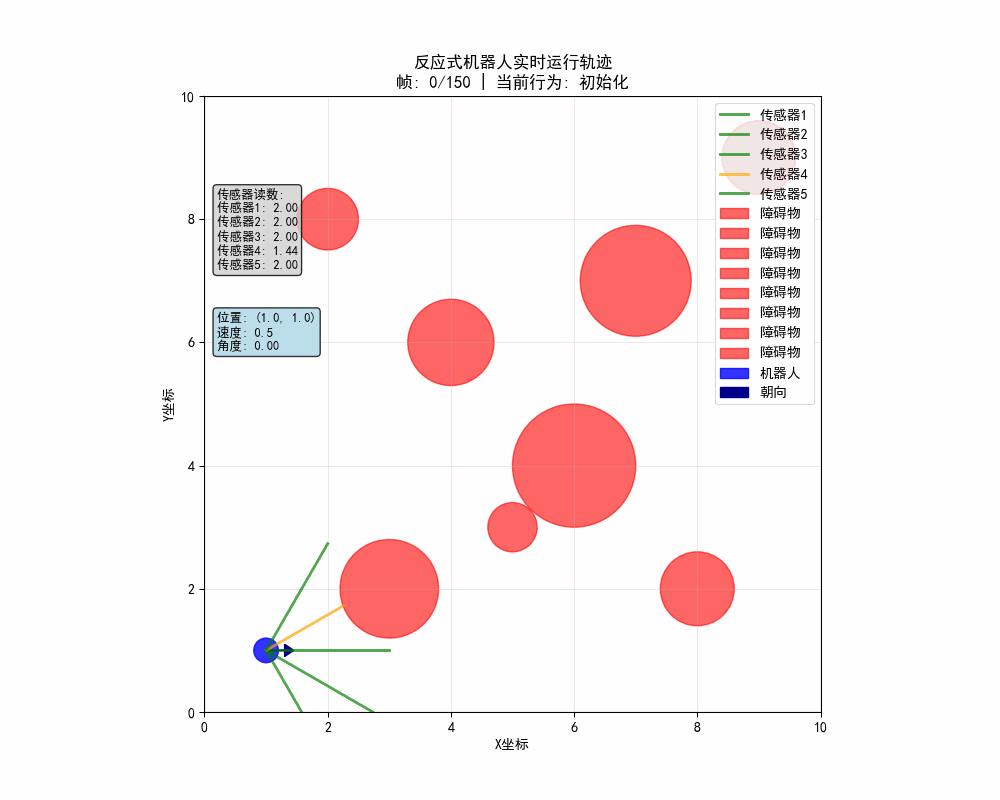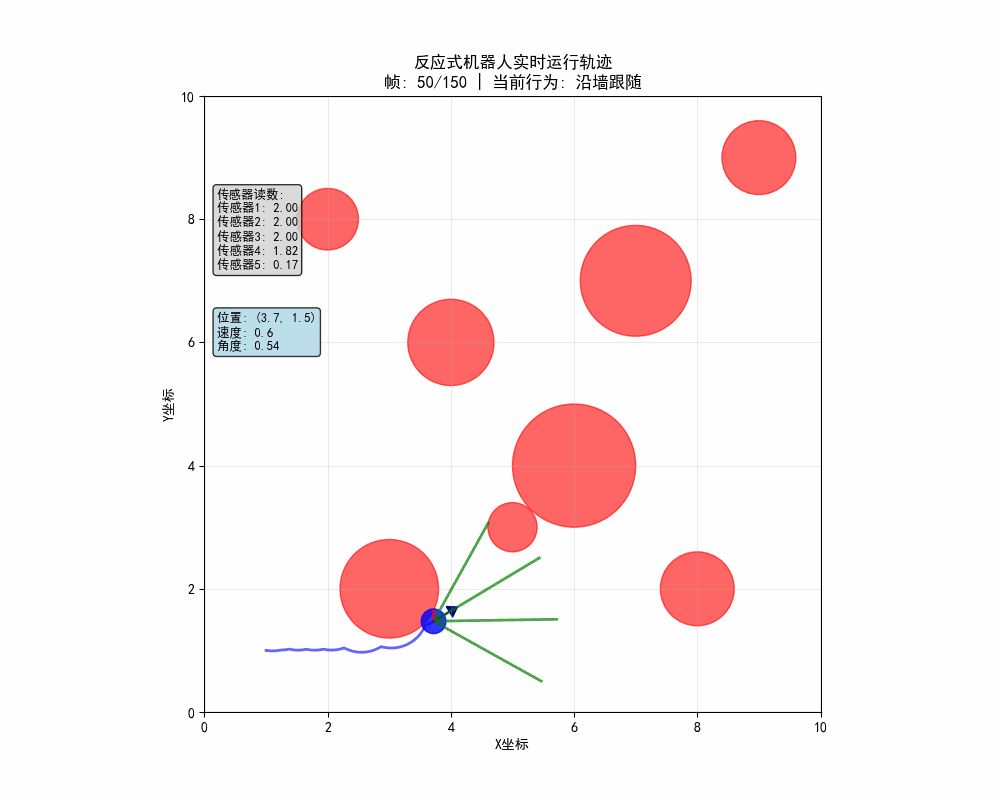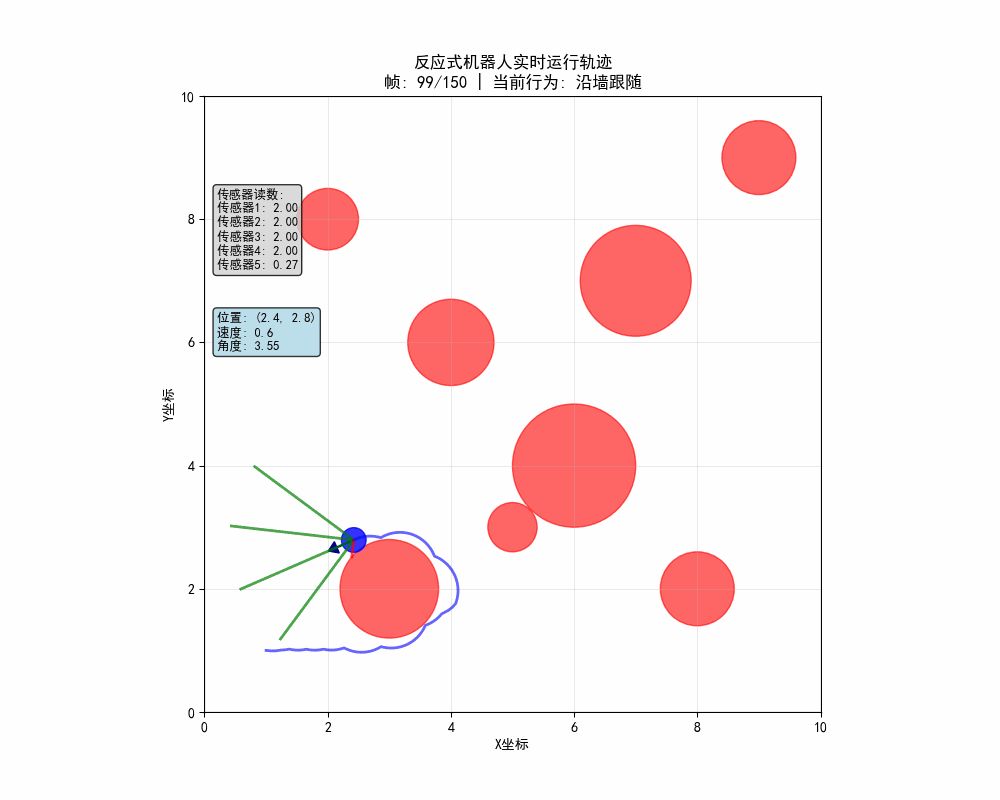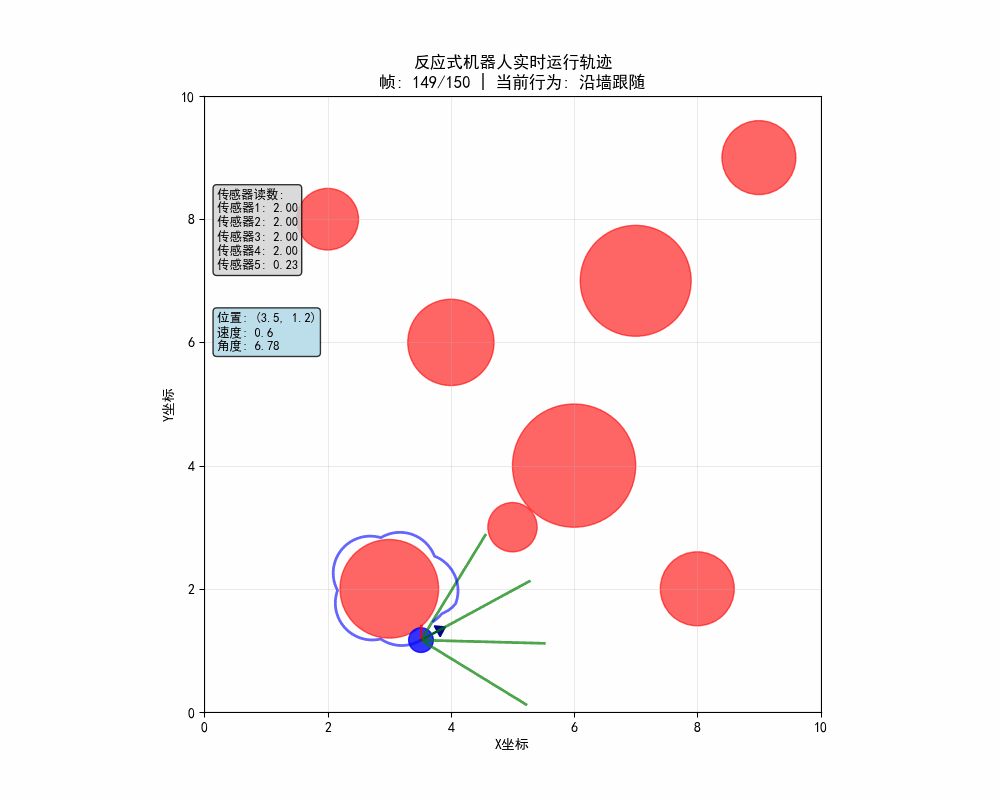
在代碼運行後體現幾大功能點:
- 機器人自主導航:在沒有地圖的情況下避開所有障礙物
- 智能行為切換:根據環境自動在避障、沿牆、探索間切換
- 實時決策顯示:動態顯示當前行為和傳感器狀態
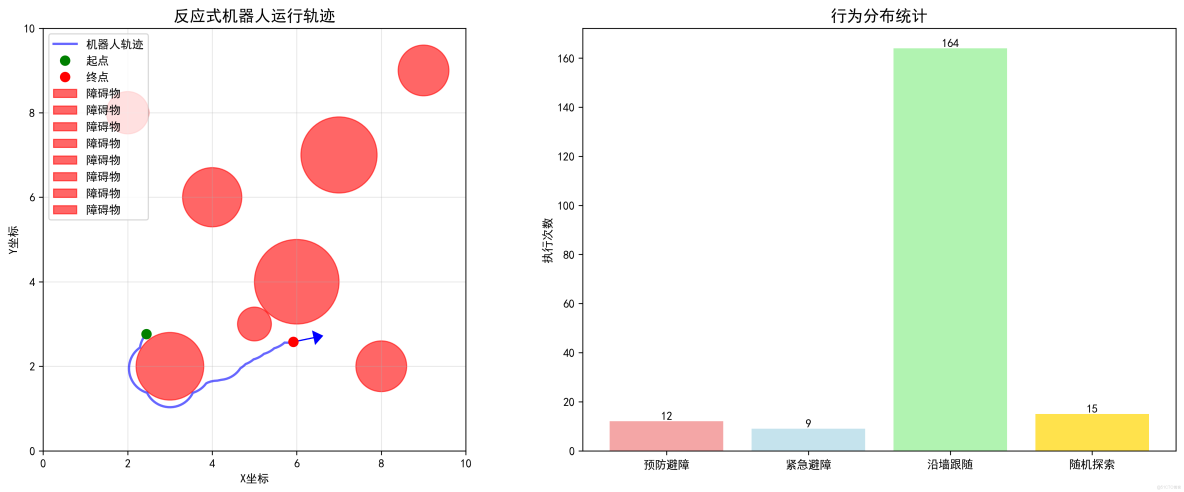
- 軌跡分析:通過顏色可以看到不同行為對應的運動模式
1. 代碼重點部分
1.1 傳感器模擬原理
def get_sensor_readings(self, obstacles):
readings = []
for sensor_angle in self.sensor_angles:
sensor_dir = np.array([
np.cos(self.angle + sensor_angle), # 傳感器方向向量x分量
np.sin(self.angle + sensor_angle) # 傳感器方向向量y分量
])
min_distance = self.sensor_range # 初始化為最大探測距離
for obstacle in obstacles:
# 計算機器人到障礙物的向量
obstacle_pos = np.array([obstacle[0], obstacle[1]])
robot_pos = np.array([self.x, self.y])
to_obstacle = obstacle_pos - robot_pos
# 向量投影:判斷障礙物是否在傳感器前方
projection = np.dot(to_obstacle, sensor_dir)
if projection > 0: # 障礙物在傳感器前方
# 計算障礙物到傳感器射線的垂直距離
distance_to_ray = np.linalg.norm(to_obstacle - projection * sensor_dir)
if distance_to_ray < obstacle[2]: # 如果距離小於障礙物半徑
# 計算實際的碰撞距離
hit_distance = projection - np.sqrt(obstacle[2]**2 - distance_to_ray**2)
if 0 < hit_distance < min_distance:
min_distance = hit_distance
readings.append(min_distance)
return readings
- sensor_dir:計算每個傳感器的方向向量
- projection > 0:確保只檢測前方的障礙物
- distance_to_ray < obstacle[2]:判斷是否與障礙物相交
- 返回5個傳感器的距離讀數列表
1.2 反應式決策核心
def reactive_control(self, sensor_readings):
# 傳感器分組:左2個、前1個、右2個
left_readings = sensor_readings[:2] # 左側傳感器
front_readings = sensor_readings[2] # 前方傳感器
right_readings = sensor_readings[3:] # 右側傳感器
# 計算各方向的最小距離
min_front = min(front_readings, self.sensor_range)
min_left = min(left_readings)
min_right = min(right_readings)
# 行為1: 緊急避障 (最高優先級)
if min_front < 0.8: # 前方很近有障礙
self.speed = 0.3 # 減速
# 選擇更空曠的一側轉向
if min_left > min_right:
self.angle -= np.pi/4 # 向右轉45度
else:
self.angle += np.pi/4 # 向左轉45度
self.current_behavior = "緊急避障"
return self.current_behavior
# 行為2: 預防性避障 (中優先級)
elif min_front < 1.5: # 前方較近有障礙
self.speed = 0.4
if min_left > min_right:
self.angle -= np.pi/8 # 向右轉22.5度
else:
self.angle += np.pi/8 # 向左轉22.5度
self.current_behavior = "預防避障"
return self.current_behavior
# 行為3: 沿牆跟隨 (低優先級)
elif min_left < 1.2 or min_right < 1.2: # 側面有牆
self.speed = 0.6
if min_left < min_right: # 左側有牆
self.angle -= 0.1 # 向右微調
else: # 右側有牆
self.angle += 0.1 # 向左微調
self.current_behavior = "沿牆跟隨"
return self.current_behavior
# 行為4: 隨機探索 (默認行為)
else:
self.speed = 0.8 # 正常速度
# 加入隨機擾動,避免陷入局部循環
self.angle += random.uniform(-0.2, 0.2)
self.current_behavior = "隨機探索"
return self.current_behavior
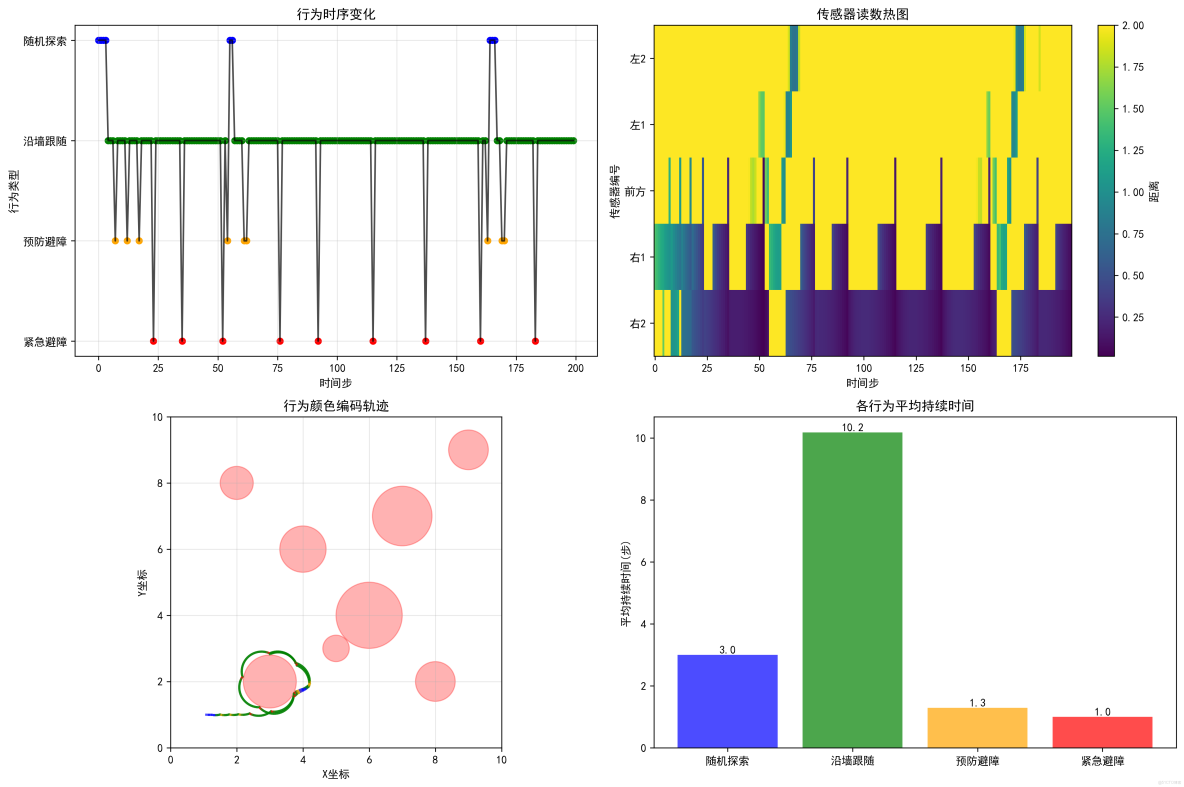
- 固定優先級:緊急避障 > 預防避障 > 沿牆跟隨 > 隨機探索
- 距離閾值:不同距離觸發不同行為
- 轉向策略:總是轉向更空曠的一側
- 速度調節:危險時減速,安全時加速
1.3 位置更新邏輯
def update_position(self, obstacles, area_bounds):
# 1. 感知:獲取傳感器數據
sensor_readings = self.get_sensor_readings(obstacles)
# 2. 決策:反應式控制
behavior = self.reactive_control(sensor_readings)
# 3. 行動:更新位置
dx = self.speed * np.cos(self.angle) * 0.1 # x方向位移
dy = self.speed * np.sin(self.angle) * 0.1 # y方向位移
new_x = self.x + dx
new_y = self.y + dy
# 邊界檢查:防止跑出環境
if (area_bounds[0] < new_x < area_bounds[2] and
area_bounds[1] < new_y < area_bounds[3]):
self.x = new_x
self.y = new_y
# 記錄軌跡(最多100個點)
self.trajectory.append((self.x, self.y))
if len(self.trajectory) > 100:
self.trajectory.pop(0) # 移除最舊的點
return behavior, sensor_readings
1.4 環境創建與障礙物設置
def create_environment():
# 障礙物格式:(x座標, y座標, 半徑)
obstacles = [
(3, 2, 0.8), # 中心區域的大障礙物
(6, 4, 1.0), # 右側的大障礙物
(8, 2, 0.6), # 右上角的小障礙物
(4, 6, 0.7), # 中部偏上的障礙物
(7, 7, 0.9), # 右上角的大障礙物
(2, 8, 0.5), # 左上角的小障礙物
(9, 9, 0.6), # 最右上角的障礙物
(5, 3, 0.4) # 中心區域的小障礙物
]
# 環境邊界:(x_min, y_min, x_max, y_max)
area_bounds = (0, 0, 10, 10)
return obstacles, area_bounds
- 複雜路徑:障礙物分佈形成曲折的通道
- 大小混合:不同大小的障礙物增加導航難度
- 邊界限制:10x10的封閉環境
1.5 動態動畫的核心邏輯
def animate(frame):
ax.clear()
# 更新機器人位置(第一幀除外)
if frame > 0:
behavior, sensor_readings = robot.update_position(obstacles, area_bounds)
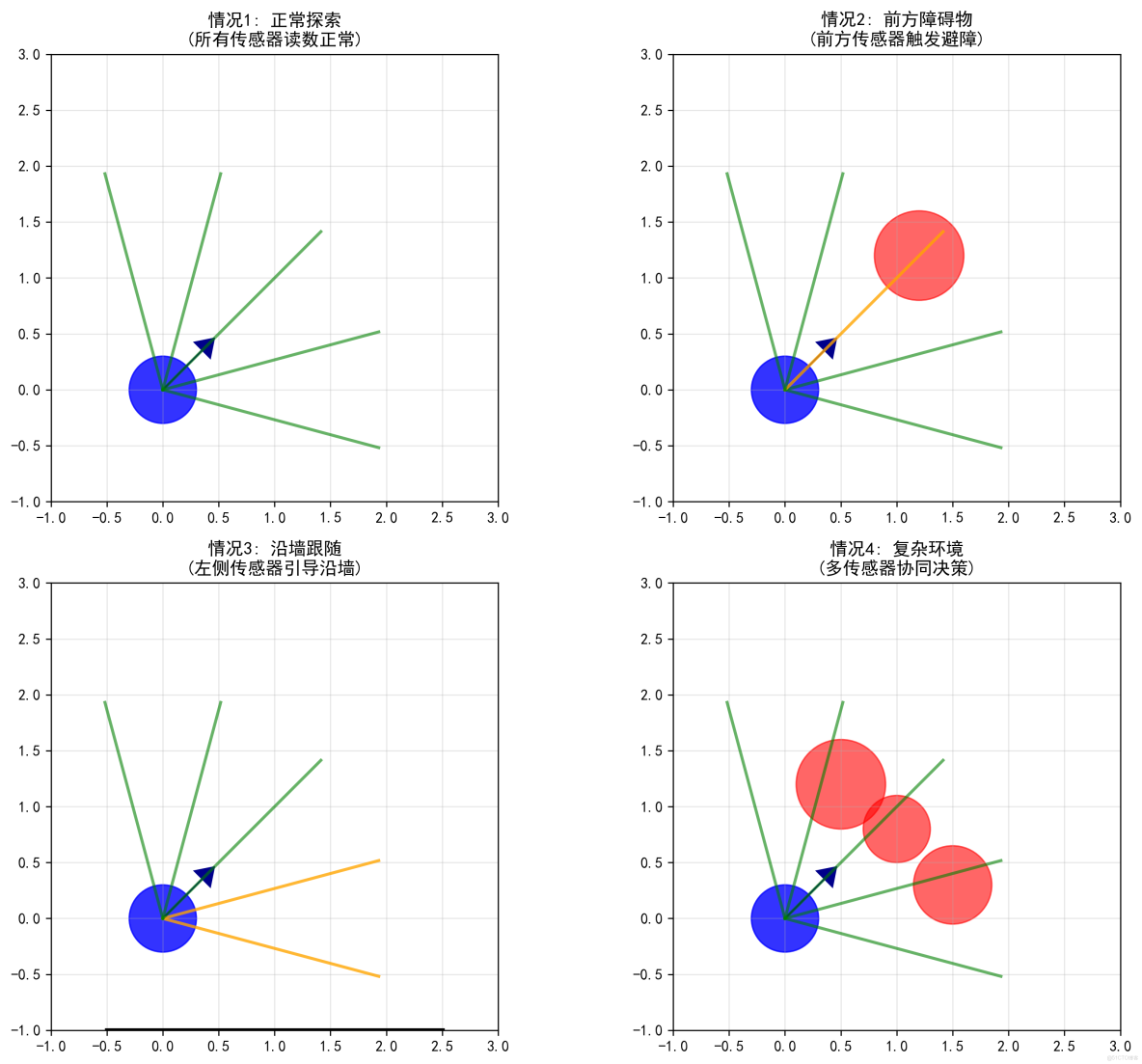
# 繪製傳感器(顏色編碼)
for i, (sensor_angle, reading) in enumerate(zip(robot.sensor_angles, sensor_readings)):
sensor_dir = np.array([np.cos(robot.angle + sensor_angle),
np.sin(robot.angle + sensor_angle)])
sensor_length = min(reading, robot.sensor_range)
end_x = robot.x + sensor_length * sensor_dir[0]
end_y = robot.y + sensor_length * sensor_dir[1]
# 顏色編碼:綠色(安全) → 橙色(警告) → 紅色(危險)
if reading > 1.5:
color = 'green' # 安全距離
elif reading > 0.8:
color = 'orange' # 警告距離
else:
color = 'red' # 危險距離
ax.plot([robot.x, end_x], [robot.y, end_y], color=color,
linewidth=2, alpha=0.7)
- 實時更新:每幀重新繪製所有元素
- 顏色編碼:用顏色直觀顯示傳感器狀態
- 軌跡顯示:保留歷史軌跡顯示運動路徑
1.6 反應式智能體的核心特徵
特徵1:無內部狀態模型
# 機器人沒有記憶環境地圖,只依賴當前傳感器數據
def reactive_control(self, sensor_readings): # 只使用當前傳感器讀數
# 不訪問歷史數據,不維護環境模型
# 決策完全基於當前的sensor_readings
特徵2:固定優先級仲裁
# 明確的優先級順序
if min_front < 0.8: # 1. 緊急避障 (最高)
elif min_front < 1.5: # 2. 預防避障
elif min_left < 1.2 or ... # 3. 沿牆跟隨
else: # 4. 隨機探索 (最低)
特徵3:實時響應
# 每幀都重新感知和決策
def update_position(self, obstacles, area_bounds):
sensor_readings = self.get_sensor_readings(obstacles) # 實時感知
behavior = self.reactive_control(sensor_readings) # 實時決策
# 立即執行動作
特徵4:行為涌現
# 簡單規則組合產生複雜行為
# 單個規則很簡單,但組合後能:
# - 自主避開所有障礙物
# - 沿着牆壁行走
# - 探索未知區域
# - 不會陷入死循環
2. 輸出結果
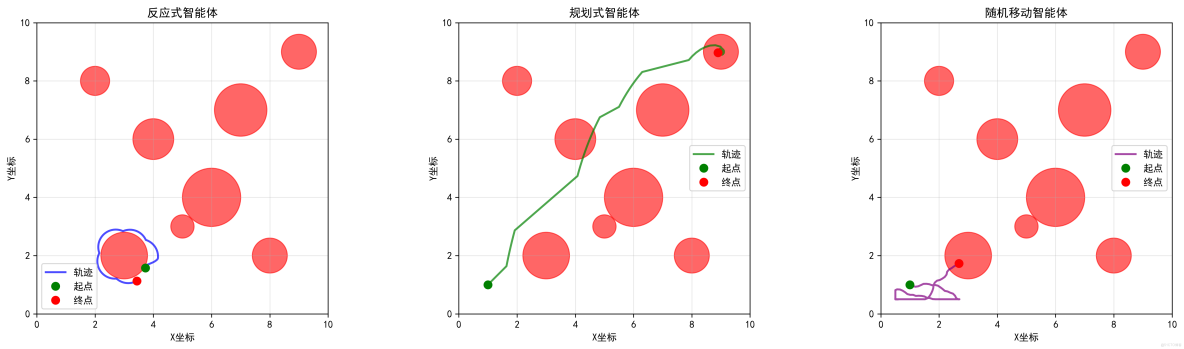
反應式機器人的動態路徑:
反應式機器人的靜態軌跡圖:
反應式機器人的傳感器工作原理:
反應式機器人的智能體對比:
反應式機器人的行為分析:
六、總結
反應式智能體以其簡單、快速、可靠的核心優勢,在AI領域佔據了不可替代的一席之地。它完美地詮釋了“簡單規則產生複雜行為”的涌現智慧。
- 它的主要優勢在於:響應延遲極低、對傳感器錯誤不敏感、開發和調試相對簡單。
- 它的主要侷限在於:缺乏長遠規劃能力,在需要深思熟慮的任務中顯得愚蠢。
反應式智能體代表的是一種工程哲學:用簡單、可靠、可驗證的組件構建複雜的智能系統。它提醒我們,有時候最有效的解決方案不一定是最複雜的。
就像自然界中的螞蟻,每個個體都遵循簡單的規則,但整個蟻羣卻展現出令人驚歎的集體智慧。反應式智能體教會我們:智能不一定源於複雜的計算,也可以來自簡單規則與環境之間的巧妙互動。
在追求更復雜AI技術的今天,理解反應式智能體的原理和價值,不僅有助於我們構建更可靠的實時系統,也為我們理解智能的本質提供了重要的視角。有時候,後退一步,採用更簡單的方法,反而能夠走得更遠。