
一、什麼是深思熟慮的智能體
當我們談論一個決策是深思熟的,我們指的是這個決策經歷了深度的思考過程,不僅僅是快速的反應,而是包含了分析、推理、權衡和規劃的複雜認知活動。同樣,在人工智能領域,深思熟慮的智能體(Deliberative Agent) 是指能夠進行復雜推理、規劃未來行動、並基於內部狀態和外部環境做出決策的智能系統。與簡單的反應式智能體不同,深思熟慮的智能體具備:
- 維護內部狀態:記住歷史交互和當前信念
- 進行深度推理:基於現有信息進行邏輯分析和推斷
- 制定複雜計劃:規劃多步行動序列以實現長期目標
- 反思和學習:從經驗中總結教訓並調整策略
- 權衡決策:在不同選擇間進行利弊分析

與簡單的反應式智能體相比,深思熟慮智能體更像人類的思考過程:
- 反應式智能體:感知 → 行動
- 深思熟慮智能體:感知 → 推理 → 規劃 → 決策 → 行動 → 反思
二、深思熟慮的核心要求
要實現真正的深思熟慮,智能體需要具備:
- 世界建模能力:建立和維護對環境的內部表徵,理解因果關係和事件聯繫,進行心理模擬和後果預測
- 自主決策機制:基於內在價值系統做出選擇,在不確定性下進行推理,處理目標衝突和資源約束
- 學習與適應能力:從經驗中提取知識,調整決策策略和行為模式,適應環境變化和新挑戰
正是為了滿足上述深思熟慮的需求,BDI架構應運而生。BDI架構提供了一個系統化的框架,將抽象的思考過程具體化為可計算的組件。
三、BDI 架構:信念-願望-意圖
深思熟慮智能體通常採用 BDI 架構,Belief-Desire-Intention,這是最經典的智能體架構之一,包含三大主要核心組件:
- 信念(Beliefs):智能體對世界的認知和理解
- 願望(Desires):智能體可能追求的目標狀態
- 意圖(Intentions):智能體承諾要實現的願望
1. 架構圖
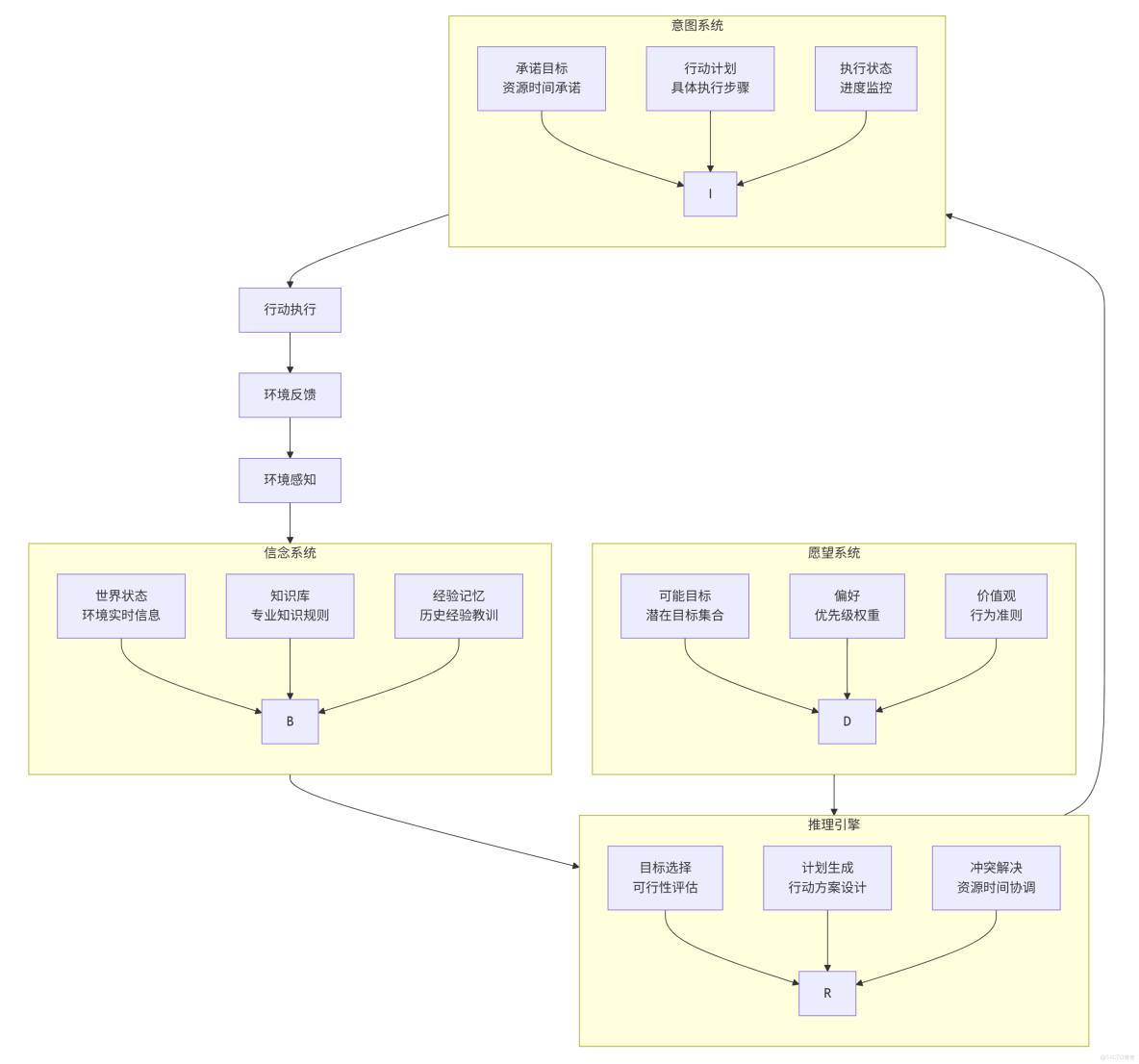
2. 架構詳細説明
2.1 信念系統 (Beliefs) - "我知道什麼"
核心作用:建立和維護智能體對世界的認知模型,三大組成部分:
- 世界狀態
- 實時環境感知:當前環境的動態信息
- 自身狀態監控:智能體自身的運行狀態
- 情境上下文:理解當前操作的環境背景
- 示例:"當前電量剩餘30%","環境温度25°C","附近有3個障礙物"
- 知識庫
- 專業知識存儲:特定領域的專業規則
- 常識推理基礎:通用的邏輯推理知識
- 操作規範:行為準則和操作流程
- 示例:"紅色表示停止","電池低於20%需充電"
- 經驗記憶
- 歷史記錄:過去的決策和結果
- 成功模式:有效的解決方案
- 失敗教訓:需要避免的錯誤
- 示例:"上次使用A方法成功","在擁擠環境B策略易失敗"
2.2 願望系統 (Desires) - "我想要什麼"
核心作用:定義智能體的目標和價值取向,三大組成部分:
- 可能目標
- 目標生成:基於當前狀態產生潛在目標
- 目標分類:區分短期和長期目標
- 目標管理:維護目標集合
- 示例:"完成運輸任務","學習新技能","維護系統健康"
- 偏好
- 優先級設定:為不同目標分配權重
- 效用計算:評估目標的期望價值
- 選擇標準:決策時的參考依據
- 示例:"安全比效率更重要","質量優於速度"
- 價值觀
- 倫理準則:道德行為規範
- 原則體系:核心行為原則
- 身份認同:角色定位和使命
- 示例:"不傷害人類","保護用户隱私"
2.3 推理引擎 - "我如何決定"
核心作用:協調信念和願望,生成最優決策,三大處理功能:
- 目標選擇
- 輸入:信念(環境認知) + 願望(目標集合)
- 處理:
- 評估目標可行性
- 計算期望效用
- 確定優先級排序
- 輸出:最優目標集合
- 計劃生成
- 輸入:選定目標 + 當前信念
- 處理:
- 設計行動方案
- 預測可能結果
- 評估執行風險
- 輸出:具體行動計劃
- 衝突解決
- 輸入:各類衝突情況
- 處理:
- 資源衝突協調
- 時間衝突安排
- 價值衝突權衡
- 輸出:一致決策方案
2.4 意圖系統 (Intentions) - "我將做什麼"
核心作用:將決策轉化為具體行動承諾,三大組成部分:
- 承諾目標
- 目標鎖定:確定要追求的目標
- 資源承諾:分配必要資源
- 時間承諾:設定完成時限
- 示例:"承諾在今天完成區域掃描"
- 行動計劃
- 任務分解:目標拆分為具體步驟
- 時序安排:確定執行順序
- 資源規劃:詳細資源分配
- 示例:"路徑: A→B→C, 時間: 30分鐘"
- 執行狀態
- 進度跟蹤:監控執行進展
- 狀態報告:維護當前狀態
- 問題識別:檢測執行異常
- 示例:"完成步驟2/5,遇到障礙"
3 完整的決策流程
┌─────────────┐
│ 環境感知 │
└──────┬──────┘
↓
┌─────────────┐
│ 信念更新 │ ← 更新世界模型
└──────┬──────┘
↓
┌─────────────┐
│ 願望生成 │ ← 基於信念激活願望
└──────┬──────┘
↓
┌─────────────┐
│ 意圖形成 │ ← 選擇並承諾於特定願望
└──────┬──────┘
↓
┌─────────────┐
│ 計劃生成 │ ← 制定實現意圖的具體計劃
└──────┬──────┘
↓
┌─────────────┐
│ 行動執行 │ ← 執行計劃中的行動
└──────┬──────┘
↓
┌─────────────┐
│ 結果反思 │ ← 評估結果並學習
└──────┬──────┘
↓
┌─────────────┐
│ 信念調整 │ ← 基於經驗更新信念
└─────────────┘
主要環節:
- 感知環境 → 更新信念系統
- 激活願望 → 基於信念生成目標
- 推理決策 → 協調信念願望生成意圖
- 執行行動 → 實施具體計劃
- 獲得反饋 → 觀察行動結果
BDI架構作為實現深思熟慮智能體的核心框架,代表了人工智能從"工具性"向"認知性"邁進的重要一步。它不僅僅是一個技術架構,更是對智能本質的深入探索。
通過信念、願望、意圖三個組件的有機整合,BDI架構為人工智能系統提供了:
- 真正的理解能力而不僅僅是模式識別
- 自主的決策能力而不僅僅是規則執行
- 持續的學習能力而不僅僅是經驗存儲
- 理性的行為能力而不僅僅是刺激響應
四、智能體架構
1. 核心狀態管理
深思熟慮智能體維護多種狀態來支持複雜推理,狀態類型:
- 操作狀態:空閒、思考、執行、反思
- 認知狀態:不確定、自信、衝突、解決
- 情感狀態:好奇、挫敗、滿意、困惑
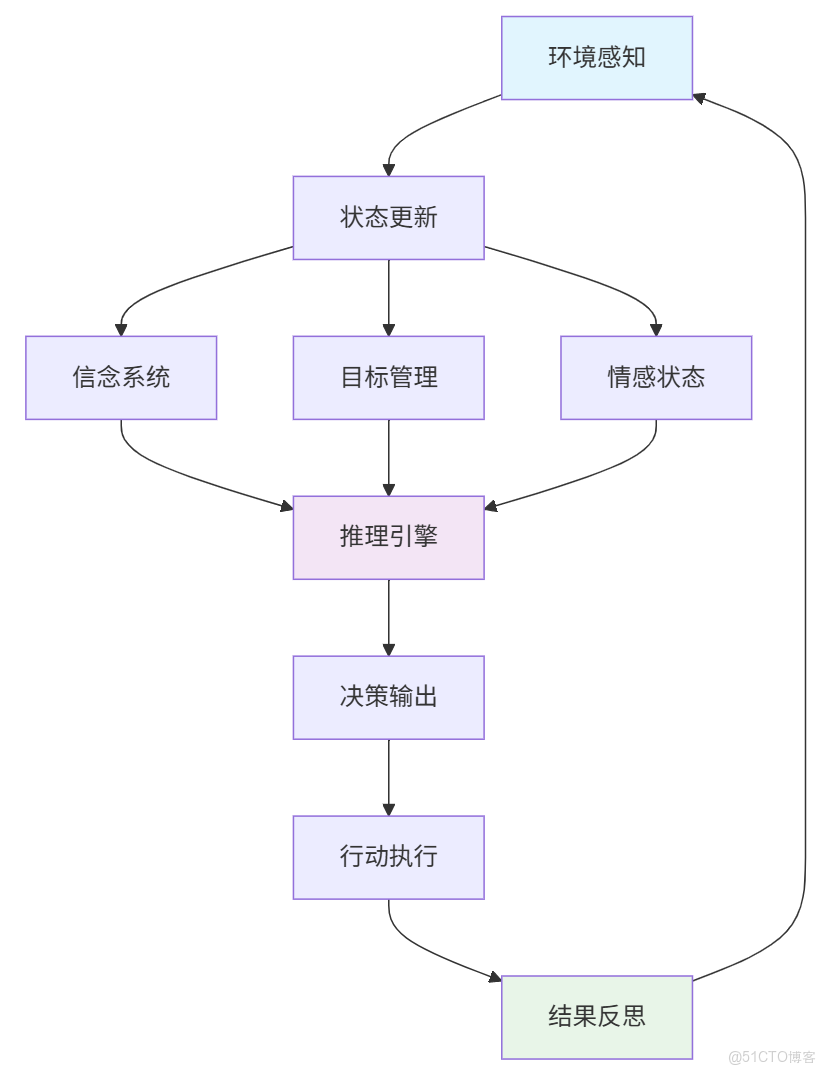
三種狀態類型構成了智能體的多層次心智框架,為複雜推理提供完整的上下文環境和決策依據。這些狀態相互交織,共同支撐智能體從感知到行動的完整認知循環。
1.1 操作狀態:行為控制層
- 定義:描述智能體當前的外部行為模式和資源分配狀態
- 狀態詳解:
- 空閒:待機等待模式,維持基礎環境監測,計算資源消耗最低
- 思考:內部處理活躍期,進行深度分析、方案生成和決策權衡
- 執行:任務實施階段,按照既定計劃行動並監控執行進度
- 反思:經驗學習過程,評估執行效果並提取知識教訓
- 核心作用:確定智能體的行為焦點和資源分配策略
1.2 認知狀態:知識評估層
- 定義:反映智能體對當前任務和環境的認知把握程度
- 狀態詳解:
- 不確定:信息不足或模糊,置信度低,需要進一步探索驗證
- 自信:信息充分可靠,推理清晰,能夠做出明確決策
- 衝突:存在信念矛盾或目標競爭,需要深入分析和權衡
- 解決:達成認知一致,形成明確的問題理解和解決方案
- 核心作用:指導智能體的信息處理深度和決策謹慎程度
1.3 情感狀態:動機調節層
- 定義:表徵智能體的內在驅動力和情緒傾向
- 狀態詳解:
- 好奇:強烈的探索和學習慾望,驅動知識獲取和創新嘗試
- 挫敗:目標實現受阻,觸發策略調整和行為模式改變
- 滿意:目標達成或進展順利,強化成功經驗和方法
- 困惑:理解困難或方向不明,促使尋求澄清和簡化問題
- 核心作用:調節智能體的探索傾向和風險偏好
1.4 狀態間動態影響
- 操作狀態為認知和情感狀態提供行為載體
- 認知狀態制約操作狀態的執行方式和情感狀態的產生
- 情感狀態影響操作狀態的執行力度和認知狀態的開放程度
1.5 狀態組合示例
- 思考+不確定+好奇 → 探索性學習模式
- 執行+自信+滿意 → 高效執行模式
- 反思+衝突+困惑 → 深度分析模式
- 空閒+解決+滿意 → 準備就緒模式
2. 智能體核心循環
深思熟慮智能體的工作流程是一個持續的循環:
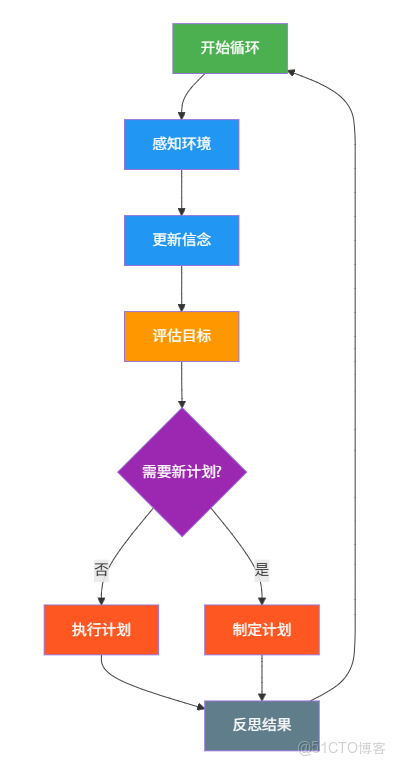
流程説明:
- 1. 開始循環:啓動或重新開始智能體的思考-行動循環
- 2. 感知環境:從外部環境獲取新信息,接收傳感器數據、用户輸入等
- 3. 更新信念:將新信息整合到現有知識中,調整對世界的認知和理解
- 4. 評估目標:檢查當前目標的狀態和優先級,確定是否需要調整目標焦點
- 5. 決策分支:判斷是否需要制定新計劃
- 是:進入計劃制定階段
- 否:繼續執行現有計劃
- 6. 執行階段:執行當前計劃或新制定的計劃,將決策轉化為具體行動
- 7. 反思結果:評估行動執行效果,結經驗教訓用於改進
- 8. 循環繼續:回到第一步,開始新的循環,實現持續學習和適應
3. 實現深度推理
3.1 信念管理系統
信念是智能體對世界的理解基礎。一個健壯的信念系統應該有完善的信念衝突解決機制:
- 當新信念與舊信念衝突時:
- 1. 比較置信度:選擇置信度更高的信念
- 2. 檢查來源可靠性:優先選擇可靠來源的信念
- 3. 時間新鮮度:優先選擇更新的信息
- 4. 一致性檢查:選擇與大多數其他信念一致的信念
3.2 目標選擇算法
智能體可能同時有多個目標,需要智能地選擇當前要追求的目標:
- 目標評分公式:目標總分 = 優先級權重 × 0.6 + 可行性評分 × 0.3 + 緊急度 × 0.1
- 其中:
- - 優先級權重:目標本身的重要性(1-10)
- - 可行性評分:基於智能體能力和資源的評估(0-1)
- - 緊急度:基於時間限制的緊迫性(0-1)
五、智能體設計示例
一個智能研究助手,主要是做學術研究任務,具體研究"人工智能在醫療診斷中的應用現狀與發展趨勢"
1. 代碼設計
1.1 基礎數據結構定義
from enum import Enum
class ResearchStatus(Enum):
NOT_STARTED = "未開始"
TOPIC_CONFIRMED = "主題確認"
LITERATURE_REVIEW = "文獻調研"
# ... 其他狀態
class TaskStatus(Enum):
PENDING = "待執行"
IN_PROGRESS = "執行中"
# ... 其他狀態
- 使用枚舉類型確保狀態值的一致性
- 提供清晰的狀態標識,便於狀態管理和追蹤
- 增強代碼的可讀性和可維護性
1.2 核心數據結構
from dataclasses import dataclass
@dataclass
class Belief:
content: str
confidence: float
source: str
timestamp: float
@dataclass
class TaskResult:
task_name: str
status: TaskStatus
output: Any
execution_time: float
lessons_learned: List[str]
- 使用數據類簡化數據結構定義
- 明確每個數據字段的類型和含義
- 便於數據的序列化和反序列化
- 支持類型檢查和自動補全
1.3 智能體初始化系統
def initialize_belief_system(self):
self.beliefs = {
'current_topic': None,
'research_status': ResearchStatus.NOT_STARTED,
'knowledge_base': {
'ai_techniques': [
Belief("機器學習在醫療診斷中應用廣泛", 0.9, "領域知識", time.time()),
# ...
]
}
}
def initialize_desire_system(self):
self.desires = {
'primary_goals': [
"完成高質量研究報告",
# ...
],
'quality_standards': {
'completeness': 0.9,
# ...
}
}
- 分離不同系統的初始化邏輯
- 提供清晰的初始狀態
- 建立完整的BDI架構基礎
- 便於後續的狀態管理和更新
1.4 環境感知模塊
def perceive_environment(self, research_topic: str) -> Dict[str, Any]:
print(f" {self.name} 正在感知環境...")
perception = {
'research_topic': research_topic,
'timestamp': time.time(),
'complexity': self.assess_topic_complexity(research_topic)
}
return perception
def assess_topic_complexity(self, topic: str) -> str:
complexity_keywords = {
'高': ['趨勢', '發展', '現狀', '綜述', '分析'],
# ...
}
- 模擬智能體從環境接收信息的過程
- 提供初步的信息分析和分類
- 為後續的信念更新提供原始數據
- 體現智能體的感知能力
1.5 信念更新系統
def update_beliefs(self, perception: Dict[str, Any]):
# 更新研究主題
self.beliefs['current_topic'] = perception['research_topic']
# 更新研究狀態
self.beliefs['research_status'] = ResearchStatus.TOPIC_CONFIRMED
# 添加新的信念
new_belief = Belief(
content=f"研究主題'{perception['research_topic']}'複雜度為{perception['complexity']}",
confidence=0.8,
source='複雜度評估',
timestamp=time.time()
)
- 將感知信息轉化為內部信念
- 維護信念的一致性和時效性
- 支持信念的增量更新
- 體現智能體的學習和記憶能力
1.6 目標評估系統
def evaluate_goals(self) -> List[str]:
# 基於當前信念激活相關願望
activated_goals = []
if self.beliefs['research_status'] == ResearchStatus.TOPIC_CONFIRMED:
activated_goals = [
"收集相關文獻資料",
"分析技術應用現狀",
# ...
]
# 設置目標優先級
prioritized_goals = self.prioritize_goals(activated_goals)
return prioritized_goals
def prioritize_goals(self, goals: List[str]) -> List[str]:
priority_order = {
"收集相關文獻資料": 1,
"分析技術應用現狀": 2,
# ...
}
- 基於當前信念激活相關目標
- 提供目標優先級排序機制
- 支持目標衝突的解決
- 體現智能體的決策導向
1.7 計劃生成系統
def generate_research_plan(self) -> Dict[str, Any]:
research_plan = {
'research_topic': self.beliefs['current_topic'],
'phases': {
'phase_1': {
'name': '文獻調研階段',
'description': '全面收集和閲讀相關文獻',
'tasks': [
'檢索學術數據庫',
'收集相關論文',
# ...
],
'success_criteria': ['收集30+篇相關論文', '完成文獻綜述'],
'time_estimate': 3,
'resource_allocation': 0.3
},
# ... 其他階段
}
}
- 將抽象目標轉化為具體計劃
- 提供詳細的任務分解和時間安排
- 支持資源分配和進度跟蹤
- 體現智能體的規劃能力
1.8 計劃執行系統
def execute_plan(self) -> List[TaskResult]:
all_results = []
plan = self.intentions['current_plan']
for phase_id, phase_details in plan['phases'].items():
phase_results = self.execute_phase(phase_id, phase_details)
all_results.extend(phase_results)
# 更新階段進度信念
self.update_phase_progress(phase_id, phase_results)
return all_results
def execute_phase(self, phase_id: str, phase_details: Dict[str, Any]) -> List[TaskResult]:
phase_results = []
for task in phase_details['tasks']:
result = self.execute_task(task, phase_id)
phase_results.append(result)
# 更新任務歷史信念
self.beliefs['task_history'].append({
'task': task,
'phase': phase_id,
'result': result,
'timestamp': time.time()
})
return phase_results
- 按計劃執行具體任務
- 實時更新執行狀態和進度
- 收集任務執行結果數據
- 體現智能體的執行能力
1.9 任務執行器系統
def execute_task(self, task: str, phase: str) -> TaskResult:
task_executors = {
'檢索學術數據庫': self.search_databases,
'收集相關論文': self.collect_papers,
# ...
}
executor = task_executors.get(task, self.default_task_executor)
output = executor()
# 評估任務成功率(模擬)
success_rate = 0.85 + (hash(task) % 100) * 0.001
status = TaskStatus.COMPLETED if success_rate > 0.8 else TaskStatus.FAILED
return TaskResult(
task_name=task,
status=status,
output=output,
execution_time=execution_time,
lessons_learned=[f"任務{task}執行{'成功' if status == TaskStatus.COMPLETED else '失敗'}"]
)
def search_databases(self):
return {
'databases_searched': ['CNKI', 'Web of Science', 'IEEE Xplore'],
'papers_found': 35,
'keywords_used': ['AI醫療診斷', '深度學習醫療', '智能診斷系統']
}
- 提供具體任務的執行邏輯
- 模擬真實的任務執行過程
- 生成詳細的執行結果數據
- 支持任務執行的擴展和定製
1.10 反思學習系統
def reflect_on_results(self, execution_results: List[TaskResult]):
# 計算整體成功率
successful_tasks = [r for r in execution_results if r.status == TaskStatus.COMPLETED]
overall_success_rate = len(successful_tasks) / len(execution_results)
# 提取經驗教訓
lessons = self.extract_lessons(execution_results)
# 更新信念系統
self.update_beliefs_from_reflection(lessons, overall_success_rate)
def extract_lessons(self, results: List[TaskResult]) -> List[str]:
lessons = []
# 分析成功任務模式
successful_tasks = [r for r in results if r.status == TaskStatus.COMPLETED]
if successful_tasks:
common_success_patterns = self.identify_success_patterns(successful_tasks)
lessons.append(f"成功模式: {common_success_patterns}")
return lessons
- 從執行結果中提取有價值的信息
- 識別成功模式和失敗原因
- 更新信念系統以改進未來決策
- 體現智能體的學習能力
1.11 主控制循環
def run_complete_cycle(self, research_topic: str):
# 1. 感知環境
perception = self.perceive_environment(research_topic)
# 2. 更新信念
self.update_beliefs(perception)
# 3. 評估目標
goals = self.evaluate_goals()
# 4. 生成計劃
plan = self.generate_research_plan()
# 5. 執行計劃
results = self.execute_plan()
# 6. 反思結果
reflection = self.reflect_on_results(results)
- 整合所有組件形成完整的工作流程
- 確保各系統間的協調運作
- 提供清晰的執行順序和邏輯
- 支持循環執行和持續學習
1.12 報告生成系統
def generate_final_report(self, reflection: Dict[str, Any]):
print(f"\n📄 最終研究報告摘要 - {self.beliefs['current_topic']}")
print("-" * 50)
print(f"研究狀態: {self.beliefs['research_status'].value}")
print(f"任務成功率: {reflection['success_rate']:.1%}")
print("\n📚 知識積累:")
for category, beliefs in self.beliefs['knowledge_base'].items():
if beliefs:
print(f" {category}: {len(beliefs)}條知識")
- 提供執行結果的總結和展示
- 輸出有價值的信息和洞察
- 支持決策的透明化和可解釋性
- 便於人類理解和評估智能體表現
這個分解展示了深思熟慮智能體的完整架構:
- 模塊化設計:每個組件職責單一,便於理解和維護
- 數據驅動:通過明確的數據結構傳遞信息
- 狀態管理:維護完整的狀態信息支持複雜推理
- 學習能力:通過反思機制持續改進性能
- 可擴展性:每個組件都可以獨立擴展和優化
這種設計使得智能體能夠真正實現"深思熟慮",而不僅僅是簡單的條件反射。
2. 輸出結果
=================================================
AI研究專家 開始執行研究任務
=================================================
AI研究專家 正在感知環境...
接收到研究任務: 人工智能在醫療診斷中的應用現狀與發展趨勢
AI研究專家 正在更新信念系統...
信念更新: 研究主題確認, 複雜度高
AI研究專家 正在評估目標...
激活目標: 收集相關文獻資料, 分析技術應用現狀, 總結研究成果, 預測發展趨勢, 撰寫研究報告
AI研究專家 正在生成研究計劃...
計劃生成完成: 共4個階段
AI研究專家 開始執行研究計劃...
=================================================
執行階段: 文獻調研階段
描述: 全面收集和閲讀相關文獻
預計時間: 3天
執行任務: 檢索學術數據庫
執行任務: 收集相關論文
執行任務: 閲讀核心文獻
執行任務: 整理研究脈絡
執行任務: 撰寫文獻綜述
執行階段: 技術分析階段
描述: 深入分析AI技術應用細節
預計時間: 4天
執行任務: 分析AI技術應用
執行任務: 評估診斷準確性
執行任務: 比較不同方法
執行任務: 識別技術瓶頸
執行任務: 總結技術優勢
執行階段: 趨勢預測階段
描述: 預測未來發展方向
預計時間: 2天
執行任務: 分析發展軌跡
執行任務: 識別新興技術
執行任務: 預測未來方向
執行任務: 提出發展建議
執行任務: 驗證預測合理性
執行階段: 報告撰寫階段
描述: 整理研究成果形成報告
預計時間: 3天
執行任務: 組織研究內容
執行任務: 撰寫研究報告
執行任務: 審核修改完善
執行任務: 格式排版優化
執行任務: 最終定稿提交
AI研究專家 正在反思執行結果...
=================================================
執行統計:
總任務數: 20
成功任務: 20
成功率: 100.0%
平均任務時間: 0.00秒
經驗總結:
• 成功模式: 檢索學術數據庫類任務成功率最高
• 效率優化: 任務執行效率良好
=================================================
研究任務完成!
=================================================
最終研究報告摘要 - 人工智能在醫療診斷中的應用現狀與發展趨勢
--------------------------------------------------
研究狀態: 已完成
任務成功率: 100.0%
總執行時間: 0.00秒
知識積累:
ai_techniques: 3條知識
medical_domains: 3條知識
topic_complexity: 1條知識
reflection_insights: 1條知識
主要經驗:
• 成功模式: 檢索學術數據庫類任務成功率最高
• 效率優化: 任務執行效率良好
後續改進方向:
• 優化複雜任務執行策略
• 提升任務執行效率
• 加強知識積累和應用
六、總結
深思熟慮智能體就像一個會真正動腦子的智能助手,它和那些只會機械回答問題的普通程序完全不同。當你交給它一個任務時,它不會立即給出答案,而是會像經驗豐富的研究員一樣,先深入理解問題,然後規劃完整的解決步驟,最後系統性地執行,並且在完成後還會反思總結,讓自己下次做得更好。
這套思考方式的核心就是BDI架構,可以簡單理解為三個關鍵部分:信念是它的知識庫,記住它知道什麼;願望是它的目標,明確它要達成什麼;意圖是它的行動計劃,決定它具體要怎麼做。正是這種結構化的思考方式,讓智能體能夠像人類一樣進行深度思考,而不是簡單地條件反射,從而能夠處理各種複雜任務並持續進步。