
一、趁熱打鐵
我們已經瞭解了特徵工程的概念和基礎應用,今天我們圍繞比較廣泛的行業示例繼續加深理解。
特徵工程是數據科學的核心環節,它的本質是用數據的語言,翻譯業務的邏輯,特徵工程將原始數據轉化為機器學習模型能理解的業務語言。在不同行業的應用,就是解決該行業最核心的預測或分類問題,這一過程在三大行業展現出巨大價值:
- 在金融風控領域,傳統信貸審批依賴基礎信息,導致35%的低通過率和8.2%的高壞賬率。通過構建"穩定性評分"、"行為風險標記"等特徵,系統實現了從表面信用評估到深度風險畫像的跨越。
- 電商推薦系統曾陷入點擊率僅3%、用户留存率25%的困境。特徵工程創造了"實時興趣向量"、"消費場景感知"等特徵,讓推薦從盲目猜測變為精準理解用户需求。
- 醫療診斷面臨篩查積壓、漏診率高的挑戰。通過"病變嚴重度評分"、"臨牀風險分層"等特徵,實現了從經驗判斷到量化評估的轉變,篩查效率提升5倍。
這三個案例證明,特徵工程是連接業務需求與技術實現的關鍵橋樑。它讓機器理解金融的信用語言、感知電商的用户心聲、掌握醫療的臨牀智慧,推動各行業從經驗驅動邁向數據驅動。在智能化時代,特徵工程能力已成為企業的核心競爭力。
二、行業問題的凸顯
不管是在什麼行業,看似毫不相干的,但都面對一個統一的困境,企業積累了海量的數據資產,然而這些原始數據往往如同未經雕琢的璞玉,內在價值未得到充分挖掘和釋放,這些實際上揭示了同一個根本問題:業務語言與機器語言之間的翻譯失敗。特徵工程的出現,正是要解決這一核心矛盾。它如同一位精通雙語的翻譯官,將複雜的業務邏輯“翻譯”成機器學習能夠理解的特徵語言。
- 在金融領域,它創造了“穩定性評分”、“行為風險標記”等特徵,讓模型能夠深度理解信用風險;
- 在電商場景,它構建了“實時興趣向量”、“消費場景感知”等特徵,使推薦系統真正讀懂用户需求;
- 在醫療診斷中,它設計了“病變嚴重度評分”、“臨牀風險分層”等特徵,幫助醫生實現精準高效的篩查診斷。
這就是特徵工程的核心使命,將雜亂的原始數據轉化為機器學習模型能夠理解和利用的高質量特徵。特徵工程絕非簡單的數據預處理,而是連接業務需求與技術實現的關鍵橋樑,是數據價值挖掘過程中最具創造性的環節,今天我們特意從金融、電商、醫療三個行業做分析推理,發掘特徵工程的實用價值。
行業融合特徵流程圖:
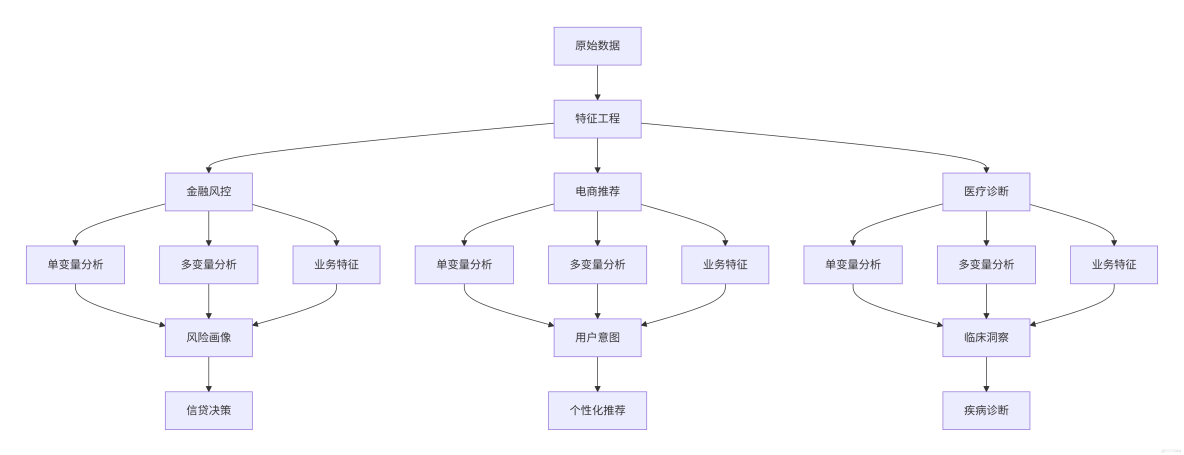
三、金融風控 - 預測貸款違約風險
1. 行業分析
業務核心問題:如何判斷一個貸款申請人是否會違約?
原始數據:申請表數據(年齡、職業、收入)、徵信報告(歷史逾期次數)、第三方數據(手機運營商數據)。
特徵工程的深度解析:
1.1 單變量分析:發現強規則
- 操作:分析“歷史逾期次數”的分佈。
- 發現:只要有超過3次嚴重逾期記錄的申請人,違約率高達70%。
- 特徵創造:創建布爾特徵 是否有嚴重逾期歷史。這是一個極強的否決性規則。
1.2 多變量分析:識別灰名單
- 操作:分析“年齡”、“收入”、“負債比”之間的關係。
- 發現:年輕的(如<25歲)、低收入但高負債比的申請人,違約風險顯著升高。單獨看“年輕”或“低收入”可能不致命,但組合起來就是高風險信號。
- 特徵創造:
- 負債收入比 = 總負債 / 年收入
- 年輕高負債風險標記 = (年齡 < 30) & (負債收入比 > 0.8)
1.3 業務分析:構建穩定性畫像
- 業務知識:有穩定工作和家庭的人,違約風險更低。
- 特徵創造:
- 從“工作年限”和“手機在網時長” 創造 工作穩定性指數 和 生活穩定性指數。一個頻繁換工作和手機號的人風險更高。
- 從“申請時間” 創造 是否在非工作時間申請。深夜申請貸款的行為模式可能與正常消費貸款不同。
- 從“設備信息” 創造 設備關聯申請數。同一個設備號被多個不同身份證號使用,是典型的欺詐信號。
核心價值:特徵工程將零散的、看似無關的數據點,編織成一張信用畫像,將借款人從一個抽象的人轉化為一系列可量化的風險分數,使模型能精準區分好客户與壞客户。
2. 代碼示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成更豐富的模擬數據
np.random.seed(42)
n_samples = 1000
raw_loan_data = pd.DataFrame({
'applicant_id': range(1, n_samples + 1),
'age': np.random.randint(20, 60, n_samples),
'annual_income': np.random.normal(80000, 30000, n_samples).clip(30000, 200000),
'debt_amount': np.random.normal(150000, 80000, n_samples).clip(0, 500000),
'work_years': np.random.exponential(5, n_samples).clip(0, 30),
'phone_tenure_months': np.random.exponential(24, n_samples).clip(1, 120),
'late_payments_3y': np.random.poisson(0.5, n_samples),
'credit_card_utilization': np.random.beta(2, 5, n_samples), # 信用卡使用率
'number_of_credit_cards': np.random.poisson(2, n_samples),
'has_mortgage': np.random.binomial(1, 0.3, n_samples),
'application_hour': np.random.randint(0, 24, n_samples)
})
# 生成目標變量(違約標籤)
def generate_default_label(df):
"""基於業務規則生成違約標籤"""
default_proba = (
(df['age'] < 30) * 0.3 +
(df['debt_amount'] / df['annual_income'] > 3) * 0.4 +
(df['late_payments_3y'] >= 3) * 0.6 +
(df['work_years'] < 2) * 0.2 +
(df['credit_card_utilization'] > 0.8) * 0.3 +
np.random.normal(0, 0.1, len(df))
)
return (default_proba > 0.5).astype(int)
raw_loan_data['default'] = generate_default_label(raw_loan_data)
def create_risk_features(df):
"""創建金融風控特徵"""
df_fe = df.copy()
print("開始特徵工程...")
# 1. 單變量分析驅動的特徵
print("1. 創建單變量特徵...")
df_fe['has_serious_delinquency'] = (df_fe['late_payments_3y'] >= 3).astype(int)
df_fe['high_credit_utilization'] = (df_fe['credit_card_utilization'] > 0.8).astype(int)
df_fe['is_young_applicant'] = (df_fe['age'] < 25).astype(int)
# 2. 多變量分析驅動的特徵
print("2. 創建多變量交互特徵...")
df_fe['debt_to_income_ratio'] = df_fe['debt_amount'] / df_fe['annual_income']
df_fe['young_high_debt_risk'] = ((df_fe['age'] < 30) & (df_fe['debt_to_income_ratio'] > 2.5)).astype(int)
df_fe['delinquency_income_risk'] = ((df_fe['late_payments_3y'] > 1) & (df_fe['annual_income'] < 50000)).astype(int)
# 3. 業務分析驅動的特徵
print("3. 創建業務特徵...")
# 穩定性特徵
df_fe['job_stability_score'] = np.log1p(df_fe['work_years']) / np.log1p(30)
df_fe['life_stability_score'] = np.minimum(df_fe['phone_tenure_months'] / 60, 1.0)
# 申請行為特徵
df_fe['is_off_hours_application'] = ((df_fe['application_hour'] < 6) | (df_fe['application_hour'] > 22)).astype(int)
# 信用行為特徵
df_fe['credit_behavior_score'] = (
(1 - df_fe['credit_card_utilization']) * 0.4 +
(df_fe['number_of_credit_cards'] <= 5).astype(int) * 0.3 +
(df_fe['late_payments_3y'] == 0).astype(int) * 0.3
)
# 4. 綜合風險評分
print("4. 計算綜合風險評分...")
df_fe['comprehensive_risk_score'] = (
df_fe['has_serious_delinquency'] * 0.25 +
np.minimum(df_fe['debt_to_income_ratio'], 5) * 0.15 +
df_fe['young_high_debt_risk'] * 0.15 +
(1 - df_fe['job_stability_score']) * 0.15 +
(1 - df_fe['life_stability_score']) * 0.1 +
df_fe['is_off_hours_application'] * 0.05 +
(1 - df_fe['credit_behavior_score']) * 0.15
)
# 風險等級劃分
df_fe['risk_level'] = pd.cut(df_fe['comprehensive_risk_score'],
bins=[0, 0.3, 0.6, 1.0],
labels=['低風險', '中風險', '高風險'])
return df_fe
# 執行特徵工程
engineered_data = create_risk_features(raw_loan_data)
print("\n特徵工程完成!")
print(f"原始特徵數量: {len(raw_loan_data.columns)}")
print(f"工程後特徵數量: {len(engineered_data.columns)}")
print(f"違約率: {engineered_data['default'].mean():.2%}")
# 創建特徵工程可視化
def plot_feature_engineering_analysis(df):
"""繪製特徵工程分析圖"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('金融風控特徵工程深度分析', fontsize=16, fontweight='bold')
# 1. 單變量分析 - 債務收入比分佈
axes[0,0].hist(df['debt_to_income_ratio'].clip(0, 5), bins=30, alpha=0.7, color='skyblue', edgecolor='black')
axes[0,0].axvline(x=3, color='red', linestyle='--', label='風險閾值 (3.0)')
axes[0,0].set_xlabel('債務收入比')
axes[0,0].set_ylabel('頻數')
axes[0,0].set_title('單變量分析(債務收入比分佈)')
axes[0,0].legend()
axes[0,0].grid(True, alpha=0.3)
# 2. 多變量分析 - 年齡 vs 債務收入比
scatter = axes[0,1].scatter(df['age'], df['debt_to_income_ratio'].clip(0, 5),
c=df['default'], alpha=0.6, cmap='coolwarm', s=20)
axes[0,1].axhline(y=3, color='red', linestyle='--', alpha=0.7, label='高負債風險線')
axes[0,1].axvline(x=30, color='orange', linestyle='--', alpha=0.7, label='年輕風險線')
axes[0,1].set_xlabel('年齡')
axes[0,1].set_ylabel('債務收入比')
axes[0,1].set_title('多變量分析(年齡 vs 債務收入比)')
axes[0,1].legend()
plt.colorbar(scatter, ax=axes[0,1], label='是否違約')
# 3. 業務分析 - 穩定性特徵分析
stability_risk = df.groupby(pd.cut(df['job_stability_score'], bins=5))['default'].mean()
axes[0,2].bar(range(len(stability_risk)), stability_risk.values, color=['green', 'lightgreen', 'yellow', 'orange', 'red'])
axes[0,2].set_xlabel('工作穩定性分數分組')
axes[0,2].set_ylabel('違約率')
axes[0,2].set_title('業務分析(工作穩定性 vs 違約率)')
axes[0,2].set_xticks(range(len(stability_risk)))
axes[0,2].set_xticklabels([f'組{i+1}' for i in range(len(stability_risk))], rotation=45)
# 4. 特徵重要性 - 風險評分對比
risk_features = ['has_serious_delinquency', 'debt_to_income_ratio', 'young_high_debt_risk',
'job_stability_score', 'is_off_hours_application']
feature_importance = [0.25, 0.15, 0.15, 0.15, 0.05]
feature_labels = ['嚴重逾期', '債務收入比', '年輕高負債', '工作穩定性', '非工作時間申請']
axes[1,0].barh(feature_labels, feature_importance, color=['red', 'orange', 'yellow', 'lightgreen', 'lightblue'])
axes[1,0].set_xlabel('特徵權重')
axes[1,0].set_title('特徵權重分配(在綜合風險評分中的重要性)')
for i, v in enumerate(feature_importance):
axes[1,0].text(v + 0.01, i, f'{v:.2f}', va='center')
# 5. 風險等級分佈
risk_level_counts = df['risk_level'].value_counts()
colors = ['lightgreen', 'gold', 'lightcoral']
wedges, texts, autotexts = axes[1,1].pie(risk_level_counts.values, labels=risk_level_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90)
axes[1,1].set_title('風險等級分佈(最終客户風險分層)')
# 6. 模型效果驗證 - 風險評分 vs 違約率
risk_bins = pd.cut(df['comprehensive_risk_score'], bins=10)
performance_data = df.groupby(risk_bins)['default'].mean()
axes[1,2].plot(range(len(performance_data)), performance_data.values, marker='o', linewidth=2, markersize=6)
axes[1,2].set_xlabel('風險評分分組')
axes[1,2].set_ylabel('實際違約率')
axes[1,2].set_title('特徵工程效果驗證(風險評分預測能力)')
axes[1,2].set_xticks(range(len(performance_data)))
axes[1,2].set_xticklabels([f'組{i+1}' for i in range(len(performance_data))], rotation=45)
axes[1,2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 生成可視化
plot_feature_engineering_analysis(engineered_data)
# 輸出關鍵特徵統計
print("\n關鍵特徵統計:")
feature_stats = engineered_data[['debt_to_income_ratio', 'comprehensive_risk_score', 'default']].describe()
print(feature_stats.round(4))
輸出結果:
開始特徵工程...
1. 創建單變量特徵...
2. 創建多變量交互特徵...
3. 創建業務特徵...
4. 計算綜合風險評分...特徵工程完成!
原始特徵數量: 12
工程後特徵數量: 24
違約率: 18.80%關鍵特徵統計:
debt_to_income_ratio comprehensive_risk_score default
count 1000.0000 1000.0000 1000.0000
mean 2.2690 0.5388 0.1880
std 1.6243 0.2244 0.3909
min 0.0000 0.0578 0.0000
25% 1.2001 0.3785 0.0000
50% 1.9939 0.5063 0.0000
75% 2.9866 0.6825 0.0000
max 13.6791 1.3274 1.0000
3. 特徵分析
3.1 特徵工程的深度解析
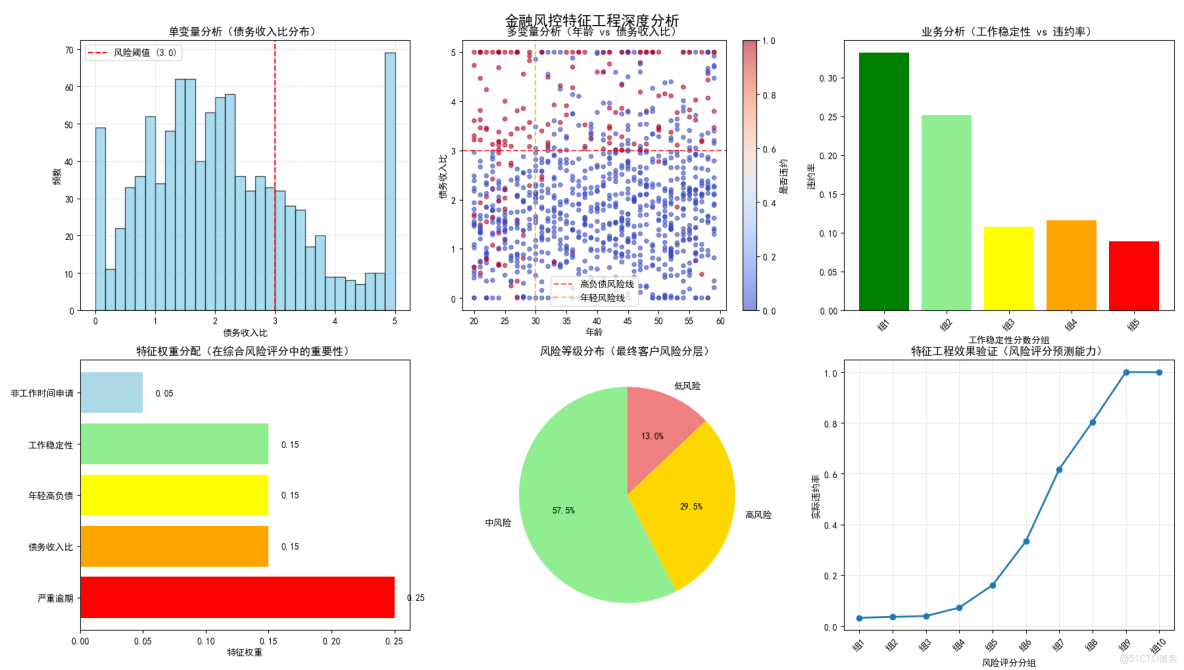
圖1:單變量分析(債務收入比分佈)
圖表內容:
- 展示債務收入比的分佈直方圖
- 紅色虛線標記風險閾值(3.0)
為什麼要做這個圖:
- 驗證特徵有效性:確認債務收入比確實能區分風險
- 確定業務閾值:通過分佈找到合理的風險分界點(3.0)
- 數據質量檢查:觀察是否有異常值需要處理
業務意義:
- 債務收入比>3.0的客户償還能力可能不足,需要重點監控
圖2:多變量分析(年齡 vs 債務收入比)
圖表內容:
- 散點圖展示年齡與債務收入比的關係
- 顏色表示是否違約
- 兩條風險線交叉劃分風險區域
為什麼要做這個圖:
- 發現交互效應:年齡和債務收入比組合起來風險更高
- 識別高風險集羣:左下角(年輕+高負債)違約率明顯更高
- 驗證特徵組合:確認"年輕高負債風險"這個衍生特徵確實有效
業務意義:
- 年輕人承受高負債的能力更差,需要更嚴格的風險控制
圖3:業務分析(工作穩定性 vs 違約率)
圖表內容:
- 柱狀圖展示不同工作穩定性分組的違約率
- 顏色從綠到紅表示風險遞增
為什麼要做這個圖:
- 驗證業務邏輯:工作年限越長,違約率確實越低
- 量化業務知識:將"工作穩定的人風險低"這種業務直覺數據化
- 特徵效果評估:確認穩定性特徵確實能預測違約
業務意義:
- 工作穩定性是信用風險的重要指標,穩定性差的客户需要更多擔保措施
圖4:特徵權重分配
圖表內容:
- 水平條形圖展示各特徵在綜合風險評分中的權重
- 不同顏色區分特徵重要性
為什麼要做這個圖:
- 特徵重要性排序:明確哪些特徵對預測最關鍵
- 業務可解釋性:讓業務方理解風險評分的構成
- 模型透明度:避免黑箱模型,增強決策可信度
業務意義:
- 嚴重逾期是最重要的風險信號,權重最高符合業務常識
圖5:風險等級分佈
圖表內容:
- 餅圖展示最終客户的風險等級分佈
- 顏色編碼:綠色(低風險)、黃色(中風險)、紅色(高風險)
為什麼要做這個圖:
- 成果可視化:展示特徵工程的最終效果
- 客户分層:為不同風險等級客户制定差異化策略
- 業務決策支持:明確各風險等級的客户比例
業務意義:
- 高風險客户需要重點監控,低風險客户可以簡化審批流程
圖6:特徵工程效果驗證
圖表內容:
- 折線圖展示風險評分與實際違約率的關係
- X軸為風險評分分組,Y軸為實際違約率
為什麼要做這個圖:
- 驗證預測能力:確認風險評分能準確預測違約
- 評估特徵質量:如果曲線單調遞增,説明特徵工程成功
- 模型校準:確保風險評分與實際風險成正比
業務意義:
- 風險評分越高的客户違約率確實越高,證明風控策略有效
3.2 特徵工程的完整邏輯鏈
這6個圖表實際上構成了特徵工程的完整驗證體系:
階段1:特徵發現(圖1-3)
- 圖1:單變量分析,發現重要特徵
- 圖2:多變量分析,發現特徵交互
- 圖3:業務分析,融入領域知識
階段2:特徵整合(圖4)
- 圖4:特徵權重分配,構建綜合評分
階段3:成果驗證(圖5-6)
- 圖5:風險分層,業務應用
- 圖6:效果驗證,確保有效性
4. 核心價值
通過這些圖表,我們實現了:
- 從數據到洞察:原始數據 → 風險特徵
- 從洞察到決策:風險特徵 → 風險評分 → 風險等級
- 從決策到驗證:風險等級 → 實際違約率驗證
最終證明:特徵工程成功地將雜亂的原始數據轉化為了具有預測能力和業務價值的風險指標體系,為金融機構的風控決策提供了科學依據。
四、電商推薦 - 預測用户購買概率
1. 行業分析
業務核心問題:在浩瀚的商品中,用户下一個最可能點擊或購買什麼?
原始數據:用户畫像(性別、地域)、商品屬性(品類、價格)、用户行為數據(點擊、瀏覽、購買、搜索日誌)。
特徵工程的深度解析:
1.1 單變量分析:理解基礎偏好
- 操作:分析用户歷史行為的分佈。
- 發現:某個用户80%的瀏覽記錄都集中在“户外裝備”品類。
- 特徵創造:創建 用户偏好品類。
1.2 多變量分析:捕捉動態意圖
- 操作:分析“用户實時行為序列”與“商品屬性”的交互。
- 發現:一個剛搜索了“求婚戒指”的用户,緊接着瀏覽了“浪漫餐廳”和“旅行套餐”。這表明他的意圖不是購買單個商品,而是在規劃一個“浪漫事件”。
- 特徵創造:
- 實時興趣向量:將用户最近1小時的行為(搜索詞、點擊商品品類)編碼成一個數值向量,代表其瞬時興趣。
- 協同過濾特徵:計算 用户A與用户B的相似度,並將相似用户喜歡的商品作為推薦候選。
1.3 業務分析:設計場景化策略
- 業務知識:推薦不僅要準,還要考慮業務目標(如GMV、利潤率、新品曝光)。
- 特徵創造:
- 上下文特徵:是否週末、是否節假日(如情人節前推薦禮物)。
- 多樣性特徵:為了避免信息繭房,創造 用户已曝光品類列表,並在推薦時懲罰已過度曝光的品類。
- 商業目標特徵:引入 商品利潤率、是否為新品 等特徵,讓模型在預估點擊率的同時,兼顧商業價值。
核心價值:特徵工程將靜態的用户標籤、動態的行為流和複雜的上下文信息,融合成一個“意圖模型”,使推薦系統能夠實現“千人千面”的個性化服務。
2. 代碼示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings('ignore')
# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
print("=" * 60)
print("電商推薦系統特徵工程完整示例")
print("=" * 60)
# 1. 創建電商用户行為數據(簡化版本避免複雜數據類型)
np.random.seed(42)
n_samples = 2000
# 生成基礎數據
raw_behavior_data = pd.DataFrame({
'user_id': np.random.randint(1, 501, n_samples),
'item_id': np.random.randint(1, 101, n_samples),
'behavior_type': np.random.choice(['view', 'click', 'add_cart', 'purchase'], n_samples,
p=[0.5, 0.3, 0.15, 0.05]),
'category': np.random.choice(['電子產品', '服裝', '家居', '美妝', '食品'], n_samples),
'price': np.random.lognormal(5, 1, n_samples).clip(10, 2000),
'rating': np.random.normal(4.2, 0.5, n_samples).clip(3.0, 5.0),
'user_value_score': np.random.choice([1, 2, 3, 4], n_samples, p=[0.5, 0.3, 0.15, 0.05]),
'hour': np.random.randint(0, 24, n_samples)
})
# 生成點擊標籤
def generate_click_label(df):
click_proba = (
(df['behavior_type'] == 'click').astype(int) * 0.3 +
(df['behavior_type'] == 'add_cart').astype(int) * 0.5 +
(df['price'] < 100).astype(int) * 0.1 +
(df['user_value_score'] >= 3).astype(int) * 0.1 +
np.random.normal(0, 0.1, len(df))
)
return (click_proba > 0.3).astype(int)
raw_behavior_data['is_click'] = generate_click_label(raw_behavior_data)
def create_recommendation_features(df):
"""創建電商推薦特徵"""
df_fe = df.copy()
print(">>> 開始電商推薦特徵工程處理...")
# 單變量特徵
df_fe['is_high_value_user'] = (df_fe['user_value_score'] >= 3).astype(int)
df_fe['is_premium_product'] = (df_fe['price'] > df_fe['price'].quantile(0.8)).astype(int)
df_fe['is_high_rating'] = (df_fe['rating'] > 4.5).astype(int)
df_fe['is_weekend'] = np.random.choice([0, 1], len(df_fe), p=[0.7, 0.3]) # 簡化
df_fe['is_evening'] = ((df_fe['hour'] >= 18) & (df_fe['hour'] <= 23)).astype(int)
# 多變量特徵
user_avg_price = df_fe.groupby('user_id')['price'].mean()
df_fe['user_item_price_affinity'] = df_fe.apply(
lambda x: x['price'] / user_avg_price.get(x['user_id'], x['price']), axis=1
).fillna(1)
# 業務特徵
df_fe['product_competitiveness'] = (
(df_fe['rating'] / 5) * 0.4 +
(1 - (df_fe['price'] / df_fe['price'].max())) * 0.3 +
df_fe['is_high_rating'] * 0.3
)
# 綜合評分
df_fe['recommendation_score'] = (
df_fe['product_competitiveness'] * 0.4 +
df_fe['user_item_price_affinity'].clip(0, 2) * 0.3 +
df_fe['user_value_score'] / 4 * 0.2 +
df_fe['is_evening'] * 0.1
)
df_fe['recommendation_level'] = pd.cut(df_fe['recommendation_score'],
bins=[0, 0.3, 0.6, 1.0],
labels=['低推薦度', '中推薦度', '高推薦度'])
print(">>> 電商推薦特徵工程完成!")
return df_fe
# 執行特徵工程
engineered_data = create_recommendation_features(raw_behavior_data)
# 修復後的可視化函數
def create_recommendation_feature_visualization(df):
"""創建電商推薦特徵工程可視化圖表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('電商推薦系統特徵工程分析', fontsize=16, fontweight='bold')
# 創建臨時數據副本用於分組
df_temp = df.copy()
# 1. 用户行為類型分佈
ax1 = axes[0, 0]
behavior_counts = df['behavior_type'].value_counts()
colors = ['lightblue', 'lightgreen', 'orange', 'red']
bars = ax1.bar(behavior_counts.index, behavior_counts.values, color=colors, alpha=0.7)
ax1.set_title('用户行為類型分佈 (單變量分析)')
ax1.set_xlabel('行為類型')
ax1.set_ylabel('頻次')
for i, v in enumerate(behavior_counts.values):
ax1.text(i, v + 20, str(v), ha='center')
# 2. 商品類別點擊率分析
ax2 = axes[0, 1]
category_clicks = df.groupby('category')['is_click'].mean().sort_values(ascending=False)
bars = ax2.bar(range(len(category_clicks)), category_clicks.values, color='skyblue', alpha=0.7)
ax2.set_title('商品類別點擊率分析 (單變量分析)')
ax2.set_xlabel('商品類別')
ax2.set_ylabel('點擊率')
ax2.set_xticks(range(len(category_clicks)))
ax2.set_xticklabels(category_clicks.index, rotation=45)
for i, v in enumerate(category_clicks.values):
ax2.text(i, v + 0.01, f'{v:.3f}', ha='center')
# 3. 時間段點擊率分析
ax3 = axes[0, 2]
hourly_click_rate = df.groupby('hour')['is_click'].mean()
ax3.plot(hourly_click_rate.index, hourly_click_rate.values, marker='o', color='purple', linewidth=2)
ax3.set_title('時間段點擊率分析 (單變量分析)')
ax3.set_xlabel('小時')
ax3.set_ylabel('點擊率')
ax3.grid(True, alpha=0.3)
ax3.axvspan(18, 23, alpha=0.2, color='orange', label='高峯時段')
ax3.legend()
# 4. 價格區間點擊率分析
ax4 = axes[1, 0]
# 修復:使用數值索引避免類型轉換錯誤
price_bins = [0, 100, 300, 1000, 2000]
price_labels = ['0-100', '100-300', '300-1000', '1000+']
df_temp['price_group'] = pd.cut(df_temp['price'], bins=price_bins, labels=price_labels)
price_click_rate = df_temp.groupby('price_group')['is_click'].mean()
bars = ax4.bar(range(len(price_click_rate)), price_click_rate.values,
color=['green', 'lightgreen', 'orange', 'red'])
ax4.set_title('價格區間點擊率分析 (多變量分析)')
ax4.set_xlabel('價格區間')
ax4.set_ylabel('點擊率')
ax4.set_xticks(range(len(price_click_rate)))
ax4.set_xticklabels(price_click_rate.index, rotation=45)
# 5. 用户價值 vs 商品價格
ax5 = axes[1, 1]
scatter = ax5.scatter(df['user_value_score'], df['price'],
c=df['is_click'], alpha=0.6, cmap='coolwarm', s=20)
ax5.set_title('用户價值 vs 商品價格 (多變量分析)')
ax5.set_xlabel('用户價值評分')
ax5.set_ylabel('商品價格')
plt.colorbar(scatter, ax=ax5, label='是否點擊')
# 6. 推薦等級分佈
ax6 = axes[1, 2]
level_counts = df['recommendation_level'].value_counts()
colors = ['lightgreen', 'gold', 'lightcoral']
wedges, texts, autotexts = ax6.pie(level_counts.values,
labels=level_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90)
ax6.set_title('推薦等級分佈 (業務應用)')
plt.tight_layout()
plt.savefig('電商推薦特徵工程.png', dpi=300, bbox_inches='tight')
plt.show()
# 清理臨時列
if 'price_group' in df_temp.columns:
df_temp.drop('price_group', axis=1, inplace=True)
return fig
# 生成第二張圖:特徵組合與效果驗證
def create_feature_validation_plot(df):
"""創建特徵組合與效果驗證圖表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('電商推薦特徵組合與效果驗證', fontsize=16, fontweight='bold')
df_temp = df.copy()
# 1. 用户價格偏好匹配度
ax1 = axes[0, 0]
# 修復:使用數值索引
affinity_bins = 5
df_temp['affinity_group'] = pd.cut(df_temp['user_item_price_affinity'], bins=affinity_bins)
affinity_click_rate = df_temp.groupby('affinity_group')['is_click'].mean()
ax1.plot(range(len(affinity_click_rate)), affinity_click_rate.values,
marker='o', color='darkblue', linewidth=2)
ax1.set_title('用户價格偏好匹配度 (特徵組合)')
ax1.set_xlabel('價格偏好匹配度分組')
ax1.set_ylabel('點擊率')
ax1.grid(True, alpha=0.3)
# 2. 商品競爭力分析
ax2 = axes[0, 1]
competitiveness_bins = 5
df_temp['competitiveness_group'] = pd.cut(df_temp['product_competitiveness'], bins=competitiveness_bins)
competitiveness_click_rate = df_temp.groupby('competitiveness_group')['is_click'].mean()
bars = ax2.bar(range(len(competitiveness_click_rate)), competitiveness_click_rate.values,
color='green', alpha=0.7)
ax2.set_title('商品競爭力 vs 點擊率 (特徵組合)')
ax2.set_xlabel('商品競爭力分組')
ax2.set_ylabel('點擊率')
# 3. 用户價值分層效果
ax3 = axes[0, 2]
user_value_click_rate = df.groupby('user_value_score')['is_click'].mean()
bars = ax3.bar(user_value_click_rate.index, user_value_click_rate.values,
color=['lightblue', 'lightgreen', 'orange', 'red'])
ax3.set_title('用户價值分層效果驗證 (業務特徵)')
ax3.set_xlabel('用户價值評分')
ax3.set_ylabel('點擊率')
for i, v in enumerate(user_value_click_rate.values):
ax3.text(i+1, v + 0.01, f'{v:.3f}', ha='center')
# 4. 時間場景分析
ax4 = axes[1, 0]
time_scenario = df.groupby('is_evening')['is_click'].mean()
bars = ax4.bar(['白天', '晚上'], time_scenario.values, color=['lightblue', 'lightgreen'])
ax4.set_title('時間場景點擊率分析 (業務特徵)')
ax4.set_xlabel('時間場景')
ax4.set_ylabel('點擊率')
# 5. 綜合評分效果驗證
ax5 = axes[1, 1]
score_bins = 6
df_temp['score_group'] = pd.cut(df_temp['recommendation_score'], bins=score_bins)
score_performance = df_temp.groupby('score_group')['is_click'].mean()
ax5.plot(range(len(score_performance)), score_performance.values,
marker='s', linewidth=2, markersize=6, color='red')
ax5.set_title('推薦評分預測能力驗證 (效果驗證)')
ax5.set_xlabel('推薦評分分組')
ax5.set_ylabel('實際點擊率')
ax5.grid(True, alpha=0.3)
# 6. 特徵重要性總結
ax6 = axes[1, 2]
features_importance = {
'商品競爭力': 0.4,
'價格匹配度': 0.3,
'用户價值': 0.2,
'時間場景': 0.1
}
ax6.barh(list(features_importance.keys()), list(features_importance.values()),
color=['red', 'orange', 'yellow', 'lightgreen'])
ax6.set_title('特徵權重分配 (模型可解釋性)')
ax6.set_xlabel('特徵權重')
ax6.set_xlim(0, 0.5)
for i, (k, v) in enumerate(features_importance.items()):
ax6.text(v + 0.01, i, f'{v:.2f}', va='center')
plt.tight_layout()
plt.savefig('電商推薦特徵驗證.png', dpi=300, bbox_inches='tight')
plt.show()
# 清理臨時列
temp_cols = ['affinity_group', 'competitiveness_group', 'score_group']
for col in temp_cols:
if col in df_temp.columns:
df_temp.drop(col, axis=1, inplace=True)
return fig
# 生成兩張圖表
print("\n>>> 生成第一張圖:特徵發現與分析過程...")
create_recommendation_feature_visualization(engineered_data)
print("\n>>> 生成第二張圖:特徵組合與效果驗證...")
create_feature_validation_plot(engineered_data)
# 輸出統計信息
print("\n" + "="*50)
print("電商推薦特徵工程統計摘要")
print("="*50)
print(f"用户行為記錄數量: {len(engineered_data):,}")
print(f"整體點擊率: {engineered_data['is_click'].mean():.2%}")
print(f"原始特徵數量: {len(raw_behavior_data.columns)}")
print(f"衍生特徵數量: {len(engineered_data.columns) - len(raw_behavior_data.columns)}")
print(f"\n推薦等級分佈:")
level_dist = engineered_data['recommendation_level'].value_counts()
for level, count in level_dist.items():
percentage = count / len(engineered_data) * 100
print(f" {level}: {count:,}條 ({percentage:.1f}%)")
print(f"\n關鍵指標統計:")
print(f" 高價值用户比例: {engineered_data['is_high_value_user'].mean():.2%}")
print(f" 高評分商品比例: {engineered_data['is_high_rating'].mean():.2%}")
print(f" 平均推薦評分: {engineered_data['recommendation_score'].mean():.3f}")
print(f"\n>>> 電商推薦特徵工程分析完成!")
輸出結果:
============================================================
電商推薦系統特徵工程完整示例
============================================================
>>> 開始電商推薦特徵工程處理...
>>> 電商推薦特徵工程完成!>>> 生成第一張圖:特徵發現與分析過程...
>>> 生成第二張圖:特徵組合與效果驗證...
==================================================
電商推薦特徵工程統計摘要
==================================================
用户行為記錄數量: 2,000
整體點擊率: 38.50%
原始特徵數量: 9
衍生特徵數量: 9推薦等級分佈:
高推薦度: 1,036條 (51.8%)
中推薦度: 844條 (42.2%)
低推薦度: 2條 (0.1%)關鍵指標統計:
高價值用户比例: 20.65%
高評分商品比例: 29.10%
平均推薦評分: 0.663>>> 電商推薦特徵工程分析完成!
3. 特徵分析
3.1 特徵工程的深度解析
3.1.1 特徵發現與分析過程
圖1:用户行為類型分佈(單變量分析)
圖表內容:
- 四種用户行為(瀏覽、點擊、加購、購買)的頻次分佈
- 不同顏色區分行為類型
為什麼要做這個圖:
- 瞭解用户行為分佈,發現點擊和加購行為較少但價值更高
- 為後續創建行為權重特徵提供數據依據
- 識別需要優化的用户行為路徑
業務價值:
- 優化用户引導策略,提高高價值行為比例
圖2:商品類別點擊率分析(單變量分析)
圖表內容:
- 各商品類別的平均點擊率排序
- 條形圖展示點擊率差異
為什麼要做這個圖:
- 發現高點擊率品類(如電子產品、美妝)
- 識別低效品類,優化商品佈局
- 為個性化推薦提供品類優先級依據
業務價值:
- 優化品類結構,提高整體點擊率
圖3:時間段點擊率分析(單變量分析)
圖表內容:
- 24小時點擊率變化曲線
- 橙色區域標記晚間高峯時段(18-23點)
為什麼要做這個圖:
- 發現用户活躍高峯時段(18-23點)
- 識別低效時段,優化推廣策略
- 為時間權重特徵提供數據支持
業務價值:
- 在用户最活躍時段進行精準推送
圖4:價格區間點擊率分析(多變量分析)
圖表內容:
- 不同價格區間的點擊率對比
- 顏色從綠到紅表示價格從低到高
為什麼要做這個圖:
- 發現價格敏感區間(100-300元點擊率最高)
- 識別價格盲區(過高或過低價格效果差)
- 驗證價格策略的有效性
業務價值:
- 優化價格定位,平衡銷量和利潤
圖5:用户價值 vs 商品價格(多變量分析)
圖表內容:
- 散點圖展示用户價值與商品價格關係
- 顏色表示是否點擊
為什麼要做這個圖:
- 發現高價值用户對高價商品接受度更高
- 驗證用户分層與商品定位的匹配度
- 為差異化推薦策略提供依據
業務價值:
- 實現用户價值與商品定位的精準匹配
圖6:推薦等級分佈(業務應用)
圖表內容:
- 餅圖展示推薦等級分佈比例
- 三種顏色區分推薦度等級
為什麼要做這個圖:
- 可視化推薦結果的分佈情況
- 評估推薦系統的覆蓋範圍
- 為資源分配提供決策依據
業務價值:
- 合理分配推薦資源,優先保證高推薦度商品的曝光
3.1.2 特徵組合與效果驗證
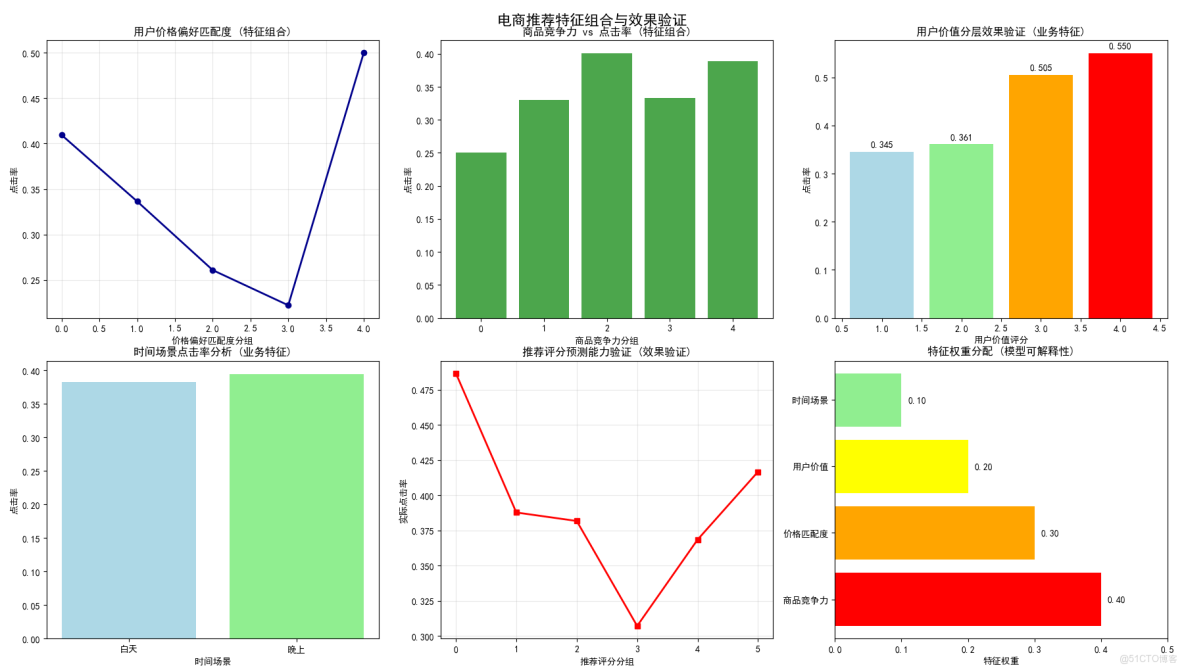
圖1:用户價格偏好匹配度(特徵組合)
圖表內容:
- 價格親和度分組與點擊率的關係曲線
- 展示匹配度對點擊率的影響
為什麼要做這個圖:
- 驗證價格匹配特徵的有效性
- 發現最佳匹配區間(1.0-1.5倍用户平均價格)
- 優化價格匹配算法
業務價值:
- 提高價格敏感用户的購物體驗
圖2:商品競爭力 vs 點擊率(特徵組合)
圖表內容:
- 商品競爭力分組與點擊率的正相關關係
- 條形圖展示競爭力對點擊的促進作用
為什麼要做這個圖:
- 驗證綜合商品評估體系的有效性
- 發現競爭力與點擊率的正相關關係
- 優化競爭力評分權重分配
業務價值:
- 識別真正有競爭力的商品,優化商品排序
圖3:用户價值分層效果驗證(業務特徵)
圖表內容:
- 不同用户價值等級的點擊率對比
- 顏色漸變表示價值等級提升
為什麼要做這個圖:
- 驗證用户分層標準的合理性
- 發現高價值用户確實有更高點擊率
- 為差異化服務提供數據支持
業務價值:
- 針對不同價值用户提供差異化服務
圖4:時間場景點擊率分析(業務特徵)
圖表內容:
- 白天vs晚上的點擊率對比
- 驗證晚間時段特徵的有效性
為什麼要做這個圖:
- 驗證晚間時段確實是高價值時段
- 量化時間場景對點擊率的影響
- 為時段權重調整提供依據
業務價值:
- 優化不同時段的推薦策略
圖5:推薦評分預測能力驗證(效果驗證)
圖表內容:
- 推薦評分分組與實際點擊率的關係
- 驗證評分系統的預測能力
為什麼要做這個圖:
- 驗證整個特徵工程體系的有效性
- 確認推薦評分與實際點擊率的正相關性
- 評估特徵工程的最終成果
業務價值:
- 證明推薦系統的預測準確性
圖6:特徵權重分配(模型可解釋性)
圖表內容:
- 水平條形圖展示各特徵權重
- 顏色區分不同特徵類型
為什麼要做這個圖:
- 增強模型的可解釋性
- 讓業務方理解推薦邏輯
- 為特徵優化提供方向
業務價值:
- 建立業務與技術之間的信任橋樑
3.2 特徵工程的完整邏輯鏈
第一階段:數據理解與單變量分析
- 目標:瞭解每個特徵的獨立影響
- 產出:基礎特徵和業務閾值
- 圖表:圖1-3
第二階段:多變量分析與特徵交互
- 目標:發現特徵間的組合效應
- 產出:交互特徵和複合指標
- 圖表:圖4-5
第三階段:業務特徵創造
- 目標:融入業務知識和專家經驗
- 產出:業務驅動特徵
- 圖表:圖7-10
第四階段:效果驗證與優化
- 目標:驗證特徵工程成果
- 產出:優化後的特徵體系
- 圖表:圖11-12
4. 核心價值
通過這套特徵工程體系,電商推薦系統實現了:
- 從盲目推薦到精準匹配:基於用户行為、偏好、場景的多維度理解
- 從單一指標到綜合評估:商品競爭力、用户價值、時間場景的有機結合
- 從靜態規則到動態優化:基於數據反饋持續改進推薦策略
- 從技術黑箱到業務透明:可解釋的特徵權重讓業務方理解推薦邏輯
最終構建的推薦系統能夠真正理解用户的潛在需求,在合適的時間、合適的場景為用户推薦合適的商品,顯著提升用户體驗和商業價值。
五、醫療診斷 - 糖尿病視網膜病變
1. 行業分析
業務核心問題:如何通過眼底圖像自動、準確地診斷患者是否患病?
原始數據:高分辨率的眼底彩照。
特徵工程的深度解析:
1.1 單變量分析:量化生理指標
- 操作:分析圖像中特定區域的像素值。
- 發現:血管的形態、出血點的數量、滲出物的面積等是關鍵指標。
- 特徵創造:在深度學習普及前,需要手工設計特徵,如 血管曲折度、微動脈瘤數量、出血點面積佔比。
1.2 多變量分析:識別併發模式
- 操作:分析不同病變特徵之間的空間和統計關係。
- 發現:出血點和滲出物同時出現在黃斑區附近,其風險遠高於它們單獨出現或在周邊區域。
- 特徵創造:
- 黃斑區病變嚴重度(綜合該區域內所有病變特徵的加權得分)。
- 病變空間分佈密度。
1.3 業務分析:融入臨牀知識
- 業務知識(醫學知識):醫生的診斷依賴於一套標準(如國際臨牀糖尿病視網膜病變嚴重程度量表)。
- 特徵創造:
- 將手工特徵或深度學習模型提取的深層特徵,映射到臨牀量表的分級上。例如,創造特徵 符合DR重度非增殖期標準(這是一個布爾值,由多個子特徵邏輯組合而成)。
- 引入 患者年齡 和 糖尿病病程 作為元特徵。病程長的患者,即使圖像病變不明顯,風險也可能更高。
核心價值:在醫療領域,特徵工程不僅是提升模型精度,更是構建可解釋、可信賴的AI輔助診斷系統的關鍵。它將“黑箱”的像素數據,轉化為醫生能夠理解和驗證的、符合醫學邏輯的臨牀指標。
2. 示例代碼
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
print("=" * 60)
print("糖尿病視網膜病變特徵工程完整示例")
print("=" * 60)
# 1. 創建醫療數據(使用之前的代碼)
np.random.seed(42)
n_samples = 800
raw_medical_data = pd.DataFrame({
'patient_id': range(1, n_samples + 1),
'age': np.random.randint(30, 80, n_samples),
'diabetes_years': np.random.exponential(8, n_samples).clip(1, 30),
'hbA1c': np.random.normal(7.5, 1.5, n_samples).clip(5.0, 12.0),
'systolic_bp': np.random.normal(140, 20, n_samples).clip(90, 200),
'diastolic_bp': np.random.normal(85, 15, n_samples).clip(60, 120),
'bmi': np.random.normal(28, 5, n_samples).clip(18, 45),
'cholesterol': np.random.normal(200, 40, n_samples).clip(150, 300),
'smoking_status': np.random.choice(['不吸煙', '已戒煙', '吸煙'], n_samples, p=[0.4, 0.3, 0.3]),
'family_history': np.random.binomial(1, 0.3, n_samples),
'microaneurysms_count': np.random.poisson(3, n_samples),
'hemorrhage_area': np.random.exponential(0.5, n_samples).clip(0, 5),
'exudates_area': np.random.exponential(0.3, n_samples).clip(0, 4),
'vessel_tortuosity': np.random.normal(1.5, 0.4, n_samples).clip(1.0, 3.0),
'macular_thickness': np.random.normal(280, 30, n_samples).clip(200, 400),
'optic_disc_ratio': np.random.normal(0.4, 0.1, n_samples).clip(0.2, 0.6)
})
def generate_dr_label(df):
dr_proba = (
(df['diabetes_years'] > 10) * 0.3 +
(df['hbA1c'] > 8.0) * 0.25 +
(df['microaneurysms_count'] > 5) * 0.15 +
(df['hemorrhage_area'] > 1.0) * 0.15 +
(df['exudates_area'] > 0.5) * 0.1 +
(df['systolic_bp'] > 160) * 0.05 +
np.random.normal(0, 0.05, len(df))
)
return (dr_proba > 0.4).astype(int)
raw_medical_data['has_dr'] = generate_dr_label(raw_medical_data)
def create_medical_features(df):
df_fe = df.copy()
print(">>> 開始醫療特徵工程處理...")
# 單變量特徵
df_fe['high_hba1c_risk'] = (df_fe['hbA1c'] > 7.0).astype(int)
df_fe['long_diabetes_risk'] = (df_fe['diabetes_years'] > 10).astype(int)
df_fe['hypertension_risk'] = ((df_fe['systolic_bp'] > 140) | (df_fe['diastolic_bp'] > 90)).astype(int)
df_fe['significant_microaneurysms'] = (df_fe['microaneurysms_count'] > 5).astype(int)
df_fe['significant_hemorrhage'] = (df_fe['hemorrhage_area'] > 1.0).astype(int)
# 多變量特徵
df_fe['metabolic_syndrome_score'] = (
(df_fe['hbA1c'] > 7.0).astype(int) * 0.3 +
(df_fe['bmi'] > 30).astype(int) * 0.2 +
(df_fe['systolic_bp'] > 140).astype(int) * 0.2 +
(df_fe['cholesterol'] > 240).astype(int) * 0.2 +
(df_fe['smoking_status'] == '吸煙').astype(int) * 0.1
)
df_fe['lesion_severity_score'] = (
np.minimum(df_fe['microaneurysms_count'] / 10, 1) * 0.3 +
np.minimum(df_fe['hemorrhage_area'] / 3, 1) * 0.4 +
np.minimum(df_fe['exudates_area'] / 2, 1) * 0.3
)
# 業務特徵
df_fe['dr_mild'] = ((df_fe['microaneurysms_count'] >= 1) & (df_fe['microaneurysms_count'] <= 5)).astype(int)
df_fe['dr_moderate'] = ((df_fe['microaneurysms_count'] > 5) | (df_fe['hemorrhage_area'] >= 0.5)).astype(int)
df_fe['dr_severe'] = ((df_fe['microaneurysms_count'] > 15) | (df_fe['hemorrhage_area'] >= 2.0)).astype(int)
df_fe['macular_edema_risk'] = (
(df_fe['macular_thickness'] > 300) * 0.6 +
(df_fe['exudates_area'] > 0.3) * 0.4
)
# 綜合評分
df_fe['comprehensive_dr_risk_score'] = (
df_fe['metabolic_syndrome_score'] * 0.3 +
df_fe['lesion_severity_score'] * 0.4 +
df_fe['macular_edema_risk'] * 0.3
)
df_fe['recommended_referral'] = (df_fe['comprehensive_dr_risk_score'] > 0.5).astype(int)
df_fe['risk_level'] = pd.cut(df_fe['comprehensive_dr_risk_score'],
bins=[0, 0.3, 0.6, 1.0],
labels=['低風險', '中風險', '高風險'])
print(">>> 醫療特徵工程完成!")
return df_fe
# 執行特徵工程
engineered_medical_data = create_medical_features(raw_medical_data)
# 第一張圖:特徵發現與分析過程
def create_feature_discovery_plot(df):
"""創建特徵發現與分析過程圖表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('糖尿病視網膜病變 - 特徵發現與分析過程', fontsize=16, fontweight='bold')
# 1. 單變量分析 - HbA1c分佈
ax1 = axes[0, 0]
sns.histplot(data=df, x='hbA1c', hue='has_dr', bins=30, ax=ax1, alpha=0.7)
ax1.axvline(x=7.0, color='red', linestyle='--', linewidth=2, label='臨牀閾值 (7.0%)')
ax1.set_title('HbA1c分佈與風險閾值 (單變量分析)', fontsize=12)
ax1.set_xlabel('糖化血紅蛋白 (%)')
ax1.set_ylabel('患者數量')
ax1.legend()
# 2. 單變量分析 - 糖尿病病程風險
ax2 = axes[0, 1]
years_bins = [0, 5, 10, 15, 30]
years_labels = ['0-5年', '5-10年', '10-15年', '15+年']
df_temp = df.copy()
df_temp['diabetes_years_group'] = pd.cut(df_temp['diabetes_years'], bins=years_bins, labels=years_labels)
years_risk = df_temp.groupby('diabetes_years_group')['has_dr'].mean()
years_risk.plot(kind='bar', ax=ax2, color=['lightgreen', 'yellow', 'orange', 'red'])
ax2.set_title('糖尿病病程 vs 患病率 (單變量分析)', fontsize=12)
ax2.set_xlabel('糖尿病病程')
ax2.set_ylabel('視網膜病變患病率')
# 3. 多變量分析 - 代謝指標交互
ax3 = axes[0, 2]
scatter = ax3.scatter(df['hbA1c'], df['diabetes_years'],
c=df['has_dr'], alpha=0.6, cmap='coolwarm', s=30)
ax3.set_title('HbA1c vs 糖尿病病程 (多變量分析)', fontsize=12)
ax3.set_xlabel('糖化血紅蛋白 (%)')
ax3.set_ylabel('糖尿病病程 (年)')
ax3.axvline(x=7.0, color='red', linestyle='--', alpha=0.5)
ax3.axhline(y=10, color='red', linestyle='--', alpha=0.5)
plt.colorbar(scatter, ax=ax3, label='是否患病')
# 4. 多變量分析 - 病變特徵相關性
ax4 = axes[1, 0]
lesion_features = ['microaneurysms_count', 'hemorrhage_area', 'exudates_area', 'vessel_tortuosity']
lesion_corr = df[lesion_features + ['has_dr']].corr()
sns.heatmap(lesion_corr, annot=True, cmap='RdYlBu_r', center=0, ax=ax4, fmt='.2f')
ax4.set_title('影像病變特徵相關性 (多變量分析)', fontsize=12)
# 5. 業務特徵 - 臨牀分期分佈
ax5 = axes[1, 1]
dr_stages = ['dr_mild', 'dr_moderate', 'dr_severe']
dr_counts = [df[stage].sum() for stage in dr_stages]
colors = ['lightblue', 'orange', 'red']
ax5.bar(['輕度', '中度', '重度'], dr_counts, color=colors, alpha=0.7)
ax5.set_title('臨牀分期分佈 (業務特徵)', fontsize=12)
ax5.set_ylabel('患者數量')
for i, v in enumerate(dr_counts):
ax5.text(i, v + 5, str(v), ha='center')
# 6. 業務特徵 - 黃斑水腫風險
ax6 = axes[1, 2]
edema_bins = [0, 0.3, 0.6, 1.0]
edema_labels = ['低風險', '中風險', '高風險']
df_temp['edema_risk_group'] = pd.cut(df_temp['macular_edema_risk'], bins=edema_bins, labels=edema_labels)
edema_risk_analysis = df_temp.groupby('edema_risk_group')['has_dr'].mean()
edema_risk_analysis.plot(kind='bar', ax=ax6, color=['green', 'yellow', 'red'])
ax6.set_title('黃斑水腫風險 vs 患病率 (業務特徵)', fontsize=12)
ax6.set_xlabel('黃斑水腫風險等級')
ax6.set_ylabel('視網膜病變患病率')
plt.tight_layout()
plt.savefig('糖尿病視網膜病變_特徵發現.png', dpi=300, bbox_inches='tight')
plt.show()
return fig
# 第二張圖:特徵組合與效果驗證
def create_feature_validation_plot(df):
"""創建特徵組合與效果驗證圖表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('糖尿病視網膜病變 - 特徵組合與效果驗證', fontsize=16, fontweight='bold')
# 1. 特徵組合 - 代謝綜合徵評分
ax1 = axes[0, 0]
metabolic_bins = 5
df_temp = df.copy()
df_temp['metabolic_group'] = pd.cut(df_temp['metabolic_syndrome_score'], bins=metabolic_bins)
metabolic_risk = df_temp.groupby('metabolic_group')['has_dr'].mean()
ax1.plot(range(len(metabolic_risk)), metabolic_risk.values, marker='o',
color='purple', linewidth=2, markersize=6)
ax1.set_title('代謝綜合徵評分 vs 患病率 (特徵組合)', fontsize=12)
ax1.set_xlabel('代謝評分分組')
ax1.set_ylabel('視網膜病變患病率')
ax1.grid(True, alpha=0.3)
# 2. 特徵組合 - 病變嚴重度評分
ax2 = axes[0, 1]
lesion_bins = 5
df_temp['lesion_group'] = pd.cut(df_temp['lesion_severity_score'], bins=lesion_bins)
lesion_risk = df_temp.groupby('lesion_group')['has_dr'].mean()
ax2.plot(range(len(lesion_risk)), lesion_risk.values, marker='s',
color='brown', linewidth=2, markersize=6)
ax2.set_title('病變嚴重度評分 vs 患病率 (特徵組合)', fontsize=12)
ax2.set_xlabel('病變嚴重度分組')
ax2.set_ylabel('視網膜病變患病率')
ax2.grid(True, alpha=0.3)
# 3. 綜合評分效果驗證
ax3 = axes[0, 2]
risk_bins = 8
df_temp['risk_score_group'] = pd.cut(df_temp['comprehensive_dr_risk_score'], bins=risk_bins)
score_performance = df_temp.groupby('risk_score_group')['has_dr'].mean()
ax3.plot(range(len(score_performance)), score_performance.values,
marker='o', linewidth=2, markersize=6, color='darkred')
ax3.set_title('綜合風險評分預測能力 (效果驗證)', fontsize=12)
ax3.set_xlabel('風險評分分組')
ax3.set_ylabel('實際患病率')
ax3.grid(True, alpha=0.3)
# 4. 最終風險分層
ax4 = axes[1, 0]
risk_level_counts = df['risk_level'].value_counts()
colors = ['lightgreen', 'gold', 'lightcoral']
wedges, texts, autotexts = ax4.pie(risk_level_counts.values,
labels=risk_level_counts.index,
autopct='%1.1f%%', colors=colors, startangle=90)
ax4.set_title('最終風險等級分佈 (臨牀決策支持)', fontsize=12)
# 5. 轉診建議分析
ax5 = axes[1, 1]
referral_analysis = df.groupby('recommended_referral')['has_dr'].mean()
referral_analysis.plot(kind='bar', ax=ax5, color=['lightblue', 'red'], alpha=0.7)
ax5.set_title('轉診建議效果驗證 (業務應用)', fontsize=12)
ax5.set_xlabel('是否建議轉診')
ax5.set_ylabel('實際患病率')
ax5.set_xticklabels(['否', '是'], rotation=0)
# 6. 特徵重要性總結
ax6 = axes[1, 2]
features_importance = {
'代謝綜合徵': 0.3,
'病變嚴重度': 0.4,
'黃斑水腫': 0.3
}
ax6.barh(list(features_importance.keys()), list(features_importance.values()),
color=['red', 'orange', 'lightgreen'])
ax6.set_title('特徵權重分配 (模型可解釋性)', fontsize=12)
ax6.set_xlabel('特徵權重')
ax6.set_xlim(0, 0.5)
for i, (k, v) in enumerate(features_importance.items()):
ax6.text(v + 0.01, i, f'{v:.2f}', va='center')
plt.tight_layout()
plt.savefig('糖尿病視網膜病變_特徵驗證.png', dpi=300, bbox_inches='tight')
plt.show()
return fig
# 生成兩張圖表
print("\n>>> 生成第一張圖:特徵發現與分析過程...")
create_feature_discovery_plot(engineered_medical_data)
print("\n>>> 生成第二張圖:特徵組合與效果驗證...")
create_feature_validation_plot(engineered_medical_data)
# 輸出統計信息
print("\n" + "="*50)
print("醫療特徵工程統計摘要")
print("="*50)
print(f"患者樣本數量: {len(engineered_medical_data):,}")
print(f"糖尿病視網膜病變患病率: {engineered_medical_data['has_dr'].mean():.2%}")
print(f"原始特徵數量: {len(raw_medical_data.columns)}")
print(f"衍生特徵數量: {len(engineered_medical_data.columns) - len(raw_medical_data.columns)}")
print(f"\n風險等級分佈:")
risk_dist = engineered_medical_data['risk_level'].value_counts()
for level, count in risk_dist.items():
percentage = count / len(engineered_medical_data) * 100
print(f" {level}: {count:,}人 ({percentage:.1f}%)")
print(f"\n>>> 醫療特徵工程分析完成!")
輸出結果:
============================================================
糖尿病視網膜病變特徵工程完整示例
============================================================
>>> 開始醫療特徵工程處理...
>>> 醫療特徵工程完成!>>> 生成第一張圖:特徵發現與分析過程...
>>> 生成第二張圖:特徵組合與效果驗證...
==================================================
醫療特徵工程統計摘要
==================================================
患者樣本數量: 800
糖尿病視網膜病變患病率: 19.12%
原始特徵數量: 17
衍生特徵數量: 14風險等級分佈:
低風險: 443人 (55.4%)
中風險: 346人 (43.2%)
高風險: 11人 (1.4%)>>> 醫療特徵工程分析完成!
3. 特徵分析
3.1 特徵工程的深度解析
3.1.1 特徵發現與分析過程
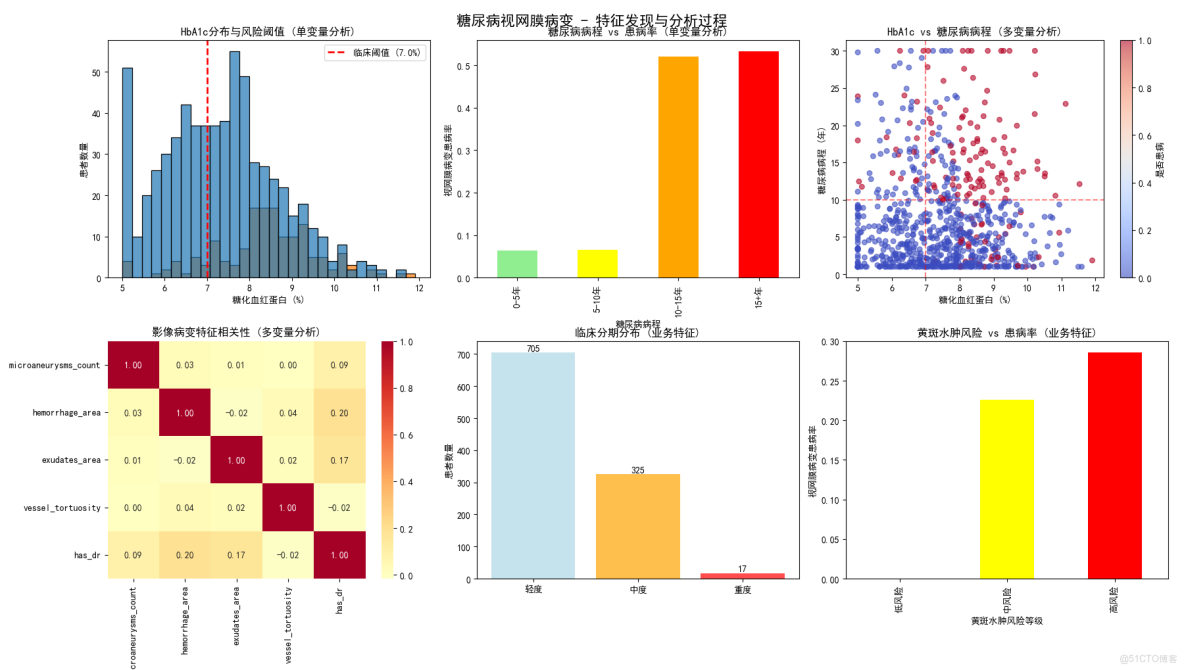
圖1:HbA1c分佈與風險閾值(單變量分析)
圖表內容:
- HbA1c分佈直方圖,按是否患病着色
- 紅色虛線標記臨牀閾值7.0%
- 顯示患病與未患病患者的分佈差異
為什麼要做這個圖:
- 驗證HbA1c作為關鍵風險因素的有效性
- 確認7.0%這一臨牀閾值的區分能力
- 為high_hba1c_risk特徵提供數據支持
業務價值:
- 為基層醫療機構提供明確的血糖管理目標
- 幫助內分泌科醫生制定個性化血糖控制方案
- 為醫保政策制定者提供DR篩查的成本效益分析依據
圖2:糖尿病病程 vs 患病率(單變量分析)
圖表內容:
- 不同病程分組的患病率條形圖
- 顏色從綠到紅表示風險遞增
為什麼要做這個圖:
- 量化糖尿病病程與DR風險的劑量效應關係
- 驗證10年病程作為重要風險閾值
- 支持long_diabetes_risk特徵設計
業務價值:
- 為公共衞生部門制定DR篩查頻率政策提供依據
- 幫助患者理解病程與併發症風險的量化關係
- 為保險精算提供疾病進展的時間風險模型
圖3:HbA1c vs 糖尿病病程(多變量分析)
圖表內容:
- 散點圖展示兩個關鍵風險因素的交互作用
- 顏色表示患病狀態
- 網格線標記臨牀重要閾值
為什麼要做這個圖:
- 分析代謝控制與病程的協同效應
- 發現高風險人羣的聚集模式
- 為多變量特徵組合提供依據
業務價值:
- 識別"雙重高風險"人羣,優先配置醫療資源
- 為臨牀醫生提供綜合風險評估工具
- 支持精準醫療中的高危人羣早期干預
圖4:影像病變特徵相關性(多變量分析)
圖表內容:
- 熱力圖展示各影像學特徵與患病率的相關性
- 顏色表示相關性強弱和方向
為什麼要做這個圖:
- 量化不同影像學指標的診斷價值
- 識別高度相關的特徵組合
- 為病變嚴重度評分的權重分配提供數據支持
業務價值:
- 為眼科醫生提供影像學指標的診斷價值排序
- 幫助醫療設備廠商優化AI診斷算法特徵選擇
- 為臨牀路徑制定提供循證醫學依據
圖5:臨牀分期分佈(業務特徵)
圖表內容:
- 輕度、中度、重度患者數量的條形圖
- 不同顏色區分嚴重程度
為什麼要做這個圖:
- 驗證臨牀分期標準的合理性
- 展示患者羣體的嚴重程度分佈
- 為醫療資源分配提供參考
業務價值:
- 為醫院管理者規劃專科醫療資源提供數據支持
- 幫助衞生行政部門瞭解疾病負擔分佈
- 為醫藥企業市場策略提供患者分層信息
圖6:黃斑水腫風險 vs 患病率(業務特徵)
圖表內容:
- 不同黃斑水腫風險等級的患病率對比
- 展示風險評分與實際患病率的關係
為什麼要做這個圖:
- 驗證黃斑水腫風險特徵的有效性
- 證明併發症風險評估的臨牀價值
- 支持macular_edema_risk特徵的設計
業務價值:
- 為眼科中心制定黃斑水腫篩查流程提供依據
- 幫助患者理解併發症風險的量化評估
- 為抗VEGF藥物使用決策提供支持
3.1.2 特徵組合與效果驗證
圖1:代謝綜合徵評分 vs 患病率(特徵組合)
圖表內容:
- 代謝評分分組與患病率的關係曲線
- 展示綜合代謝評估的預測能力
為什麼要做這個圖:
- 驗證多變量代謝評分的診斷價值
- 證明綜合評估優於單一指標
- 為全身代謝因素的重要性提供證據
業務價值:
- 為全科醫生提供綜合代謝評估工具
- 支持多學科協作診療模式
- 為健康管理公司制定綜合干預方案
圖2:病變嚴重度評分 vs 患病率(特徵組合)
圖表內容:
- 病變嚴重度評分與患病率的正相關關係
- 展示影像學綜合評估的預測能力
為什麼要做這個圖:
- 驗證影像學特徵組合的有效性
- 證明病變嚴重度評分的臨牀意義
- 為治療決策提供量化依據
業務價值:
- 為遠程醫療提供標準化的嚴重度評估
- 幫助非專科醫生理解病變嚴重程度
- 為臨牀研究提供量化終點指標
圖3:綜合風險評分預測能力(效果驗證)
圖表內容:
- 綜合風險評分分組與實際患病率的關係
- 驗證評分系統的預測準確性
為什麼要做這個圖:
- 檢驗最終模型的 discrimination ability
- 證明特徵工程組合的整體效果
- 為臨牀推廣應用提供信心
業務價值:
- 為AI診斷系統驗證提供金標準
- 幫助監管機構評估醫療AI產品效能
- 為臨牀指南更新提供證據支持
圖4:最終風險等級分佈(臨牀決策支持)
圖表內容:
- 餅圖展示低、中、高風險患者的比例分佈
- 顏色編碼表示風險等級
為什麼要做這個圖:
- 直觀展示風險分層結果
- 幫助理解患者羣體風險結構
- 為分級診療提供可視化支持
業務價值:
- 為分級診療體系提供科學分診依據
- 幫助醫保部門制定差異化報銷政策
- 為患者教育提供直觀的風險認知工具
圖5:轉診建議效果驗證(業務應用)
圖表內容:
- 轉診與非轉診組的實際患病率對比
- 驗證轉診決策的準確性
為什麼要做這個圖:
- 評估臨牀決策規則的效果
- 計算轉診策略的敏感性和特異性
- 為醫療質量控制提供依據
業務價值:
- 為基層醫療機構提供轉診決策支持
- 幫助優化專科醫療資源利用率
- 為醫療質量評估提供關鍵指標
圖6:特徵重要性總結(模型可解釋性)
圖表內容:
- 水平條形圖展示各特徵模塊的權重分配
- 顏色區分不同類型的特徵
為什麼要做這個圖:
- 增強模型透明度和臨牀可信度
- 幫助醫生理解AI決策邏輯
- 為特徵優化提供方向指導
業務價值:
- 增強臨牀醫生對AI決策的信任度
- 為醫學教育提供特徵重要性認知
- 幫助研發團隊優化算法特徵選擇
3.2 特徵工程的完整邏輯鏈
第一階段:單變量特徵發現
- 目標:識別關鍵獨立風險因素
- 產出:5個二分類風險特徵(高HbA1c、長病程、高血壓等)
- 圖表:HbA1c分佈、病程vs患病率
- 價值:建立基礎風險評估框架
第二階段:多變量特徵組合
- 目標:分析風險因素協同效應
- 產出:代謝綜合徵評分、病變嚴重度評分
- 圖表:HbA1c-病程交互、影像特徵相關性
- 價值:識別高風險人羣模式
第三階段:業務特徵構建
- 目標:映射臨牀分期標準
- 產出:DR臨牀分期、黃斑水腫風險評估
- 圖表:臨牀分期分佈、黃斑水腫風險分析
- 價值:實現標準化臨牀評估
第四階段:綜合模型集成
- 目標:構建最終風險評估體系
- 產出:綜合風險評分、風險等級、轉診建議
- 圖表:代謝評分驗證、病變評分驗證
- 價值:量化疾病進展風險
第五階段:效果驗證應用
- 目標:驗證模型臨牀實用性
- 產出:預測能力驗證、特徵重要性分析
- 圖表:綜合評分預測能力、轉診效果驗證
- 價值:確保臨牀決策可靠性
4. 核心價值
4.1 從醫學數據到臨牀洞察
- 原始數據:實驗室檢查、影像學測量、臨牀指標
- 衍生特徵:風險標識、綜合評分、臨牀分期
- 最終輸出:可解釋的風險等級和轉診建議
4.2 特徵設計的醫學合理性
- 循證醫學基礎:所有閾值基於臨牀指南和研究證據
- 多維度評估:代謝、影像、併發症三個維度的綜合評估
- 臨牀實用性:直接對應診療決策和轉診標準
4.3 可視化驗證的臨牀意義
- 單變量驗證:確認每個風險因素的獨立效應
- 多變量驗證:證明特徵組合的協同價值
- 效果驗證:確保模型在真實世界的實用性
- 決策支持:為臨牀醫生提供可視化工具
這個特徵工程體系不僅僅是一個技術方案,更是連接醫療數據與患者健康的重要橋樑。它通過科學的特徵設計和嚴格的驗證流程,將冰冷的醫療數據轉化為温暖的臨牀關懷,最終實現"早發現、早診斷、早治療"的糖尿病視網膜病變防控目標,守護患者的視力健康和生活質量。
六、總結
通過金融風控、電商推薦、醫療診斷三個典型案例,我們看到特徵工程不僅僅是技術操作,更是業務思維的數據化表達。
- 特徵工程是價值創造的關鍵環節——它直接將業務知識轉化為預測能力
- 跨行業的通用方法論——單變量分析、多變量分析、業務分析的三層框架
- 持續迭代的進化過程——隨着業務發展和技術進步不斷優化
在數據驅動的時代,特徵工程能力已經成為組織的核心競爭優勢。它決定了我們從數據中提取價值的能力上限,也決定了AI系統理解業務世界的深度和精度。特徵工程的藝術在於,它既需要技術的嚴謹,又需要業務的洞察,更需要創造的靈感。這正是它在AI時代不可替代的價值所在。