
一、前言
前面的文章我們詳細講過,大型語言模型雖在自然語言處理領域展現卓越能力,但仍面臨幻覺問題、知識時效性不足及領域專業性缺失的問題,結合RAG通過“檢索外部知識+增強模型生成”的範式,作為大模型的“外置知識庫”有效緩解上述痛點,無需重新訓練即可動態整合最新領域知識,顯著提升回答準確性與可信度。
然而,傳統 RAG 系統在處理大規模知識庫時存在顯著侷限:全局檢索模式易受噪聲干擾,高維嵌入導致存儲與延遲的可擴展性瓶頸,且上下文輸入中冗餘信息佔比高,造成計算資源浪費。
KMeans++ 聚類算法通過優化初始中心選擇策略,提升了傳統 K-means 的穩定性,能夠將高維文本嵌入按語義相似性劃分為獨立分區,實現“先聚類後檢索”的二級優化架構,可以有效解決傳統 RAG 的檢索效率與準確性瓶頸。

二、KMeans++算法原理
傳統 KMeans 算法在實際應用中存在三大核心侷限:需預先確定簇數、對噪聲數據敏感,以及聚類結果嚴重依賴簇中心初始位置。其中初始中心選擇的隨機性可能導致聚類質量顯著波動——在相同數據集上,不同隨機初始點可能產生差異較大的簇劃分結果,甚至陷入局部最優解。這種不穩定性在高維數據場景(如文本向量聚類)中尤為突出,直接影響後續任務的可靠性。
為解決這一問題,KMeans++ 算法通過改進初始簇中心的選擇策略,使聚類過程更可能收斂至全局較優解。其核心創新在於基於距離加權的概率採樣機制,即離已選中心越遠的樣本點被選為下一個中心的概率越高。
前一篇文章我們已經詳細講機過了KMeans,今天我們通過示例強化一下Kmeans++的運行邏輯,這個示例實現了 K-Means++ 聚類算法的完整可視化過程,包括初始化階段和聚類迭代階段,先看看示例的重點部分,附錄中附上完整代碼:
1. 示例代碼
1.1 初始設置和導入庫
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib.colors as mcolors
import os
import imageio
# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
- 導入必要的庫:NumPy 用於數值計算,Matplotlib 用於可視化,imageio 用於生成 GIF
- 設置中文字體支持
1.2 創建輸出目錄
if not os.path.exists('kmeans_frames'):
os.makedirs('kmeans_frames')
- 創建目錄用於保存每一幀的圖片
1.3 生成示例數據
np.random.seed(42)
n_samples = 100
n_clusters = 4
# 生成四個高斯分佈的數據點
X1 = np.random.normal([2, 2], 0.5, [n_samples//4, 2])
X2 = np.random.normal([-2, 2], 0.5, [n_samples//4, 2])
X3 = np.random.normal([-2, -2], 0.5, [n_samples//4, 2])
X4 = np.random.normal([2, -2], 0.5, [n_samples//4, 2])
X = np.vstack([X1, X2, X3, X4])
- 設置隨機種子確保結果可重現
- 生成四個高斯分佈的數據集,每個包含 25 個點
- 將這些數據集合併成一個 100×2 的矩陣
1.4 初始化圖形界面
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
fig.suptitle('K-Means++ 算法原理動態演示', fontsize=16)
# 左圖:K-Means++ 初始化過程
ax1.set_xlim(-4, 4)
ax1.set_ylim(-4, 4)
ax1.set_title('K-Means++ 初始化過程')
ax1.grid(True, linestyle='--', alpha=0.7)
# 右圖:K-Means 聚類過程
ax2.set_xlim(-4, 4)
ax2.set_ylim(-4, 4)
ax2.set_title('K-Means 聚類過程')
ax2.grid(True, linestyle='--', alpha=0.7)
- 創建包含兩個子圖的圖形界面
- 左圖用於顯示 K-Means++ 初始化過程
- 右圖用於顯示 K-Means 聚類過程
1.5 初始化變量和顏色設置
# 繪製初始數據點
scatter1 = ax1.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7)
scatter2 = ax2.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7)
# 初始化變量
centers = []
probabilities = np.ones(len(X)) / len(X) # 初始概率均勻分佈
current_center_idx = None
distance_text = ax1.text(0.02, 0.98, "", transform=ax1.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
info_text = ax2.text(0.02, 0.98, "", transform=ax2.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
# 顏色映射
colors = list(mcolors.TABLEAU_COLORS.values())
cluster_colors = colors[:n_clusters] # 為每個簇分配一個顏色
# 存儲中心點軌跡
center_trajectories = [[] for _ in range(n_clusters)]
# K-Means 聚類變量
labels = None
iteration = 0
max_iterations = 10
# 存儲所有幀
frames = []
- 初始化散點圖對象、中心點列表、概率分佈等變量
- 設置顏色映射,為每個簇分配不同顏色
- 創建列表用於存儲中心點軌跡
- 初始化 K-Means 聚類相關變量
1.6 初始化函數
def init():
"""初始化動畫"""
scatter1.set_offsets(X)
scatter2.set_offsets(X)
distance_text.set_text("")
info_text.set_text("準備開始 K-Means++ 初始化...")
return scatter1, scatter2, distance_text, info_text
- 設置初始狀態:數據點位置、文本信息等
1.7 K-Means++ 初始化步驟函數
def kmeans_plus_plus_init_step(i):
"""K-Means++ 初始化步驟"""
global centers, current_center_idx, probabilities
if i == 0:
# 第一步:隨機選擇第一個中心點
# ...(詳細代碼)
elif i == 1 and len(centers) < n_clusters:
# 第二步:計算距離並顯示
# ...(詳細代碼)
elif i == 2 and len(centers) < n_clusters:
# 第三步:選擇下一個中心點
# ...(詳細代碼)
elif i >= 3 and len(centers) < n_clusters:
# 重複步驟2-3直到選擇足夠的中心點
# ...(詳細代碼)
elif len(centers) == n_clusters:
# 初始化完成,開始 K-Means 聚類
# ...(詳細代碼)
return scatter1, scatter2, distance_text, info_text
- 實現 K-Means++ 初始化算法的各個步驟
- 根據當前步驟 i 執行不同的操作
- 顯示概率分佈、選擇中心點、更新顯示等
1.8 K-Means 聚類步驟函數
def kmeans_step(i):
"""K-Means 聚類步驟"""
global centers, labels, iteration, cluster_colors, center_trajectories
if len(centers) < n_clusters:
return scatter1, scatter2, distance_text, info_text
# 確保centers是NumPy數組
centers_array = np.array(centers)
# 第一次迭代
if iteration == 0:
# 分配步驟:將每個點分配到最近的中心點
# ...(詳細代碼)
elif iteration < max_iterations:
if iteration % 2 == 1: # 更新步驟:重新計算中心點
# ...(詳細代碼)
else: # 分配步驟:重新分配點
# ...(詳細代碼)
else:
info_text.set_text("K-Means 算法已收斂!\n聚類完成")
# 繪製中心點軌跡
for j in range(n_clusters):
if len(center_trajectories[j]) > 1:
trajectory = np.array(center_trajectories[j])
ax2.plot(trajectory[:, 0], trajectory[:, 1], '--', color=cluster_colors[j], alpha=0.7)
return scatter1, scatter2, distance_text, info_text
- 實現 K-Means 聚類算法的迭代過程
- 交替執行分配步驟(將點分配到最近的中心)和更新步驟(重新計算中心位置)
- 繪製中心點的移動軌跡
1.9 更新函數
def update(i):
"""更新函數"""
if i < 12: # 前12幀用於K-Means++初始化
return kmeans_plus_plus_init_step(i)
else: # 後續幀用於K-Means聚類
return kmeans_step(i - 12)
- 根據當前幀數決定調用哪個函數
- 前 12 幀用於 K-Means++ 初始化,後續幀用於 K-Means 聚類
1.10 主循環和步驟圖生成
# 創建動畫並保存每一幀
for i in range(25):
# 清除右圖中的軌跡線,但保留中心點
if i >= 12:
# 清除之前的軌跡線
for line in ax2.get_lines():
line.remove()
# 更新動畫
update(i)
# 保存當前幀
frame_path = f'kmeans_frames/frame_{i:02d}.png'
plt.savefig(frame_path, dpi=100, bbox_inches='tight')
frames.append(imageio.imread(frame_path))
print(f'已保存第 {i+1}/25 幀')
plt.tight_layout()
plt.show()
- 循環 25 次,每次更新動畫狀態
- 清除之前的軌跡線(僅對 K-Means 階段)
- 保存當前幀為 PNG 圖片
- 顯示最終結果
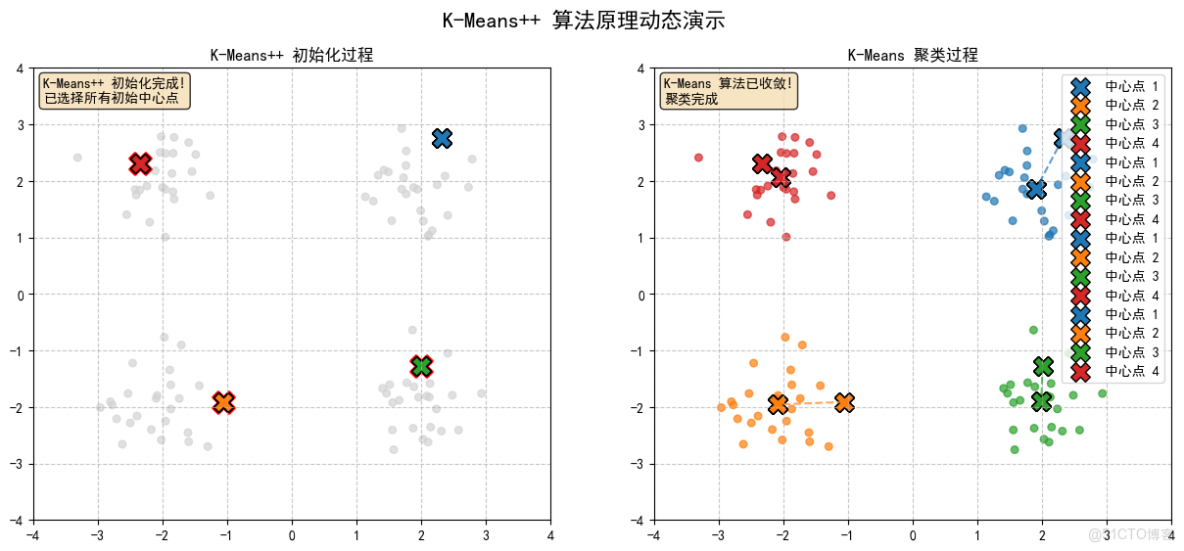
2. 輸出結果
- 左圖顯示 K-Means++ 初始化過程,使用顏色深淺表示概率大小
- 右圖顯示 K-Means 聚類過程,使用不同顏色區分簇,虛線顯示中心點移動軌跡
- 文本區域顯示當前步驟的説明信息
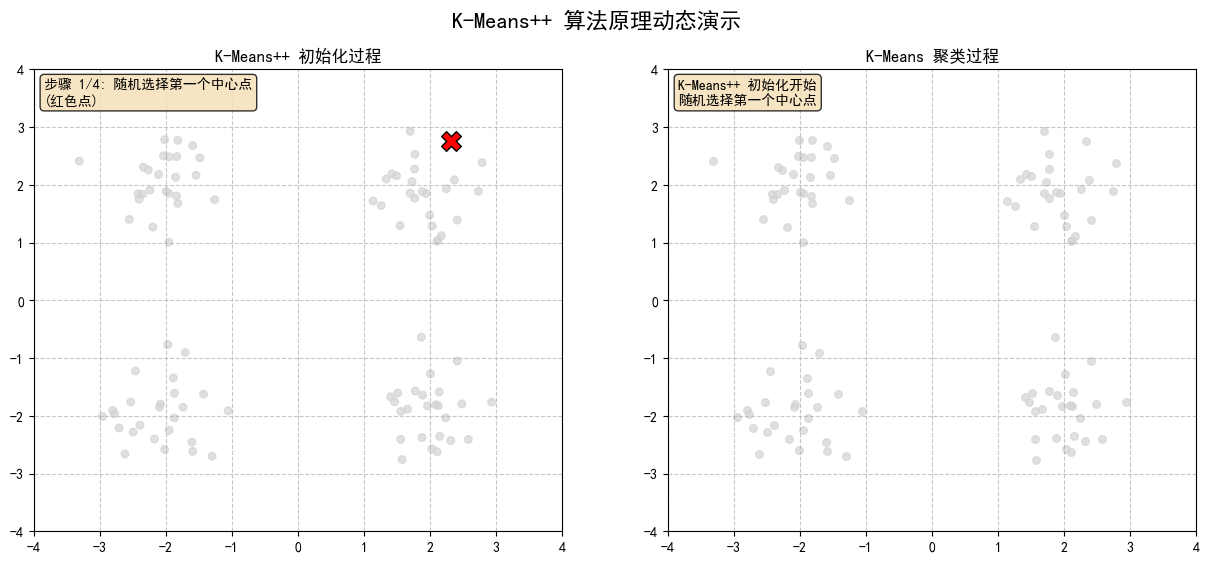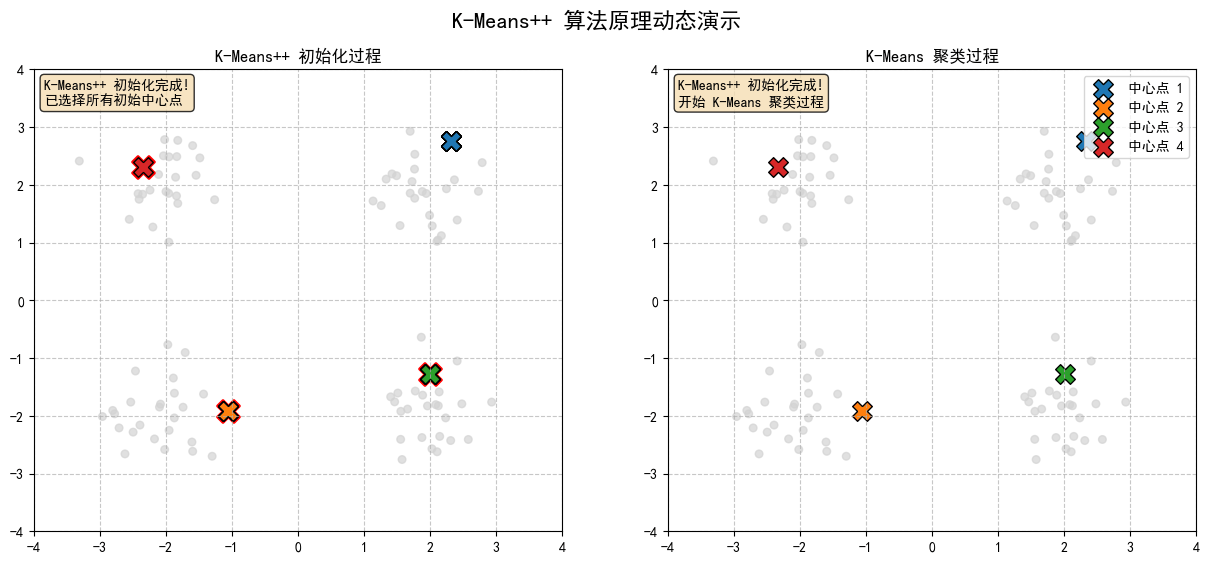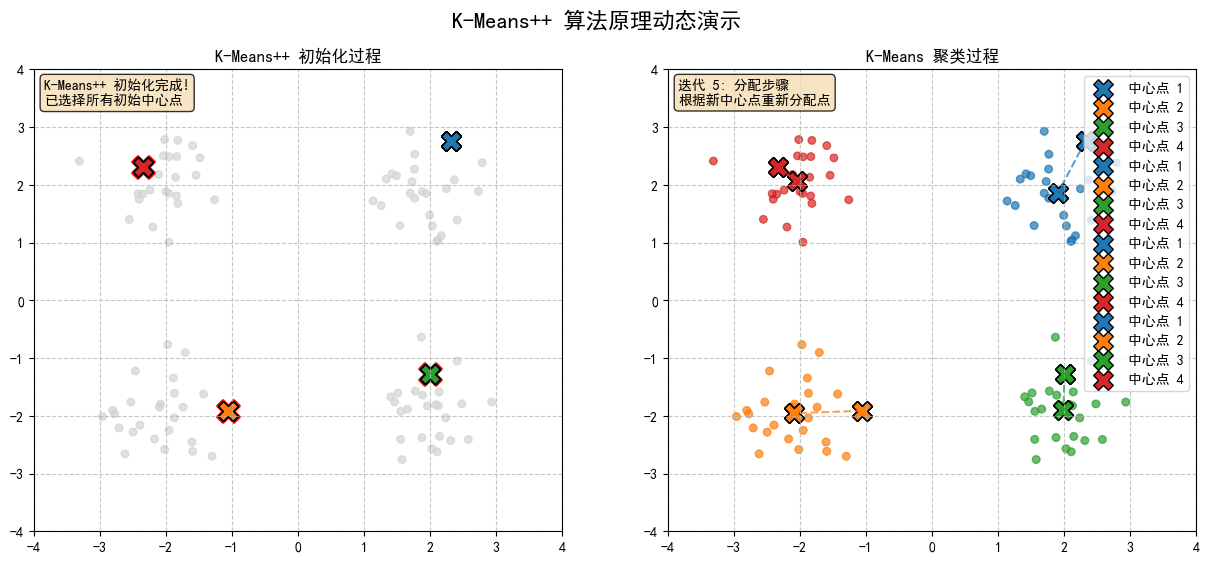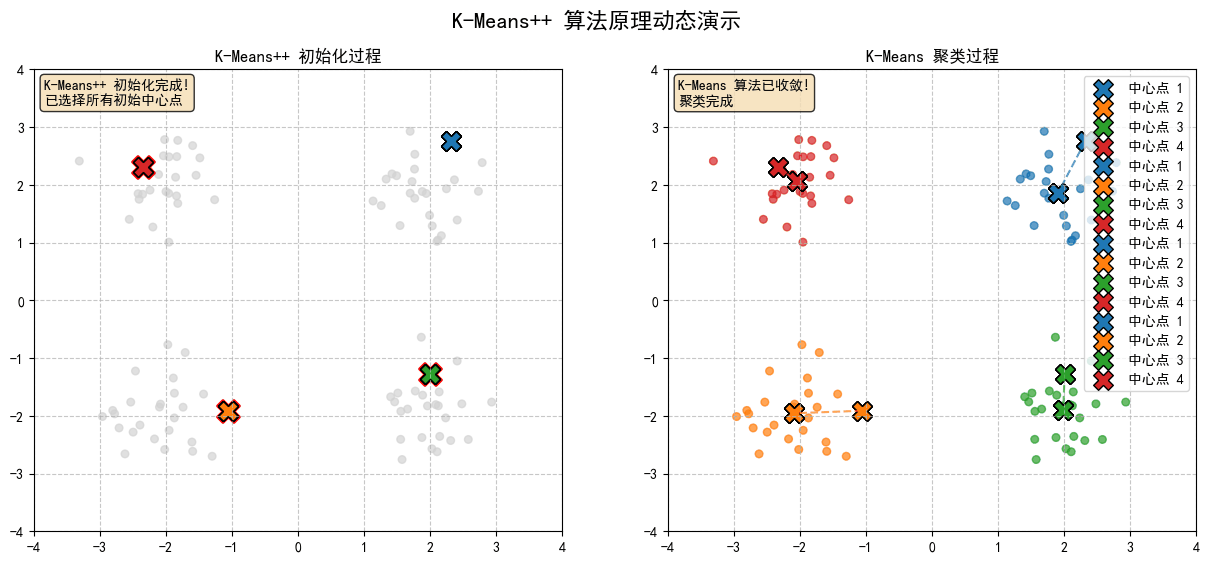
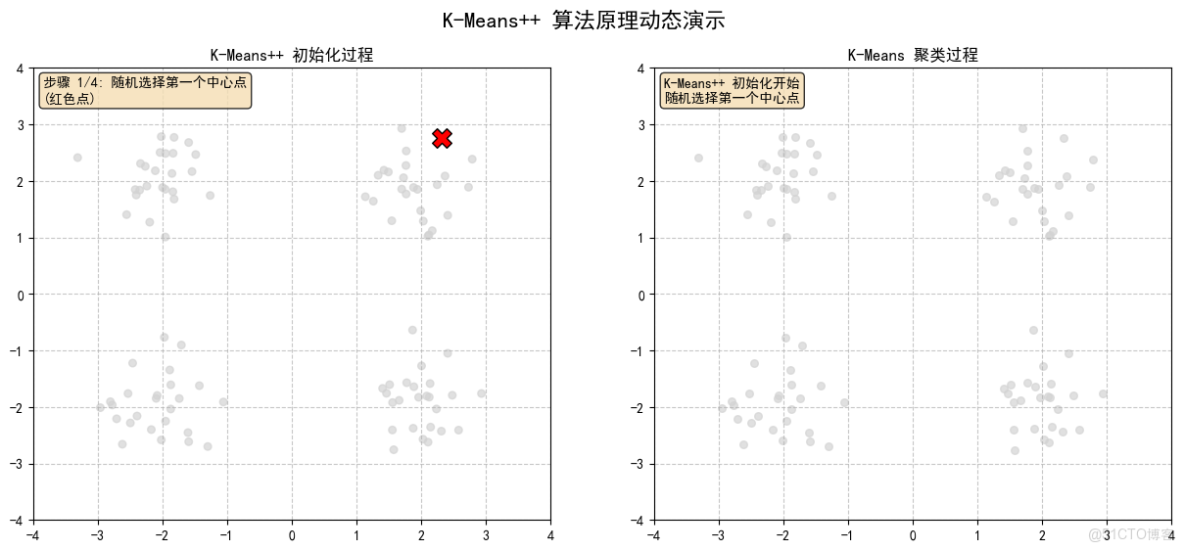
2.1 隨機選擇第一個中心點(紅色點)
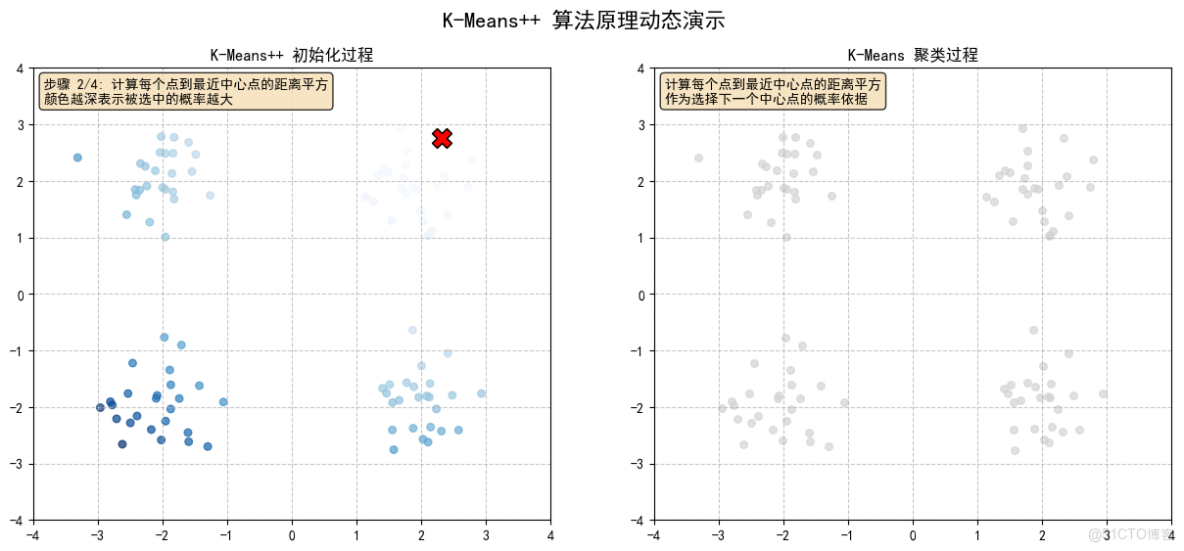
2.2 計算每個點到最近中心點的距離平方,顏色越深表示被選中的概率越大
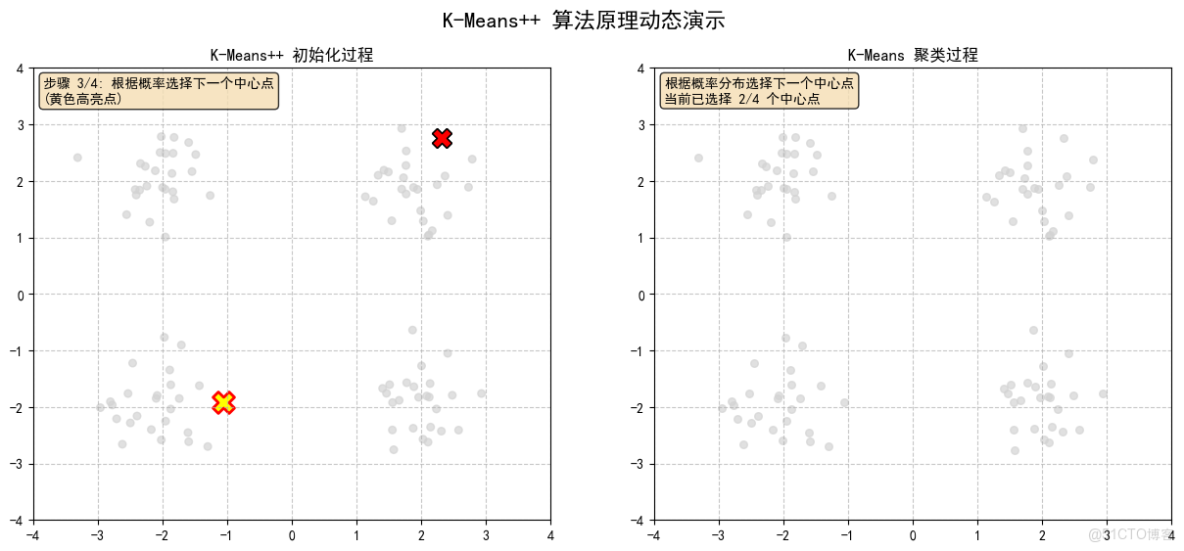
2.3 根據概率選擇下一個中心點,(黃色高亮點)
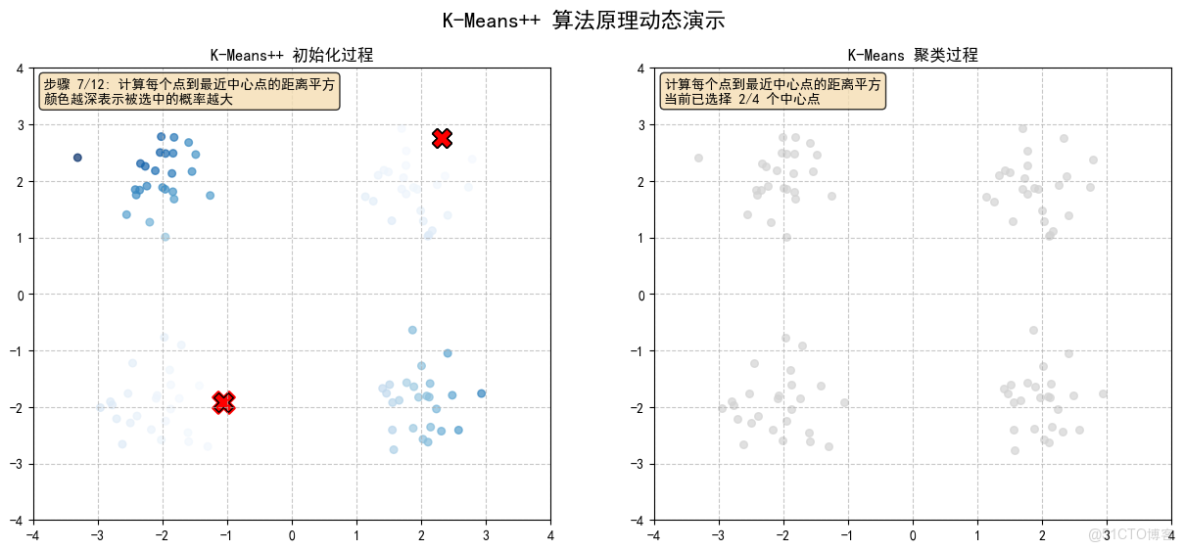
2.4 計算每個點到最近中心點的距離平方,顏色越深表示被選中的概率越大
2.5 根據概率選擇下一個中心點,(黃色高亮點)
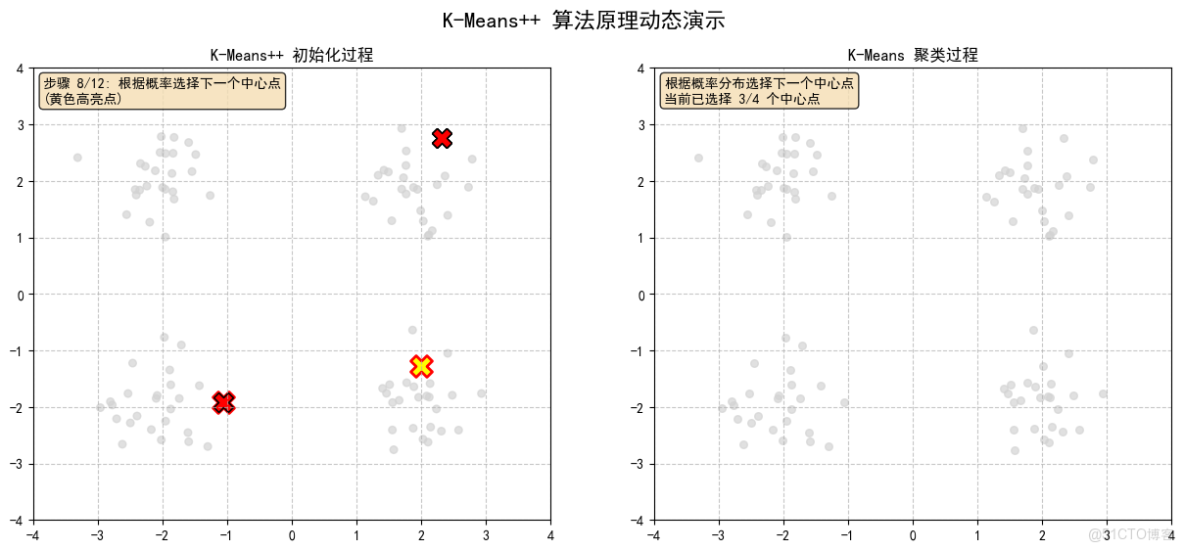
2.6 計算每個點到最近中心點的距離平方,顏色越深表示被選中的概率越大
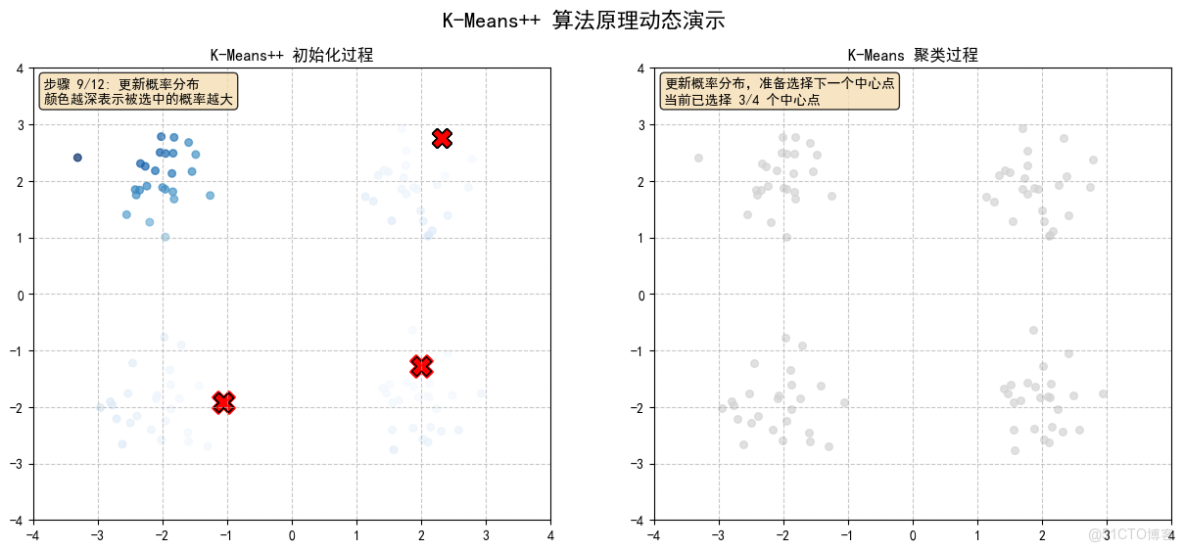
2.7 根據概率選擇下一個中心點,(黃色高亮點)
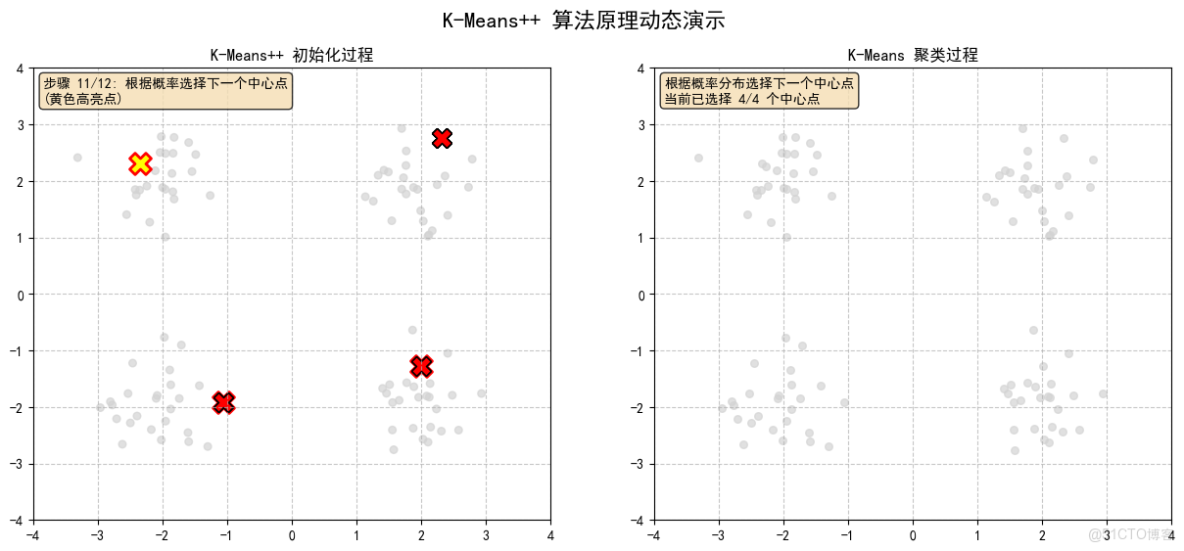
2.8 K-Means++ 初始化完成!已選擇所有初始中心點
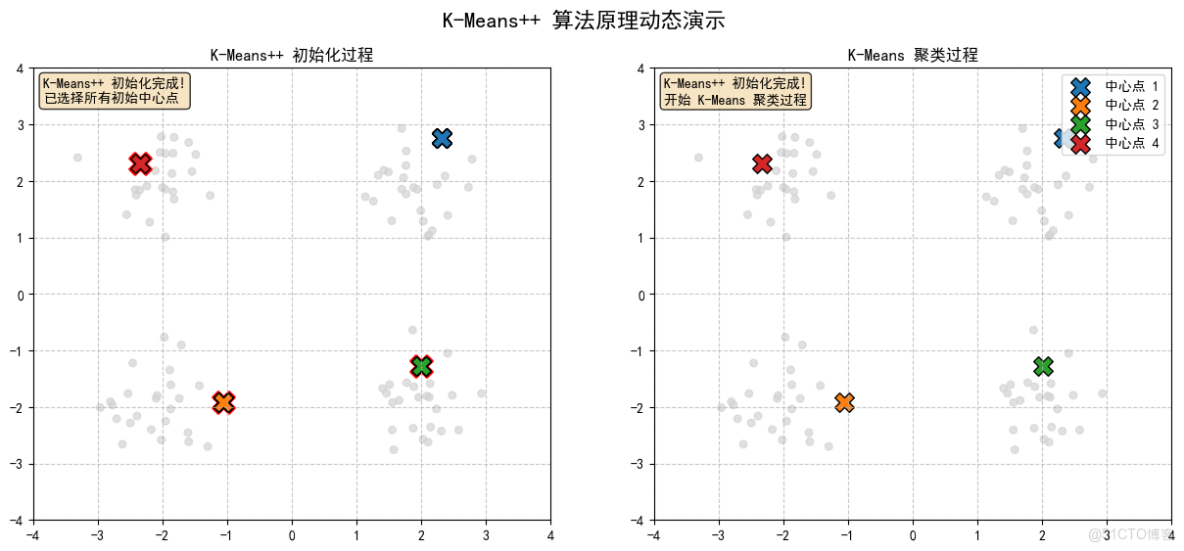
2.9 K-Means聚類,形成最終結果
3. 運行過程
開始
|
生成數據(四個高斯分佈)
|
初始化圖形(兩個子圖)
|
初始化變量(中心點列表、概率、軌跡等)
|
循環25次,每次循環為一幀:
|
|--> 如果當前幀數<12:執行K-Means++初始化步驟
| |
| |--> 幀0:隨機選擇第一個中心點
| |--> 幀1:計算每個點到最近中心點的距離平方,顯示概率分佈
| |--> 幀2:根據概率選擇下一個中心點
| |--> 幀3-5:重複計算距離、選擇中心點、顯示概率(選擇第三個中心點)
| |--> 幀6-8:重複(選擇第四個中心點)
| |--> 幀9-11:完成初始化,顯示最終中心點
|
|--> 否則(幀數>=12):執行K-Means聚類步驟
| |
| |--> 清除右圖軌跡線(為了重新繪製)
| |--> 如果是第一次進入聚類(幀12):執行分配步驟(iteration=0)
| |--> 幀13:執行更新步驟(iteration=1)
| |--> 幀14:執行分配步驟(iteration=2)
| |--> ... 依次交替,直到幀24:執行第10次迭代(iteration=9,更新步驟)
| |--> 繪製中心點軌跡
|
|--> 保存當前幀為PNG圖片
|
循環結束
|
結束
4. 算法原理
K-Means++ 初始化:
- 隨機選擇第一個中心點
- 計算每個點到最近中心點的距離平方
- 根據距離平方的概率分佈選擇下一個中心點
- 重複步驟 2-3 直到選擇足夠數量的中心點
K-Means 聚類:
- 分配步驟:將每個點分配到最近的中心點
- 更新步驟:重新計算每個簇的中心點位置
- 重複步驟 1-2 直到收斂或達到最大迭代次數
三、與 RAG 結合:文本聚類分析
這段示例實現了一個完整的文檔聚類分析系統,使用K-Means++算法對中文文檔進行聚類,生成簇的名稱和描述,並將查詢映射到向量,找到最相關的簇,並返回最相關的文檔
1. 重點部分説明
1.1 數據準備與向量化
# 1. 準備示例數據
documents = [
"股市在經濟復甦中創歷史新高,投資者信心大增",
"新研究顯示地中海飲食對心臟健康的顯著益處",
# ... 20箇中文文檔
]
# 2. 文檔向量化
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
document_embeddings = embedder.encode(documents)
- 使用20箇中文文檔作為示例數據,涵蓋多個主題領域
- 採用多語言Sentence Transformer模型將文本轉換為高維向量
- 模型選擇paraphrase-multilingual-MiniLM-L12-v2,適合處理中文文本
1.2 自定義K-Means++實現
def kmeans_plus_plus(X, n_clusters, max_iter=100, tol=1e-4):
# K-Means++ 初始化
centers = np.zeros((n_clusters, n_features))
# 隨機選擇第一個中心點
first_idx = np.random.randint(n_samples)
centers[0] = X[first_idx]
# 選擇剩餘的中心點(基於概率分佈)
for i in range(1, n_clusters):
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers[:i]]) for x in X])
probabilities = distances / np.sum(distances)
next_idx = np.random.choice(n_samples, p=probabilities)
centers[i] = X[next_idx]
# 迭代優化
for iteration in range(max_iter):
# 分配樣本到最近的中心點
labels = np.argmin(np.linalg.norm(X[:, np.newaxis] - centers, axis=2), axis=1)
# 計算新的中心點
new_centers = np.zeros((n_clusters, n_features))
for i in range(n_clusters):
cluster_points = X[labels == i]
if len(cluster_points) > 0:
new_centers[i] = np.mean(cluster_points, axis=0)
else:
# 如果簇為空,重新初始化
new_centers[i] = X[np.random.randint(n_samples)]
# 檢查收斂
if np.all(np.linalg.norm(new_centers - centers, axis=1) < tol):
break
centers = new_centers
return labels, centers
- 實現了完整的K-Means++算法,包括智能初始化
- 使用距離平方的概率分佈選擇初始中心點,避免隨機初始化的缺點
- 包含空簇處理機制,防止算法崩潰
- 設置收斂容差和最大迭代次數,確保算法終止
1.3 關鍵詞提取與簇命名
def extract_keywords(texts, top_n=5):
"""從文本中提取關鍵詞"""
words = []
for text in texts:
# 移除標點符號
text_clean = re.sub(r'[^\w\s]', '', text)
# 按空格和常見分隔符分割
text_words = re.split(r'[\s、,。;:!?]+', text_clean)
words.extend([w for w in text_words if len(w) > 1])
# 計算詞頻
word_counts = Counter(words)
return [word for word, count in word_counts.most_common(top_n)]
def generate_cluster_name(keywords):
"""根據關鍵詞生成簇名稱"""
if len(keywords) >= 2:
return f"{keywords[0]}與{keywords[1]}"
else:
return f"{keywords[0]}相關"
- 使用簡單的文本處理技術提取中文關鍵詞
- 基於詞頻統計確定最重要的關鍵詞
- 採用組合關鍵詞的方式生成有意義的簇名稱
- 這種方法雖然簡單,但對於演示目的足夠有效
1.4 可視化展示
# 使用PCA降維
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(document_embeddings)
reduced_centers = pca.transform(cluster_centers)
# 創建顏色映射
colors = ['red', 'blue', 'green', 'purple', 'orange', 'brown', 'pink', 'gray']
cluster_colors = [colors[label % len(colors)] for label in cluster_labels]
# 繪製散點圖
plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1],
c=cluster_colors, s=100, alpha=0.7)
# 標記簇中心
plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1],
c='black', marker='X', s=200, label='簇中心')
# 為每個點添加文檔索引
for i, (x, y) in enumerate(reduced_embeddings):
plt.annotate(str(i), (x, y), xytext=(5, 5), textcoords='offset points', fontsize=8)
- 使用PCA將高維向量降至2維進行可視化
- 為每個簇分配不同顏色,便於區分
- 標記簇中心點,顯示聚類效果
- 為每個文檔點添加索引,便於識別具體文檔
1.5 簇分析與統計
# 計算簇內文檔的平均相似度
cluster_embeddings = document_embeddings[info['doc_indices']]
if len(cluster_embeddings) > 1:
similarities = []
for i in range(len(cluster_embeddings)):
for j in range(i+1, len(cluster_embeddings)):
sim = np.dot(cluster_embeddings[i], cluster_embeddings[j]) / (
np.linalg.norm(cluster_embeddings[i]) * np.linalg.norm(cluster_embeddings[j]))
similarities.append(sim)
avg_similarity = np.mean(similarities) if similarities else 0
print(f"簇內平均相似度: {avg_similarity:.3f}")
- 計算每個簇內文檔之間的平均餘弦相似度
- 評估簇內文檔的一致性程度
- 高相似度表示簇內文檔主題高度相關
1.6 查詢處理功能
def find_relevant_cluster(query_embedding, cluster_centers):
"""找到與查詢最相關的簇"""
similarities = []
for center in cluster_centers:
similarity = np.dot(query_embedding, center) / (
np.linalg.norm(query_embedding) * np.linalg.norm(center))
similarities.append(similarity)
return np.argmax(similarities), similarities
def retrieve_documents(query, top_k=3):
"""檢索與查詢相關的文檔"""
# 將查詢轉換為向量
query_embedding = embedder.encode([query])[0]
# 找到最相關的簇
relevant_cluster, cluster_similarities = find_relevant_cluster(query_embedding, cluster_centers)
# 計算查詢與簇內文檔的相似度
cluster_doc_indices = cluster_info[relevant_cluster]['doc_indices']
cluster_embeddings = document_embeddings[cluster_doc_indices]
similarities = []
for emb in cluster_embeddings:
similarity = np.dot(query_embedding, emb) / (
np.linalg.norm(query_embedding) * np.linalg.norm(emb))
similarities.append(similarity)
# 獲取最相關的文檔
similarities = np.array(similarities)
top_indices = np.argsort(similarities)[-top_k:][::-1]
results = []
for idx in top_indices:
doc_idx = cluster_doc_indices[idx]
results.append((doc_idx, documents[doc_idx], similarities[idx]))
return results, relevant_cluster
- 實現基於語義的文檔檢索功能
- 先將查詢轉換為向量,再計算與簇中心和文檔的相似度
- 使用兩階段檢索:先找到最相關簇,再在簇內找最相關文檔
- 這種方法提高了檢索效率,特別適合大規模文檔集
2. 輸出結果
=========================================================================
文檔聚類詳細結果
=========================================================================
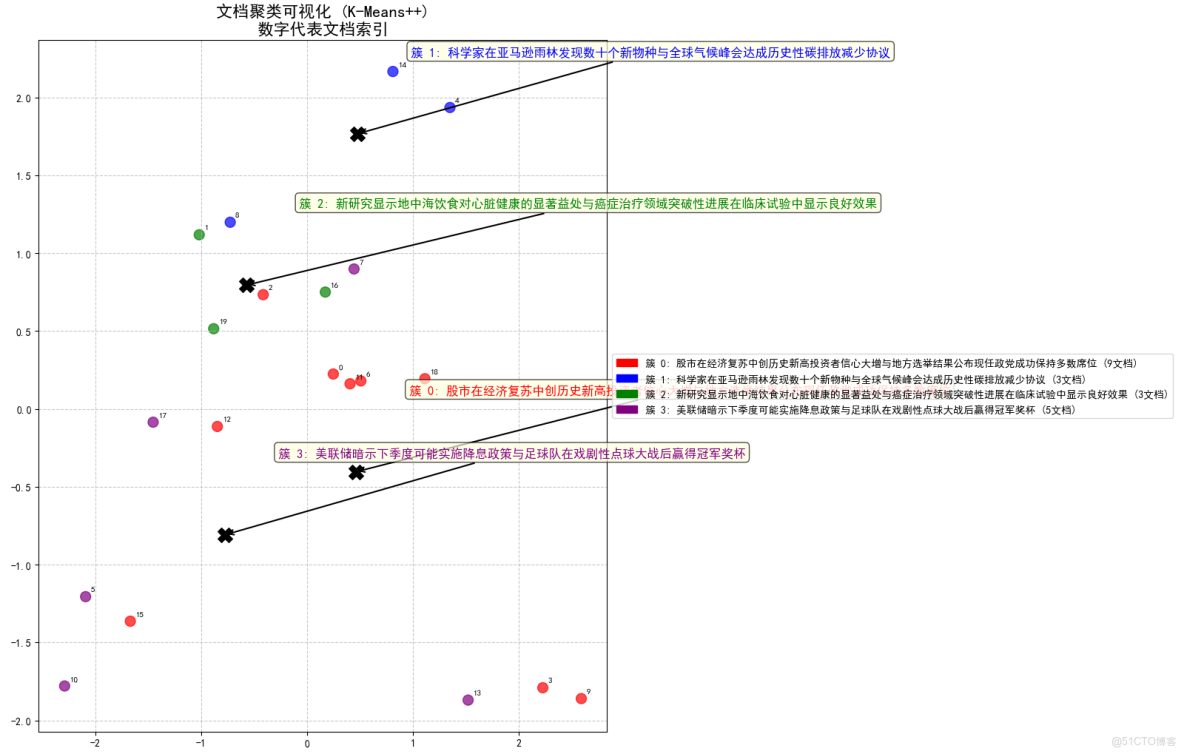
- 簇 0: 股市在經濟復甦中創歷史新高投資者信心大增與地方選舉結果公佈現任政黨成功保持多數席位 (包含 9 個文檔)
- 關鍵詞: 股市在經濟復甦中創歷史新高投資者信心大增, 地方選舉結果公佈現任政黨成功保持多數席位, 科技巨頭髮布最新智能手機搭載先進AI攝影功能, COVID19疫苗加強針現已向所有成年人開放接種, 蘋果公司發佈新一代iPhone相機系統全面升級
- 描述: 包含9個文檔,主要涉及股市在經濟復甦中創歷史新高投資者信心大增與地方選舉結果公佈現任政黨成功保持多數席位。示例文檔:股市在經濟復甦中創歷史新高,投資者信心大增;地方選舉結果公佈,現任政黨成功保持多數席位;科技巨頭髮布最新智能手機,搭載先進AI攝影功能
- 文檔列表:
- [0] 股市在經濟復甦中創歷史新高,投資者信心大增
- [2] 地方選舉結果公佈,現任政黨成功保持多數席位
- [3] 科技巨頭髮布最新智能手機,搭載先進AI攝影功能
- [6] COVID-19疫苗加強針現已向所有成年人開放接種
- [9] 蘋果公司發佈新一代iPhone,相機系統全面升級
- [11] 最新研究將空氣污染與阿爾茨海默病風險增加聯繫起來
- [12] 市議會批准50億預算用於新建公共交通系統
- [15] 財政部長髮表對數字貨幣未來發展的評論
- [18] 谷歌發佈核心搜索算法重大更新
簇內平均相似度: 0.144
------------------------------------------------------------
- 簇 1: 科學家在亞馬遜雨林發現數十個新物種與全球氣候峯會達成歷史性碳排放減少協議 (包含 3 個文檔)
- 關鍵詞: 科學家在亞馬遜雨林發現數十個新物種, 全球氣候峯會達成歷史性碳排放減少協議, 當地公園發現稀有鳥類物種觀鳥愛好者蜂擁而至
- 描述: 包含3個文檔,主要涉及科學家在亞馬遜雨林發現數十個新物種與全球氣候峯會達成歷史性碳排放減少協議。示例文檔:科學家在亞馬遜雨林發現數十個新物種;全球氣候峯會達成歷史性碳排放減少協議;當地公園發現稀有鳥類物種,觀鳥愛好者蜂擁而至
- 文檔列表:
- [4] 科學家在亞馬遜雨林發現數十個新物種
- [8] 全球氣候峯會達成歷史性碳排放減少協議
- [14] 當地公園發現稀有鳥類物種,觀鳥愛好者蜂擁而至
簇內平均相似度: 0.251
------------------------------------------------------------
- 簇 2: 新研究顯示地中海飲食對心臟健康的顯著益處與癌症治療領域突破性進展在臨牀試驗中顯示良好效果 (包含 3 個文檔)
- 關鍵詞: 新研究顯示地中海飲食對心臟健康的顯著益處, 癌症治療領域突破性進展在臨牀試驗中顯示良好效果, 颶風逼近東部海岸居民被敦促立即撤離
- 描述: 包含3個文檔,主要涉及新研究顯示地中海飲食對心臟健康的顯著益處與癌症治療領域突破性進展在臨牀試驗中顯示良好效果。示例文檔:新研究顯示地中海飲食對心臟健康的顯著益處;癌症治療領域突破性進展在臨牀試驗中顯示良好效果;颶風逼近東部海岸,居民被敦促立即撤離
- 文檔列表:
- [1] 新研究顯示地中海飲食對心臟健康的顯著益處
- [16] 癌症治療領域突破性進展在臨牀試驗中顯示良好效果
- [19] 颶風逼近東部海岸,居民被敦促立即撤離
簇內平均相似度: 0.149
------------------------------------------------------------
- 簇 3: 美聯儲暗示下季度可能實施降息政策與足球隊在戲劇性點球大戰後贏得冠軍獎盃 (包含 5 個文檔)
- 關鍵詞: 美聯儲暗示下季度可能實施降息政策, 足球隊在戲劇性點球大戰後贏得冠軍獎盃, 央行宣佈新貨幣政策以遏制通貨膨脹趨勢, 三星推出新款可摺疊手機挑戰市場競爭格局, 市長候選人承諾制定全面計劃解決無家可歸危機
- 描述: 包含5個文檔,主要涉及美聯儲暗示下季度可能實施降息政策與足球隊在戲劇性點球大戰後贏得冠軍獎盃。示例文檔:美聯儲暗示下季度可能實施降息政策;足球隊在戲劇性點球大戰後贏得冠軍獎盃;央行宣佈新貨幣政策以遏制通貨膨脹趨勢
- 文檔列表:
- [5] 美聯儲暗示下季度可能實施降息政策
- [7] 足球隊在戲劇性點球大戰後贏得冠軍獎盃
- [10] 央行宣佈新貨幣政策以遏制通貨膨脹趨勢
- [13] 三星推出新款可摺疊手機,挑戰市場競爭格局
- [17] 市長候選人承諾制定全面計劃解決無家可歸危機
簇內平均相似度: 0.083
------------------------------------------------------------
=========================================================================
簇分類統計
=========================================================================
文檔總數: 20
簇 0 (股市在經濟復甦中創歷史新高投資者信心大增與地方選舉結果公佈現任政黨成功保持多數席位): 9 文檔 (45.0%)
簇 1 (科學家在亞馬遜雨林發現數十個新物種與全球氣候峯會達成歷史性碳排放減少協議): 3 文檔 (15.0%)
簇 2 (新研究顯示地中海飲食對心臟健康的顯著益處與癌症治療領域突破性進展在臨牀試驗中顯示良好效果): 3 文檔 (15.0%)
簇 3 (美聯儲暗示下季度可能實施降息政策與足球隊在戲劇性點球大戰後贏得冠軍獎盃): 5 文檔 (25.0%)
=========================================================================
查詢處理示例
=========================================================================
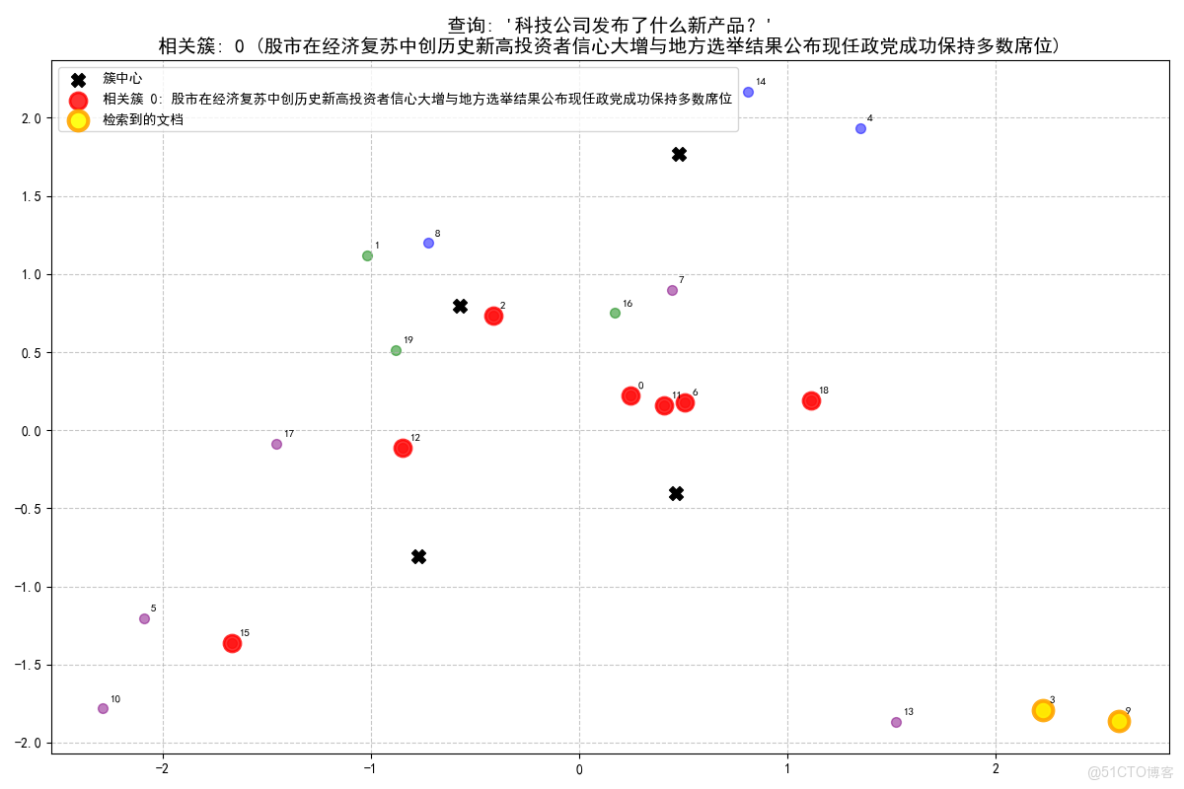
查詢: '科技公司發佈了什麼新產品?'
- 查詢最相關的是簇 0 (股市在經濟復甦中創歷史新高投資者信心大增與地方選舉結果公佈現任政黨成功保持多數席位), 相似度: 0.424
- 從簇 0 (股市在經濟復甦中創歷史新高投資者信心大增與地方選舉結果公佈現任政黨成功保持多數席位) 中找到 2 個相關文檔:
- [文檔 3, 相似度: 0.439]: 科技巨頭髮布最新智能手機,搭載先進AI攝影功能
- [文檔 9, 相似度: 0.346]: 蘋果公司發佈新一代iPhone,相機系統全面升級
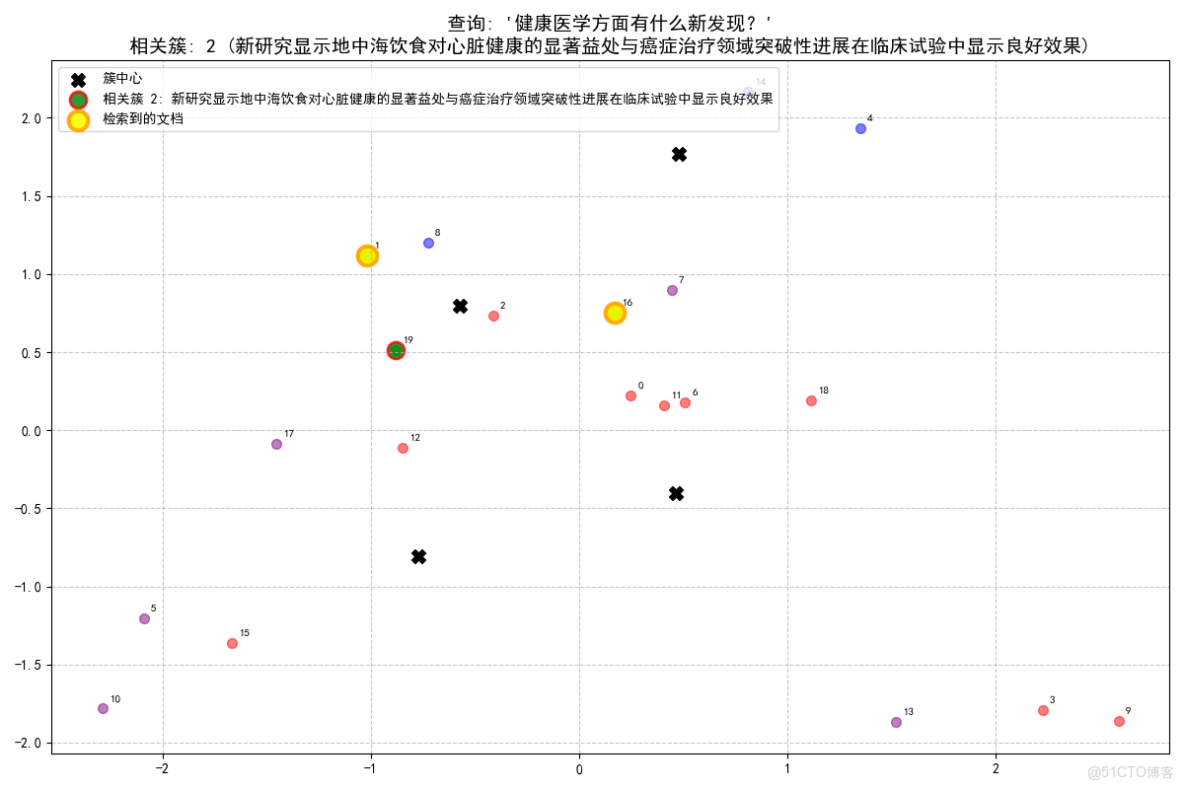
查詢: '健康醫學方面有什麼新發現?'
- 查詢最相關的是簇 2 (新研究顯示地中海飲食對心臟健康的顯著益處與癌症治療領域突破性進展在臨牀試驗中顯示良好效果), 相似度: 0.385
- 從簇 2 (新研究顯示地中海飲食對心臟健康的顯著益處與癌症治療領域突破性進展在臨牀試驗中顯示良好效果) 中找到 2 個相關文檔:
- [文檔 16, 相似度: 0.454]: 癌症治療領域突破性進展在臨牀試驗中顯示良好效果
- [文檔 1, 相似度: 0.321]: 新研究顯示地中海飲食對心臟健康的顯著益處
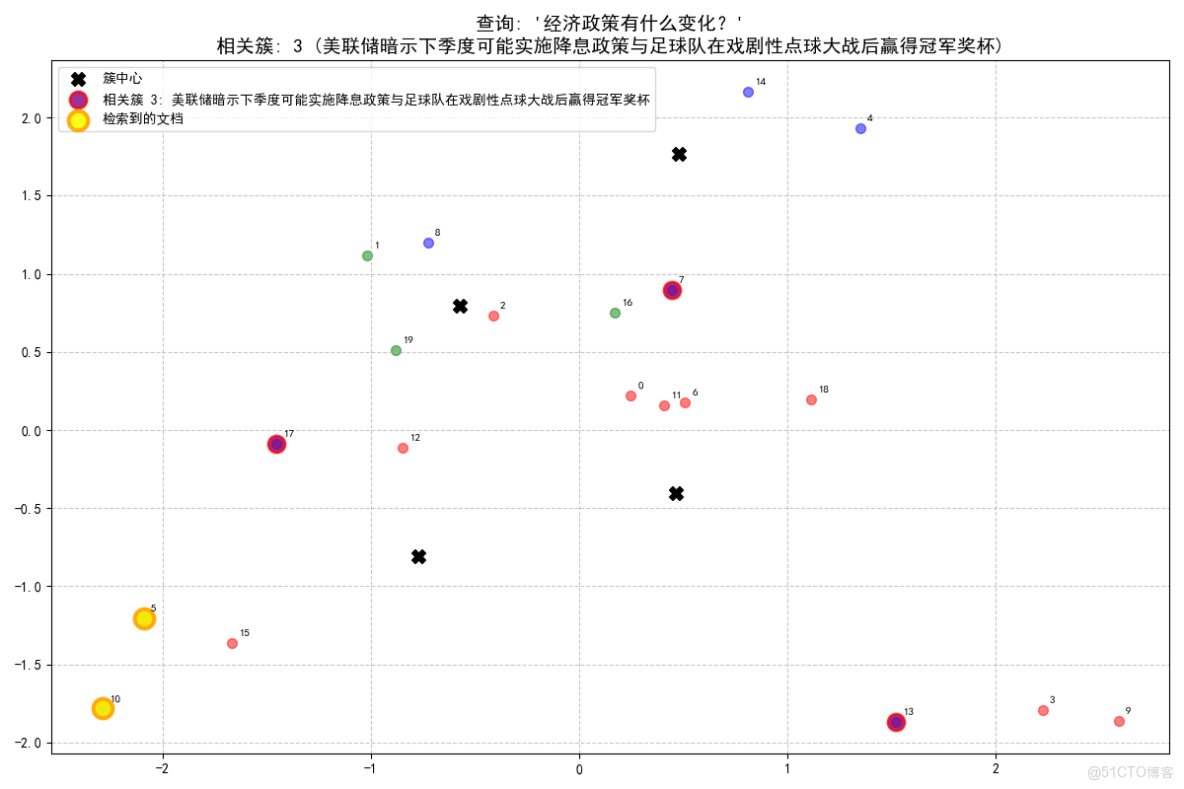
查詢: '經濟政策有什麼變化?'
- 查詢最相關的是簇 3 (美聯儲暗示下季度可能實施降息政策與足球隊在戲劇性點球大戰後贏得冠軍獎盃), 相似度: 0.335
- 從簇 3 (美聯儲暗示下季度可能實施降息政策與足球隊在戲劇性點球大戰後贏得冠軍獎盃) 中找到 2 個相關文檔:
- [文檔 5, 相似度: 0.354]: 美聯儲暗示下季度可能實施降息政策
- [文檔 10, 相似度: 0.315]: 央行宣佈新貨幣政策以遏制通貨膨脹趨勢
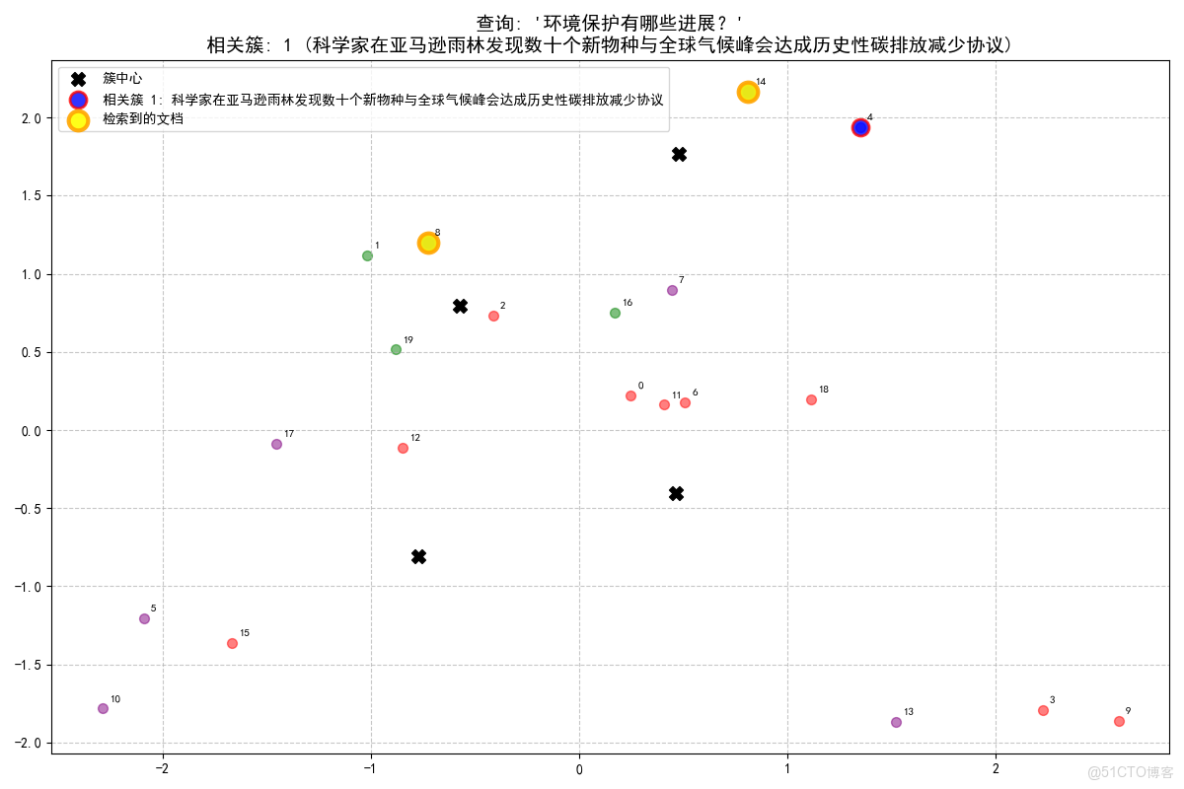
查詢: '環境保護有哪些進展?'
- 查詢最相關的是簇 1 (科學家在亞馬遜雨林發現數十個新物種與全球氣候峯會達成歷史性碳排放減少協議), 相似度: 0.461
- 從簇 1 (科學家在亞馬遜雨林發現數十個新物種與全球氣候峯會達成歷史性碳排放減少協議) 中找到 2 個相關文檔:
- [文檔 8, 相似度: 0.468]: 全球氣候峯會達成歷史性碳排放減少協議
- [文檔 14, 相似度: 0.259]: 當地公園發現稀有鳥類物種,觀鳥愛好者蜂擁而至
四、應用場景
- 企業知識管理:構建智能企業知識庫,實現高效的知識檢索和問答
- 學術研究支持:對大量學術文獻進行智能分類和關聯分析
- 新聞媒體分析:自動發現新聞話題趨勢和內容關聯
- 客户服務自動化:快速匹配用户問題與解決方案庫
- 內容創作輔助:基於已有內容生成新的創意和觀點
五、總結
KMeans++與RAG系統的融合技術主要通過知識庫多分區構建與檢索結果優化兩大場景實現性能提升,其核心邏輯是利用聚類算法的語義分組能力優化信息組織與檢索流程,解決傳統RAG系統中存在的效率瓶頸與質量偏差問題。
KMeans++與RAG系統的創新性結合,構建了一個高效、智能的文檔處理與信息檢索系統。通過將傳統機器學習算法與現代大語言模型相結合,我們實現了從海量文檔中自動發現知識結構並提供精準問答的能力。
附錄一:K-Means++ 動態算法演示
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib.colors as mcolors
import os
import imageio
# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 創建輸出目錄
if not os.path.exists('kmeans_frames'):
os.makedirs('kmeans_frames')
# 生成示例數據
np.random.seed(42)
n_samples = 100
n_clusters = 4
# 生成四個高斯分佈的數據點
X1 = np.random.normal([2, 2], 0.5, [n_samples//4, 2])
X2 = np.random.normal([-2, 2], 0.5, [n_samples//4, 2])
X3 = np.random.normal([-2, -2], 0.5, [n_samples//4, 2])
X4 = np.random.normal([2, -2], 0.5, [n_samples//4, 2])
X = np.vstack([X1, X2, X3, X4])
# 初始化圖形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
fig.suptitle('K-Means++ 算法原理動態演示', fontsize=16)
# 左圖:K-Means++ 初始化過程
ax1.set_xlim(-4, 4)
ax1.set_ylim(-4, 4)
ax1.set_title('K-Means++ 初始化過程')
ax1.grid(True, linestyle='--', alpha=0.7)
# 右圖:K-Means 聚類過程
ax2.set_xlim(-4, 4)
ax2.set_ylim(-4, 4)
ax2.set_title('K-Means 聚類過程')
ax2.grid(True, linestyle='--', alpha=0.7)
# 繪製初始數據點
scatter1 = ax1.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7)
scatter2 = ax2.scatter(X[:, 0], X[:, 1], c='lightgray', s=30, alpha=0.7)
# 初始化變量
centers = []
probabilities = np.ones(len(X)) / len(X) # 初始概率均勻分佈
current_center_idx = None
distance_text = ax1.text(0.02, 0.98, "", transform=ax1.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
info_text = ax2.text(0.02, 0.98, "", transform=ax2.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
# 顏色映射
colors = list(mcolors.TABLEAU_COLORS.values())
cluster_colors = colors[:n_clusters] # 為每個簇分配一個顏色
# 存儲中心點軌跡
center_trajectories = [[] for _ in range(n_clusters)]
# K-Means 聚類變量
labels = None
iteration = 0
max_iterations = 10
# 存儲所有幀
frames = []
def init():
"""初始化動畫"""
scatter1.set_offsets(X)
scatter2.set_offsets(X)
distance_text.set_text("")
info_text.set_text("準備開始 K-Means++ 初始化...")
return scatter1, scatter2, distance_text, info_text
def kmeans_plus_plus_init_step(i):
"""K-Means++ 初始化步驟"""
global centers, current_center_idx, probabilities
if i == 0:
# 第一步:隨機選擇第一個中心點
first_idx = np.random.randint(len(X))
centers.append(X[first_idx].copy())
current_center_idx = first_idx
# 記錄中心點軌跡
center_trajectories[0].append(centers[0].copy())
# 更新顯示
scatter1.set_offsets(X)
scatter1.set_facecolors(['lightgray'] * len(X))
face_colors = ['red' if j == first_idx else 'lightgray' for j in range(len(X))]
scatter1.set_facecolors(face_colors)
# 繪製中心點
ax1.scatter(centers[0][0], centers[0][1], c='red', s=200, marker='X', edgecolors='black')
distance_text.set_text("步驟 1/4: 隨機選擇第一個中心點\n(紅色點)")
info_text.set_text("K-Means++ 初始化開始\n隨機選擇第一個中心點")
elif i == 1 and len(centers) < n_clusters:
# 第二步:計算距離並顯示
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X])
probabilities = distances / np.sum(distances)
# 更新顯示
scatter1.set_offsets(X)
# 使用顏色深淺表示概率大小
norm = plt.Normalize(probabilities.min(), probabilities.max())
prob_colors = cm.Blues(norm(probabilities))
scatter1.set_facecolors(prob_colors)
# 繪製已選中心點
for idx, center in enumerate(centers):
ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black')
distance_text.set_text("步驟 2/4: 計算每個點到最近中心點的距離平方\n顏色越深表示被選中的概率越大")
info_text.set_text("計算每個點到最近中心點的距離平方\n作為選擇下一個中心點的概率依據")
elif i == 2 and len(centers) < n_clusters:
# 第三步:選擇下一個中心點
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X])
probabilities = distances / np.sum(distances)
next_idx = np.random.choice(len(X), p=probabilities)
centers.append(X[next_idx].copy())
current_center_idx = next_idx
# 記錄中心點軌跡
center_trajectories[len(centers)-1].append(centers[-1].copy())
# 更新顯示
scatter1.set_offsets(X)
scatter1.set_facecolors(['lightgray'] * len(X))
# 繪製所有中心點
for idx, center in enumerate(centers):
ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black')
# 高亮顯示當前選擇的中心點
ax1.scatter(centers[-1][0], centers[-1][1], c='yellow', s=250, marker='X', edgecolors='red', linewidth=2)
distance_text.set_text(f"步驟 3/4: 根據概率選擇下一個中心點\n(黃色高亮點)")
info_text.set_text(f"根據概率分佈選擇下一個中心點\n當前已選擇 {len(centers)}/{n_clusters} 箇中心點")
elif i >= 3 and len(centers) < n_clusters:
# 重複步驟2-3直到選擇足夠的中心點
if (i - 3) % 3 == 0: # 計算距離
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X])
probabilities = distances / np.sum(distances)
# 更新顯示
scatter1.set_offsets(X)
norm = plt.Normalize(probabilities.min(), probabilities.max())
prob_colors = cm.Blues(norm(probabilities))
scatter1.set_facecolors(prob_colors)
# 繪製已選中心點
for idx, center in enumerate(centers):
ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black')
step = len(centers) + 1
distance_text.set_text(f"步驟 {step*3-2}/12: 計算每個點到最近中心點的距離平方\n顏色越深表示被選中的概率越大")
info_text.set_text(f"計算每個點到最近中心點的距離平方\n當前已選擇 {len(centers)}/{n_clusters} 箇中心點")
elif (i - 3) % 3 == 1: # 選擇中心點
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X])
probabilities = distances / np.sum(distances)
next_idx = np.random.choice(len(X), p=probabilities)
centers.append(X[next_idx].copy())
current_center_idx = next_idx
# 記錄中心點軌跡
center_trajectories[len(centers)-1].append(centers[-1].copy())
# 更新顯示
scatter1.set_offsets(X)
scatter1.set_facecolors(['lightgray'] * len(X))
# 繪製所有中心點
for idx, center in enumerate(centers):
ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black')
# 高亮顯示當前選擇的中心點
ax1.scatter(centers[-1][0], centers[-1][1], c='yellow', s=250, marker='X', edgecolors='red', linewidth=2)
step = len(centers)
distance_text.set_text(f"步驟 {step*3-1}/12: 根據概率選擇下一個中心點\n(黃色高亮點)")
info_text.set_text(f"根據概率分佈選擇下一個中心點\n當前已選擇 {len(centers)}/{n_clusters} 箇中心點")
else: # 顯示概率分佈
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers]) for x in X])
probabilities = distances / np.sum(distances)
# 更新顯示
scatter1.set_offsets(X)
norm = plt.Normalize(probabilities.min(), probabilities.max())
prob_colors = cm.Blues(norm(probabilities))
scatter1.set_facecolors(prob_colors)
# 繪製已選中心點
for idx, center in enumerate(centers):
ax1.scatter(center[0], center[1], c='red', s=200, marker='X', edgecolors='black')
step = len(centers)
distance_text.set_text(f"步驟 {step*3}/12: 更新概率分佈\n顏色越深表示被選中的概率越大")
info_text.set_text(f"更新概率分佈,準備選擇下一個中心點\n當前已選擇 {len(centers)}/{n_clusters} 箇中心點")
elif len(centers) == n_clusters:
# 初始化完成,開始 K-Means 聚類
distance_text.set_text("K-Means++ 初始化完成!\n已選擇所有初始中心點")
info_text.set_text("K-Means++ 初始化完成!\n開始 K-Means 聚類過程")
# 繪製最終的中心點
scatter1.set_offsets(X)
scatter1.set_facecolors(['lightgray'] * len(X))
for idx, center in enumerate(centers):
ax1.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black')
# 在右圖繪製初始中心點
scatter2.set_offsets(X)
scatter2.set_facecolors(['lightgray'] * len(X))
for idx, center in enumerate(centers):
ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black', label=f'中心點 {idx+1}')
ax2.legend(loc='upper right')
return scatter1, scatter2, distance_text, info_text
def kmeans_step(i):
"""K-Means 聚類步驟"""
global centers, labels, iteration, cluster_colors, center_trajectories
if len(centers) < n_clusters:
return scatter1, scatter2, distance_text, info_text
# 確保centers是NumPy數組
centers_array = np.array(centers)
# 第一次迭代
if iteration == 0:
# 分配步驟:將每個點分配到最近的中心點
# 修復:使用正確的數組索引
distances = np.array([np.linalg.norm(X - center, axis=1) for center in centers_array])
labels = np.argmin(distances, axis=0)
# 更新顯示
scatter2.set_offsets(X)
scatter2.set_facecolors([cluster_colors[label] for label in labels])
# 繪製中心點
for idx, center in enumerate(centers_array):
ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black')
# 記錄中心點軌跡
center_trajectories[idx].append(center.copy())
info_text.set_text(f"迭代 {iteration+1}: 分配步驟\n將每個點分配到最近的中心點")
iteration += 1
elif iteration < max_iterations:
if iteration % 2 == 1: # 更新步驟:重新計算中心點
new_centers = np.array([X[labels == j].mean(axis=0) if np.sum(labels == j) > 0 else centers_array[j] for j in range(n_clusters)])
# 繪製中心點移動軌跡
for j in range(n_clusters):
ax2.plot([centers_array[j][0], new_centers[j][0]],
[centers_array[j][1], new_centers[j][1]],
'k--', alpha=0.5)
# 記錄中心點軌跡
center_trajectories[j].append(new_centers[j].copy())
centers = new_centers.tolist() # 轉換為列表以保持一致性
# 更新顯示
scatter2.set_offsets(X)
scatter2.set_facecolors([cluster_colors[label] for label in labels])
# 繪製中心點
for idx, center in enumerate(new_centers):
ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black')
info_text.set_text(f"迭代 {iteration+1}: 更新步驟\n重新計算每個簇的中心點位置")
iteration += 1
else: # 分配步驟:重新分配點
# 確保centers是NumPy數組
centers_array = np.array(centers)
# 分配步驟:將每個點分配到最近的中心點
distances = np.array([np.linalg.norm(X - center, axis=1) for center in centers_array])
labels = np.argmin(distances, axis=0)
# 更新顯示
scatter2.set_offsets(X)
scatter2.set_facecolors([cluster_colors[label] for label in labels])
# 繪製中心點
for idx, center in enumerate(centers_array):
ax2.scatter(center[0], center[1], c=cluster_colors[idx], s=200, marker='X', edgecolors='black')
info_text.set_text(f"迭代 {iteration+1}: 分配步驟\n根據新中心點重新分配點")
iteration += 1
else:
info_text.set_text("K-Means 算法已收斂!\n聚類完成")
# 繪製中心點軌跡
for j in range(n_clusters):
if len(center_trajectories[j]) > 1:
trajectory = np.array(center_trajectories[j])
ax2.plot(trajectory[:, 0], trajectory[:, 1], '--', color=cluster_colors[j], alpha=0.7)
return scatter1, scatter2, distance_text, info_text
def update(i):
"""更新函數"""
if i < 12: # 前12幀用於K-Means++初始化
return kmeans_plus_plus_init_step(i)
else: # 後續幀用於K-Means聚類
return kmeans_step(i - 12)
# 創建動畫並保存每一幀
for i in range(25):
# 清除右圖中的軌跡線,但保留中心點
if i >= 12:
# 清除之前的軌跡線
for line in ax2.get_lines():
line.remove()
# 更新動畫
update(i)
# 保存當前幀
frame_path = f'kmeans_frames/frame_{i:02d}.png'
plt.savefig(frame_path, dpi=100, bbox_inches='tight')
frames.append(imageio.imread(frame_path))
print(f'已保存第 {i+1}/25 幀')
plt.tight_layout()
plt.show()
附錄二:與 RAG 結合:文本聚類分析
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import warnings
warnings.filterwarnings('ignore')
import re
from collections import Counter
# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 1. 準備示例數據
documents = [
"股市在經濟復甦中創歷史新高,投資者信心大增",
"新研究顯示地中海飲食對心臟健康的顯著益處",
"地方選舉結果公佈,現任政黨成功保持多數席位",
"科技巨頭髮布最新智能手機,搭載先進AI攝影功能",
"科學家在亞馬遜雨林發現數十個新物種",
"美聯儲暗示下季度可能實施降息政策",
"COVID-19疫苗加強針現已向所有成年人開放接種",
"足球隊在戲劇性點球大戰後贏得冠軍獎盃",
"全球氣候峯會達成歷史性碳排放減少協議",
"蘋果公司發佈新一代iPhone,相機系統全面升級",
"央行宣佈新貨幣政策以遏制通貨膨脹趨勢",
"最新研究將空氣污染與阿爾茨海默病風險增加聯繫起來",
"市議會批准50億預算用於新建公共交通系統",
"三星推出新款可摺疊手機,挑戰市場競爭格局",
"當地公園發現稀有鳥類物種,觀鳥愛好者蜂擁而至",
"財政部長髮表對數字貨幣未來發展的評論",
"癌症治療領域突破性進展在臨牀試驗中顯示良好效果",
"市長候選人承諾制定全面計劃解決無家可歸危機",
"谷歌發佈核心搜索算法重大更新",
"颶風逼近東部海岸,居民被敦促立即撤離"
]
# 2. 文檔向量化
print("正在加載嵌入模型...")
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
print("正在生成文檔嵌入向量...")
document_embeddings = embedder.encode(documents)
# 3. 自定義 K-Means++ 實現
def kmeans_plus_plus(X, n_clusters, max_iter=100, tol=1e-4):
"""自定義 K-Means++ 實現"""
n_samples, n_features = X.shape
# K-Means++ 初始化
centers = np.zeros((n_clusters, n_features))
# 隨機選擇第一個中心點
first_idx = np.random.randint(n_samples)
centers[0] = X[first_idx]
# 選擇剩餘的中心點
for i in range(1, n_clusters):
# 計算每個樣本到最近中心點的距離平方
distances = np.array([min([np.linalg.norm(x - c)**2 for c in centers[:i]]) for x in X])
# 按概率選擇下一個中心點
probabilities = distances / np.sum(distances)
next_idx = np.random.choice(n_samples, p=probabilities)
centers[i] = X[next_idx]
# 迭代優化
for iteration in range(max_iter):
# 分配樣本到最近的中心點
labels = np.argmin(np.linalg.norm(X[:, np.newaxis] - centers, axis=2), axis=1)
# 計算新的中心點
new_centers = np.zeros((n_clusters, n_features))
for i in range(n_clusters):
cluster_points = X[labels == i]
if len(cluster_points) > 0:
new_centers[i] = np.mean(cluster_points, axis=0)
else:
# 如果簇為空,重新初始化
new_centers[i] = X[np.random.randint(n_samples)]
# 檢查收斂
if np.all(np.linalg.norm(new_centers - centers, axis=1) < tol):
break
centers = new_centers
return labels, centers
# 使用自定義 K-Means++ 進行聚類
print("正在進行文檔聚類...")
n_clusters = 4
cluster_labels, cluster_centers = kmeans_plus_plus(document_embeddings, n_clusters)
# 4. 生成簇名稱和分類信息
def extract_keywords(texts, top_n=5):
"""從文本中提取關鍵詞"""
# 中文文本簡單分詞(按常見分隔符分割)
words = []
for text in texts:
# 移除標點符號
text_clean = re.sub(r'[^\w\s]', '', text)
# 按空格和常見分隔符分割
text_words = re.split(r'[\s、,。;:!?]+', text_clean)
words.extend([w for w in text_words if len(w) > 1]) # 只保留長度大於1的詞
# 計算詞頻
word_counts = Counter(words)
return [word for word, count in word_counts.most_common(top_n)]
def generate_cluster_name(keywords):
"""根據關鍵詞生成簇名稱"""
if not keywords:
return "未命名簇"
# 簡單規則:取前兩個關鍵詞組合
if len(keywords) >= 2:
return f"{keywords[0]}與{keywords[1]}"
else:
return f"{keywords[0]}相關"
# 為每個簇生成名稱和描述
cluster_info = {}
for cluster_id in range(n_clusters):
cluster_docs = [documents[i] for i, label in enumerate(cluster_labels) if label == cluster_id]
# 提取關鍵詞
keywords = extract_keywords(cluster_docs)
# 生成簇名稱
cluster_name = generate_cluster_name(keywords)
# 生成簇描述
if len(cluster_docs) > 0:
# 取前幾個文檔作為示例
sample_docs = cluster_docs[:min(3, len(cluster_docs))]
description = f"包含{len(cluster_docs)}個文檔,主要涉及{cluster_name}。示例文檔:{';'.join(sample_docs)}"
else:
description = "空簇"
cluster_info[cluster_id] = {
'name': cluster_name,
'keywords': keywords,
'description': description,
'doc_count': len(cluster_docs),
'doc_indices': [i for i, label in enumerate(cluster_labels) if label == cluster_id]
}
# 5. 可視化聚類結果
print("正在生成可視化圖表...")
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(document_embeddings)
reduced_centers = pca.transform(cluster_centers)
# 創建顏色映射
colors = ['red', 'blue', 'green', 'purple', 'orange', 'brown', 'pink', 'gray']
cluster_colors = [colors[label % len(colors)] for label in cluster_labels]
plt.figure(figsize=(16, 12))
scatter = plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1],
c=cluster_colors, s=100, alpha=0.7)
# 標記簇中心
plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1],
c='black', marker='X', s=200, label='簇中心')
# 為每個點添加文檔索引
for i, (x, y) in enumerate(reduced_embeddings):
plt.annotate(str(i), (x, y), xytext=(5, 5), textcoords='offset points', fontsize=8)
# 添加簇名稱標註
for cluster_id in range(n_clusters):
center_x, center_y = reduced_centers[cluster_id]
plt.annotate(
f"簇 {cluster_id}: {cluster_info[cluster_id]['name']}",
xy=(center_x, center_y),
xytext=(center_x + 0.5, center_y + 0.5),
fontsize=12,
weight='bold',
color=colors[cluster_id % len(colors)],
bbox=dict(boxstyle="round,pad=0.3", facecolor="lightyellow", alpha=0.7),
arrowprops=dict(arrowstyle="->", color='black', lw=1.5)
)
# 添加圖例
legend_patches = [mpatches.Patch(color=colors[i],
label=f'簇 {i}: {cluster_info[i]["name"]} ({cluster_info[i]["doc_count"]}文檔)')
for i in range(n_clusters)]
plt.legend(handles=legend_patches, loc='center left', bbox_to_anchor=(1, 0.5))
plt.title('文檔聚類可視化 (K-Means++)\n數字代表文檔索引', fontsize=16)
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.savefig('kmeans_clustering.png', dpi=300, bbox_inches='tight')
plt.show()
# 6. 打印詳細的聚類結果
print("=" * 80)
print("文檔聚類詳細結果")
print("=" * 80)
for cluster_id in range(n_clusters):
info = cluster_info[cluster_id]
print(f"\n--- 簇 {cluster_id}: {info['name']} (包含 {info['doc_count']} 個文檔) ---")
print(f"關鍵詞: {', '.join(info['keywords'])}")
print(f"描述: {info['description']}")
print("文檔列表:")
for doc_idx in info['doc_indices']:
print(f" [{doc_idx}] {documents[doc_idx]}")
# 計算簇內文檔的平均相似度
cluster_embeddings = document_embeddings[info['doc_indices']]
if len(cluster_embeddings) > 1:
# 計算簇內所有文檔兩兩之間的餘弦相似度
similarities = []
for i in range(len(cluster_embeddings)):
for j in range(i+1, len(cluster_embeddings)):
sim = np.dot(cluster_embeddings[i], cluster_embeddings[j]) / (
np.linalg.norm(cluster_embeddings[i]) * np.linalg.norm(cluster_embeddings[j]))
similarities.append(sim)
avg_similarity = np.mean(similarities) if similarities else 0
print(f"簇內平均相似度: {avg_similarity:.3f}")
print("-" * 60)
# 7. 生成簇分類統計
print("\n" + "=" * 80)
print("簇分類統計")
print("=" * 80)
# 統計每個簇的大小
cluster_sizes = [cluster_info[i]['doc_count'] for i in range(n_clusters)]
total_docs = len(documents)
print(f"文檔總數: {total_docs}")
for cluster_id in range(n_clusters):
percentage = (cluster_info[cluster_id]['doc_count'] / total_docs) * 100
print(f"簇 {cluster_id} ({cluster_info[cluster_id]['name']}): {cluster_info[cluster_id]['doc_count']} 文檔 ({percentage:.1f}%)")
# 8. 模擬查詢處理
def find_relevant_cluster(query_embedding, cluster_centers):
"""找到與查詢最相關的簇"""
# 計算查詢與每個簇中心的餘弦相似度
similarities = []
for center in cluster_centers:
similarity = np.dot(query_embedding, center) / (np.linalg.norm(query_embedding) * np.linalg.norm(center))
similarities.append(similarity)
return np.argmax(similarities), similarities
def retrieve_documents(query, top_k=3):
"""檢索與查詢相關的文檔"""
# 將查詢轉換為向量
query_embedding = embedder.encode([query])[0]
# 找到最相關的簇
relevant_cluster, cluster_similarities = find_relevant_cluster(query_embedding, cluster_centers)
cluster_name = cluster_info[relevant_cluster]['name']
print(f"查詢最相關的是簇 {relevant_cluster} ({cluster_name}), 相似度: {cluster_similarities[relevant_cluster]:.3f}")
# 獲取簇內的所有文檔
cluster_doc_indices = cluster_info[relevant_cluster]['doc_indices']
cluster_embeddings = document_embeddings[cluster_doc_indices]
# 計算查詢與簇內文檔的相似度
similarities = []
for emb in cluster_embeddings:
similarity = np.dot(query_embedding, emb) / (np.linalg.norm(query_embedding) * np.linalg.norm(emb))
similarities.append(similarity)
similarities = np.array(similarities)
top_indices = np.argsort(similarities)[-top_k:][::-1]
# 獲取最相關的文檔
results = []
for idx in top_indices:
doc_idx = cluster_doc_indices[idx]
results.append((doc_idx, documents[doc_idx], similarities[idx]))
return results, relevant_cluster
# 示例查詢
queries = [
"科技公司發佈了什麼新產品?",
"健康醫學方面有什麼新發現?",
"經濟政策有什麼變化?",
"環境保護有哪些進展?"
]
print("\n" + "=" * 80)
print("查詢處理示例")
print("=" * 80)
for query in queries:
print(f"\n查詢: '{query}'")
results, cluster_id = retrieve_documents(query, top_k=2)
cluster_name = cluster_info[cluster_id]['name']
print(f"從簇 {cluster_id} ({cluster_name}) 中找到 {len(results)} 個相關文檔:")
for doc_idx, doc_text, similarity in results:
print(f" [文檔 {doc_idx}, 相似度: {similarity:.3f}]: {doc_text}")
# 可視化查詢結果
plt.figure(figsize=(12, 8))
# 繪製所有文檔點
for i, (x, y) in enumerate(reduced_embeddings):
plt.scatter(x, y, c=cluster_colors[i], s=50, alpha=0.5)
plt.annotate(str(i), (x, y), xytext=(5, 5), textcoords='offset points', fontsize=8)
# 標記簇中心
plt.scatter(reduced_centers[:, 0], reduced_centers[:, 1],
c='black', marker='X', s=100, label='簇中心')
# 高亮顯示相關簇
relevant_points = reduced_embeddings[cluster_labels == cluster_id]
plt.scatter(relevant_points[:, 0], relevant_points[:, 1],
c=colors[cluster_id % len(colors)], s=150, alpha=0.8,
edgecolors='red', linewidth=2, label=f'相關簇 {cluster_id}: {cluster_name}')
# 高亮顯示檢索到的文檔
retrieved_indices = [doc_idx for doc_idx, _, _ in results]
retrieved_points = reduced_embeddings[retrieved_indices]
plt.scatter(retrieved_points[:, 0], retrieved_points[:, 1],
c='yellow', s=200, alpha=0.9,
edgecolors='orange', linewidth=3, label='檢索到的文檔')
plt.title(f"查詢: '{query}'\n相關簇: {cluster_id} ({cluster_name})", fontsize=14)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.savefig(f'query_result_{queries.index(query)}.png', dpi=300, bbox_inches='tight')
plt.show()
print("\n=== 分析完成 ===")