
概述#
最近在通過 Redis 學 C 語言,不得不説,Redis的代碼寫的真的工整。這篇文章會比較全面的深入的講解了Redis數據結構字符串的源碼實現,希望大家能夠從中學到點東西。
Redis 的字符串源碼主要都放在了 sds.c 和 sds.h 這兩個文件中。
Redis 的動態字符串結構如下圖所示:
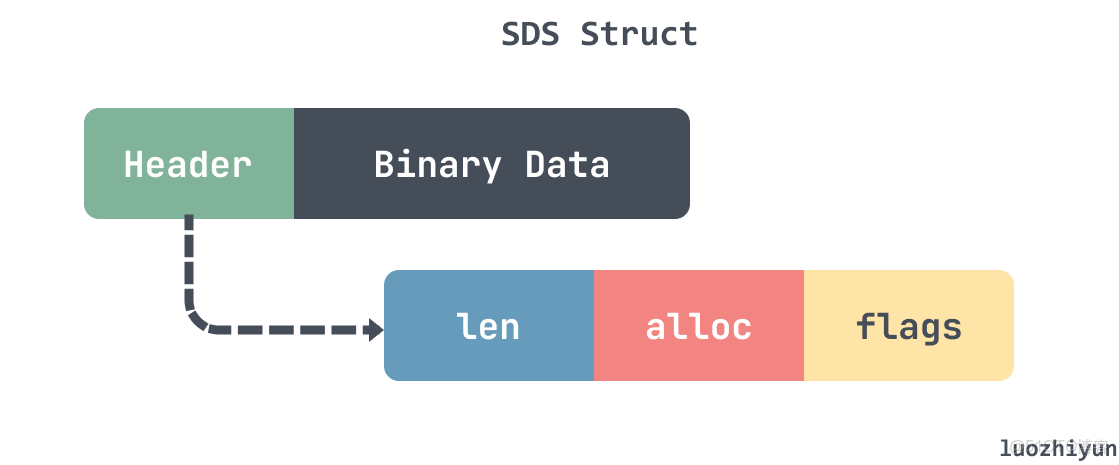
SDS 大致由兩部分構成:header以及 數據段,其中 header 還包含3個字段 len、alloc、flags。len 表示數據長度,alloc 表示分配的內存長度,flags 表示了 sds 的數據類型。
在以前的版本中,sds 的header其實佔用內存是固定8字節大小的,所以如果在redis中存放的都是小字符串,那麼 sds 的 header 將會佔用很多的內存空間。
但是隨着 sds 的版本變遷,其實在內存佔用方面還是做了一些優化:
- 在 sds 2.0 之前 header 的大小是固定的 int 類型,2.0 版本之後會根據傳入的字符大小調整 header 的 len 和 alloc 的類型以便節省內存佔用。
- header 的結構體使用
__attribute__修飾,這裏主要是防止編譯器自動進行內存對齊,這樣可以減少編譯器因為內存對齊而引起的 padding 的數量所佔用的內存。
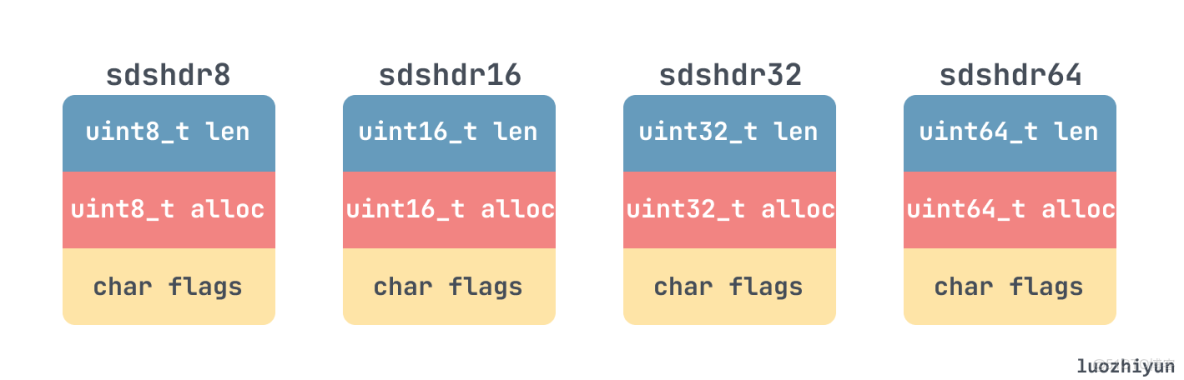
目前的版本中共定義了五種類型的 sds header,其中 sdshdr5 是沒用的,所以沒畫:
源碼分析#
sds 的創建#
sds 的創建主要有如下幾個函數:
Copy
sds sdsnewlen(const void *init, size_t initlen); sds sdsnew(const char *init); sds sdsempty(void); sds sdsdup(const sds s);- sdsnewlen 傳入一個 C 的字符串進去,創建一個 sds 字符串,並且需要傳入大小;
- sdsnew 傳入一個 C 的字符串進去,創建一個 sds 字符串,它裏面實際上會調用
strlen(init)計算好長度之後調用 sdsnewlen; - sdsempty 會創建一個空字符串 “”;
- sdsdup 調用 sdsnewlen,複製一個已存在的字符串;
所以通過上面的創建可以知道,最終都會調用 sdsnewlen 來創建字符串,所以我們看看這個函數具體怎麼實現。
sdsnewlen#
其實對於一個字符串對象的創建來説,其實就做了三件事:申請內存、構造結構體、字符串拷貝到字符串內存區域中。下面我們看一下 Redis 的具體實現。
申請內存#
Copy
sds sdsnewlen(const void *init, size_t initlen) { void *sh; //指向SDS結構體的指針 sds s; //sds類型變量,即char*字符數組 char type = sdsReqType(initlen); //根據數據大小獲取sds header 類型 if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; int hdrlen = sdsHdrSize(type); // 根據類型獲取sds header大小 unsigned char *fp; /* flags pointer. */ assert(hdrlen+initlen+1 > initlen); /* Catch size_t overflow */ sh = s_malloc(hdrlen+initlen+1); //新建SDS結構,並分配內存空間,這裏加1是因為需要在最後加上\0 ... return s; }在內存申請之前,需要做的事情有以下幾件:
- 因為 sds 會根據傳入的大小來設計 header 的類型,所以需要調用 sdsReqType 函數根據 initlen 獲取 header 類型;
- 然後調用 sdsHdrSize 根據 header 類型獲取 header 佔用的字節數;
- 最後調用 s_malloc 根據 header 長度和字符串長度分配內存,這裏需要加1是因為在 c 裏面字符串是以
\0結尾的,為了兼容 c 的字符串格式。
既然説到了 header 類型,那麼我們先來看看 header 的類型定義:
Copy
struct __attribute__ ((__packed__)) sdshdr8 { // 佔用 3 byte uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { // 佔用 5 byte uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { // 佔用 9 byte uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { // 佔用 17 byte uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };在這裏 __attribute__ 是用來防止內存對齊用的,否則也會浪費一些存儲空間。關於內存對齊相關的知識,我在 《Go中由WaitGroup引發對內存對齊思考》 這篇文章裏面也講解過了,知識點是通用的,感興趣的可以回過去看看。
看了上面的定義之後,我們自然而然的就可以想到,Redis 會根據傳入的大小判斷生成的 sds header 頭類型:
Copy
static inline char sdsReqType(size_t string_size) { if (string_size < 1<<5) // 小於 32 return SDS_TYPE_5; if (string_size < 1<<8) // 小於 256 return SDS_TYPE_8; if (string_size < 1<<16) // 小於 65,536 return SDS_TYPE_16; #if (LONG_MAX == LLONG_MAX) if (string_size < 1ll<<32) return SDS_TYPE_32; return SDS_TYPE_64; #else return SDS_TYPE_32; #endif }可以看到 sdsReqType 是根據傳入的字符串長度來判斷字符類型。
構造結構體#
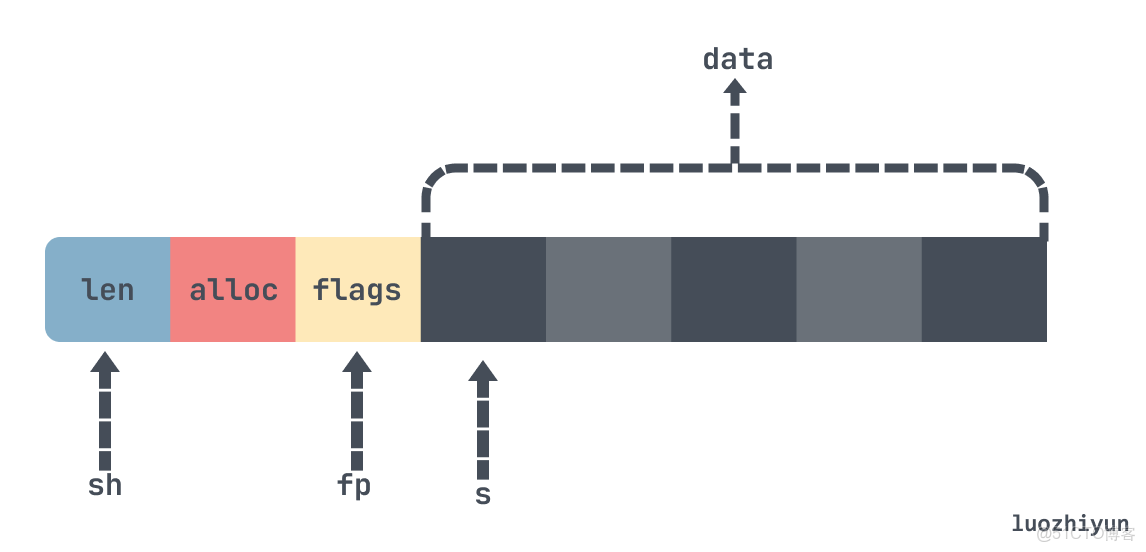
對於Redis來説,如果沒用過C語言的同學,會覺得它這裏構造結構體的方式比較 hack。首先它是直接根據需要的內存大小申請一塊內存,然後初始化頭結構的指針指向的位置,最後為頭結構的指針設值。
Copy
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T))); sds sdsnewlen(const void *init, size_t initlen) { ... sh = s_malloc(hdrlen+initlen+1); // 1.申請內存,這裏長度加1是為了在最後面存放一個 \0 if (sh == NULL) return NULL; if (init==SDS_NOINIT) init = NULL; else if (!init) memset(sh, 0, hdrlen+initlen+1);// 2.將內存的值都設置為0 s = (char*)sh+hdrlen; //3.將s指針指向數據起始位置 fp = ((unsigned char*)s)-1; //4.將fp指針指向sds header的flags字段 switch(type) { case SDS_TYPE_5: { *fp = type | (initlen << SDS_TYPE_BITS); break; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); //5.構造sds結構體header sh->len = initlen; // 初始化 header len字段 sh->alloc = initlen; // 初始化 header alloc字段 *fp = type; // 初始化 header flag字段 break; } ... } ... return s; }上面的過程我已經標註清楚了,可能直接看代碼比較難理解這裏的頭結構體構造的過程,我下面用一張圖表示一下指針指向的位置:
字符串拷貝#
Copy
sds sdsnewlen(const void *init, size_t initlen) { ... if (initlen && init) memcpy(s, init, initlen); //將要傳入的字符串拷貝給sds變量s s[initlen] = '\0'; //變量s末尾增加\0,表示字符串結束 return s; }memcpy 函數會逐個字節的將字符串拷貝到 s 對應的內存區域中。
sdscatlen 字符串追加#
Copy
sds sdscatlen(sds s, const void *t, size_t len) { size_t curlen = sdslen(s); // 獲取字符串 len 大小 //根據要追加的長度len和目標字符串s的現有長度,判斷是否要增加新的空間 //返回的還是字符串起始內存地址 s = sdsMakeRoomFor(s,len); if (s == NULL) return NULL; // 將新追加的字符串拷貝到末尾 memcpy(s+curlen, t, len); // 重新設置字符串長度 sdssetlen(s, curlen+len); s[curlen+len] = '\0'; return s; }在這個字符串追加的方法裏,其實把空間檢查和擴容封裝在了 sdsMakeRoomFor 函數中,它裏面所要做的就是:
- 有沒有剩餘空間,有的話直接返回;
- 沒有剩餘空間,那麼需要擴容,擴容多少?
- 字符串是否可以在原來的位置追加空間,還是需要重新申請一塊內存區域。
那麼下面我把 sdsMakeRoomFor 函數分為兩部分來看:擴容、內存申請。
擴容#
Copy
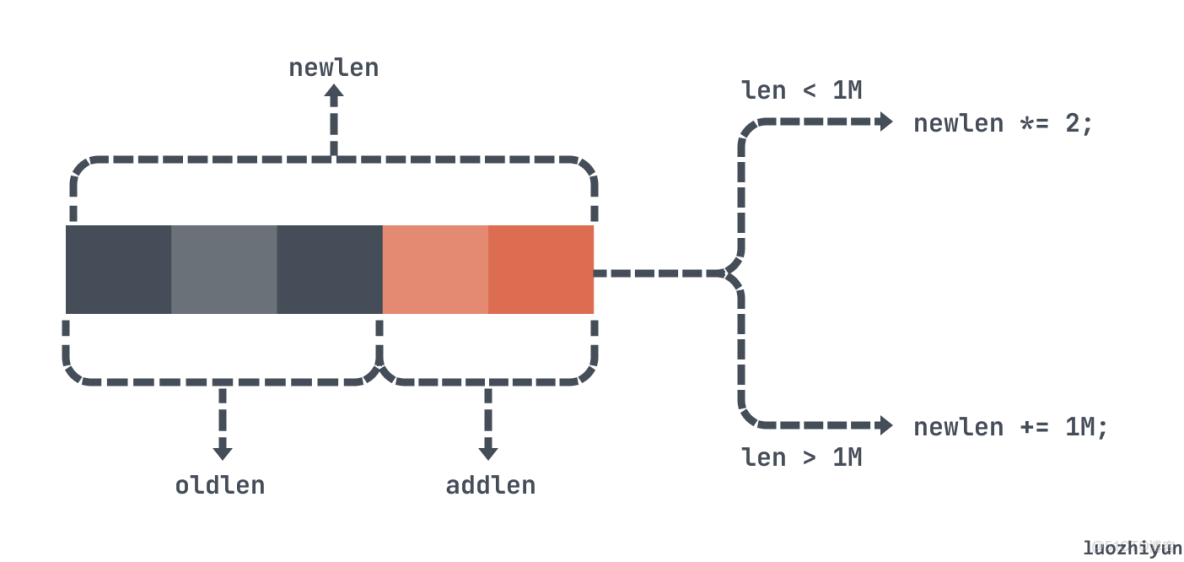
sds sdsMakeRoomFor(sds s, size_t addlen) { void *sh, *newsh; size_t avail = sdsavail(s); //這裏是用 alloc-len,表示可用資源 size_t len, newlen; char type, oldtype = s[-1] & SDS_TYPE_MASK; int hdrlen; if (avail >= addlen) return s; // 如果有空間剩餘,那麼直接返回 len = sdslen(s); // 獲取字符串 len 長度 sh = (char*)s-sdsHdrSize(oldtype); //獲取到header的指針 newlen = (len+addlen); // 新的內存空間 if (newlen < SDS_MAX_PREALLOC) //如果小於 1m, 那麼存儲空間直接翻倍 newlen *= 2; else newlen += SDS_MAX_PREALLOC; //超過了1m,那麼只會多增加1m空間 ... return s; }對於擴容來説,首先會看一下空間是否足夠,也就是根據 alloc-len 判斷, 有剩餘空間直接返回。
然後 Redis 會根據 sds 的大小不同來進行擴容,如果 len+addlen空間小於 1m,那麼新的空間直接翻倍;如果 len+addlen空間大於 1m ,那麼新空間只會增加 1m。
內存申請#
Copy
sds sdsMakeRoomFor(sds s, size_t addlen) { ... type = sdsReqType(newlen); // 根據新的空間佔用計算 sds 類型 hdrlen = sdsHdrSize(type); // header 長度 if (oldtype==type) { // 和原來header一樣,那麼可以複用原來的空間 newsh = s_realloc(sh, hdrlen+newlen+1); // 申請一塊內存,並追加大小 if (newsh == NULL) return NULL; s = (char*)newsh+hdrlen; } else { //如果header 類型變了,表示內存頭變了,那麼需要重新申請內存 //因為如果使用s_realloc只會向後追加內存 newsh = s_malloc(hdrlen+newlen+1); if (newsh == NULL) return NULL; memcpy((char*)newsh+hdrlen, s, len+1); s_free(sh); // 釋放掉原內存 s = (char*)newsh+hdrlen; s[-1] = type; sdssetlen(s, len); } sdssetalloc(s, newlen);//重新設置alloc字段 return s; }在內存申請上,Redis 分為兩種情況,一種是 sds header 類型沒變,那麼可以直接調用 realloc在原有內存後面追加新的內存區域即可;
另一種是 sds header 類型發生了變化,這裏一般是 header 佔用的空間變大了,因為 realloc 無法向前追加內存區域,所以只能調用 malloc 重新申請一塊內存區域,然後通過 memcpy 將字符串拷貝到新的地址中去。
總結#
通過這篇文章,我們深入學習到 Redis 的字符串是怎麼實現,得知它通過版本的更迭做了哪些改變,大家可以自己拿 sds 和自己熟悉的語言的字符串實現做個對比,看看實現上有啥差異,哪個更好。