
Naive RAG 架構剖析
2022年底,ChatGPT 的出現讓大語言模型(LLMs)變得非常流行。差不多同一時間,一種叫做“檢索增強生成”(RAG)的技術也出現了。這個技術主要是為了解決一些大語言模型本身存在的問題,比如:
- 有時會“胡説八道”,也就是生成一些不準確或不真實的信息。
- 能處理的信息量有限,就像一個人一次只能記住這麼多東西。
- 無法訪問一些非公開的數據,比如公司內部的資料。
- 無法自動獲取模型訓練之後的新信息,如果要更新知識,就需要重新訓練模型,這既耗時又耗力。
RAG 的最簡單架構設計的實現方式是這樣的:
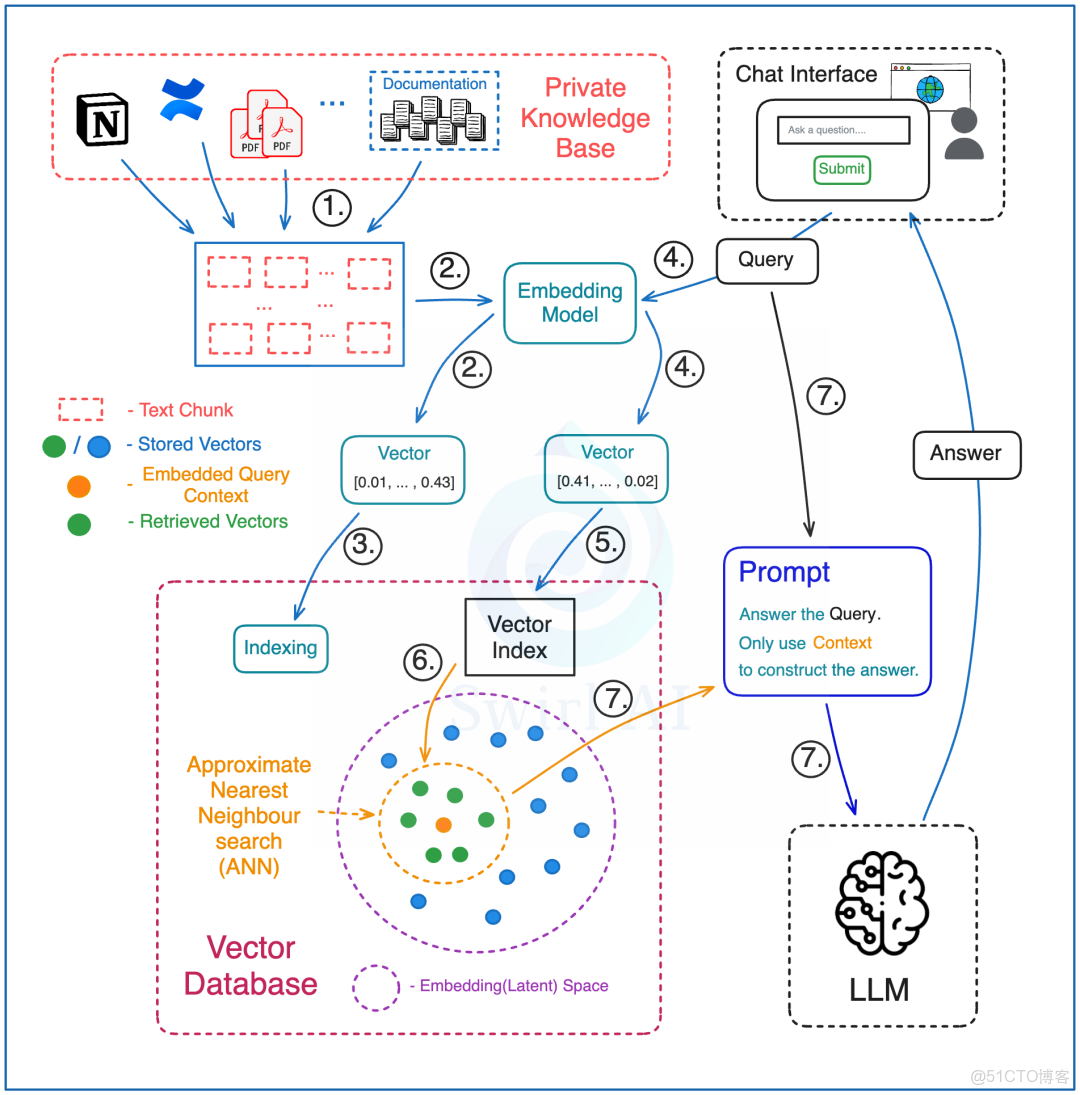
預處理階段
- 把整個知識庫的文本資料分割成一個個小塊,每個小塊都是一段可以查詢的文本。這些資料可能來自不同的地方,比如:公司內部的文檔、PDF 報告等。
- 用一個特殊的模型(嵌入模型)把這些文本塊轉換成一種特殊的代碼(向量嵌入)。
- 把這些代碼存到一個特殊的數據庫(向量數據庫)裏,同時保存每個向量對應的原始文本和指向向量的鏈接。
檢索階段
- 在向量數據庫裏,用同一個嵌入模型處理知識庫中的文檔內容和用户的問題,確保查詢和知識庫中的信息能夠準確匹配。
- 在向量數據庫的索引上運行查詢,選擇要檢索的向量數量,這決定了你將用多少上下文信息來回答查詢。
- 向量數據庫會執行一個搜索,找到最相似的向量,然後把這些向量映射回它們對應的原始文本塊。
- 把問題和檢索到的上下文文本塊一起通過一個提示詞傳遞給大語言模型,告訴模型只用這些上下文來回答這個問題。這並不意味着不需要設計好的提示詞--你還需要確保模型返回的答案符合預期,比如:如果檢索到的上下文中沒有相關信息,就不要編造答案。
Naive RAG 架構的模塊組成
在搭建一個能用在實際工作(生產級)的 RAG 系統時,即使不使用什麼高級技術,也要考慮很多會變化的部分(動態模塊)。
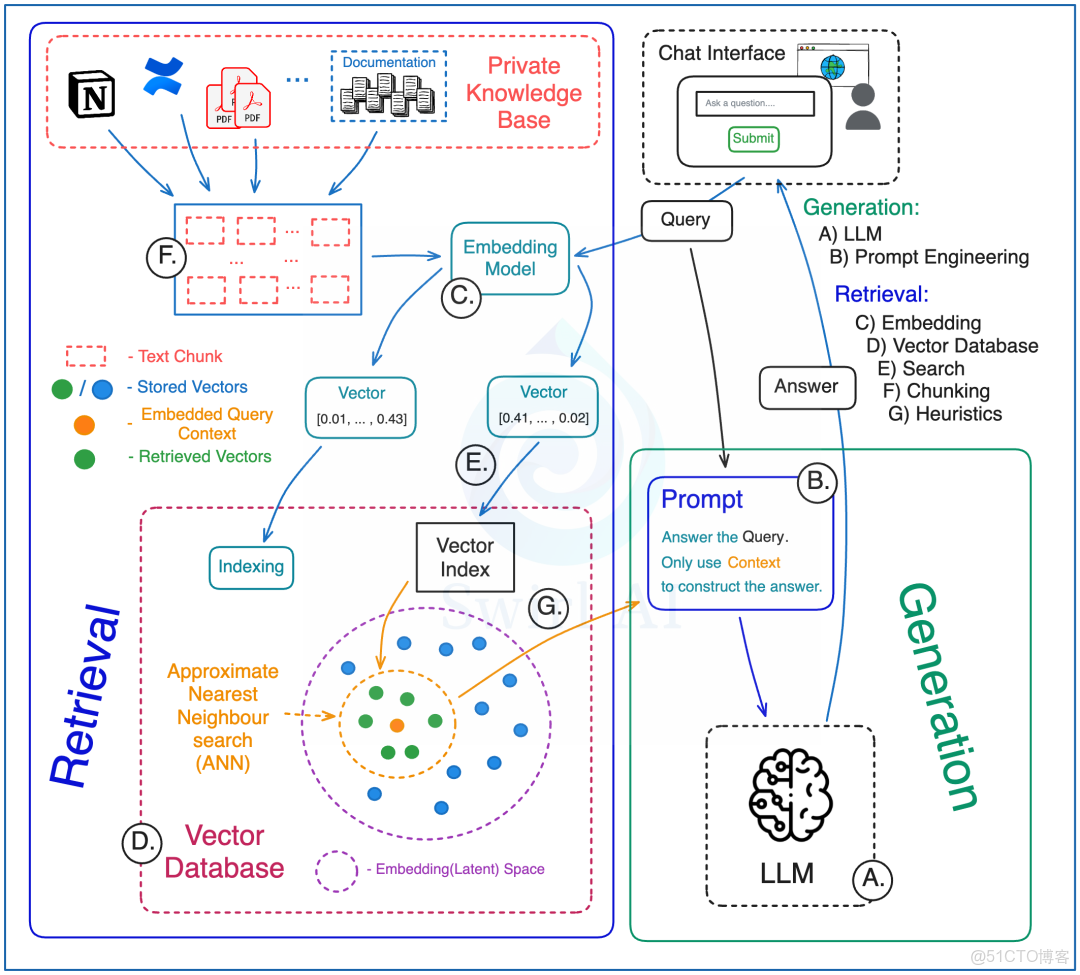
檢索部分
- 分塊策略:決定怎麼把用來提供額外信息的數據切成一塊一塊的。
- 可以選擇切小一點或大一點的塊。
- 可以用滑動窗口或固定窗口的方法來切。
- 檢索時,可以選擇是否帶上塊的“親戚”信息(父塊/鏈接塊),或者只用原始檢索到的數據。
- 嵌入模型:選擇一個模型,把額外信息轉換成一種特殊的向量(嵌入到 latent space),或者用這個模型從這種向量中檢索信息。這裏需要考慮上下文嵌入。
- 向量數據庫:
- 選擇用哪種數據庫。
- 決定數據庫放在哪裏。
- 考慮除了向量嵌入,還要存哪些額外信息(元數據),這些信息可以用來在檢索前篩選和檢索後過濾結果。
- 確定如何構建數據庫的索引。
- 向量搜索:
- 選擇用什麼標準來衡量相似度。
- 決定查詢時是先看元數據還是先做近似最近鄰(ANN)搜索。
- 可以考慮混合搜索方案。
- 啓發式規則:在檢索流程中應用一些基於經驗的規則。
- 根據文檔的時間來調整重要性。
- 對檢索到的上下文進行去重,按多樣性排序。
- 檢索時帶上內容的原始來源信息。
- 根據不同條件(比如:用户的查詢意圖、文檔類型)對原始文本進行特別處理。
生成部分
- 大語言模型:為你的應用選擇合適的大語言模型(LLM)。
- 提示詞工程:即使可以在提示詞中加入上下文信息,也需要精心設計提示詞,調整系統,以生成符合預期的輸出,並防止被“越獄”(即防止模型生成不適當的內容)。
完成所有這些步驟後,我們才能搭建起一個能運行的 RAG 系統。
但不幸的是,這類系統往往難以真正解決實際問題。由於各種原因,這種系統的準確性可能並不高。
Naive RAG 架構設計的高級技術
為了提升 Naive RAG 系統的精確度,我們嘗試了一些有效的方法:
查詢調整
這裏有幾個技巧:
- 查詢重寫:讓大語言模型(LLM)改寫原始問題,讓它更適合用來檢索信息。這可能包括修正語法錯誤,或者把問題簡化成更直接的表述。
- 查詢擴展:讓 LLM 對原始問題進行多次改寫,生成多個不同的版本。然後,對每個版本都進行檢索,以找到更多可能相關的信息。
重新排序
對初次檢索出來的文檔,使用比普通搜索更復雜的方法來重新排序。這通常需要用到更大型的模型,並且在檢索階段故意獲取比實際需要更多的文檔。重新排序和前面提到的查詢擴展一起用效果最好,因為查詢擴展通常能返回更多的數據。這個過程有點像我們在推薦系統中的做法。
微調嵌入模型
在某些領域(比如:醫療),如果用基礎的嵌入模型來檢索信息效果不好,你可能需要對嵌入模型進行定製化的微調。
接下來,我們再看看其他一些高級的 RAG 技術和架構。
上下文檢索
上下文檢索這個想法是 Anthropic 團隊去年提出來的,主要是為了讓用檢索來加強生成的 AI 系統更精確、更靠譜。
我覺得上下文檢索既簡單又直接,而且效果確實不錯。
下面是上下文檢索怎麼操作的:
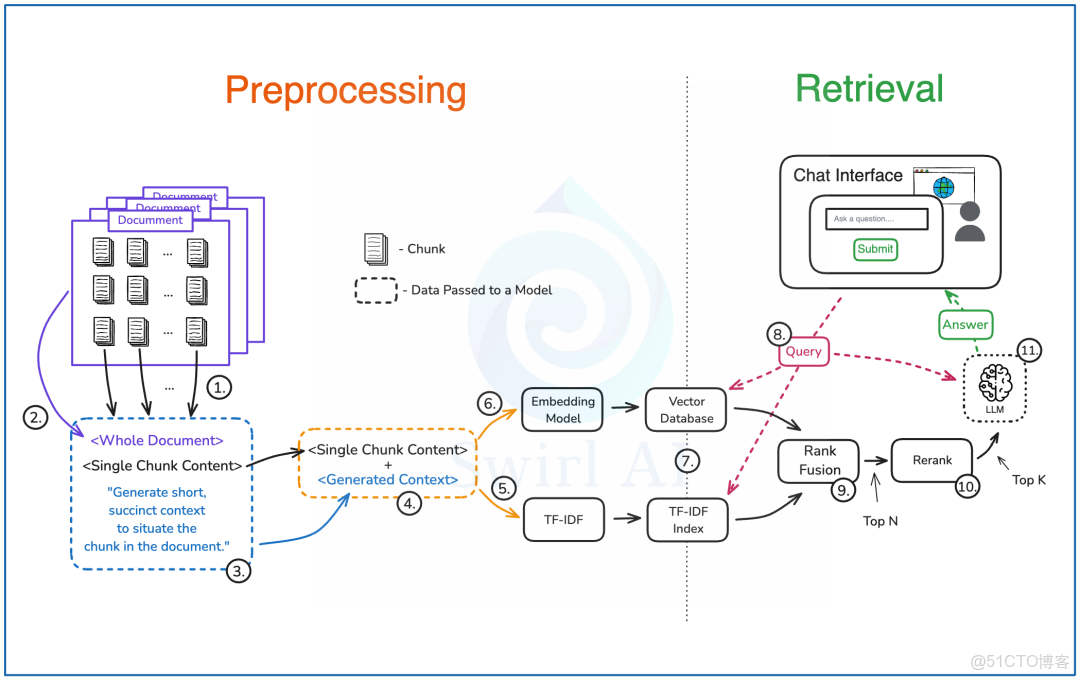
預處理階段
- 用你選好的方法把文檔切成一塊一塊的文本。
- 把每個文本塊和整個文檔一起放到一個提示詞裏。
- 在提示詞里加上指示,讓大語言模型(LLM)找出文本塊在文檔裏的位置,並給它寫個簡短的介紹。然後把這個提示詞放到 LLM 裏。
- 把上一步做出來的介紹和原始文本塊合在一起。
- 把這些合併好的數據放到一個 TF-IDF 嵌入器裏。
- 再把數據放到一個基於 LLM 的嵌入模型裏。
- 把步驟5和步驟6做出來的東西存到一個能快速搜索的數據庫裏。
檢索階段
- 用用户的提問去找相關的介紹。用一種叫近似最近鄰(ANN)的方法來做語義匹配,同時用 TF-IDF 索引來做精確搜索。
- 用排序融合技術把檢索出來的結果合併、去重,然後選出前 N 個選項。
- 對上一步的結果重新排序,縮小到前 K 個選項。
- 把步驟3的結果和用户提問一起放到 LLM 裏,生成最終的答案。
一些思考
步驟3聽起來(實際上也是)很費事,但是用一個叫提示詞緩存的技術可以大大減少這個成本。
提示詞緩存這個技術可以用在私有(閉源)模型上,也可以用在開源模型上。
緩存增強生成(Cache Augmented Generation)
2024年底,社交媒體上出現了一份引起轟動的白皮書,介紹了一種可能徹底改變 RAG(檢索增強生成)的技術--CAG(緩存增強生成)。我們先了解一下 RAG,再簡單看看 CAG:
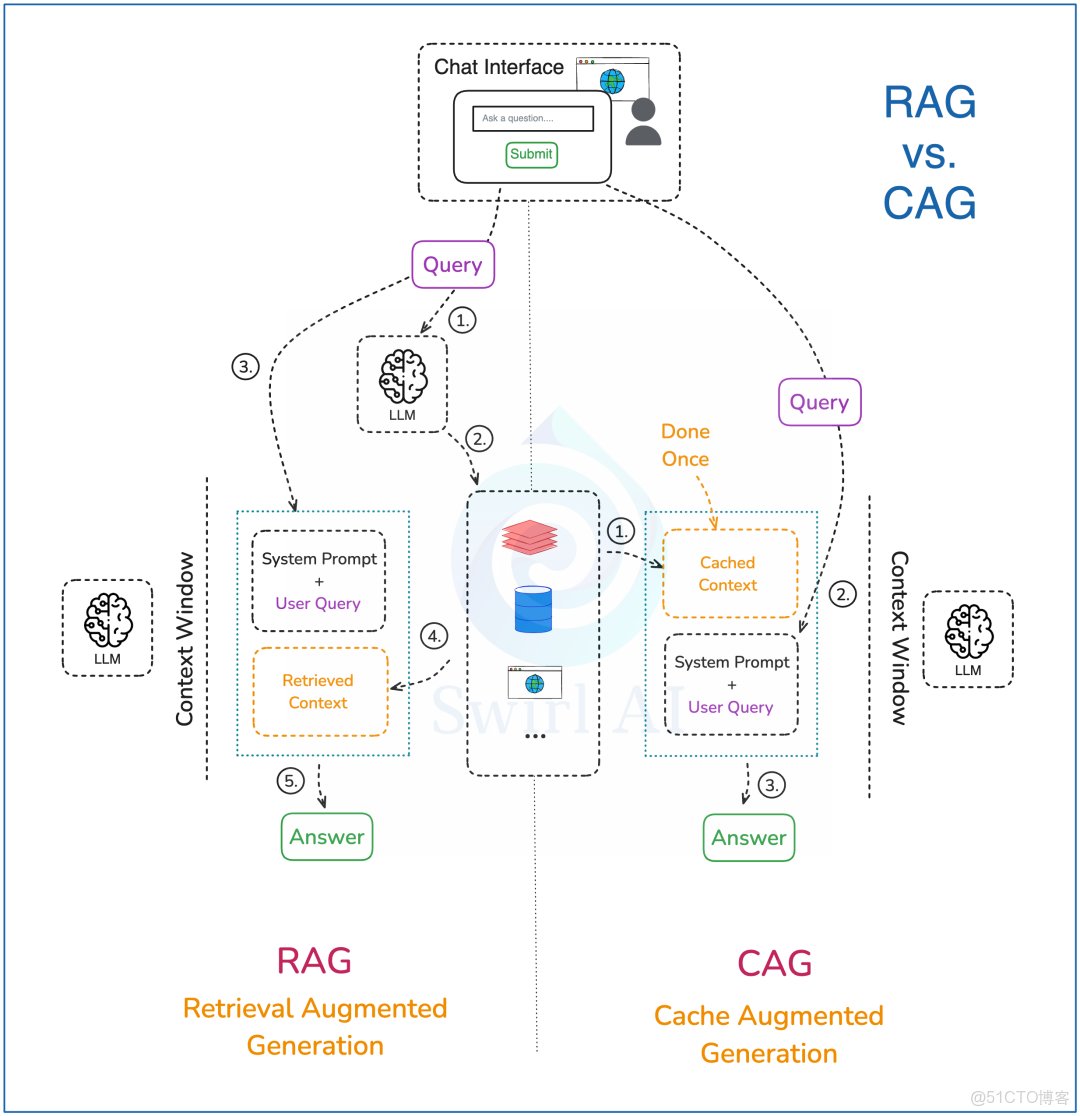
- CAG 會把所有的外部預先信息計算好,存到大語言模型(LLM)的緩存裏,並存到內存中。這個計算只需要做一次,之後就可以重複使用這個緩存,不需要重新計算。
- 把用户的提問和一些系統提示詞和怎麼使用緩存信息的提示詞一起輸入 LLM。
- 把 LLM 生成的答案返回給用户。完成後,清除緩存裏的臨時內容,只保留最初緩存的信息,這樣 LLM 就可以準備生成下一個答案了。
CAG 承諾,通過把全部信息存在緩存裏(而不是每次生成時只檢索一部分),可以實現更精確的檢索。但實際情況如何呢?
- CAG 並不能解決因為信息太長而導致的不準確問題。
- 在數據安全方面,CAG 有很多限制。
- 對於大公司來説,把整個內部知識庫都加載到緩存裏幾乎不可能。
- 緩存不能動態更新,添加新數據非常困難。
實際上,自從很多 LLM 供應商引入了提示詞緩存技術後,我們實際上已經在用 CAG 的一種變體了。我們的方法可以説是 CAG 和 RAG 的結合,具體操作如下:
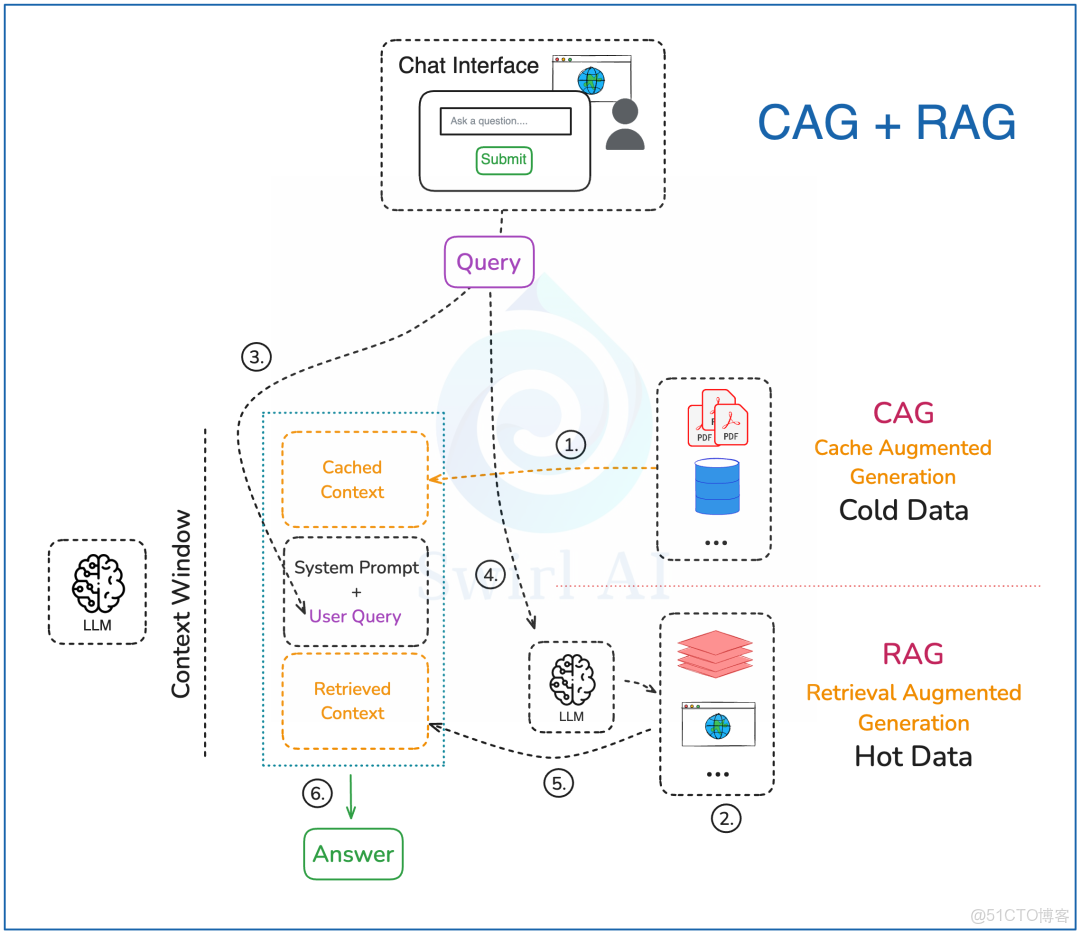
數據預處理
- 在 CAG 中,我們只使用變化不大的數據源。除了要求數據更新不頻繁,我們還會考慮哪些數據源最常被查詢用到。確定了這些信息後,我們才會把所有選定的數據預先計算好,存到 LLM 的緩存裏,並緩存在內存中。這個計算只需要做一次,之後就可以多次使用,不需要重新計算。
- 對於 RAG,如果需要,我們可以把向量嵌入預先計算好,存到兼容的數據庫裏,供之後檢索用。有時候對於RAG來説,只需要更簡單的數據類型,常規數據庫就足夠了。
查詢路徑
- 構建一個包含用户提問和系統提示詞的提示詞,明確指導大語言模型怎麼利用緩存的信息和外部檢索到的信息。
- 把用户提問轉換成向量嵌入,用來在向量數據庫裏進行語義搜索,並從存儲中檢索相關數據。如果不需要語義搜索,就查詢其他來源,比如實時數據庫或互聯網。
- 把步驟4中獲取的外部信息整合到最終的提示詞中,以提高回答的質量。
- 把最終生成的答案返回給用户。
接下來,我們將探討最新的技術發展方向--Agentic RAG。
Agentic RAG 架構設計
Agentic RAG 引入了兩個新的關鍵部分,目的是在處理複雜的用户問題時,讓結果更加穩定可靠。
這兩個部分是:
- 數據源選擇(Data Source Routing)。
- 答案檢查和調整(Reflection)。
下面我們看看這兩個部分是怎麼工作的。
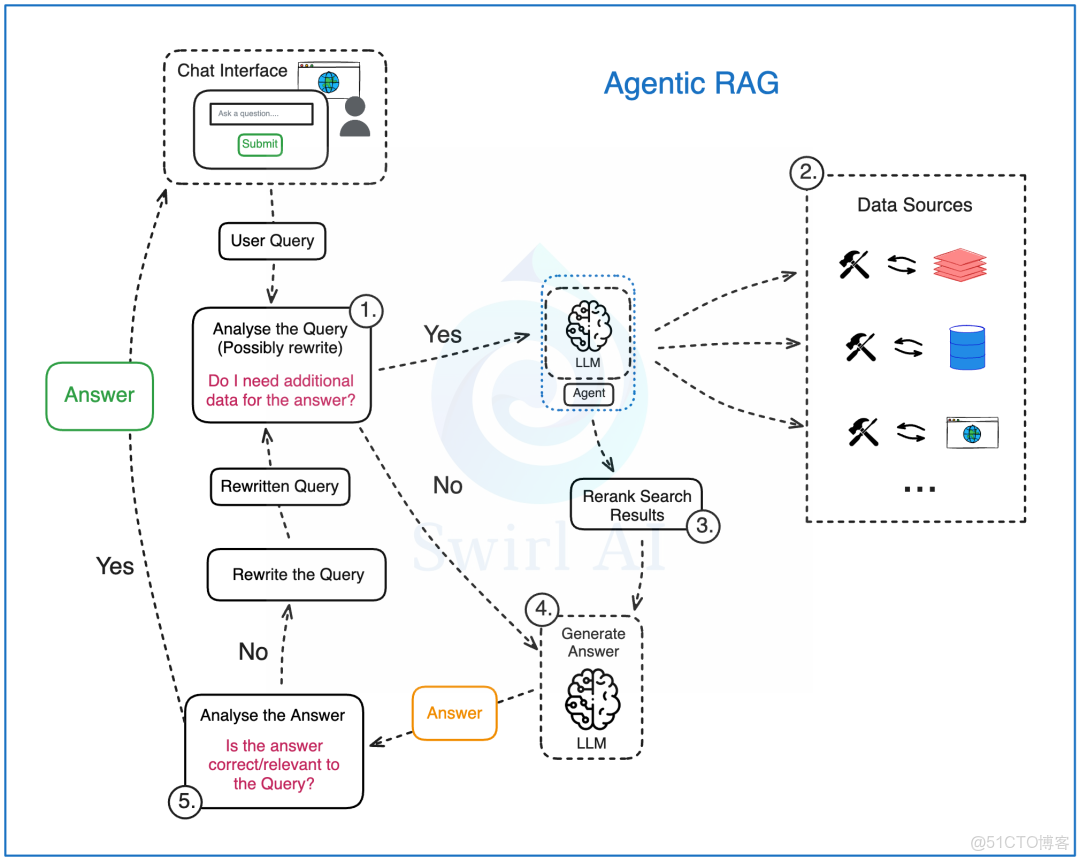
Agentic RAG 的工作流程:
- 分析用户的問題:把用户的問題交給一個基於大語言模型的智能助手來分析。在這個階段:
- 原始問題可能會被改寫,有時候需要改寫好幾次,最後變成一個或幾個新的問題,送到下一步處理。
- 智能助手會判斷是否需要額外的數據來回答這個問題。這是它展現自主決策能力的第一步。
- 如果需要其他數據,就會開始檢索步驟,這時會進行數據源選擇。系統裏可以預先設置一個或多個數據集,智能助手可以自己選擇哪個數據源最適合當前的問題。比如:
- 實時的用户數據(比如:用户現在的位置)。
- 用户可能感興趣的內部文件。
- 網絡上的公開數據。
- 一旦從多個數據源中檢索到數據,我們就會像在普通的 RAG 中一樣對這些數據進行重新排序。這也是一個關鍵步驟,因為不同存儲技術的數據源都可以整合到這個 RAG 系統中。檢索過程的複雜性都被智能助手用的工具所隱藏。
- 嘗試直接用大語言模型生成答案(可能是一個答案,也可能是多個答案,或者是一組操作指令)。這個過程可以在第一輪就完成,或者在答案檢查和調整之後進行。
- 對生成的答案進行檢查,總結並評估它們的正確性和相關性:
- 如果智能助手認為答案已經很好,就直接返回給用户。
- 如果智能助手覺得答案還需要改進,就會嘗試重新改寫用户的問題,並重復這個生成循環。這是 Agentic RAG 和 Naive RAG 的第二個主要區別。
最近,Anthropic 的開源項目 MCP,將會大大推動 Agentic RAG 的開發。
總結
我們已經回顧了檢索增強生成(RAG)技術的發展過程。RAG 技術不僅沒有過時,而且我認為它在未來還會繼續發展。掌握這些技術架構,並知道什麼時候該用哪種方案,會是一筆很值得的投資。
通常來説,方案越簡單越好,因為系統的複雜性增加會帶來新的挑戰。一些新出現的挑戰包括:
- 評估整個系統從開始到結束的性能變得困難。
- 多次調用大語言模型導致整個過程的延遲變長。
- 運營成本也隨之增加。
總之,雖然 RAG 技術在不斷進步,但我們在選擇和應用時,還是需要考慮到這些新挑戰。