
這篇博客是繼續Chainlit+LlamaIndex實戰教學,帶你從零搞定一個多模態RAG系統。啥是RAG?簡單説,就是讓AI不光會聊天,還能從你的文件堆裏挖寶——PDF裏的表格、PPT的幻燈片、圖片的隱藏秘密,全都一網打盡。想想看,你的AI助手像個超級偵探,能從亂七八糟的文檔中提取情報,還能生成聰明回答。這不比純文本聊天有趣多了?接下來我們就正式開始講解。
一、學習內容總覽
先來個大地圖,免得你迷路。這個系統不是科幻小説,而是實打實的Python項目。核心分成兩大部分:
- 多模型RAG系統架構(核心:視覺大模型+大語言模型框架+向量數據庫協同) 這裏是系統的“大腦”。我們用視覺大模型處理圖像和圖表,用LlamaIndex框架管理文檔索引,再加向量數據庫存向量數據。簡單説,就是讓AI“看懂”你的文件,而不是瞎猜。
- 多模態RAG功能實現(覆蓋模塊開發:multimodal_rag.py核心邏輯、工具類、模型配置、界面集成) 這是“動手”部分。從代碼到界面,全鏈路教你怎麼實現。包括處理PDF/PPT/圖片的模塊、輔助工具、模型集成、環境變量配置,還有Chainlit做的前端聊天UI。學完這個,你能自己搭個AI聊天機器人,上傳文件就能問答。
為什麼有趣?因為傳統RAG只管文本,現在我們升級到多模態——AI能“看到”圖片裏的貓,還能解釋表格裏的數據。幽默點説,以前AI是“盲人摸象”,現在它戴上了VR眼鏡!
二、多模型 RAG 系統架構
好了,進入正題。先聊架構,這就像建房子,得先畫藍圖。我們的系統結合了視覺大模型(處理圖像)、大語言模型框架(LlamaIndex主打,Langchain輔助),加上向量數據庫Milvus。用户輸入提示詞,系統處理多模態數據(文本/圖像/表格),然後生成響應。聽起來複雜?別慌,我畫個圖給你看(其實是借來的示意圖,哈哈)。
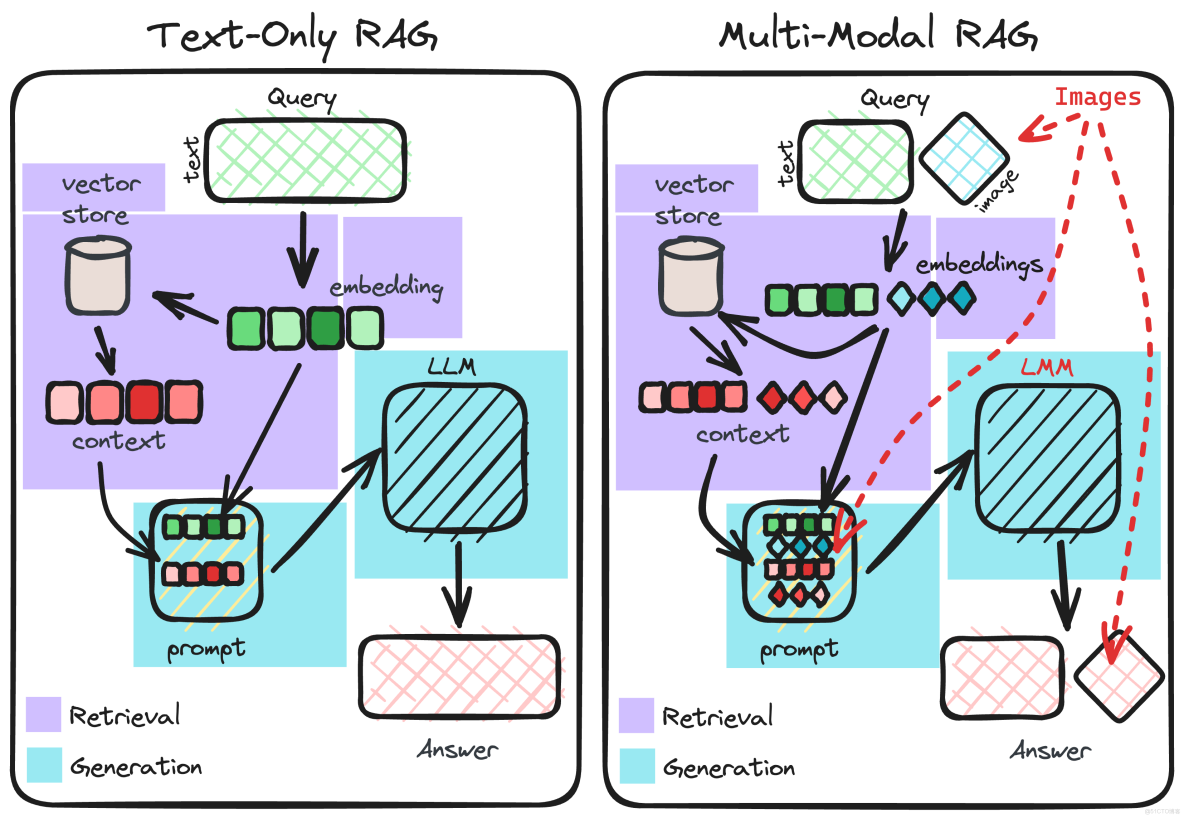
text-only RAG vs. 多模態 RAG對比圖——看,多模態多了一雙眼睛!
2.1 多模態 RAG 系統核心組成
- 視覺大模型:負責圖像 / 圖表處理,含兩大場景 圖表 / 繪圖解析:提取數據趨勢,比如從柱狀圖裏讀出銷售額增長。 圖片識別:處理截圖、掃描件,比如識別手寫筆記。 為什麼需要?因為純文本AI看不懂圖片啊!這部分我們用多模態模型來“翻譯”圖像成文本描述。
- 大語言模型開發框架:雙框架支撐 LlamaIndex:核心底座,負責文檔切塊、索引管理。像個高效的文件管理員。 Langchain:輔助重排數據,優化檢索結果。幽默地説,它是“排序小能手”,讓AI回答更準不亂套。
- 核心組件層:四大關鍵模塊 文本嵌入模型:把文本/圖像描述轉成向量(數字表示),方便搜索。 基礎大語言模型:生成響應,比如DeepSeek或Moonshot——它們像聊天高手。 向量數據庫:Milvus,存多模態向量。為什麼Milvus?它快如閃電,支持海量數據。 重排數據:優化結果順序,提升精準度。避免AI先告訴你無關緊要的事。
- 用户交互流程:提示詞輸入→多模態數據處理(文本 / 圖像 / 表格)→生成響應 用户上傳文件,系統解析、索引,然後根據查詢檢索相關片段生成回答。整個過程異步高效,不會讓你等得花兒謝。

一個典型的多模態RAG流程圖:從Medium文章到AI回答,全鏈路可視化。
2.2 多模態模型選型
選模型就像選手機,得看需求和預算。我們有在線和開源兩種:
- 在線多模態對話模型 模型名稱:通義千問 VL-Plus 官方地址:https://www.aliyun.com/product/bailian 核心優勢:支持多類型圖像解析,無需本地部署。基於阿里雲的Qwen系列,它在多模態處理上很強,比如分析PDF裏的圖像或表格。適合RAG,因為它能無縫集成文檔處理。價格?按調用付費,2025年估計有免費試用層(具體查官網)。幽默地説,它像雲端保姆,不用你操心服務器。
- 開源免費多模態對話模型 模型名稱:InternVL 官方地址:https://internvl.opengvlab.com/ 核心優勢:可本地部署,無API成本,適合隱私敏感場景。InternVL擅長圖像描述和圖表分析,能在RAG中處理PPT幻燈片或掃描圖片。2025年版本可能更優化了,支持更大上下文。缺點?部署需要點硬件,但免費就是王道!
選哪個?在線的省心,開源的靈活。根據你的場景混用吧。
三、多模態 RAG 功能實現
理論説完,滾起袖子幹活!這部分是代碼實戰,從核心模塊到工具類,一步步教你實現。所有代碼基於Python,依賴LlamaIndex、PyMuPDF等庫。記住,代碼不是死的——多調試,多試錯(我試過無數次崩潰,哈哈)。
3.1 rag/multimodal_rag.py(核心邏輯模塊)
這是系統的“心臟”,處理文件生成Document對象(LlamaIndex的結構化數據單位)。
3.1.1 核心功能定位
- 處理多類型文件(PDF、PPT、圖片、文本),生成結構化Document。
- 支持異步執行,提升效率。想象一下,同時上傳10個PDF,它不會卡住。
3.1.2 關鍵函數設計
- 表格提取與處理:parse_all_tables 從PDF頁面找表格,轉成Pandas DataFrame,保存Excel。還抓表格圖像和上下文文本。避坑:加try-except,單個表格出錯不崩盤。 代碼snippet(簡化版): python
tables = page.find_tables(...)
for tab in tables:
pandas_df = tab.to_pandas()
# 保存Excel,生成描述,建Document
artifex.com
用PyMuPDF提取PDF表格的示例——從混亂到有序!
- 圖像提取與描述:parse_all_images 提取有效圖像(濾掉小圖),保存,調用describe_image生成描述。加元數據如來源、頁碼。 代碼tip:用fitz.Rect獲取bbox,過濾width < page.width / 20的噪音圖。
- PDF 文件全處理:process_pdf_file 提取文本(跳頁眉頁腳)、表格、圖像。分組文本塊避免過長。整合成Document列表。
- PPT 文件處理:process_ppt_file 先轉PDF,再轉圖像,提取文本/備註,生成描述。完美處理幻燈片。
- 異步數據加載:load_data 按文件類型分流,異步run_jobs處理。返回Document列表。效率翻倍!
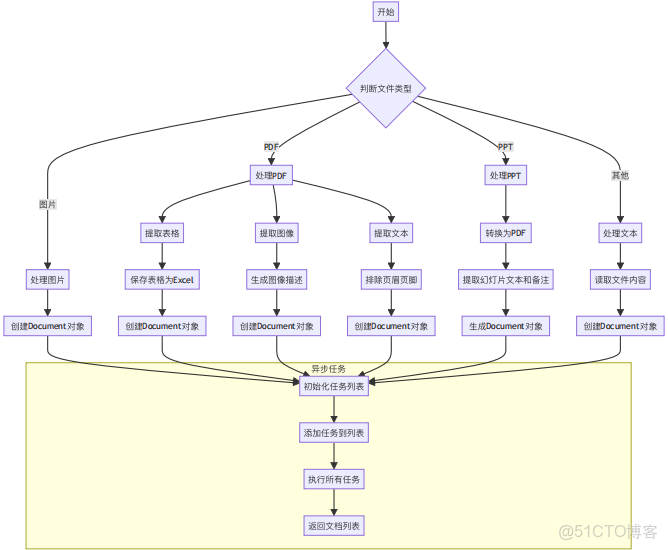
3.1.3 控制流與流程説明
load_data收文件列表 → 判斷類型 → 調用對應函數 → 異步執行 → 返回Documents。流程圖:
3.2 rag/utils.py(多模態工具類)
輔助函數庫,像瑞士軍刀。
import base64
import os
import subprocess
from io import BytesIO
from pathlib import Path
import fitz
from PIL import Image
from pptx import Presentation
from .config import RagConfig
from .llms import moonshot_llm, vllm, deepseek_llm
from .ocr import ocr_file_to_text
def ocr_file_to_text_llm(file_path) -> str:
"""
提取⽂件中的⽂本
:param file_path:
:return:
"""
client = moonshot_llm()
file_object = client.files.create(file=Path(file_path), purpose="file
-extract")
file_content = client.files.content(file_id=file_object.id).json()
return file_content.get("content")
def get_b64_image_from_path(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def is_image(file_path):
try:
with Image.open(file_path) as img:
img.verify() # 驗證⽂件是否是有效的圖像
return True
except Exception as e:
print(f"Error: {e}")
return False
def process_table(file):
"""
解析表格:
1、藉助ocr直接識別表格內容
2、藉助多模態⼤模型識別
:param file:
:return: 表格內容及對錶格的描述信息
"""
content = ocr_file_to_text_llm(file)
llm = deepseek_llm()
response = llm.complete(f"你的職責是解釋表格。"
f"你是將線性化表格轉換成簡單中⽂⽂本供⼤型語⾔模型(L
LMs)使⽤的專家。"
f"請解釋以下線性化表格: {content}")
return content, response.tex3.2.1 核心工具函數分類
- 圖像處理工具:describe_image用VLLM API描述圖像;get_b64_image_from_path轉Base64;is_image驗證文件。
- 表格處理工具:process_table OCR+DeepSeek解釋表格。
- 文本輔助工具:extract_text_around_item抓上下文;process_text_blocks分組文本。
- 格式轉換工具:convert_ppt_to_pdf用LibreOffice轉格式;convert_pdf_to_images轉圖像;extract_text_and_notes_from_ppt抓PPT內容;save_uploaded_file存文件。
3.3 rag/llms.py(多模態模型配置)
集成模型:vllm for VLLM(圖像描述);moonshot_llm for OCR;deepseek_llm for 解釋。更新模型字典支持大上下文。
from typing import Dict
from llama_index.llms.openai import OpenAI as DeepSeeK
from openai import OpenAI
from .config import RagConfig
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODEL
S
DEEPSEEK_MODELS: Dict[str, int] = {
"deepseek-chat": 64000,
}
ALL_AVAILABLE_MODELS.update(DEEPSEEK_MODELS)
CHAT_MODELS.update(DEEPSEEK_MODELS)
def moonshot_llm(**kwargs):
llm = OpenAI(api_key=RagConfig.moonshot_api_key,
base_url="https://api.moonshot.cn/v1",
**kwargs)
return llm
def deepseek_llm(**kwargs):
llm = DeepSeeK(api_key=RagConfig.deepseek_api_key,
model="deepseek-chat",
api_base="https://api.deepseek.com/v1",
temperature=0.7,
**kwargs)
return llm
def vllm(**kwargs):
from openai import OpenAI
llm = OpenAI(api_key=RagConfig.vllm_api_key,
base_url=RagConfig.vllm_base_url,
**kwargs)
return llm3.4 .env 環境變量(多模態配置新增)
新增VLLM_API_KEY、VLLM_BASE_URL、VLLM_MODEL_NAME。其他如Milvus URI。安全第一,別硬碼密鑰!
3.5 rag/config.py(多模態配置集成)
Pydantic類管理配置,單例模式。新增VLLM參數,默認從.env取。
import os
from pydantic import BaseModel, Field
class RAGConfig(BaseModel):
"""
RAG配置模型。
該模型使⽤Pydantic庫來定義和驗證配置參數。每個字段都設置了默認值和描述,
以便於理解和維護。這些配置參數對於RAG系統的運⾏⾄關重要,包括數據庫連接、
模型維度、API密鑰等。
"""
# Milvus URI,⽤於數據庫連接
milvus_uri: str = Field(default=os.getenv("MILVUS_URI"), description=
"Milvus URI")
# 嵌⼊模型維度
embedding_model_dim: int = Field(default=512, description="Embedding m
odel dimension")
# Moonshot API密鑰
moonshot_api_key: str = Field(default=os.getenv("MOONSHOT_API_KEY"), d
escription="Moonshot API key")
# DeepSeek API密鑰
deepseek_api_key: str = Field(default=os.getenv("DEEPSEEK_API_KEY"), d
escription="DeepSeek API key")
# Postgres數據庫連接字符串
pg_connection_string: str = Field(default=os.getenv("PG_CONNECTION_STR
ING"), description="Postgres connection string")
# OCR下載⽬錄
ocr_download_dir: str = Field(default=os.getenv("OCR_DOWNLOAD_PATH"),
description="OCR download directory")
# OCR基礎URL
ocr_base_url: str = Field(default=os.getenv("OCR_BASE_URL"), descripti
on="OCR base URL")
# VLLM API密鑰
vllm_api_key: str = Field(default=os.getenv("VLLM_API_KEY"), descripti
on="VLLM API key")
# VLLM基礎URL
vllm_base_url: str = Field(default=os.getenv("VLLM_BASE_URL"), descrip
tion="VLLM base URL")
# VLLM模型名稱
vllm_model_name: str = Field(default=os.getenv("VLLM_MODEL_NAME"), des
cription="VLLM model name")
# 實例化RAGConfig對象---單例模式
RagConfig = RAGConfig()3.6 chainlit_ui.py(多模態界面集成)
前端用Chainlit,超級簡單。(因為代碼太多了,可以去找我要源碼,這裏的話,主要是一些展示代碼)
import random
from typing import Optional, List
# 導⼊chainlit庫,⽤於構建和部署AI應⽤
import chainlit as cl
# 導⼊chainlit的數據模塊,⽤於處理數據相關的操作
import chainlit.data as cl_data
# 從chainlit.element模塊中導⼊ElementBased類,⽤於創建基於元素的組件
from chainlit.element import ElementBased
# 從chainlit.input_widget模塊中導⼊Select和Switch類,⽤於創建選擇和開關輸⼊組件
from chainlit.input_widget import Select, Switch
# 從chainlit.types模塊中導⼊ThreadDict類,⽤於定義線程字典類型
from chainlit.types import ThreadDict
# 導⼊dotenv庫,⽤於加載環境變量
from dotenv import load_dotenv
# 從llama_index.core.base.llms.types模塊中導⼊ChatMessage類,⽤於定義聊天消息
類型
from llama_index.core.base.llms.types import ChatMessage
# 從llama_index.core.chat_engine模塊中導⼊SimpleChatEngine類,⽤於實現簡單的聊
天引擎
from llama_index.core.chat_engine import SimpleChatEngine
# 從llama_index.core.chat_engine.types模塊中導⼊ChatMode類,⽤於定義聊天模式
from llama_index.core.chat_engine.types import ChatMode
# 從llama_index.core.memory模塊中導⼊ChatMemoryBuffer類,⽤於創建聊天記憶緩衝區
from llama_index.core.memory import ChatMemoryBuffer
# 導⼊⾃定義模塊以⽀持特定功能
from persistent.minio_storage_client import MinioStorageClient
from persistent.postgresql_data_layer import PostgreSQLDataLayer
from rag.base_rag import RAG
from rag.config import RagConfig
from rag.multimodal_rag import MultiModalRAG
from rag.traditional_rag import TraditionalRAG
from utils.milvus import list_collections
# 加載環境變量,⽤於配置應⽤程序
load_dotenv()
# 實例化MinIO存儲客户端,⽤於與MinIO對象存儲服務交互
storage_client = MinioStorageClient()
# 配置Chainlit數據層以使⽤PostgreSQL和MinIO進⾏數據持久化
cl_data._data_layer = PostgreSQLDataLayer(conninfo=RagConfig.pg_connectio
n_string, storage_provider=storage_client)
async def view_pdf(elements: List[ElementBased]):
"""查看PDF⽂件"""
files = []
contents = []
for element in elements:
if element.name.endswith(".pdf"):
pdf = cl.Pdf(name=element.name, display="side", path=element.
path)
files.append(pdf)
contents.append(element.name)
if len(files) == 0:
return
await cl.Message(content=f"查看PDF⽂件:" + ",".join(contents), elemen
ts=files).send()
@cl.set_chat_profiles
async def chat_profile(current_user: cl.User):
if current_user.metadata["role"] != "admin":
return None
# 知識庫信息最後存儲在關係數據庫中:名稱,描述,圖標
kb_list = list_collections()
profiles = [
cl.ChatProfile(
name="default",
markdown_description=f"⼤模型對話",
icon=f"/public/kbs/4.png",
)
]
for kb_name in kb_list:
profiles.append(
cl.ChatProfile(
name=kb_name,
markdown_description=f"{kb_name} 知識庫",
icon=f"/public/kbs/{random.randint(1, 3)}.jpg",
)
)
return profiles3.6.1 核心界面功能新增
- 多模態開關:設置面板Switch,默認開。
- 展示:圖像inline顯示,來源side顯示。
- 其他:知識庫選擇、Starters提示、恢復對話、密碼認證。

docs.chainlit.io
Chainlit文件上傳界面——拖拽就好,簡單!
3.6.2 關鍵邏輯:多模態 RAG 調用
main函數判斷開關,用MultiModalRAG或TraditionalRAG創建索引。上傳文件後流式響應,還顯示來源。
4.2 依賴安裝命令
核心:pip install pymupdf python-pptx pillow openai libreoffice-python。 原有:pip install pymilvus llama-index-vector-stores-milvus chainlit python-dotenv llama-index-embeddings-huggingface。
結語:這個系統不光實用,還能讓你在AI開發中脱穎而出。試試吧,説不定你的下一個項目就靠它了!有問題評論區見,保持好奇,繼續coding。