
作者 | VVingerfly
3D人體姿態和形狀估計在最近幾年是一個重要的研究熱點,但大部分工作僅僅關注人體部分,忽略了手部動作,港中文聯合Facebook AI研究院提出了一種從單張圖片同時估計人體姿態和手部動作的新方法,展示效果好似科學怪物。

如下圖左下和右下所示,易看出本文提出的方法姿態估計效果更好。

1
介紹
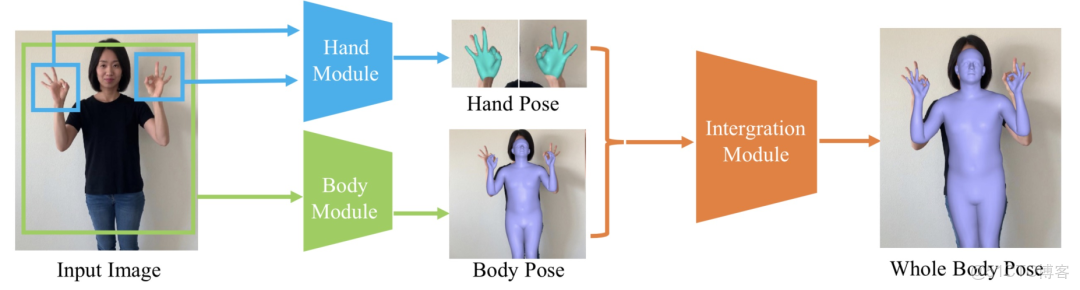
本文作者提出了一個3D人體全身運動捕捉系統 FrankMocap,能夠從單目視頻同時估計出3D人體和手部運動,在一塊GeForce RTX 2080 GPU上能夠達到 9.5 FPS。作者提到 “FrankMocap” 是對現代普羅米修斯 (The Modern Prometheus)中科學怪人 (Frankenstein) 的怪物的致敬。
人們每天會拍大量的日常活動視頻上傳到網絡,如果有一種基於普通攝像頭的運動捕捉系統,能夠捕捉視頻中人體的運動,將在人機交互、人工智能、機器人等眾多方向有所應用。
同時捕捉人體和人手的運動對這些應用同樣重要,但人手只佔身體的很小一部分,要想直接捕捉兩者的運動是一個很難的問題。當前的大部分相關工作都只顧及圖片中人體的3D姿態,忽略圖片中人手的動作。有部分工作關注從單張圖片同時估計人體的全身運動,但這些工作都是基於優化的方法,將參數化的人體模型擬合到圖像信息,速度較慢不適合實時應用。
這篇文章提出了一個快速準確的方法來從RGB圖片或視頻估計人體和人手的姿態。作者採用 SMPL-X 人體模型,首先通過兩個迴歸模塊來從輸入圖片分別估計人體和人手的3D姿態,然後再通過一個整合模塊將預測的結果組合在一起,得到最終的3D全身人體。文章代碼將會開源。

2
方法
作者使用 SMPL-X 人體模型,給定一張彩色圖片,通過兩個網絡模塊分別預測手部姿態和人體姿態,然後再通過整合模塊將手和身體組合在一起,得到最終的3D全身模型,整個流程如下圖所示。
SMPL-X 模型
SMPL-X 人體模型是一個參數化的3D人體模型,是 SMPL 模型的擴展,能夠通過低維的人體形狀和姿態參數的組合來表達不同形狀和姿態的3D人體,其與 SMPL 模型的最大差異在於 SMPL-X 模型通過引入額外參數,能夠同時表達人體的手指運動和麪部表情。
SMPL-X 人體模型可以用如下數學公式來表達:
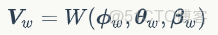
這裏

是人體的整體旋轉,
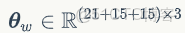
是人體姿態相關的變形參數,

是人體和人手形狀相關的參數。作者將姿態參數
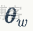
拆分為人體相關的參數

和左右手相關的參數

、

,所以
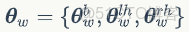
。所有的姿態參數由軸角表達,是某關節點相對於其父節點的相對旋轉。最終得到的 SMPL-X 人體模型包含 10,745 個頂點

。人體關節點的3D位置可以通過在頂點上作用關節點回歸矩陣 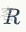

這裏
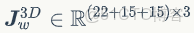
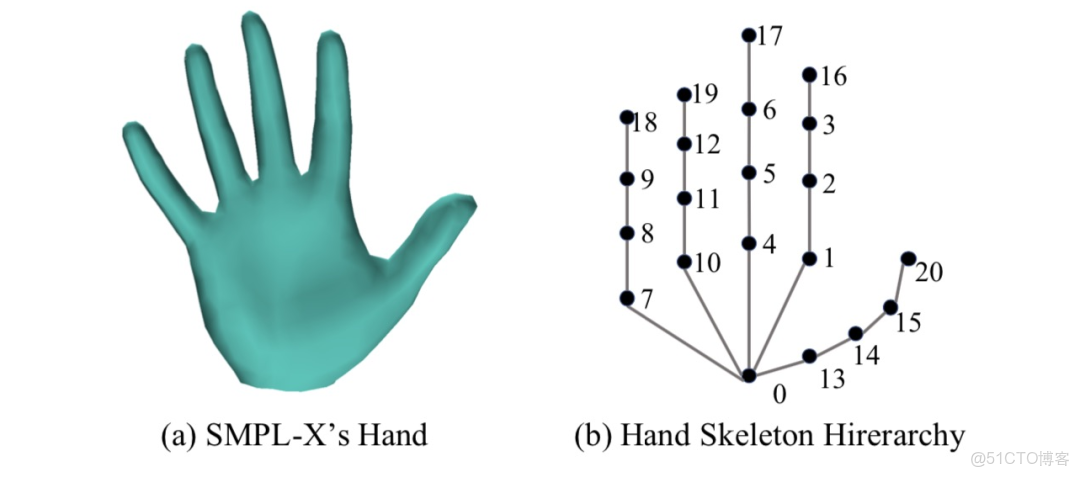
。人手模型來自 SMPL-X 的手部,定義為
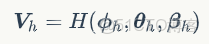
其中

是手的姿態參數,
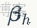
是手的形狀參數,

是手的整體旋轉。最終手部的網格包含 788 個頂點,即

,其中

的一個子集。同樣手部關節點的位置可以通過關節點回歸矩陣計算得到

這裏

包含一個手腕關節點、15個手指關節點和5個指尖點。手部網格和骨架層級關係如下圖所示:
3D手部估計模塊
手部預測模塊基於一個端到端的神經網絡,直接回歸手部姿態參數,其定義如下:

其
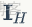
是從輸入圖像中截取的手部區域圖片塊,
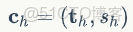
是弱透視投影的相機參數,能夠將手部模型投影到輸入圖像。
網絡架構
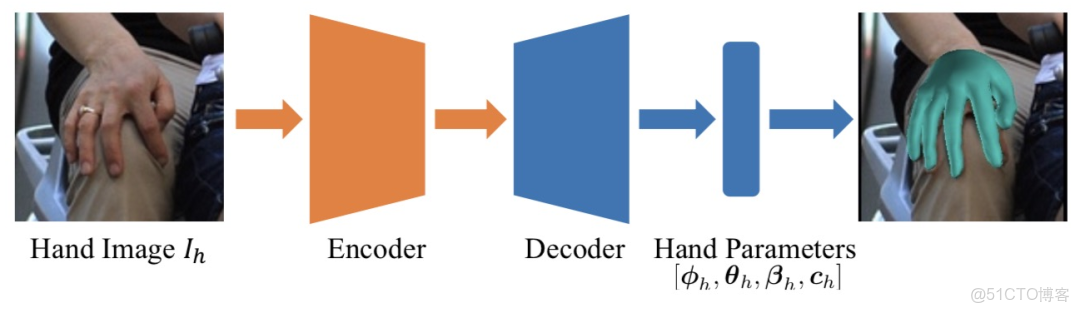
手部模塊的架構如下圖所示,其由一個編碼器和解碼器組成,編碼器使用 ResNet-50,將手部圖像塊作為輸入輸出編碼的圖像特徵,解碼器由全連接層構成,從圖像特徵迴歸手部模型參數。
損失函數
手部姿態和形狀估計的網絡訓練時使用的損失函數主要由4個部分組成:
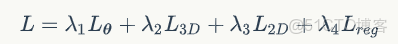
其中
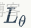
是在有3D人體參數時的關節點軸角損失:


是3D關節點標註數據時添加的關節點損失:
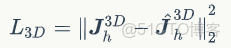

是2D關節點損失,其對預測相機參數非常重要:
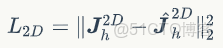

是手部形狀參數的正則項,用於懲罰不自然的手部形狀。
3D手部姿態數據集
3D手部姿態數據集通常是在受限的實驗室環境下采集的,用這些數據集訓練的模型經常會遇到過擬合的問題,在室外數據表現較差。
作者注意到,現有3D人體姿態估計方法表明利用不同的數據集可以大大提高模型的泛化能力,因此作者使用盡可能多的公開數據集來訓練手部姿態估計網絡,包括 FreiHAND、HO-3D、MTC (Monocular Total Capture) 、STB (Stereo Hand Pose Tracking Benchmark)、RHD (Rendered Hand Dataset)、MPII+NZSL 數據集。由於部分數據集的手部骨架與文字不同,作者以中指長度為參考,對這些數據集的3D手部關節點縮放到與文章手部模型近似一致的尺寸,並將關節點順序按照文章的層次結構重新排列。
3D人體估計模塊
3D人體姿態和形狀估計網絡參考自 SPIN 的網絡結構,SPIN 是一個從單張圖片估計 SMPL 人體模型參數的 SOTA 的方法,作者將其輸出從 SMPL 的參數修改為 SMPL-X 模型參數,並對網絡進行了微調。3D人體姿態估計模塊的定義如下
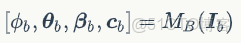
其中
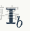
是從輸入圖像中截取的人體部分,

分別是人體全局旋轉、人體姿態參數和人體形狀參數。同樣這裏使用弱透視投影相機參數
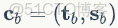
。
損失函數和數據集
3D人體估計網絡使用了 Human3.6M 數據集和 EFT 數據集,其中 EFT 數據集包含 COCO 和 MPI 中的人體圖片及其對應的 SMPL 模型參數。由於 SMPL 的形狀參數和 SMPL-X 不兼容,作者在訓練時只使用這些數據集的人體姿態參數。損失函數和 SPIN 原始論文中使用的一樣,但是沒用使用 SMPLify 損失部分。
全身整合模塊
整合模塊將3D人體和手部模塊輸出的結果組合在一起得到 SMPL-X 模型的參數表達,作者提供了兩種方法來整合:
- 複製粘貼方式:直接將人體和手部組合起來,速度快;
- 優化擬合方式:使用2D關鍵點來優化人體參數以得到更加準確的結果,但速度較慢。
複製粘貼組合
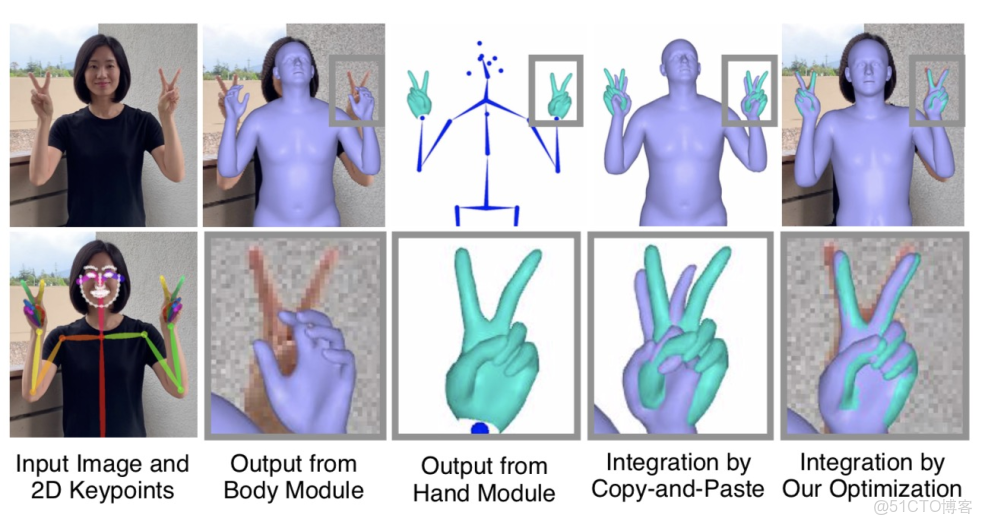
由於人體和手部模塊的輸出與 SMPL-X 人體模型的參數是兼容的,因此可以很簡單地將兩者合併在一起。只需將左右手從世界座標系變換到人體模型腕關節的局部座標系下即可。
優化擬合方式
優化擬合方式通過優化人體模型的參數來擬合人體的2D關鍵點,以得到與圖片更加對齊、更加準確的人體網格。優化的目標函數如下:
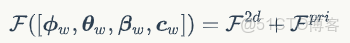
這裏
是3D關鍵點的投影與目標圖像中檢測的2D關鍵點之間的投影誤差,

是一個先驗項,使得人體的姿態和形狀參數處在一個合理的範圍。作者參考 EFT[3] 文章中的方法,通過微調網絡來最小化目標函數,只需迭代少數幾次便能得到不錯的結果。
下圖展示了複製粘貼組合和優化擬合組合兩種方法的結果對比,可以看到優化後人體的姿態更加準確,但速度會有所下降。
3
結果
下面表格展示了文章方法和其他方法的運行時間對比,文章的複製粘貼組合方式在 GeForce RTX 2080 GPU 上能夠達到9.5FPS,優化的方法也有0.95FPS,均高於 SMPLify-X 和 MTC 方法。

下圖展示了文章方法在手部姿態估計方面與當前 state-of-the-art 的方法的比較,文章方法的結果更加準確,與圖片更加一致。

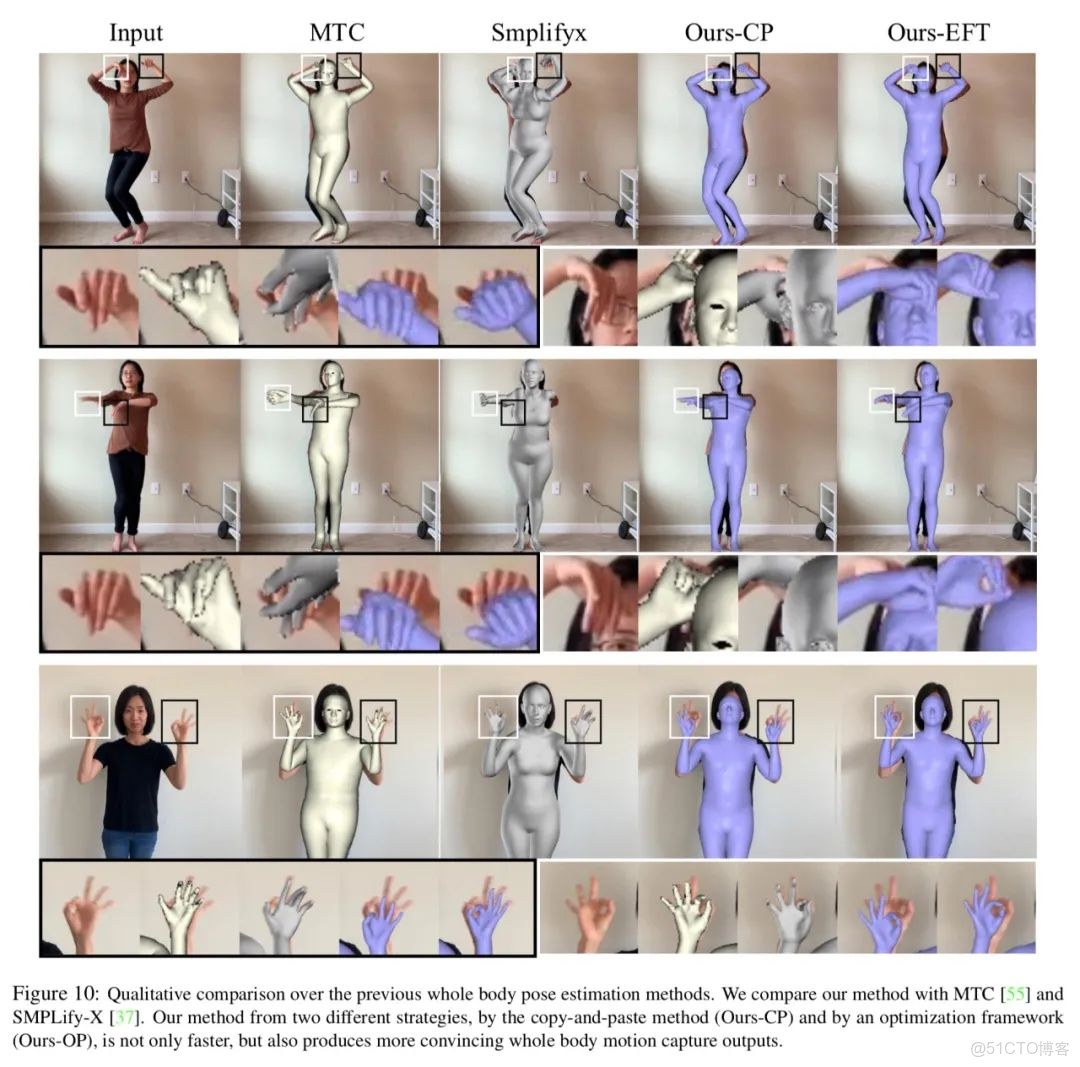
下圖展示了文章方法和 Monocular Total Capture,SMPLify-X 結果的比較,文章方法估計的人體、人手姿態更加準確,而且速度會快很多。
更多演示結果
不如跳舞~

熟練地玩抽紙~

倒杯水喝~

參考論文
- FrankMocap: A Fast Monocular 3D Hand and Body Motion Capture by Regression and Integration. Yu Rong, Takaaki Shiratori, Hanbyul Joo. ArXiv, 2020.
- Expressive Body Capture: 3D Hands, Face, and Body from a Single Image. Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. CVPR, 2019.
- Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation. Hanbyul Joo, Natalia Neverova, Andrea Vedaldi. ArXiv, 2020.