
AsyPPO: 輕量級mini-critics如何提升大語言模型推理能力
大型語言模型強化學習訓練面臨計算瓶頸,傳統對稱actor-critic架構導致critic模型參數量巨大,訓練成本高昂。本文介紹的Asymmetric Proximal Policy Optimization (AsyPPO)算法通過創新的非對稱架構設計,使用輕量級mini-critics組合實現高效價值估計,在保持性能的同時顯著降低計算開銷。實驗表明,該方法在多個數學推理基準上平均提升超過3%準確率,訓練內存佔用減少20%,每步訓練時間縮短約20秒。
文章核心
研究背景:
在大型語言模型強化學習訓練中,傳統PPO算法採用的對稱actor-critic架構面臨嚴峻挑戰。由於LLM參數規模巨大,與actor同等規模的critic模型導致計算開銷呈指數級增長,訓練成本難以承受。此外,在稀疏獎勵和長推理軌跡場景下,大規模critic訓練往往效果不佳且易於過擬合。為應對這些挑戰,當前主流方法如GRPO等選擇放棄critic,轉而使用平均優勢基線進行粗粒度估計,但這犧牲了穩健狀態價值估計帶來的訓練穩定性優勢。如何在保持計算效率的同時恢復critic的關鍵作用,成為RL4LLM領域亟待解決的核心問題。
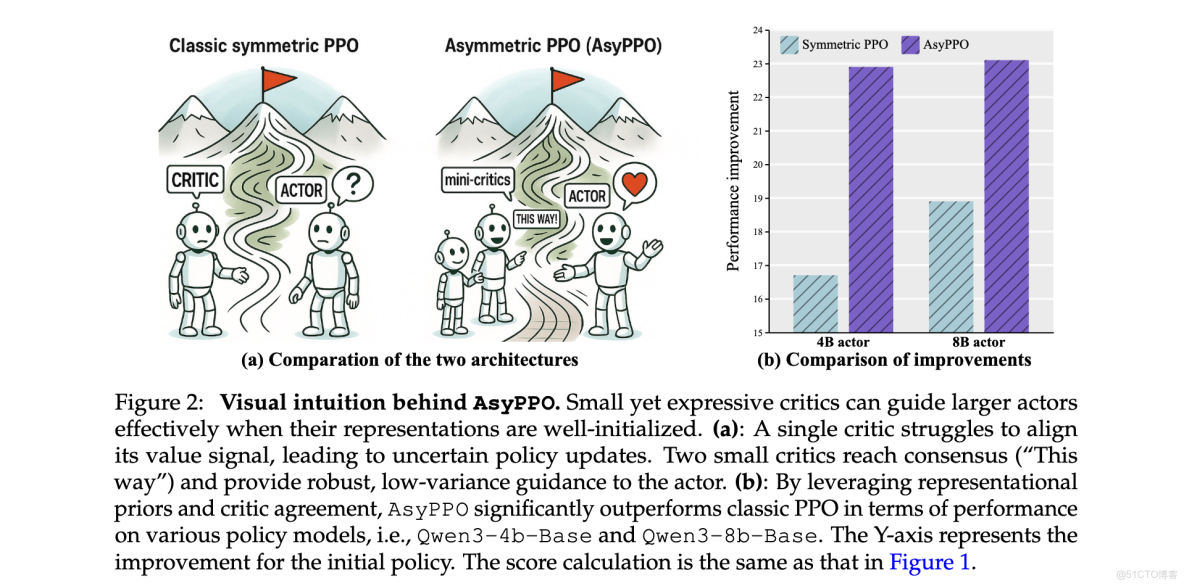
研究問題:
- 計算效率瓶頸:傳統對稱PPO架構中critic模型參數量與actor相當,在LLM規模下導致訓練內存和時間開銷巨大
- 價值估計準確性:單個輕量級critic在稀疏獎勵和長推理軌跡場景下價值估計偏差較大,難以提供有效指導
- 樣本利用效率:現有方法缺乏有效的樣本質量評估機制,導致低信息樣本造成的過擬合和無意義探索
主要貢獻:
- 輕量級非對稱架構:提出基於mini-critics集合的非對稱actor-critic設計,通過多個輕量級critic組合實現穩健價值估計,顯著降低計算開銷(峯值內存減少20%,訓練時間每步縮短約20秒)
- 數據分割策略:創新性地採用prompt級非重疊數據分割技術,確保每個critic學習差異化軌跡,增強ensemble多樣性同時保持感知同步性
- 不確定性感知優化:利用critic間價值估計差異作為信號,提出advantage masking和entropy filtering機制,提升樣本效率和探索安全性
- 性能顯著提升:在僅使用5,000個開源樣本訓練後,在Qwen3-4b-Base上取得超過6%的性能提升,在Qwen3-8b-Base和Qwen3-14b-Base上實現約3%的提升
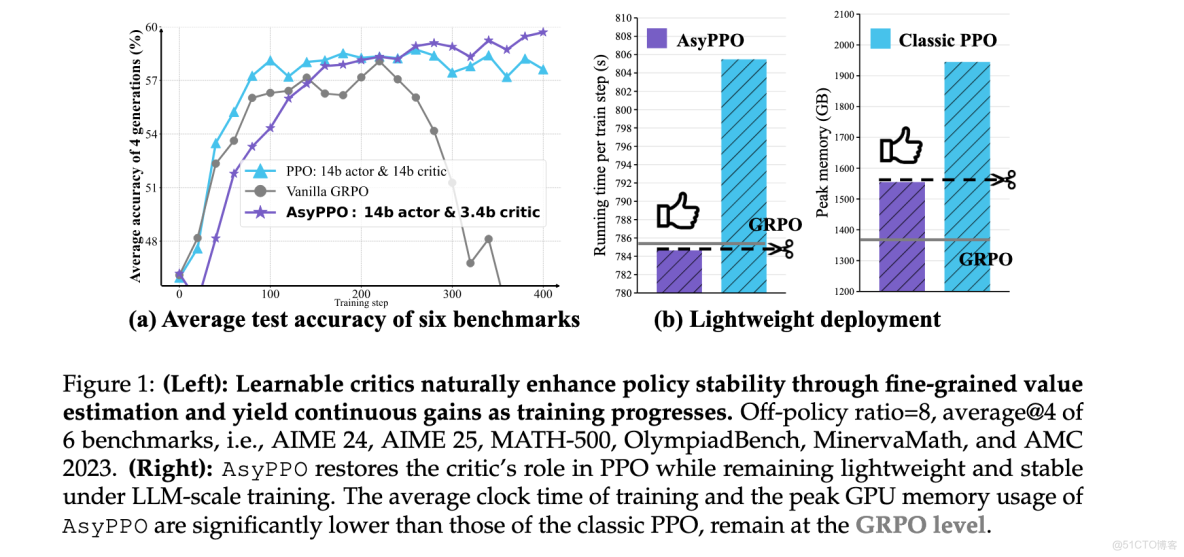
方法論精要
AsyPPO算法的核心思想是通過架構創新解決RL4LLM中的計算效率與價值估計質量之間的矛盾。該方法包含三個關鍵組件:輕量級mini-critics集合、非重疊數據分割策略和不確定性感知的policy優化目標。
輕量級非對稱架構設計
傳統PPO採用對稱actor-critic架構,critic與actor規模相當,這在LLM場景下造成巨大計算負擔。AsyPPO突破性地採用非對稱設計,使用多個輕量級mini-critics指導大規模actor。研究發現,得益於預訓練模型提供的豐富表示能力,小規模critic(如Qwen3-0.6b-Base)能夠為大規模actor(如Qwen3-8b-Base)提供有意義的指導。然而,單個mini-critic由於表達能力有限,在稀疏獎勵和長推理軌跡場景下價值估計準確性不足。
為解決這一限制,AsyPPO引入critic ensemble機制。但與傳統ensemble不同,直接使用多個相同初始化的critic效果有限,因為它們往往產生幾乎相同的價值估計,缺乏必要的多樣性。實驗表明,兩個critics是效果與效率的最佳平衡點,能夠在提供可靠價值校正的同時保持較低的計算開銷。
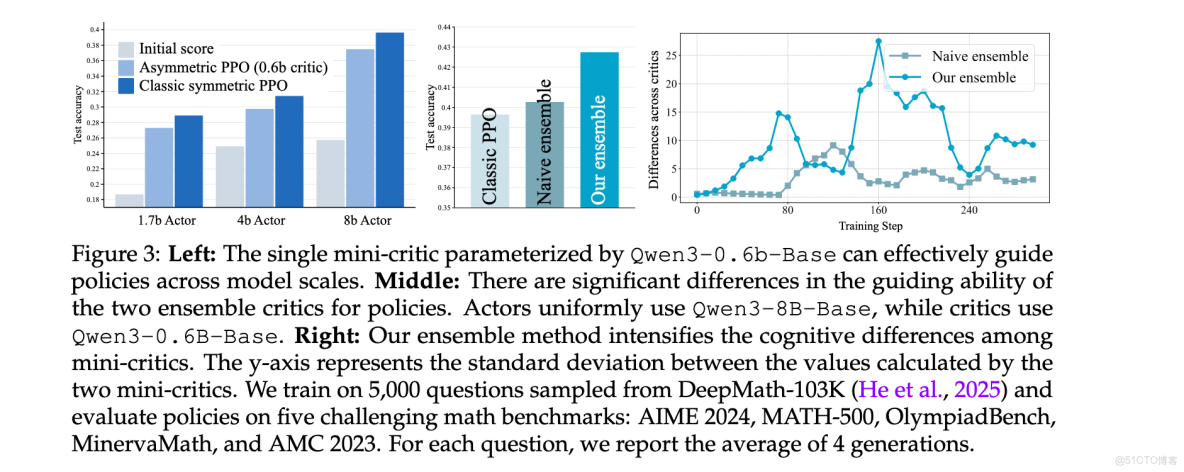
非重疊數據分割策略
為增強mini-critics之間的多樣性,AsyPPO提出創新的prompt級非重疊數據分割技術。具體而言,對於每個prompt,均勻提取響應序列分配給不同critic,確保每個critic在每個問題中都能看到完整的推理軌跡片段,同時接收差異化的獎勵信號和觀測數據。
這種設計的關鍵優勢在於維持了critics之間的感知同步性,避免了隨機數據分割可能導致的問題類型不平衡和過擬合風險。形式化地,對於M個mini-critics,訓練目標定義為:

其中


不確定性感知的policy優化
AsyPPO的另一個核心創新是利用critics間價值估計的不確定性作為信號來改進policy優化。通過分析critics價值估計的一致性和分歧模式,可以推斷狀態的信息量和探索成本。
Advantage Masking機制:當critics對某個狀態的價值估計高度一致時(標準差低),表明該狀態信息量有限,學習潛力較小。AsyPPO識別並屏蔽這些低價值-標準差狀態對應的advantage值,減少對低信息樣本的過擬合,提高訓練穩定性。具體實現為:

其中


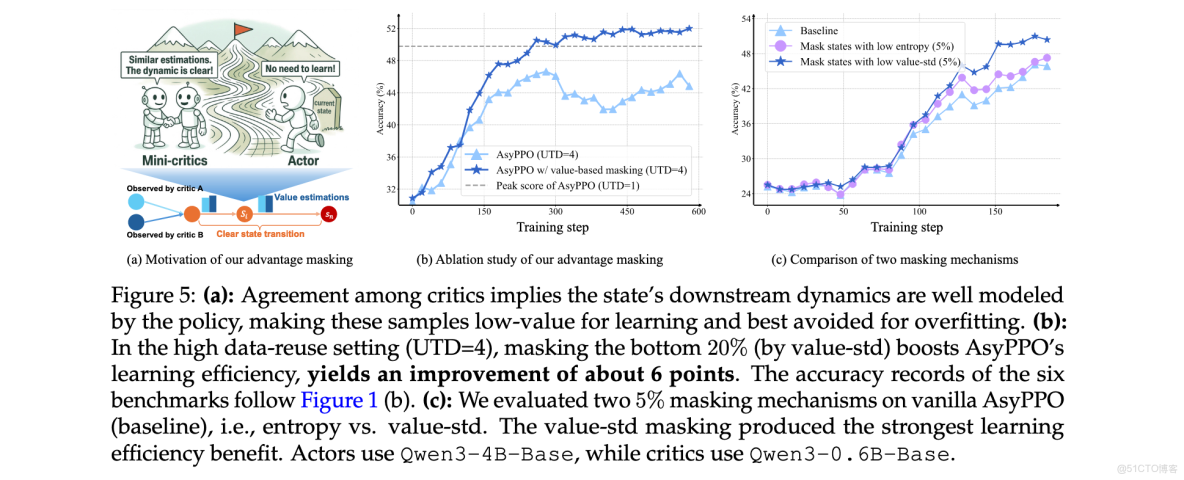
Entropy Filtering機制:當critics對某個狀態的價值估計分歧較大時(標準差高),可能表明該狀態與最終結果弱相關,包含大量推理無關的噪聲模式。在這些狀態下進行持續探索意義不大。AsyPPO從熵正則化中過濾掉高價值標準差狀態,促進更有意義的探索:

其中
算法流程
AsyPPO的完整訓練流程如Algorithm 1所示。對於每個訓練步驟,系統首先生成響應序列,然後為每個critic構建訓練子集並更新價值函數。接着計算校正後的優勢估計和不確定性指標,生成masking和filtering向量。最後使用重構的PPO損失更新policy參數。

實驗洞察
AsyPPO在多個數學推理基準上進行了全面評估,包括MATH-500、OlympiadBench、MinervaMath和AMC 2023等挑戰性任務。實驗設計圍繞三個核心研究問題展開:AsyPPO在大規模模型上的泛化能力、對critic規模和數量的敏感性,以及advantage masking和entropy filtering的最佳設置。
大規模模型泛化性能
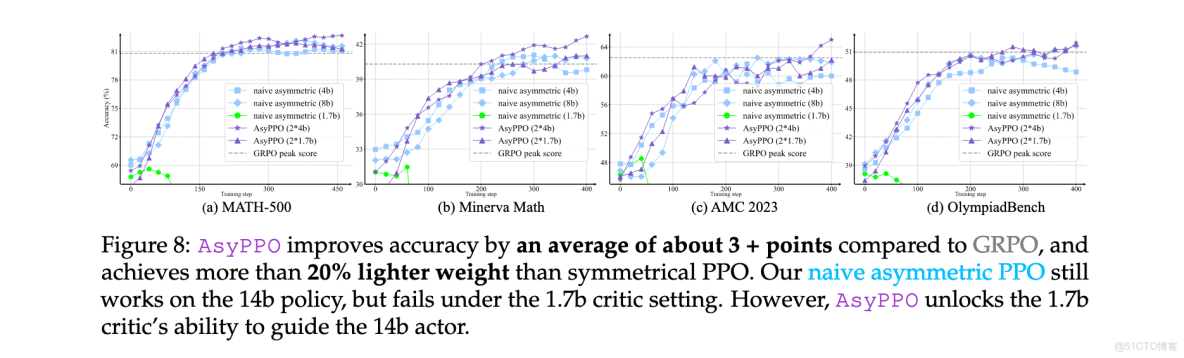
在Qwen3-14b-Base actor上的實驗結果表明,AsyPPO相比基線方法取得顯著提升。具體而言,使用兩個4b critics的AsyPPO在所有任務上實現最強性能,相比GRPO平均提升約3個百分點。值得注意的是,樸素非對稱PPO(單個mini-critic指導大規模actor)存在明顯的critic容量閾值:單個Qwen3-1.7b-Base critic無法可靠指導14b actor,儘管它能成功指導8b actor;升級到4b critic則恢復有效學習。相比之下,AsyPPO降低了這一要求,1.7b critics即可提供實質性的推理能力提升。
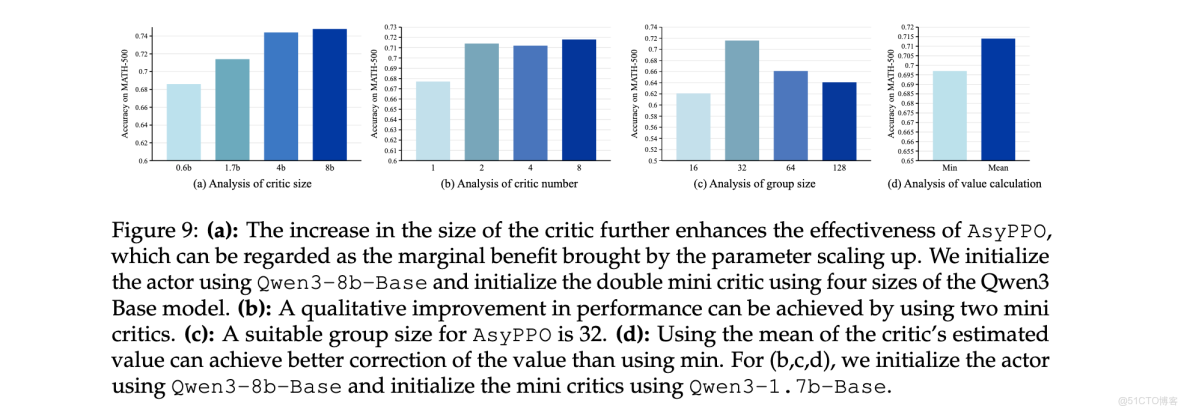
Critic配置敏感性分析
對critic規模和數量的消融研究揭示了重要見解。圖9(a)顯示了類似縮放定律的趨勢:增加critic規模穩步提高policy的峯值分數,建議使用GPU內存允許的最大critic模型以最大化AsyPPO的優化能力。然而,增加critic數量並未帶來類似收益:圖9(b)顯示兩個mini-critics足以實現明顯的性能躍升。在GRPO組大小(每個prompt的軌跡數)變化實驗中,發現32是一個魯棒的設置。在ensemble價值聚合方面,價值均值優於最小值,表明在RL4LLM中高估並非主導問題。
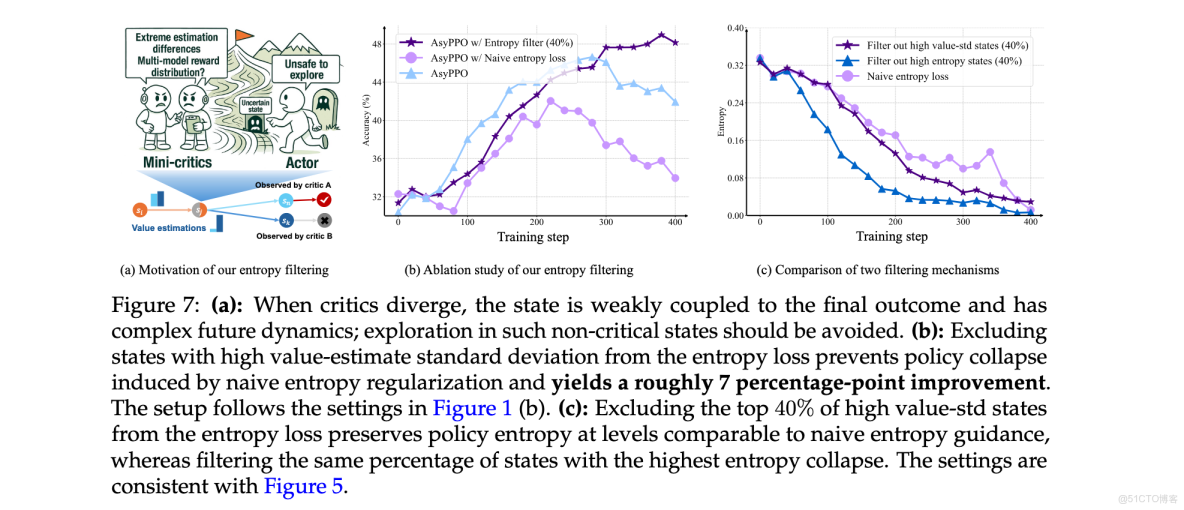
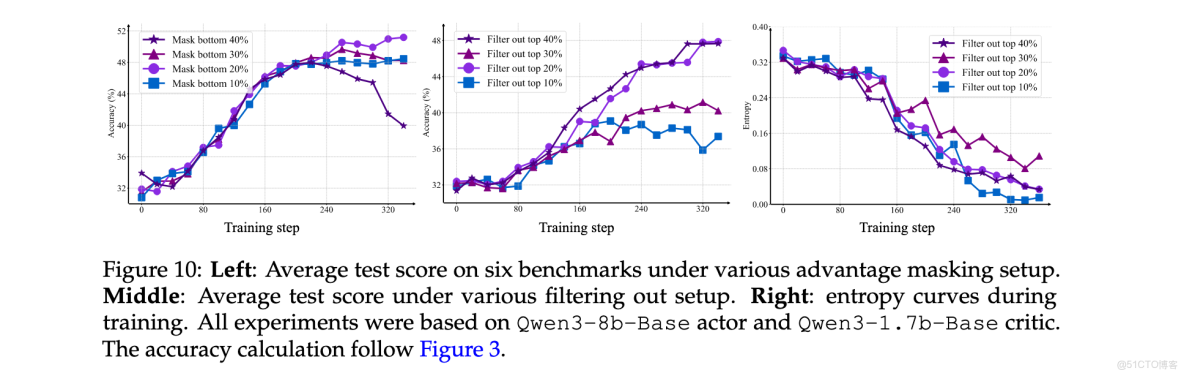
不確定性機制優化
為確定魯棒的advantage masking百分比,採用Qwen3-8b-Base作為policy和兩個Qwen3-1.7b-Base critics的設置。圖10(左)顯示屏蔽20%的低價值-標準差狀態提供最強收益。對於entropy filtering,測試了10%、20%、30%和40%的過濾比例。如圖10(中、右)所示,較大的mask會導致熵崩潰,而20%在探索-利用平衡方面表現最佳。
計算效率分析
AsyPPO在保持性能的同時顯著提高了計算效率。如圖1(b)所示,AsyPPO的峯值GPU內存使用和平均訓練時鐘時間顯著低於經典PPO,保持在GRPO水平。具體而言,非對稱架構減少峯值內存20%,每步訓練加速約20秒。這種輕量級部署特性使AsyPPO成為實際RL4LLM應用的理想選擇。
價值估計質量分析
從語言學角度的統計分析顯示,AsyPPO ensemble框架的校正價值顯著鼓勵policy獲取核心推理模式。圖4表明,mini-critics能夠對涉及關鍵推理模式的狀態提供積極估計,包括驗證回溯、反向推理和子目標設定等。這種能力解釋了為什麼AsyPPO能夠在稀疏獎勵和長推理軌跡場景下保持穩定學習。
AsyPPO的成功不僅體現在性能提升上,更重要的是為RL4LLM算法設計開闢了新方向。通過架構創新而非純粹的算法或優化改進,AsyPPO解決了critic瓶頸問題,同時保持了訓練穩定性和樣本效率。這一方法為未來大規模語言模型強化學習訓練提供了實用且高效的解決方案。