
簡言
在後端開發中,API接口是服務間通信的核心載體,而數據存儲與緩存策略則直接決定了接口的性能與穩定性。Spring框架憑藉其強大的生態成為API開發的首選,MySQL作為關係型數據庫提供了可靠的數據持久化支持。當系統併發量提升時,單一數據庫架構易出現性能瓶頸,此時引入Redis(分佈式緩存)與Caffeine(本地緩存)構建多級緩存體系,成為優化性能的關鍵方案。本文將從基礎實現出發,深入探討多級緩存的優勢、劣勢、適用場景及實踐注意點。
文章目錄
- 簡言
- 一、基礎架構:Spring+MySQL實現API接口
- 1.1 核心組件與依賴
- 1.2 核心實現流程
- 二、多級緩存:Redis+Caffeine的組合邏輯
- 2.1 組件特性對比
- 2.2 多級緩存工作流程
- 三、多級緩存的優勢與劣勢
- 3.1 核心優勢
- 3.1.1 極致的性能提升
- 3.1.2 分佈式場景適配
- 3.1.3 高可用性保障
- 3.2 主要劣勢
- 3.2.1 架構複雜度提升
- 3.2.2 內存資源消耗增加
- 3.2.3 數據一致性風險
- 四、適用場景與實踐注意點
- 4.1 核心適用場景
- 4.1.1 高頻讀、低頻寫場景
- 4.1.2 分佈式微服務架構
- 4.1.3 高併發核心接口
- 4.2 關鍵實踐注意點
- 4.2.1 合理配置緩存策略
- 4.2.2 保障數據一致性
- 4.2.3 避免緩存常見問題
- 4.2.4 監控與運維保障
- 五、總結
一、基礎架構:Spring+MySQL實現API接口
Spring生態中,Spring Boot結合MyBatis/MyBatis-Plus可快速搭建基於MySQL的API接口服務。其核心邏輯是通過Spring MVC接收前端請求,Service層處理業務邏輯,Mapper層通過MyBatis操作MySQL數據庫,最終將數據返回給調用方。
1.1 核心組件與依賴
實現該架構需引入以下核心依賴(以Maven為例):
<!-- Spring Boot Web核心 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis-Plus啓動器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<!-- MySQL驅動 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 數據庫連接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>1.2 核心實現流程
- 配置數據庫連接:在application.yml中配置MySQL地址、用户名、密碼及連接池參數;
- 定義實體類:對應MySQL數據表結構,使用MyBatis-Plus註解簡化配置;
- 編寫Mapper接口:繼承BaseMapper實現CRUD操作,無需手動編寫SQL;
- Service層封裝業務:調用Mapper接口處理業務邏輯,如數據校驗、權限控制;
- Controller暴露接口:通過@RestController、@RequestMapping等註解定義API路徑,接收請求並返回結果。
該架構的優勢是開發效率高、數據一致性強,但當併發請求量超過MySQL承載能力時,會出現查詢延遲、連接池耗盡等問題,此時緩存的引入至關重要。
二、多級緩存:Redis+Caffeine的組合邏輯
多級緩存的核心思路是“近緩存優先”,將訪問頻率高的數據存儲在距離應用更近的緩存中,減少網絡開銷和數據庫壓力。Caffeine作為本地緩存(進程內緩存),Redis作為分佈式緩存(獨立服務),二者結合可兼顧性能與分佈式一致性。
<!-- 分佈式緩存: redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 本地緩存:caffeine(注意:3.x版本java版本至少要在11以上)-->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>2.1 組件特性對比
|
特性 |
Caffeine |
Redis |
|
存儲位置
|
應用進程內
|
獨立服務器/集羣
|
|
訪問延遲
|
微秒級(極快)
|
毫秒級(較快)
|
|
分佈式支持
|
不支持(進程隔離)
|
支持(集羣部署)
|
|
存儲容量
|
受JVM內存限制
|
支持大容量(GB/TB級)
|
|
持久化
|
不支持(進程重啓丟失)
|
支持(RDB/AOF)
|
2.2 多級緩存工作流程
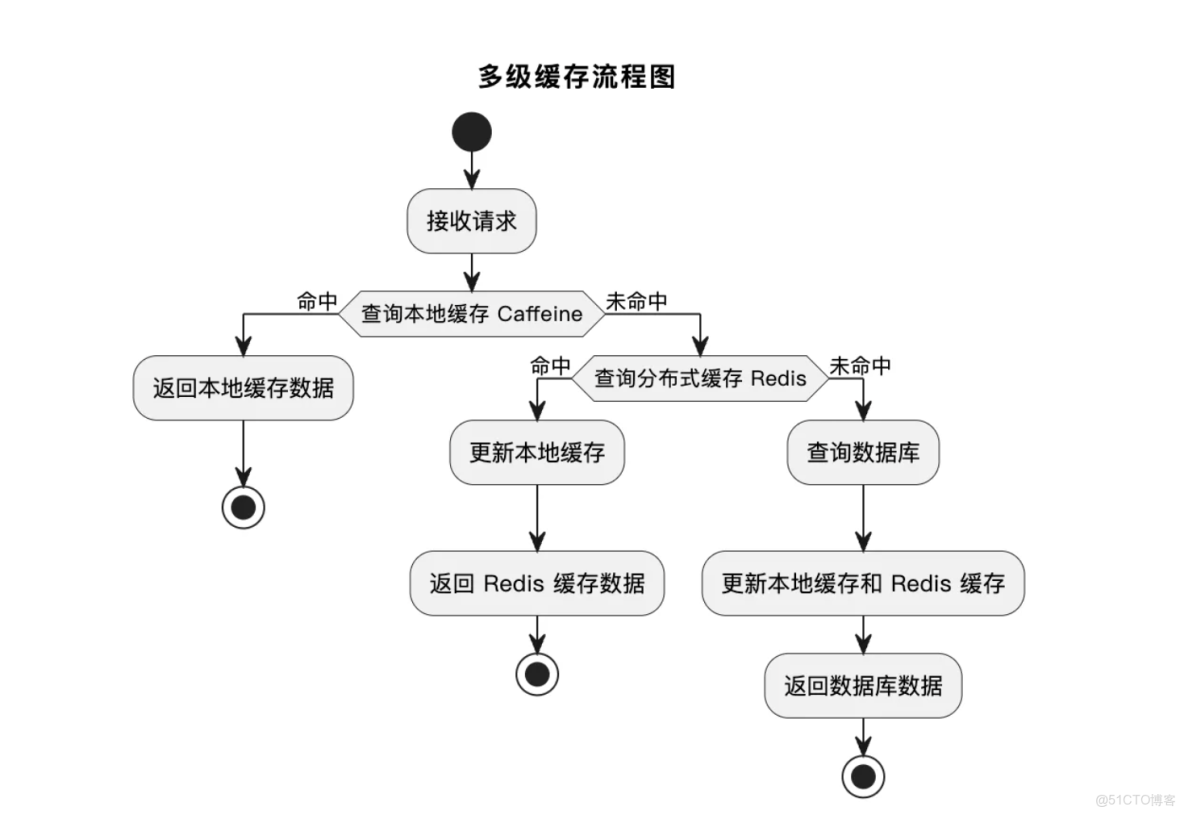
基於Spring Cache抽象,可快速整合Caffeine與Redis,核心流程如下:
- 查詢緩存:請求到達後,先查詢Caffeine本地緩存,若命中直接返回數據;
- 分佈式緩存查詢:若Caffeine未命中,查詢Redis分佈式緩存,若命中則將數據同步到Caffeine後返回;
- 數據庫查詢:若Redis也未命中,查詢MySQL數據庫,將查詢結果同步到Redis和Caffeine後返回;
- 緩存更新/失效:當數據發生修改時,先更新數據庫,再刪除對應Redis和Caffeine緩存(避免緩存與數據庫不一致)。
弧圖圖項目中的一個分頁列表接口示例:
/**
* 採用多級緩存,先查詢本地緩存,如果本地緩存查詢不到,在查詢分佈式緩存,如果再沒有再從數據庫中查詢
* @param pictureQueryRequest
* @param request
* @return
*/
@Resource
private ValueOperations<String, String> stringValueWithRedisTemplate;
@Resource
private Cache<String,String> localCacheWithCaffeine;
@ApiOperation(value = "分頁圖片列表VO多級緩存")
@PostMapping("/list/page/vo/multi-level")
public BaseResponse<Page<PictureVo>> listPictureVOByPageWithMultiLevel(@RequestBody PictureQueryRequest pictureQueryRequest,HttpServletRequest request) {
int current = pictureQueryRequest.getCurrent();
int pageSize = pictureQueryRequest.getPageSize();
ThrowUtil.throwIf(pageSize > 20, ResponseCode.PARAMS_ERROR);
// 只有審核過的圖片可以在主頁顯示
pictureQueryRequest.setReviewStatus(ReviewStatusEnum.PASS.getValue());
Page<Picture> picturePage = pictureService.page(new Page<>(current, pageSize)
,
pictureService.getQueryWrapper(pictureQueryRequest));
// 1. 構造key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
// 查詢條件加密
queryCondition = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = String.format("hututu:listPictureVOByPageWithCache:%s", queryCondition);
// 2. 先查詢本地緩存
String cacheValue = localCacheWithCaffeine.getIfPresent(cacheKey);
Page<PictureVo> pictureVOPage= null;
if(cacheValue != null) {
pictureVOPage= JSONUtil.toBean(cacheValue,Page.class);
return ResponseUtil.success(pictureVOPage);
}
// 3 查詢redis緩存
cacheValue = stringValueWithRedisTemplate.get(cacheKey);
if(cacheValue != null) {
pictureVOPage = JSONUtil.toBean(cacheValue,Page.class);
return ResponseUtil.success(pictureVOPage);
}
// 4. 查詢mysql
pictureVOPage = pictureService.getPictureVOPage(picturePage, request);
// 5 存儲本地緩存和redis緩存
localCacheWithCaffeine.put(cacheKey, JSONUtil.toJsonStr(pictureVOPage));
stringValueWithRedisTemplate.set(cacheValue, JSONUtil.toJsonStr(pictureVOPage),300+ RandomUtil.randomInt(0,300), TimeUnit.SECONDS);
return ResponseUtil.success(pictureVOPage);
}實現前端效果:

在這裏插入圖片描述
三、多級緩存的優勢與劣勢
任何技術方案都有其適用場景,多級緩存的優劣需結合業務場景客觀評估。
3.1 核心優勢
3.1.1 極致的性能提升
Caffeine的微秒級訪問延遲可覆蓋大部分高頻查詢場景,減少對Redis的網絡調用;Redis則承接跨服務的緩存需求,二者結合使緩存命中率大幅提升,數據庫查詢壓力顯著降低。實測顯示,在商品詳情查詢場景中,引入多級緩存後接口響應時間可從50-100ms降至1-5ms,併發承載能力提升10倍以上。
3.1.2 分佈式場景適配
在微服務架構中,Caffeine的本地緩存可減少服務間對Redis的競爭,而Redis確保了不同服務實例間的緩存一致性。例如,用户登錄狀態緩存可存儲在Redis中供所有服務訪問,而服務本地的高頻配置數據可存儲在Caffeine中,兼顧一致性與性能。
3.1.3 高可用性保障
當Redis集羣因網絡故障或節點宕機暫時不可用時,Caffeine本地緩存可作為“兜底緩存”,保障核心接口的可用性;反之,若單個服務實例故障,Redis中的緩存數據可被其他實例複用,避免緩存雪崩。
3.2 主要劣勢
3.2.1 架構複雜度提升
引入多級緩存後,需額外維護Caffeine的本地緩存配置(如容量、過期時間、淘汰策略)和Redis的集羣部署、持久化策略;同時需處理緩存一致性問題(如更新/刪除時的緩存同步),增加了開發和運維成本。
3.2.2 內存資源消耗增加
Caffeine緩存佔用JVM堆內存,若配置不當(如容量過大、淘汰策略不合理),易導致JVM內存溢出(OOM);Redis集羣則需獨立的服務器資源,增加了硬件成本。
3.2.3 數據一致性風險
多級緩存存在“緩存不一致”的天然風險:例如,服務A更新數據後刪除了自身Caffeine緩存和Redis緩存,但服務B的Caffeine緩存中仍有舊數據,直到過期才會更新。雖可通過發佈訂閲機制(如Redis Pub/Sub)觸發全量服務的本地緩存失效,但會增加系統複雜度。
四、適用場景與實踐注意點
4.1 核心適用場景
4.1.1 高頻讀、低頻寫場景
如商品詳情、新聞資訊、字典配置等數據,查詢頻率遠高於更新頻率,多級緩存可最大化發揮性能優勢。例如,電商平台的商品列表查詢,90%以上的請求可通過Caffeine命中,剩餘請求通過Redis命中,僅極少數請求需查詢數據庫。
4.1.2 分佈式微服務架構
微服務間的接口調用頻繁,多級緩存可減少跨服務依賴和網絡開銷。例如,訂單服務查詢用户信息時,先查本地Caffeine緩存,未命中再查Redis緩存,最後調用用户服務接口並同步緩存,降低服務間的耦合度。
4.1.3 高併發核心接口
如秒殺活動、限時優惠等場景,併發量可達數萬QPS,單一數據庫或Redis無法承載。多級緩存可通過Caffeine承接大部分瞬時請求,Redis保障分佈式一致性,數據庫僅處理最終的下單邏輯。
4.2 關鍵實踐注意點
4.2.1 合理配置緩存策略
- Caffeine配置:建議設置最大容量(如10000條)、過期時間(如5分鐘),採用LRU(最近最少使用)或LFU(最不經常使用)淘汰策略;避免緩存超大對象(如超過1MB),防止JVM內存碎片化。
- Redis配置:採用集羣部署(如3主3從)保障高可用,開啓AOF持久化避免數據丟失;針對熱點數據設置合理的過期時間(如10分鐘),並通過“熱點Key”防護機制避免緩存擊穿。
4.2.2 保障數據一致性
採用“先更新數據庫,再刪除緩存”的策略(避免更新緩存失敗導致不一致);對於強一致性需求場景,可引入Redis Pub/Sub機制,當數據更新時,發佈緩存失效消息,所有服務實例接收消息後刪除本地Caffeine緩存;對於弱一致性場景,可依賴緩存過期機制自然失效。
4.2.3 避免緩存常見問題
- 緩存穿透:請求不存在的數據
- 對不存在的Key,在Redis中緩存空值(設置短過期時間,如10秒),並結合布隆過濾器過濾無效Key;
- 緩存擊穿:請求不存在的熱點數據
- 對熱點Key設置“永不過期”,通過後台線程定期更新;或採用互斥鎖機制,確保同一時間僅一個請求查詢數據庫;
- 緩存雪崩:大量緩存同時過期
- 將緩存過期時間設置為“基礎時間+隨機偏移”(如10分鐘±30秒),避免大量緩存同時失效;Redis集羣採用多區域部署,避免單點故障。
4.2.4 監控與運維保障
通過Spring Boot Actuator監控Caffeine緩存命中率、容量使用情況;通過Redis監控工具(如Redis Insight)監控Redis的命中率、內存佔用、集羣狀態;設置告警機制,當緩存命中率低於閾值(如80%)或Redis內存使用率超過閾值(如80%)時及時預警。
五、總結
Spring+MySQL是API接口開發的基礎架構,而Redis+Caffeine多級緩存則是應對高併發場景的“性能利器”。其核心價值在於通過“本地緩存+分佈式緩存”的組合,兼顧了性能、一致性與可用性,但同時也帶來了架構複雜度和資源消耗的提升。
在實踐中,需結合業務場景選擇是否引入多級緩存:對於低頻請求、強一致性需求的接口,單一數據庫或Redis緩存即可滿足需求;對於高頻讀、低頻寫的核心接口,多級緩存則能帶來顯著的性能提升。同時,需通過合理的緩存配置、一致性策略和監控機制,規避潛在風險,確保系統穩定運行。