
目錄
- 一、概述
- 二、節點類型&作用
- 1)master節點(主節點)
- 2)data節點(數據節點)
- 3)Coordinating節點(協調節點/Client節點)
- 4)Ingest節點(預處理節點)
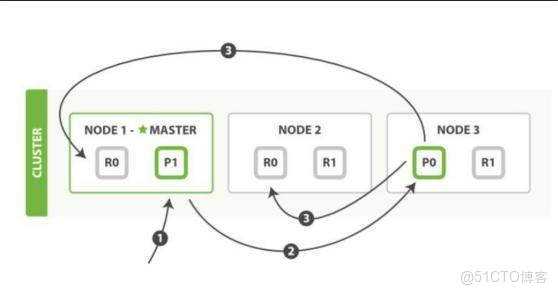
- 三、Elasticsearch 是如何實現 master 選舉的
- 前提條件
- 實現步驟
- 四、如何解決ES集羣的腦裂問題
- 五、調優
- 1)部署時,對 Linux 的設置優化方法
- 2)寫入調優
- 3)查詢調優
- 六、Elasticsearch 索引文檔的過程
- 七、索引模板
- 1)模板優先級
- 2)索引模板的匹配
- 3)setting 部分
- 八、冷熱數據分離
- 1)實現原理
- 九、分片不均衡原因&解決方案
- 原因
- 解決方案
- 1)方案一:手動移動分片
- 2)方案二:重建索引,從另外一個集羣導入
- 3)方案三:配置平衡參數
- 十、解決Elasticsearch分片未分配的問題
- 十一、ES讀寫數據過程
- 1)ES寫入數據的過程
- 2)ES讀數據過程
- 十二、在海量數據中提高效率的幾個手段
一、概述
Elasticsearch是一個基於Lucene的搜索引擎。它提供了具有HTTP Web界面和無架構JSON文檔的分佈式,多租户能力的全文搜索引擎。Elasticsearch是用Java開發的,根據Apache許可條款作為開源發佈。
二、節點類型&作用
1)master節點(主節點)
配置
node.master:true
node.data:false(這裏也可以配置成node.data:true)【注意】node.master和node.data默認都是true, 但還是建議顯式配置
作用
- 索引的創建或刪除
- 跟蹤哪些節點是集羣的一部分
- 決定哪些分片分配給相關的節點
2)data節點(數據節點)
配置
node.master:false(這裏也可以配置成node.master:true)
node.data:true作用
- 存儲索引數據
- 對文檔進行增刪改查,聚合操作
3)Coordinating節點(協調節點/Client節點)
每一個節點都隱式的是一個協調節點,Coordinating節點是負責接收任何 Client 的請求,包括 REST Client 等。該節點將請求分發到合適的節點,最終把結果彙集到一起。一般來説,每個節點默認起到了 Coordinating節點 的職責。
配置
node.master:false
node.data:false作用
- 處理路由請求
- 處理搜索
- 分發索引
4)Ingest節點(預處理節點)
在索引數據之前可以先對數據做預處理操作,所有節點其實默認都是支持 Ingest 操作的,也可以專門將某個節點配置為 Ingest 節點。
配置
node.ingest:true作用
- Ingest節點和集羣中的其他節點一樣,但是它能夠創建多個處理器管道,用以修改傳入文檔。類似 最常用的Logstash過濾器已被實現為處理器。
- Ingest節點 可用於執行常見的數據轉換和豐富。 處理器配置為形成管道。 在寫入時,Ingest Node有20個內置處理器,例如grok,date,gsub,小寫/大寫,刪除和重命名
- 在批量請求或索引操作之前,Ingest節點攔截請求,並對文檔進行處理。
三、Elasticsearch 是如何實現 master 選舉的
前提條件
- 只有候選主節點(master:true)的節點才能成為主節點。
- 最小主節點數(min_master_nodes)的目的是防止腦裂。
實現步驟
- 第一步:確認候選主節點數達標,elasticsearch.yml 設置的值discovery.zen.minimum_master_nodes;
- 第二步:對所有候選主節點根據nodeId字典排序,每次選舉每個節點都把自己所知道節點排一次序,然後選出第一個(第0位)節點,暫且認為它是master節點。
- 第三步:如果對某個節點的投票數達到一定的值(候選主節點數n/2+1)並且該節點自己也選舉自己,那這個節點就是master。否則重新選舉一直到滿足上述條件。
【補充】master 節點的職責主要包括集羣、節點和索引的管理,不負責文檔級別的管理;data 節點可以關閉 http 功能。
四、如何解決ES集羣的腦裂問題
【原因】
所謂集羣腦裂,是指 Elasticsearch 集羣中的節點(比如共 20 個),其中的 10 個選了一個 master,另外 10 個選了另一個 master 的情況。
【解決】
當集羣 master 候選數量不小於 3 個時,可以通過設置最少投票通過數量(discovery.zen.minimum_master_nodes)超過所有候選節點一半以上來解決腦裂問題;
五、調優
1)部署時,對 Linux 的設置優化方法
- 關閉緩存 swap;
- 堆內存設置為:Min(節.點內存/2,理想是 32GB);
- 設置最大文件句柄數;
- 線程池+隊列大小根據業務需要做調整;
- 磁盤存儲 raid 方式——存儲有條件使用 RAID10,增加單節點性能以及避免單節點存儲故障。
2)寫入調優
- 寫入前副本數設置為 0;
- 寫入前關閉 refresh_interval 設置為-1,禁用刷新機制;
- 寫入過程中:採取 bulk 批量寫入;
- 寫入後恢復副本數和刷新間隔;
- 儘量使用自動生成的 id。
3)查詢調優
- 禁用 wildcard(wildcard 檢索可以定義為:支持通配符的模糊檢索。類似於mysql的like);
- 禁用批量 terms(成百上千的場景);
- 充分利用倒排索引機制,能 keyword 類型儘量 keyword;
- 據量大時候,可以先基於時間敲定索引再檢索;
- 設置合理的路由機制。
六、Elasticsearch 索引文檔的過程
這裏的索引文檔應該理解為文檔寫入 ES,創建索引的過程。
文檔寫入包含:單文檔寫入和批量 bulk 寫入,這裏只解釋一下:單文檔寫入流程。
- 第一步:客户寫集羣某節點寫入數據,發送請求。(如果沒有指定路由/協調節點,請求的節點扮演路由節點的角色。)
- 第二步:節點 1 接受到請求後,使用文檔_id 來確定文檔屬於分片 0。請求會被轉到另外的節點,假定節點 3。因此分片 0 的主分片分配到節點 3 上。
- 第三步:節點 3 在主分片上執行寫操作,如果成功,則將請求並行轉發到節點 1和節點 2 的副本分片上,等待結果返回。所有的副本分片都報告成功,節點 3 將向協調節點(節點 1)報告成功,節點 1 向請求客户端報告寫入成功。
七、索引模板
索引模板,簡而言之,是一種複用機制,就像一些項目的開發框架如 Laravel 一樣,省去了大量的重複,體力勞動。當新建一個 Elasticsearch 索引時,自動匹配模板,完成索引的基礎部分搭建。
典型的如下所示:
{
"order": 0,
"template": "sample_info*",
"settings": {
"index": {
"number_of_shards": "64",
"number_of_replicas": "1"
}
},
"mappings": {
"info": {
"dynamic_templates": [
{
"string_fields": {
"mapping": {
"analyzer": "only_words_analyzer",
"index": "analyzed",
"type": "string",
"fields": {
"raw": {
"ignore_above": 512,
"index": "not_analyzed",
"type": "string"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
],
"properties": {
"user_province": {
"analyzer": "lowercase_analyzer",
"index": "analyzed",
"type": "string",
"fields": {
"raw": {
"ignore_above": 512,
"index": "not_analyzed",
"type": "string"
}
}
}
}
}
},
"aliases": {}
}上述模板定義,看似複雜,拆分來看,主要為如下幾個部分:
{
"order": 0, // 模板優先級
"template": "sample_info*", // 模板匹配的名稱方式
"settings": {...}, // 索引設置
"mappings": {...}, // 索引中各字段的映射定義
"aliases": {...} // 索引的別名
}1)模板優先級
一個模板可能絕大部分符合新建索引的需求,但是局部需要微調,此時,如果複製舊的模板,修改該模板後,成為一個新的索引模板即可達到我們的需求,但是這操作略顯重複。此時,可以採用模板疊加與覆蓋來操作。模板的優先級是通過模板中的 order 字段定義的,數字越大,優先級越高。
如下為定義所有以 te 開頭的索引的模板:
{
"order": 0
"template" : "te*",
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"type1" : {
"_source" : { "enabled" : false }
}
}
}索引模板是有序合併的。如何想單獨修改某一小類索引的一兩處單獨設置,可以在累加一層模板:
{
"order" : 1,
"template" : "tete*",
"settings" : {
"number_of_shards" : 2
},
"mappings" : {
"type1" : {
"_all" : { "enabled" : false }
}
}
}上述第一個模板的 order 為0,第二個模板的 order 為1,優先級高於第一個模板,其會覆蓋第一個模板中的相同項。所以對於所有以 tete 開頭的索引模板效果如下:
{
"settings" : {
"number_of_shards" : 2
},
"mappings" : {
"type1" : {
"_source" : { "enabled" : false },
"_all" : { "enabled" : false }
}
}
}兩個模板疊加了,項目的字段,優先級高的覆蓋了優先級低的,如分片數。
2)索引模板的匹配
索引模板中的 "template" 字段定義的是該索引模板所應用的索引情況。如 "template": "tete*" 所表示的含義是,當新建索引時,所有以 tete 開頭的索引都會自動匹配到該索引模板。利用該模板進行相應的設置和字段添加等。
3)setting 部分
索引模板中的 setting 部分一般定義的是索引的主分片、拷貝分片、刷新時間、自定義分析器等。常見的 setting 部分結構如下:
"settings": {
"index": {
"analysis": {...}, // 自定義的分析器
"number_of_shards": "32", // 主分片的個數
"number_of_replicas": "1", // 主分片的拷貝分片個數
"refresh_interval": "5s" // 刷新時間
}
}八、冷熱數據分離
ES集羣的索引寫入及查詢速度主要依賴於磁盤的IO速度,冷熱數據分離的關鍵為使用SSD磁盤存儲數據。若全部使用SSD,成本過高,且存放冷數據較為浪費,因而使用普通SATA磁盤與SSD磁盤混搭,可做到資源充分利用,性能大幅提升的目標。為了解決控制成本的前提下讀寫性能問題,Elasticsearch冷熱分離架構應運而生。
- 冷數據索引:查詢頻率低,基本無寫入,一般為當天或最近2天以前的數據索引
- 熱數據索引:查詢頻率高,寫入壓力大,一般為當天數據索引
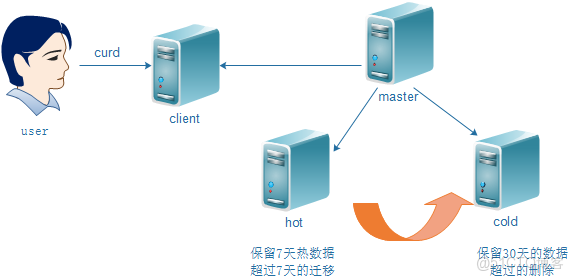
1)實現原理
- Hot節點設置:索引節點(寫節點),同時保持近期頻繁使用的索引。 屬於IO和CPU密集型操作,建議使用SSD的磁盤類型,保持良好的寫性能;節點的數量設置一般是大於等於3個。將節點設置為hot類型:
node.attr.box_type: hot- Warm節點設置: 用於不經常訪問的read-only索引。由於不經常訪問,一般使用普通的磁盤即可。內存、CPU的配置跟Hot節點保持一致即可;節點數量一般也是大於等於3個。將節點設置為warm類型:
node.attr.box_type: warmes1:master節點
# elasticsearch.yml
node.name: "master"
cluster.name: "test-cluster"
network.host: 0.0.0.0
node.master: true
node.data: falsees2、es3、es4 熱數據節點
# elasticsearch.yml
node.name: "hot-datanode-00x" # 提示:自行修改其他節點的名稱
cluster.name: "test-cluster"
network.host: 0.0.0.0
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["master"]
node.attr.box_type: "hot" # 標識為熱數據節點es5、es6 冷/温數據節點
# elasticsearch.yml
node.name: "cold-datanode-00x" # 提示:自行修改其他節點的名稱cluster.name: "docker-cluster" network.host: 0.0.0.0 node.master: false node.data: true discovery.zen.ping.unicast.hosts: ["master"] node.attr.box_type: "warm" # 標識為温數據節點九、分片不均衡原因&解決方案
原因
可能存在的部分原因有以下幾種:
- Shard設置不合理。
説明:大多數負載不均問題是由於shard設置不合理導致,建議優先排查。
- Segment大小不均。
- 存在典型的冷熱數據需求場景。
説明:例如查詢中添加了routing或查詢頻率較高的熱點數據,則必然導致數據出現負載不均。
- 沒有釋放長連接,導致流量不均。
説明:該問題時常暴露於採用負載均衡及多可用區架構部署時。
解決方案
1)方案一:手動移動分片
例如移動node-1的分片0到node-4
curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"move":{
"index":"indexName",
"shard":0,
"from_node":"node-1",
"to_node":"node-4"
}}]}'- 優點:操作簡單,恢復時間短;不必修改master node的配置,master node長期負載後高
- 缺點:索引大,移動時有很高的IO,索引容易損壞,需要做備份,不能解決master node既是數據節點又是負載均衡轉發器的問題
【注意】分片和副本無法移動到同一個節點
2)方案二:重建索引,從另外一個集羣導入
刪除原來的索引,重新建立索引,;利用elasticsearch dump等工具從另一個集羣中把數據導入到新的索引中
- 優點:可以重新配置master node和data node,主從負載均勻
- 缺點:費時間,容易數據丟失,需要驗證數據的一致性
3)方案三:配置平衡參數
使用下面的命令恢復平衡
PUT_cluster/settings
{
"persistent": {
"cluster.routing.rebalance.enable": "all"
}
}十、解決Elasticsearch分片未分配的問題
原因整體概述:
- 出現這個問題的原因是原有分片未正常關閉和清理,所以當分片要重新分配回出問題節點的時候沒有辦法獲得分片鎖。
- 這不會造成分片數據丟失,只需要重新觸發一下分配。
unassigned 分片問題可能的原因如下:
- INDEX_CREATED: 由於創建索引的API導致未分配。
- CLUSTER_RECOVERED: 由於完全集羣恢復導致未分配。
- INDEX_REOPENED: 由於打開open或關閉close一個索引導致未分配。
- DANGLING_INDEX_IMPORTED: 由於導入dangling索引的結果導致未分配。
- NEW_INDEX_RESTORED: 由於恢復到新索引導致未分配。
- EXISTING_INDEX_RESTORED: 由於恢復到已關閉的索引導致未分配。
- REPLICA_ADDED: 由於顯式添加副本分片導致未分配。
- ALLOCATION_FAILED: 由於分片分配失敗導致未分配。
- NODE_LEFT: 由於承載該分片的節點離開集羣導致未分配。
- REINITIALIZED: 由於當分片從開始移動到初始化時導致未分配(例如,使用影子shadow副本分片)。
- REROUTE_CANCELLED: 作為顯式取消重新路由命令的結果取消分配。
- REALLOCATED_REPLICA: 確定更好的副本位置被標定使用,導致現有的副本分配被取消,出現未分配。
解決方案如下:
執行修復命令
POST /_cluster/reroute?retry_failed十一、ES讀寫數據過程
1)ES寫入數據的過程
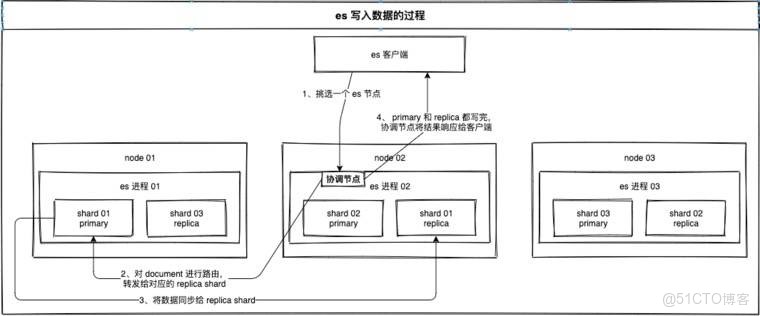
- 客户端發送任何一個請求到任意一個node,這個節點就成為協調節點(coordinate node)
- 協調節點對document(可以手動設置doc id,也可以由系統分配)進行hash路由,將請求轉發給對應的node
- node上的primary shard處理請求,然後將數據同步到replica node
- 協調節點如果發現primary shard所在的node和所有的replica shard所對應的node都搞定之後,就會將請求返回給客户端
2)ES讀數據過程
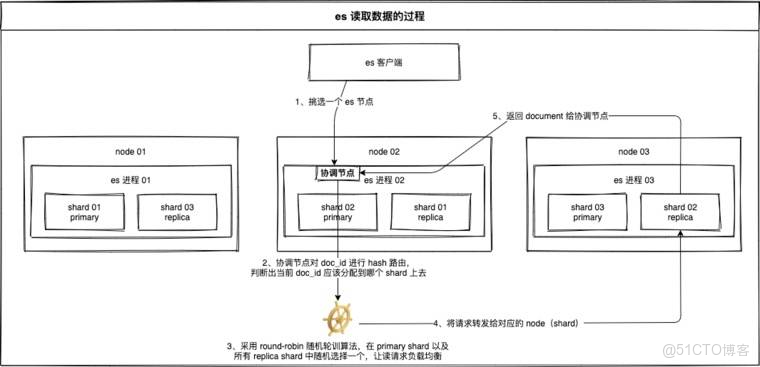
可以通過doc id來查詢,根據doc id進行hash,判斷當時寫這個document時是分配到哪個shard上去了,然後就去那個shard上查詢。
- 客户端發送任何一個請求到任意一個node,這個節點就成為協調節點(coordinate node)
- 協調節點對doc id進行hash路由,將請求轉發到對應的node,此時會使用round-robin隨機輪詢算法,在primary shard以及所有的replica shard中隨機選擇一個,讓讀請求負載均衡
- 接受請求的node,返回document給協調節點
- 協調節點再將數據返回給客户端
十二、在海量數據中提高效率的幾個手段
- filesystem cache:ES的搜索引擎嚴重依賴底層的filesystem cache,如果給filesystem cache更多的內存,儘量讓內存可以容納所有的index segment file索引數據文件
- 數據預熱:對於那些你覺得比較熱的數據,即經常會有人訪問的數據,最好做一個專門的緩存預熱子系統,對於熱數據,每隔一段時間,系統本身就提前訪問一下,讓數據進入filesystem cache裏面去,這樣下次訪問的時候,性能會更好一些。
- 冷熱分離:
- 冷數據索引:查詢頻率低,基本無寫入,一般為當天或最近2天以前的數據索引,這種數據可以存儲在機械硬盤HDD中
- 熱數據索引:查詢頻率高,寫入壓力大,一般為當天的數據索引,這種數據可以存儲在SSD中
- document的模型設計:不要在搜索的時候去執行各種複雜的操作,儘量在document模型設計和數據寫入的時候就將複雜操作處理掉
- 分頁性能優化:翻頁的時候,翻得越深,每個shard返回的數據越多,而且協調節點處理的時間越長,此時,要用scroll,scroll會一次性的生成所有數據的快照,然後每次翻頁都是通過移動遊標來完成