
數據
insert into boy (id,b_id,b_name) values
(1,1,'張三'),
(2,2,'李四'),
(3,3,'王五'),
(4,4,'陳六');
insert into girl (id,g_id,g_name) values
(1,2,'小紅'),
(2,3,'小紫'),
(3,4,'小藍'),
(4,6,'小青'),
(5,2,'小橙');
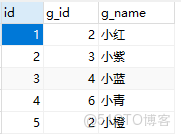
cross join
-- cross join
-- 笛卡爾乘積,共產生 b.row * g.* 行數據,儘量少用效率低,以下兩種寫法一樣
SELECT b.* ,g.*FROM boy b,girl g WHERE b.b_id = g.g_id
SELECT b.* ,g.*FROM boy b cross join girl g on b.b_id = g.g_idexplain


result
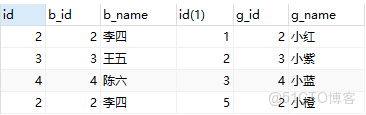
inner join
-- inner join -笛卡爾乘積,mysql inner join和 cross join 行為一致,查詢出滿足天劍的列
-- 篩選出並集,結果為滿足條件的m*n個結果,例如:假如boy表中有1條記錄符合,girl表中有2條記錄符合會產生2條數據
SELECT b.* ,g.*FROM boy b join girl g ON b.b_id = g.g_id
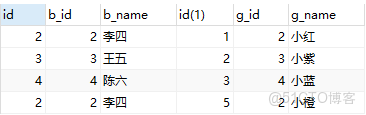
left join
-- left join -笛卡爾乘積,以左表為基準查詢
explain SELECT b.* ,g.*FROM boy b left join girl g ON b.b_id = g.g_id
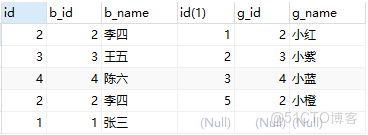
right join
-- rightjoin -以右表為基準查詢
SELECT b.* ,g.*FROM boy b right join girl g ON b.b_id = g.g_id
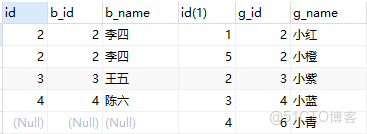
full join
-- full join mysql 沒有full join,可以使用union代替,union all不會去重,union自動去除重複數據,以第一張表字段為基準將兩張表合併
SELECT * FROM boy UNION all select * FROM girl g
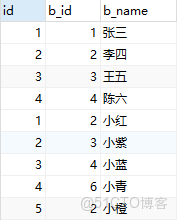
exists,not exits,in
-- in 和 exist ,使用時in 鏈接小表,exist鏈接大表,
SELECT b.b_id FROM boy b WHERE EXISTS(SELECT * FROM girl g WHERE b.b_id = g.g_id )
SELECT b.b_id FROM boy b WHERE b.b_id in (select g.g_id FROM girl g)


如何看explain
expain出來的信息有10列,分別是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
id
- id相同時,執行順序由上至下
- 如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行
- id如果相同,可以認為是一組,從上往下順序執行;在所有組中,id值越大,優先級越高,越先執行
type
常用的類型有: ALL, index, range, ref, eq_ref, const, system, NULL(從左到右,性能從差到好)即system>const>eq_ref>ref>range>index>all
一般來説,得保證查詢至少達到range級別,最好能達到ref。
- ALL:Full Table Scan, MySQL將遍歷全表以找到匹配的行
- index: Full Index Scan,index與ALL區別為index類型只遍歷索引樹
- range:只檢索給定範圍的行,使用一個索引來選擇行
- ref: 表示上述表的連接匹配條件,即哪些列或常量被用於查找索引列上的值
- eq_ref: 類似ref,區別就在使用的索引是唯一索引,對於每個索引鍵值,表中只有一條記錄匹配,簡單來説,就是多表連接中使用primary key或者 unique key作為關聯條件
- const、system: 當MySQL對查詢某部分進行優化,並轉換為一個常量時,使用這些類型訪問。如將主鍵置於where列表中,MySQL就能將該查詢轉換為一個常量,system是const類型的特例,當查詢的表只有一行的情況下,使用system
- NULL: MySQL在優化過程中分解語句,執行時甚至不用訪問表或索引,例如從一個索引列裏選取最小值可以通過單獨索引查找完成。
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。