
簡介
文章分享了將AI Agent技術應用於"智能播報助手"和"批量建任務"兩個業務場景的實踐歷程,闡述了AI Agent與傳統工程系統深度融合而非完全替代的有效路徑。通過MCP協議擴展Agent能力邊界,實現報表自動監控和釘釘消息推送;在批量建任務場景中,探索了Agent與工程結合的最佳實踐,強調應準確理解技術邊界和長處,構建高效穩健的解決方案。
本文通過分享將AI Agent技術應用於“智能播報助手”和“批量建任務”兩個真實業務場景的實踐歷程,深刻闡述了當下將AI Agent與傳統工程系統深度融合,而非追求完全替代,才是實現業務提效和價值落地的有效路徑。
Agent隨着Agent相關技術的快速發展,驗證其在企業實際業務場景中的價值已成為當務之急。脱離應用場景的技術創新終將淪為“空中樓閣”。本文分享我將agent與工程結合並應用於兩個業務場景的歷程,並在最後給出agent與工程的選型總結。
一、Agent + MCP 打造智能播報助手
1.1. 業務背景與問題
在我們的日常工作中會製作或使用大量統計報表。淘天會在一款數據產品上製作報表相關內容,製作好的報表會由關心報表數據的同學每隔一定週期去查看報表的數據是否出現異常。比如每天早上十點查看錶A的數據、大促上下線時每隔半小時查看錶B的數據。
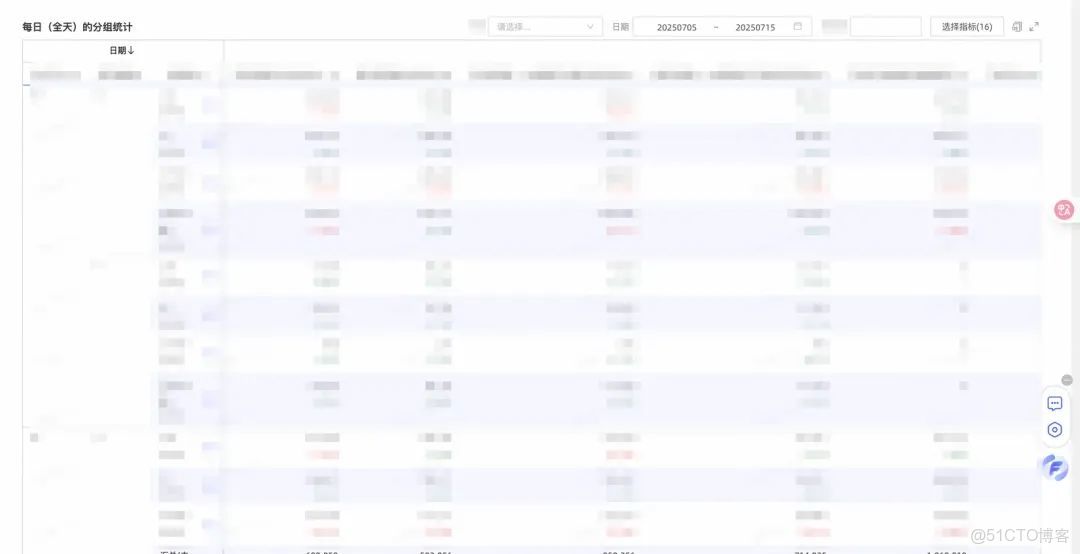
定時看報表的整體流程,簡單概括就是打開網頁,找到異常數據,基於異常數據採取某些行為。FBI擁有定時播報的能力,但是存在以下侷限性:
- 表格類型報表只能播報圖片,若要導出報表數據,只能選擇「郵件格式」並且只能把數據導出為excel格式。若用工程(編碼)處理,需要對每一個表格類型定義接收對象。
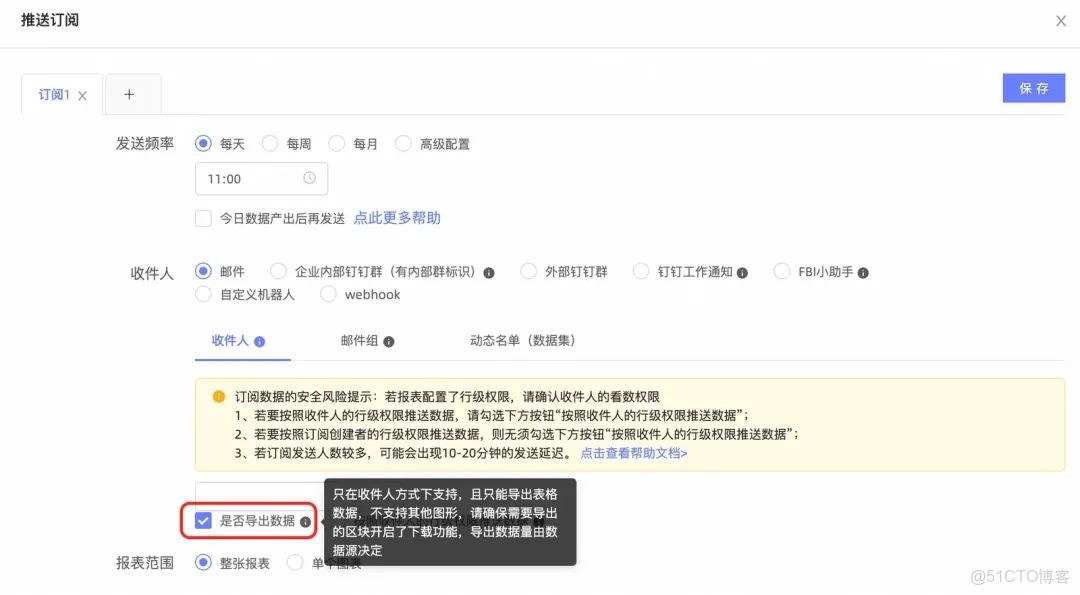
- 文本類型報表可以定義異常指標,但只能修改異常指標的展示樣式,滿足不了「只有某指標出現異常時才播報給某些特定的聯繫人」的需求,並且無法基於異常數據進行後續動作。
- 雖然底表的數據我們可以直接獲取,但無法拿到FBI加工過的數據如日環比。
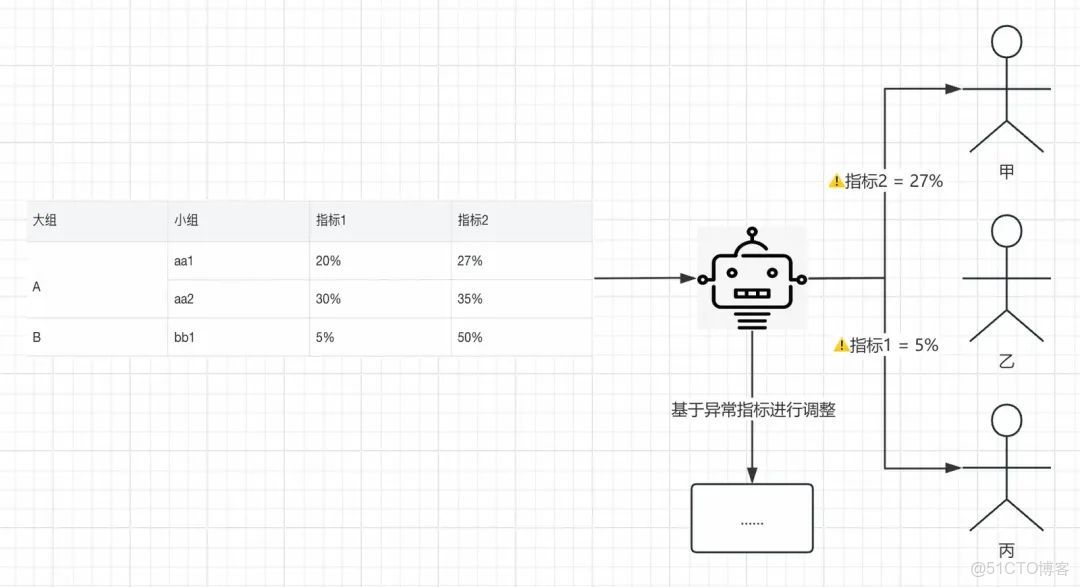
比如下圖中,定義異常數據為「指標1 < 10%或指標2 < 30%」。同學甲只關注A-aa1的數據、同學乙只關注A-aa2的數據、同學丙只關注B-bb1的數據。那麼就期望在週期到達時,向同學甲和同學丙播報異常數據,甚至是基於異常數據進行下一步動作。FBI目前做不到這一點。
1.2. MCP介紹
事情的轉折點在於LLM的不斷進化(如claude4)以及MCP的橫空出世。MCP (Model Context Protocol) ,翻譯過來就是模型上下文協議,簡單來説,它定義了一套標準規則,讓LLM模型能夠安全、有序地訪問和使用各種外部資源,從而大大擴展Agent的能力邊界。MCP中有兩個重要角色:MCP Client和MCP Server。MCP Server提供各種各樣的能力與工具,MCP Client是MCP Server的調用者。
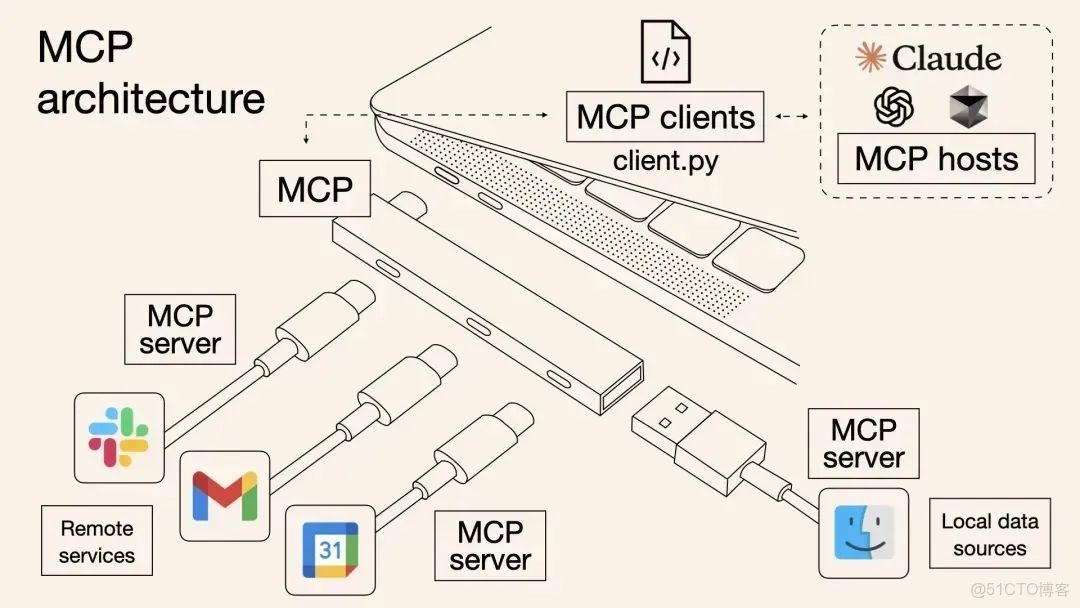
舉一個通俗的例子,把MCP Client 想象成DVD播放器,DVD播放器可以放入不同的碟片(MCP Server),不同的碟片有不同的內容(能力),但肯定不能向DVD播放器中放入磁帶(不符合MCP的Server)。在AI場景下,就是給予Agent通用地調用各種各樣工具的能力。
可能會有同學好奇:讓Agent調用工具難道是最近才有的能力嗎?其實並不是這樣,工具調用(Function Calling)是早於MCP提出來的能力,也就是説agent在MCP出現前就可以進行工具調用。過去只有Function Calling時,不同廠商(OpenAI、Anthropic…)的Function Calling協議都不同,並且許多開源模型不支持Function Calling。比如為OpenAI的某個模型開發了一個tool,想要複用到Anthropic(Claude的開發者)的某個模型,先要查看模型是否支持Function Calling,若支持還需要重新對tool進行適配開發。而MCP提供了一套通用的協議,免去了重複開發工具的問題,大大降低了工具使用的複雜度。
MCP目前有三種通訊方式:STDIO(Standard Input/Output)、SSE(Server-Sent Events,基於HTTP的單向數據流傳輸方式)和StreamableHttp。Mcp Client和Mcp Server部署在同一台機器上,通過標準輸入輸出通信的方式就是STDIO模式。部署在不同機器通過Http請求通信就是SSE模式和StreamableHttp模式。STDIO因為在本地運行,是絕對安全的;但SSE和StreamableHttp模式若暴露連接方式,可能會有安全問題。
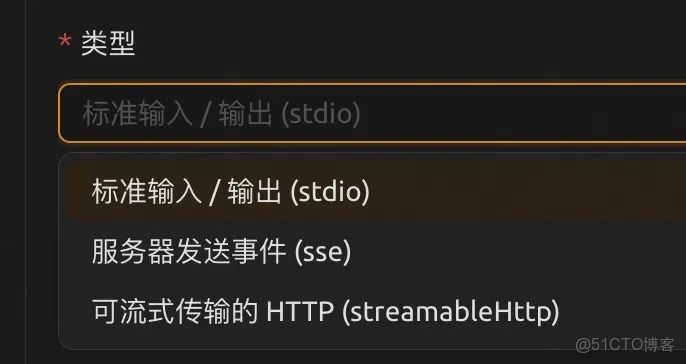
cherryStudio中連接類型設置
2025年3月26日,Anthropic在MCP規範中正式棄用SSE傳輸,全面轉向StreamableHttp。為什麼要用StreamableHttp替換SSE?SSE的原理是MCP Client與MCP Server通過HTTP建立SSE長鏈接,之後MCP Server就可以不斷向Client發送數據,而不需要每次都進行三次握手;MCP Client可以主動關閉SSE長鏈接。問題在於SSE的整個通訊過程都需要依賴SSE長鏈接,一旦出現網絡毛刺(短暫中斷),那麼MCP Server向MCP Client發送的數據就會丟失,並且MCP Server無法感知到數據的丟失。而Streamable方式中,MCP Server可以感知到數據丟失,連接恢復時可以持續地將沒有發送給MCP Client的數據再次發送,保證長鏈接的高可用性。
隨着MCP的流行,其社區也不斷壯大,出現了越來越多符合MCP的工具,相關平台也在積極適配MCP模塊。(mcp.so、魔搭社區)MCP就是模型進行工具調用的未來。
mcp.so
1.3. agent + MCP快速上手
沒有使用過MCP的同學可以按照以下步驟快速上手體驗一下,非常簡單。
1.首先需要一個AI對話客户端。ideaLab就是這樣的產品,但ideaLab目前不支持STDIO模式。市場上現在有大量的客户端,我們選擇Cherry Studio快速體驗。首先安裝客户端。
Cherry Studio官網
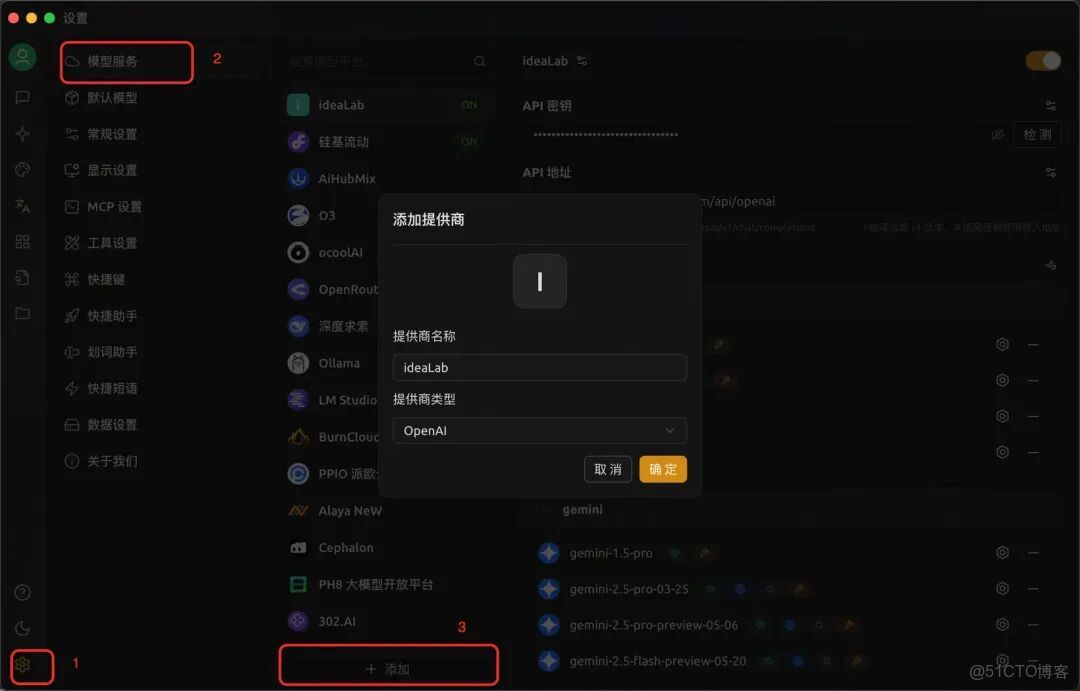
2.安裝完成後,點擊設置–模型服務–添加。隨便填寫“提供商名稱”。若使用ideaLab的sk,提供商類型選擇默認的OpenAI。
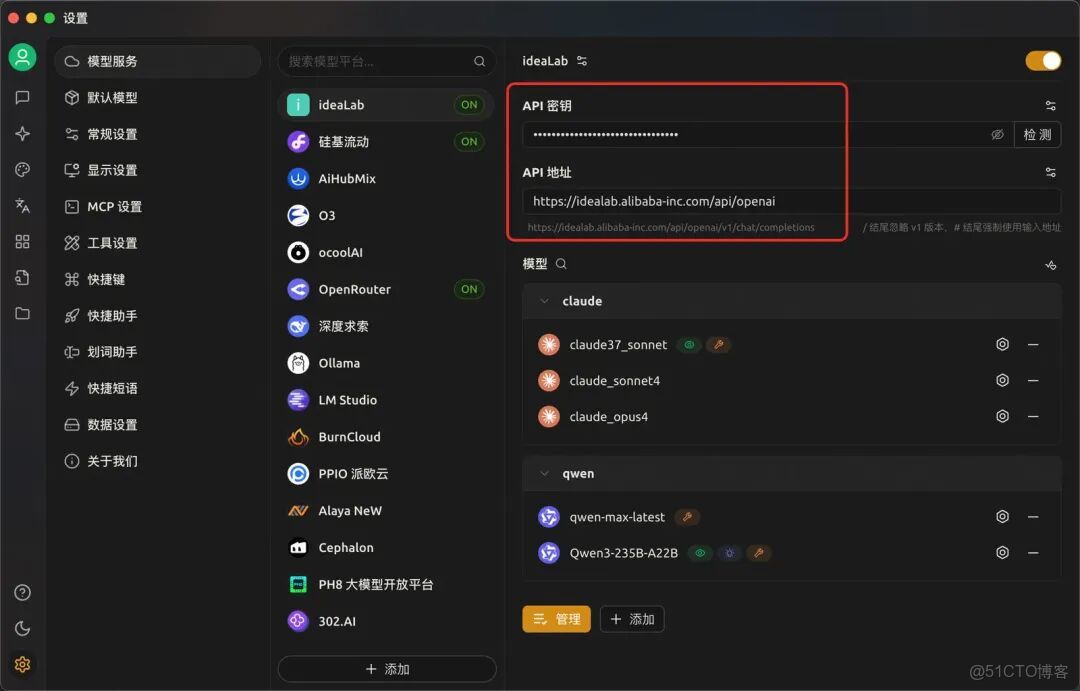
3.添加完成後,輸入ideaLab的sk,填入API地址。
4.點擊模型平台中的“添加”,這裏需要填入模型ID。進入ideaLab提供的模型清單,複製模型ID,填入即可。注意,選擇的模型必須要有工具調用能力。
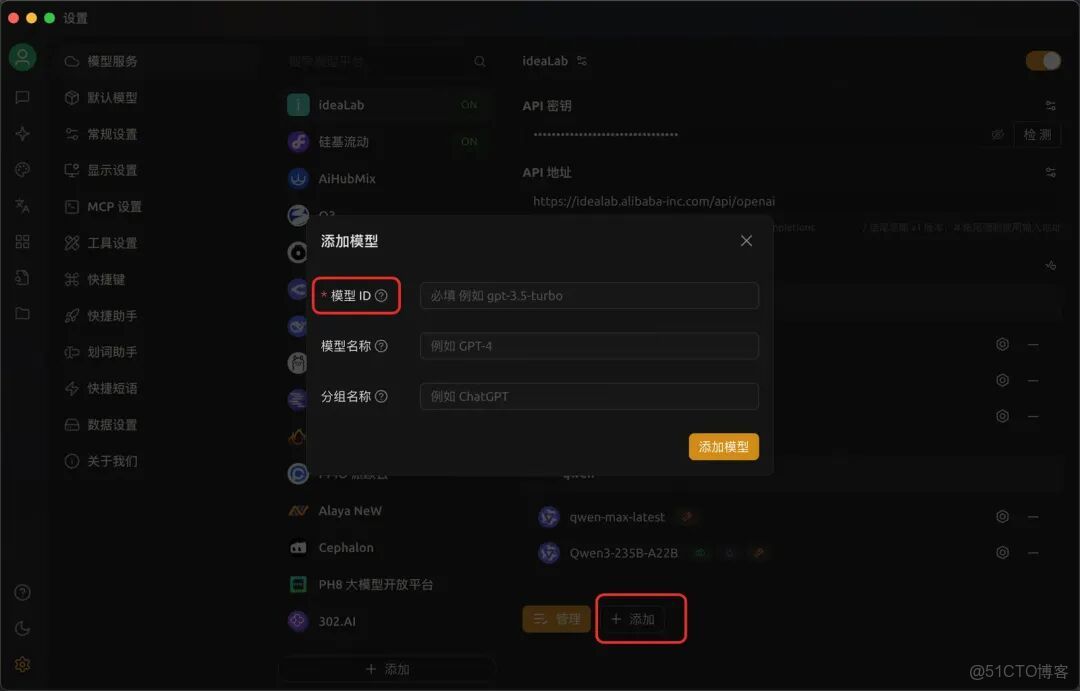
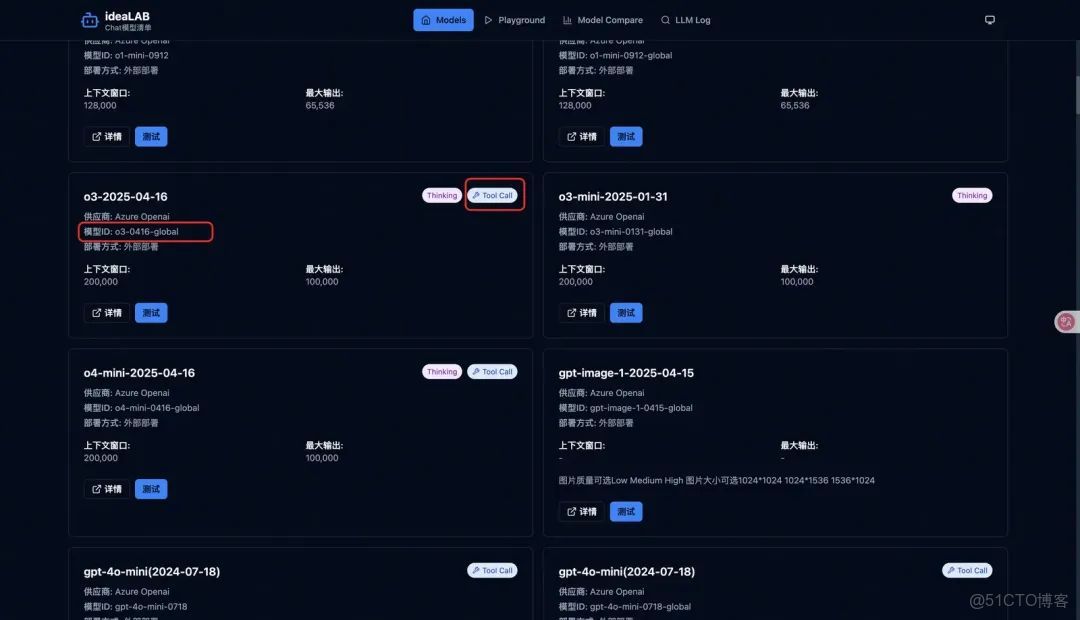
ideaLab模型清單
5.點擊“助手”,選擇配置的模型,測試連通性。
6.回到設置,選擇“MCP設置”,點擊添加服務器–快速創建。(若需要安裝依賴,跟着客户端教程無腦安裝即可)
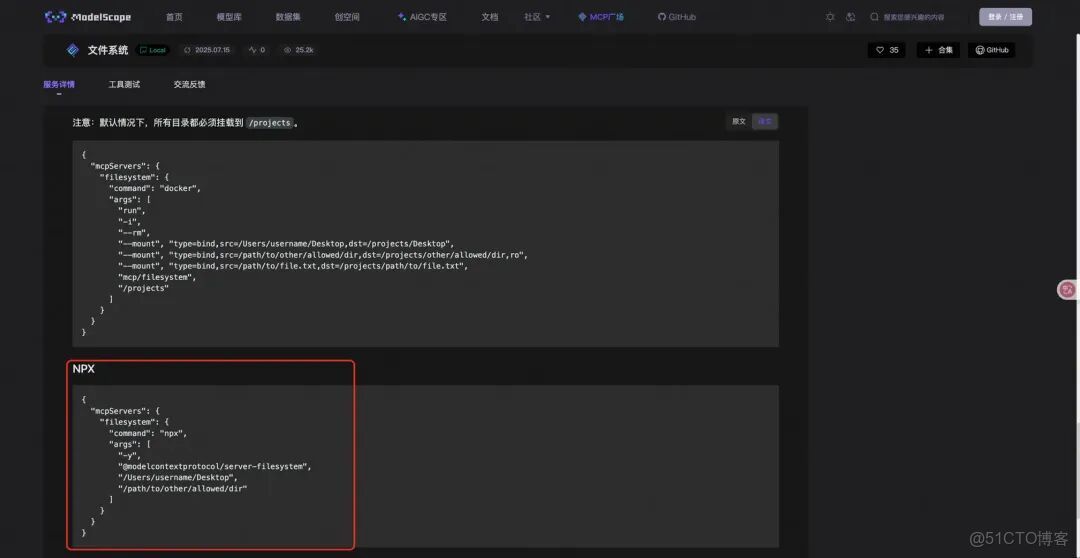
7.配置MCP Server。這裏以魔搭社區提供的文件系統服務為例。
魔搭社區
8.進入後可以看到服務提供的工具,我們以stdio方式安裝。

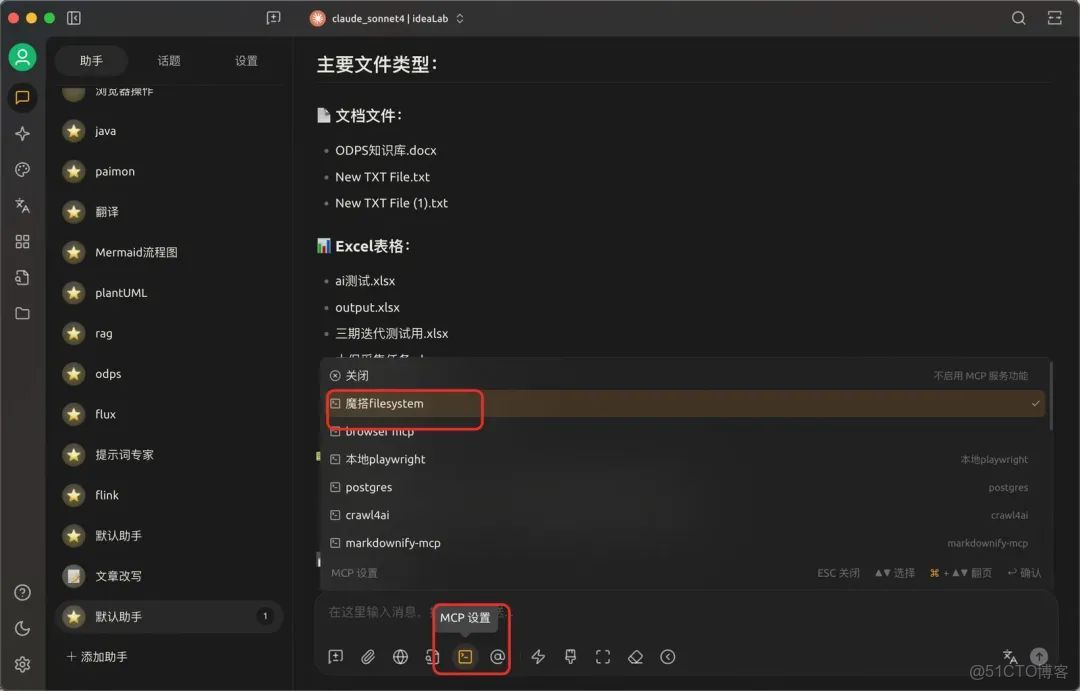
9.點擊助手–MCP設置,選擇剛才配置好的MCP Server。(再次強調,模型必須要有工具調用能力)
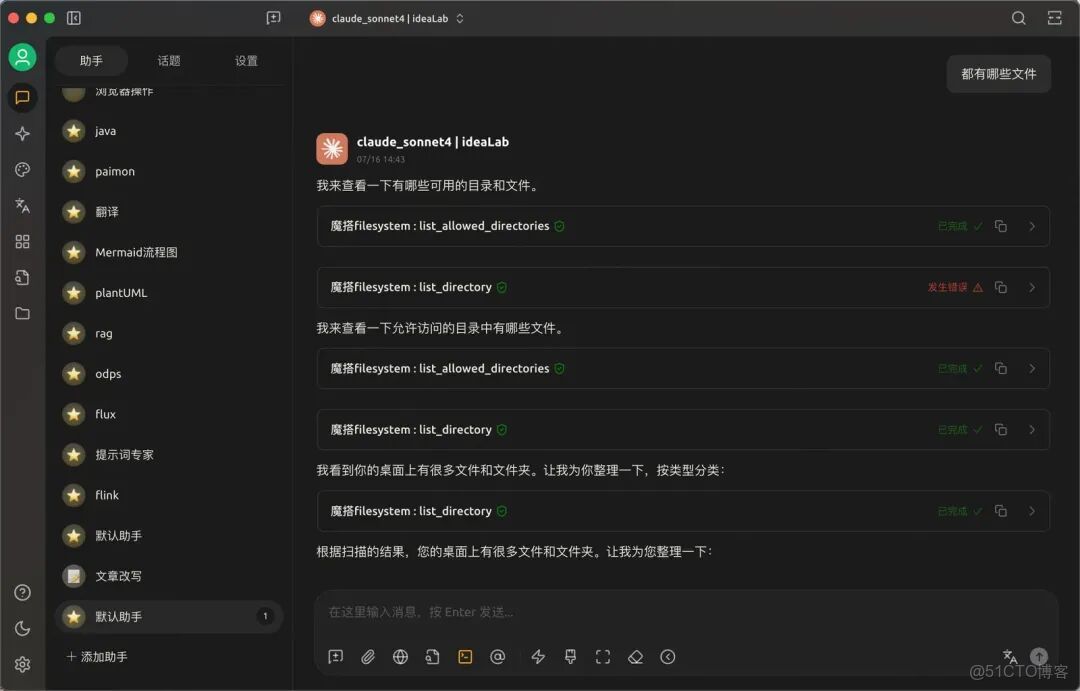
10.測試工具調用效果。
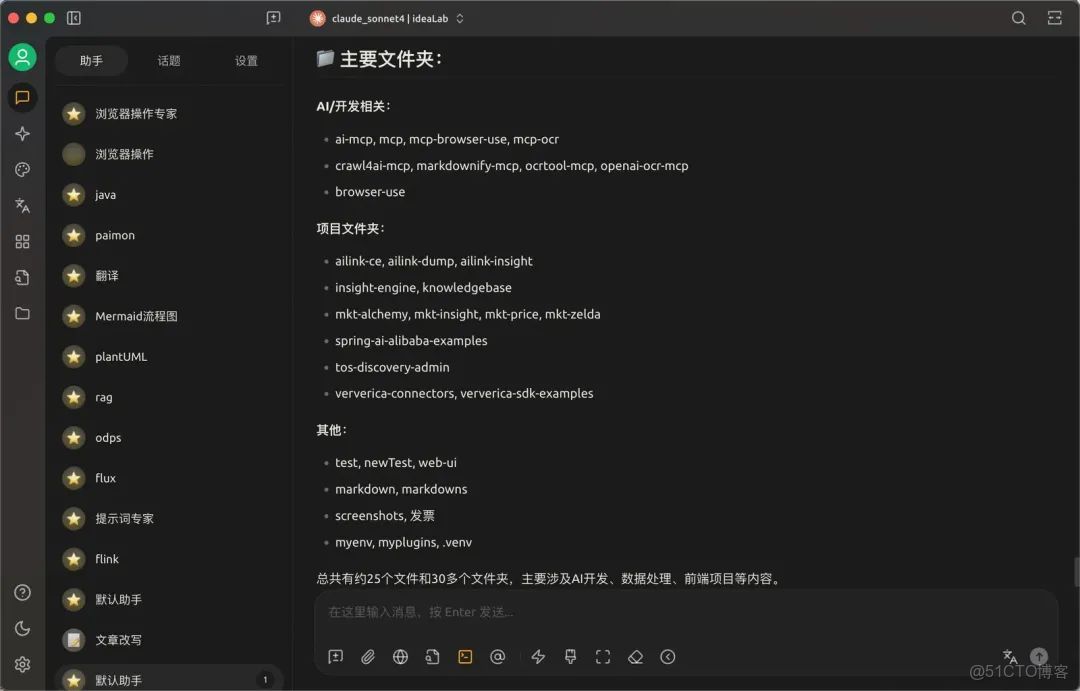
實際體驗後,不知道大家有沒有體會到MCP的作用:MCP Client使用統一的配置方式,可以快速接入各種各樣的工具。沒有工具調用能力的agent,最多就是充當「百科全書」的角色。而當agent可以進行工具調用,就可以把agent當作是一個「人」來看待了。工具調用大大拓展了agent的能力邊界,它可以像我們一樣寫文件或是操作瀏覽器。那麼上述的看報表場景痛點,或許可以通過agent + MCP的方式解決。
1.4. 瀏覽器操作探索過程
1.4.1. 服務選擇
瀏覽器相關的MCP Server主要分為以下兩類:
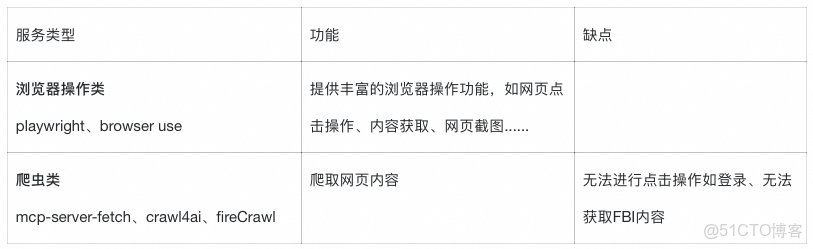
playwright-mcp:一個模型上下文協議(MCP)服務器,利用 Playwright 提供瀏覽器自動化功能。該服務器使大型語言模型能夠通過結構化的可訪問性快照與網頁進行交互,無需依賴截圖或視覺調優模型。目前仍在活躍更新中。
playwright Releases版本
其提供的工具列表如下,可以直接在github中查看:
|
能力
|
工具
|
解釋
|
|
核心自動化功能
|
browser_click
|
點擊操作
|
|
browser_close
|
關閉瀏覽器
|
|
|
browser_console_messages
|
獲取控制枱消息
|
|
|
browser_drag
|
按住鼠標左鍵進行拖拽
|
|
|
browser_evaluate
|
評估JavaScript
|
|
|
browser_file_upload
|
上傳文件
|
|
|
browser_hover
|
將鼠標懸停在頁面上的某元素
|
|
|
browser_navigate
|
導航到指定URL
|
|
|
browser_navigate_back
|
返回上一頁
|
|
|
browser_navigate_forward
|
前進到下一頁
|
|
|
browser_network_requests
|
獲取所有網絡請求
|
|
|
browser_press_key
|
模擬鍵盤操作
|
|
|
browser_resize
|
調整瀏覽器窗口大小
|
|
|
browser_select_option
|
在下拉列表選擇選項
|
|
|
browser_snapshot
|
獲取頁面快照
|
|
|
browser_take_screenshot
|
截圖
|
|
|
browser_type
|
在可編輯元素中輸入文本
|
|
|
browser_wait_for
|
等待文本出現或消失,或等待指定時間
|
|
|
標籤頁管理
|
browser_tab_close
|
關閉標籤頁
|
|
browser_tab_list
|
列出標籤頁
|
|
|
browser_tab_new
|
打開新標籤頁
|
|
|
browser_tab_select
|
選擇標籤頁
|
|
|
瀏覽器安裝
|
browser_install
|
安裝配置中指定的瀏覽器
|
|
基於座標 使用 --caps=vision開啓
|
browser_mouse_click_xy
|
點擊指定座標
|
|
browser_mouse_drag_xy
|
按住鼠標左鍵,拖拽到指定座標
|
|
|
browser_mouse_move_xy
|
把鼠標移動到指定座標
|
|
|
PDF生成 使用 --caps=pdf開啓
|
browser_pdf_save
|
將頁面另存為PDF
|
測試playwright-mcp的效果,還是以cherry studio舉例。
1.在設置–MCP服務器中,添加一個服務器,類型選擇「stdio」,命令輸入「npx」,寫入參數如圖。-y 可以讓agent自動進行工具調用而無需等待用户同意;@playwright/mcp@0.0.27 指定安裝的工具及版本,也可以指定@playwright/mcp@latest;–headless開啓無頭模式,agent的瀏覽器操作不會打開一個可見的瀏覽器,如果想要看瀏覽器的調用過程就移除這個參數。
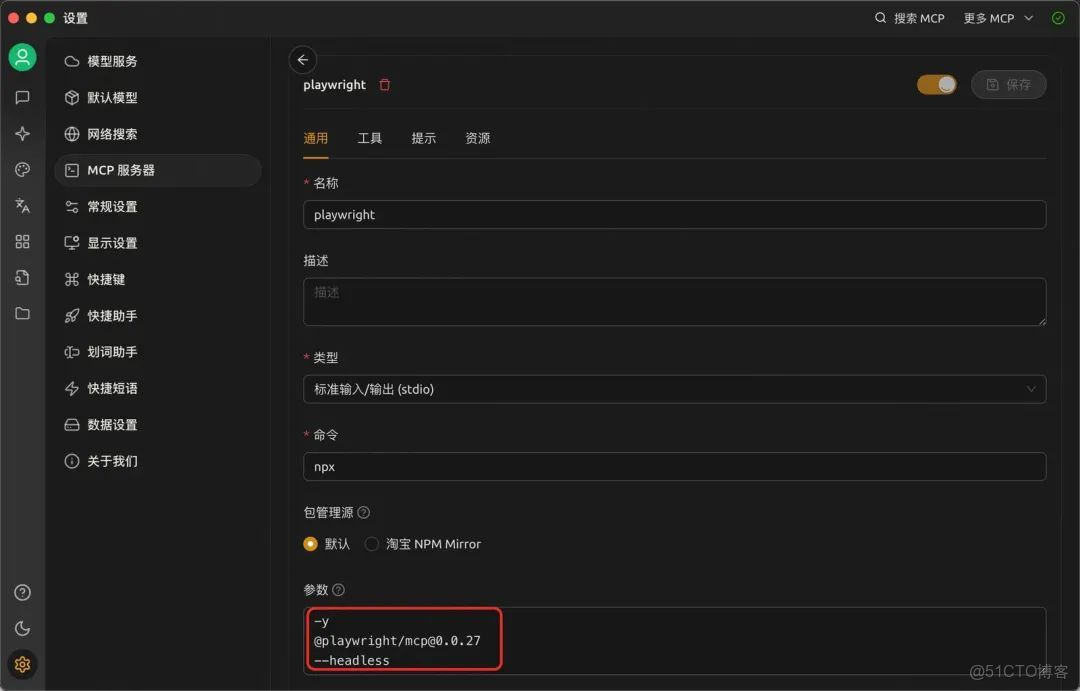
2.回到聊天助手頁面,打開MCP服務器,選擇剛才配置好的MCP Server。
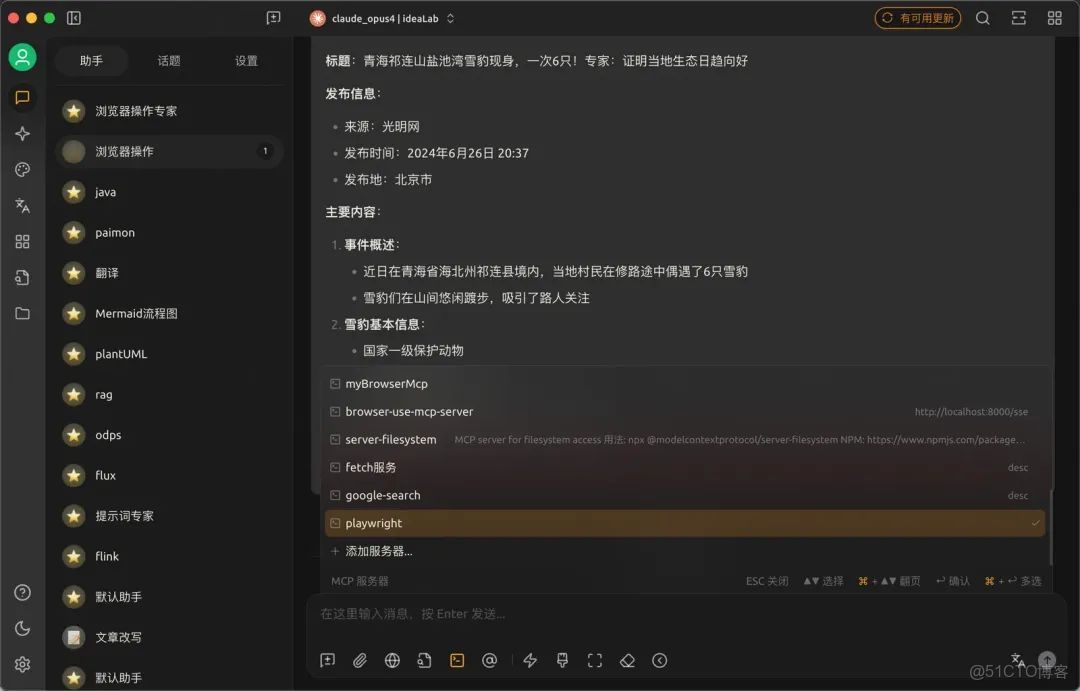
3.讓agent總結網頁內容,效果如下。
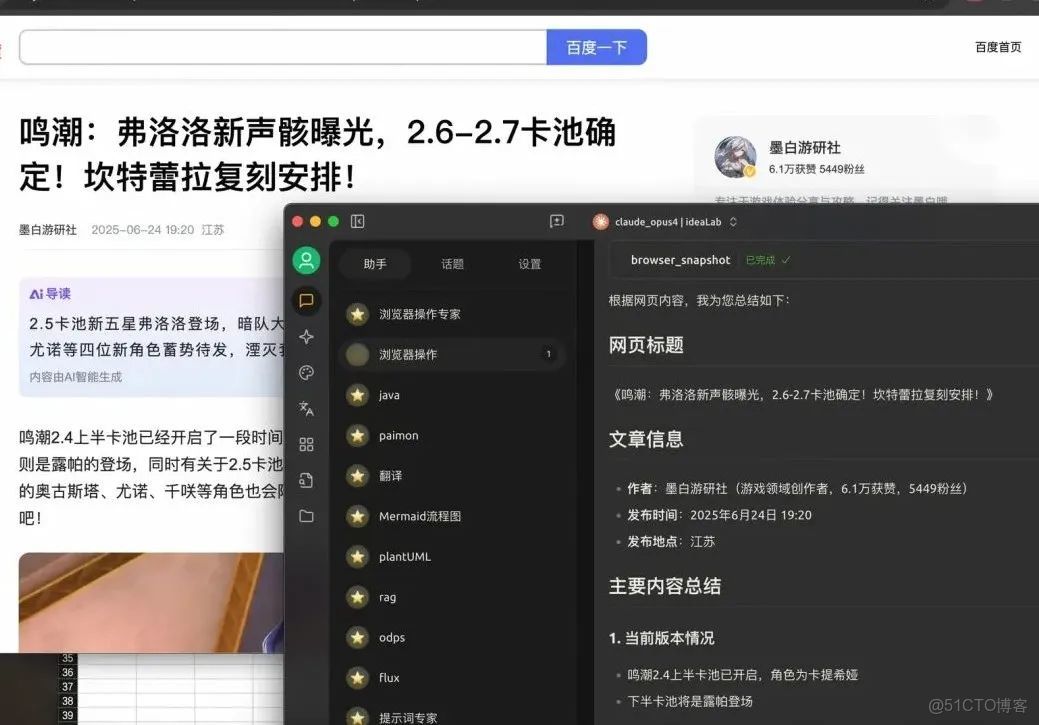
1.4.2. 環境準備
若要在項目環境中使用agent和mcp服務,需要以下準備。
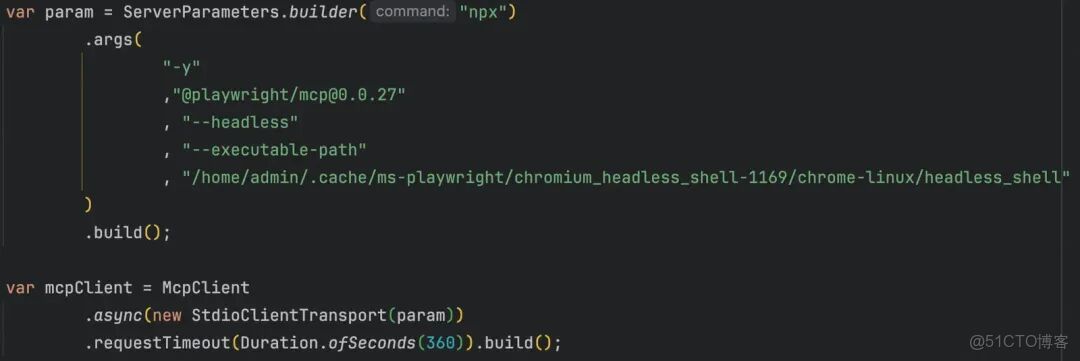
1.工程dockerFile中需安裝playwright,並解決大量的依賴問題。(也可以新建docker,但只能用sse或streamableHttp模式)

2.Java工程中需要使用Spring-Ai或Spring-Ai-Alibaba框架進行Agent開發。創建MCP Client時需確保是無頭模式且要指定playwright的無頭瀏覽器路徑。
1.4.3. agent構建
有了工具的支持,就可以設置定時任務讓agent看報表了。對於不同的報表場景,定時時間、具體的網頁操作、要關注的指標、聯繫人等都各不相同。對數據類型進行劃分,主要分為以下兩類。
|
配置類:觸發agent
|
補充信息類:agent拿到後執行具體任務與生成結果
|
|
模型相關配置(選擇什麼模型,模型的温度)、定時時間、觸發提示詞。如圖就是一段期望每天早上09:30執行的場景配置。
|
不同場景的工作流、要打開的url、瀏覽器窗口大小、結果標題與內容格式、規定異常數據、具體示例等。
|
構建系統提示詞時,先使用agent生成一個提示詞框架,然後基於agent的行為與結果不斷調整。
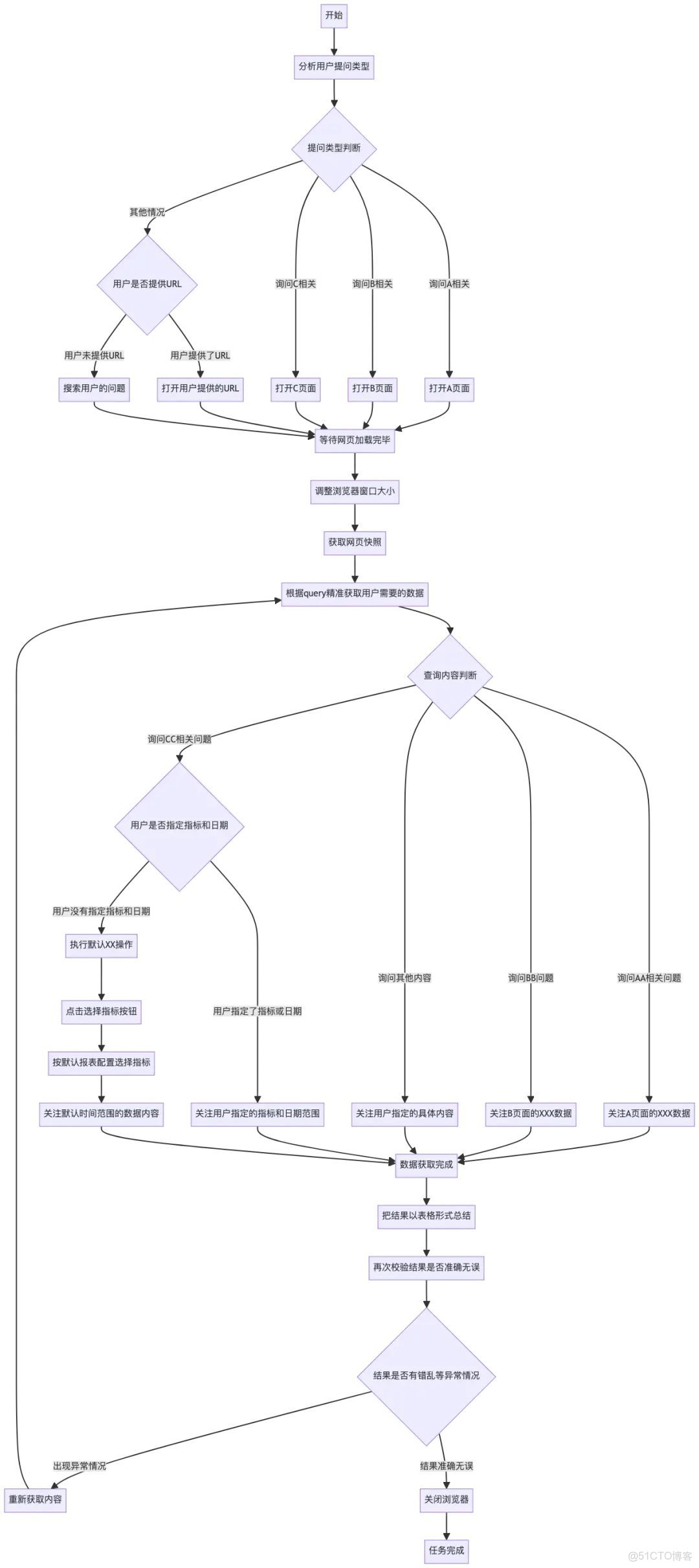
最開始構建時,我把不同的場景全部放到了系統提示詞中,通過mermaid的選擇節點來區分不同的場景,如下圖。但隨着場景的增多,會導致流程描述越來越複雜,這種方案肯定是不行的。
於是想到把不同場景的不同信息保存到向量數據庫中,但向量數據庫更適合保存非結構化文本。現在需要保存的是不同場景的元數據信息,不太適合保存到向量數據庫中。於是嘗試把數據保存到關係型數據庫中,表結構中我設置了keywords列,用户提問後agent會先查詢keywords,進行語意匹配,返回最適合的id,再查詢id對應的其他信息。若沒有匹配的keywords,則按照用户提供的信息進行任務,這一步其實就是RAG做的事情。流程如下。
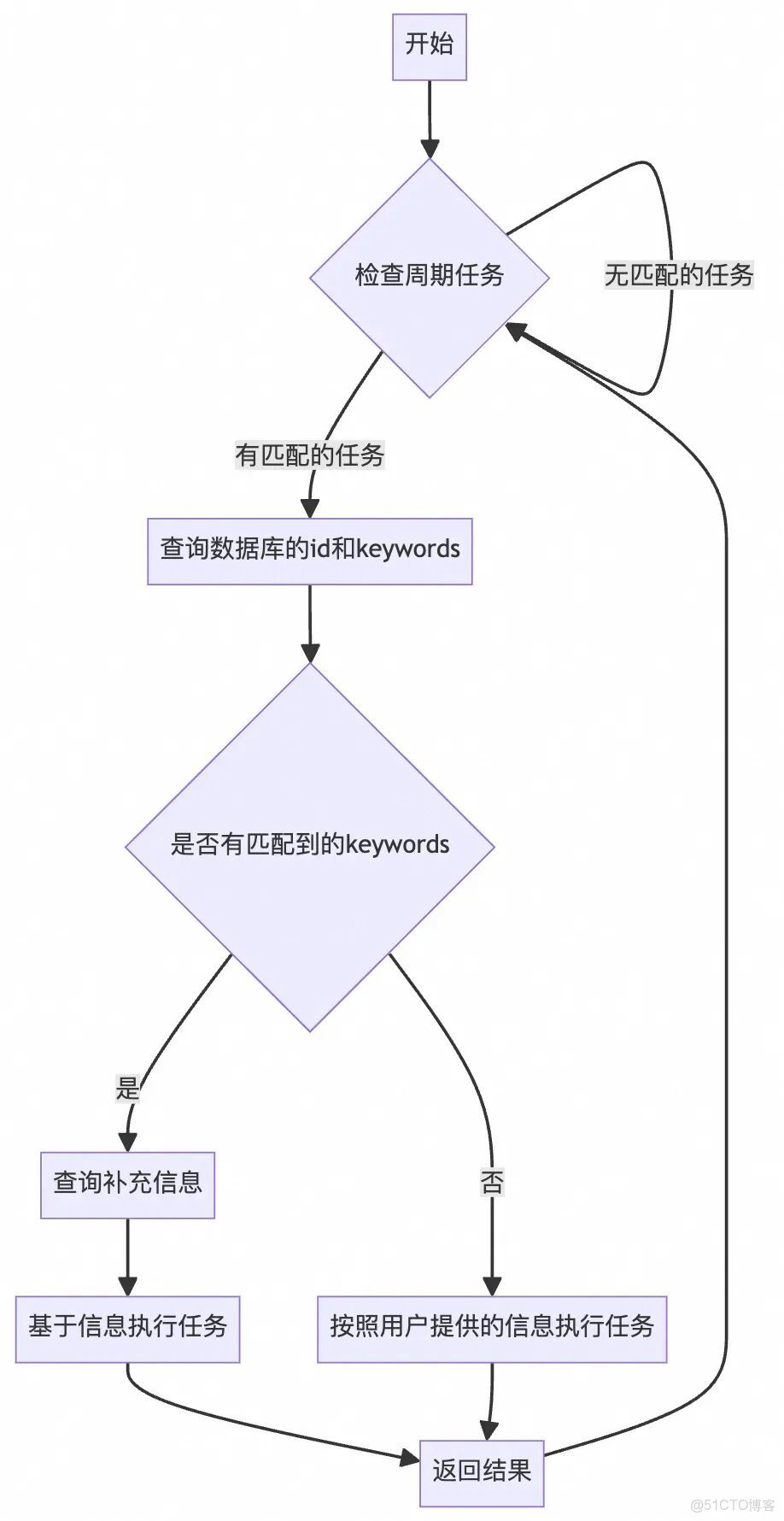
若擔心agent生成危險的sql,也可以直接在系統提示詞中寫好需要執行的sql,並且創建一個只用來讓agent調用的數據庫,不要直接讓agent調用線上的庫表,降低風險。
1.4.4. 消息推送
消息推送可以在工程中結合釘釘機器人實現。只需要在知識庫(數據庫)中配置好場景結果的聯繫人工號或羣id,讓agent按照指定JSON格式返回結果,工程解析後就可以實現釘釘消息推送。
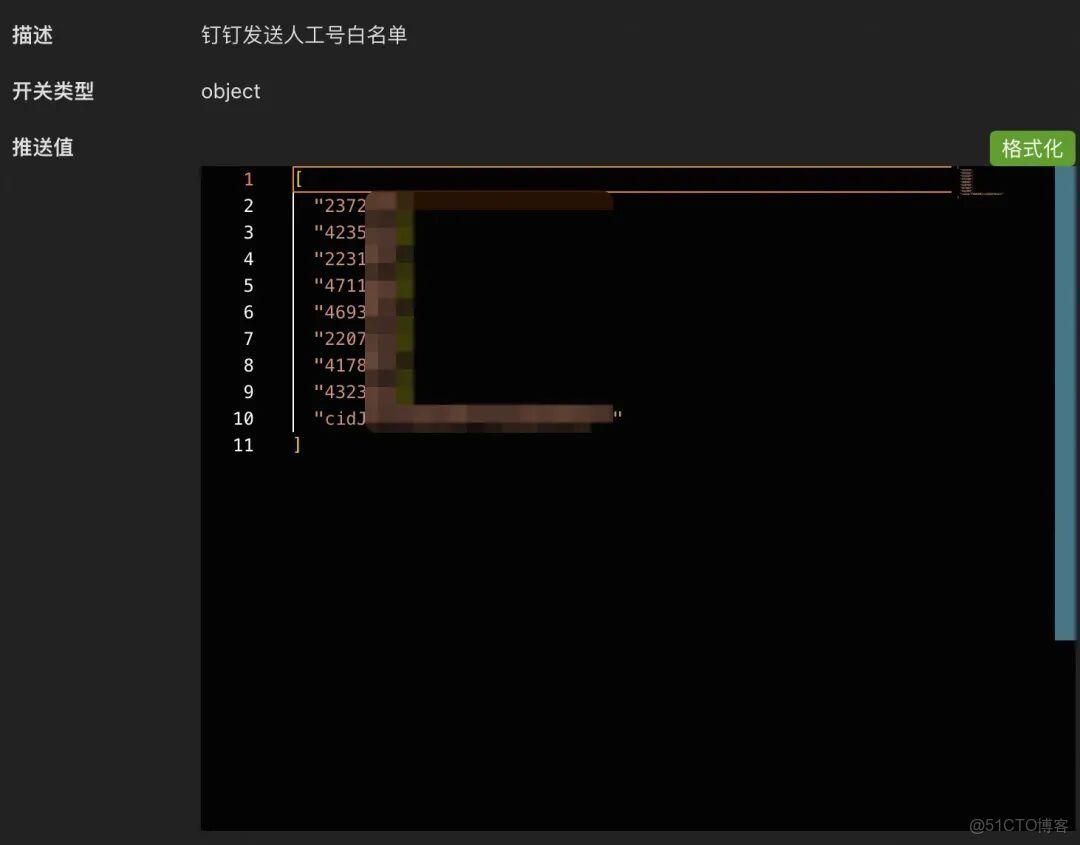
為了避免把消息發送給無關的人或羣,在Switch中配置工號/羣號白名單,工程中作強校驗。
1.4.5. 已有場景介紹
目前有如下三個場景已驗證且穩定執行,並且有其他場景待接入:
1.每天09:30查看某報表是否存在異常數據(指定日環比小於-20%),如果有異常數據,就發送釘釘消息給相應負責人。
2.大促上線時,每半小時查看某任務的的執行情況並在羣中播報。

3.每天11:00查看報表某指標,若小於90%,則打開另一個指定頁面,篩選後關閉開關。
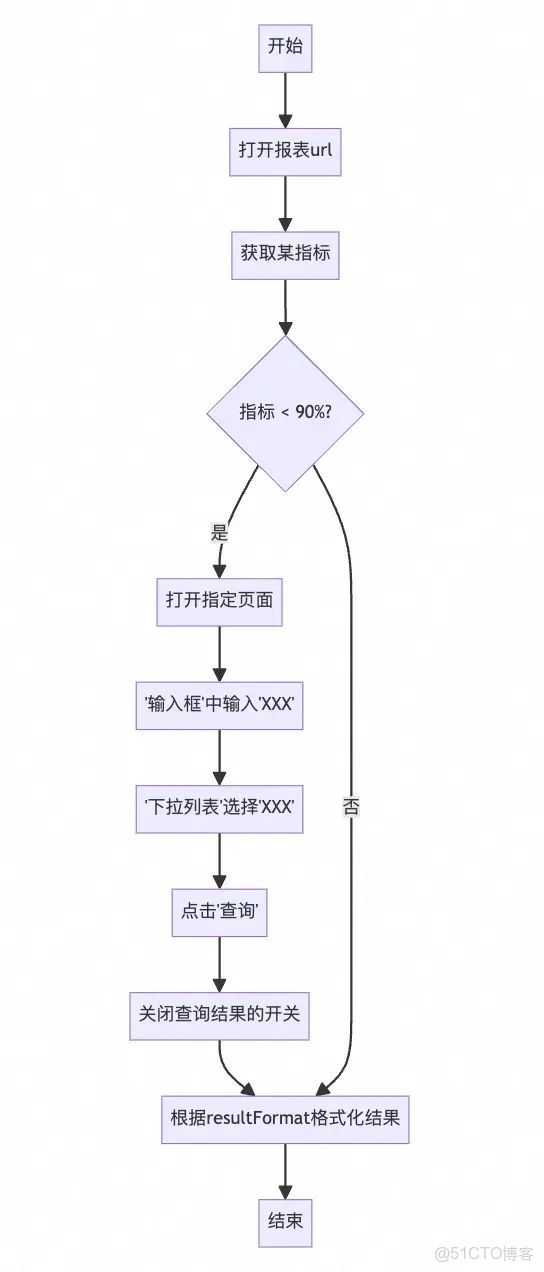
1.4.6. 問題彙總
使用過程中遇到的問題如下:
1.瀏覽器窗口大小會影響快照結果。基於實際經驗設置窗口大小為3840*2160可以滿足大部分場景。也可以在提示詞中説“為了獲取完整結果,你需要調整合適的窗口大小”。
2.表格數據容易出現數據錯亂的情況,可能需要在examples中模擬表格數據。需要在靈活性與準確性中找到平衡點。
3.提示詞中約束agent可以獲取的快照內容,如“遵守快照內容最小獲取原則”。否則容易導致token直接超出限制。
4.提示詞中限制失敗重試最大次數,否則agent可能會重複調用失敗方法。如“若某操作執行失敗,重試三次之後換一種操作方式。若仍然失敗,則結束任務”。
5.瀏覽器操作最後一定要關閉瀏覽器。playwright執行新任務會默認打開新的瀏覽器窗口,若不關閉,可能出現資源泄漏和端口衝突問題。
6.釘釘markdown消息不支持表格類型,不適合返回大量數據的場景。

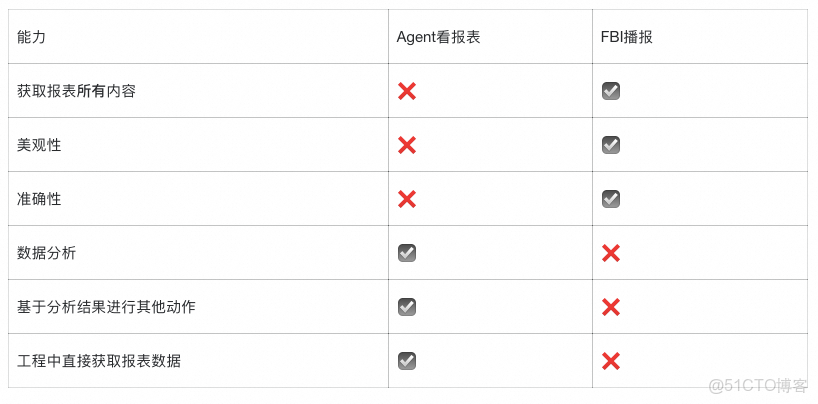
1.4.7. Agent看報表與FBI播報對比
對比如下表。總體來説,前者可以不侷限於FBI平台,任何頁面都可以通過agent + playwright-mcp 的方式進行操作處理,並且可以輕鬆獲取頁面的數據。但若只是定時播報,直接使用FBI的播報能力即可。
二、Agent批量建任務
1.1. 業務背景與問題
在大促與日常切換時,運營會在某平台基於excel的內容進行批量任務的創建與暫停操作。目前存在以下痛點:
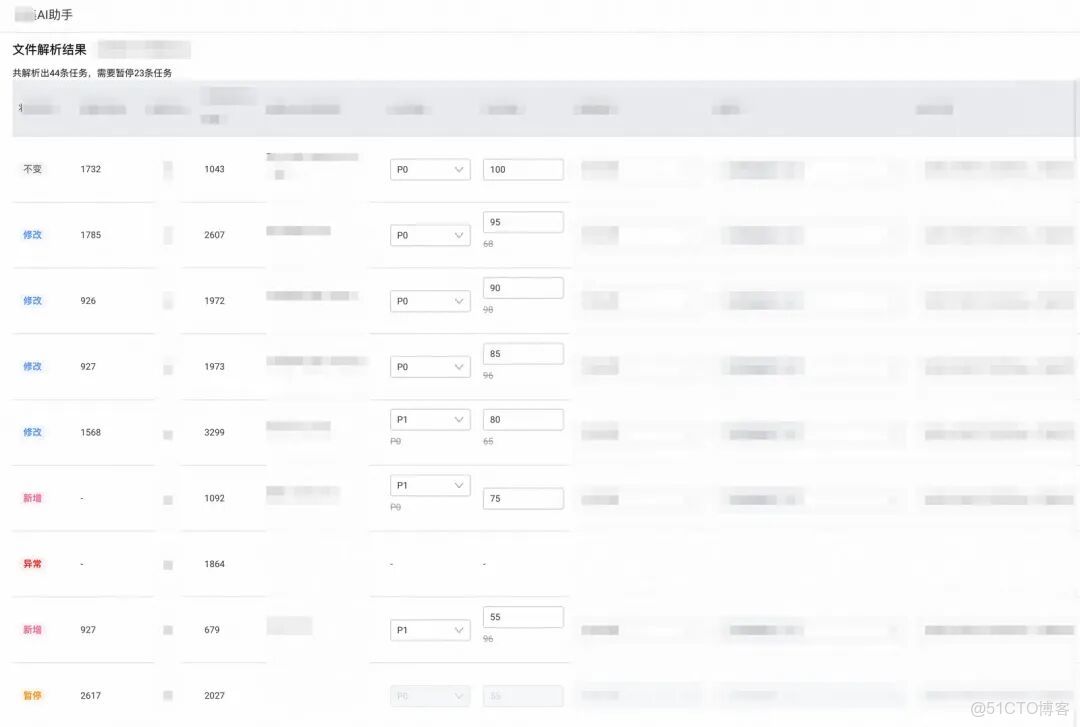
1.任務量過多,任務的配置都不相同,每次操作需一小時左右。
2.需人肉對比excel中的任務與線上的任務,判斷哪些任務應該新增創建、哪些任務應該修改,且要找到所有不存在於excel中的任務並暫停。
在這個背景下,嘗試引入agent,期望讓agent基於excel和已有的任務自動生成結果,解放人力。
1.2. Agent批量建任務探索過程
1.2.1. 能力嘗試:只讓Agent處理最簡單的場景
首先只考慮最簡單的情況,試驗可行性:對於上傳的所有任務,統一按照新增處理。通過工程解析excel,在ideaLab中配置agent,並在提示詞中增加字段轉換規則(即將excel的字段內容轉換為枚舉值)和補充信息規則(即給每個任務添加默認屬性和默認值),agent處理流程圖如下。
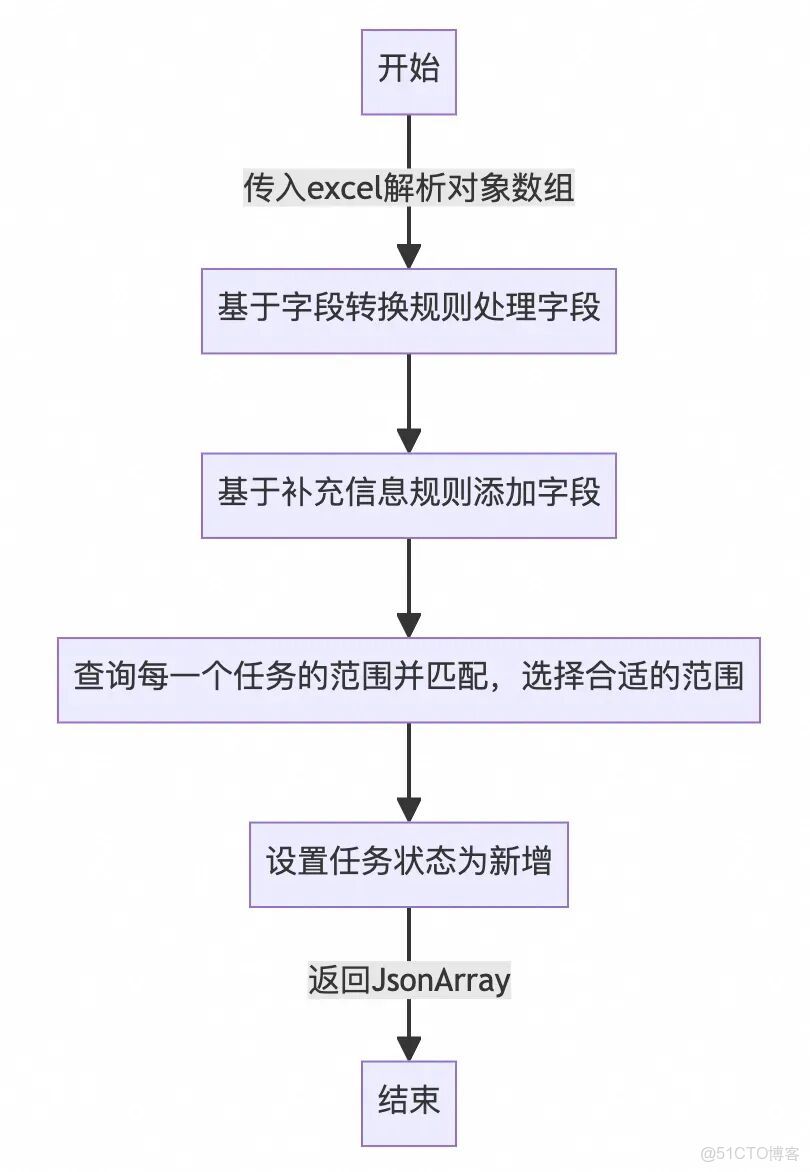
在該場景下,任務範圍需要由agent調用工具並基於一定規則進行匹配。可以在ideaLab中添加工具實現。
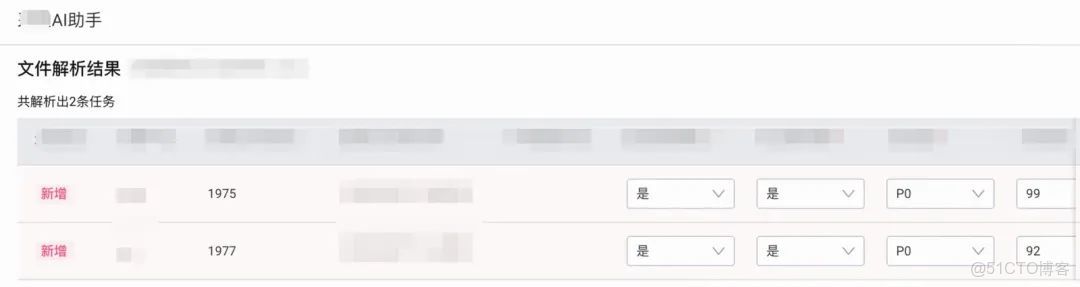
最終效果如下。Agent可以完成該場景下的“NL2Task”任務。於是繼續探索更加複雜的場景。
1.2.2. 初見端倪:完全讓Agent處理複雜邏輯
現在需要讓agent處理更加複雜的場景,要對比上傳的任務和已經存在的任務。agent處理流程圖如下。
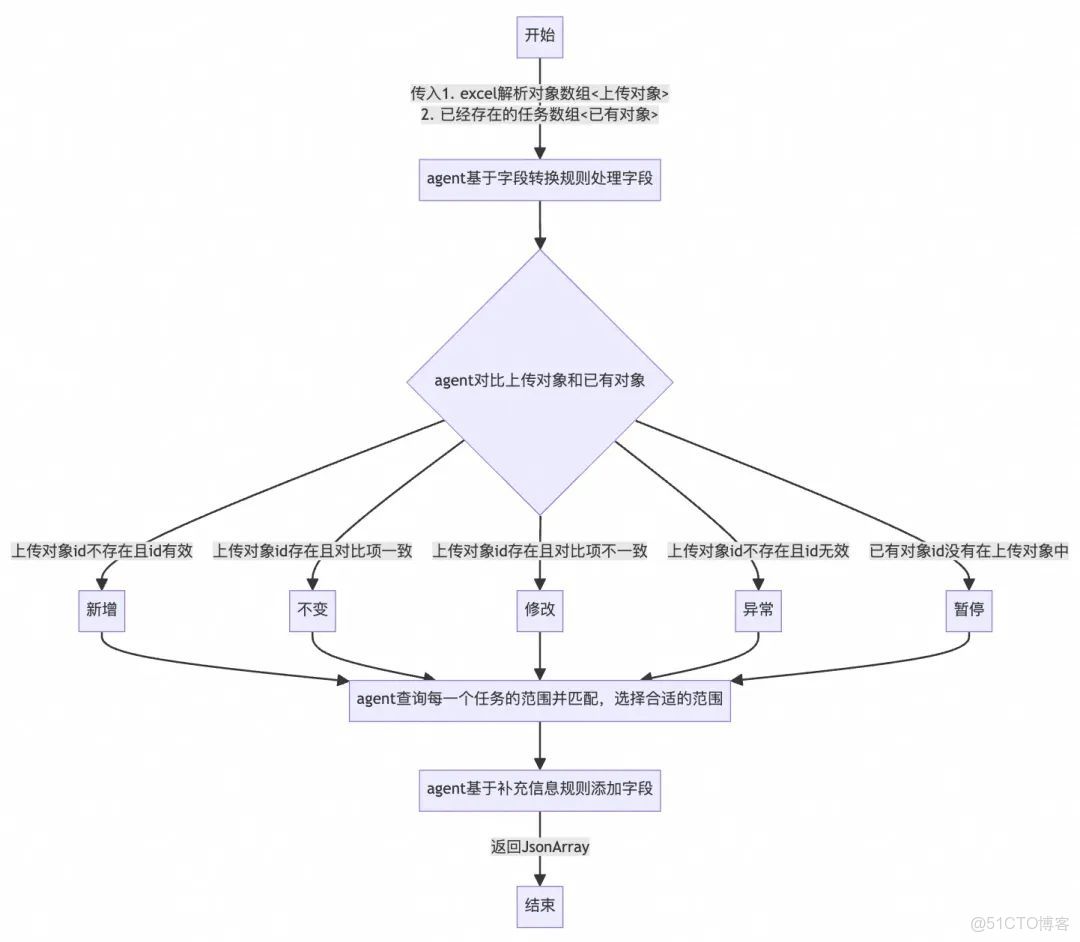
相比於初版,複雜點在於:
1.輸入token更多:需要把已經存在的任務信息全部交給agent;
2.處理更加複雜:需要對比每一個上傳對象和已有對象,尋找差異;
在與實際業務結合後,出現了以下問題:
1.運營每次需要處理50個左右的任務,若一次性讓agent處理所有任務,agent的回答速度非常慢且質量很差;
2.小二工作台限制HSF方法等待時間最大為60s且不支持sse,無法保證agent在規定時間內完成響應;
解決方式如下:
1.拆分任務,併發調用。經過測試,調用ideaLab的agent請求接口最多支持10併發;
2.從同步等待改為異步輪詢,將agent結果保存到redis中;
雖然拆分了任務,減少了每次處理的任務數量,但是我在調試時發現輸入token數量非常龐大,一次調用就需要4w左右,再加上我把任務拆成了十份,那麼調用一次成本就在40000/1000*0.1*10=40元左右。

成本問題無法避免。並且因為token輸入過多,模型響應速度很慢,平均在25s左右才會進行首次響應。且我花費了大量時間調整提示詞,生成的結果依舊無法保證比較高的準確性,包括但不限於字段轉換錯誤、範圍匹配錯誤、漏處理任務等問題。
現在回過頭來重新考慮這個場景:

前面三點,工程不僅可以幹,而且處理的更精準,更快!換句話説,這個事情本來就應該工程做,強行讓agent做,耗費大量精力和財力,最終效果也是差到無法交付的地步!
1.2.3. 各取所長:工程 + agent結合高效處理
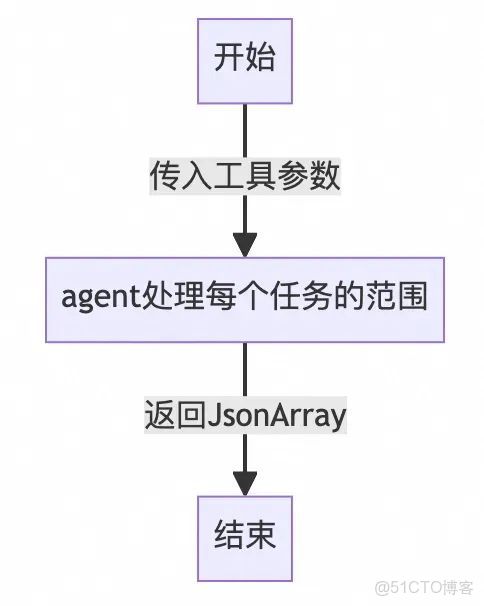
最終對流程進行重構,工程處理除了任務範圍的所有工作,agent處理流程圖如下。任務範圍因為要根據excel的內容基於規則進行語意匹配,還是適合agent處理。
最終agent只幹一件事情,減少了輸入輸出token,提高了響應速度和回答質量,再結合工程保障準確性,效果非常好。
三、總結
以上兩個場景都將agent與工程進行結合並作用於實際業務場景中,目的是為了利用Agent提效。但第二個場景起初讓agent做了不適合的工作,反而降低了效率。以下列出agent和工程的能力對比。
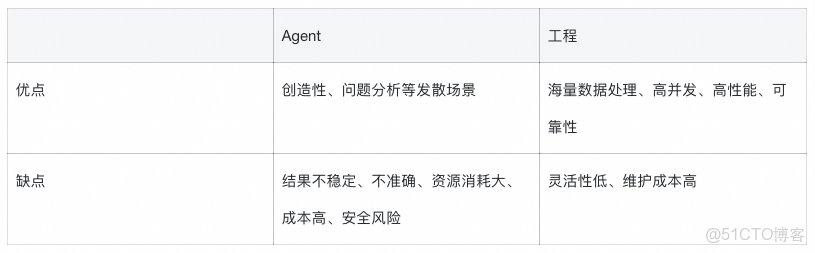
agent的本質還是概率遊戲,它並不是萬能的,千萬不要把任何場景問題都一股腦全部丟給agent,期望它可以給出一個完美的結果。現階段的最優策略是將agent與工程結合使用,揚長避短。在做技術方案時,要充分考慮每一環適合用什麼工具解決。在具體實踐時,若發現方向不對且嘗試調整過後仍然得不到比較好的結果,就及時更換方向,不要死磕。只有準確理解各種技術的邊界和長處,才能構建出真正高效、穩健的解決方案。