
最近看了黃老師的視頻課,一下子覺得自己對這些內容又生疏了,於是找來看了看。現在記錄一下 一、框架 框架的選擇上,我看老黃選擇的也是這張圖,正好作者有點料,於是直接將鏈接添加鏈接描述附上。 這裏有個點,這裏的圖很重要。注意,LSTM的輸出中,每個字輸出為label的概率。 二、LSTM的參數量
- 參數量計算
- LSTM的官方文檔
- LSTM的結構圖如下
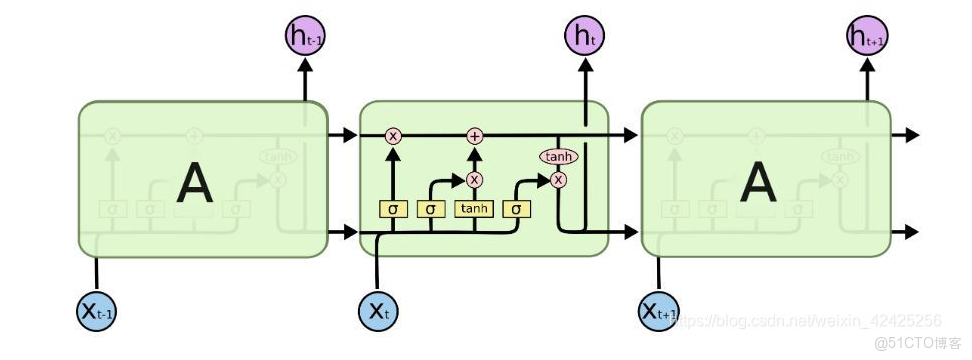
- lstm的計算公式為:
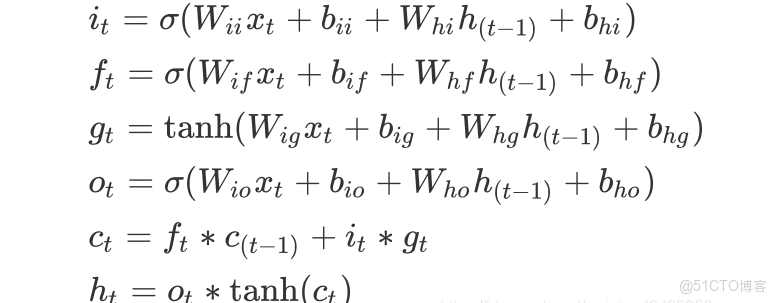
- GRU的結構圖為:
- 圖中的zt和rt分別表示更新門和重置門。更新門用於控制前一時刻的狀態信息被帶入到當前狀態中的程度,更新門的值越大説明前一時刻的狀態信息帶入越少。重置門控制前一狀態有多少信息被寫入到當前的候選集 h~t 上,重置門越小,前一狀態的信息被寫入的越少。
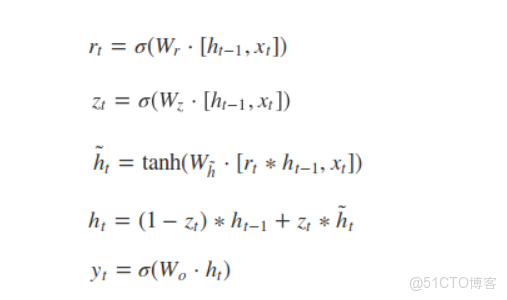
- 更新門是GRU的主要精髓。公式分析時,主要看更新門的寫法 注意:rt和zt都是從h(t-1)和xt得來的,其實包含了他們之間的相關性。
三、CRF的詳細介紹
- 參考這位大哥的博客博客,我找到了印象深處的英文解釋添加鏈接描述。從而加深了對章一 中的理解。
- 這篇文章,從CRF的起源講起,很好。
- 此外,我記得依靠模板,crf本身就可以用機器學習的方式(添加模板,U和B模板)來進行BIO學習。我的筆記裏有。
- BILSTM算出來的是 每個字為每個標籤(BIO)的發射概率,CRF算出來的是 字與字之間的轉移概率。
- loss函數 是:最有路徑 和全路徑的函數。
- 預測:維特比算法。
- 維特比算法為什麼不存在 最大熵模型的標註偏置問題?答:因為 維特比算法 的歸一化 是 所有路徑的全局歸一化;最大熵模型的歸一化 是從previous出發的局部歸一化,局部歸一化會造成局部問題,即 標註偏置問題
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。