
一.軟件的下載與卸載:
默認安裝在C:Profiles,可以調整安裝位置 卸載: 1、卸載安裝目錄 2、使用過程中可能存在臨時文件和運行文件,需要將此目錄一併刪除 3、部分軟件(如MySQL)需要在電腦的服務中將相關服務停止並刪除
二、Java
1、註釋:
註釋就是給程序説明的作用,增強代碼的可讀性,JVM運行時註釋不會被解析,JVM會跳過註釋。
- 多行註釋:/*..... */,通常用於方法內的多行或者類的多行註釋。
- 單行註釋://,註釋代碼中的一行,建議大家放在要註釋的代碼的上面
- 文檔註釋:/**.. */,用於類的説明和方法的説明。
2、標識符:
- 在java語言中,對各種變量,方法和類等要素命名時説使用的字符序列就是標識符,這些標識符有JDK定義好的,也有我們自己開發時候需要定義的。
- java中標識符由26個英文字符大小寫,數字0-9,符號_$。注意:數字不能開頭。
- java中時嚴格區分大小寫。
- 類名和接口的規範:在上面的約束的命名規範的情況下, 首字符要大寫,如果由多個 單詞構成每個單詞的首字符都大寫。
- 變量名和方法名:在上面的約束的命名規範的情況下,單詞首字符不要大寫,如果由多個單詞構成,從第二個單詞起首字符都大寫。
- 包名:在上面的約束的命名規範下,都小寫。
- 常量:所有字符都大寫,多個單詞之間使用下劃線來分割。
- JDK定義的標識符就是關鍵字。
3、數據類型:
Java中的數據類型
Java的數據類型分為基本數據類型和引用數據類型。
基本數據類型分為數值類型、布爾類型(boolean)、字符類型(char)。
數值類型又分為整數類型和小數類型。
整數類型裏面有字節類型(byte)、短整型(short)、整形(int)、長整型(long)
小數類型裏面有單精度(float)、雙精度(double)。
|
整數類型
|
類型
|
佔用存儲空間
|
表述範圍
|
|
byte
|
1字節
|
-128-127
|
|
|
short
|
2字節
|
-2^15~(2^15) -1
|
|
|
int
|
4字節
|
|
|
|
long
|
8字節
|
|
1個字節佔8個二進制位(裏面只有0和1)
數值類型中最常用的類型就是int,其次是long。如果寫的類型是long類型,那麼就得加上L
|
小數數類型
|
類型
|
佔用存儲空間
|
表述範圍
|
|
float
|
4字節
|
|
|
|
double
|
8字節
|
|
|
Float和long比較由於存儲結構不同,float比long表示的範圍大。如果寫的類型是float類型,那麼必須加上F。
字符類型佔用2個字節。 布爾類型只有true和false兩個值。
js中的數據類型
在js中也分為基本數據類型和引用數據類型,基本數據類型是不可變的(值本身無法被修改),存儲在棧內存中,賦值時直接複製值
基本數據類型:
- Number(數字)
- 包含整數、浮點數、NaN(Not a Number,非數字)、Infinity(無窮大)。
- 示例:
let num = 100; let float = 3.14; let nan = NaN- String(字符串)
- 由單引號、雙引號或反引號(`)包裹的字符序列。
- 示例:
let str1 = 'hello'; let str2 = "world"; let str3 =js;- Boolean(布爾值)
- 只有兩個值:
true(真)和false(假)。 - 示例:
let isOk = true; let isEmpty = false;- Undefined(未定義)
- 變量聲明後未賦值時的默認值。
- 示例:
let a; console.log(a); // undefined- Null(空值)
- 表示 “空” 或 “不存在”,通常用於主動釋放對象引用。
- 示例:
let obj = null;- Symbol(符號,ES6 新增)
- 唯一的、不可變的值,用於對象的唯一屬性名。
- 示例:
let s = Symbol('id'); let obj = { [s]: 123 };- BigInt(大整數,ES2020 新增)
- 用於表示超出 Number 最大安全範圍(±2⁵³-1)的整數,結尾加
n。 - 示例:
let big = 9007199254740993n;引用數據類型:
引用數據類型是可變的,值存儲在堆內存中,變量存儲的是堆內存的引用地址,賦值時複製的是地址。
- Object(對象)
- 最基礎的引用類型,由鍵值對組成。
- 示例:
let obj = { name: 'js', age: 20 };- Array(數組)
- 特殊的對象,用於存儲有序數據集合,索引從 0 開始。
- 示例:
let arr = [1, 2, 3, 'hello'];- Function(函數)
- 可執行的代碼塊,也是一種特殊對象,有自己的屬性和方法。
- 示例:
function sum(a, b) { return a + b; }Mysql中的數據類型
MYSQL中的數據類型有很多,主要分為三類:數值類型、字符串類型、日期時間類型
|
分類
|
類型
|
大小
|
有符號(SIGNED)範圍
|
無符號(UNSIGNED)範圍
|
描述
|
|
數值類型
|
TINYINT
|
1 byte
|
(-128, 127)
|
(0, 255)
|
小整數值
|
|
SMALLINT
|
2 bytes
|
(-32768, 32767)
|
(0, 65535)
|
大整數值
|
|
|
MEDIUMINT
|
3 bytes
|
(-8388608, 8388607)
|
(0, 16777215)
|
大整數值
|
|
|
INT或INTEGER
|
4 bytes
|
(-2147483648, 2147483647)
|
(0, 4294967295)
|
大整數值
|
|
|
BIGINT
|
8 bytes
|
(-263, 263-1)
|
(0, 2^64-1)
|
極大整數值
|
|
|
FLOAT
|
4 bytes
|
(-3.402823466 E+38,3.402823466351 E+38)
|
0 和 (1.175494351 E-38,3.402823466 E+38)
|
單精度浮點數值
|
|
|
DOUBLE
|
8 bytes
|
(-1.7976931348623157 E+308,1.7976931348623157 E+308)
|
0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308)
|
雙精度浮點數值
|
|
|
DECIMAL
|
依賴於M(精度)和D(標度)的值
|
依賴於M(精度)和D(標度)的值
|
依賴於M(精度)和D(標度)的值
|
小數值(精確定點數)
|
|
分類
|
類型
|
大小
|
描述
|
|
字符串類型
|
CHAR
|
0-255 bytes
|
定長字符串
|
|
VARCHAR
|
0-65535 bytes
|
變長字符串
|
|
|
TINYBLOB
|
0-255 bytes
|
不超過255個字符的二進制數據
|
|
|
TINYTEXT
|
0-255 bytes
|
短文本字符串
|
|
|
BLOB
|
0-65 535 bytes
|
二進制形式的長文本數據
|
|
|
TEXT
|
0-65 535 bytes
|
長文本數據
|
|
|
MEDIUMBLOB
|
0-16 777 215 bytes
|
二進制形式的中等長度文本數據
|
|
|
MEDIUMTEXT
|
0-16 777 215 bytes
|
中等長度文本數據
|
|
|
LONGBLOB
|
0-4 294 967 295 bytes
|
二進制形式的極大文本數據
|
|
|
LONGTEXT
|
0-4 294 967 295 bytes
|
極大文本數據
|
CHAR和VARCHAR都帶有參數CHAR(10)這裏的10就代表最多存儲10個字符,定長字符如果你存的是一個字符,但是也會佔據10個字符的空間,未佔用的空間會使用空格進行補位,但是如果你使用的是varchar變長字符串的話會根據你所存儲的內容去計算當前所佔用的空間是多少。
|
分類
|
類型
|
大小
|
範圍
|
格式
|
描述
|
|
日期類型
|
DATE
|
3
|
1000-01-01 至 9999-12-31
|
YYYY-MM-DD
|
日期值
|
|
TIME
|
3
|
-838:59:59 至 838:59:59
|
HH:MM:SS
|
時間值或持續時間
|
|
|
YEAR
|
1
|
1901 至 2155
|
YYYY
|
年份值
|
|
|
DATETIME
|
8
|
1000-01-01 00:00:00 至 9999-12-31 23:59:59
|
YYYY-MM-DD HH:MM:SS
|
混合日期和時間值
|
|
|
TIMESTAMP
|
4
|
1970-01-01 00:00:01 至 2038-01-19 03:14:07
|
YYYY-MM-DD HH:MM:SS
|
混合日期和時間值,時間戳
|
強轉是否存在失真的現象?
在 Java 中,強制類型轉換(強轉)可能存在失真現象,具體取決於源類型和目標類型的範圍關係:
1. 當 源類型範圍 > 目標類型範圍 時,強轉可能失真
此時由於目標類型無法容納源類型的全部取值,轉換後可能出現數據溢出或精度丟失:
- 整數類型之間:例如
int(4 字節)轉byte(1 字節),超出byte範圍的值會溢出:
int num = 300;
byte b = (byte) num; // byte 範圍是 -128~127,300 溢出後結果為 44(300 - 256 = 44)浮點型轉整數型:會直接截斷小數部分(不是四捨五入),若整數部分超出目標整數類型範圍,也會溢出:
double d = 3.99;
int i = (int) d; // 截斷小數,結果為 3(精度丟失)
double bigD = 3000000000.0;
int bigI = (int) bigD; // 超出 int 範圍,結果為負數(溢出失真)布爾型不能強轉:布爾型(boolean)與任何其他類型之間不能相互強轉,編譯直接報錯
4、運算符
算術運算符
用於對數值類型進行加減乘除等運算,包括:
|
運算符
|
名稱
|
示例
|
説明
|
|
|
加法
|
|
兩數相加,也可用於字符串拼接
|
|
|
減法
|
|
兩數相減,也可表示負數(如 |
|
|
乘法
|
|
兩數相乘
|
|
|
除法
|
|
兩數相除,整數除法會截斷小數(如 |
|
|
取模(餘數)
|
|
求 |
|
|
自增
|
|
自身加 1, |
|
|
自減
|
|
自身減 1,規則同自增
|
int a = 5, b = 2;
System.out.println(a + b); // 7
System.out.println(a / b); // 2(整數除法)
System.out.println(a % b); // 1
System.out.println(++a); // 6(先加後用)賦值運算符
將右側值賦給左側變量,包括基礎賦值和複合賦值:
|
運算符
|
名稱
|
示例
|
等價於
|
|
|
基礎賦值
|
|
將 |
|
|
加後賦值
|
|
|
|
|
減後賦值
|
|
|
|
|
乘後賦值
|
|
|
|
|
除後賦值
|
|
|
|
|
取模後賦值
|
|
|
int a = 10;
a += 5; // 等價於 a = a + 5 → a=15
a *= 2; // 等價於 a = a * 2 → a=30比較運算符
用於比較兩個值的關係,結果為 true 或 false:
|
運算符
|
名稱
|
示例
|
説明
|
|
|
等於
|
|
判斷兩值是否相等(注意:引用類型比較地址)
|
|
|
不等於
|
|
判斷兩值是否不相等
|
|
|
大於
|
|
判斷 |
|
|
小於
|
|
判斷 |
|
|
大於等於
|
|
判斷 |
|
|
小於等於
|
|
判斷 |
int a = 5, b = 10;
System.out.println(a == b); // false
System.out.println(a < b); // true邏輯運算符
用於連接多個布爾表達式,結果為 true 或 false:
|
運算符
|
名稱
|
示例
|
説明
|
|
|
邏輯與(短路)
|
|
兩邊都為 |
|
||
|
邏輯或(短路)
|
a || b
|
|
|
|
邏輯非
|
|
取反( |
|
至少一邊為 |
boolean a = true, b = false;
System.out.println(a && b); // false(短路:右邊不執行)
System.out.println(a || b); // true(短路:右邊不執行)
System.out.println(!a); // false三元運算符
格式:條件表達式 ? 表達式1 : 表達式2
- 若條件為
true,結果為表達式 1;否則為表達式 2。
int x = 10, y = 20;
int max = (x > y) ? x : y; // 條件為false,結果為y → 20
String result = (x % 2 == 0) ? "偶數" : "奇數"; // 結果為"偶數"5、跳出循環的關鍵字:break,continue,return 區別
在循環結構中,break、continue、return 都可用於改變程序的執行流程,但它們的作用範圍和效果有顯著區別
1. break:徹底終止當前循環
- 作用:立即終止當前所在的循環(如
for、while、do-while),跳出循環體,繼續執行循環後面的代碼。 - 適用場景:當滿足某個條件時,無需繼續循環,直接結束整個循環
for (int i = 0; i < 5; i++) {
if (i == 2) {
break; // 當i=2時,終止整個for循環
}
System.out.println(i); // 輸出:0、1(i=2時循環終止)
}
System.out.println("循環結束"); // 會執行2. continue:跳過本次循環,進入下一次循環
- 作用:僅跳過當前循環的剩餘代碼,直接進入下一次循環的判斷條件(如
for的更新語句、while的條件判斷)。 - 適用場景:當滿足某個條件時,無需執行本次循環的後續代碼,但仍需繼續下一次循環。
for (int i = 0; i < 5; i++) {
if (i == 2) {
continue; // 當i=2時,跳過本次循環剩餘代碼
}
System.out.println(i); // 輸出:0、1、3、4(跳過i=2)
}
System.out.println("循環結束"); // 會執行3. return:終止當前方法(包含其中的循環)
- 作用:直接結束當前所在的方法,無論方法中是否有循環,都會立即退出方法,並返回一個值(無返回值方法中
return可省略返回值)。 - 適用場景:當滿足某個條件時,不僅要終止循環,還要結束整個方法的執行。
public static void test() {
for (int i = 0; i < 5; i++) {
if (i == 2) {
return; // 當i=2時,終止整個test()方法
}
System.out.println(i); // 輸出:0、1(i=2時方法終止)
}
System.out.println("循環結束"); // 不會執行(方法已退出)
}6、Switch分支判斷
- switch應用於等值判斷。
- switch的表達式只能是byte,short,char,int,但是1.7後可以使用String
- break可以省略不會報錯,如果省略就會穿透執行語句(不管是否匹配上),後面的case即使不匹配也會執行,直到遇到一個break才會跳出,所以我們不建議省略break。
- 如果所有的case後面的值和表達式的值都不匹配,就會執行default裏面的語句體,然後結束整個switch語句。
- 基本語法:
switch (表達式) {
case 值1:
// 當表達式結果等於值1時執行的代碼
break; // 可選,用於阻止穿透
case 值2:
// 當表達式結果等於值2時執行的代碼
break;
...
default:
// 當所有case都不匹配時執行的代碼(可選)
}case穿透:
- 定義:當
case分支中沒有break語句時,程序會繼續執行下一個case的代碼,直到遇到break或switch結束,這種現象稱為 “case 穿透”。
int day = 3;
switch (day) {
case 1:
case 2:
case 3:
case 4:
case 5:
System.out.println("工作日"); // day=3時,從case3穿透到此處執行
break; // 阻止繼續穿透
case 6:
case 7:
System.out.println("休息日");
break;
}
// 輸出:工作日7、static靜態關鍵字
static關鍵字修飾在屬性上
語法:static 數據類型 變量名
使用static修飾的屬性我們認為是類的屬性,不帶static修飾的屬性我們認為是對象的屬性。
類的屬性訪問:第一種方式:類名.屬性名(推薦使用) 第二種方式:對象實例.屬性名
類屬性的當前的class文件加載進入jvm,類屬性就被初始化,jvm'執行完畢,類屬性也就銷燬了,隨着類的加載而加載,優先於對象出現的。
類屬性可以被每一個對象共享。
public class Student {
// 靜態成員變量(所有學生共享學校名稱)
public static String schoolName = "陽光中學";
// 實例變量(每個學生有自己的姓名)
private String name;
}static關鍵字修飾在方法上
加載源文件靜態方法就會被初始化了,對象方法也是早早的就進入jvm了,但是不一定被啓用,因為只有調用它才會啓用。
類方法不能訪問對象屬性和對象方法(只能靜態的訪問靜態的,但是非靜態的可以訪問靜態的)。
類方法最常見的應用場景就是工具類的定義(因為不用創建對象就可以使用類型.屬性名或方法),靜態方法中是沒有this關鍵字的。
public class MathUtil {
// 靜態方法(工具類常用靜態方法)
public static int sum(int a, int b) {
return a + b;
}
}
// 調用:直接通過類名
int result = MathUtil.sum(1, 2);static靜態代碼塊
- 靜態代碼塊主要用於初始化數據。
- 靜態代碼塊在main之前執行。
- 靜態代碼塊可以範訪問類方法和類屬性(先定義)。
public class DBUtil {
// 靜態代碼塊:初始化數據庫驅動
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}8、final關鍵字
修飾變量
final修飾的變量不能被修改。(final修飾基本數據類型記錄的值不能發生改變 final修飾引用數據類型時記錄的地址值不能發生改變,內部的屬性可以發生改變 ),final修飾屬性,要麼直接顯示賦值,要麼在構造方法中賦值,並且所有的構造方法必須都賦值。
// 修飾成員變量(聲明時賦值)
final int MAX_NUM = 100;
// 修飾局部變量(延遲賦值)
public void method() {
final String name;
name = "Java"; // 首次賦值有效
// name = "Python"; 錯誤:不能重新賦值
}
// 修飾引用類型(地址不可變,內容可變)
final List<String> list = new ArrayList<>();
list.add("a"); // 允許(修改對象內容)
// list = new ArrayList<>(); 錯誤(修改引用地址)修飾方法
被 final 修飾的方法不能被子類重寫(Override),但可以被繼承和調用
class Parent {
// final方法不能被重寫
public final void print() {
System.out.println("父類方法");
}
}
class Child extends Parent {
// @Override 錯誤:不能重寫final方法
// public void print() {}
}修飾類
final修飾的類不能被繼承
final class FinalClass {
// 此類不能被繼承
}
// class SubClass extends FinalClass {} 錯誤:不能繼承final類final和finally的區別
|
關鍵字
|
作用領域
|
核心功能
|
使用場景
|
|
|
修飾類、方法、變量
|
限制修改(不可繼承、不可重寫、不可重新賦值)
|
保證數據 / 結構穩定性(如常量、核心方法)
|
|
|
異常處理
|
定義必須執行的代碼(無論是否異常)
|
釋放資源(如關閉流、連接)
|
9、訪問權限修飾符
Java 中共有 4 種訪問權限修飾符,用於控制類、成員變量、方法的訪問範圍,從嚴格到寬鬆依次為:private(私有)→ default(默認,無關鍵字)→ protected(受保護)→ public(公共)。它們的核心區別在於可訪問的範圍不同。
|
修飾符
|
同一類中
|
同一包中(不同類)
|
不同包的子類中
|
不同包的非子類中
|
|
|
✅ 可訪問
|
❌ 不可訪問
|
❌ 不可訪問
|
❌ 不可訪問
|
|
|
✅ 可訪問
|
✅ 可訪問
|
❌ 不可訪問
|
❌ 不可訪問
|
|
|
✅ 可訪問
|
✅ 可訪問
|
✅ 可訪問
|
❌ 不可訪問
|
|
|
✅ 可訪問
|
✅ 可訪問
|
✅ 可訪問
|
✅ 可訪問
|
private(私有)
- 場景:修飾類的內部細節(如成員變量、工具方法),僅允許類自身訪問,對外隱藏實現細節(封裝的核心)。
- 示例:實體類的屬性(通過
get/set方法間接訪問)、類內部的輔助方法。
default(默認,無修飾符)
- 場景:修飾同一包內需要共享,但不希望被包外訪問的成員(如包內工具類的方法)。
- 注意:僅在同一包內可見,跨包無法訪問(包括子類)。
protected(受保護)
- 場景:修飾需要被子類繼承複用,但不希望被非子類訪問的成員(如父類的核心方法)。
- 核心:允許跨包子類訪問,但拒絕跨包非子類訪問。
public(公共)
- 場景:修飾需要對外暴露的接口、工具類、核心方法(如
java.lang.String類、main方法)。 - 特點:全局可見,任何地方都可訪問。
10、封裝
目的:提高數據安全性,通過封裝,可以是實現對屬性的訪問權限控制,同時增加了程序的可維護性。
封裝:對象代表什麼,就得封裝對應的數據,並提供數據對應的行為。將屬性私有化,使用private關鍵字完成屬性私有化,這種屬性只能本類能訪問,我們一般對每一個私有屬性提供公共public的set和get這種方法供外界來訪問我們的私有屬性。
class Student {
// 私有變量(隱藏細節)
private String name;
private int age;
// set方法:設置年齡,帶校驗
public void setAge(int age) {
// 只允許年齡在0-120之間
if (age >= 0 && age <= 120) {
this.age = age;
} else {
System.out.println("年齡不合法,默認設為0");
this.age = 0;
}
}
// get方法:獲取年齡
public int getAge() {
return this.age;
}
// set方法:設置姓名
public void setName(String name) {
this.name = name; // 簡單賦值(也可添加校驗,如非空判斷)
}
// get方法:獲取姓名
public String getName() {
return this.name;
}
}
public class Test {
public static void main(String[] args) {
Student s = new Student();
s.setAge(-10); // 觸發校驗:輸出"年齡不合法,默認設為0"
System.out.println(s.getAge()); // 輸出:0
s.setAge(20); // 合法賦值
System.out.println(s.getAge()); // 輸出:20
s.setName("張三");
System.out.println(s.getName()); // 輸出:張三
}
}11、繼承
描述類的時候,我們如果發現幾個類有重複的屬性和方法我們就可以採用繼承的方式來設計。
語法:使用extends關鍵字來繼承 class 子類 extends 父類{ 子類屬性 子類方法 }
|
成員類型
|
修飾符
|
能否被子類繼承
|
能否被子類直接使用
|
補充説明
|
|
構造方法
|
任意
|
❌ 不能繼承
|
❌ 不能直接調用
|
子類構造需通過 |
|
成員變量
|
public
|
✅ 能繼承
|
✅ 能直接使用
|
-
|
|
成員變量
|
private
|
✅ 能繼承
|
❌ 不能直接使用
|
需通過父類的 |
|
成員方法
|
public
|
✅ 能繼承
|
✅ 能直接調用
|
-
|
|
成員方法
|
private
|
❌ 不能繼承
|
❌ 不能調用
|
父類私有方法僅自身可見,子類完全無法訪問
|
繼承的特點:
- 子類會把父類所有的屬性和方法繼承下來(暫時不考慮final)。
- 私有化的成員變量雖然能被繼承下來但是不能直接使用,,子類只能獲得父類中非private的屬性,如果想要繼承就得提供公共的set和get方法。私有的方法是無法繼承下來的。
- java只能單繼承。
- 子類中所有構造方法默認先訪問父類中的的無參構造方法先完成父類數據空間的初始化。
- 成員方法是否可以被繼承: 在最頂層會創建一個虛方法表(非private 非static 非final)往下繼承時會在上一個父類基礎上再添加自己類中的虛方法表。
只有父類中的虛方法才能被子類繼承。
繼承中:成員變量訪問特點:就近原則(誰離我近,我就用誰)
在類的繼承結構中,如果創建一個子類的對象,那麼在子類的對象的內部創建一個父類的對象,如果通過子類的對象訪問屬性的時候,子類中沒有,就會到父類的對象中查找,如果調用方法的時候也是一樣的。
特殊情況:若父類沒有無參構造(僅定義了帶參構造),子類必須在構造第一行顯式調用 super(參數),否則編譯報錯。
class Parent {
// 父類僅帶參構造,無無參構造
public Parent(String name) { this.name = name; }
}
class Child extends Parent {
// 子類必須顯式調用父類帶參構造
public Child(String name, int age) {
super(name); // 顯式調用父類帶參構造,初始化name
this.age = age; // 再初始化子類自己的age
}
}12、多態
同類型的對象,表現出的不同形態。
多態的表現形式: 父類類型 對象名稱 = 子類對象;
多態的前提: 1.有繼承關係 2.有父類引用指向子類對象(fu f = new zi() 3.有方法重寫
子類自動轉換成父類: Teacher jt = new JavaTeacher() javaTeach繼承於teacher
- 如果子類對父類的方法有重寫,並且子類的實例賦值給父類的引用,通過這個引用來調用這個重寫的方法的時候,調用的是子類。
- 父類指向子類的實例的引用不能調用子類的特有的方法和屬性。
- 如果父子類有同名的屬性,那麼父類指向子類的實例的引用調用這個屬性的時候調用的還是父類的。
父類轉換成子類不能自動轉,父類轉換成子類的前提是父類的真身是這個子類,強轉回子類後就可以訪問內部的方法和屬性 。
通過繼承的方式來體現的多態
在多態形式下,右邊對象可以實現解耦合,便於擴展和維護。
定義方法的時候,使用父類型作為參數,可以接收所有子類對象,體現多態的擴展性和遍歷。
多態的弊端:不能調用子類的特有功能。(編譯的時候會先檢查父類中有沒有這個方法,如果沒有直接報錯)
解決方案:強轉
轉換的時候不能瞎轉,如果轉成其他類型,則會報錯。instanceof:判斷是否屬於這個類
//先判斷a是否為Dog'類型,如果是,則強轉成Dog類型,轉換之後變量名為d,如果不是,則不強轉,結果直接是false
if( a instanceof Dog d ) {
d.lookhome();
}instanceof 判斷是否包含並返回true 或 false
13、接口
什麼是接口:當一個抽象類,如果抽象類中的所有方法都是抽象的,那麼我們就可以把他定義為一個接口,接口是對行為的抽象,類是對屬性和行為的抽象。
- 語法:interface 接口{ 方法的定義; }
// 定義接口(用interface關鍵字)
public interface 接口名 {
// 抽象方法(默認public abstract,可省略)
返回值類型 方法名(參數列表);
// 常量(默認public static final,可省略)
數據類型 常量名 = 值; // 如:String FILE_PATH = "/data/logs";
}
// 實現接口(用implements關鍵字)
public class 實現類名 implements 接口名1, 接口名2 {
// 必須重寫所有接口中的抽象方法(否則該類需聲明為抽象類)
@Override
public 返回值類型 方法名(參數列表) {
// 實現邏輯
}
}接口的特徵:
- 接口中的方法的定義不需要abstract來修飾,默認就是抽象的。
- 接口是不可以實例化的,需要有類來實現接口。實現接口的語法 :class 類名implements 接口名,接口名{ // 實現每一個接口中的方法 }
- 接口中的方法不能和private,static和final共存。
- 在接口中可以定義常量,可以通過接口的實現類的實例來訪問,還可以通過接口名來訪問(推薦大家使用),接口中的屬性不能修改,我們接口中的屬性默認都是final static 的,通常在接口中來定義屬性把它作為常量,常量的名字規範是凡此大寫,而且多個單詞之間用下劃線來分割。比如:FILE_PATH。
- 接口可以繼承接口(多繼承)。
- 當一個方法的參數是接口時,可以傳遞接口所有實現類的對象,這種方式稱之為接口多態。
接口的關鍵價值(基於特徵的延伸)
- 強制規範實現:所有實現類必須重寫接口的所有方法,確保不同實現類的行為 “有章可循”(如
Comparable接口強制實現類定義compareTo()方法,保證對象可比較)。 - 解耦與擴展:依賴接口而非實現類,更換實現類時無需修改調用方代碼(如接口
Payment可切換Alipay/WechatPay,支付邏輯調用方不變)。 - 彌補單繼承侷限:一個類可實現多個接口,同時擁有多種行為(如
Dog類可實現Runable和Swimmable接口,既會跑也會遊)。
14、==與equals的區別
|
類型
|
|
|
|
本質
|
比較值(基本類型)或地址(引用類型)
|
默認比較地址,重寫後可比較對象內容
|
|
適用場景
|
基本類型比較、判斷對象是否為同一實例
|
引用類型的內容比較(需確保已重寫)
|
|
能否重寫
|
不能(運算符無法重寫)
|
能(通過重寫自定義比較邏輯
|
15、String,StringBuffer,StringBuilder區別
|
特性
|
|
|
|
|
可變性 |
不可變(Immutable)
|
可變(Mutable)
|
可變(Mutable)
|
|
線程安全 |
安全(無多線程問題)
|
安全(方法加 |
不安全(無同步鎖)
|
|
性能 |
低(修改時創建新對象)
|
中(同步開銷)
|
高(無同步開銷)
|
|
適用場景 |
字符串不常修改的場景
|
多線程環境下的字符串修改
|
單線程環境下的字符串修改
|
1. String:不可變字符串
- 可變性:
String是 不可變的(底層用final char[]存儲字符,數組長度和內容不可修改)。例如:對String進行拼接、替換等操作時,不會修改原對象,而是創建新的String對象。
String s = "a";
s += "b"; // 實際創建了新對象 "ab",原對象 "a" 仍存在(等待垃圾回收)- 線程安全:由於不可變,多線程同時訪問時不會出現修改衝突,天然線程安全。
- 性能:頻繁修改字符串時(如循環拼接),會產生大量臨時對象,導致性能低下(內存開銷大、GC 頻繁)。
- 適用場景:字符串內容固定,無需頻繁修改(如常量定義、少量拼接)。
2. StringBuffer:線程安全的可變字符串
- 可變性:
StringBuffer是 可變的(底層用char[]存儲字符,可通過append()、insert()等方法直接修改數組內容,不創建新對象)。
StringBuffer sb = new StringBuffer("a");
sb.append("b"); // 直接在原對象後追加 "b",結果為 "ab"(無新對象)- 線程安全:所有修改方法(如
append())都被synchronized修飾,多線程環境下修改不會出現數據不一致,線程安全。 - 性能:由於同步鎖的開銷,單線程環境下性能比
StringBuilder低。 - 適用場景:多線程環境中需要頻繁修改字符串(如多線程日誌拼接)。
3. StringBuilder:高效的可變字符串(JDK 5 新增)
- 可變性:與
StringBuffer一樣,StringBuilder也是 可變的,底層實現和修改邏輯相同(無新對象創建)。 - 線程安全:非線程安全(方法沒有
synchronized修飾),多線程同時修改可能導致數據錯亂。 - 性能:由於省去了同步鎖的開銷,單線程環境下性能優於
StringBuffer,是頻繁修改字符串的首選。 - 適用場景:單線程環境中需要頻繁修改字符串(如循環拼接、字符串構建)。
16、包裝類
包裝類:基本數據類型對應的引用類型,用一個對象把基本數據類型給包起來。
集合不能存基本數據類型。
|
基本數據類型
|
包裝類
|
特點(補充)
|
|
|
|
-
|
|
|
|
-
|
|
|
|
最常用,有緩存機制(重點)
|
|
|
|
有緩存機制(範圍:-128~127)
|
|
|
|
無緩存機制
|
|
|
|
無緩存機制
|
|
|
|
緩存機制(範圍:0~127)
|
|
|
|
緩存 |
public static integer valueOf(int i) 根據傳遞的整數創建一個integer對象
細節:因為在實際開發中,-128—127之間的數據,用的比較多。所以每次使用都是new對象,太浪費內存了,所以提前把這個範圍之內的每一個數據都創建好對象,如果要用到了不會創建新的,而是返回已經創建好的對象。
Integer i1 = Integer.valueOf(100);
Integer i2 = Integer.valueOf(100);
System.out.println(i1 == i2); // true(緩存對象,地址相同)
Integer i3 = Integer.valueOf(200); // 超出127,新建對象
Integer i4 = Integer.valueOf(200);
System.out.println(i3 == i4); // false(不同對象,地址不同)以前包裝類計算:1.把對象進行拆箱,變成基本數據類型 2.相加 3.把得到的結果再次進行裝箱(再變成包裝類)。
自動裝箱:把基本數據類型會自動變成對應的包裝類。
Integer a = 10; // 等價於 Integer a = Integer.valueOf(10);(自動裝箱)自動拆箱:把包裝類自動變成對象的基本數據類型。
Integer b = 20;
int c = b; // 等價於 int c = b.intValue();(自動拆箱)在JDK5以後,int和Intger可以看作一個東西
Integer成員方法:
|
方法
|
功能描述
|
示例
|
|
|
轉為二進制字符串(無符號)
|
|
|
|
轉為八進制字符串(無符號)
|
|
|
|
轉為十六進制字符串(無符號,小寫)
|
|
|
|
將字符串轉為 |
|
|
|
將字符串轉為 |
|
|
|
將 |
|
將包裝類轉為基本數據類型 intValue
8種包裝類中,除了Character都有對應的parsexxx方法,進行類型轉換。
17、集合
集合就是容器跟數組一樣可以存儲多個數據,但是集合長度可以改變,自動擴容,集合只能存儲引用數據類型。
|
對比維度
|
數組
|
集合(以 |
|
長度特性
|
固定長度(初始化後不可變)
|
動態長度(自動擴容,無需手動管理)
|
|
存儲類型
|
可存基本類型 / 引用類型
|
僅存引用類型(基本類型需用包裝類)
|
|
功能豐富度
|
僅支持索引訪問,無額外方法
|
提供增刪改查、遍歷、排序等豐富方法
|
集合可以分為兩類:Collection單列集合(每次都添加一個數據)和Map雙列集合(每次要添加一對數據)。
Collection(單列集合)
- List系列集合:添加的元素是有序的(存和取的順序是有序的),可重複的,有索引的。
- Set系列集合:添加的元素是無序的,不可重複,無索引的。
Collection是單列集合的頂層接口,他的功能是全部單列集合都可以繼承的。
|
|
向當前集合添加單個元素
|
|
- |
|
|
將指定集合中的所有元素添加到當前集合
|
|
原集合元素會被 “追加”,而非替換當前集合。
|
|
|
清空集合中所有元素(集合本身保留)
|
無返回值
|
清空後集合 |
|
|
刪除集合中第一個匹配的元素
|
|
依賴元素的 |
|
|
刪除當前集合中所有在指定集合中存在的元素
|
|
本質是 “求差集”,保留當前集合中不在 |
|
|
判斷集合中是否包含指定元素
|
|
其中contains方法的細節:
1:底層是依賴equals方法進行判斷是否存在。
2:如果集合中存儲的是自定義對象,也想通過contains方法來進行判斷是否存在,那麼在javabean中一定要重寫equals方法。
List系列
Collction的方法List都繼承了。 List’集合因為有索引,所以多了很多索引操作的方法。
|
方法聲明
|
功能描述
|
|
|
在指定索引處插入元素,原索引及後續元素後移
|
|
|
刪除指定索引處的元素,返回被刪除的元素
|
|
|
修改指定索引處的元素,返回被替換的舊元素
|
|
|
返回指定索引處的元素
|
List集合的遍歷方式:
1.迭代器遍歷 2.列表迭代器遍歷 3.增強for遍歷 4.Lambda表達式遍歷 5.普通for循環(因為List集合有索引)
列表迭代器:
集合.ListIterator 有一個add方法
在遍歷的時候需要添加元素的時候請使用列表迭代器。
如果遍歷的時候想操作索引,可以用普通for
1. ArrayList
- 底層結構:基於動態數組實現,數組元素在內存中連續存儲,支持通過索引快速訪問(隨機訪問)。
- 線程安全:非線程安全,多線程併發修改可能導致數據不一致(如
ConcurrentModificationException)。 - 性能特點:
- 查詢快:
get(index)直接通過數組下標定位,時間複雜度O(1)。 - 增刪慢:在中間或頭部增刪元素時,需要移動後續元素(如
add(0, e)需移動所有元素),時間複雜度O(n);尾部增刪效率高(無需移動元素)。
- 擴容機制:當元素數量超過當前容量時,擴容為原容量的 1.5 倍(通過
Arrays.copyOf()複製數組)。 - 適用場景:單線程環境下,查詢操作頻繁,增刪操作少(尤其是中間增刪),如數據展示、排行榜等。
2. LinkedList
- 底層結構:基於雙向鏈表實現,每個節點包含
prev(前驅指針)、data(數據)、next(後繼指針),元素在內存中不連續。 - 線程安全:非線程安全,與
ArrayList一致,無同步機制。 - 性能特點:
- 查詢慢:
get(index)需從鏈表頭 / 尾遍歷(默認從離索引近的一端開始),時間複雜度O(n)。 - 增刪快:在中間或頭部增刪元素時,只需修改前後節點的指針(無需移動元素),時間複雜度
O(1)(前提是已定位到節點);首尾操作效率極高(內部維護頭 / 尾節點引用)。
- 獨有方法:提供直接操作首尾元素的方法(因鏈表特性),如
addFirst()、addLast()、getFirst()、removeLast()等,適合實現隊列(Queue)或棧(Stack)。 - 適用場景:單線程環境下,增刪操作頻繁(尤其是中間或首尾),查詢操作少,如實現隊列、鏈表式數據結構等。
3. Vector
- 底層結構:基於動態數組實現,與
ArrayList類似,但設計更早期。 - 線程安全:線程安全,所有方法(如
add()、get())都被synchronized修飾,多線程併發修改時不會出現數據錯亂。 - 性能特點:
- 查詢效率:與
ArrayList相同(O(1)),但因同步鎖開銷,實際效率低於ArrayList。 - 增刪效率:與
ArrayList相同(中間增刪需移動元素),但同步鎖進一步降低效率。
- 擴容機制:默認擴容為原容量的 2 倍(可通過構造方法指定擴容增量),比
ArrayList更 “激進”,可能浪費更多內存。 - 適用場景:多線程環境下需要線程安全的
List,但因性能問題,現代開發中更推薦用Collections.synchronizedList(new ArrayList<>())替代(靈活性更高)。
set系列
Set系列:1.無序:存取順序不一致。 2.不重複:可以去除重複 3.無索引:沒有帶索引的方法。所以不能使用普通for循環遍歷,也不能通過索引來獲取元素,最多隻能存一個null值。
Set集合實現類:
- HashSet:無序、不重複、無索引
- LinkedHashSet:有序、不重複、無索引。
- TreeSet:可排序,不重複、無索引。
Set接口中的方法上基本上與Collection的API一致
1. HashSet(最常用的 Set 實現)
- 底層結構:基於哈希表(JDK 8 後為 “數組 + 鏈表 + 紅黑樹”),通過哈希值定位元素存儲位置。
- 存儲順序:無序,元素的存儲位置由其
hashCode()決定,與添加順序無關。 - 去重邏輯:添加元素時,先通過
hashCode()計算哈希值,定位到哈希表中的位置;若該位置已有元素,再通過equals()比較內容,兩者都相同則視為重複,拒絕添加。
- 關鍵:存儲自定義對象時,必須同時重寫
hashCode()和equals(),否則無法正確去重。 - 示例:
class Student {
String id;
// 必須重寫hashCode和equals
@Override
public int hashCode() { return id.hashCode(); }
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj instanceof Student s) return id.equals(s.id);
return false;
}
}
HashSet<Student> set = new HashSet<>();
set.add(new Student("1001"));
set.add(new Student("1001")); // 重複,添加失敗
System.out.println(set.size()); // 1- 適用場景:需去重且不關心順序的場景(如存儲唯一標識的集合)。
2. LinkedHashSet(HashSet 的子類)
- 底層結構:在
HashSet的哈希表基礎上,額外維護了一個雙向鏈表,記錄元素的添加順序。 - 存儲順序:有序,遍歷元素時按添加順序輸出(鏈表保證順序)。
- 去重邏輯:與
HashSet完全一致(繼承父類的去重邏輯,依賴hashCode()+equals())。 - 性能:插入 / 刪除效率略低於
HashSet(需額外維護鏈表指針),但遍歷效率更高(鏈表有序,無需計算哈希)。 - 適用場景:需去重且保持添加順序的場景(如日誌記錄、歷史操作軌跡)。
3. TreeSet(可排序的 Set)
- 底層結構:基於紅黑樹(一種自平衡的二叉搜索樹),元素按 “鍵值” 有序排列。
- 存儲順序:有序,默認按自然排序(如
Integer升序、String字典序);也可通過Comparator自定義排序規則。 - 去重邏輯:不依賴
hashCode()和equals(),而是通過比較方法(compareTo()或compare())判斷:若返回0,則視為重複元素,拒絕添加。
- 兩種排序方式:
- 自然排序:元素類實現
Comparable接口,重寫compareTo()方法。
class Student implements Comparable<Student> {
int age;
@Override
public int compareTo(Student s) {
return this.age - s.age; // 按年齡升序排序
}
}
TreeSet<Student> set = new TreeSet<>(); // 依賴自然排序- 自定義排序:創建
TreeSet時傳入Comparator對象,定義排序規則。
TreeSet<Student> set = new TreeSet<>((s1, s2) -> s2.age - s1.age); // 按年齡降序- 特點:不允許
null元素(添加null會拋NullPointerException),因為排序時無法比較null。 - 適用場景:需去重且按指定規則排序的場景(如排行榜、按日期排序的記錄)
集合的遍歷
一、迭代器(Iterator):集合專用的 “手動遍歷工具”
1. 核心作用
迭代器是 Collection 集合(包括 List、Set)通用的遍歷方式,不依賴索引,通過指針逐個訪問元素,支持在遍歷中安全刪除元素。
2. 基本用法(三步曲)
Collection<String> coll = new ArrayList<>(List.of("a", "b", "c"));
// 1. 獲取迭代器對象(指針默認指向集合第一個元素之前)
Iterator<String> it = coll.iterator();
// 2. 循環判斷是否有下一個元素
while (it.hasNext()) {
// 3. 獲取當前元素,並移動指針
String elem = it.next();
System.out.println(elem);
}3. 關鍵方法與細節
|
方法
|
功能
|
注意事項
|
|
|
判斷是否有下一個元素
|
無元素時返回 |
|
|
獲取當前元素並移動指針
|
① 無元素時調用會拋 |
|
|
刪除當前指針指向的元素(剛通過 |
① 必須在 |
4. 併發修改異常(ConcurrentModificationException)
- 觸發場景:迭代器遍歷期間,用集合的
add()/remove()方法修改集合結構(如coll.remove(elem))。 - 原因:迭代器依賴集合的 “修改次數” 標識(
modCount),集合自身修改會導致標識不一致。 - 解決方案:如需刪除元素,使用迭代器的
remove()方法(會同步更新modCount)。
while (it.hasNext()) {
String elem = it.next();
if (elem.equals("b")) {
it.remove(); // 安全刪除,不會拋異常
}
}二、增強 for 循環(foreach):簡化版迭代器
1. 底層原理
增強 for 循環是迭代器的 “語法糖”,編譯後會自動轉換為迭代器代碼,本質還是迭代器遍歷。
2. 適用場景
- 僅需遍歷元素,無需修改集合結構(不支持增刪,否則拋
ConcurrentModificationException)。 - 支持遍歷所有單列集合(
Collection及其實現類)和數組。
3. 基本用法
// 遍歷集合
Collection<String> coll = new ArrayList<>(List.of("a", "b", "c"));
for (String elem : coll) {
System.out.println(elem);
}
// 遍歷數組
int[] arr = {1, 2, 3};
for (int num : arr) {
System.out.println(num);
}4. 關鍵細節
- 只讀性:修改循環變量不會影響集合 / 數組的原始數據(變量是元素的副本)。
for (String elem : coll) {
elem = "x"; // 集合中元素仍為 "a", "b", "c"
}- 不支持索引:無法獲取元素的索引位置(如需索引,用普通 for 循環,僅限
List)。
三、Lambda 表達式遍歷(forEach 方法):JDK 8+ 簡化遍歷
1. 底層原理
Collection 接口在 JDK 8 中新增 forEach(Consumer<? super T> action) 方法,底層通過迭代器遍歷集合,將每個元素傳遞給 Consumer 的 accept() 方法執行自定義邏輯。
2. 適用場景
- 僅需遍歷元素,邏輯簡單(一行代碼可完成),無需修改集合結構。
3. 基本用法
Collection<String> coll = new ArrayList<>(List.of("a", "b", "c"));
// Lambda表達式寫法
coll.forEach(elem -> System.out.println(elem));
// 方法引用簡化(當邏輯是直接調用某個方法時)
coll.forEach(System.out::println);泛型
可以在編譯階段約束操作的數據類型,並進行檢查。
泛型只能支持引用數據類型。
List<int> list1; // 錯誤:泛型不支持基本類型
List<Integer> list2; // 正確:使用包裝類因為多態的弊端是不能訪問子類特有功能,所以用迭代器方式遍歷集合獲取數值的時候不能調用裏面的特有功能,所以規定泛型調整同一類型。
泛型的好處:1.統一數據類型 2.把運行時期的問題提前到了編譯時期,避免了強制類型轉換可能出現的異常,因為在編譯階段類型就能確定下來。
指定泛型的具體類型後,傳遞數據時,可以傳入該類型或者其子類類型。
如果不寫泛型,類型默認時object。
List list = new ArrayList();
list.add("abc");
String s = (String) list.get(0); // 需強制轉換,若存了其他類型則運行時報錯泛型寫在類後面時泛型類,寫在方法上面是泛型方法,寫在接口後面是泛型接口
可變參數
修飾符 返回值類型 方法名(數據類型... 變量名) {
// 方法體(變量名可作為數組使用)
}
public static int sum(int...p){
return 0;
}注意:參數p實際是一個數組,p都是同一種類型。
可變參數底層就是一個數組。
細節:1.在方法的形參中最多隻能寫一個可變參數
2.在方法當中,如果出現了可變參數以外,還有其他的形參,那麼可變參數要寫在最後。
Arrays
操作數組的工具類
Public static String toString() 把數組拼接成字符串
int[] arr = {1, 2, 3};
System.out.println(Arrays.toString(arr)); // 輸出:[1, 2, 3]
String[] strs = {"a", "b"};
System.out.println(Arrays.toString(strs)); // 輸出:[a, b]Pubic static int binarySearch(數組,查找的元素) 二分查找查找元素
細節:1.二分查找的前提:數組中的元素必須是有序的,數組中的元素必須是升序的。
2.如果要查找的元素是存在的的,那麼返回的是真實的索引,但是如果元素不存在,那麼返回的是 -插入點 - 1
int[] arr = {10, 20, 30, 40}; // 升序數組
// 找到元素
int index1 = Arrays.binarySearch(arr, 30);
System.out.println(index1); // 輸出:2(索引為2)
// 未找到元素(插入點為1,應插在20前面)
int index2 = Arrays.binarySearch(arr, 25);
System.out.println(index2); // 輸出:-(1 + 1) = -2|
方法
|
功能描述
|
|
|
從原數組開頭拷貝,新數組長度由參數指定
|
|
|
拷貝原數組中 |
細節:拷貝數組時包頭不包尾,包左不包右,方法的底層會根據第二個參數來創建新的數組,如果新數組的長度是小於老數組的長度,會部分拷貝,如果新數組的長度是等於老數組的長度,會完全拷貝,如果新數組的長度是大於老數組的長度,會不上默認初始值。
並且Arrays.copyOf()是淺拷貝,
- 淺拷貝僅複製對象的引用(內存地址),而不復制對象本身。對於基本數據類型(如
int、double),由於它們直接存儲值,淺拷貝會創建新副本,修改拷貝後的數組不會影響原數組。 - 對於引用數據類型(如對象數組),
Arrays.copyOf()僅複製引用地址,新數組和原數組會共享同一組對象。修改拷貝後數組中的對象屬性會影響原數組中的對象。
Public static void fill(數組,元素) 填充數組
Public static void sort(數組) 按照默認的方式進行數組排序
// 基本類型數組(默認升序)
int[] arr = {3, 1, 2};
Arrays.sort(arr); // 數組變為 [1, 2, 3]
// 引用類型數組(需實現 Comparable)
class Student implements Comparable<Student> {
int age;
@Override
public int compareTo(Student s) {
return this.age - s.age; // 按年齡升序
}
}
Student[] students = {new Student(20), new Student(18)};
Arrays.sort(students); // 按年齡排序為 [18, 20]Public static void sort(數組,排序規則) 按照指定的規則排序///
// 按年齡降序排序(無需 Student 實現 Comparable)
Student[] students = {new Student(20), new Student(18)};
Arrays.sort(students, (s1, s2) -> s2.age - s1.age); // 結果:[20, 18]對數組的對象來排序,數組中的對象必須要來實現comparator接口,只能給引用數據類型的數組進行排序,所以如果是基本數據類型,需要變成對應的包裝類
sort()排序的底層原理:利用插入排序 + 二分查找的方式進行排序,默認把0索引的數據當作是有序的序列,1索引到最後認為是無序的序列,遍歷無序的序列得到裏面的每一個元素,假設當前遍歷得到的元素是A元素,把A往有序序列中進行插入,在插入的時候,是利用二分查找確定A元素的插入點,拿着A元素,跟插入點的元素進行比較,比較的規則就是compar方法的方法體,
如果方法的返回值是負數,拿着A繼續跟前面的數據進行比較
如果方法的返回值是正數,拿着A繼續跟後面的數據進行比較
如果方法的返回值是0,也拿着跟後面的數據進行比較,直到確定A的最終位置為止。
Collections
- java.util.Collections:是集合工具類
- 作用:Collections不是集合,而是集合的工具類
常用的API:
|
方法名稱
|
説明
|
|
|
批量添加元素
|
|
|
打亂List集合元素的順序
|
|
|
排序
|
|
|
根據指定的規則進行排序
|
|
|
以二分查找法查找元素
|
|
|
拷貝集合中的元素
|
|
|
使用指定的元素填充集合
|
|
|
根據默認的自然排序獲取最大/小值
|
|
|
交換集合中指定位置的元素
|
Map集合
Map即是鍵值對的集合的接口抽象,我們可以通過key的值來獲取相應的值,將鍵映射到值的對象。一個映射不能包含重複的鍵;每個鍵最多隻能映射到一個值。鍵只允許有一個空值,值可以有多個空值。Map<K,V> K:此映射所維護的鍵的類型 V:映射值的類型,map也是無序的。
特點:
- 雙列集合一次需要存一對數據,分別為鍵和值
- 鍵不能重複,值可以重複
- 鍵和值是一 一對應的,每一個鍵只能找到自己對應的值
- 鍵+值這個整體我們稱之為“鍵值對”或者“鍵值對對象”,在java中叫做“Entry對象”
Map的常見API
|
方法名稱
|
説明
|
|
V |
添加元素
|
|
V remove(Object key)
|
根據鍵刪除鍵值對元素
|
|
void clear()
|
移除所有的鍵值對元素
|
|
boolean containsKey(Object key)
|
判斷集合是否包含指定的鍵
|
|
boolean containsValue(Object value)
|
判斷集合是否包含指定的值
|
|
boolean isEmpty()
|
判斷集合是否為空
|
|
int size()
|
集合的長度,也就是集合中鍵值對的個數
|
添加元素的細節:
- 在添加元素的時候哦,如果j鍵不存在,那麼直接把鍵值對對象添加到map集合當中,方法返回null。
- 在添加數據的時候,如果鍵存在,那麼會把原有的鍵值對對象覆蓋,會把被覆蓋的值進行返回。
HashMap
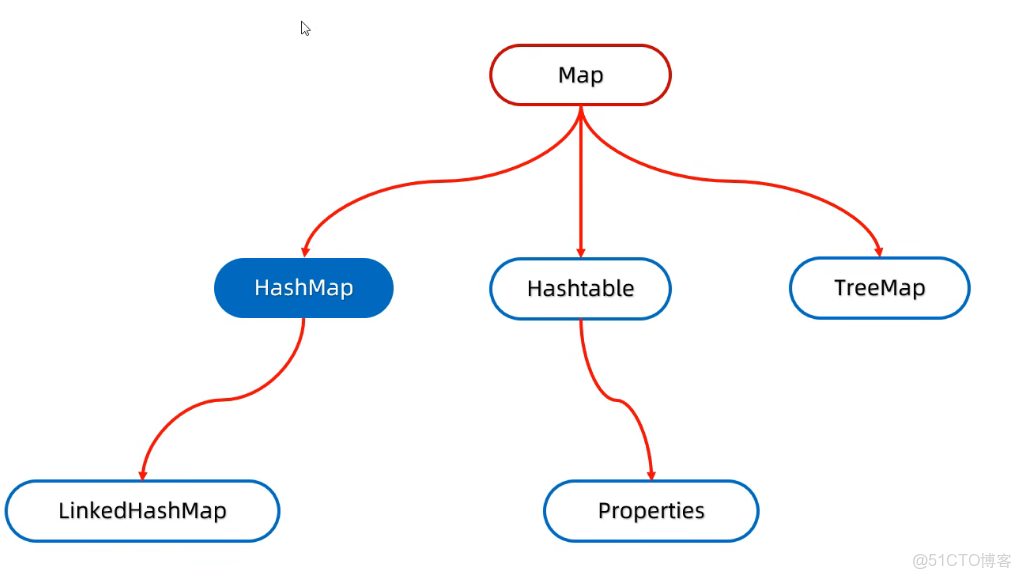
1.HashMap是map的實現類。
2.特點都是由鍵決定的:無序、不重複、無索引
3.HashMap跟HashSet底層原理是一摸一樣的,都是哈希表結構,依賴hasCode方法和equals方法保證鍵的唯一
4.如果鍵存儲的是自定義對象,需要重寫hashCode和equals方法,如果值存儲自定義對象,不需要重寫hashCode和equals方法
LinkedHashMap
LinkedHashMap特點:1.LinkedHashMap時map的實現類。
1.由鍵決定:有序,不重複,無索引。 這裏的有序是指保證存儲和取出的元素順序一致。 原理:底層數據結構依然是哈希表,只是每個鍵值對元素又額外的多了一個雙鏈表的機制記錄存儲的順序。
TreeMap
TreeMap跟TreeSet底層原理一樣,都是紅黑樹結構的。
由鍵決定特性:不重複、無索引、可排序。(排序是指對鍵進行排序)
注意:默認按照鍵的從小到大進行排序,也可以自己規定鍵的排序規則。
代碼書寫兩種排序規則:
- 實現Comparable接口,指定比較規則
// 鍵的類實現 Comparable
class Student implements Comparable<Student> {
String id;
// 重寫比較規則:按 id 升序
@Override
public int compareTo(Student o) {
return this.id.compareTo(o.id); // 字符串自然排序
}
}
// 創建 TreeMap(默認使用鍵的自然排序)
TreeMap<Student, String> map = new TreeMap<>();
map.put(new Student("002"), "李四");
map.put(new Student("001"), "張三");
// 遍歷結果:鍵按 id 升序排列 → 001(張三)、002(李四)- 創建集合時傳遞Comparator比較器對象,指定比較規則。
// 創建 TreeMap 時傳入比較器(Lambda 表達式)
TreeMap<Student, String> map = new TreeMap<>((s1, s2) ->
s2.id.compareTo(s1.id) // 按 id 降序
);
map.put(new Student("002"), "李四");
map.put(new Student("001"), "張三");
// 遍歷結果:鍵按 id 降序排列 → 002(李四)、001(張三)特點:可以按照key來做排序,key不能null,key不能重複,值可以有多個null,不是線程安全的
HashTable
HashTable特點:1.HashTable時map的實現類。
2.不允許任何null值和null鍵。
3.HashTable中的元素沒有順序(跟添加的順序無關)
4.HashTable時線程安全的。
文件類File
file對象就表示一個路徑,可以是文件的路徑、也可以是文件夾的路徑
這個路徑可以是存在的,也允許是不存在的
絕對路徑:帶盤符的
相對路徑:不帶盤符的,默認到當前項目下去找。
|
方法名稱
|
説明
|
|
|
根據文件路徑創建文件對象
|
|
|
根據父路徑名字符串和子路徑名字符串創建文件對象
|
|
|
根據父路徑對應文件對象和子路徑名字符串創建文件對象
|
父級路徑就是去掉文件本身就是前面的路徑,而子路徑就是本身
File的常見成員方法(判斷、獲取)
|
方法名稱
|
説明
|
|
|
判斷此路徑名錶示的File是否為文件夾
|
|
|
判斷此路徑名錶示的File是否為文件
|
|
|
判斷此路徑名錶示的File是否存在
|
|
|
返回文件的大小(字節數量)
|
|
|
返回文件的絕對路徑
|
|
|
返回定義文件時使用的路徑
|
|
|
返回文件的名稱,帶後綴
|
|
|
返回文件的最後修改時間(時間毫秒值)
|
length()方法的細節:
1.這個方法只能獲取文件的大小,單位是字節。
2.這個方法無法獲取文件夾的大小,如果我們要獲取一個文件夾的大小,需要把這個文件夾裏面所有的文件大小都累加在一起。
File的常見成員方法(創建、刪除)
|
方法名稱
|
説明
|
|
|
創建一個新的空的文件
|
|
|
創建單級文件夾
|
|
|
創建多級文件夾
|
|
|
刪除文件、空文件夾
|
注意:delete方法默認只能刪除文件和空文件夾,delete方法直接刪除不走回收站
createNewFile方法細節:
1.如果當前路徑表示的文件時不存在的,則創建成功,方法返回true。如果當前路徑表示的文件時存在的,則創建失敗,方法返回false。
2.如果父級路徑時不存在的,那麼方法會有異常IOEception
3.createNewFile方法創建的一定是文件,如果路徑中不包含後綴名,則創建一個沒有後綴的文件。
mkdir方法細節:
1.windows當中路徑是唯一的,如果當前路徑名已經存在,則創建失敗,返回false
2.mkdir方法只能創建單級文件夾,無法創建多級文件夾
mkidrs方法細節:既可以創建單極的,又可以創建多級的文件夾。
File的常見成員方法(獲取並遍歷)
|
方法名稱
|
説明
|
|
|
獲取當前該路徑下所有內容
|
重點:
- 當調用者File表示的路徑不存在時,返回null
- 當調用者File表示的路徑是文件時,返回null
- 當調用者File表示的路徑時一個空文件夾時,返回一個長度為0的數組
- 當調用者File表示的路徑時一個有內容的文件夾時,將裏面所有文件和文件夾的路徑放在File數組中返回,包含隱藏文件。
- 當調用這File表示的路徑時需要權限才能訪問的文件夾時,返回null
IO流
IO流:存儲和讀取數據的解決方案
File表示系統中的文件或者文件夾的路徑,注意:File類只能對文件本身進行操作,不能讀寫文件裏面存儲的數據。
IO流:用於讀寫文件中的數據(可以讀寫文件,或網絡中的數據...)
IO流中,在在讀,誰在寫?以誰為參照物看讀寫的方向呢?
是以程序為參照物
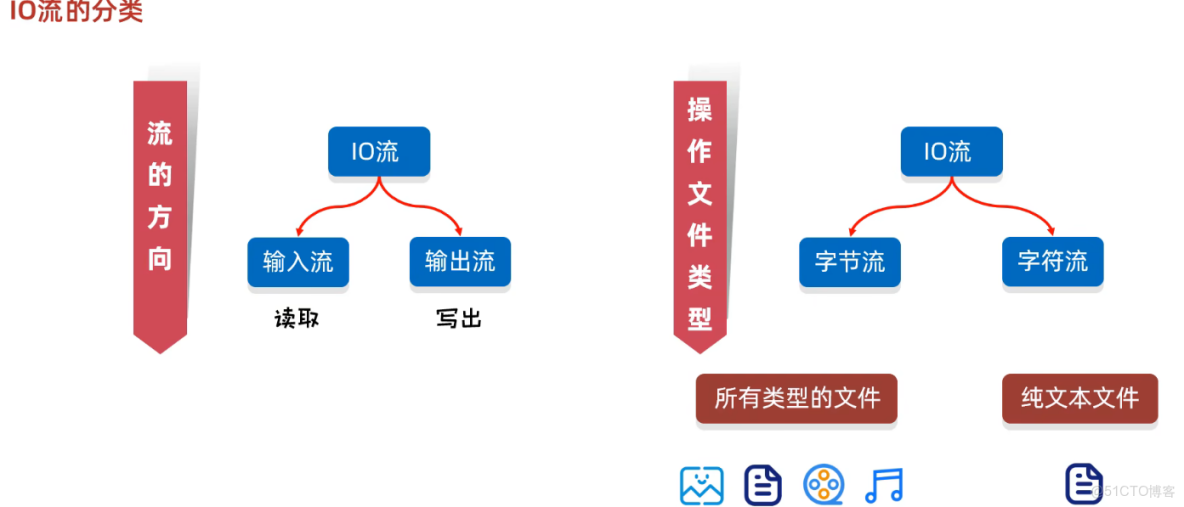
輸出流:程序---->文件
輸入流:文件----->程序
純文本文件:Windows自帶的記事本打開能讀懂
一、字符流與字節流的本質區別
|
類型
|
操作單元
|
處理的數據
|
核心用途
|
底層依賴
|
|
字符流 |
以 “字符” 為單位(1 字符 = 2 字節,Unicode 編碼)
|
文本數據(如 |
直接操作文本內容,自動處理字符編碼(如 UTF-8、GBK),避免亂碼
|
底層依賴字節流 + 編碼表
|
|
字節流 |
以 “字節” 為單位(8 位二進制)
|
二進制數據(如音頻、視頻、圖片、壓縮包等)
|
處理所有類型文件(文本 / 非文本),直接操作原始字節
|
直接操作二進制數據,不涉及編碼
|
二、字符流與字節流的典型實現
1. 字符流(Reader/Writer 體系)
字符流的頂層抽象類是 Reader(輸入)和 Writer(輸出),常用實現類按功能分為 “基礎流” 和 “緩衝流”(高效流):
|
類型
|
輸入流(Reader)
|
輸出流(Writer)
|
功能説明
|
|
基礎流 |
|
|
直接讀寫文件中的字符(依賴系統默認編碼,可能有亂碼風險)
|
|
|
|
字節流→字符流的橋樑(手動指定編碼,如 UTF-8,避免亂碼) |
|
|
高效流 |
|
|
帶緩衝區的字符流,通過緩衝減少 IO 次數,提升讀寫效率(需包裝基礎字符流)
|
|
標準流 |
|
|
與系統交互的字符流( |
2. 字節流(InputStream/OutputStream 體系)
字節流的頂層抽象類是 InputStream(輸入)和 OutputStream(輸出),常用實現類同樣分為 “基礎流” 和 “緩衝流”:
|
類型
|
輸入流(InputStream)
|
輸出流(OutputStream)
|
功能説明
|
|
基礎流 |
|
|
直接讀寫文件中的字節(適用於所有文件類型,包括文本和二進制)
|
|
高效流 |
|
|
帶緩衝區的字節流,通過緩衝提升大文件讀寫效率(需包裝基礎字節流)
|
|
標準流 |
|
|
系統默認的字節流,通常需轉為字符流使用(如 |
三、字符流與字節流的轉換橋樑
字符流本質上是 “字節流 + 編碼表” 的封裝,兩者的轉換通過以下兩個類實現:
InputStreamReader:將字節輸入流(InputStream)轉換為字符輸入流(Reader),可指定編碼(如UTF-8)。OutputStreamWriter:將字符輸出流(Writer)轉換為字節輸出流(OutputStream),可指定編碼
// 字節輸入流 → 字符輸入流(指定 UTF-8 編碼)
InputStream in = new FileInputStream("test.txt");
Reader reader = new InputStreamReader(in, StandardCharsets.UTF_8);
// 字符輸出流 → 字節輸出流(指定 UTF-8 編碼)
OutputStream out = new FileOutputStream("output.txt");
Writer writer = new OutputStreamWriter(out, StandardCharsets.UTF_8);四、使用場景總結
- 優先用字符流的場景:操作文本文件(如
.txt、.java),需要直接處理字符內容(如讀取文字、換行符),且需避免編碼問題時。
- 推薦組合:
InputStreamReader(指定編碼) +BufferedReader(高效讀取)。
- 必須用字節流的場景:操作非文本文件(如音頻、視頻、圖片、壓縮包),或需要處理原始二進制數據(如文件傳輸、加密解密)時。
- 推薦組合:
FileInputStream+BufferedInputStream(高效讀取)。
- 轉換流的核心價值:當需要指定編碼讀寫文本時(如避免系統默認編碼導致的亂碼),必須通過
InputStreamReader/OutputStreamWriter轉換,這是字符流與字節流協作的關鍵
常見字符編碼
|
編碼
|
適用場景
|
優點
|
缺點
|
|
ASCII
|
純英文文本
|
簡單、佔用空間小
|
不支持中文等非英文字符
|
|
GBK
|
簡體中文為主的場景(如舊系統)
|
中文佔 2 字節,節省空間
|
不支持全球字符,跨語言場景易亂碼
|
|
UTF-8
|
跨平台、多語言場景(推薦)
|
兼容 ASCII、支持全球字符、節省空間
|
中文佔 3 字節(比 GBK 略費空間)
|
|
UTF-16
|
系統內部處理(如 Java 字符串)
|
字符定位快(固定長度)
|
佔用空間較大(英文也需 2 字節
|
關鍵注意點
- 亂碼問題:文件讀寫時,若編碼方式與文件實際編碼不一致,會導致亂碼(如用 GBK 讀 UTF-8 編碼的中文文件)。
- 開發建議:新系統 / 項目優先使用 UTF-8,避免編碼兼容問題(尤其是跨國、多語言場景)
對象流
序列化流
序列化流也是高級流,用來包裝基本流的,屬於字節流的高級流
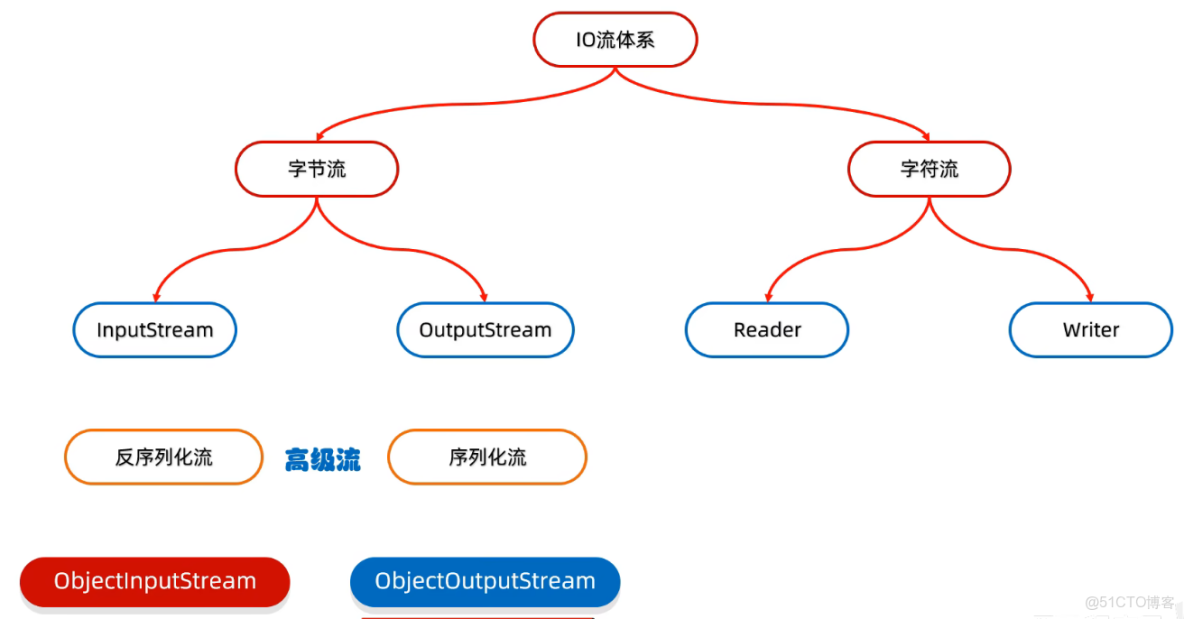
可以把Java中的的對象寫到本地文件中,但是是看不懂的,也叫對象操作輸出流
|
構造方法 |
説明 |
|
|
把基本流包裝成高級流
|
|
成員方法 |
説明 |
|
|
把對象序列化(寫出)到文件中去
|
細節:
使用對象輸出流將對象保存到文件時會出現NotSerializableException異常,解決方案:需要讓Javabean類實現Sserializable接口
Serializanle接口裏面沒有抽象方法,時一個標記型接口,一旦實現了這個接口,那麼就表示當前Student類可以被序列化
反序列化流
可以把序列化到本地文件中的對象,讀取到程序中來,也叫對象操作輸入流
|
構造方法 |
説明 |
|
|
把基本流包裝成高級流
|
|
成員方法 |
説明 |
|
|
把序列化到本地文件中的對象,讀取到程序中來
|
序列化時注意的細節:
如果你在序列化對象的時候寫到文件中時,javabean類會根據屬性計算出一個版本號,但是之後又修改了javabean,那麼javabean類又會計算出來一個版本號,所以在反序列化讀取文件時會報錯版本號不一致。
解決方案:
規定一個版本號不能改變:private static final long serialVersionUID = 1L;
如果你不想javabean其中的一個屬性序列化那麼就在屬性前面加上瞬態關鍵字transient(不會把當前屬性序列化到本地文件當中)
序列化流寫到文件中的數據時不能修改的,一旦修改就無法再次讀取。
網絡編程
網絡編程是指通過計算機網絡協議實現不同設備(或進程)之間的數據傳輸,核心涉及 UDP、TCP 兩種傳輸層協議,以及支撐它們的 網絡分層模型。以下系統梳理三者的核心概念和關係:
一、網絡分層模型(OSI 七層模型與 TCP/IP 四層模型)
網絡通信的底層依賴分層設計(“分層解耦”),每一層負責特定功能,通過接口向上層提供服務。實際應用中常用 TCP/IP 四層模型(簡化自 OSI 七層模型):
|
TCP/IP 四層模型
|
核心功能
|
對應協議 / 技術
|
|
應用層 |
為用户提供具體服務(如網頁、文件傳輸),定義數據格式和交互規則。
|
HTTP、FTP、SMTP、DNS 等
|
|
傳輸層 |
負責端到端(進程到進程)的數據傳輸,控制數據的可靠性和流量。
|
TCP、UDP 協議
|
|
網絡層 |
負責跨網絡的路由選擇(找到數據傳輸的路徑),處理 IP 地址和數據包轉發。
|
IP 協議、ICMP(網絡控制)、路由協議等
|
|
網絡接口層 |
負責物理設備(如網卡)的二進制數據傳輸,處理 MAC 地址和硬件細節。
|
以太網、Wi-Fi 等底層協議
|
核心作用:上層無需關心底層細節(如應用層不用管數據如何通過網線傳輸),每層僅與相鄰層交互,降低了網絡設計的複雜度。
二、UDP 協議(用户數據報協議)
UDP 是一種 無連接、不可靠 的傳輸層協議,特點是 “簡單、快速”,適合對實時性要求高但可容忍少量數據丟失的場景。
1. 核心特點
- 無連接:通信前無需建立連接(如打電話前不撥號),直接發送數據。
- 不可靠:
- 不保證數據一定到達接收方;
- 不保證數據順序(先發的數據可能後到);
- 不保證數據不重複。
- 高效性:協議簡單,開銷小,傳輸速度快(無確認、重傳等機制)。
- 數據限制:每個數據包(數據報)大小有限制(通常不超過 64KB)。
2. 適用場景
- 實時通信:如視頻通話、語音聊天(卡頓可容忍,延遲需低);
- 廣播 / 多播:如直播、遊戲同步(向多個接收方發送數據);
- 簡單交互:如 DNS 查詢(數據量小,對實時性要求高)。
3. 通信流程
- 發送方直接通過 UDP 套接字(
DatagramSocket)發送數據報(DatagramPacket),包含目標 IP 和端口; - 接收方通過 UDP 套接字監聽端口,收到數據報後解析內容;
- 無確認、斷開連接等步驟,通信結束無需 “揮手”。
三、TCP 協議(傳輸控制協議)
TCP 是一種 面向連接、可靠 的傳輸層協議,特點是 “可靠、有序”,適合對數據完整性要求高的場景。
1. 核心特點
- 面向連接:通信前必須通過 “三次握手” 建立連接(類似打電話前撥號確認),通信結束需 “四次揮手” 斷開連接。
- 可靠性:
- 數據確認:接收方收到數據後必須發送確認(ACK),未收到確認則發送方重傳;
- 順序保證:通過序列號(Sequence Number)確保數據按發送順序到達;
- 流量控制:通過滑動窗口機制避免接收方處理不及(防止數據淹沒接收方);
- 擁塞控制:避免網絡擁堵時發送過多數據(減少丟包)。
- 低效性:協議複雜,開銷大(確認、重傳等機制增加數據量和延遲)。
- 無數據大小限制:數據可分片傳輸(底層 IP 協議負責分片,TCP 負責重組)。
2. 適用場景
- 數據完整性優先:如文件傳輸(FTP)、網頁瀏覽(HTTP/HTTPS)、郵件發送(SMTP);
- 重要通信:如轉賬、登錄驗證(不允許數據丟失或錯亂)。
3. 通信流程(核心步驟)
- 建立連接(三次握手):
- 客户端 → 服務器:“我要連接你(SYN)”;
- 服務器 → 客户端:“我準備好了,你可以發了(SYN+ACK)”;
- 客户端 → 服務器:“好的,開始發數據(ACK)”。
- 數據傳輸:通過字節流(
InputStream/OutputStream)連續傳輸,TCP 保證數據可靠有序。 - 斷開連接(四次揮手):
- 客户端 → 服務器:“我要斷開了(FIN)”;
- 服務器 → 客户端:“收到,我準備一下(ACK)”;
- 服務器 → 客户端:“我也準備好了,斷開吧(FIN)”;
- 客户端 → 服務器:“好的,斷開(ACK)”。
四、UDP 與 TCP 的核心區別
|
對比維度
|
UDP
|
TCP
|
|
連接性
|
無連接
|
面向連接(三次握手 / 四次揮手)
|
|
可靠性
|
不可靠(無確認、重傳)
|
可靠(確認、重傳、順序保證)
|
|
速度
|
快(協議簡單,開銷小)
|
慢(額外機制增加延遲和開銷)
|
|
數據形式
|
數據報(有限大小)
|
字節流(無大小限制)
|
|
適用場景
|
實時通信(視頻、語音)
|
可靠傳輸(文件、網頁、登錄
|