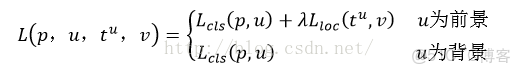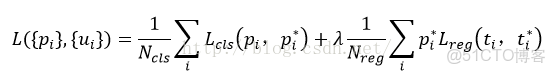算法發展:
R-CNN:把2000個建議框,分別送入網絡
Fast-RCNN:把圖片送入網絡中,再把2000個建議框映射到網絡訓練出來的feature map上
Faster-RCNN:利用RPN選取300建議框,加入ROI層,ROI pooling層能實現訓練和測試的顯著加速,並提高檢測的正確率。
算法框架:
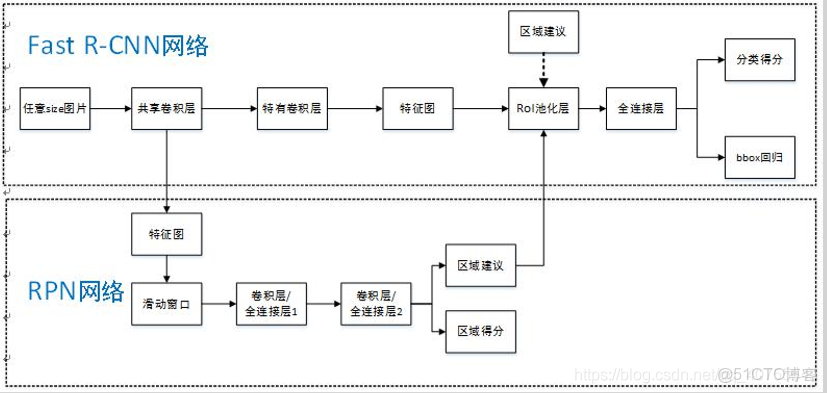
算法流程:
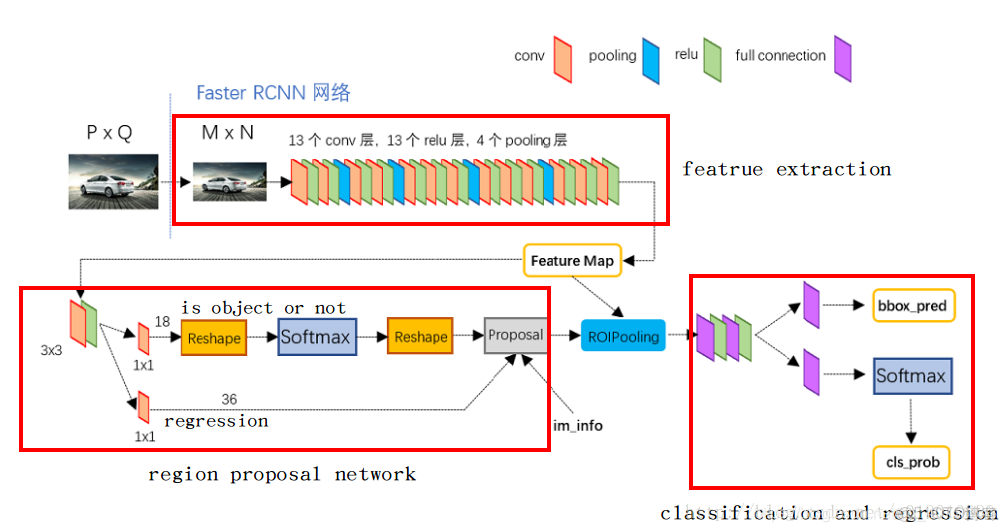
- 輸入圖片(224x224x3)
- 整張圖輸入CNN,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取input image的feature maps,該feature maps會用於後續的RPN層和全連接層
- RPN:利用RPN網絡生成建議框(Anchor box),每張圖片生成300個建議框窗口(包括IoU和NMS),對這些建議框進行裁剪過濾(reshape)後通過softmax判斷anchors屬於前景(foreground)或者後景(background),即是物體or不是物體,所以這是一個二分類;同時,另一分支bounding box regression修正anchor box,形成較精確的proposal
- RoI pooling層:該層把RPN生成的proposals映射到VGG16最後一層得到的feature map,得到固定大小的proposal feature map,進入到後面可利用全連接操作來進行目標識別和定位
- Classifier:將Roi Pooling層形成固定大小的feature map進行全連接操作,利用Softmax Loss進行具體類別的分類,同時,利用SmoothL1 Loss完成bounding box regression迴歸操作獲得物體的精確位置
算法細節:
1.Conv layers
Faster RCNN首先是支持輸入任意大小的圖片,進入網絡之前對圖片進行了規整化尺度的設定,如可設定圖像短邊不超過600,圖像長邊不超過1000,我們可以假定M*N=1000*600(如果圖片少於該尺寸,可以邊緣補0,即圖像會有黑色邊緣)。
VGG16:(2+2+3+3+3)的連續卷積塊
- 13個conv層:kernel_size=3,pad=1,stride=1;
- 13個relu層:激活函數,不改變圖片大小
- 4個pooling層:kernel_size=2,stride=2;pooling層會讓輸出圖片是輸入圖片的1/2
經過Conv layers,圖片大小變成(M/16)*(N/16),即:60*40(1000/16≈60,600/16≈40);則,Feature Map就是60*40*512
注:VGG16是512-d,ZF是256-d,表示特徵圖的大小為60*40,深度為512
2.RPN
RPN-Anchor box 生成:
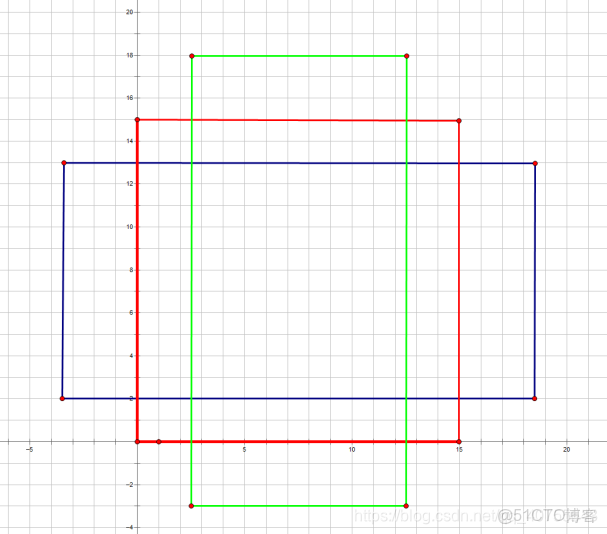
經過Conv layers後,圖片大小變成了原來的1/16,令feat_stride=16,在生成Anchors時,我們先定義一個base_anchor,大小為16*16的box(因為特徵圖(60*40)上的一個點,可以對應到原圖(1000*600)上一個16*16大小的區域),源碼中轉化為[0,0,15,15]的數組,參數ratios=[0.5, 1, 2]scales=[8, 16, 32]
[0,0,15,15],面積保持不變,長、寬比分別為[0.5, 1, 2]是產生的Anchors box:
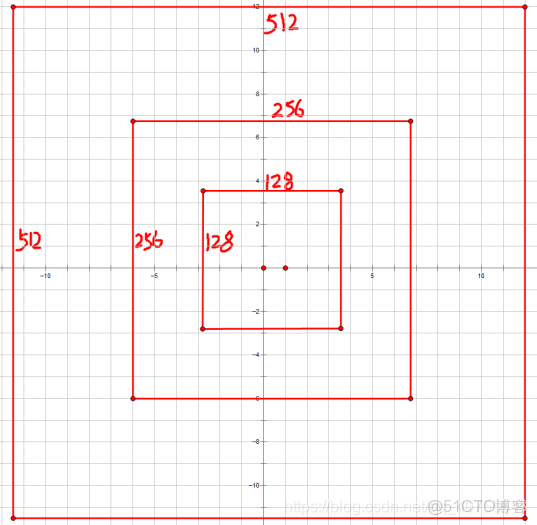
經過scales變化,即長、寬分別均為 (16*8=128)、(16*16=256)、(16*32=512),對應anchor box:
綜合以上兩種變換(1:1,1:2,2:1),最後生成9個Anchor box:
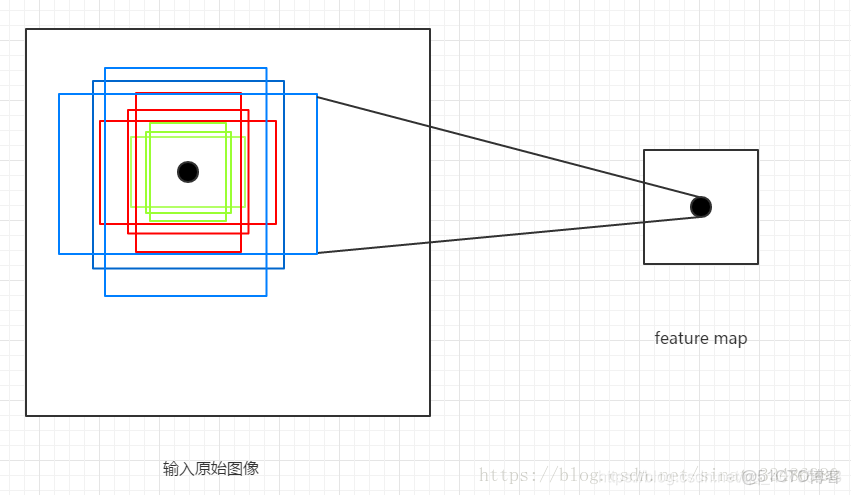
特徵圖大小為60*40,所以會一共生成60*40*9=21600個Anchor box。
generate_anchors源碼解析:
首先看main函數:
if __name__ == '__main__':
import time
t = time.time()
a = generate_anchors() #最主要的就是這個函數
print time.time() - t
print a
from IPython import embed; embed()進入到generate_anchors函數中:
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2**np.arange(3, 6)):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window.
"""
base_anchor = np.array([1, 1, base_size, base_size]) - 1
print ("base anchors",base_anchor)
ratio_anchors = _ratio_enum(base_anchor, ratios)
print ("anchors after ratio",ratio_anchors)
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])
print ("achors after ration and scale",anchors)
return anchors參數有三個:
1.base_size=16
這個參數指定了最初的類似感受野的區域大小,因為經過多層卷積池化之後,feature map上一點的感受野對應到原始圖像就會是一個區域,這裏設置的是16,也就是feature map上一點對應到原圖的大小為16x16的區域。也可以根據需要自己設置。
2.ratios=[0.5,1,2]
這個參數指的是要將16x16的區域,按照1:2,1:1,2:1三種比例進行變換
3.scales=2**np.arange(3, 6)
這個參數是要將輸入的區域,的寬和高進行三種倍數,2^3=8,2^4=16,2^5=32倍的放大,如16x16的區域變成(16*8)*(16*8)=128*128的區域,(16*16)*(16*16)=256*256的區域,(16*32)*(16*32)=512*512的區域。
接下來看第一句代碼:
base_anchor = np.array([1, 1, base_size, base_size]) - 1
'''base_anchor值為[ 0, 0, 15, 15]'''表示最基本的一個大小為16x16的區域,四個值,分別代表這個區域的左上角和右下角的點的座標。
ratio_anchors = _ratio_enum(base_anchor, ratios)這一句是將前面的16x16的區域進行ratio變化,也就是輸出三種寬高比的anchors,這裏調用了_ratio_enum函數,其定義如下:
輸入參數為一個anchor(四個座標值表示)和三種寬高比例(0.5,1,2)
def _ratio_enum(anchor, ratios):
"""
Enumerate a set of anchors for each aspect ratio wrt an anchor.
"""
size = w * h #size:16*16=256
size_ratios = size / ratios #256/ratios[0.5,1,2]=[512,256,128]
#round()方法返回x的四捨五入的數字,sqrt()方法返回數字x的平方根
ws = np.round(np.sqrt(size_ratios)) #ws:[23 16 11]
hs = np.round(ws * ratios) #hs:[12 16 22],ws和hs一一對應。as:23&12
#給定一組寬高向量,輸出各個預測窗口,也就是將(寬,高,中心點橫座標,中心點縱座標)的形式,轉成
#四個座標值的形式
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors在這個函數中又調用了一個_whctrs函數,這個函數定義如下,其主要作用是將輸入的anchor的四個座標值轉化成(寬,高,中心點橫座標,中心點縱座標)的形式。
最後該函數輸出的變換了三種寬高比的anchor如下:
ratio_anchors = _ratio_enum(base_anchor, ratios)
'''[[ -3.5, 2. , 18.5, 13. ],
[ 0. , 0. , 15. , 15. ],
[ 2.5, -3. , 12.5, 18. ]]'''進行完上面的寬高比變換之後,接下來執行的是面積的scale變換:
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])這裏最重要的是_scale_enum函數,該函數定義如下,對上一步得到的ratio_anchors中的三種寬高比的anchor,再分別進行三種scale的變換,也就是三種寬高比,搭配三種scale,最終會得到9種寬高比和scale 的anchors。這就是論文中每一個點對應的9種anchors。
def _scale_enum(anchor, scales):
"""
Enumerate a set of anchors for each scale wrt an anchor.
"""
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors在這個函數中又調用了一個_whctrs函數,這個函數定義如下,其主要作用是將輸入的anchor的四個座標值轉化成(寬,高,中心點橫座標,中心點縱座標)的形式。
def _whctrs(anchor):
"""
Return width, height, x center, and y center for an anchor (window).
"""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr通過這個函數變換之後將原來的anchor座標(0,0,15,15)轉化成了w:16,h:16,x_ctr=7.5,y_ctr=7.5的形式。
_scale_enum函數中也是首先將寬高比變換後的每一個ratio_anchor轉化成(寬,高,中心點橫座標,中心點縱座標)的形式,再對寬和高均進行scale倍的放大,然後再轉換成四個座標值的形式。最終經過寬高比和scale變換得到的9種尺寸的anchors的座標如下:
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])
'''
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
'''
源碼中,通過width:(0~60)*16,height(0~40)*16建立shift偏移量數組,再和base_ancho基準座標數組累加,得到特徵圖上所有像素對應的Anchors的座標值,是一個[216000,4]的數組。
RPN-分類與迴歸
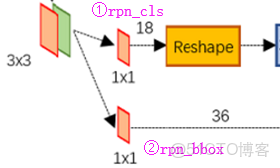
Feature Map進入RPN後,先經過一次3*3的卷積,同樣,特徵圖大小依然是60*40*512,這樣做的目的應該是進一步集中特徵信息,接着看到兩個全卷積,即kernel_size=1*1,p=0,stride=1。這裏:1*1卷積的意義是改變特徵維度(18,36)。
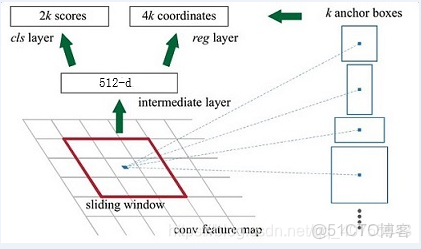
如上圖中標識:
① rpn_cls:60*40*512-d ⊕18 ==> 60*40*9*2
逐像素對其9個Anchor box進行二分類
② rpn_bbox:60*40*512-d ⊕36==>60*40*9*4
逐像素得到其9個Anchor box四個座標信息(其實是偏移量)
RPN-工作原理
Caffe版本下的網絡:
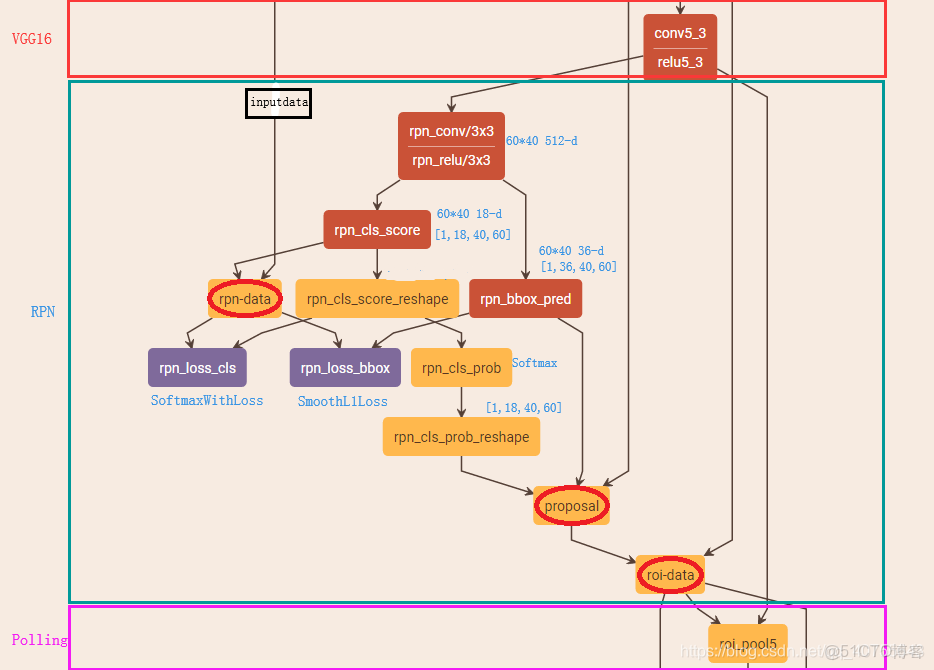
<<1>>rpn-data:
生成Anchor box,對Anchor box進行過濾和打標籤(為了softmax),且對Anchor box和Ground Truth計算偏移量(為了SmoothL1)
layer {
2. name: 'rpn-data'
3. type: 'Python'
4. bottom: 'rpn_cls_score' #僅提供特徵圖的height和width的參數大小
5. bottom: 'gt_boxes' #ground truth box
6. bottom: 'im_info' #包含圖片大小和縮放比例,可供過濾anchor box
7. bottom: 'data'
8. top: 'rpn_labels'
9. top: 'rpn_bbox_targets'
10. top: 'rpn_bbox_inside_weights'
11. top: 'rpn_bbox_outside_weights'
12. python_param {
13. module: 'rpn.anchor_target_layer'
14. layer: 'AnchorTargetLayer'
15. param_str: "'feat_stride': 16 \n'scales': !!python/tuple [8, 16, 32]"
16. }
17. }這一層主要是為特徵圖60*40上的每個像素生成9個Anchor box(位置),並且對生成的Anchor box進行過濾和標記,參照源碼。
過濾和標記規則如下:
去除掉超過1000*600這原圖的邊界的anchor box
如果anchor box與ground truth的IoU>0.7,標記為正樣本,label=1
如果anchor box與ground truth的IoU<0.3,標記為負樣本,label=0
剩下的既不是正樣本也不是負樣本,不用於最終訓練,label=-1
除了對anchor box進行標記外,另一件事情就是計算anchor box與ground truth之間的偏移量
令:ground truth:標定的框也對應一箇中心點位置座標x*,y*和寬高w*,h*
anchor box: 中心點位置座標x_a,y_a和寬高w_a,h_a
所以,偏移量:
△x=(x*-x_a)/w_a △y=(y*-y_a)/h_a
△w=log(w*/w_a) △h=log(h*/h_a)
通過ground truth box與預測的anchor box之間的差異來進行學習,從而是RPN網絡中的權重能夠學習到預測box的能力
<<2>>rpn_loss_cls、rpn_loss_bbox、rpn_cls_prob:
其中‘rpn_loss_cls’、‘rpn_loss_bbox’是分別對應softmax,smooth L1計算損失函數。
- Softmax公式,計算各分類的概率值
- Softmax Loss公式,RPN進行分類時,即尋找最小Loss值
RPN訓練設置:在訓練RPN時,一個Mini-batch是由一幅圖像中任意選取的256個proposal組成的,其中正負樣本的比例為1:1。如果正樣本不足128,則多用一些負樣本以滿足有256個Proposal可以用於訓練,反之亦然。
舉個栗子:共5000個proposal進行訓練,其中正例200,反例4800。每個Mini-batch每次分別隨機從正反選出128個。為什麼這麼做?因為反例一般佔據大多數,如果隨機選擇,則反例會佔每個Mini-batch的絕大數,會導致算出的loss不準。
rpn_cls_prob 存放的是每個框的類別得分。是為了進行下一步的nms的操作,眾所周知nms是按照置信度(類別得分)來排序的。
<<3>>proposal
layer {
2. name: 'proposal'
3. type: 'Python'
4. bottom: 'rpn_cls_prob_reshape' #[1,18,40,60]==> [batch_size, channel,height,width]Caffe的數據格式,anchor box分類的概率
5. bottom: 'rpn_bbox_pred' # 記錄訓練好的四個迴歸值△x, △y, △w, △h
6. bottom: 'im_info'
7. top: 'rpn_rois'
8. python_param {
9. module: 'rpn.proposal_layer'
10. layer: 'ProposalLayer'
11. param_str: "'feat_stride': 16 \n'scales': !!python/tuple [4, 8, 16, 32]"
12. }
13. }在輸入中我們看到’rpn_bbox_pred’,記錄着訓練好的四個迴歸值△x, △y, △w, △h。
源碼中,會重新生成60*40*9個anchor box,然後累加上訓練好的△x, △y, △w, △h,從而得到了相較於之前更加準確的預測框region proposal。
進一步對預測框進行越界剔除和使用nms非最大值抑制,剔除掉重疊的框;
比如,設定IoU為0.7的閾值,即僅保留覆蓋率不超過0.7的局部最大分數的box(粗篩)。最後留下大約2000個anchor,然後再取前N個box(比如300個);這樣,進入到下一層ROI Pooling時region proposal大約只有300個
<<4>>roi_data
layer {
2. name: 'roi-data'
3. type: 'Python'
4. bottom: 'rpn_rois'
5. bottom: 'gt_boxes'
6. top: 'rois'
7. top: 'labels'
8. top: 'bbox_targets'
9. top: 'bbox_inside_weights'
10. top: 'bbox_outside_weights'
11. python_param {
12. module: 'rpn.proposal_target_layer'
13. layer: 'ProposalTargetLayer'
14. param_str: "'num_classes': 81"
15. }
16. }為了避免定義上的誤解,我們將經過‘proposal’後的預測框稱為region proposal(其實,RPN層的任務其實已經完成,roi_data屬於為下一層準備數據)
主要作用:
- RPN層只是來確定region proposal是否是物體(是/否),這裏roi_data根據region proposal和ground truth box的最大重疊指定具體的標籤(就不再是二分類問題了,參數中指定的是81類),再次打標籤。
- 計算region proposal與ground truth boxes的偏移量,計算方法和之前的偏移量計算公式相同
經過這一步後的數據輸入到ROI Pooling層進行進一步的分類和定位。
3.ROI Pooling:
layer {
2. name: "roi_pool5"
3. type: "ROIPooling"
4. bottom: "conv5_3" #輸入特徵圖大小
5. bottom: "rois" #輸入region proposal
6. top: "pool5" #輸出固定大小的feature map
7. roi_pooling_param {
8. pooled_w: 7
9. pooled_h: 7
10. spatial_scale: 0.0625 # 1/16
11. }
12. }把建議框映射到CNN的最後一層faature map上,進行pooling得到固定大小的proposal feature map
從上述的Caffe代碼中可以看到,輸入的是RPN層產生的region proposal(假定有300個region proposal box)和VGG16最後一層產生的特徵圖(60*40 512-d),遍歷每個region proposal,將其座標值縮小16倍,這樣就可以將在原圖(1000*600)基礎上產生的region proposal映射到60*40的特徵圖上,從而將在feature map上確定一個區域(定義為RB*)。在feature map上確定的區域RB*,根據參數pooled_w:7,pooled_h:7,將這個RB*區域劃分為7*7,即49個相同大小的小區域,對於每個小區域,使用max pooling方式從中選取最大的像素點作為輸出,這樣,就形成了一個7*7的feature map。
ROI pooling層能實現training和testing的顯著加速,並提高檢測accuracy。
該層有兩個輸入:
- 從具有多個卷積核池化的深度網絡中獲得的固定大小的feature maps,VGG16最後一層產生的特徵圖(60*40 512-d)
- RPN層產生的region proposal(假定有300個region proposal box),表示為所有ROI的N*5的矩陣,其中N(300)表示ROI的數目。第一列表示圖像index,其餘四列表示其餘的左上角和右下角座標;
ROI pooling具體操作如下:參考:
- 根據輸入image,將ROI映射到feature map對應位置;
- 將映射後的區域劃分為相同大小的sections(sections數量與輸出的維度相同);
- 對每個sections進行max pooling操作;
這樣我們就可以從不同大小的方框得到固定大小的相應 的feature maps。值得一提的是,輸出的feature maps的大小不取決於ROI和卷積feature maps大小。ROI pooling 最大的好處就在於極大地提高了處理速度。
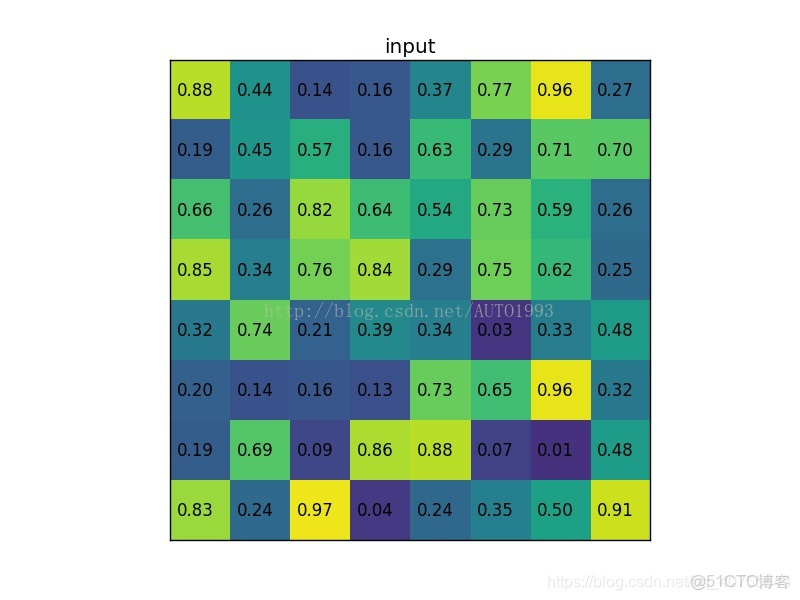
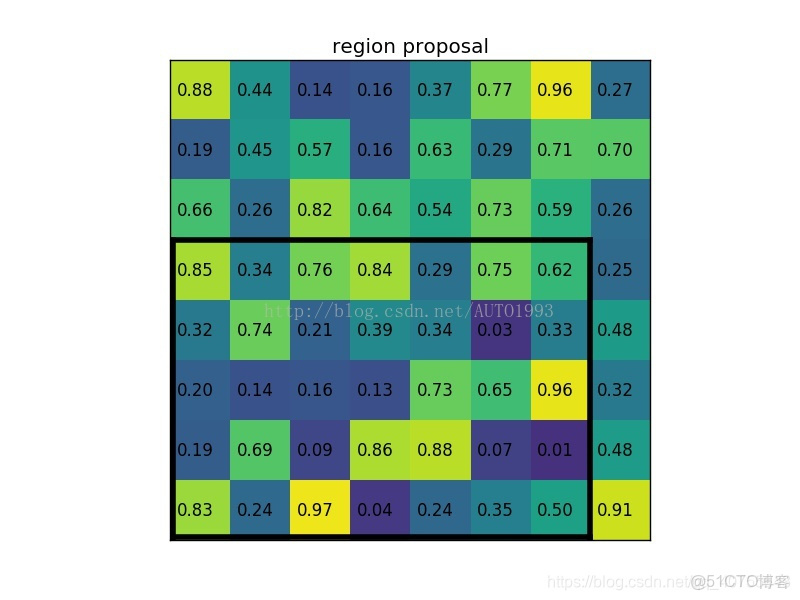
example
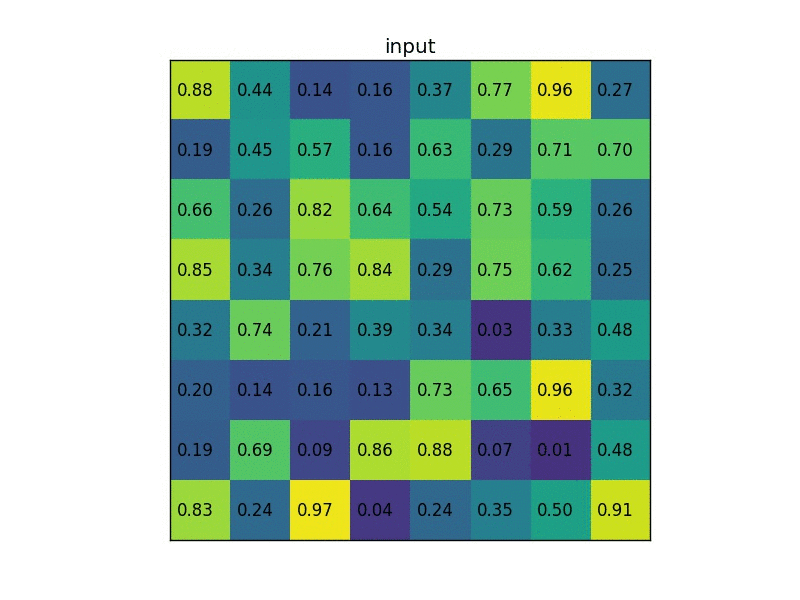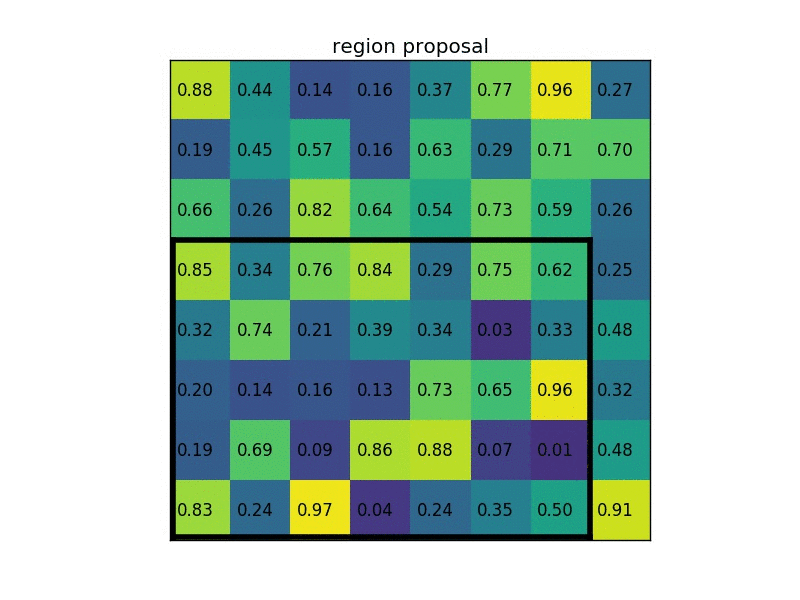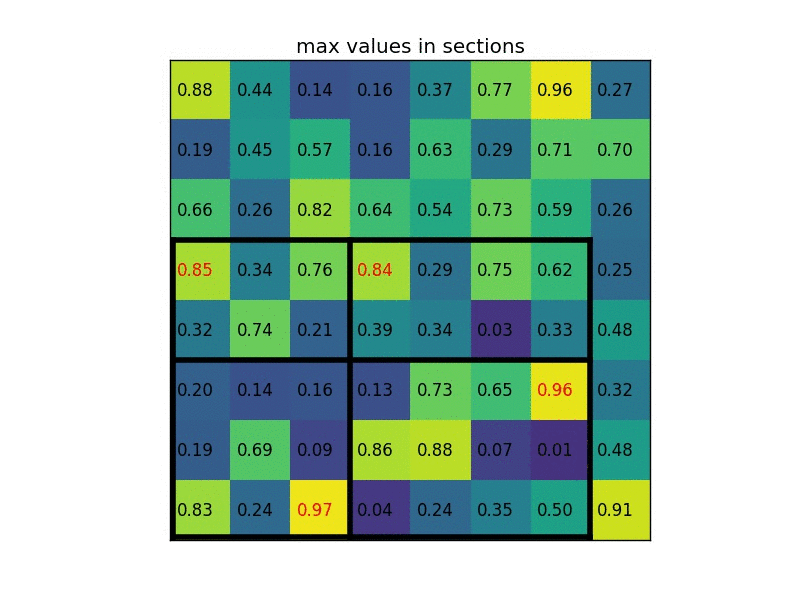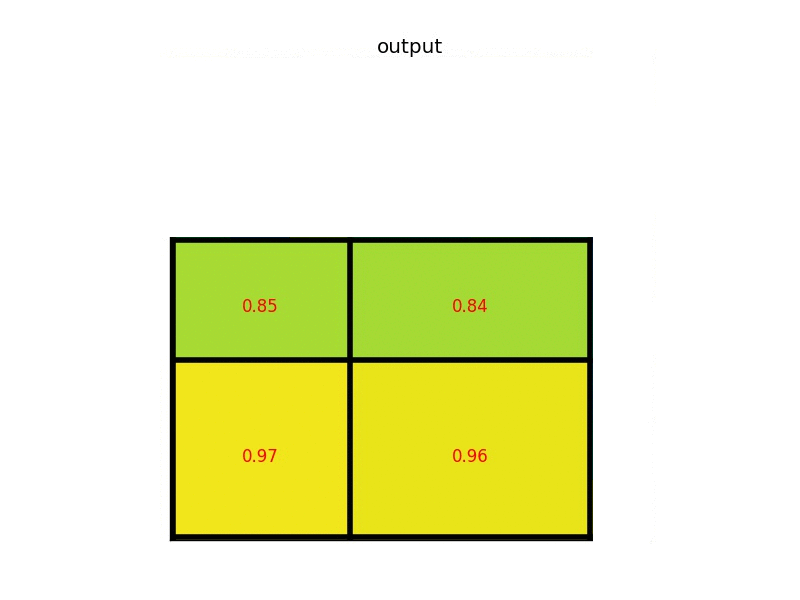
一個8*8大小的feature map,一個ROI,以及輸出大小為2*2。
(1)輸入的固定大小的feature map
(2)region proposal 投影之後位置(左上角,右下角座標):(0,3),(7,8)
(3)將其劃分為(2*2)個sections(因為輸出大小為2*2),我們可以得到:
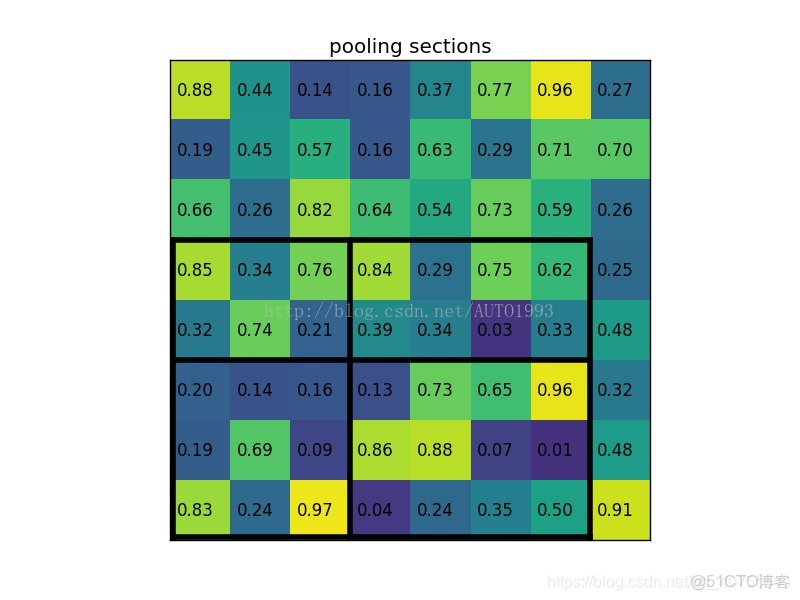
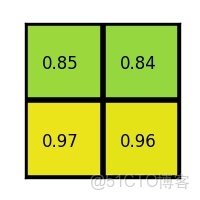
(4)對每個section做max pooling,可以得到:
4.Classifier
經過roi pooling層之後,batch_size=300, proposal feature map的大小是7*7*512,對特徵圖進行全連接,參照下圖,最後同樣利用Softmax Loss和L1 Loss完成分類和定位。
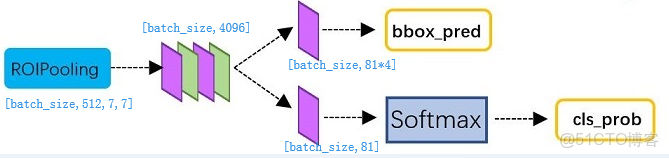
PoI Pooling獲取到7x7大小的proposal feature maps後,通過全連接主要做了:
- 通過全連接和softmax對region proposals進行具體類別的分類
- 再次對region proposals進行bounding box regression,獲取更高精度的rectangle box
LOSS