1.ShardingSphere
sharding-jdbc後續發展為Sharding-Sphere,包含sharding-jdbc、Sharding-Proxy、Sharding-Sidecar。
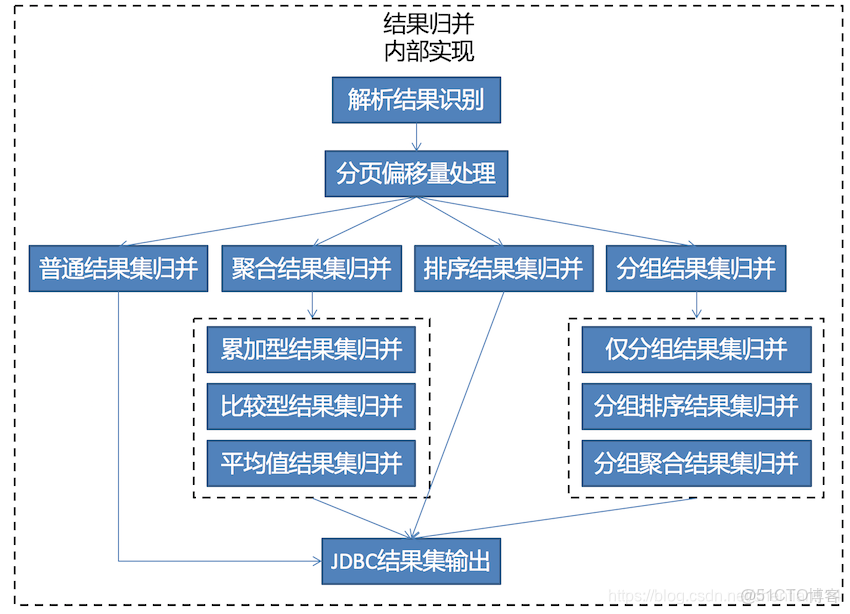
1)概述:ShardingSphere是一套開源的分佈式數據庫中間件解決方案組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(計劃中)這3款相互獨立的產品組成。 他們均提供標準化的數據分片、分佈式事務和數據庫治理功能,可適用於如Java同構、異構語言、容器、雲原生等各種多樣化的應用場景。
2)定位:ShardingSphere定位為關係型數據庫中間件,旨在充分合理地在分佈式的場景下利用關係型數據庫的計算和存儲能力,而並非實現一個全新的關係型數據庫。
2.Sharding-JDBC
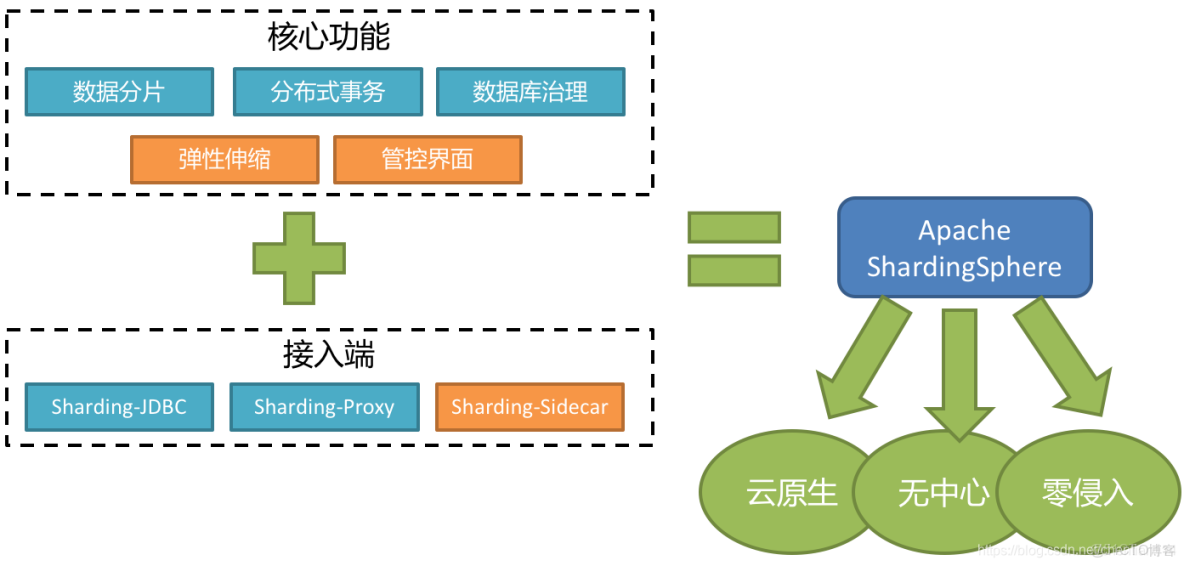
定位為輕量級Java框架,在Java的JDBC層提供的額外服務。 它使用客户端直連數據庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全兼容JDBC和各種ORM框架。
1)適用於任何基於Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2)基於任何第三方的數據庫連接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3)支持任意實現JDBC規範的數據庫。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
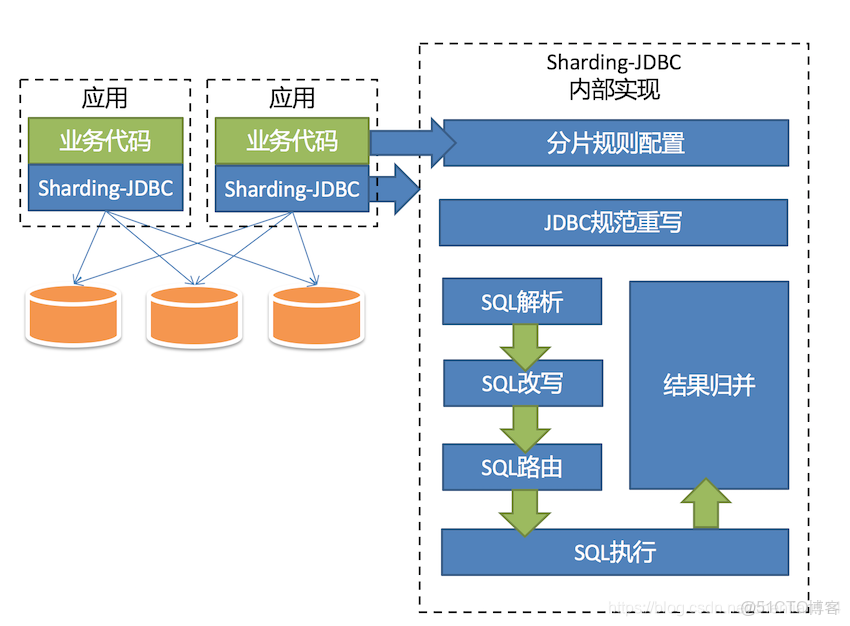
3.Sharding-Proxy
定位為透明化的數據庫代理端,提供封裝了數據庫二進制協議的服務端版本,用於完成對異構語言的支持。
目前先提供MySQL版本,它可以使用任何兼容MySQL協議的訪問客户端(如:MySQL Command Client, MySQL Workbench等)操作數據,對DBA更加友好。
1)嚮應用程序完全透明,可直接當做MySQL使用。
2)適用於任何兼容MySQL協議的客户端。
4.Sharding-Sidecar(TBD)
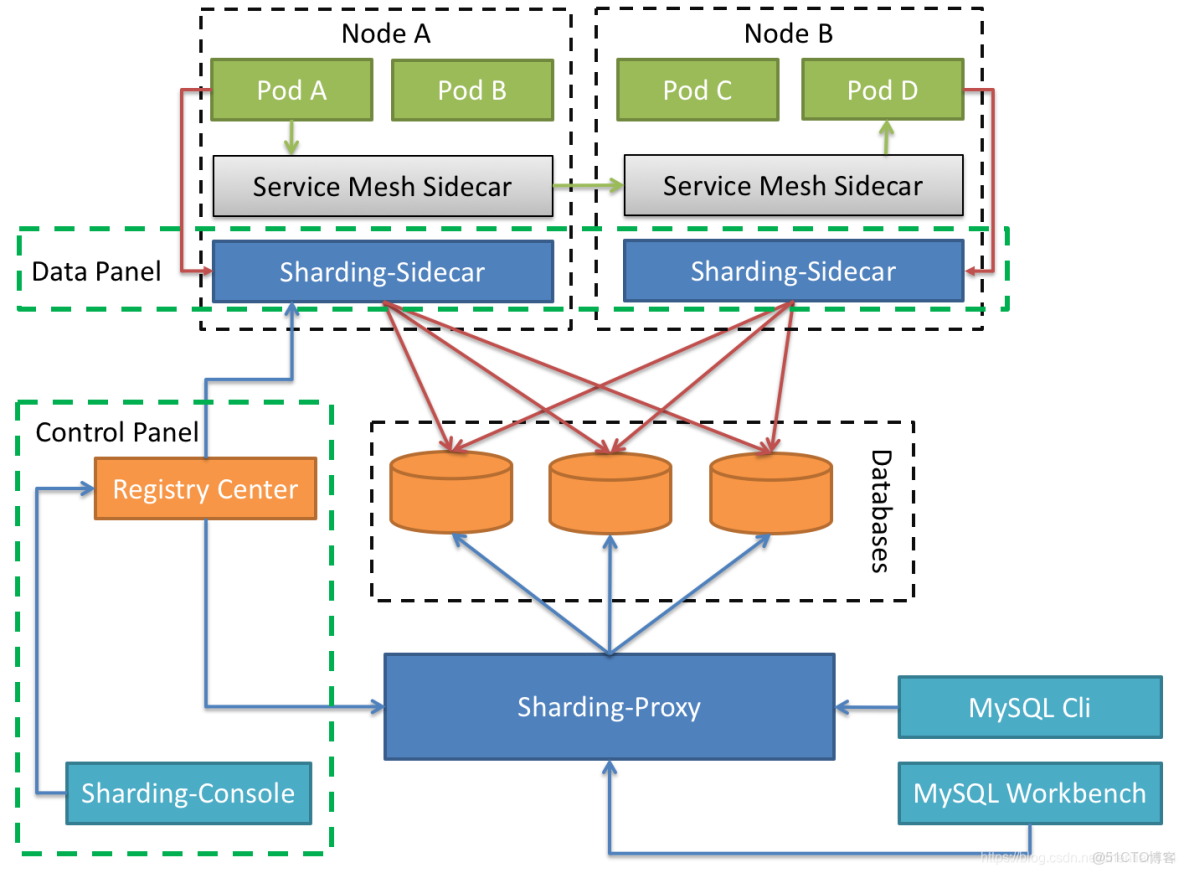
定位為Kubernetes或Mesos的雲原生數據庫代理,以DaemonSet的形式代理所有對數據庫的訪問。 通過無中心、零侵入的方案提供與數據庫交互的的齧合層,即Database Mesh,又可稱數據網格。
Database Mesh的關注重點在於如何將分佈式的數據訪問應用與數據庫有機串聯起來,它更加關注的是交互,是將雜亂無章的應用與數據庫之間的交互有效的梳理。
使用Database Mesh,訪問數據庫的應用和數據庫終將形成一個巨大的網格體系,應用和數據庫只需在網格體系中對號入座即可,它們都是被齧合層所治理的對象。
|
|
Sharding-JDBC |
Sharding-Proxy |
Sharding-Sidecar |
|
數據庫 |
任意 |
MySQL |
MySQL |
|
連接消耗數 |
高 |
低 |
高 |
|
異構語言 |
僅Java |
任意 |
任意 |
|
性能 |
損耗低 |
損耗略高 |
損耗低 |
|
無中心化 |
是 |
否 |
是 |
|
靜態入口 |
無 |
有 |
無 |
5.Sharding-JDBC包含的一些核心概念:
1)LogicTable。
數據分片的邏輯表,對於水平拆分的數據庫(表),同一類表的總稱。例:訂單數據根據主鍵尾數拆分為10張表,分別是t_order_0到t_order_9,他們的邏輯表名為t_order。
2)ActualTable。
在分片的數據庫中真實存在的物理表。即上個示例中的t_order_0到t_order_9。
3)DataNode。
數據分片的最小單元。由數據源名稱和數據表組成,例:ds_1.t_order_0。配置時默認各個分片數據庫的表結構均相同,直接配置邏輯表和真實表對應關係即可。如果各數據庫的表結果不同,可使用ds.actual_table配置。
4)DynamicTable。
邏輯表和真實表不一定需要在配置規則中靜態配置。比如按照日期分片的場景,真實表的名稱隨着時間的推移會產生變化。此類需求Sharding-JDBC是支持的,不過目前配置並不友好,會在新版本中提升。
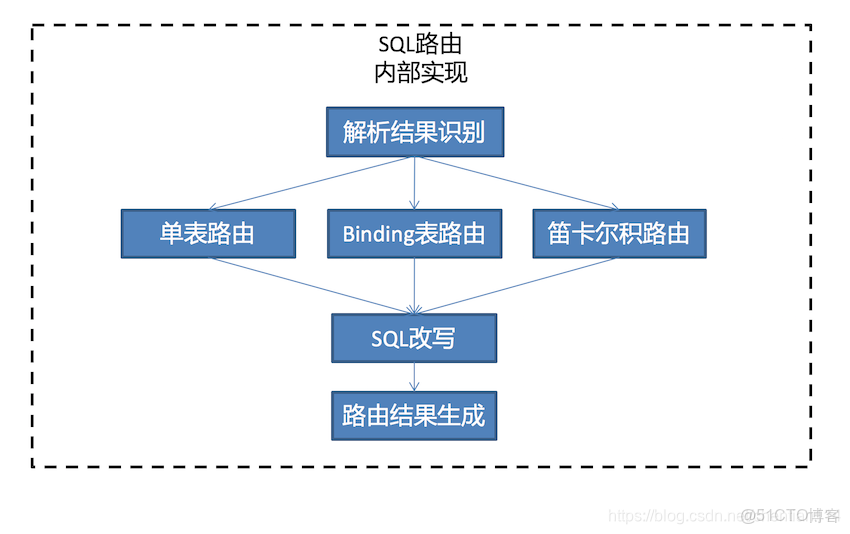
5)BindingTable。
指在任何場景下分片規則均一致的主表和子表。例:訂單表和訂單項表,均按照訂單ID分片,則此兩張表互為BindingTable關係。BindingTable關係的多表關聯查詢不會出現笛卡爾積關聯,關聯查詢效率將大大提升。
6)ShardingColumn。
分片字段。用於將數據庫(表)水平拆分的關鍵字段。例:訂單表訂單ID分片尾數取模分片,則訂單ID為分片字段。SQL中如果無分片字段,將執行全路由,性能較差。Sharding-JDBC支持多分片字段。
7)ShardingAlgorithm。
分片算法。Sharding-JDBC通過分片算法將數據分片,支持通過等號、BETWEEN和IN分片。分片算法目前需要業務方開發者自行實現,可實現的靈活度非常高。未來Sharding-JDBC也將會實現常用分片算法,如range,hash和tag等。
8)SQL Hint。
對於分片字段非SQL決定,而由其他外置條件決定的場景,可使用SQL Hint靈活的注入分片字段。例:內部系統,按照員工登錄ID分庫,而數據庫中並無此字段。SQL Hint支持通過ThreadLocal和SQL註釋(待實現)兩種方式使用。
6.分佈式數據庫中間件、產品——sharding-jdbc、mycat、drds比較
業務發展到一定程度,分庫分表是一種必然的要求,分庫可以實現資源隔離,分表則可以降低單表數據量,提高訪問效率。
分庫分表的技術方案,很久以來都有兩種理念:
集中式的Proxy,實現MySQL客户端協議,使用户無感知
分佈式的Proxy,在代碼層面進行增強,實現一個路由程序
這兩種方式是各有利弊的,集中式Proxy的好處是業務沒有感知,一切交給DBA把控,分佈式的Proxy其支持的語言有限,比如本文要提及的ShardingShpere-JDBC就只支持Java。
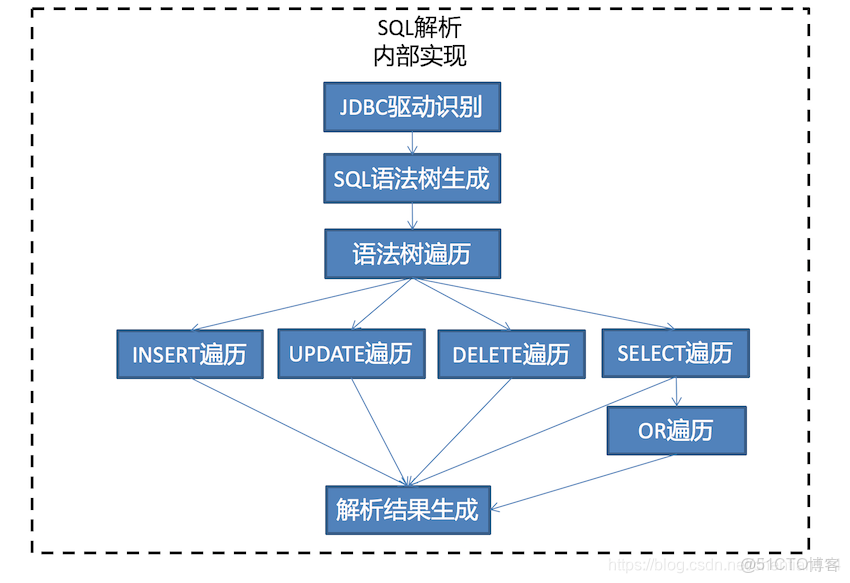
我們需要了解一點,集中式的Proxy其實現非常複雜,這要從MySQL處理SQL語句的原理説起,因為不是本文要論述的重點,因此只是簡單的提及幾點:
SQL語句要被Parser解析成抽象語法樹
SQL要被優化器解析出執行計劃
SQL語句完成解析後,發給存儲引擎
因此大部分的中間件都選擇了自己實現SQL的解析器和查詢優化器,下面是著名的中間件dble的實現示意圖:

只要有解析的過程,其性能損耗就是比較可觀的,我們也可以認為這是一種重量級的解決方案。
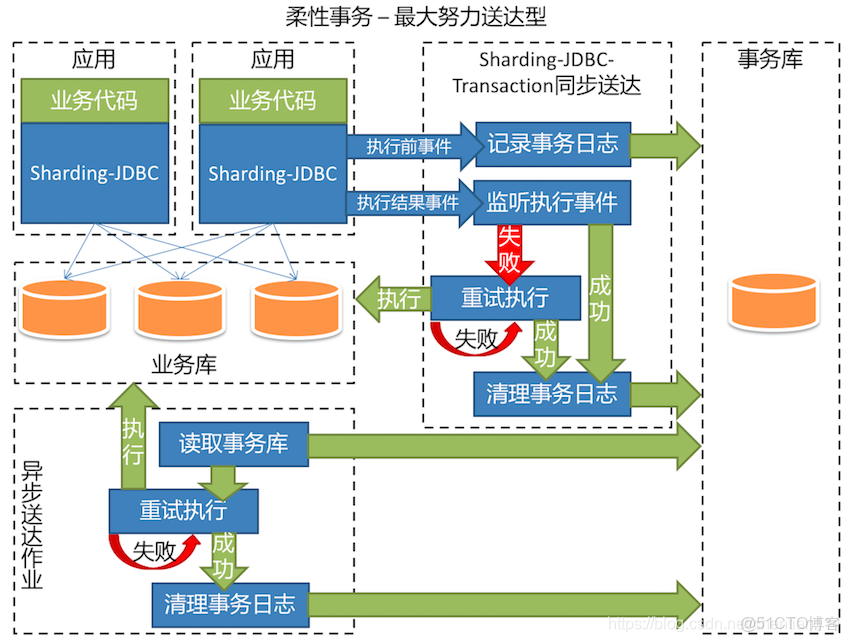
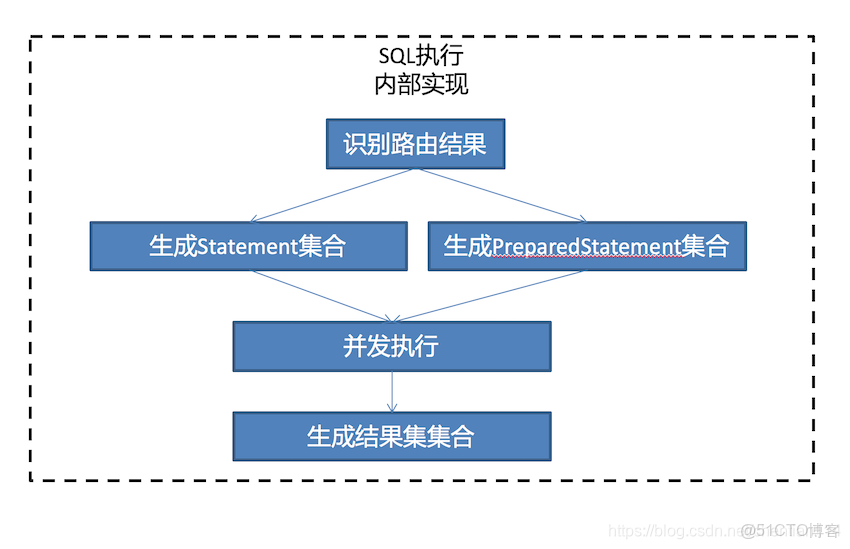
與之形成對比的是ShardingSphere-JDBC,其原理示意圖如下:

每一個服務都持有一個Sharing-JDBC,這個JDBC以Jar包的形式提供,基本上可以認為是一個增強版的jdbc驅動,需要一些分庫分表的配置,業務開發人員不需要去對代碼進行任何的修改。可以很輕鬆的移植到SpringBoot,ORM等框架上。
但是這個中結構也不是完美的,每一個服務持有一個proxy意味着會在MySQL服務端新建大量的連接,維持連接會增加MySQL服務器的負載,雖然這種負載提升一般無法察覺。
1.2 概念
邏輯表
**
即水平拆分的表的總稱。比如訂單業務會被拆分成t_order0,t_order1兩張表,但是他們同屬於一個邏輯表:t_order
綁定表
分片規則一直的主表和子表。比如還是上面的t_order表,其分片鍵是order_id,其子表t_order_item的分片鍵也是order_id。在規則配置時將兩個表配置成綁定關係,就不會在查詢時出現笛卡爾積。
在關聯查詢時,如果沒有綁定關係,則t_order和t_order_item的關聯會出現這樣一種場景:
select * from t_order0 inner join t_order_item0 on order_id = order_id where order_id in (0, 1);
select * from t_order0 inner join t_order_item1 on order_id = order_id where order_id in (0, 1;
select * from t_order1 inner join t_order_item0 on order_id = order_id where order_id in (0, 1;
select * from t_order1 inner join t_order_item1 on order_id = order_id where order_id in (0, 1;
如果配置了綁定關係,則會精確地定位到order_id所在的表,消除笛卡爾積。
廣播表
有一些表是沒有分片的必要的,比如省份信息表,全國也就30多條數據,這種表在每一個節點上都是一樣的,這種表叫做廣播表。
1)原因:一般對於業務記錄類隨時間會不斷增加的數據,當數據量增加到一定量(一般認為整型值為主的表達到千萬級,字符串為主的表達到五百萬)的時候,性能將遇到瓶頸,同時調整表結構也會變得非常困難。為了避免生產遇到這樣的問題,在做系統設計時需要預估可能產生的數據量:預估記錄主體個數*預估記錄主體產生的記錄數(用户訂單表預估數據量=預估用户數*單用户產生訂單數),預估達到一定量時,就不得不考慮分庫分表了。
2)選擇:目前國內比較成熟的開源數據庫中間件有:sharding-jdbc、mycat;而drds是阿里雲最近推出的商業產品,考慮到大部分公司都在使用阿里雲,做一個全家桶,也是一個不錯的選擇。
接下來將對這三款產品的優缺點及適用場景做以介紹。
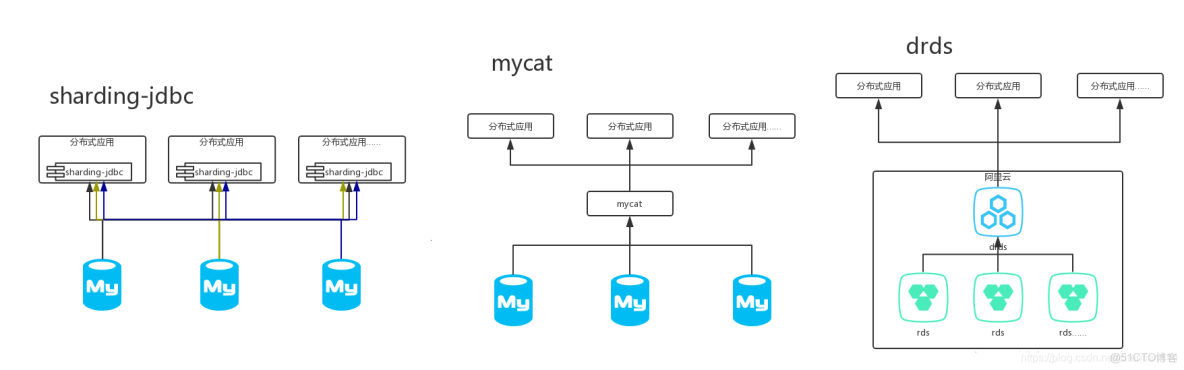
3)使用方式:sharding-jdbc作為一個組件集成在應用內,而mycat則作為一個獨立的應用需要單獨部署,drds則是阿里雲的一個獨立產品,不過需要結合rds一起使用。
4)sharding-jdbc
優點:1.理論性能最高。從架構上看sharding-jdbc更符合分佈式架構的設計,直連數據庫,沒有中間應用,理論性能是最高的(實際性能需要結合具體的代碼實現,理論性能可以理解為上限,通過不斷優化代碼實現,逐漸接近理論性能)。
缺點:1.開發成本相對較高。由於作為組件存在,需要集成在應用內,意味着作為使用方,必須要集成到代碼裏,使得開發成本相對較高;2.開發場景限定為Java。由於需要集成在應用內,使得需要針對不同語言有不同的實現,事實上sharding-jdbc目前只支持java,這樣組件本身的維護成本也會很高。
5)mycat
mycat是支持SQL92標準,遵守Mysql原生協議,跨語言,跨平台,跨數據庫的通用中間件代理。
優點:作為對比可以參考上表中的Sharding-Proxy,需要單獨部署,由於遵守Mysql原生協議,應用時不需要特殊處理,和使用MySQL是一樣的,所以應用場景不受限制;
缺點:需要維護自身的連接池。但是mycat不支持二維路由,僅支持單庫多表或多庫單表,同時由於自定義連接池,這樣就會存在mycat自身維護一個連接池,MySQL也有一個連接池,任何一個連接池上限都會成為性能的瓶頸,而mycat的連接池設計也略顯粗暴,當請求鏈接數大於設置連接池上限時直接拋出異常,因此在配置mycat連接池的大小是,需要結合場景做合理設置。
總的來説,mycat以邏輯表的形式屏蔽掉應用處理分庫分表的複雜邏輯,遵守Mysql原生協議,跨語言,跨平台,有着更為通用的應用場景。
6)DRDS
DRDS 兼容 MySQL 協議和語法,支持分庫分表、平滑擴容、服務升降配、透明讀寫分離和分佈式事務等特性,具備分佈式數據庫全生命週期的運維管控能力。
可以看成mycat的商業化產品,也就是mycat所有的優點它都有,而且作為一個商業化產品使用上更為簡單透明,功能也更為豐富;如果不差錢而且正準備對數據做重構,那麼drds是一個不錯的選擇,之所以説準備做數據重構時考慮用drds,是因為drds不是一個簡單的做sharding路由,即使原來使用的是rds,也無法通過drds做路由,唯一的辦法新建drds實例,定義路由規則(drds支持二維路由),導入歷史數據,然後就可以開心的使用drds了。
|
|
sharding-jdbc |
mycat |
drds |
|
性能 |
高 |
中 |
高 |
|
應用場景限制 |
java應用 |
無 |
無 |
|
是否支持自定義sharding路由 |
是 |
是 |
是 |
|
最大支持sharding路由維度 |
2 |
1 |
2 |
|
分佈式事務 |
支持 |
支持弱xa、支持XA分佈式事務(1.6.5) |
支持以下分佈式事務策略:FREE、2PC、XA、FLEXIBLE |
|
是否開源 |
是 |
是 |
否 |
7.sharding-jdbc詳細實現