
在材料科學領域,金屬有機框架(Metal–Organic Frameworks,MOFs)堪稱科學家們的「瑞士軍刀」:它們具有高比表面積、化學可調性和結構多樣性,在氣體分離與儲存、催化以及傳感等領域具有廣泛應用。然而,對於科研人員而言,MOF 的世界極其龐大且複雜——目前已有超過 12.5 萬種 MOF 框架被合成,並計算預測了數百萬種可能的結構。
雖然人工智能(AI)已經深刻改變了 MOFs 研究領域,但大多數現有方法仍然範圍有限,主要關注單一性能的提取或不易擴展的靜態數據集。 即使是大規模文本挖掘數據集,也更強調從文獻中提取性能,而非與晶體結構建立穩健的關聯。實現這種統一的一個主要障礙是缺乏標準化命名約定——例如,同一化合物在文獻中可能被稱為 「HKUST-1」,在某篇文章中標記為「Compound 1」,而在劍橋結構數據庫(CSD)中被登記為「FIQCEN」。這種不一致不僅存在於 MOFs,而是普遍存在於材料科學領域,使人類和大語言模型(LLM)在跨來源匹配數據時面臨困難。
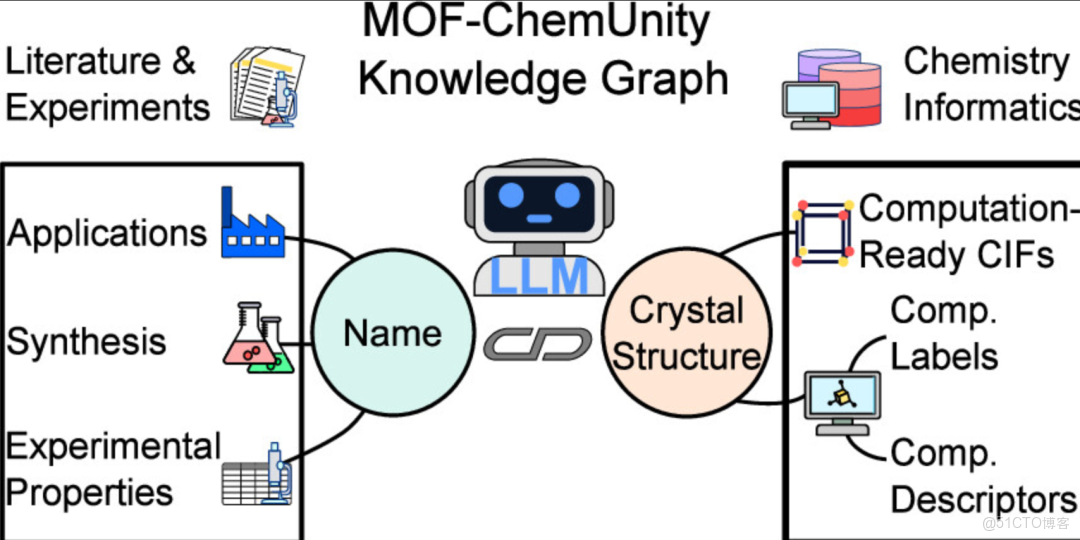
以此為背景下,來自加拿大多倫多大學以及加拿大國家研究委員會清潔能源創新研究中心的研究團隊提出 MOF-ChemUnity:一個結構化、可擴展、可拓展的知識圖譜。 該方法利用 LLM 在文獻中 MOF 名稱及其同指代與 CSD 中登記的晶體結構之間建立可靠的一一映射,從而實現 MOF 名稱及其同義詞與晶體結構的消歧。在當前版本中,MOF-ChemUnity 集成了約 1 萬篇科學文章以及超過 1.5 萬條 CSD 晶體結構及其計算化學性質,以機器可操作的格式呈現。當作為知識源增強 LLM 時,MOF-ChemUnity 使得 AI 助手能夠基於完整文獻知識開展推理。專家評估顯示,在檢索、結構–性能關係推斷、材料推薦等任務中,其準確性、可解釋性與可信度均優於標準 LLM。
相關研究成果以「MOF-ChemUnity: Literature-Informed Large Language Models for Metal–Organic Framework Research」為題,已刊登 ACS Publications。
研究亮點:
-
MOF-ChemUnity 通過識別並將所有指代和名稱鏈接到單一材料實體,實現了跨出版物的信息整合和分析。
-
這一結構允許研究者提出高層次科學問題,並使 AI 模型能夠在有事實依據和可解釋的基礎上對 MOF 化學空間進行推理,從而開啓超越單篇閲讀或手動數據收集的新型文獻交互方式。
-
對於面臨與 MOF 類似問題的領域,如缺乏標準命名規範與數據異質性,MOF-ChemUnity 提供了統一信息的有力藍圖。

論文地址:
https://pubs.acs.org/doi/10.1021/jacs.5c11789
關注公眾號,後台回覆「MOF-ChemUnit」獲取完整 PDF
更多 AI 前沿論文:
https://hyper.ai/papers
數據集:提供全面的數據視角
MOF-ChemUnity 的數據基礎來源於兩個主要數據庫:CoRE MOF 2019 和 QMOF,總計超過 31,000 個獨特晶體結構。 為了確保數據可靠,研究團隊僅保留了帶有氣體吸附或能帶信息的條目,並且必須擁有 CSD(Cambridge Structural Database)參考代碼,以便追蹤到原始文獻。
通過文本挖掘與數據挖掘(TDM)方法,研究人員從多個出版商獲取全文,包括 ACS、Elsevier、RSC 等。無論是 XML 還是 PDF 格式的文獻,都被轉換為統一的 Markdown 文件,確保後續 AI 模型可以高效處理。
應用匹配工作流程後,該團隊成功解析並關聯了 93% 的 MOF 晶體結構,即 15,143 個晶體結構,與 9,874 篇文獻中的名稱及同指代信息建立了對應關係。更為關鍵的是,研究團隊不僅匹配了 MOF 名稱與晶體結構,還識別了文獻中的指代信息(如「Compound 1」指代特定 MOF),確保每個 MOF 實體在知識圖中形成一一對應的條目,為後續的模型訓練和信息提取打下了堅實基礎。
在此基礎上,研究團隊還將 MOF 的實驗性質、合成路線及推薦應用提取出來,形成了一個包含 70,000 多條性質數據和 2,500 多條應用建議的結構化寶庫,為科學家提供了全面的數據視角。
ChemUnity:結構化、可擴展、可拓展的知識圖譜
在 MOF-ChemUnity 中,核心是一個由 LLM 匹配與提取代理和知識圖譜組成的模型框架:
LLM 匹配代理
工作流的第一部分旨在解決 MOF 的命名實體識別、指代消解和唯一實體關聯問題。 研究人員的解決方案是向 LLM 提供晶體結構衍生信息,將論文中的 MOF 名稱與對應的 CSD 參考代碼匹配。這些信息包括 CSD 參考代碼、晶格參數、金屬節點、空間羣、分子式、化學名稱及已知同義詞,均通過 CSD Python API 獲取。LLM 被指令查找論文中哪些唯一 MOF 名稱對應給定的 CSD 參考代碼,從而確保每篇論文中的 CSD 參考代碼與 MOF 名稱一一對應。LLM 還需查找與該 MOF 相關的所有指代。通過將 MOF 名稱匹配和指代消解任務分離,能夠對每一步進行精細化準確性評估,為後續信息提取提供可靠基礎。如下圖所示:
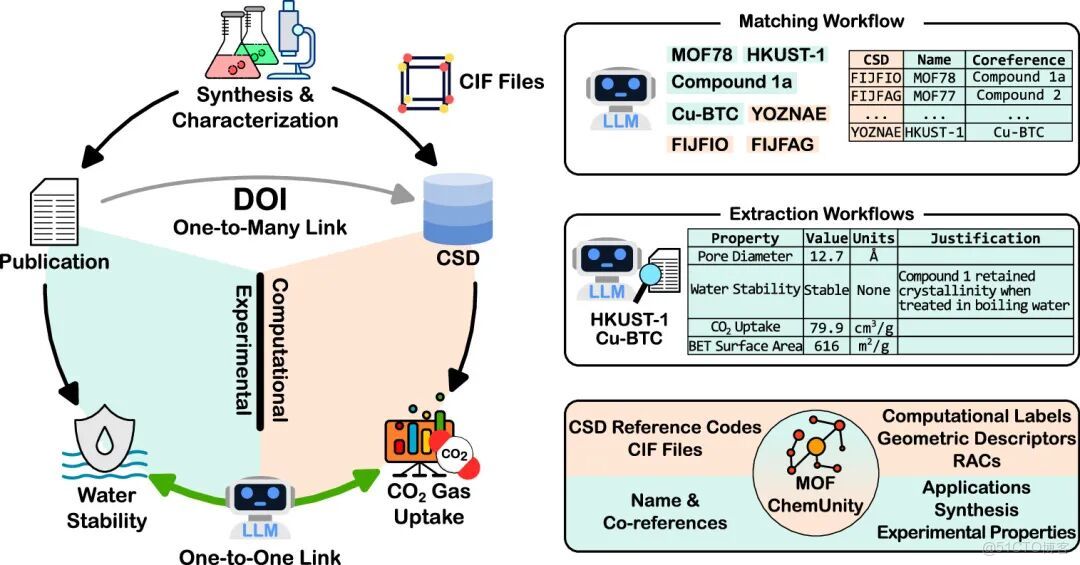
::: hljs-center
用於匹配和提取 MOF 數據的 LLM 代理
:::
信息提取工作流
通用工作流: 由匹配工作流提取的 MOF 名稱用於信息提取集成;在該集成中,多個工作流接收 MOF 名稱並提取與其相關的不同信息,如性質、推薦應用和合成信息。
專用工作流: 針對複雜性質(如水穩定性),採用驗證鏈(Chain of Verification, CoV)方法,確保提取結果可靠,減少 AI 「幻覺」產生。
知識圖譜 MOF-ChemUnity 構建
在設計 MOF-ChemUnity 時,研究人員聚焦於 3 個關鍵目標:可擴展性、可關聯性和可查詢性。
首先,知識圖譜必須可擴展且可追加,能夠隨着文獻和計算數據庫的增長無縫整合新數據;其次,它必須支持跨文檔實體解析,確保對同一化合物的多重引用,無論來自不同論文、命名方式還是數據庫,都能準確關聯;第三,它應支持局部和全局查詢,既能進行精細查詢(如單一 MOF 的合成條件),也能進行更廣泛的分析(如跨應用領域識別結構–性質趨勢)。
為實現這些目標,研究團隊設計了具有獨特節點類型和關係類型的模式。 每個 MOF 被表示為一個 MOF 節點,出版物、合成步驟、性質和應用提及被建模為獨立節點,並通過語義關係連接。生成的知識圖譜包含超過 40,000 個節點和 3,200,000 條關係。完整模式、完整知識圖譜以及單個 MOF 子圖如下圖所示:
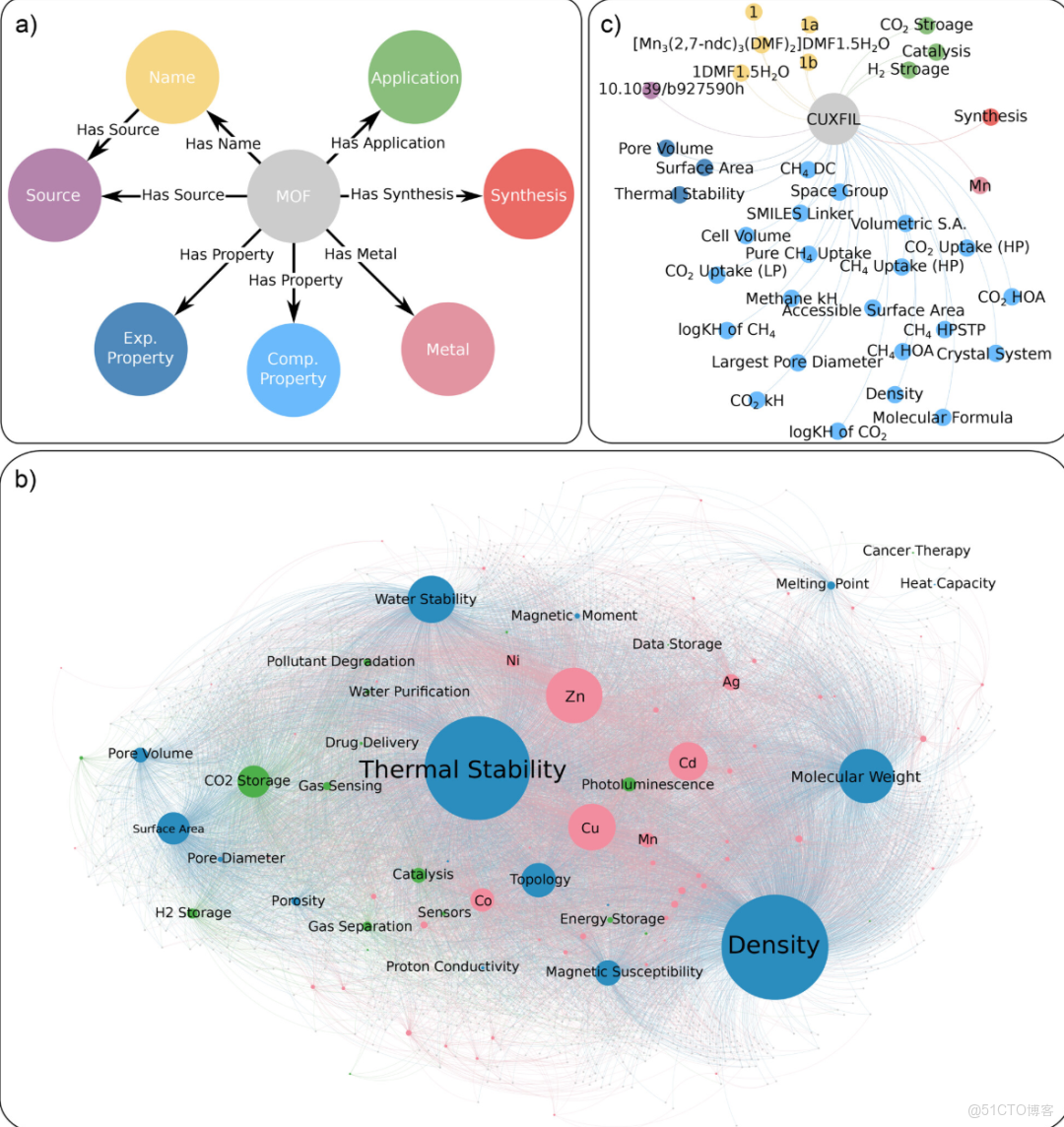
::: hljs-center
通過知識圖譜構建異構 MOF 數據
:::
圖增強檢索增強生成(Graph-Enhanced RAG)
圖增強 RAG 系統檢索相關信息,並將其作為少樣本上下文用於通用問答。該框架還結合基於機器學習的嵌入來識別結構或化學上相似的 MOF,從而支持更有信息量的問答。核心組件——查詢工具(Query)和鄰近查找工具(Neighbor Finder)——是模塊化的,可根據 AI 代理需要調用。
MOF 推薦與嵌入空間
使用化學與幾何描述符(RAC、孔體積、孔徑等),將 MOF 投影到低維嵌入空間,通過最近鄰方法推薦相似材料。可用於氣體吸附、碳捕集等應用場景,將人工經驗轉化為可機器學習的規則。
成果展示:科學家和 AI 系統都能充分利用 MOF 的完整知識
通過上述框架,研究團隊開展了系統驗證與應用演示:
水穩定性預測
利用 MOF-ChemUnity 的水穩定性數據集,研究人員訓練了一個分類器模型,在水穩定性預測中表現優異,準確率達到 80%,F1 分數為 86%(見下圖)。更重要的是,由於 MOF-ChemUnity 還包含來自分子模擬的 CO₂ 吸附數據,研究人員可以進行聯合篩選,識別同時滿足這兩個標準的材料。
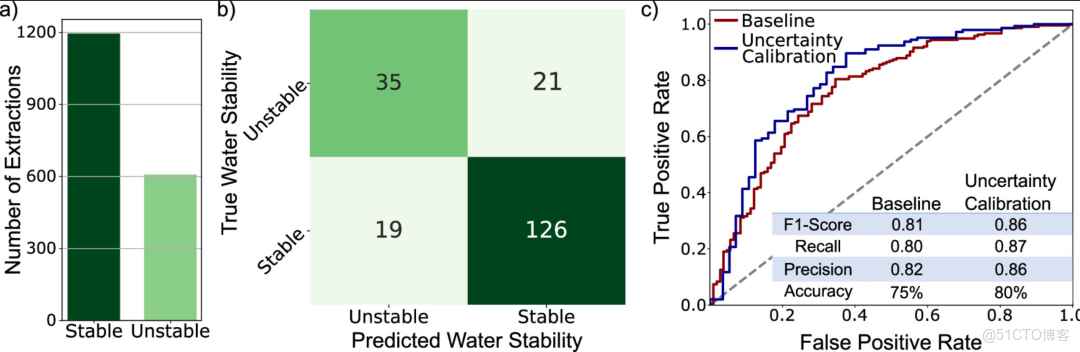
::: hljs-center
利用機器學習預測 MOF 的水穩定性
:::
專家推薦驗證
專家通常會基於直覺、經驗或領域知識,將其 MOF 推薦用於特定應用。儘管這些信息本身非常有價值,但往往難以形式化或系統化使用。為解決這一問題,研究人員利用 MOF-ChemUnity 中專家推薦與晶體結構之間的關聯,將 MOF 嵌入到結構感知的化學空間。
研究人員評估了該方法在兩個具有計算屬性數據的應用上的有效性:甲烷存儲和二氧化碳捕集。如下圖所示,在這兩類應用中,這些鄰近 MOF(標記為模型推薦)表現出與專家推薦材料相似的性能。這表明,當專家直覺映射到結構空間後,機器學習模型能夠學習其直覺並結合實驗數據進行預測。
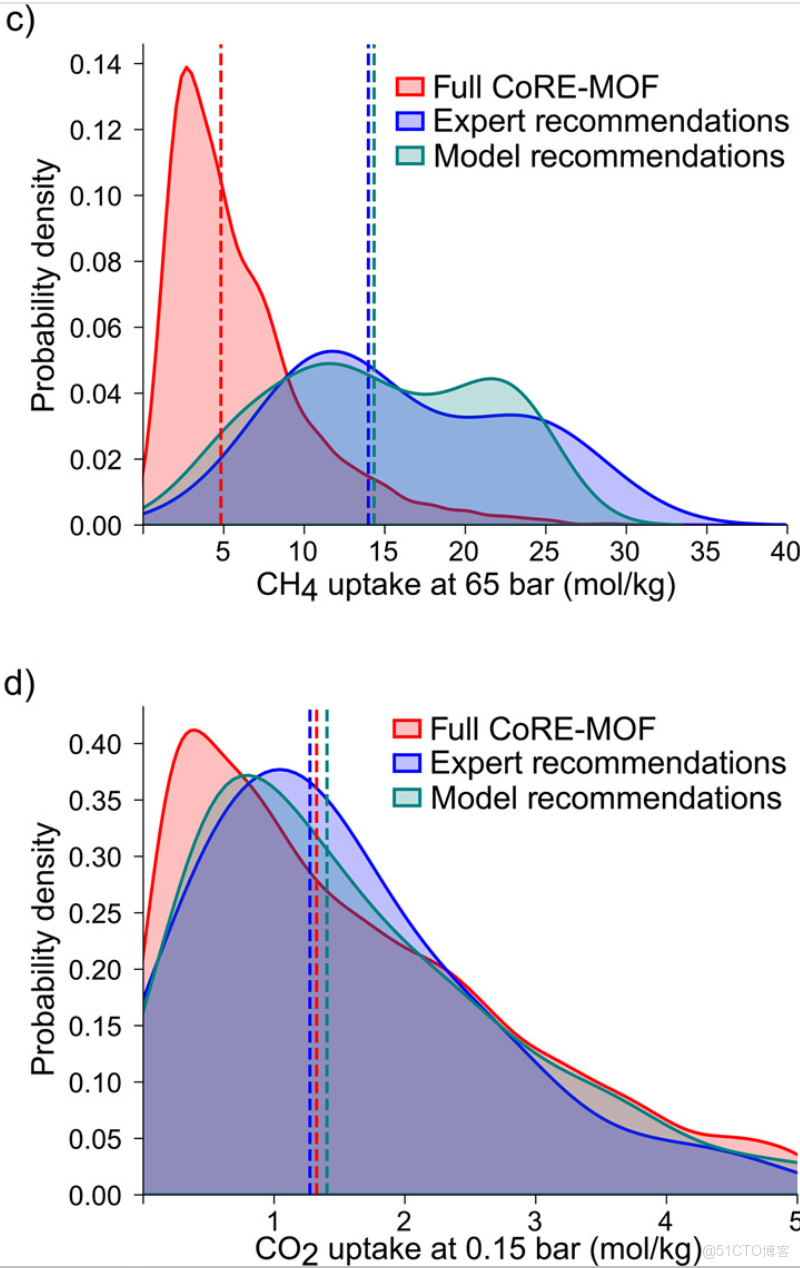
::: hljs-center
CoRE MOF 2019 數據庫中所有材料的甲烷和二氧化碳吸收分佈
:::
評估專家推薦的強度和特異性同樣具有啓發意義。為此,研究人員還將專家推薦 MOF 的性能分佈與其鄰近材料以及從整個數據庫中隨機抽樣的材料進行比較。對於甲烷存儲,專家推薦及其鄰近 MOF 的平均 CH4 吸附量明顯高於整個數據集的平均值,説明專家有效地選擇了甲烷存儲性能優異的材料。這與之前的研究一致,即甲烷存儲主要受直觀幾何屬性(如空隙率和壓力擺動工況下的有效容量)影響。
相比之下,對於二氧化碳捕集,專家推薦 MOF 的性能分佈與隨機樣本相似,表明在這一領域,專家直覺的可靠性較低。
文獻 AI 助手應用
Banerjee 等人合成了一種基於鋰的 MOF,稱為超輕 MOF(ULMOF-5),並在論文中將其稱作「Compound 1」。 當使用標準 LLM 查詢 ULMOF-5 的水穩定性時,模型會給出「幻覺」回答,將其與名稱相似但無關的 Zn 基 MOF-5 混淆。相比之下,MOF-ChemUnity 將所有指代與正確的晶體結構關聯,並捕捉到論文中句子「compound 1 is soluble in water」所表明的水穩定性標籤(「不穩定」)。本研究提出的系統能夠檢索此信息,並提供帶有引用和解釋的、事實依據充分的答案,從而提升準確性和透明度。
為了進一步評估系統,研究人員還在三個任務上對比了圖增強 RAG 和原始 LLM(GPT-4o)的回答:事實檢索、結構–性質推斷和材料推薦。九位 MOF 專家在盲測調查中評估了回答的質量和可信度。下圖 c 顯示,圖增強助手在所有任務中評分更高。專家特別重視其引用文獻、具體示例和可驗證的論斷,而基線模型的回答常常泛泛、不具依據或無法驗證。這表明,將結構化科學知識整合到 LLM 中可提升事實可靠性和用户信任。
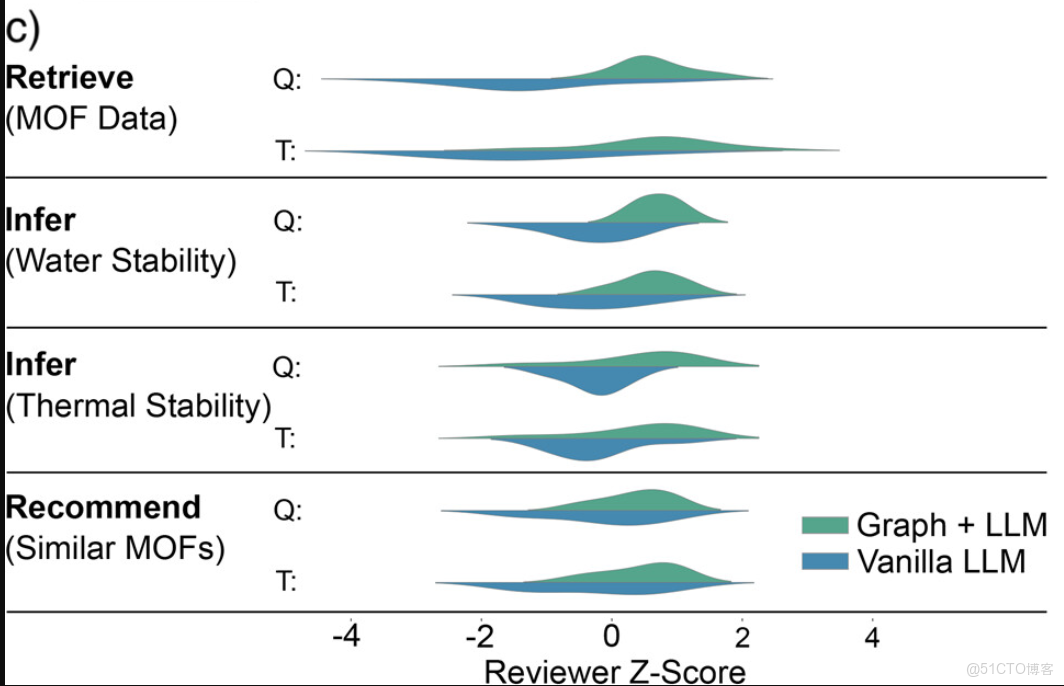
::: hljs-center
基於知識圖譜的 RAG 作為文獻信息 AI 助手
:::
MOF-ChemUnity 可擴展至其他材料類別
MOF-ChemUnity 的意義遠超現有 MOF 數據整合,它為材料科學研究提供了一種跨領域、可擴展的數據管理和分析範式。近年來,隨着共價有機框架、沸石、聚合物及多孔材料研究的快速發展,各類材料數據呈現高度異質性、命名不統一的問題,這使得跨文獻、跨數據庫的信息整合成為制約科學發現的瓶頸。在這一背景下,MOF-ChemUnity 所建立的知識圖譜框架為這些材料類別提供了可借鑑的藍圖:通過統一實體解析、核心關係標註及屬性抽取的方法,即便在缺乏標準化命名或數據格式差異較大的領域,也能夠實現不同來源數據的有效關聯和系統化管理。
業界也有許多團隊在推進與之具有類似意義的工作。 比如,大量的材料學術文獻積累了豐富的科學成果,以文本形式散佈在文獻中的科學知識一般仍由研究人員手動收集和分析,這通常十分耗時且難以保證信息的完整度。如果將文獻中的材料科學信息表示為結構化的知識,再結合知識關聯、融合、推理等方法,構建材料知識圖譜,可以使研究人員準確而又高效地獲取信息。
北京大學深圳研究生院新材料學院潘鋒教授課題組近年來致力於構建材料知識圖譜以及解決其關鍵科學問題和技術難題,發展了一套高精度且高效的同名消歧以及信息搜索框架,構建了名為 MatKG 的材料知識圖譜。在此基礎上,2022 年,該課題組提出了一種可實現材料科學知識嵌入的語義表示框架,通過多源信息融合提高材料實體的表示質量以對材料科學文獻中的鋰離子電池正極材料實體進行精準挖掘並構建正極材料知識圖譜,預測高性能鋰電池材料。
論文標題: Automating Materials Exploration with a Semantic Knowledge Graph for Li-ion Battery Cathodes
論文地址: https://advanced.onlinelibrary.wiley.com/doi/abs/10.1002/adfm.202201437
另一方面,隨着 IUPAC Adsorption Information File (AIF) 等標準化格式的提出,MOF-ChemUnity 的設計允許新標準的無縫接入,實現數據的統一、可追溯與可解釋。通過這種方式,未來無論是新的文獻報道還是計算模擬數據,都可以輕鬆納入系統,實現數據集的持續擴展和迭代更新。這種可持續更新能力為高通量、多目標材料篩選提供了堅實基礎,也順應了當前材料基因組計劃和 FAIR 數據原則的趨勢,為科研人員提供了可重複、可驗證的分析框架。
未來,MOF-ChemUnity 的潛力還體現在其作為科學助手的能力。通過自然語言交互和圖查詢工具,科研人員能夠提出複雜問題,如「在水環境中適用於污染物去除的 MOF 中,哪些兼具高穩定性和特定金屬節點?」,系統即可提供基於文獻、實驗與計算數據的可驗證答案。這種融合了知識圖和 LLM 的方法,為材料科學研究中的 AI 應用樹立了新標杆。
參考文獻:
1. https://pubs.acs.org/doi/10.1021/jacs.5c11789
2. https://advanced.onlinelibrary.wiley.com/doi/abs/10.1002/adfm.202201437
3. https://news.pku.edu.cn/jxky/64f28e5b50074113bfaec41af68c1971.htm







