你説的“司南”指的是 OpenCompass 司南大模型評測平台,由 上海人工智能實驗室(Shanghai AI Lab) 推出,是一個面向大語言模型(LLM)和多模態模型的 權威評測與對比平台,核心功能包括:
✅ 核心定位
“大模型的競技場” —— 讓模型匿名對戰,用户投票選出更優回答,最終形成 動態更新的 leaderboard(排行榜),解決“誰更強”這個終極問題。
✅ 主要功能模塊
模塊 説明
LLM Arena 匿名雙盲對戰,用户提問後兩個模型同時回答,投票選出更好的一方,防止“刷分”或“品牌偏見”。
多模態 Arena 支持圖文混合輸入,評測多模態模型(如 Qwen-VL、InternVL、GPT-4V 等)。
任務模式 提供專項任務評測(如數學、代碼、邏輯推理、中文理解等),可定向測試模型能力。
Compass Rank 基於真實用户投票+客觀指標,定期發佈排行榜,是目前中文社區最可信的模型榜單之一。
模型身份揭曉 投票結束後可查看模型真身,幫助開發者瞭解“到底誰輸給了誰”。
---
✅ 技術亮點
- 匿名機制:防止“品牌光環”干擾判斷,確保投票真實反映模型能力。
- 中文優化:大量中文主觀題、文化題、時政題,彌補英文 benchmark 的盲區。
- 用户參與:任何人都能來“當裁判”,投票數據實時迴流,榜單動態更新。
- 開源開放:評測框架 OpenCompass 已開源,支持開發者自定義數據集和任務。
適合誰用?
用户類型 用途
普通用户 想直觀感受不同模型誰更“聰明”,比如 GPT-4o、Kimi、Qwen、Claude 到底差在哪。
開發者/企業 選型前先來“打擂台”,避免“宣傳文案”誤導,用真實表現説話。
研究機構 用匿名投票數據做主觀評測研究,補充傳統客觀指標的不足。
---
✅ 一句話總結
OpenCompass 司南 是中文社區最活躍、最公正的大模型“實戰擂台”,讓模型在匿名狀態下真刀真槍地比拼,用用户投票告訴你:
> 別信廣告,信對戰。
---
如果你想親自體驗,直接訪問:
司南
進去隨便問個問題,就能開始“當裁判”了。
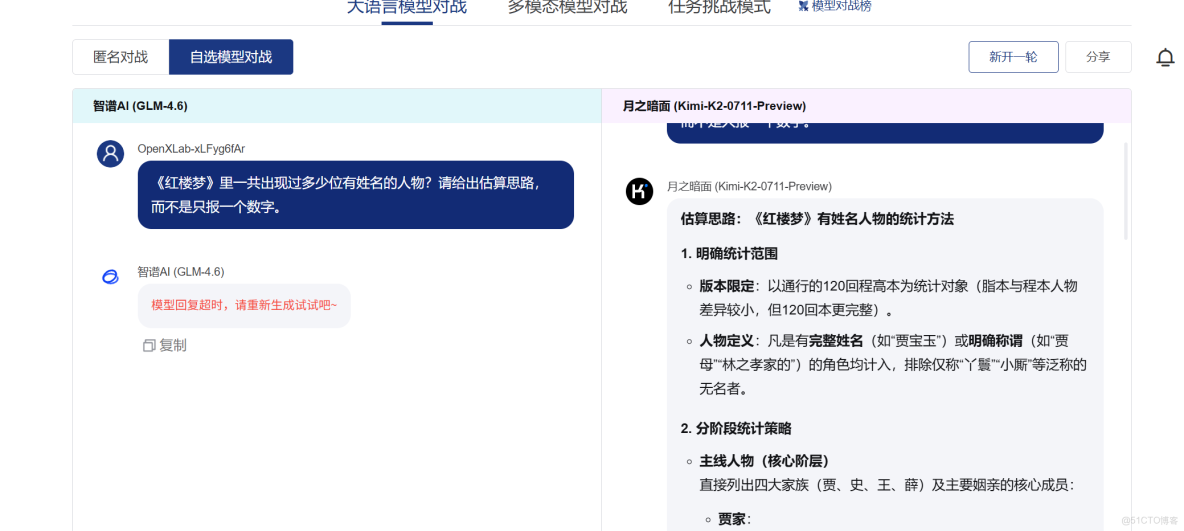
問題1:《紅樓夢》裏一共出現過多少位有姓名的人物?請給出估算思路,而不是隻報一個數字。
問題2:請幫我寫一份將yolov8部署到rk3588開發板上的推理代碼,用c++
問題3:用一句話解釋‘量子隧穿’,再用一個日常類比讓初一學生聽懂;最後指出類比在哪個點上其實不嚴謹。

問題4:2024 年 7 月 11 日央行下調常備借貸便利(SLF)利率 10 bp,請推鏈條:這一步如何影響中小銀行負債成本→LPR→居民房貸?給出每環節大致傳導時滯。

問題5:求 2¹⁰⁰⁰ mod 10007 的精確值,並説明如果模數換成 10007²,你的算法要怎麼升級。
問題6:一副 52 張撲克洗勻後,前 13 張裏‘恰有兩條’(exactly one pair,其餘 11 張不成對且不成三條以上)的概率是多少?給出含階乘的閉式即可,不必化簡小數。”
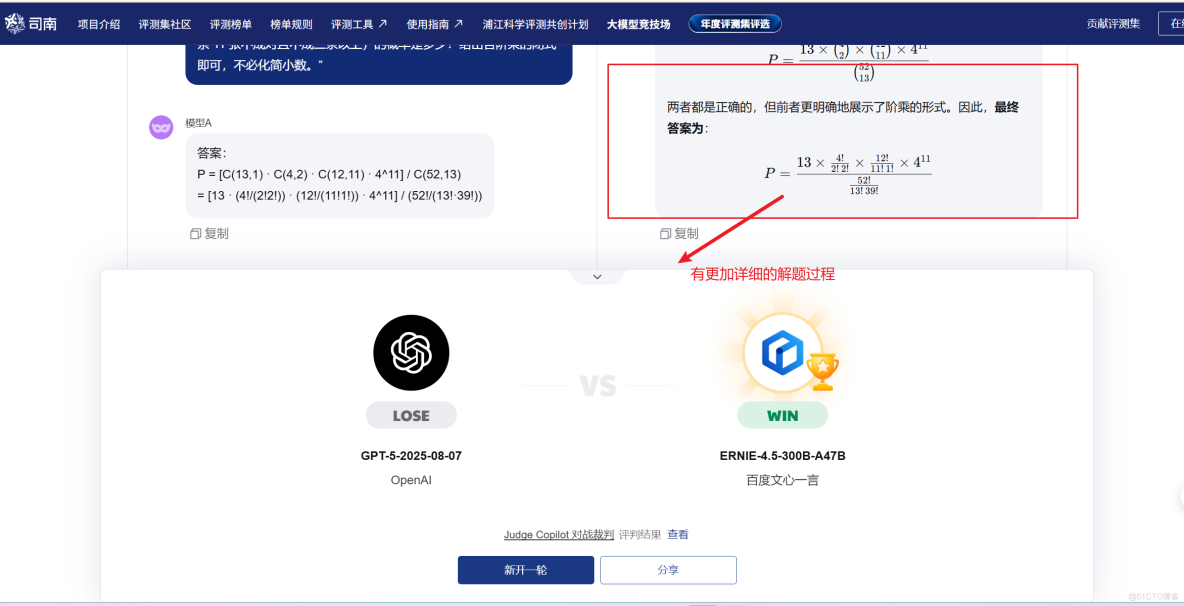
問題7:
問題8:
問題9:
問題10: