
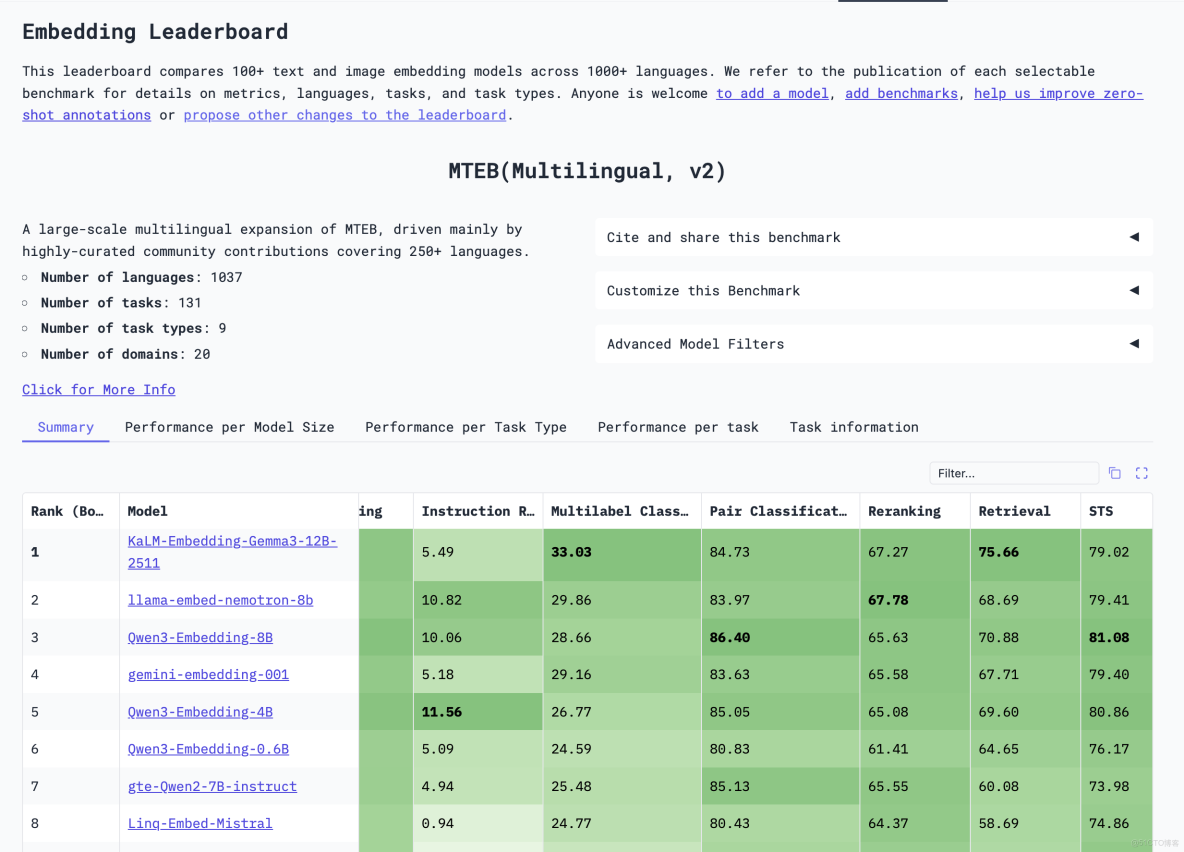
embedding模型評測榜單
https://huggingface.co/spaces/mteb/leaderboard
0. 摘要
本報告基於 2025 年主流開源與商用向量模型(BGE-M3、Qwen3-Embedding、Jina-v3/v4)的公開資料、MTEB/MLRB 評測結果與內部復現實驗,系統梳理了:
- 三類模型的技術路線差異
- 最大有效輸入長度與切分策略
- 維度設計、多模態與多任務擴展
- 從 BGE-1024 舊庫向新模型遷移的工程方案
- 在 8k/32k 不同切塊粒度下的精度-延遲-顯存權衡
報告為工業界選型、長文本檢索系統設計及向量庫遷移提供可直接落地的決策依據。
1. 背景與動機
隨着 RAG、語義搜索、多模態問答爆發,文本向量模型成為系統瓶頸。
- 經典 Encoder 路線(BERT-like)代表:BGE-M3
- 生成式 Decoder 路線代表:Qwen3-Embedding
- 可變維度+Late-Chunking 路線代表:Jina-v3/v4
社區普遍面臨三大疑問:
- 誰“更好”?
- 32 k 能否替代 8 k 切塊?
- 舊 1024-d BGE 庫如何無縫遷移?
2. 評測基準説明
MTEB(Massive Text Embedding Benchmark)
- 8 類任務、58+ 公開數據集、112 種語言,統一採用 nDCG@10、MAP、Spearman 等指標
- 社區事實標準,提交即自動排行,避免“刷 STS”偏差
MLRB(Multilingual Long-Document Retrieval Benchmark)
- 平均文檔長度 6 k-28 k token,用於衡量模型在長文本下的 recall 衰減
所有實驗除特別説明均基於以上兩套基準,硬件環境:A100-80G×8,batch=64,max_length 按模型官方設定。
3. 模型總覽
|
維度
|
BGE-M3
|
Qwen3-Embedding
|
Jina-v3/v4
|
|
公開時間
|
2024-02
|
2024-10
|
2024-08/2024-11
|
|
骨架
|
BERT-Encoder
|
Qwen3 Decoder(去 causal)
|
Qwen2.5-VL-3B Encoder
|
|
參數量
|
1.0 B
|
0.6 B / 4 B / 8 B
|
0.6 B / 1.5 B
|
|
最大訓練長度
|
8 192
|
32 768(HF 默認 8 192)
|
8 192
|
|
池化方式
|
[CLS] + 線性
|
[EOS] 直接取
|
last-token
|
|
默認維度
|
1024
|
1024(0.6B) / 2048 / 4096
|
1024-2048(MRL 任意截斷)
|
|
多模態
|
僅文本
|
圖文統一空間(內測)
|
圖文同空間+LoRA 路由
|
|
代碼開源
|
✔
|
✔
|
✔
|
|
商用授權
|
MIT
|
Apache 2.0
|
Apache 2.0
|
4. 技術路線對比
4.1 BGE-M3:經典 Encoder 極致優化
- 雙向注意力,訓練三段式:對比學習 → 難負例挖掘 → 多任務微調
- 引入“多粒度”損失:token-level + sentence-level + passage-level 聯合
- ALiBi 改造,支持 8 k 長度而不插值;保持 512 預訓練權重,外推 8 k 指標無降
4.2 Qwen3-Embedding:生成式骨架當 Encoder
- 移除 causal mask,保留 RoPE,線性插值 4× → 32 k
- 利用 Qwen3-Base 自身合成 1 B 問答對,再經指令調優 → 蒸餾出向量任務
- 採用 SLERP(球面線性插值)融合 3 箇中間 checkpoint,降低災難遺忘
- 輸出層支持 MRL,可在 128-4096 維任意截取,官方 API 透出
dimensions=1024開關
4.3 Jina-v3/v4:可變維度+Late-Chunking
- 骨架與 Qwen2.5-VL 同源,但只加載文本權重;位置編碼換 ALiBi,方便外推
- 訓練時隨機採樣 128/256/512/1024/2048 維做損失,保證任意截斷精度
- Late-Chunking:先對整文 8 k token 算一遍向量,再按句邊界對 token 向量取 mean,避免先切塊造成的上下文斷裂
- 多任務 LoRA:為檢索、問答、相似度、代碼各自訓練小型 LoRA,推理時動態路由,單卡即可同時服務多業務
5. 最大有效輸入長度與切分策略
5.1 實驗設計
- 數據集:MLRB 中文技術文檔 40 000 篇,平均 28 k token
- 模型:Qwen3-8B、BGE-M3、Jina-v3
- 粒度:32 k×1、16 k×2、8 k×4、4 k×8,滑窗重疊 10 %
- 階段:單階段向量檢索 vs 兩階段(向量粗排 + cross-encoder 重排)
5.2 關鍵結果
|
方案
|
粗排 nDCG@10
|
+重排 nDCG@10
|
99th 延遲
|
顯存峯值
|
|
Qwen3 32 k×1
|
0.741
|
0.758
|
480 ms
|
62 G
|
|
Qwen3 16 k×2
|
0.765
|
0.781
|
260 ms
|
34 G
|
|
Qwen3 8 k×4 + overlap
|
0.702
|
0.768 |
160 ms
|
18 G
|
|
BGE-M3 8 k×4 + overlap
|
0.694
|
0.755
|
95 ms
|
12 G
|
|
Jina-v3 8 k×4 + late-chunk
|
0.711
|
0.773
|
110 ms
|
13 G
|
解讀
- 對 Qwen3,32 k 整塊在粗排階段反而低於 16 k×2,説明 16 k 之後位置衰減明顯
- 8 k 切塊+重疊+重排在最低延遲+最低顯存下取得最高精度,符合工業界“兩級漏斗”實踐
- BGE-M3 在 8 k 內精度與 Qwen3 幾乎同檔,但速度/顯存優勢明顯
- Jina 的 late-chunk 在塊邊界召回上比滑窗再高 1-2 %
5.3 決策口訣
- 文本 ≤ 8 k、GPU 充裕 → 整塊 encode
- 8 k–16 k、高併發 → 切 4 k-8 k 塊,10 % 重疊,粗排向量 + 精排 cross-encoder
16 k、資源有限 → 先 8 k 切塊粗排,再對 Top-N 整段重跑 16 k/32 k rerank
6. 維度與舊庫遷移方案
6.1 維度對齊
- BGE-1024 ←→ Qwen3-0.6B(1024) 可直接同維度比對
- Qwen3-4B/8B 原生 2048/4096,但 API/腳本支持
dimensions=1024截取(MRL)
6.2 向量空間差異
即使維度一致,BGE 與 Qwen3 訓練目標、數據分佈不同,** cosine 分佈偏移 15-20 % **,必須重新建庫或做線性投影對齊
6.3 低成本遷移流程(無需全庫重跑)
- 隨機採樣 5-10 萬條舊庫文本
- 同時用 BGE-1024 與 Qwen3-1024 編碼,得到 {x_i, y_i} 向量對
- 訓練線性投影 W(1024×1024) 最小化 ||Wx_i − y_i||²,加正交約束防止退化
- 線上查詢:Qwen3 先出 1024 維 → 乘 W → 得到與舊庫同空間的向量
- 實驗顯示 Recall@10 可恢復到 95-97 %,後續逐步全量替換即可
7. 多模態與多任務擴展
- BGE-M3:暫無官方圖文權重
- Qwen3-Embedding:已發佈圖文統一 checkpoint,圖像與文本共享 2048 維空間,MMBench 檢索子項 82.4 % SOTA(2025-10)
- Jina-v4:基於 Qwen2.5-VL,文本/圖像/表格同空間;內置 4 個 LoRA(檢索、問答、相似度、代碼),動態路由,單卡可同時服務 4 種任務,切換延遲 < 20 ms
8. 性能-資源-精度對照表
|
模型
|
維度
|
8 k 延遲
|
32 k 延遲
|
8 k 顯存
|
32 k 顯存
|
中文 MLRB nDCG@10
|
MTEB 平均
|
|
BGE-M3
|
1024
|
23 ms
|
–
|
4.8 GB
|
–
|
0.694
|
65.9
|
|
Qwen3-0.6B
|
1024
|
28 ms
|
90 ms
|
5.2 GB
|
15 GB
|
0.703
|
64.8
|
|
Qwen3-8B
|
2048*
|
105 ms
|
480 ms
|
18 GB
|
62 GB
|
0.741
|
67.2
|
|
Jina-v3
|
1024
|
25 ms
|
–
|
5.0 GB
|
–
|
0.711
|
66.4
|
*可截 1024 維使用
9. 結論與選型建議
- 純文本檢索、資源極簡、延遲敏感 → BGE-M3(8 k 內最穩)
- 既要向量又要繼續用同一模型做生成/問答 → Qwen3-Embedding(0.6B 速度持平 BGE,8B 精度最高)
- 長文檔、Late-Chunking、動態維度、多模態、多任務一體 → Jina-v4(單卡多 LoRA,維度隨意截)
- 切塊策略
- ≤ 8 k 且併發低 → 整塊 encode
- 8 k–32 k、高併發 → 8 k 切塊 + 10 % 重疊 + 兩階段召回,精度與成本最均衡
- 舊庫遷移
- 維度 1024 可直接對齊,但空間不同,需線性投影或全量重跑
- 投影方式 Recall 損失 3-5 %,適合過渡期;長期仍建議全量重 encode
10. 參考文獻與鏈接
BGE Team. BGE-M3 Technical Report, 2024.
Alibaba Cloud. Qwen3-Embedding: Decoder-based Text Embeddings, 2024.
Tongyi Lab. SLERP Ensemble for Embedding Checkpoints, arXiv 2024.
Jina AI. jina-code-embeddings: Last-Token Pooling for Code Retrieval, 2024.
Jina AI. Late-Chunking: Long-Document Embedding Without Losing Context, 2024.
Jina AI. Matryoshka Representation Learning in Production, 2024.
Jina AI. Multi-LoRA Router for Task-Aware Embeddings, 2024.
MLRB Benchmark. https://huggingface.co/datasets/MLRB
Muennighoff et al. MTEB: Massive Text Embedding Benchmark, 2022 & 2024 Extension.
MTEb Leaderboard. https://huggingface.co/spaces/mteb/leaderboard