

0. 簡介
深度學習中做量化提升運行速度是最常用的方法,尤其是大模型這類非常吃GPU顯存的方法。一般是高精度浮點數表示的網絡權值以及激活值用低精度(例如8比特定點)來近似表示達到模型輕量化,加速深度學習模型推理,目前8比特推理已經比較成熟。比如int8量化,就是讓原來32bit存儲的數字映射到8bit存儲。int8範圍是[-128,127], uint8範圍是[0,255]。
使用低精度的模型推理的優點:1. 模型存儲主要是每個層的權值,量化後模型佔用空間小,32比特可以縮減至8比特,並且激活值用8比特後,減小了內存的訪問帶寬需求。2:單位時間內處理定點運算指令比浮點數運算指令多。
1. 量化分類
一般按照量化階段不同分為後量化和訓練時量化,用的比較多的是後量化,像tensorRT和RKNN按照量化映射方法又可以分為對稱量化和非對稱量化。
1.1 非對稱量化(uint8 0-256)
非對稱量化需要一個偏移量Z來完成零點的映射,即量化前的零點和量化後的零點不一致。非對稱量化的一般公式為:
S=rmax−rminqmax−qminS=qmax−qminrmax−rmin
Z=qmax−Round(rmaxS)Z=qmax−Round(Srmax)
rmaxrmax和rminrmin表示真實數據的最大值和最小值, qmaxqmax和qminqmin表示量化後的最大值和最小值,例如uint8就是0和256。 Round()表示取整,如果是量化為int型。
1.1.1 量化
q=Round(rS+Z)q=Round(Sr+Z)
1.1.2 反量化
r=(q−Z)∗Sr=(q−Z)∗S


1.2 對稱量化(int8 -128-127)
對稱算法是通過一個收縮因子,將FP32中的最大絕對值映射到8比特的最大值,最大絕對值的負值(注意此值不是fp32的最小值,是最大絕對值的相反數,故對稱)映射到8比特的最小值。對稱量化在量化前和量化後的零點保持一致,即零點對應,因此無需像非對稱量化那樣引入一個偏移量Z。 對稱量化的一般公式為:
S=∣rmax∣∣qmax∣S=∣qmax∣∣rmax∣
1.2.1量化
q=Round(rS)q=Round(Sr)Round()表示取整,如果是量化為int型。
1.2.2 反量化
r=q∗Sr=q∗S


2. 量化的優缺點
2.1 量化的優點
- 減小模型尺寸,如8位整型量化可減少75%的模型大小
- 減少存儲空間,在邊緣側存儲空間不足時更具有意義
- 易於在線升級,模型更小意味着更加容易傳輸
- 減少內存耗用,更小的模型大小意味着不需要更多的內存
- 加快推理速度,訪問一次32位浮點型可以訪問四次int8整型,整型運算比浮點型運算更快
- 減少設備功耗,內存耗用少了推理速度快了自然減少了設備功耗
- 支持微處理器,有些微處理器屬於8位的,低功耗運行浮點運算速度慢,需要進行8bit量化
2.2 量化的缺點
- 模型量化增加了操作複雜度,在量化時需要做一些特殊的處理,否則精度損失更嚴重
- 模型量化會損失一定的精度,雖然在微調後可以減少精度損失,但推理精度確實下降
3. 對稱和非對稱使用
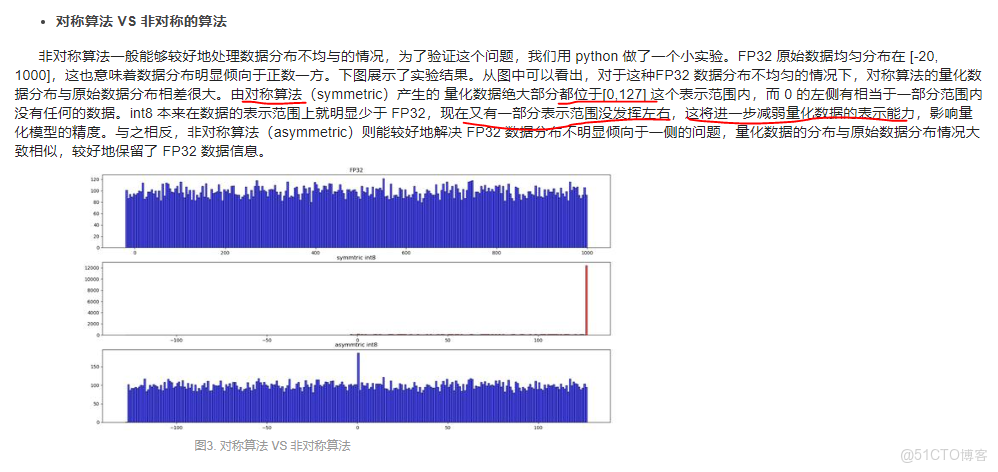
對稱量化無需引入偏移量Z,因此計算量低,缺點是量化後的數據是非飽和的,即有一部分區域不存在量化的數據。
非對稱量化因為額外引入了一個偏移量來修正零點,因此需要的計算量會大一點。優點是其量化後的數據是飽和的,即量化前的最小值對應量化範圍的最小值,量化後的最大值對應量化範圍的最大值。

對於fp32的值若均勻分佈在0左右,映射後的值也會均勻分佈,若fp32的值分佈不均勻,映射後不能充分利用。所以非對稱可以處理好FP32數據分佈不均勻的情況。
若對稱算法產生的量化後數據很多都是在【0,127】內,左邊的範圍利用很少,減弱了量化數據的表示能力,影響模型精度。
此外還有很多其他的魔改版本,比如激活值飽和量化,通過選擇合適的閾值T來將一些範圍利用少的情況去除,然後再做對稱量化。從而也實現對應的飽和量化的操作。下圖為魔改版本激活值飽和量化(右圖),選擇合適的閾值T。以及原始版本權值非飽和量化(左圖)
