隨着人工智能模型規模擴大和數據複雜度提升,整合多源異構數據實現多模態協同建模,已成為提升模型性能的核心路徑。高效的數據預處理體系需在保證數據質量與多樣性的前提下,突破大規模數據清洗、增強與合成的系統性技術瓶頸,以平衡訓練效能與成本控制。阿里雲人工智能平台 PAI 分佈式訓練 PAI-DLC 推出的一項全新任務類型 DataJuicer on DLC,旨在為用户帶來開箱即用、高性能、穩定高效的數據處理能力。用户可以一鍵提交 DataJuicer 框架任務,高效地完成大規模數據的清洗、過濾、轉換和增強, 實現大模型場景下文本及多模態數據處理計算能力。
在大規模數據集樣本下,DataJuicer on DLC 支持異構集羣、具備多模態協同處理引擎,表現出更高效的數據處理效率和更優資源利用率。本文將介紹 DataJuicer 和 PAI-DLC,以及如何在 PAI-DLC 支持快速提交 DataJuicer 框架任務。
PAI-DLC 及 DataJuicer 相關介紹
DataJuicer 介紹
DataJuicer是一款專注於處理大規模多模態數據(如文本、圖像、音頻和視頻)的開源工具。旨在幫助研究人員和開發者高效地清洗、過濾、轉換和增強大規模數據集,為大語言模型 (LLM) 提供更高質量、更豐富、更易“消化”的數據。

PAI-DLC 介紹
PAI-DLC是阿里雲人工智能平台PAI提供的雲原生AI分佈式訓練服務,為開發者和企業提供靈活、穩定、易用和高性能的訓練環境, 支持多種AI訓練框架,能夠處理大規模分佈式模型訓練任務,在降低成本的同時提升訓練效率。

DataJuicer on DLC 介紹
DataJuicer on DLC 是由阿里雲人工智能平台PAI和通義實驗室,聯合推出的一款數據處理服務,支持用户在雲上一鍵提交DataJuicer框架任務,高效地完成大規模數據的清洗、過濾、轉換和增強, 實現LLM多模態數據處理計算能力。
3.1 DataJuicer on DLC 技術特性
- 高性能:DataJuicer on DLC 在千萬級多模態數據集的處理中,展現出卓越的線性擴展性能,和數據處理速度優勢,有效優化資源利用。
- 支持異構集羣:在海量多模態數據處理場景下,支持不同類型的算子、以及同一個數據處理管線的不同階段算子,在異構集羣(GPU/CPU)分別執行,進一步提升資源利用效率和處理性能
- 多模態協同處理引擎:內置文本、圖像、視頻、音頻等專用算子,支持視覺-文本-時序數據的聯合清洗與增強,不同類型算子可以靈活調度在異構集羣(比如文本用cpu,圖像視頻用gpu)執行,避免傳統工具鏈的"碎片化"處理的同時大大提升資源利用率。
- 算子豐富:為用户提供 100 多個核心算子,包含 aggregator、deduplicator、filter、formatter、grouper、mapper、selector 等, 覆蓋了數據加載和規範化,數據編輯和轉換,數據過濾和去重,及高質量樣本篩選的數據處理全週期。

- 大規模:依託 PAI DLC 的分佈式計算框架與深度硬件加速優化(CUDA/OP 融合),支持從千級樣本的實驗到百億級生產數據的高效處理。
- 自動容錯:PAI DLC 本身提供節點、任務、容器維度的容錯和自愈能力,同時 DataJuicer 進一步提供算子級別的容錯能力,解決服務器、網絡等基礎設施等故障導致的中斷風險。
- 資源預估:DataJuicer 支持智能平衡資源限制與運行效率,自動預估算子OP最優併發數,顯著降低內存溢出(OOM)導致的任務失敗率,同時優化資源分配策略,有效提升數據處理效率。
- 簡單易用:開發者可依據業務場景靈活編排算子鏈,精準滿足不同類型的數據處理需求, 並且總結多個行業級模板,方便用户一鍵使用。PAI DLC 提供直觀的用户界面和易於理解的API,免部署、免運維, 用户無需關注底層基礎設施的部署與運維複雜性, 一鍵提交DataJuicer任務進行AI數據處理。

3.2 性能優勢
- 在億級超大規模數據處理場景, DataJuicer on DLC 呈現出顯著的線性加速比與可擴展性。GPU資源配置相同情況下,當數據集擴展至5倍時,數據處理耗時約擴展4.8倍,其線性效率高達96%,最大化GPU資源利用率。

- 在千萬級中等規模數據處理場景, DataJuicer on DLC 與雲原生節點運行相比,耗時更短,速度更快,約節省24.8%的處理時間。
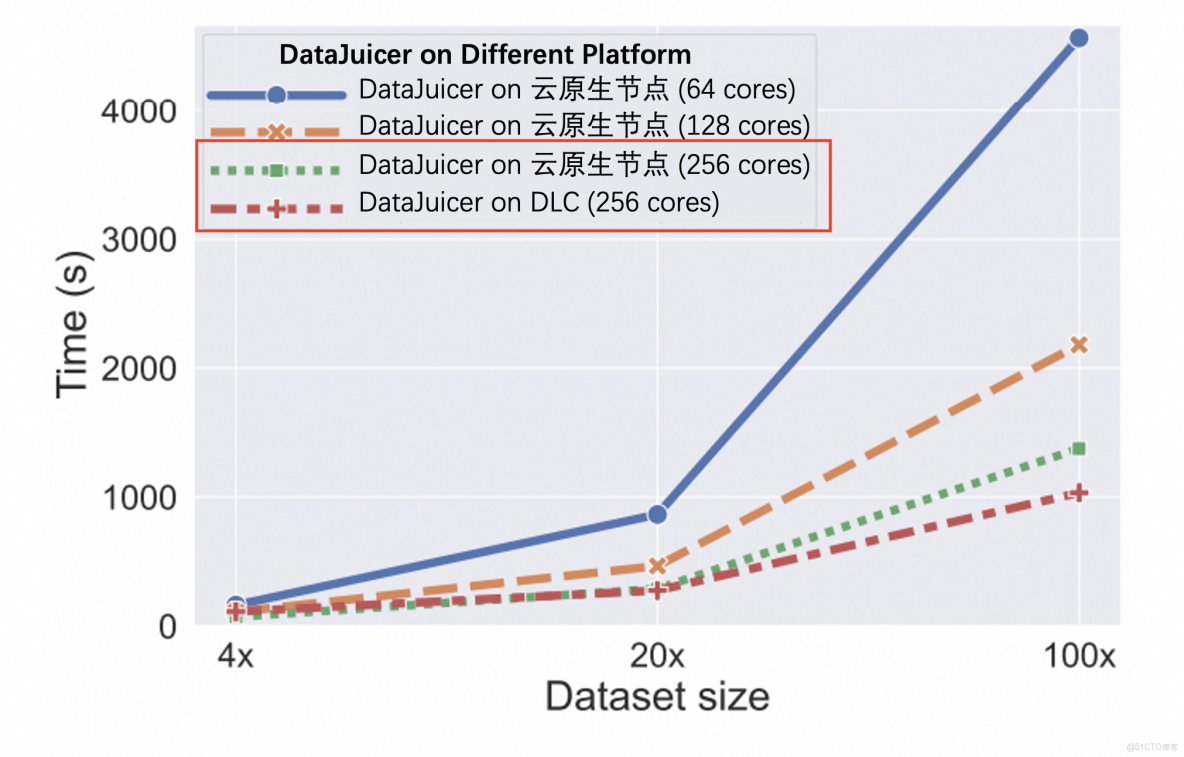
多模態數據(千萬級規模)CPU任務耗時對比圖
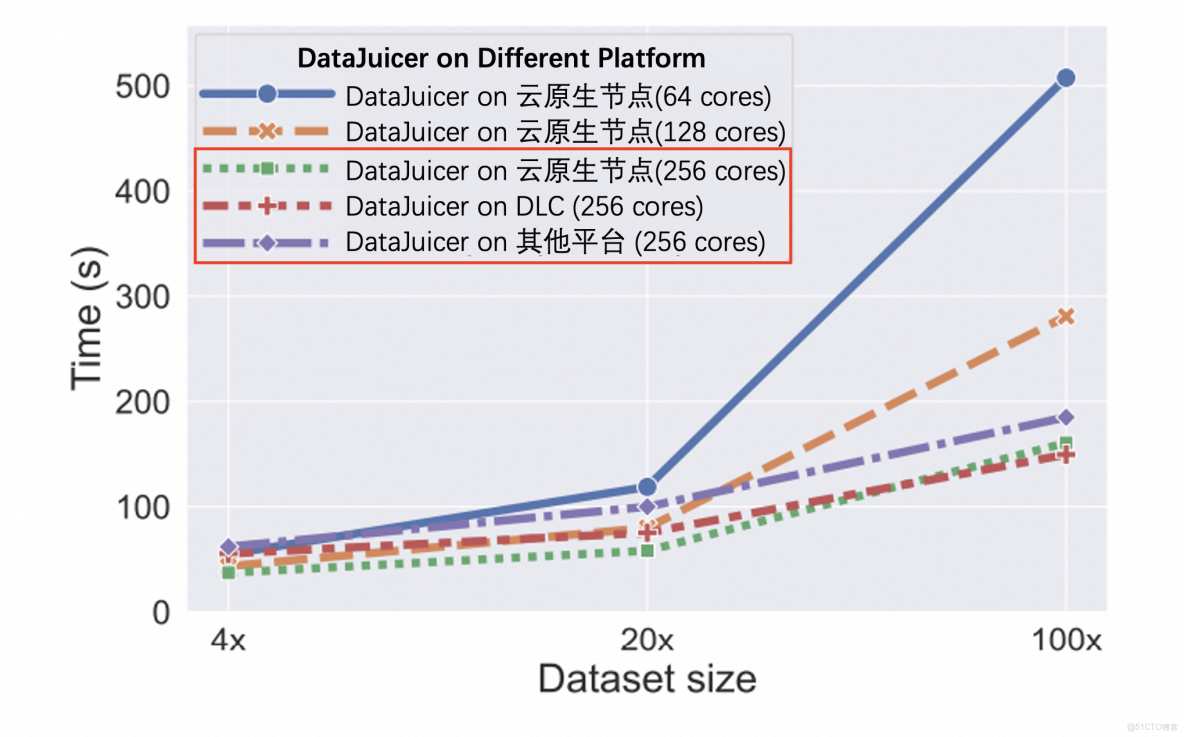
文本數據(千萬級規模)CPU任務耗時對比圖
- 在 200GB、1TB、5TB 的數據集上測試了基於 MinHash 的 Ray 去重算子,測試機器的 CPU 核數從 640 核到 1280 核。實驗表明,當數據集大小增長 5 倍,處理時間增長 4.02 到 5.62 倍。當 CPU 核數翻倍,處理時間較原來減少了 58.9% 到 67.1%。
實操案例
- 以海量視頻數據處理場景為例,隨着多模態大語言模型(MLLM)在自動駕駛、具身智能等領域的突破性應用,海量視頻數據的精細化處理已成為構建行業核心競爭力的技術高地。在自動駕駛場景中,模型需從車載攝像頭持續輸入的視頻流中實時解析複雜路況、交通標識、行人行為等多維度信息;而具身智能系統則依賴視頻數據構建物理世界動態表徵,以完成機器人運動規劃、環境交互等高階任務。然而,傳統數據處理方案面臨三大核心挑戰:
- 模態割裂:視頻數據包含視覺、音頻、時序、文本描述等多源異構信息,需跨模態特徵融合工具鏈,而傳統流水線式工具難以實現全局關聯分析。
- 質量瓶頸:數據清洗需經歷去重、標註修復、關鍵幀提取、噪聲過濾等多個環節,傳統多階段處理易造成信息損失與冗餘計算。
- 工程效能:大規模視頻數據(TB/PB級)處理對分佈式算力調度、異構硬件適配提出極高要求,自建系統存在開發週期長、資源利用率低等問題。
- PAI-DLC DataJuicer 框架為上述挑戰提供端到端解決方案。DataJuicer on DLC 解決方案技術優勢體現在:
- 多模態協同處理引擎:內置文本、圖像、視頻、音頻等專用算子,支持視覺-文本-時序數據的聯合清洗與增強,避免傳統工具鏈的"碎片化"處理。
- 雲原生彈性架構:深度集成PAI的百GB/s級分佈式存儲加速、GPU/CPU異構資源池化能力,支持千節點任務自動擴縮容。
本案例以自動駕駛和具身智能所需的視頻處理流程為例,演示如何通過DataJuicer完成以下處理:
- 過濾原始數據中時長過短的視頻頻段
- 根據NSFW得分過濾髒數據
- 對視頻抽幀 生成視頻的文本caption描述
Step1 數據準備:以Youku-AliceMind數據集為例,抽取2000條視頻數據。原始數據參考:https://modelscope.cn/datasets/modelscope/Youku-AliceMind。
Step2 鏡像選擇:選擇官方鏡像,data-juicer:1.4.3-pytorch2.6-gpu-py310-cu121-ubuntu22.04。
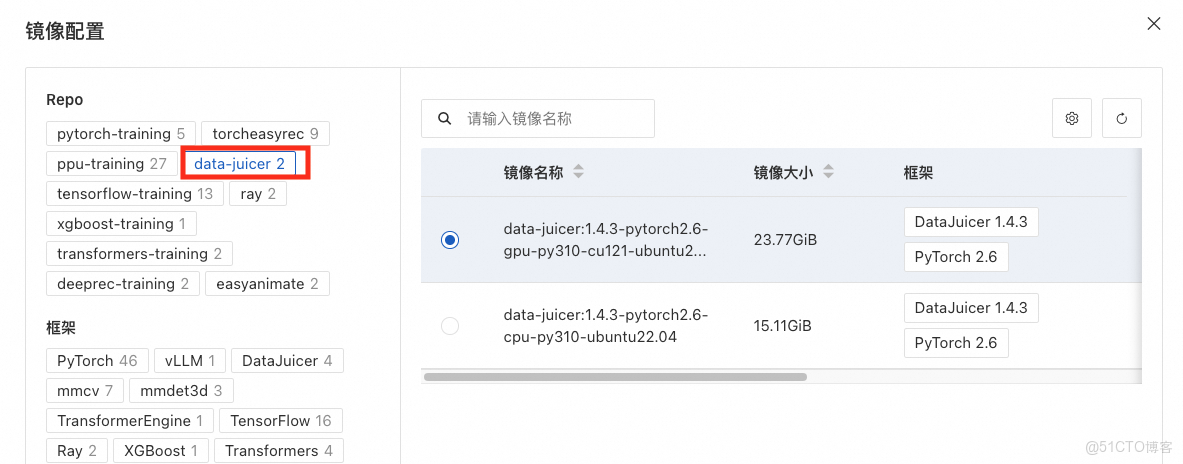
Step3 資源配置:選擇DataJuicer框架,選擇分佈式的運行模式,並配置如下資源。

Step4 YAML配置:
# global parameters
project_name: 'dj-video-demo'
dataset_path: '/mnt/data/data/Youku-AliceMind/caption/validation/youku_alice_mind_dj_2k.jsonl'
executor_type: 'ray'
skip_op_error: false # 調試階段
export_type: 'jsonl'
export_path: '/mnt/data/outputs/video_demo/v1'
video_key: 'videos'
video_special_token: '<__dj__video>'
eoc_special_token: '<|__dj__eoc|>'
# process schedule
# a list of several process operators with their arguments
process:
- video_duration_filter:
min_duration: 0
max_duration: 3600
any_or_all: any
- video_nsfw_filter:
hf_nsfw_model: Falconsai/nsfw_image_detection
max_score: 0.5
frame_sampling_method: all_keyframes
frame_num: 3
reduce_mode: avg
any_or_all: any
- video_captioning_from_frames_mapper:
hf_img2seq: 'Salesforce/blip2-opt-2.7b'
caption_num: 1
keep_candidate_mode: 'random_any'
keep_original_sample: true
frame_sampling_method: 'all_keyframes'
frame_num: 3PAI 全鏈路加速套件
高效、高質量的多模態數據處理為業務提供良好的起點之後,人工智能平台 PAI 提供全鏈路加速套件,覆數據處理、模型訓練和模型推理等階段,所有加速套件都可以在 PAI 上實現與業務的無縫銜接。
paiTurboX
在自動駕駛場景,paiTurboX 為複雜數據預處理、離線大規模模型訓練和實時智能駕駛推理提供了全方位的加速解決方案,深度融合 PAI 平台的異構算力調度、分佈式訓練和分佈式推理等核心能力,顯著提升了感知、規劃、控制等多模塊系統的訓練與推理效率。
paiTurboX 從系統、數據、模型三個方面針對自動駕駛面臨的兩大難題進行優化。在系統側,TurboX 通過優化 CPU 親和性、流水線並行和動態編譯等方案,支持 CPU 計算和 GPU 計算流水並行調度執行,提升模型訓練推理效率。

paiFuser
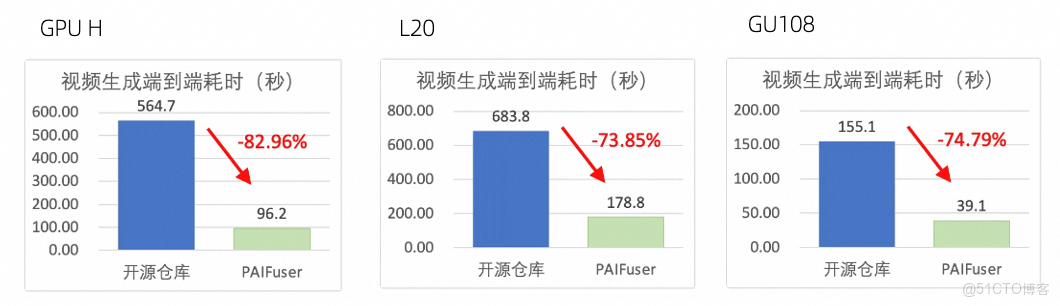
針對擴散模型(Diffusion Models),尤其是 DiT(Diffusion Transformer)架構,paiFuser 通過高性能一體化訓練與推理加速框架,有效解決高計算複雜度、顯存消耗大、實時性不足等問題。結合 PAI 平台的靈活、穩定、易用和高性能的訓練/推理環境,在數千卡集羣,訓練場景達到了40%+的 MFU;在單機8卡條件下,推理場景生成時間最高減少80%+。

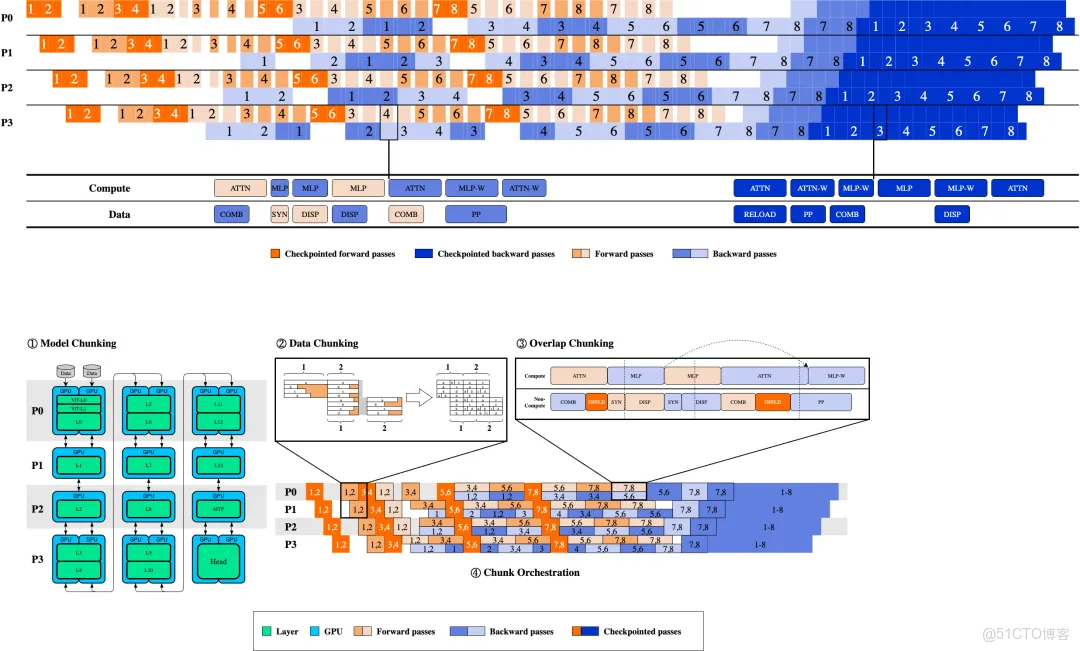
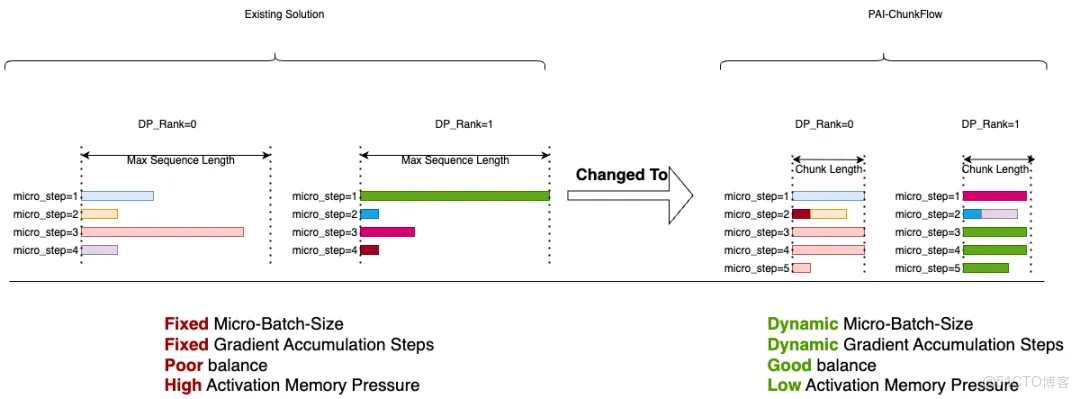
paiMoE
針對大規模 MoE 模型,PAI 提供 paiMoE 引擎。paiMoE 核心技術含 MoE 高性能訓練優化 Tangram 和 長序列訓練優化 ChunkFlow,通過統一調度機制、自適應計算通信掩蓋、EP計算負載均衡和計算顯存分離式並行等方面深度優化,有效解決工作負載不同、稀疏 MoE 通信佔比高等問題,實測達到 Qwen3 訓練端到端加速比提效 3 倍。