









本案例由開發者:給無眠點壓力提供
最新案例動態,請查閲《【案例共創】華為開發者空間,基於倉頡與DeepSeek的MCP智能膳食助手》。小夥伴快來領取華為開發者空間進行實操吧
一、概述
1. 案例介紹
MCP,全稱Model Context Protocol,中文叫“模型上下文協議”。你可以把它想象成AI的“USB 接口” --讓不同的AI模型、工具和應用程序能用統一的方式交流。那麼我的理解是:它更像是一個適配器來調節各種AI不同的接口達到一致的效果,讓AI的交流更加簡單,即使沒有身份預設,走MCP是完美的讓AI成為你的最佳助手。
隨着人們對健康飲食關注度的提升,越來越多用户希望藉助AI助手實現個性化的飲食分析與管理。然而,目前市面上的飲食類應用普遍存在如下痛點:
- 缺乏智能分析:大多數僅記錄卡路里,無法提供專業點評與優化建議;
- 知識更新不及時:難以結合最新營養研究進行推薦與判斷;
- 缺乏可擴展性:難以適配特定人羣(如高血壓、糖尿病、健身人羣等)的差異需求。
本項目旨在構建一個基於大語言模型(DeepSeek)和結構化協議(MCP)的智能飲食健康助手,通過自然語言交互,幫助用户實現飲食數據結構化、健康風險識別與個性化建議生成。
2. 適用對象
- 企業
- 個人開發者
- 高校學生
3. 案例時間
本案例總時長預計90分鐘。
4. 案例流程

説明:
- 登錄華為開發者空間工作台,領取雲主機。在雲主機登錄ModelArts Studio(MaaS)控制枱,領取DeepSeek-V3百萬免費Tokens。
- 華為開發者空間 - 雲主機 桌面打開CodeArts IDE for Python構建本地MCP服務項目,實現飲食語義解析、食物識別、健康標籤打標、Prompt生成與請求路由。
- 華為開發者空間 - 雲主機 桌面打開CodeArts IDE for Cangjie構建本地倉頡AI機器人,接收經過標準化構造的請求Prompt,返回結構化營養建議、健康分析與飲食優化建議。
5. 資源總覽
本案例預計花費0元。
|
資源名稱 |
規格 |
單價(元) |
時長(分鐘) |
|
華為開發者空間 - 雲主機 |
鯤鵬通用計算增強型 kc2 | 4vCPUs | 8G | Ubuntu |
免費 |
90 |
二、環境與資源準備
1. 配置開發者空間
面向廣大開發者羣體,華為開發者空間提供一個隨時訪問的“開發桌面雲主機”、豐富的“預配置工具集合”和靈活使用的“場景化資源池”,開發者開箱即用,快速體驗華為根技術和資源。
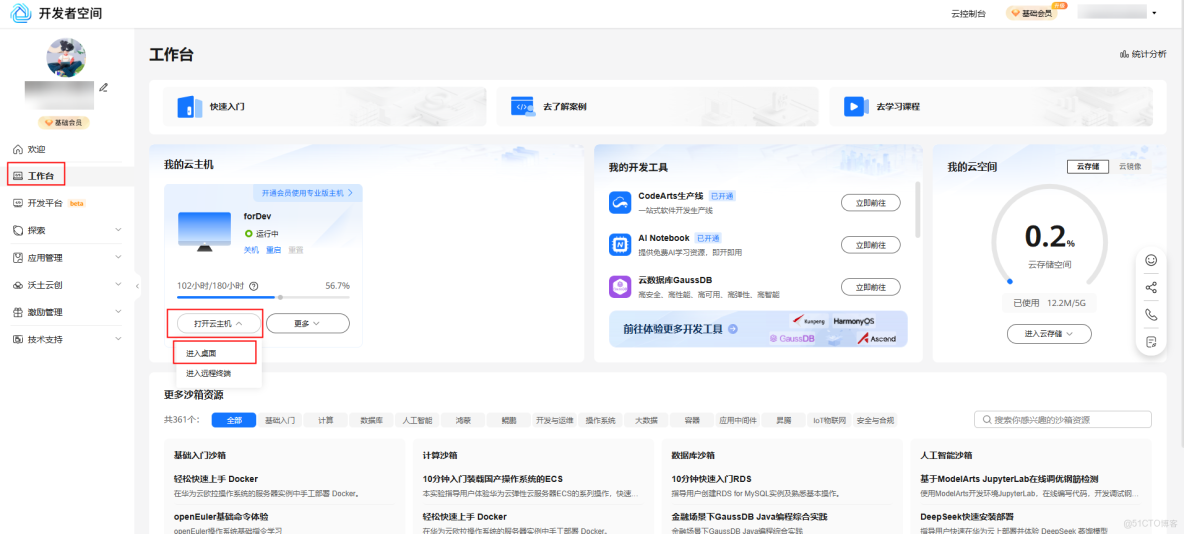
如果還沒有領取雲主機進入工作台界面後點擊配置雲主機,選擇Ubuntu操作系統。

進入華為開發者空間工作台界面,點擊打開雲主機 > 進入桌面連接雲主機。

2. 免費領取DeepSeek R1滿血版
華為雲提供了單模型200萬免費Tokens,包含DeepSeek-V3滿血版等,我們可以登錄華為雲ModelArts Studio(MaaS)控制枱領取免費額度,這裏我們選擇DeepSeek-R1滿血版來搭建我們的專屬AI聊天機器人。
在雲主機桌面底部菜單欄,點擊打開火狐瀏覽器。用火狐瀏覽器訪問ModelArts Studio首頁:https://www.huaweicloud.com/product/modelarts/studio.html,點擊**ModelArts Studio控制枱**跳轉到登錄界面,按照登錄界面提示登錄,即可進入ModelArts Studio控制枱。
根據系統提示簽署免責聲明。
進入ModelArts Studio控制枱首頁,區域選擇西南-貴陽一,在左側菜單欄,選擇模型推理 > 在線推理 > 預置服務 > 免費服務,選擇DeepSeek-V3-32K模型,點擊領取額度,領取200萬免費token。
領取後點擊調用説明,可以獲取到對應的API地址、模型名稱。
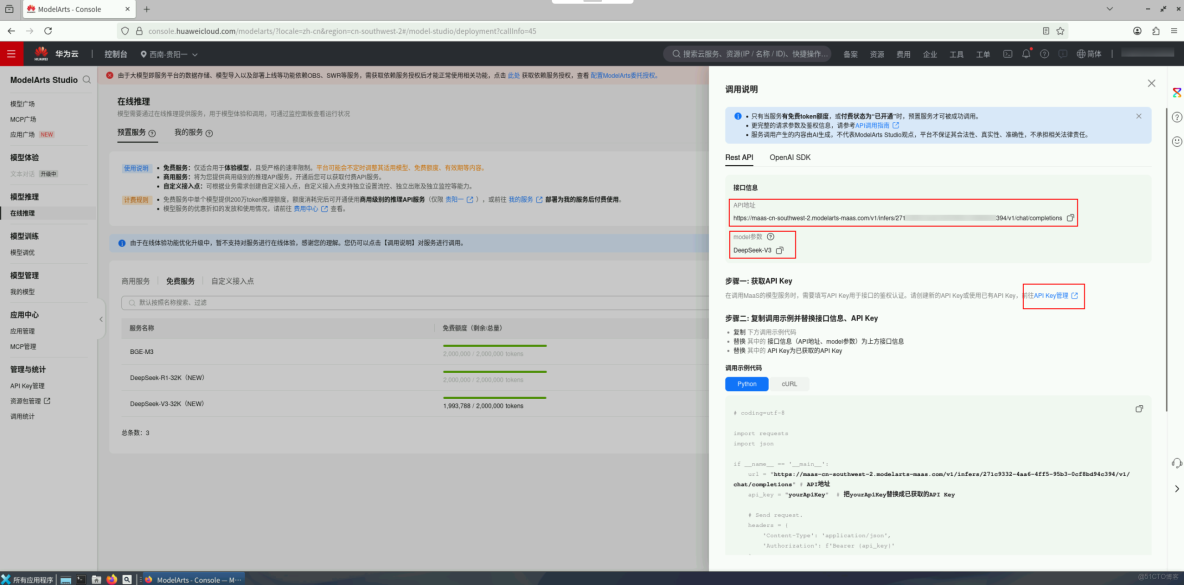
點擊API Key管理,進入API Key管理界面。點擊右上角的創建API Key,編輯標籤和描述,點擊確定。

點擊右側覆按鈕,將密鑰複製保存到本地。

注:API Key僅會在新建後顯示一次,若API Key丟失,需要新建API Key。
通過本節操作,我們在ModelArts Studio控制枱獲取到三個關鍵數據:API地址、模型名稱和API Key。
四、構建本地MCP服務項目
本案例採用本地MCP服務 + 本地倉頡AI機器人對話。本章節講解如何構建本地MCP服務。
1. 新建項目food_mcp
在雲主機桌面打開CodeArts IDE for Python。

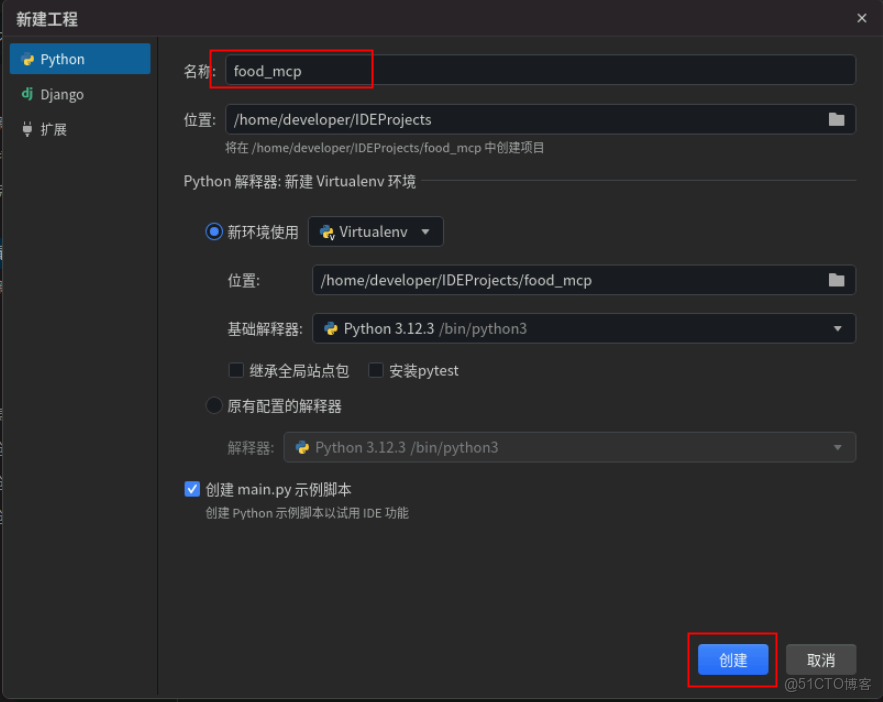
在新打開的CodeArts IDE for Python的提示界面或通過文件 > 新建 > 工程,打開新建工程配置界面。

在新建工程配置界面,編輯項目名稱為food_mcp,然後點擊創建。
2. 功能實現mcp_server.py
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為mcp_server.py,下一步在此文件中開始編寫代碼。
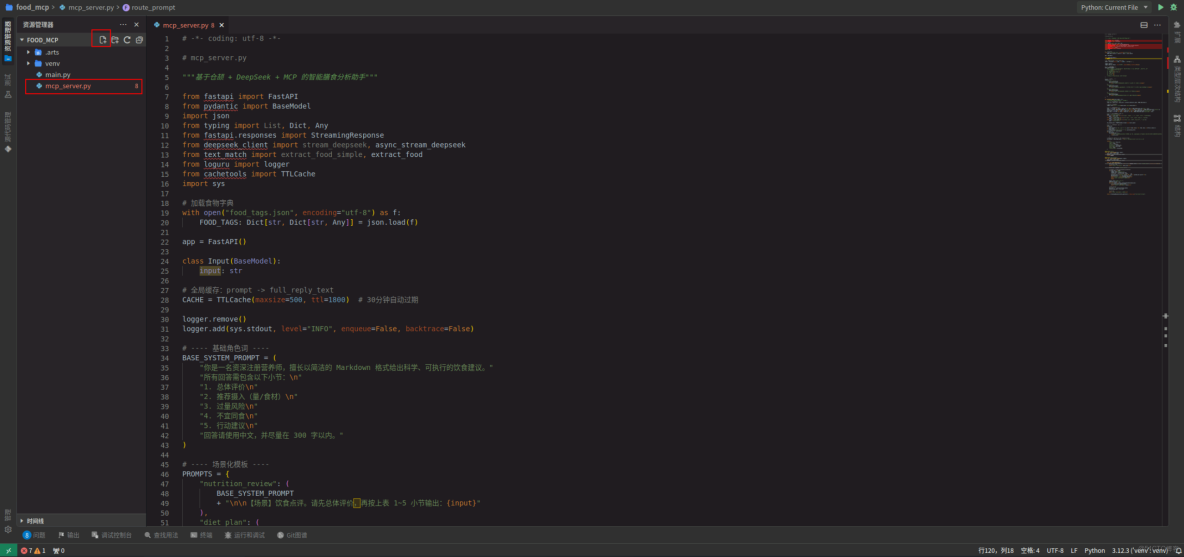
2.1 模塊導入與初始化
依次導入FastAPI框架構建Web服務、使用Pydantic定義數據模型、導入JSON處理模塊、導入類型註解工具、導入流式響應支持、導入DeepSeek API客户端(流式/異步流式)、導入食物文本匹配工具、導入日誌工具、導入帶TTL的緩存系統、導入系統模塊(日誌配置)。
# -*- coding: utf-8 -*-
# mcp_server.py
"""基於倉頡 + DeepSeek + MCP 的智能膳食分析助手"""
from fastapi import FastAPI
from pydantic import BaseModel
import json
from typing import List, Dict, Any
from fastapi.responses import StreamingResponse
from deepseek_client import stream_deepseek, async_stream_deepseek
from text_match import extract_food_simple, extract_food
from loguru import logger
from cachetools import TTLCache
import sys2.2 數據加載
從food_tags.json文件加載食物標籤數據,創建全局字典FOOD_TAGS存儲食物屬性:
- 營養標籤 (tags)
- 副作用/禁忌 (effects)
- 相剋食物 (avoid_with)
- 飲食類型 (diet_type)
# 加載食物字典
with open("food_tags.json", encoding="utf-8") as f:
FOOD_TAGS: Dict[str, Dict[str, Any]] = json.load(f)2.3 API服務初始化
創建FastAPI應用實例:定義輸入數據模型(僅含 input 字符串字段),初始化全局緩存(500條容量,30分鐘過期),配置日誌系統(輸出到控制枱,INFO級別)。
app = FastAPI()
class Input(BaseModel):
input: str
# 全局緩存:prompt -> full_reply_text
CACHE = TTLCache(maxsize=500, ttl=1800) # 30分鐘自動過期
logger.remove()
logger.add(sys.stdout, level="INFO", enqueue=False, backtrace=False)2.4 提示詞模板系統
定義營養師基礎角色設定;創建多場景提示詞模板:
- nutrition_review:常規飲食分析;
- diet_plan:減脂期食譜生成(含熱量表格);
- effects_inquiry:食物過量風險分析;
- avoid_inquiry:食物相剋關係分析;
統一要求輸出包含5個核心部分:總體評價、推薦攝入、過量風險、不宜同食、行動建議。
# ---- 基礎角色詞 ----
BASE_SYSTEM_PROMPT = (
"你是一名資深註冊營養師,擅長以簡潔的 Markdown 格式給出科學、可執行的飲食建議。"
"所有回答需包含以下小節:\n"
"1. 總體評價\n"
"2. 推薦攝入(量/食材)\n"
"3. 過量風險\n"
"4. 不宜同食\n"
"5. 行動建議\n"
"回答請使用中文,並儘量在 300 字以內。"
)
# ---- 場景化模板 ----
PROMPTS = {
"nutrition_review": (
BASE_SYSTEM_PROMPT
+ "\n\n【場景】飲食點評。請先總體評價,再按上表 1~5 小節輸出:{input}"
),
"diet_plan": (
BASE_SYSTEM_PROMPT
+ "\n\n【場景】減脂期餐單。請輸出 3 日食譜 (表格形式),並在每餐註明熱量估計:{input}"
),
"effects_inquiry": (
BASE_SYSTEM_PROMPT
+ "\n\n【場景】過量影響。請列出已知副作用及參考文獻:{input}"
),
"avoid_inquiry": (
BASE_SYSTEM_PROMPT
+ "\n\n【場景】相剋查詢。請説明不宜同食原因及替代方案:{input}"
),
}2.5 核心處理函數
- 食物提取:識別輸入中的食物名稱,區分精確匹配和模糊匹配結果,記錄匹配日誌。
- 信息聚合:聚合所有匹配食物的屬性標籤,收集副作用信息,提取相剋食物列表,確定飲食類型。
- 場景模式識別:基於關鍵詞檢測用户意圖,自動路由到合適的處理場景。
- 提示詞構建:動態生成場景化提示詞,注入食物屬性作為關鍵約束,要求Markdown列表格式輸出。
def _process_input(user_input: str):
"""內部共用邏輯,返回分析結果和 prompt"""
# === 1. 食物關鍵字匹配 ===
food_list, exact_hits, fuzzy_hits = extract_food(user_input, FOOD_TAGS.keys())
# 記錄匹配詳情到日誌
logger.info(f"[匹配] 精確={exact_hits} 模糊={fuzzy_hits}")
# === 2. 聚合靜態信息 ===
tags = list({tag for food in food_list for tag in FOOD_TAGS[food].get("tags", [])})
effects = {food: FOOD_TAGS[food].get("effects") for food in food_list if FOOD_TAGS[food].get("effects")}
avoid_with = list({aw for food in food_list for aw in FOOD_TAGS[food].get("avoid_with", [])})
diet_type = list({dt for food in food_list for dt in FOOD_TAGS[food].get("diet_type", [])})
# === 3. 根據關鍵詞判定 mode ===
mode = "nutrition_review"
if any(k in user_input for k in ["減肥", "減脂", "低卡", "少油", "瘦身", "個人食譜"]):
mode = "diet_plan"
elif any(k in user_input for k in ["吃多了", "過量", "上火", "副作用", "影響"]):
mode = "effects_inquiry"
elif any(k in user_input for k in ["不能一起", "相剋", "不宜同食", "一起吃"]):
mode = "avoid_inquiry"
new_prompt_base = PROMPTS[mode].format(input=user_input)
# === 4. 拼接靜態附加信息 ===
notes = []
if effects:
notes.append("【過量風險】" + ";".join(f"{food}:{desc}" for food, desc in effects.items()))
if avoid_with:
notes.append("【不宜同食】" + "、".join(avoid_with))
extra_info = ";".join(notes)
if extra_info:
new_prompt_base += (
"\n\n以下為已知靜態信息(請務必先列出【過量風險】與【不宜同食】兩個小節,並完整引用下列內容,否則視為回答不完整):"
f"{extra_info}"
)
# 要求模型以 JSON 輸出,配合 response_format
new_prompt = new_prompt_base + "\n請使用 markdown bullet list 輸出建議。"
return {
"food_list": food_list,
"tags": tags,
"effects": effects,
"avoid_with": avoid_with,
"diet_type": diet_type,
"mode": mode,
"routed_input": new_prompt,
}2.6 API端點實現同步端點(/mcp)
- 接收用户輸入文本;
- 返回結構化分析結果(不含AI生成內容):識別出的食物列表、營養標籤、副作用信息、相剋食物、場景模式、構建的提示詞。
@app.post("/mcp")
async def route_prompt(data: Input):
user_input = data.input
result = _process_input(user_input)
return result2.7 API端點實現流式端點(/mcp_stream)
實現Server-Sent Events (SSE)流式響應,四階段事件流:
- meta 事件:發送食物分析元數據;
- token 事件:流式傳輸AI生成內容;
- 智能緩存:相同提示詞30分鐘內直接返回緩存;
- done 事件:標記響應結束;
支持實時顯示AI生成過程,優化重複請求響應速度。
@app.post("/mcp_stream")
async def route_prompt_stream(data: Input):
user_input = data.input
result = _process_input(user_input)
async def event_generator():
meta_json = json.dumps({k: v for k, v in result.items() if k != 'routed_input'}, ensure_ascii=False)
# 發送 Meta 事件
yield f"event: meta\ndata: {meta_json}\n\n"
prompt_key = result["routed_input"]
# 若緩存命中,直接按20字符切片發送緩存內容
if prompt_key in CACHE:
logger.info("[緩存] 命中")
cached_text = CACHE[prompt_key]
# SSE data 行不能包含裸換行,需逐行加前綴
payload_lines = [f"data: {line}" for line in cached_text.split("\n")]
payload_block = "\n".join(payload_lines)
yield f"event: token\n{payload_block}\n\n"
yield "event: done\ndata: [DONE]\n\n"
return
logger.info("[緩存] 未命中")
collected_chunks = []
async for chunk in async_stream_deepseek(prompt_key):
collected_chunks.append(chunk)
yield f"event: token\ndata: {chunk}\n\n"
# 緩存完整內容
full_text = "".join(collected_chunks)
CACHE[prompt_key] = full_text
# 結束事件
yield "event: done\ndata: [DONE]\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")Ctrl + S鍵保存代碼。
注: 此時工程中會報錯,這是因為開發環境中缺少必要的包文件,此處無須理會,我們將在後續步驟“8.1 編寫配置文件requirements.txt,配置依賴包”中解決依賴包的問題。
3. 功能實現deepseek_client.py
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為deepseek_client.py,下一步在此文件中開始編寫代碼。
3.1 模塊導入與初始化
# deepseek_client.py
# 基於 DeepSeek API 的客户端
import requests
import json
from typing import Generator
import httpx3.2 配置加載模塊
從config.json文件加載API配置,獲取DeepSeek API密鑰、端點URL、獲取當前使用的模型名稱。提供集中配置管理,便於維護和變更。
# 從 config.json 讀取配置
with open("config.json", encoding="utf-8") as f:
config = json.load(f)
DEEPSEEK_API_KEY = config["DEEPSEEK_API_KEY"]
DEEPSEEK_URL = config["DEEPSEEK_URL"]
MODEL_NAME = config["MODEL_NAME"]3.3 同步調用函數
- 實現同步調用DeepSeek API;
- 構建API請求頭(包含認證信息);
- 構造符合DeepSeek要求的請求體;
- 發送POST請求並獲取完整響應;
- 解析響應並返回生成的完整文本內容;
- 適用於不需要實時反饋的簡單場景。
def call_deepseek(prompt):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DEEPSEEK_API_KEY}"
}
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "user", "content": prompt}
]
}
response = requests.post(DEEPSEEK_URL, headers=headers, json=payload)
result = response.json()
return result["choices"][0]["message"]["content"]3.4 同步流式生成器
- 實現同步流式API調用,通過
stream=True參數啓用流式傳輸; - 使用
response.iter_lines()逐行處理服務器推送事件(SSE); - 解析data:開頭的有效數據塊;
- 過濾結束標記
[DONE]; - 從JSON中提取增量內容(delta);
- 使用生成器逐步返回文本片段;
- 支持實時顯示生成過程。
# 新增:流式推理生成器
def stream_deepseek(prompt) -> Generator[str, None, None]:
"""Yield generated content chunks from DeepSeek API using SSE."""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DEEPSEEK_API_KEY}"
}
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "user", "content": prompt}
],
"stream": True,
"max_tokens": 2048,
"stream_options": {"include_usage": True},
}
# 使用 stream=True 觸發增量輸出
response = requests.post(DEEPSEEK_URL, headers=headers, json=payload, stream=True)
# iter_lines 將保持連接並逐行讀取
for line in response.iter_lines(decode_unicode=True):
if not line:
continue
# DeepSeek/SSE 行以 "data: " 開頭
if line.startswith("data: "):
data_str = line[6:]
# 結束標誌
if data_str.strip() == "[DONE]":
break
# 解析 JSON,獲取增量內容
try:
data_json = json.loads(data_str)
# usage 塊 choices 為空,跳過
choices = data_json.get("choices", [])
if not choices:
continue
delta = choices[0]["delta"].get("content", "")
if delta:
yield delta
except json.JSONDecodeError:
# 忽略無法解析的片段
continue3.5 異步流式生成器
- 實現異步流式API調用,使用
httpx庫替代requests實現異步; - 通過
AsyncClient和client.stream()處理異步流; - 使用
resp.aiter_lines()異步迭代響應行; - 解析邏輯與同步版本一致;
- 適用於FastAPI等異步框架,支持高併發場景;
- 設置
timeout=None防止長文本生成超時。
參數配置:指定使用的AI模型,構造對話消息結構,通過stream=True啓用流式傳輸,設置生成token上限(防止過長響應),請求包含用量統計信息(可選) 核心處理邏輯:識別有效的SSE數據行(以 data: 開頭),跳過空行和元數據行,處理流結束信號[DONE],解析JSON格式的增量數據,提取choices[0].delta.content 中的文本片段,過濾空內容片段,異常處理確保解析失敗時不中斷流程。
# 異步流式生成器
async def async_stream_deepseek(prompt):
"""異步生成器,從 DeepSeek API 生成內容(SSE)。"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {DEEPSEEK_API_KEY}"
}
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "user", "content": prompt}
],
"stream": True,
"max_tokens": 2048,
"stream_options": {"include_usage": True},
}
async with httpx.AsyncClient(timeout=None) as client:
async with client.stream("POST", DEEPSEEK_URL, headers=headers, json=payload) as resp:
async for line in resp.aiter_lines():
if not line:
continue
if line.startswith("data: "):
data_str = line[6:]
if data_str.strip() == "[DONE]":
break
try:
data_json = json.loads(data_str)
choices = data_json.get("choices", [])
if not choices:
continue
delta = choices[0]["delta"].get("content", "")
if delta:
yield delta
except json.JSONDecodeError:
continueCtrl + S鍵保存代碼。
注: 此時工程中會報錯,這是因為開發環境中缺少必要的包文件,此處無須理會,我們將在後續步驟“8.1 編寫配置文件requirements.txt,配置依賴包”中解決依賴包的問題。
4. 功能實現test_pipeline.py
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為test_pipeline.py,下一步在此文件中開始編寫代碼。
4.1 模塊導入與初始化
# -*- coding: utf-8 -*-
# test_pipeline.py
import requests
from deepseek_client import call_deepseek
import json
from requests.exceptions import ChunkedEncodingError4.2 飲食分析測試test_diet_analysis()
測試目的:驗證常規飲食分析場景;測試MCP的食物識別和模式判斷能力;驗證DeepSeek對日常飲食的分析建議。 測試數據:典型中式餐飲組合(炸雞+奶茶,牛肉火鍋)。 預期輸出:MCP識別出炸雞、奶茶、牛肉等食物;MCP選擇nutrition_review模式;DeepSeek輸出包含健康評價和建議。
def test_diet_analysis():
user_input = "中午吃了炸雞和奶茶,晚上吃了牛肉火鍋"
# 調用 MCP
mcp_resp = requests.post("http://localhost:8001/mcp", json={"input": user_input})
mcp_data = mcp_resp.json()
print("MCP 返回:", mcp_data)
# 調用 DeepSeek
reply = call_deepseek(mcp_data["routed_input"])
print("DeepSeek 回覆:", reply)4.3 減脂計劃測試test_diet_plan()
測試目的:驗證減脂食譜生成功能;測試關鍵詞觸發diet_plan模式;驗證特定食材的食譜定製能力。 測試數據:明確減肥意圖和指定食材。 預期輸出:MCP識別減肥關鍵詞,選擇diet_plan模式;DeepSeek生成包含熱量估算的食譜表。
def test_diet_plan():
user_input = "我想要一個一週減肥計劃,主要食物包括香菇、雞胸肉和燕麥"
mcp_resp = requests.post("http://localhost:8001/mcp", json={"input": user_input})
mcp_data = mcp_resp.json()
print("MCP 返回:", mcp_data)
reply = call_deepseek(mcp_data["routed_input"])
print("DeepSeek 回覆:", reply)4.4 副作用查詢測試test_effects_inquiry()
測試目的:驗證食物過量風險分析功能;測試關鍵詞觸發effects_inquiry模式;驗證副作用信息的準確輸出。 測試數據:直接詢問食物過量影響。 預期輸出:MCP識別"吃多了"關鍵詞,選擇effects_inquiry模式,DeepSeek輸出科學依據的副作用説明。
def test_effects_inquiry():
user_input = "香菇吃多了會怎樣?"
mcp_resp = requests.post("http://localhost:8001/mcp", json={"input": user_input})
mcp_data = mcp_resp.json()
print("MCP 返回:", mcp_data)
reply = call_deepseek(mcp_data["routed_input"])
print("DeepSeek 回覆:", reply)4.5 食物相剋測試test_avoid_inquiry()
測試目的:驗證食物相剋關係分析功能;測試關鍵詞觸發avoid_inquiry模式;驗證相剋原因和替代方案輸出。 測試數據:直接詢問兩種食物兼容性。 預期輸出:MCP識別"能一起吃嗎"關鍵詞,選擇avoid_inquiry模式,DeepSeek輸出不宜同食的科學解釋。
def test_avoid_inquiry():
user_input = "牛奶和蝦能一起吃嗎?"
mcp_resp = requests.post("http://localhost:8001/mcp", json={"input": user_input})
mcp_data = mcp_resp.json()
print("MCP 返回:", mcp_data)
reply = call_deepseek(mcp_data["routed_input"])
print("DeepSeek 回覆:", reply)4.6 流式接口與核心功能測試test_stream()
- 流式接口測試:驗證SSE流式接口功能;測試元數據和內容分塊傳輸;驗證實時輸出效果。
- MCP服務集成測試:模擬客户端調用MCP的
/mcp接口,驗證服務可用性和響應格式,檢查返回數據結構完整性,打印中間結果便於調試。 - DeepSeek集成測試:驗證 DeepSeek 客户端功能;測試提示詞構建質量;檢查生成內容的相關性;評估響應時間。
- 異常處理機制:處理網絡傳輸異常;避免測試因網絡問題中斷;確保資源釋放;提供友好的錯誤提示。
def test_stream():
user_input = "我晚上吃什麼比較好呢? 中午吃了炸雞和奶茶"
try:
resp = requests.post(
"http://localhost:8001/mcp_stream",
json={"input": user_input},
stream=True,
timeout=None,
)
print("Stream start →", resp.status_code)
meta_printed = False
for line in resp.iter_lines(decode_unicode=True):
if not line:
continue
# SSE: 可能含 event: xxx
if line.startswith("event: "):
current_event = line[7:]
# 下一行應該是 data:
continue
if not line.startswith("data: "):
continue
data = line[6:]
# current_event 默認為 token
current_event = locals().get("current_event", "token")
if current_event == "meta":
try:
meta_obj = json.loads(data)
pretty_meta = json.dumps(meta_obj, ensure_ascii=False)
print("Meta:", pretty_meta)
except json.JSONDecodeError:
print("Meta:", data)
meta_printed = True
print("\n--- AI 回覆 ---\n", end="")
continue
if current_event == "done":
print("\n✅ Stream done")
break
# 其他 token 輸出
print(data, end="", flush=True)
except ChunkedEncodingError:
# 服務器已發送完畢但提前關閉連接,可忽略
print("\n⚠️ 連接提前關閉,已接收全部內容。")
finally:
try:
resp.close()
except Exception:
pass4.7 測試執行模式
模塊化測試用例設計;可選擇性執行單個測試;便於快速驗證特定功能;支持迭代開發中的持續測試。
if __name__ == "__main__":
# test_diet_analysis()
# test_diet_plan()
# test_effects_inquiry()
# test_avoid_inquiry()
test_stream()Ctrl + S鍵保存代碼。
注: 此時工程中會報錯,這是因為開發環境中缺少必要的包文件,此處無須理會,我們將在後續步驟“8.1 編寫配置文件requirements.txt,配置依賴包”中解決依賴包的問題。
5. 功能實現text_match.py
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為text_match.py,下一步在此文件中開始編寫代碼。
5.1 模塊導入與初始化
# -*- coding: utf-8 -*-
# text_match.py
import jieba
import difflib
from typing import Iterable, List, Set, Tuple5.2 核心功能:食物關鍵詞提取
從用户輸入文本中識別食物關鍵詞,支持精確匹配和模糊匹配兩種模式,返回三種匹配結果:
- 所有匹配到的食物列表(去重)
- 精確匹配的食物列表
- 模糊匹配的食物列表
def extract_food(
user_text: str,
food_vocab: Iterable[str],
fuzzy_threshold: float = 0.8,
) -> Tuple[List[str], List[str], List[str]]:
"""根據用户輸入提取食物關鍵詞。
1. 先使用 jieba 分詞命中精確詞。
2. 對分詞結果做模糊匹配,解決同義詞/花式寫法。
Args:
user_text: 用户原始輸入字符串。
food_vocab: 食物靜態數據庫的鍵集合。
fuzzy_threshold: SequenceMatcher 相似度閾值 (0-1)。
Returns:
去重後的食物列表,按出現順序返回。
"""
vocab_set: Set[str] = set(food_vocab)
tokens = jieba.lcut(user_text, cut_all=False)
hits: List[str] = []
exact_hits: List[str] = []
fuzzy_hits: List[str] = []
added: Set[str] = set()
for token in tokens:
# 精確匹配
if token in vocab_set and token not in added:
hits.append(token)
exact_hits.append(token)
added.add(token)
continue
# 模糊匹配
for food in vocab_set:
if food in added:
continue
if difflib.SequenceMatcher(None, token, food).ratio() >= fuzzy_threshold:
hits.append(food)
fuzzy_hits.append(food)
added.add(food)
break
return hits, exact_hits, fuzzy_hits5.3 輔助功能:簡化接口
提供向後兼容的簡化接口;只返回匹配到的食物列表(不區分精確/模糊);保持舊模塊的調用方式不變。
# 向後兼容的簡化接口
def extract_food_simple(user_text: str, food_vocab: Iterable[str], fuzzy_threshold: float = 0.8) -> List[str]:
"""返回僅 food list 的舊版接口,供其他模塊調用。"""
return extract_food(user_text, food_vocab, fuzzy_threshold)[0]Ctrl + S鍵保存代碼。
注: 此時工程中會報錯,這是因為開發環境中缺少必要的包文件,此處無須理會,我們將在後續步驟“8.1 編寫配置文件requirements.txt,配置依賴包”中解決依賴包的問題。
6. 編寫配置文件food_tags.json
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為food_tags.json,下一步在此文件中開始編寫配置文件。
{
"炸雞": {
"tags": ["高油脂", "高熱量"],
"effects": "經常食用可能導致能量過剩、血脂升高",
"avoid_with": ["啤酒"],
"diet_type": ["增重期", "週末放縱"],
"recipe_hint": "可使用空氣炸鍋,減少50%油脂攝入"
},
"奶茶": {
"tags": ["高糖", "高熱量"],
"effects": "過量攝入易導致胰島素抵抗、體重增加",
"avoid_with": [],
"diet_type": ["偶爾犒勞"],
"recipe_hint": "選擇低糖或無糖版本,減少珍珠"
},
"可樂": {
"tags": ["高糖"],
"effects": "長期高糖飲料攝入可增加蛀牙及肥胖風險",
"avoid_with": ["咖啡"],
"diet_type": ["偶爾犒勞"],
"recipe_hint": "選擇零度可樂或氣泡水替代"
},
"滷牛肉": {
"tags": ["高鈉", "高蛋白"],
"effects": "高鈉攝入可能升高血壓",
"avoid_with": [],
"diet_type": ["增肌期"],
"recipe_hint": "配合蔬菜食用平衡營養"
},
"牛肉火鍋": {
"tags": ["高油脂", "高鈉"],
"effects": "高鹽高油易導致水腫",
"avoid_with": ["冰啤酒"],
"diet_type": ["增重期"],
"recipe_hint": "控制湯底油脂和鹽分,搭配蔬菜"
},
"蔬菜湯": {
"tags": ["低熱量", "健康推薦"],
"effects": "一般安全",
"avoid_with": [],
"diet_type": ["減脂期", "日常維穩"],
"recipe_hint": "少鹽少油"
},
"白灼蝦": {
"tags": ["高蛋白", "健康推薦"],
"effects": "嘌呤偏高,痛風患者需控制",
"avoid_with": ["維生素C高的水果"],
"diet_type": ["增肌期", "減脂期"],
"recipe_hint": "控制蘸料用量"
},
"香菇": {
"tags": ["高纖維", "低脂"],
"effects": "過量可能導致脹氣",
"avoid_with": ["寒性食物"],
"diet_type": ["減脂期", "日常維穩"],
"recipe_hint": "烹飪前泡發充分"
},
"燕麥": {
"tags": ["高纖維", "低GI"],
"effects": "攝入過多可能引起腹脹",
"avoid_with": [],
"diet_type": ["減脂期", "增肌期"],
"recipe_hint": "配合蛋白質食物提高飽腹"
},
"糙米": {
"tags": ["高纖維", "低GI"],
"effects": "富含植酸,影響礦物質吸收,建議與其他穀物搭配",
"avoid_with": [],
"diet_type": ["減脂期", "日常維穩"],
"recipe_hint": "提前浸泡12小時再煮"
},
"炸薯條": {
"tags": ["高油脂", "高熱量"],
"effects": "反式脂肪酸攝入風險",
"avoid_with": ["汽水"],
"diet_type": ["偶爾犒勞"],
"recipe_hint": "可使用空氣炸鍋替代油炸"
} ,
"牛油果": {
"tags": ["高脂肪", "高纖維", "健康推薦"],
"effects": "脂肪含量高,減脂期注意總熱量",
"avoid_with": [],
"diet_type": ["增肌期", "日常維穩"],
"recipe_hint": "搭配全麥麪包或沙拉"
},
"酸奶": {
"tags": ["高蛋白", "益生菌"],
"effects": "乳糖不耐人羣可能腹脹",
"avoid_with": ["高糖穀物"],
"diet_type": ["減脂期", "增肌期", "日常維穩"],
"recipe_hint": "選擇無糖或低糖版本"
},
"披薩": {
"tags": ["高油脂", "高熱量"],
"effects": "高鈉高脂,注意攝入頻次",
"avoid_with": ["可樂"],
"diet_type": ["週末放縱"],
"recipe_hint": "選擇薄底、加多蔬菜版本"
},
"紅薯": {
"tags": ["低GI", "高纖維", "健康推薦"],
"effects": "過量可致腹脹",
"avoid_with": [],
"diet_type": ["減脂期", "日常維穩"],
"recipe_hint": "蒸煮可保留營養"
},
"鮭魚": {
"tags": ["高蛋白", "Omega-3"],
"effects": "富含EPA/DHA,有助心血管健康",
"avoid_with": ["富含草酸蔬菜"],
"diet_type": ["增肌期", "日常維穩"],
"recipe_hint": "推薦清蒸或空氣炸鍋"
},
"綠茶": {
"tags": ["低熱量", "抗氧化"],
"effects": "空腹或過量可致胃刺激",
"avoid_with": ["牛奶"],
"diet_type": ["減脂期", "日常維穩"],
"recipe_hint": "餐後一小時飲用更佳"
},
"巧克力": {
"tags": ["高糖", "高脂"],
"effects": "攝入過多易長痘和增重",
"avoid_with": [],
"diet_type": ["偶爾犒勞"],
"recipe_hint": "優選 70% 以上黑巧"
},
"能量飲料": {
"tags": ["高糖", "咖啡因"],
"effects": "過量可能導致心悸、睡眠障礙",
"avoid_with": ["咖啡"],
"diet_type": ["比賽備戰", "偶爾提神"],
"recipe_hint": "控制每日總咖啡因 < 400mg"
}
}7. 編寫配置文件config.json
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為config.json,下一步在此文件中開始編寫配置文件。
{
"DEEPSEEK_API_KEY": "API Key",
"DEEPSEEK_URL": "API地址",
"MCP_PORT": 8001,
"MODEL_NAME": "模型名稱"
}注:需要替換在步驟“2. 免費領取DeepSeek R1滿血版”中獲取到的API地址、模型名稱和API Key。
8. 編寫配置文件requirements.txt,配置依賴包
8.1 編寫配置文件requirements.txt
在CodeArts IDE for Python左側資源管理器 > food_mcp工程右側的新建文件按鈕,並將文件命名為requirements.txt,下一步在此文件中開始編寫配置文件。
fastapi
uvicorn
requests
httpx
jieba
cachetools
loguru8.2 配置依賴包
點擊終端,運行如下命令,系統自動安裝requirements.txt文件中的依賴包。
pip install -r requirements.txt -i https://mirrors.huaweicloud.com/repository/pypi/simple注:安裝完畢後,代碼文件中如果顯示仍然缺少依賴,請關閉ide,重新打開即可。
9. 調試MCP
點擊終端,運行如下命令,啓動MCP服務。
uvicorn mcp_server:app --port 8001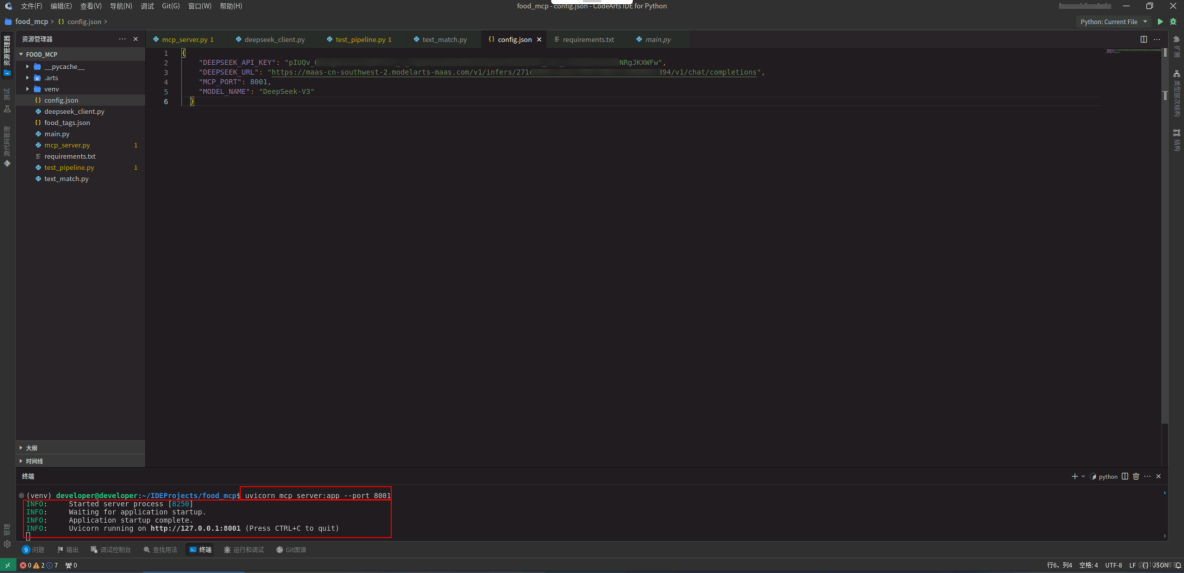
點擊終端右上角的“+”,新建終端,在新的終端界面執行如下命令,測試程序運行結果:
python test_pipeline.py
在執行測試成功的示例圖中,我們就可以看到流式響應的效果。
四、構建本地倉頡AI機器人
本案例採用本地MCP服務 + 本地倉頡AI機器人對話。本章節講解如何構建本地倉頡AI機器人。
1. 新建項目food_bot
返回雲主機桌面,打開CodeArts IDE for Cangjie。
在新打開的CodeArts IDE for Cangjie的提示界面或通過文件 > 新建 > 工程,打開新建工程配置界面。

在新建工程配置界面,編輯項目名稱為food_bot,然後點擊創建。
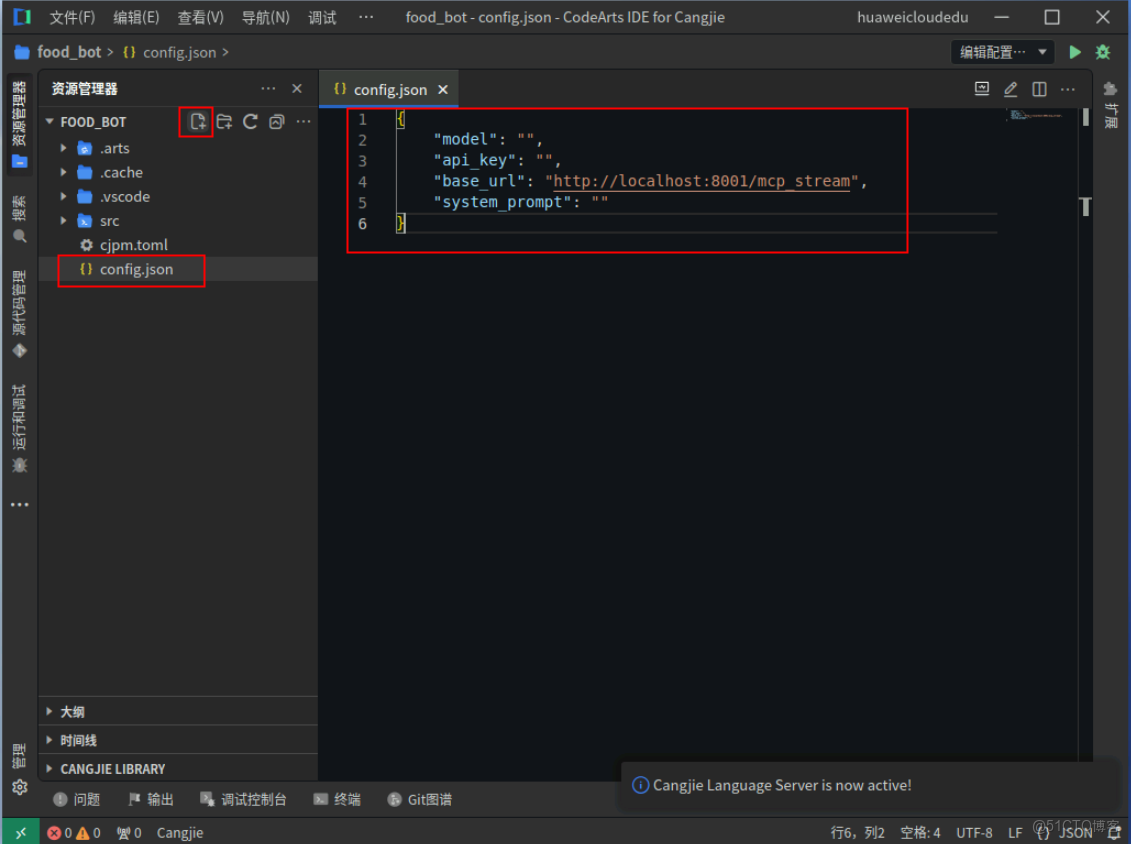
2. 編寫配置文件config.json
在CodeArts IDE for Cangjie左側資源管理器 > food_bot工程右側的新建文件按鈕,並將文件命名為config.json,下一步在此文件中開始編寫配置文件。
{
"model": "",
"api_key": "",
"base_url": "http://localhost:8001/mcp_stream",
"system_prompt": ""
}
Ctrl + S鍵保存配置文件代碼。
3. 編寫配置文件cjpm.toml
在CodeArts IDE for Cangjie左側資源管理器 > food_bot工程中找到配置文件cjpm.toml,下一步在此文件中開始編寫配置文件。
[dependencies]
[package]
cjc-version = "0.53.13"
compile-option = ""
description = "nothing here"
link-option = ""
name = "food_bot"
output-type = "executable"
src-dir = ""
target-dir = ""
version = "1.0.0"
package-configuration = {}Ctrl + S鍵保存配置文件代碼。在彈出的選項中選擇yes,修改配置文件cjpm.toml需要重啓LSPServer。
4. 功能實現src/main.cj
在CodeArts IDE for Cangjie左側資源管理器 > food_bot工程目錄中找到src/main.cj,下一步在此文件中開始編寫代碼。
4.1 模塊導入與初始化
package food_bot
import std.console.Console
import std.collection.ArrayList4.2 交互式聊天核心 (cli_chat)
- 初始化與歡迎信息:打印歡迎語,提示退出指令;初始化history列表存儲用户輸入與AI回覆的元組 (用户輸入, AI回覆)。
- 用户輸入處理:讀取控制枱輸入,跳過空輸入;支持exit/exit()退出程序;支持clear清空對話歷史。
- 流式模式動態切換:根據命令行參數stream和API地址特徵(是否以 /mcp_stream 結尾)智能啓用流式傳輸。
- 聊天接口調用:根據流式模式選擇調用stream_chat()(流式)或chat()(非流式);自動傳遞當前輸入prompt、環境配置env_info和歷史對話history。
- 健壯性設計:首次調用失敗時自動重試一次;重試仍失敗則終止程序。
- 對話歷史管理:成功響應後保存當前對話到history,維持多輪對話上下文。
func cli_chat(env_info: EnvInfo, stream!: Bool) {
println("\n歡迎使用智能膳食分析助手,輸入exit退出")
var history: ArrayList<(String, String)> = ArrayList<(String, String)>()
while (true) {
print("Input: ")
var prompt: String = ""
match(Console.stdIn.readln()) {
case Some(str1: String) => prompt=str1
case None => continue
}
if (prompt == "exit" || prompt == "exit()") {
break
}
if (prompt == "clear") {
history.clear()
println("Output: 已清理歷史對話信息。")
continue
}
// 根據配置或命令行參數判斷是否啓用流式模式
var use_stream: Bool = stream
if (!use_stream && env_info.base_url.endsWith("/mcp_stream")) {
use_stream = true
}
print("ChatBox: ")
let response_option: Option<String> = if (use_stream) {
stream_chat(prompt, env_info, history)
} else {
chat(prompt, env_info, history)
}
match (response_option) {
case Some(response: String) =>
println("${response}")
history.append((prompt, response))
case None =>
println("發生錯誤,正在重試一次...")
let retry_option = if (use_stream) {
stream_chat(prompt, env_info, history)
} else {
chat(prompt, env_info, history)
}
match(retry_option) {
case Some(resp2: String) =>
println("${resp2}")
history.append((prompt, resp2))
case None =>
println("重試失敗,即將退出")
break
}
}
}
}4.3 主入口函數 (main)
- 初始化程序環境配置(load_env_info())。
- 解析命令行參數,僅支持 --stream 標誌開啓流式輸出模式。
- 調用核心聊天函數 cli_chat() 啓動交互界面。
main(args: Array<String>): Int64 {
let env_info = load_env_info()
var stream: Bool = false
if (args.size == 1) {
if (args[0] == "--stream") {
stream = true
} else {
println("參數無效,僅支持 --stream 以開啓流式輸出")
}
}
cli_chat(env_info, stream: stream)
return 0
}Ctrl + S鍵保存代碼。
5. 功能實現src/env_info.cj
在CodeArts IDE for Cangjie左側資源管理器 > food_bot工程目錄中找到src目錄,點擊food_bot工程右側的新建文件按鈕,將文件命名為env_info.cj,下一步在此文件中開始編寫代碼。
5.1 模塊導入與初始化
package food_bot
import encoding.json.stream.*
import std.fs.File
import std.fs.Path
import std.io.ByteArrayStream5.2 環境配置類 (EnvInfo)
- 配置數據容器:存儲AI服務必需的4個核心參數;包含默認值防止空值異常。
- JSON序列化/反序列化:實現雙向JSON轉換接口,支持從JSON流構建對象 (fromJson),支持將對象輸出為JSON (toJson)。
- 健壯性設計:字段級默認值(如API密鑰佔位符),忽略未知JSON字段的容錯處理,嚴格的JSON結構校驗(BeginObject/EndObject)。
- 安全防護:API密鑰默認使用掩碼值、序列化時自動處理敏感數據。
public class EnvInfo <: JsonDeserializable<EnvInfo> & JsonSerializable {
public let model: String // 模型名稱
public let api_key: String // api密鑰
public let base_url: String // 調用接口路徑
public let system_prompt: String // 預置系統提示詞
public init(model: String, api_key: String, base_url: String, system_prompt: String) {
this.model = model
this.api_key = api_key
this.base_url = base_url
this.system_prompt = system_prompt
}
public static func fromJson(r: JsonReader): EnvInfo {
var temp_model: String = ""
var temp_api_key: String = "sk-xxx"
var temp_base_url: String = "http://xxx.xxx.xxx/v1"
var temp_system_prompt: String = "You are a helpful assistant."
while (let Some(v) <- r.peek()) {
match(v) {
case BeginObject =>
r.startObject()
while(r.peek() != EndObject) {
let n = r.readName()
match (n) {
case "model" => temp_model = r.readValue<String>()
case "api_key" => temp_api_key = r.readValue<String>()
case "base_url" => temp_base_url = r.readValue<String>()
case "system_prompt" => temp_system_prompt = r.readValue<String>()
case _ => ()
}
}
r.endObject()
break
case _ => throw Exception()
}
}
return EnvInfo(temp_model, temp_api_key, temp_base_url, temp_system_prompt)
}
public func toJson(w: JsonWriter): Unit {
w.startObject()
w.writeName("model").writeValue(this.model)
w.writeName("api_key").writeValue(this.api_key)
w.writeName("base_url").writeValue(this.base_url)
w.writeName("system_prompt").writeValue(this.system_prompt)
w.endObject()
w.flush()
}
}5.3 配置樣本生成器 (save_env_info)
- 配置模板生成:自動創建標準配置文件模板 (env_sample.json),包含帶説明的佔位值。
- 開發者輔助:為新用户提供配置參考,展示正確的JSON結構格式,
- 輸出優化:使用美化格式 (WriteConfig.pretty) 增強可讀性,清理舊文件避免衝突。
public func save_env_info(): Unit {
// 該函數用於測試EnvInfo類的序列化為json的能力,順便生成一個env_sample.json樣本做為參考
let env_path = Path("env_sample.json")
if (File.exists(env_path)) {
File.delete(env_path)
}
let file = File.create(env_path)
let env_info = EnvInfo(
"xxxx",
"sk-xxxxxx",
"http://xxx.xxx.xxx/v1/chat/completions",
"You are a helpful assistant."
)
var byte_stream = ByteArrayStream()
var json_writer = JsonWriter(byte_stream)
let write_config = WriteConfig.pretty
json_writer.writeConfig = write_config
env_info.toJson(json_writer)
file.write(byte_stream.readToEnd())
println("`env_sample.json` save ok")
file.close()
}5.4 配置加載器 (load_env_info)
- 配置文件加載:從config.json加載運行時配置,硬編碼路徑確保一致性。
- 異常處理:文件不存在時拋出明確異常,終止程序防止後續錯誤。
public func load_env_info(): EnvInfo {
// 用於加載配置文件
let env_path = Path("config.json")
if (!File.exists(env_path)) {
throw Exception("The config file not exists, please check again")
}
let file = File.openRead(env_path)
let file_str: Array<UInt8> = file.readToEnd()
var byte_stream = ByteArrayStream()
byte_stream.write(file_str)
let json_reader = JsonReader(byte_stream)
let env_info: EnvInfo = EnvInfo.fromJson(json_reader)
file.close()
// println("model: ${env_info.model}")
// println("api_key: ${env_info.api_key}")
// println("base_url: ${env_info.base_url}")
// println("system_prompt: ${env_info.system_prompt}")
return env_info
}Ctrl + S鍵保存代碼。
6. 功能實現src/chat.cj
在CodeArts IDE for Cangjie左側資源管理器 > food_bot工程目錄中找到src目錄,點擊food_bot工程右側的新建文件按鈕,將文件命名為chat.cj,下一步在此文件中開始編寫代碼。
6.1 模塊導入與初始化
package food_bot
import encoding.json.stream.*
import net.http.ClientBuilder
import net.http.HttpHeaders
import net.http.HttpRequestBuilder
import net.tls.TlsClientConfig
import net.tls.CertificateVerifyMode
import std.collection.ArrayList
import std.io.ByteArrayStream
import std.time.Duration
import std.unicode.UnicodeExtension // for String.trim()6.2 核心數據結構
- 消息角色枚舉 (RoleType)
定義對話消息的三種角色類型(用户/助手/系統)及轉換方法。
// ===== 可配置常量 =====
public let READ_TIMEOUT_SECONDS: Int64 = 300 // 長輪詢 SSE 建議 300 秒
// ===========================
public enum RoleType {
User | Assistant | System
}
public func role_type_to_str(role: RoleType): Option<String> {
return match(role) {
case RoleType.User => Some("user")
case RoleType.Assistant => Some("assistant")
case RoleType.System => Some("system")
}
}
public func str_to_role_type(role_option_str: Option<String>): RoleType {
return match(role_option_str) {
case Some(str) =>
match(str) {
case "user" => RoleType.User
case "assistant" => RoleType.Assistant
case "system" => RoleType.System
case _ => RoleType.Assistant
}
case None => RoleType.Assistant
}
}- 消息結構體 (Message)
封裝單條對話消息,實現角色和內容的雙向JSON轉換。
public struct Message<: JsonDeserializable<Message> & JsonSerializable {
public let role: RoleType
public var content: String
public init(role: RoleType, content: String) {
this.role = role
this.content = content
}
public static func fromJson(r: JsonReader): Message {
var temp_role: Option<String> = None
var temp_content: String = ""
while (let Some(v) <- r.peek()) {
match(v) {
case BeginObject =>
r.startObject()
while(r.peek() != EndObject) {
let n = r.readName()
match(n) {
case "role" => temp_role = r.readValue<Option<String>>()
case "content" => temp_content = r.readValue<String>()
case _ => r.skip()
}
}
r.endObject()
break
case _ => throw Exception("can't deserialize for Message")
}
}
let role_type: RoleType = str_to_role_type(temp_role)
return Message(role_type, temp_content)
}
public func toJson(w: JsonWriter) {
w.startObject()
w.writeName("role").writeValue<Option<String>>(role_type_to_str(this.role))
w.writeName("content").writeValue<String>(this.content)
w.endObject()
w.flush()
}
}- 聊天請求結構體 (ChatRequest)
多場景構造器:直接使用消息列表;基於提示詞+歷史對話+系統提示構建。 智能上下文構建:系統提示 > 歷史對話循環 > 用户輸入。
public struct ChatRequest <: JsonSerializable {
private let model: String
private let messages: ArrayList<Message>
private let max_tokens: Int64
private let stream: Bool
public init(
model: String,
messages: ArrayList<Message>,
max_tokens: Int64,
stream: Bool
) {
// construction function with messages
this.model = model
this.messages = messages
this.max_tokens = max_tokens
this.stream = stream
}
public init(
model: String,
prompt: String,
history: ArrayList<(String, String)>,
system_prompt: String,
max_tokens: Int64,
stream: Bool
){
// construction function with prompt and system_prompt
this.model = model
this.messages = ArrayList<Message>([
Message(RoleType.System, system_prompt)
])
for ((use_msg, bot_msg) in history) {
this.messages.append(Message(RoleType.User, use_msg))
this.messages.append(Message(RoleType.Assistant, bot_msg))
}
this.messages.append(Message(RoleType.User, prompt))
this.max_tokens = max_tokens
this.stream = stream
}
public init(
model: String,
prompt: String,
history: ArrayList<(String, String)>,
system_prompt: String,
stream: Bool
){
// construction function with prompt and default arguments
this.model = model
this.messages = ArrayList<Message>([
Message(RoleType.System, system_prompt)
])
for ((use_msg, bot_msg) in history) {
this.messages.append(Message(RoleType.User, use_msg))
this.messages.append(Message(RoleType.Assistant, bot_msg))
}
this.messages.append(Message(RoleType.User, prompt))
this.max_tokens = 2000
this.stream = stream
}
public func toJson(w: JsonWriter) {
w.startObject()
w.writeName("model").writeValue<String>(this.model)
w.writeName("messages").writeValue<ArrayList<Message>>(this.messages)
w.writeName("max_tokens").writeValue<Int64>(this.max_tokens)
w.writeName("stream").writeValue<Bool>(this.stream)
w.endObject()
w.flush()
}
}- 響應相關結構體Choice
封裝AI返回的選擇項(支持流式增量)。
public struct Choice <: JsonDeserializable<Choice> & JsonSerializable {
public let index: Int32
public let message: Option<Message>
public let delta: Option<Message>
public let finish_reason: Option<String>
public let logprobs: Option<Float64> // dashscope for qwen need
public init(
index: Int32,
message: Option<Message>,
delta: Option<Message>,
finish_reason: Option<String>,
logprobs: Option<Float64>
) {
this.index = index
this.message = message
this.delta = delta
this.finish_reason = finish_reason
this.logprobs = logprobs
}
public static func fromJson(r: JsonReader): Choice {
var temp_index: Int32 = -1
var temp_message: Option<Message> = None
var temp_delta: Option<Message> = None
var temp_finish_reason: Option<String> = None
var temp_logprobs: Option<Float64> = None
while (let Some(v) <- r.peek()) {
match(v) {
case BeginObject =>
r.startObject()
while(r.peek() != EndObject) {
let n = r.readName()
match (n) {
case "index" => temp_index = r.readValue<Int32>()
case "message" => temp_message = r.readValue<Option<Message>>()
case "delta" => temp_delta = r.readValue<Option<Message>>()
case "finish_reason" => temp_finish_reason = r.readValue<Option<String>>()
case "logprobs" => temp_logprobs = r.readValue<Option<Float64>>()
case _ => r.skip()
}
}
r.endObject()
break
case _ => throw Exception("can't deserialize for Choice")
}
}
return Choice(temp_index, temp_message, temp_delta, temp_finish_reason, temp_logprobs)
}
public func toJson(w: JsonWriter) {
w.startObject()
w.writeName("index").writeValue<Int32>(this.index)
w.writeName("message").writeValue<Option<Message>>(this.message)
w.writeName("delta").writeValue<Option<Message>>(this.delta)
w.writeName("finish_reason").writeValue<Option<String>>(this.finish_reason)
w.writeName("logprobs").writeValue<Option<Float64>>(this.logprobs)
w.endObject()
w.flush()
}
}- 響應相關結構體Usage
實現統計token消耗。
public struct Usage <: JsonDeserializable<Usage> & JsonSerializable {
public let prompt_tokens: UInt64
public let completion_tokens: UInt64
public let total_tokens: UInt64
public init(prompt_tokens: UInt64, completion_tokens: UInt64, total_tokens: UInt64) {
this.prompt_tokens = prompt_tokens
this.completion_tokens = completion_tokens
this.total_tokens = total_tokens
}
public static func fromJson(r: JsonReader): Usage {
var temp_prompt_tokens: UInt64 = 0
var temp_completion_tokens: UInt64 = 0
var temp_total_tokens: UInt64 = 0
while (let Some(v) <- r.peek()) {
match(v) {
case BeginObject =>
r.startObject()
while(r.peek() != EndObject) {
let n = r.readName()
match (n) {
case "prompt_tokens" => temp_prompt_tokens = r.readValue<UInt64>()
case "completion_tokens" => temp_completion_tokens = r.readValue<UInt64>()
case "total_tokens" => temp_total_tokens = r.readValue<UInt64>()
case _ => r.skip()
}
}
r.endObject()
break
case _ => throw Exception("can't deserialize for Usage")
}
}
return Usage(temp_prompt_tokens, temp_completion_tokens, temp_total_tokens)
}
public func toJson(w: JsonWriter) {
w.startObject()
w.writeName("prompt_tokens").writeValue<UInt64>(this.prompt_tokens)
w.writeName("completion_tokens").writeValue<UInt64>(this.completion_tokens)
w.writeName("total_tokens").writeValue<UInt64>(this.total_tokens)
w.endObject()
w.flush()
}
}- 響應相關結構體ChatResponse
ChatResponse,用於實現完整的響應容器。
public struct ChatResponse <: JsonDeserializable<ChatResponse> {
// some api names `id`, and some names `request_id`
public let id: Option<String>
public let request_id: Option<String>
public let system_fingerprint: Option<String>
public let model: String
public let object: String
public let created: UInt64
public let choices: ArrayList<Choice>
public let usage: Option<Usage>
public init(
id: Option<String>,
request_id: Option<String>,
system_fingerprint: Option<String>,
model: String,
object: String,
created: UInt64,
choices: ArrayList<Choice>,
usage: Option<Usage>
) {
this.id = id
this.request_id = request_id
this.system_fingerprint = system_fingerprint
this.model = model
this.object = object
this.created = created
this.choices = choices
this.usage = usage
}
public static func fromJson(r: JsonReader): ChatResponse {
var temp_id: Option<String> = None
var temp_request_id: Option<String> = None
var temp_system_fingerprint: Option<String> = None
var temp_model: String = ""
var temp_object: String = ""
var temp_created: UInt64 = 0
var temp_choices: ArrayList<Choice> = ArrayList<Choice>([])
var temp_usage: Option<Usage> = None
while (let Some(v) <- r.peek()) {
match(v) {
case BeginObject =>
r.startObject()
while(r.peek() != EndObject) {
let n = r.readName()
match (n) {
case "id" => temp_id = r.readValue<Option<String>>()
case "request_id" => temp_request_id = r.readValue<Option<String>>()
case "system_fingerprint" => temp_system_fingerprint = r.readValue<Option<String>>()
case "model" => temp_model = r.readValue<String>()
case "object" => temp_object = r.readValue<String>()
case "created" => temp_created = r.readValue<UInt64>()
case "choices" => temp_choices = r.readValue<ArrayList<Choice>>()
case "usage" => temp_usage = r.readValue<Option<Usage>>()
case _ => r.skip()
}
}
r.endObject()
break
case _ => throw Exception("can't deserialize for ChatResponse")
}
}
return ChatResponse(
temp_id,
temp_request_id,
temp_system_fingerprint,
temp_model,
temp_object,
temp_created,
temp_choices,
temp_usage
)
}
}6.3 HTTP通信核心
- 請求構建器 (build_http_client)
- 後端類型自適應:檢測URL是否含/mcp_stream區分自定義/標準API;生成差異化請求體。
- 安全連接:HTTPS啓用信任所有證書模式(TrustAll);設置域名驗證(get_domain())
- 流式支持:添加text/event-stream請求頭;設置長超時(300秒)。
public func get_domain(
url: String
): String {
var temp_url = url
if (temp_url.startsWith("https://")) {
temp_url = temp_url["https://".size..]
} else if (temp_url.startsWith("http://")) {
temp_url = temp_url["http://".size..]
}
let domain: String = temp_url.split("?")[0].split("/")[0]
return domain
}
public func build_http_client(
prompt: String,
env_info: EnvInfo,
history: ArrayList<(String, String)>,
stream!: Bool
){
// prepare input data
// If we are targeting the custom `/mcp_stream` backend we must send
// a very simple JSON body `{ "input": "<prompt>" }` instead of the
// OpenAI-style `ChatRequest`. Detect this via URL suffix.
let is_mcp_stream = env_info.base_url.endsWith("/mcp_stream")
var post_data: Array<UInt8>
if (is_mcp_stream) {
var local_stream = ByteArrayStream()
let local_writer = JsonWriter(local_stream)
// { "input": "..." }
local_writer.startObject()
local_writer.writeName("input").writeValue(prompt)
local_writer.endObject()
local_writer.flush()
post_data = local_stream.readToEnd()
} else {
var array_stream = ByteArrayStream()
let json_writer = JsonWriter(array_stream)
let chat_res = ChatRequest(
env_info.model,
prompt,
history,
env_info.system_prompt,
stream
)
chat_res.toJson(json_writer)
post_data = array_stream.readToEnd()
}
// build headers
var headers: HttpHeaders = HttpHeaders()
if (!is_mcp_stream) {
// local backend doesn't require auth header
headers.add("Authorization", "Bearer ${env_info.api_key}")
}
headers.add("Content-Type", "application/json")
if (stream) {
headers.add("Accept", "text/event-stream")
}
let request = HttpRequestBuilder()
.url(env_info.base_url)
.method("POST")
.body(post_data)
.readTimeout(Duration.second * READ_TIMEOUT_SECONDS)
.addHeaders(headers)
.build()
let client = if (env_info.base_url.startsWith("https")) {
var tls_client_config = TlsClientConfig()
tls_client_config.verifyMode = CertificateVerifyMode.TrustAll
tls_client_config.domain = get_domain(env_info.base_url)
ClientBuilder()
.tlsConfig(tls_client_config)
.build()
} else {
ClientBuilder().build()
}
return (request, client)
}- 非流式聊天 (chat)
- 客户端 > AI服務:發送完整請求。
- AI服務 > 客户端:返回完整JSON。
- 客户端 > 客户端:解析第一選擇項內容。
public func chat(
prompt: String,
env_info: EnvInfo,
history: ArrayList<(String, String)>
): Option<String> {
let (request, client) = build_http_client(
prompt,
env_info,
history,
stream: false
)
var result_message: Option<String> = None
var res_text = ""
try {
// call api
let response = client.send(
request
)
// read result (support max revice 100k data)
let buffer = Array<Byte>(102400, item: 0)
let length = response.body.read(buffer)
res_text = String.fromUtf8(buffer[..length])
// println("res_text: ${res_text}")
var input_stream = ByteArrayStream()
input_stream.write(res_text.toArray())
// convert text to ChatResponse object
let json_reader = JsonReader(input_stream)
let res_object = ChatResponse.fromJson(json_reader)
let choices: ArrayList<Choice> = res_object.choices
if (choices.size > 0) {
let message = choices[0].message.getOrThrow()
// println("message: ${message.content}")
result_message = Some(message.content)
} else {
println("can't found any response")
}
} catch (e: Exception) {
println("ERROR: ${e.message}, reviced text is ${res_text}")
}
client.close()
return result_message
}- 流式聊天 (stream_chat)
雙模式處理:
|
模式 |
數據格式 |
關鍵事件 |
|
自定義後端 |
事件流(event: xxx) |
token, ping, error, done |
|
標準OpenAI |
data: JSON對象 |
delta.content, \[DONE] |
public func stream_chat(
prompt: String,
env_info: EnvInfo,
history: ArrayList<(String, String)>
): Option<String> {
let (request, client) = build_http_client(
prompt,
env_info,
history,
stream: true
)
let is_mcp_stream = env_info.base_url.endsWith("/mcp_stream")
var result_response: String = ""
var temp_text2 = ""
try {
// call api
let response = client.send(
request
)
// read result
let buffer = Array<Byte>(10240, item: 0)
if (is_mcp_stream) {
var done = false
var current_event = ""
while(!done) {
let length = response.body.read(buffer)
if (length == 0) {
break
}
let res_text = String.fromUtf8(buffer[..length])
for (line in res_text.split("\n")) {
let trimmed = line.trim()
if (trimmed.size == 0) {
continue
}
if (trimmed.startsWith("event: ")) {
current_event = trimmed["event: ".size..]
continue
}
if (trimmed.startsWith("data: ")) {
let data = trimmed["data: ".size..]
if (current_event == "token") {
// 累積 token,暫不直接打印
result_response = result_response + data
} else if (current_event == "ping") {
// 服務器心跳,忽略即可
()
} else if (current_event == "error") {
println("服務器錯誤: ${data}")
done = true
result_response = "" // force empty so caller sees None
break
} else if (current_event == "done") {
done = true
break
}
}
}
if (done) {
break
}
}
} else {
var finish_reason: Option<String> = None
while(finish_reason.isNone() && temp_text2 != "[DONE]") {
let length = response.body.read(buffer)
let res_text = String.fromUtf8(buffer[..length])
for (temp_text in res_text.split("\n")) {
temp_text2 = if (temp_text.startsWith("data: ")) {
temp_text["data: ".size..]
} else {
temp_text
}
if (temp_text2.size == 0) {
continue
}
if (temp_text2 == "[DONE]") {
break
}
var input_stream = ByteArrayStream()
input_stream.write(temp_text2.toArray())
// convert text to ChatResponse object
let json_reader = JsonReader(input_stream)
let res_object = ChatResponse.fromJson(json_reader)
let choices: ArrayList<Choice> = res_object.choices
if (choices.size > 0) {
finish_reason = choices[0].finish_reason
if (finish_reason.isNone()) {
let delta = choices[0].delta.getOrThrow()
result_response = result_response + delta.content
}
} else {
println("can't found any response")
}
}
}
}
} catch (e: Exception) {
println("ERROR: ${e.message}, reviced text is ${temp_text2}")
}
client.close()
if (result_response.size > 0) {
return Some(result_response)
} else {
return None
}
}Ctrl + S鍵保存代碼。
7. 調試AIChat
點擊終端圖標,打開終端,執行命令:
cjpm run
程序運行成功,輸入測試語句例如:我中午吃了炸雞和奶茶還有香菇 我晚上吃點什麼比較好呢?。

我們看到日誌返回成功。切換到CodeArts IDE for Python,切換終端窗口,我們可以看到MCP服務端接受到請求的日誌為“未命中”,這是正常響應。
切換到CodeArts IDE for Cangjie,再次輸入測試語句例如:我中午吃了炸雞和奶茶還有香菇 我晚上吃點什麼比較好呢?。
再次切換回CodeArts IDE for Python,我們發現終端窗口中輸出“命中”緩存的日誌。

兩次請求的數據,若請求未命中,則去DeepSeek請求並返回正常的輸出結果;若請求相同數據,則命中緩存,返回緩存中的結果。
五、項目總結
1. 核心能力
- 食品實體識別能力
系統具備從自然語言中準確識別出飲食相關的食品實體與關鍵詞的能力。例如,用户輸入:“我今天吃了煎餅果子、滷牛肉、奶茶”,系統應能夠自動識別出食品列表:
["煎餅果子", "滷牛肉", "奶茶"]支持中文短語、多食物組合、模糊詞等多種表達方式。
- 飲食結構化分析能力(MCP中間層處理)
系統應通過MCP模塊完成對用户輸入飲食內容的語義解析與結構化處理,主要包括:
- 應提取食品清單;
- 應識別飲食行為時段(如早餐、晚餐、夜宵等);
- 應對識別出的食物打上健康標籤(如高糖、高油脂、高鈉、低纖維等);
- 應構造符合LLM輸入規範的Prompt,以支撐後續模型理解與生成。
- 結構化分析結果應作為DeepSeek模型調用的核心中間數據。
- 合理飲食建議生成能力(基於DeepSeek)
系統應利用DeepSeek大模型,根據MCP構造的Prompt生成具有科學性、專業性與可操作性的飲食建議,包括:
- 對當前飲食存在的健康風險進行分析(如糖分攝入超標、缺乏蔬菜等);
- 提供可替代食材建議(如炸雞 → 烤雞,奶茶 → 綠茶);
- 給出搭配優化方案(如餐前飲水、搭配高纖維蔬菜等);
- 提出個性化提示(如適合三高人羣、健身人羣、孕期飲食等)。
模型輸出以自然語言形式呈現,邏輯清晰、結構明確,風格應貼近真實營養師表達方式。
2. 技術選型
本項目旨在構建一套基於多模塊協作的智能膳食分析助手,通過自然語言輸入,實現對個人飲食行為的結構化分析與健康建議生成,服務於日常健康管理、飲食優化與疾病預防等場景。
系統採用模塊化設計,主要由三大核心組成部分構成:
|
模塊 |
技術棧 |
職責 |
|
客户交互 |
倉頡語言 |
提供終端或界面交互入口,接收用户自然語言輸入並展示模型生成結果 |
|
中間處理 |
MCP模塊(Python + FastAPI) |
實現飲食語義解析、食物識別、健康標籤打標、Prompt生成與請求路由 |
|
模型服務 |
DeepSeek 大語言模型 |
接收經過標準化構造的請求Prompt,返回結構化營養建議、健康分析與飲食優化建議 |
3. 項目亮點
- 使用MCP解耦輸入處理與模型調用,提升可擴展性與靈活性;
- DeepSeek 專注自然語言生成任務,MCP預處理提高prompt精度;
- 倉頡終端可後續拓展為圖形界面、Web應用或移動端入口;
- 本地配置與食物字典可按需調整,適配多種用户類型(如減脂、控糖、健身等);
- 架構支持多模型/多來源接入,可拓展至Claude、SparkDesk、ChatGPT等後端模型。
4. 後續拓展
food_bot:通過vue等各種UI前端適配不同前端風格的機器人。
food_mcp:獨立開發為自己更加需要的模式,更加契合的"USB",讓AI更加懂你。
5.關於緩存方面
緩存可以採用本地文件、redis等更加高性能的方案來替換,這樣就可以讓實現由AI回答到AI理解到了所表達和呈現的每一個需求點。






