
近日,AI“頂流”學者李飛飛的最新長文《從語言到世界:空間智能是人工智能的下一個前沿》刷屏時,整個科技圈再次被“升維”的焦慮擊中。她指出,AI的下一個前沿是“空間智能”——讓AI真正理解和交互物理世界。她將其稱為“世界模型”(World Models),並強調了其三大核心能力:生成性、交互性,以及至關重要的多模態性。
而在企業數字化與智能化落地的場景中,這種多模態能力正是實現AI價值的關鍵前提。企業的數據不僅限於文本或結構化報表,還包括圖像、視頻、傳感器數據等多種形式,呈現出天然的多模態特徵。傳統的數據平台往往難以統一管理和高效利用這些異構數據,限制了AI應用的深度和廣度。本文將深入探討企業在AI時代面臨的數據挑戰,並結合袋鼠雲的實踐,解析如何通過構建從大數據底座平台到多模態數據中台,真正激活企業的數據應用業務價值。
企業級 AI 應用挑戰
大模型時代的到來,推動了AI應用的百花齊放,從生成視頻、圖片、PPT到智能會議和Chatbot等場景,都依賴數據作為底層支撐。然而,企業級AI應用面臨多重挑戰,這些問題源於數據從結構化向多模態的演變,以及傳統數據平台的侷限性。
首先,數據規模與模態的爆炸式變化是核心痛點。傳統數據主要以結構化形式存在(如表格、數據庫),但AI時代要求數據從穩定增長轉向爆炸增長,從單模態轉向多模態(包括圖片、視頻、音頻、文檔等)。例如,在汽車行業,車輛信息表、傳感器日誌和高精地圖矢量等數據並存;在電商領域,用户評論、商品圖片和直播視頻混合使用。這種多模態數據導致數據關聯性從獨立轉向結構化關聯,實時性從離線處理轉向動態實時,安全性從弱管控轉向強管控。同時,數據質量要求從準確完整轉向真實高覆蓋,企業需處理海量非結構化數據,但傳統平台難以統一採集和存儲,導致數據孤島問題加劇。
其次,隱性知識未沉澱和效率瓶頸制約AI落地。企業內部存在大量“Know-how”,如資深工程師的故障排查經驗或銷售專家的溝通技巧,這些知識往往未被系統記錄,導致AI訓練數據不完整。傳統BI工具依賴固定報表,無法滿足敏捷、即時洞察需求,用户需跨系統調取數據,分析效率低下。此外,資源管理挑戰突出:數據分散在關係型數據庫、文件服務器和對象存儲中,開發平台分離(結構化用離線/實時平台,非結構化用算法平台),上手門檻高,權限管理不統一,引發安全風險。
最後,政策與技術兼容性問題凸顯。國家政策如《“數據要素×”三年行動計劃》強調數據要素的放大作用,但企業面臨國產信創要求(如兼容麒麟、統信OS和達夢數據庫),原有Hadoop集羣遷移複雜,AI算法與國產硬件適配難。這些挑戰如果未解決,將阻礙AI從模型訓練上半場轉向真實場景評估下半場,企業難以實現數據驅動的智能化轉型。
袋鼠雲多模態數據智能中台設計理念與架構
面對挑戰,袋鼠雲的解法是構建一個“Data + Compute + Intelligence 一體化” 的AI Ready數據底座 。這個底座的演進分為兩個核心階段:首先是構建堅實的新一代國產化大數據底座平台(EasyMR),其次是實現AI的數據全面Ready的DataZen多模態數據中台。
EasyMR: 新一代國產化大數據底座平台
EasyMR是袋鼠雲構建的面向未來的國產化AI數據底座平台 ,其核心是“1+4”全新產品矩陣 ,旨在解決最基礎的存算、運維和國產化適配問題。
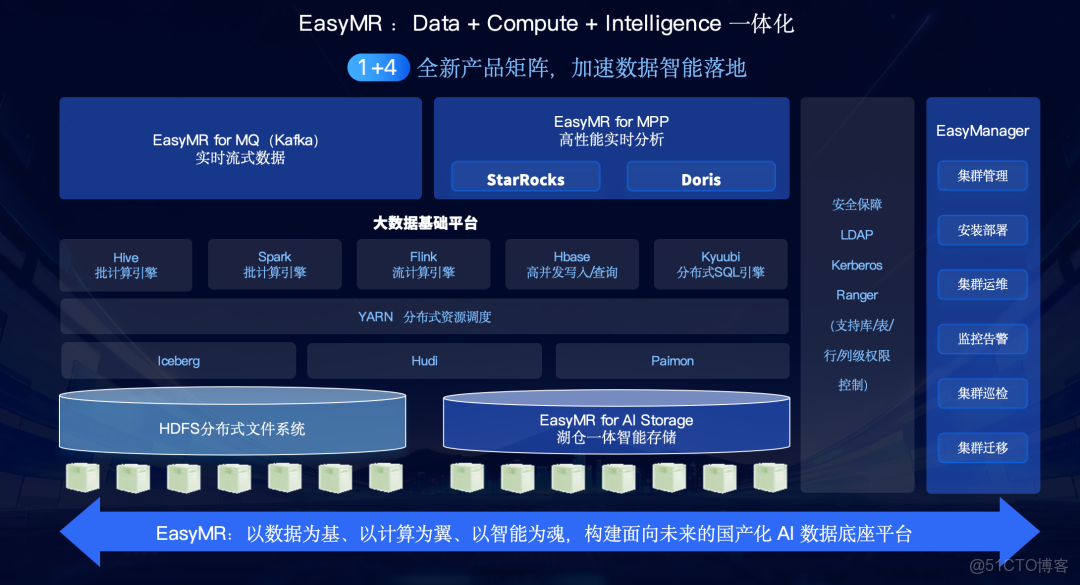
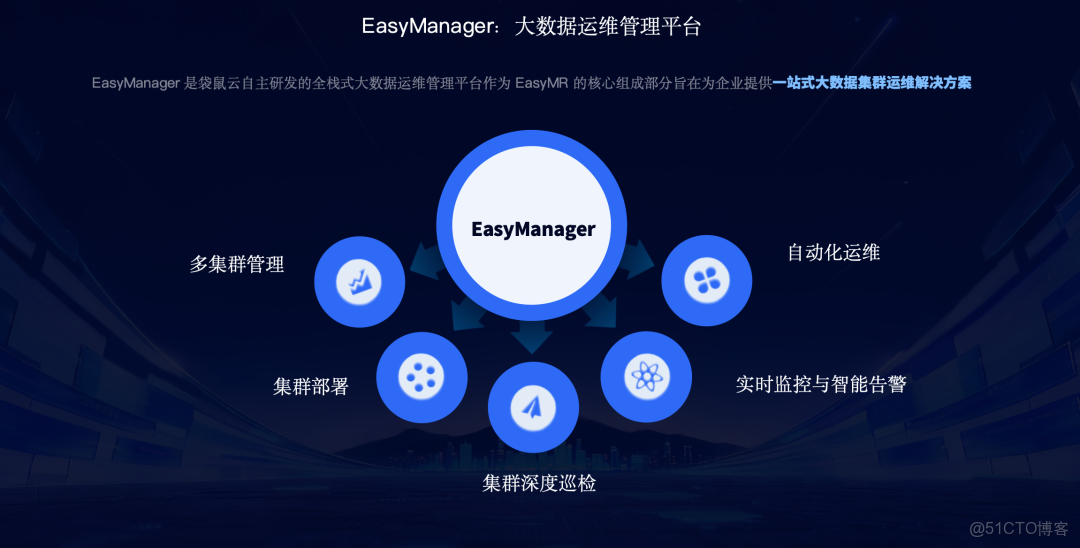
(1)1個管理平台:EasyManager,提供從安裝部署、集羣運維、監控告警到集羣遷移的全棧式大數據運維管理 。
(2)4大核心能力:
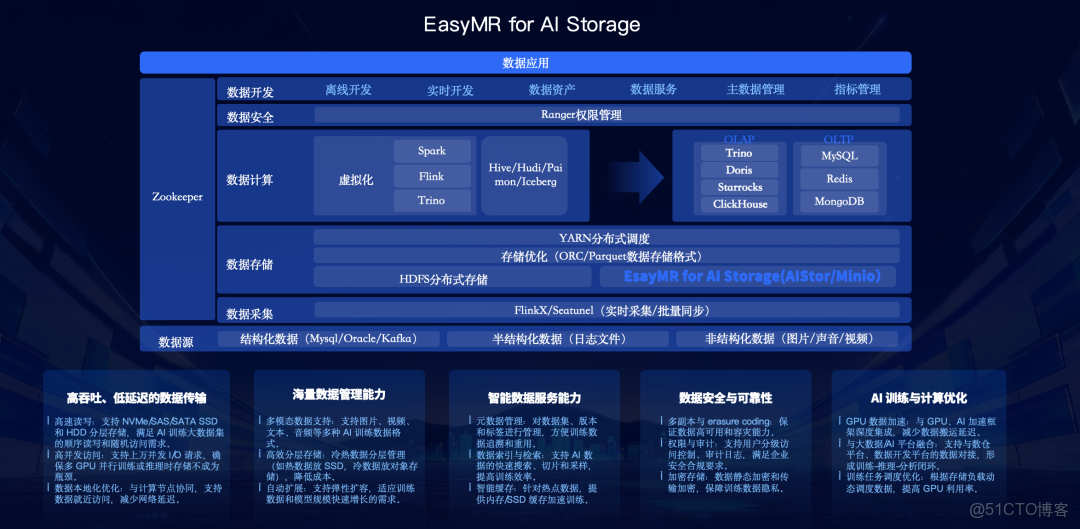
- EasyMR for AI Storage:提供湖倉一體智能存儲 ,包含HDFS分佈式文件系統 和Hbase高併發查詢等 。
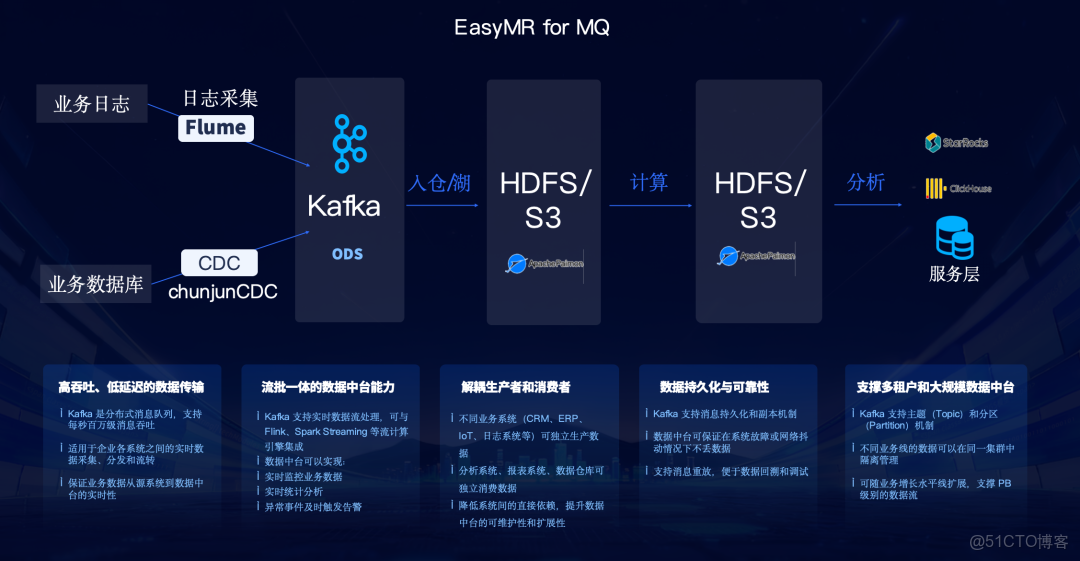
- EasyMR for MQ (Kafka):提供實時流式數據能力 ,支持高吞吐、低延遲的數據傳輸 。
- EasyMR for MPP:提供高性能實時分析 ,集成了StarRocks 和Doris等引擎。
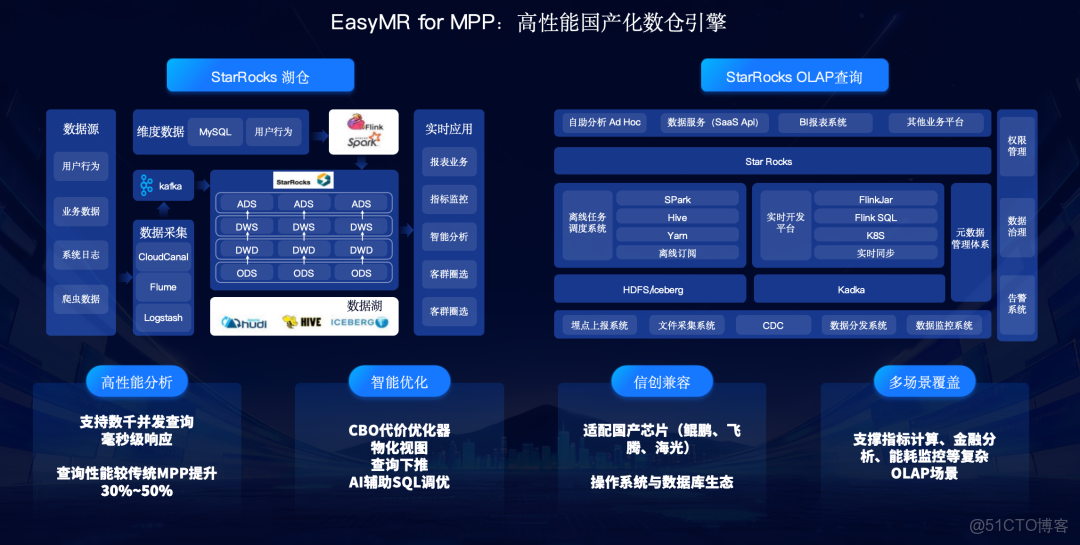
- 大數據基礎平台:包含Hive 、Spark 、Flink 等批計算和流計算引擎。
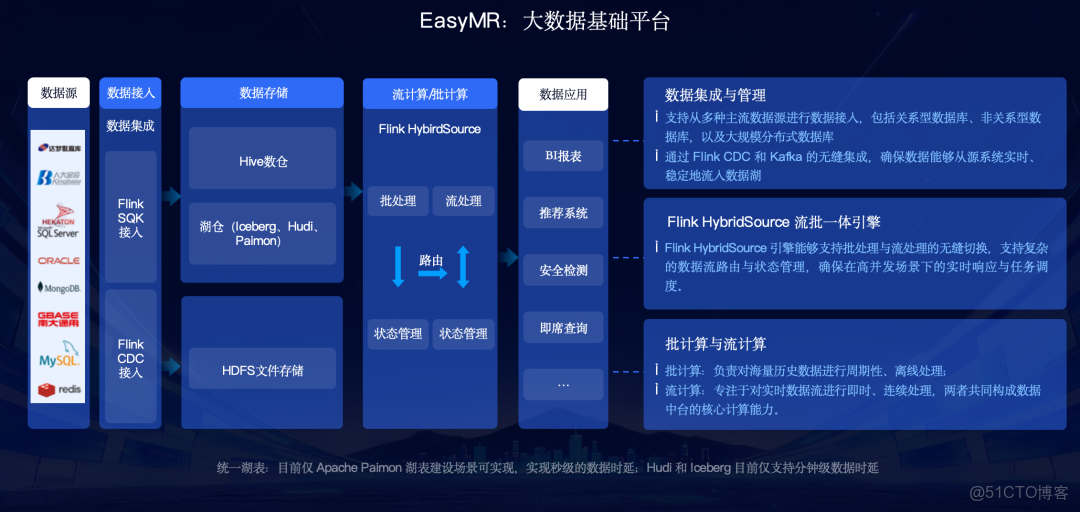
EasyMR的突出優勢在於其自主可控和全面的信創兼容。它全面適配國產處理器(如鯤鵬、飛騰、海光) ,國產操作系統(如麒麟、統信UOS、龍蜥、openEuler) 及國產數據庫(如達夢、人大金倉) 。
在安全體系上,EasyMR構建了可信、可控、可審計的底座 ,採用零信任防護層 ,基於Ranger實現庫、表、行、列級的細粒度權限管控 ,並支持多級加密體系,全面兼容國密算法 。
階段二:DataZen多模態數據中台 - 實現AI的數據全面Ready
EasyMR解決了“地基”問題,而多模態數據中台則是在此之上構建的“大廈”,其核心理念是實現所有模態數據的三大統一 :
- 統一數據集成
- 統一數據開發
- 統一數據資產管理
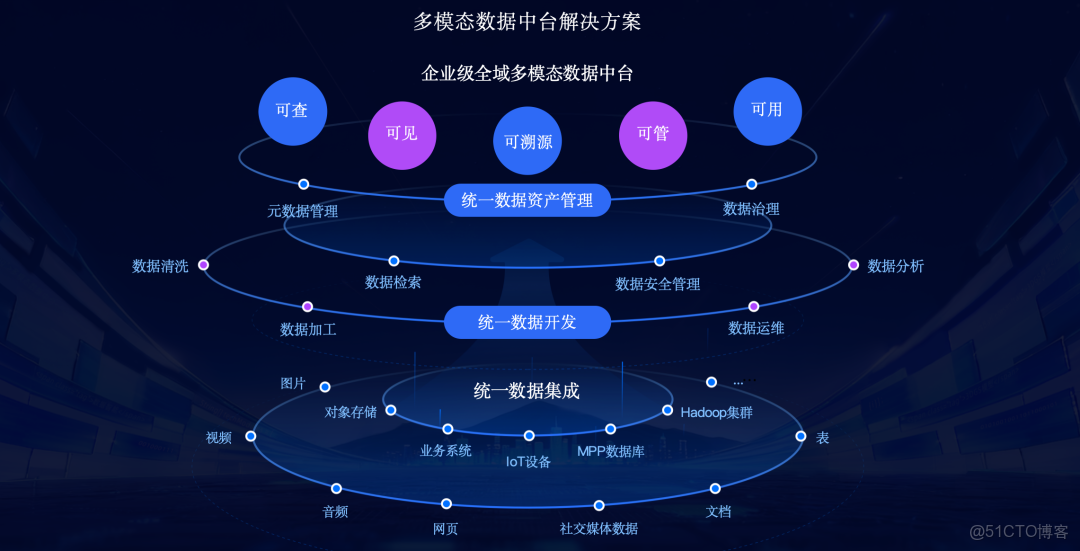
其產品架構涵蓋了從多模態數據源 (結構化 、半結構化 、非結構化 ),經過統一的數據存儲(HDFS 、MinIO S3 、Milvus )和多算力引擎(Spark 、Flink 、PyTorch/Ray ),到統一的數據開發層 、數據資產層 和最終的智能應用 。

從EasyMR大數據底座平台到DataZen多模態數據中台的關鍵能力
從EasyMR演進到DataZen多模態數據中台,袋鼠雲構建了三大核心能力,以滿足AI時代的需求。
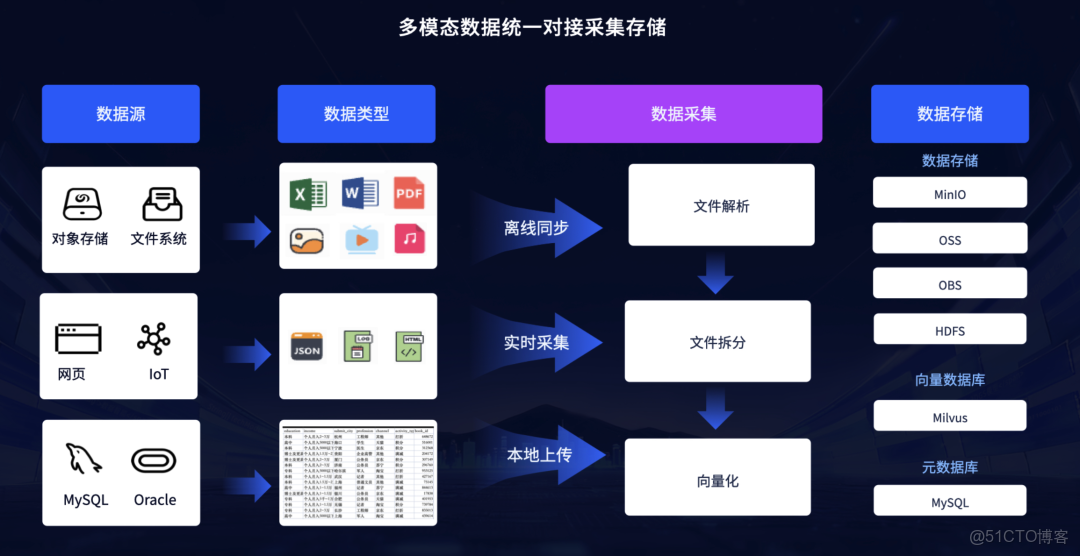
關鍵能力一:多模態數據統一對接採集存儲
平台具備對接全域數據源的能力,無論是關係型數據庫(RDB)、文檔(PDF, Word)、圖片、視頻還是網頁 和IoT設備 。
數據入庫流程被統一重構:通過離線同步、實時採集或本地上傳後,平台自動進行文件解析 、文件拆分和向量化 ,最終存入對應的向量數據庫(Milvus)、對象存儲(MinIO)或數據存儲(HDFS)中。
關鍵能力二:多模態數據統一融合處理
這是平台的核心亮點 。袋鼠雲實現了在一個平台、一個工作流中,完成跨模態任務的關聯及數據融合開發 。

① 一站式開發:如圖所示,用户可以在一個DAG(有向無環圖)中,將處理結構化數據的Spark SQL節點、處理文檔的PDF解析節點、處理圖像的圖片解析節點和處理視頻的視頻解析節點進行混編 。
② 豐富算子內置:平台內置了大量針對多模態數據的處理算子(Operator) 。例如:
- Document/Text:
doc_normalizer(文本規範化),language_filter(語言過濾),minhash_deduplicator(MinHash近鄰去重)。 - Image:image_face_blur_mapper (人臉模糊隱私保護),
image_aesthetics_filter(低美學評分圖片過濾),image_deduplicator(感知哈希去重)。 - Video:
video_duration_filter(過濾過長或過短視頻),video_captioning_from_frames_mapper(視頻幀抽幀生成文字描述)。
③ CPU+GPU混合調度:傳統的結構化數據處理(如Spark SQL)使用CPU,而文檔解析、圖像識別、視頻抽幀等AI任務則需要GPU。平台支持單個任務按需同時指定CPU和GPU的用量,實現異構資源的靈活調度 。
關鍵能力三:統一數據資產管理與安全保障
數據入庫和開發後,平台會形成統一的多模態數據資產 。
- 統一元數據:對結構化(庫、表)和非結構化(文件、目錄)的元數據進行統一存儲 、統一向量化 、統一編目打標和統一血緣追溯 。

- 統一安全:實現統一的數據安全保障 。支持租户級的數據隔離 ,並能對結構化數據的“表/行/列” 和非結構化數據的“文件/目錄” 進行統一的、細粒度的權限管控。
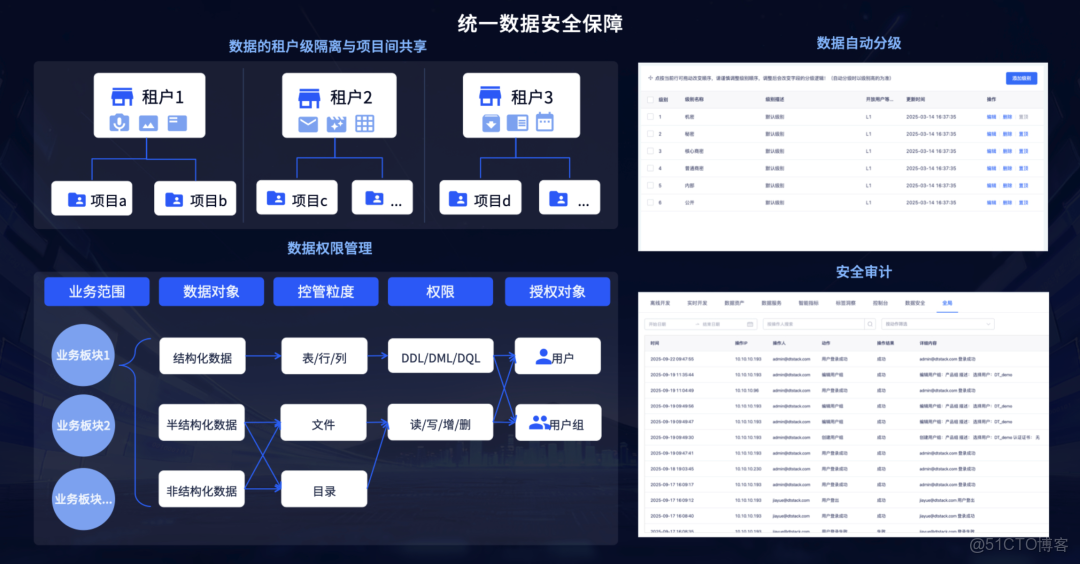
多模態數據智能中台主要應用場景與案例分析
“EMR大數據底座平台+DataZen多模態數據中台”,為上層AI應用提供了堅實的支撐。
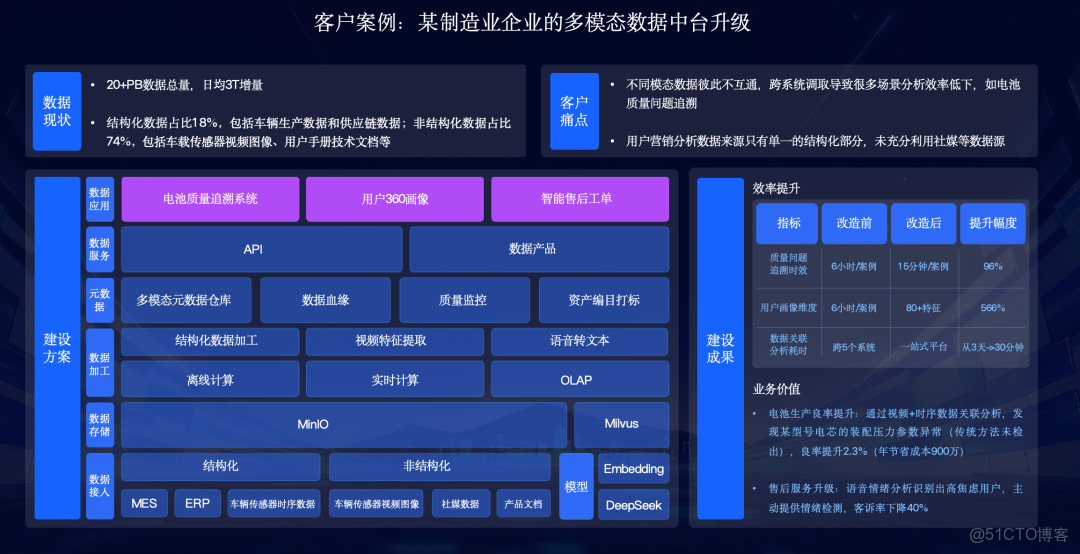
場景一:製造業 - 電池質量追溯與用户畫像
某大型製造業企業擁有20+PB數據,其中非結構化數據(車載傳感器視頻圖像、技術文檔等)佔比高達74% 。
①痛點:數據彼此不互通,跨系統調取導致分析效率低下 ;用户營銷分析僅依賴結構化數據,維度單一 。
②解決方案:構建多模態數據智能中台 ,打通了MES、ERP等結構化數據 ,與車輛傳感器的時序數據 、視頻圖像 以及社媒數據 、產品文檔等。
③業務價值:
- 效率提升:質量問題追溯時效從6小時/案例縮短至15分鐘/案例,效率提升96%。數據關聯分析耗時從3天(跨5個系統)縮短至30分鐘(一站式平台) 。
- 業務增收:通過視頻+時序數據關聯分析,發現某型號電芯的裝配壓力參數異常,使電池生產良率提升2.3%(年節省成本900萬) 。通過語音情緒分析識別高焦慮用户,客訴率下降40%。
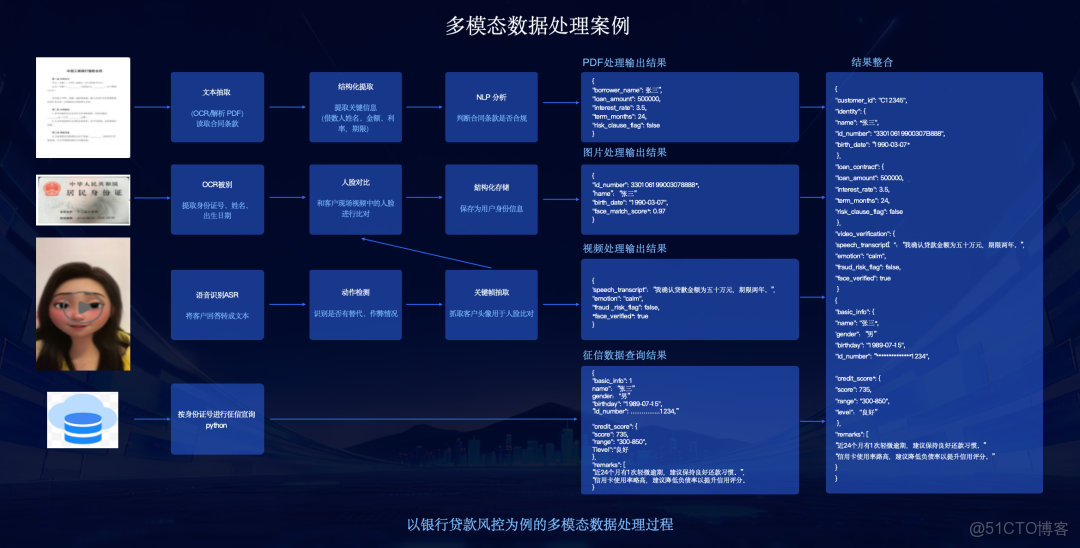
場景二:銀行業 - 貸款風控多模態審核
在銀行貸款風控場景中 ,多模態中台發揮了關鍵作用:
- 合同(PDF):通過文本抽取(OCR) 和結構化提取 ,解析出借款人姓名、金額、利率等 。
- 身份證(Image):通過OCR識別姓名、身份證號 。
- 現場視頻(Video):通過語音識別(ASR)轉錄客户回答 ;通過關鍵幀抽取和人臉對比 ,驗證“人證合一”。
- 徵信(DB):調用Python節點,按身份證號查詢徵信數據 。 最終,所有模態的數據被整合成一份統一的客户風險畫像 ,實現高效、精準的風控。
場景三:高校 - “AIMetrics智能指標”實現數據驅動決策
某高校通過建設數據治理、指標體系與AI智能問數能力 ,實現了管理模式的轉型。
業務價值:
- 管理效能:實現了從“經驗驅動”到“數據驅動”的轉型 ,跨部門協作效率提升50%,管理人員工作效率提升30%以上 。
- 服務體驗:服務響應時間縮短40%,自助服務比例提升45%。
- 資源配置:教學資源利用率提升20%,科研經費效益提升15%。

場景四:AI 輔助數據開發與報告生成
平台還提供AI Copilot能力,直接賦能數據開發者和分析師。

- AI輔助開發:在開發平台中 ,AI可基於元數據和知識庫 ,提供智能SQL生成、SQL解釋、SQL優化和日誌智能診斷 。
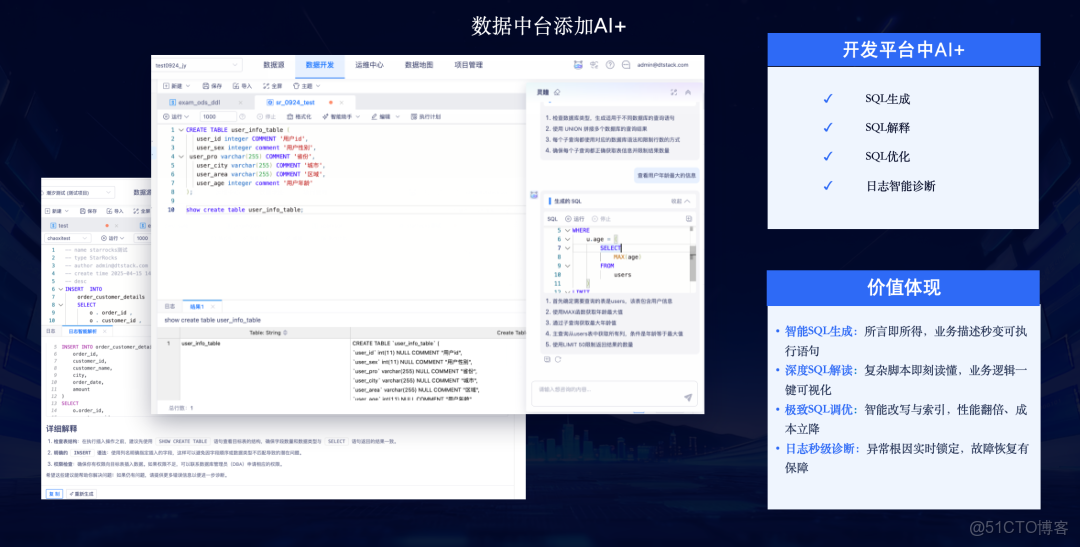
- AI文檔助手:提升報告生成效率 。用户只需上傳一份歷史文檔(如月報)作為模板 ,AI會自動將其中的指標內容標記 ,歸檔為模板並構建指標SQL ,分析師下載新文檔時,AI會自動取數並重新生成最新的文檔 。
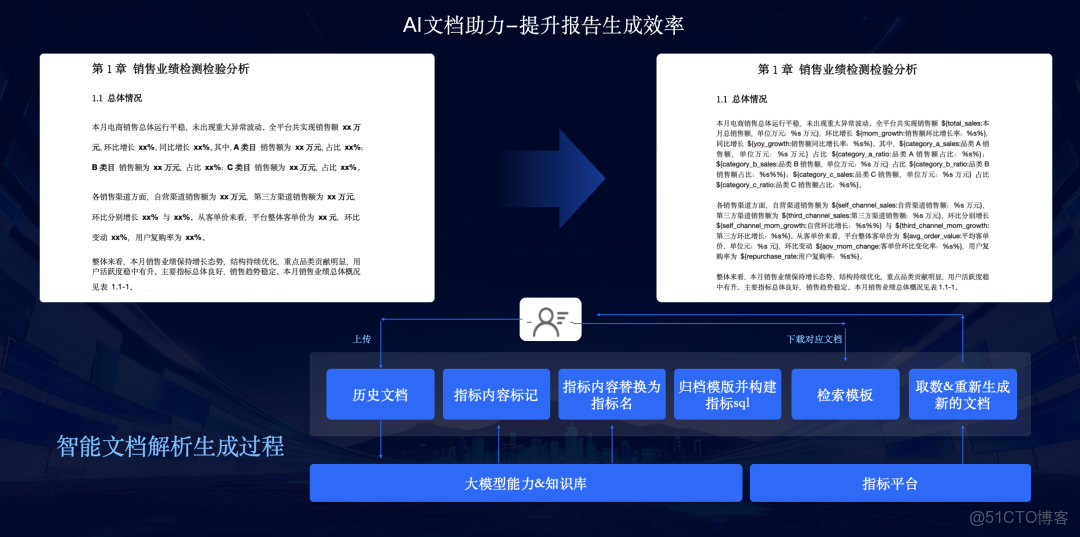
數據賦能 AI數智應用:利用AIWorks打造智能體應用
如果説多模態數據中台是“備料”,那麼袋鼠雲自研的AIWorks智能體應用平台 則是“烹飪”的過程,它負責將數據激活為智能應用 。AIWorks的核心是重構產品交互邏輯,推動產品從“點擊式界面”向“自然語言交互” 、從“單向工具”向“人機協同” 、從“硬編碼規則”向“智能決策” 轉變。
AIWorks 平台重點功能
AIWorks 是一個低代碼與模型編排平台 ,其核心功能包括:

- 可視化與低代碼編排:用户無需編寫複雜代碼,通過拖拽、連接組件的方式,即可像搭積木一樣構建複雜的AI工作流 。
- 靈活的模型與數據源集成:平台內置插件,可無縫對接多種大模型(如GPT、DeepSeek、通義千問 )和企業內部數據源(數據庫、數據湖等) 。
- 強大的工作流調度與管理:內置工作流引擎,負責任務調度、編排 ,支持出錯重試 、並行執行 、條件判斷 等複雜邏輯。
- 可觀測性與持續迭代:平台提供全面的可觀測性能力,包括日誌記錄 、指標監控 和鏈路追蹤 ,確保應用穩定和持續優化。

智能體應用:AIMetrics智能指標問數與分析場景
智能問數與分析作為企業級AI應用的標杆場景,助力企業重新定義數據使用體驗!
①功能特性:
- 精準識別:藉助大模型理解自然語言提問,支持上下文追問與修正。
- 自動分析:自動生成可視化圖表,並一鍵生成數據解讀、特徵洞察和異常校驗。
- 隨處訪問:支持PC、移動端及釘釘、企微等多平台。
- 企業級安全:支持私有化部署,數據不出域,並複用數據平台的權限管控。
②原理解析:
- 用户發起查詢(Query)。
- 系統進行Query改寫(Query Rewrite) ,並進行意圖識別。
- RAG檢索:系統從“指標元信息知識庫” 和“資料知識庫” 中檢索相關信息。
- 參數解析:AI解析出“指標名稱”、“時間維度”、“維度字段”和“維度值” 。
- 數據查詢:調用數據引擎 ,執行數據查詢 (經過權限校驗 )。
- 結果生成:根據需要展示圖表 或進行歸因分析 ,最終返回Result 。
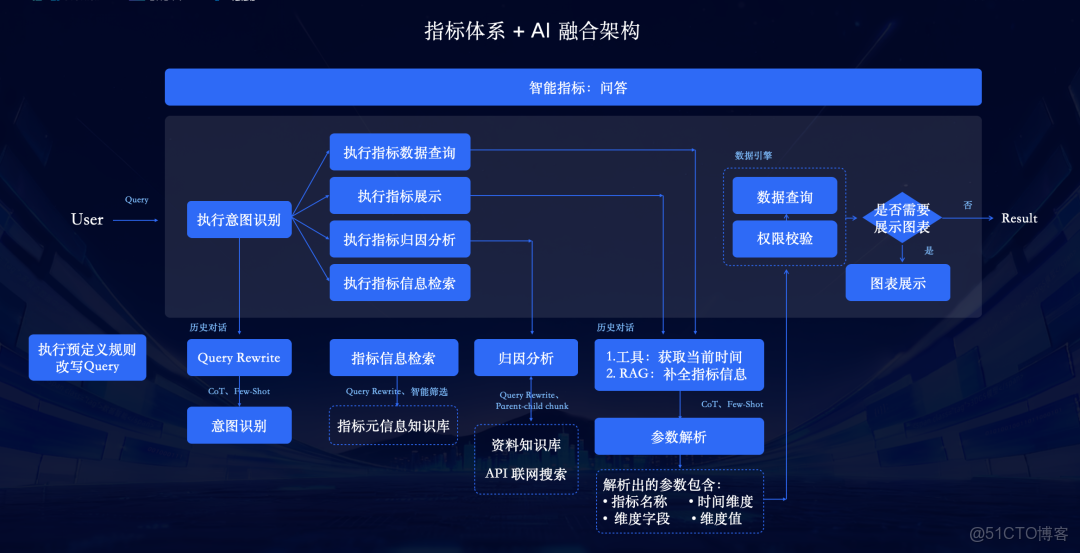
③四大核心場景:
- 智能問數與秒級響應:用户以自然語言提問,系統基於指標語義層快速識別意圖,生成可視化分析結果,真正實現“所想即所得”。相比傳統的數據排隊分析,業務決策響應效率提升一個量級。
- 指標波動監測與根因分析:指標波動自動觸發預警,通過AI與知識圖譜輔助識別異常原因。平台支持時間序列與多維歸因能力,實現問題定位從“被動響應”向“主動識別”演進。
- 趨勢預測與智能目標管理:平台支持結合結構化數據與非結構化語料進行多粒度、多模型的指標預測,並與目標管理閉環結合,實現動態評估、策略調優、結果跟蹤。
- 智能指標知識庫管理:融合指標定義與多模態的業務知識構建知識圖譜,支持AI在回答時同步調取組織語義與歷史策略,不僅提升理解準確率,也實現知識經驗的持續沉澱與複用。

在AI時代的浪潮下,企業構建智能應用已不是“是否要做”的問題,而是“如何做好”的挑戰。袋鼠雲提供的“Data+AI”融合架構 給出了一條清晰的路徑:
- 以 EasyMR 為基石 ,解決大數據底座平台的自主可控、國產信創兼容和穩定運維問題。
- DataZen多模態數據中台,通過“三大統一” 將結構化、半結構化乃至視頻、圖像、文檔等非結構化數據全面“AI-Ready”。
- 利用 AIWorks 智能體開發應用平台作為“激活器”,通過低代碼編排和模型調度能力 ,將沉睡的數據轉化為智能問數、風控審核、AI Copilot等高價值智能體應用。
- 垂直應用深耕例如AIMetrics智能指標應用平台,“指標+AI”將不僅是一個抽象概念,更是一套具備工程落地路徑、行業Know-how、智能協同能力的完整體系。它打通了數據治理與智能應用的閉環,將“指標”作為AI理解企業業務的語義底座,將“AI”作為指標能力釋放與組織協同的加速器,從實踐中可以看到“指標+AI”都已經展現出其穿透式、結構化的解決力。
從堅實的數據底座,到包羅萬象的多模態中台,再到敏捷的智能體應用,這一整套解決方案正在幫助企業構築AI時代的真正護城河 ,驅動業務實現智能躍遷。