
隨着人工智能技術在業務中的滲透,我們逐漸意識到:AI 不僅是提升效率的工具,更是重構數據處理與消費方式的核心驅動力。在這一背景下,我們思考:能否構建一款「AI + Data」一站式融合的數據引擎? 它不僅能夠統一處理文本、音視頻等非結構化數據與傳統結構化數據,還能為算法工程師提供流暢的數據開發體驗,實現數據處理與 AI 模型無縫銜接,並能確保數據處理負載與在線服務負載完全隔離。這是 2024 年末啓動 DataMind 項目的初衷。
本文整理自字節跳動 DataMind 負責人郭澤暉在 Doris Summit 2025 中的演講內容,並以演講者第一視角進行敍述。
一、DataMind:Doris + AI 一站式融合數據引擎
在項目啓動前,我們評估了多種市面上的開源方案,但未能找到完全符合 AI + Data 引擎需求的產品。因此,我們決定選擇一款優秀的 OLAP 數據庫,並在此基礎上融合和增強 AI 功能。Apache Doris 憑藉完善的功能、卓越的 OLAP 性能、豐富的生態體系、活躍的社區氛圍及良好的產品口碑吸引了我們的注意。
與此同時,我們瞭解到社區也在積極探索 Doris 與 AI 能力的結合,因此決定在 Apache Doris 基礎上二次開發,打造一站式引擎——DataMind。這些能力包括:
- Hybrid Search:將基於文本相似性、語義相似性、業務規則匹配這三種能力集成至 Doris 中,並在此基礎上補齊了向量檢索及 Tablet-level BM25 能力。(詳見章節二)。
- AI Function:基於 Doris 補齊了 AI_QUERY 和 TEXT_EMBEDDING ,並支持了 Python UDF。(詳見章節三)
- GraphRAG :在基於 Doris 的 DataMind 產品上構建了 GraphRAG,應用層研發團隊能夠更便捷地接入新的 AI 能力,縮短研發週期。(詳見章節四)
目前,我們已將部分 AI 融合的實踐成果貢獻給開源社區,大家可從 Doris 4.0 版本 中關注。
這些能力不僅是 Datamind 的重要組成,也是構建企業級 AI 問數平台奠定了堅實的技術基礎。後文將逐一展開其設計思路、實現路徑與優化實踐。
二、Hybrid Search 能力集成
AI 場景下典型的混合搜索的架構可以概括為三種搜索方式:基於文本相似性、語義相似性、業務規則的匹配。這三路的搜索結果會在後端統一排序,排序方法依賴自訓練的模型,分為粗排和精排兩個階段。粗排模型可提高處理性能,精排模型實現更優的重排序效果,平衡整體開銷。
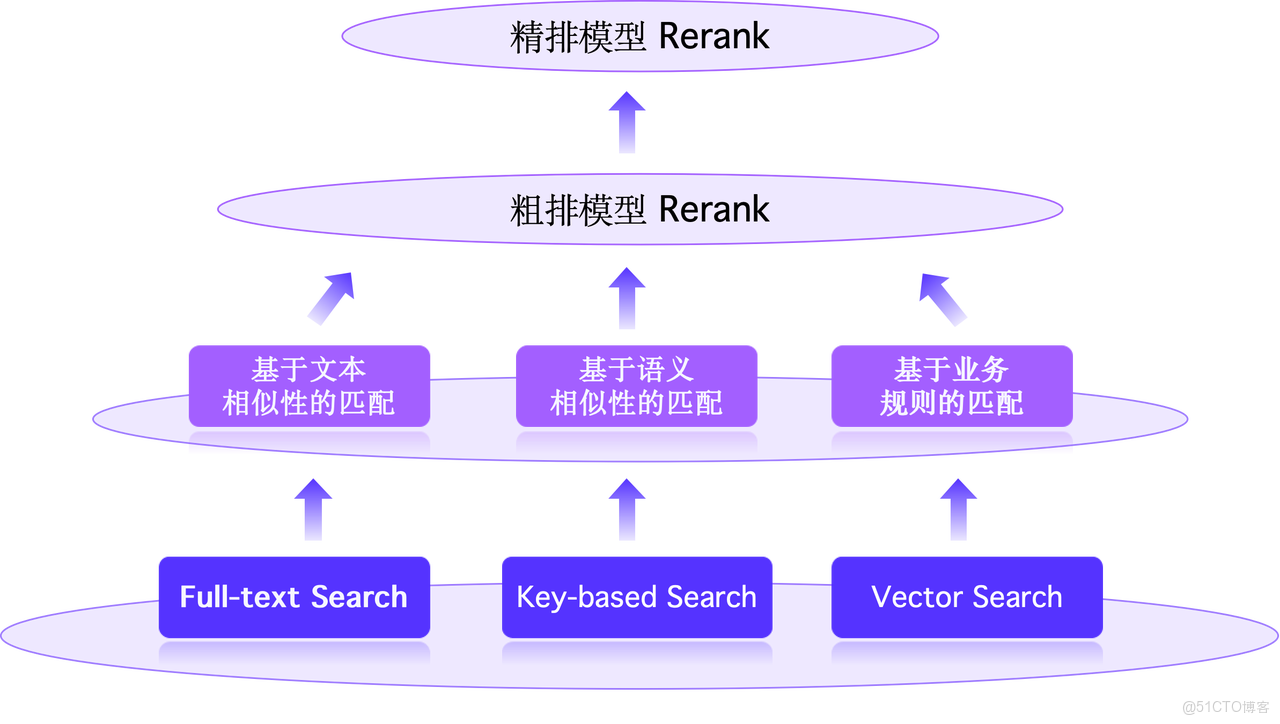
我們希望將這三類搜索能力集成至基於 Doris 的 DataMind 引擎之中,讓用户只需導入一份數據,並在完成必要的處理及索引構建後,即可直接上線服務,無需介入其他三方工具。為實現這一目標,團隊基於 Doris 補充了向量索引和 BM25 打分函數這兩項核心能力。
2.1 向量索引
我們基於 Faiss (Facebook 開源的 AI 相似性搜索工具)實現了 HNSW 與 IVF_PQ 兩種 ANN 算法的向量索引。HNSW 在大規模數據集上性能表現更優,但資源開銷較大; IVF_PQ 在大規模數據集上,成本與性能表現更加均衡。
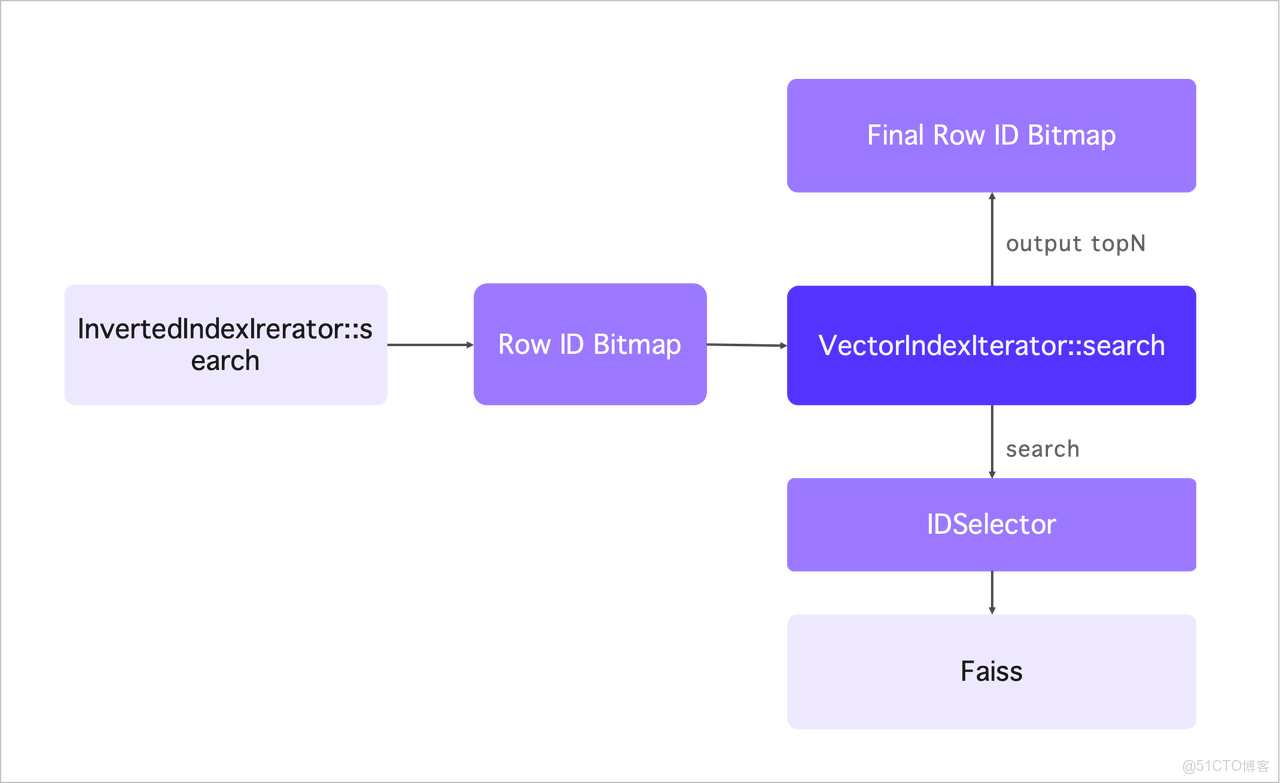
向量索引支持與其他索引條件組合使用。比如,可將倒排索引的結果通過 Faiss 提供 IDSelector 接口傳遞到底層 ANN 算法實現上以控制搜索過程。基本原理是:倒排索引首先檢索匹配行號的 Bitmap,這一 Bitmap 被傳遞給 Faiss 庫。當進行向量搜索時,Faiss 會將搜索範圍限制,最終輸出 TopN 行號結果,代表融合後的結果集。當倒排索引在第一階段篩選出的數據量較少時,會跳過向量索引進行暴力計算,這樣耗時更短、時間更精準。
2.2 Tablet-level BM25
BM25 是一種用於信息檢索的排名函數,用於衡量查詢與文檔的相關性。它基於詞頻(t)和文檔長度進行加權計算,同時考慮逆文檔頻率(IDF)以懲罰常見詞。在整個公式中,需重點關注總文檔數 N 和文檔頻率 DF 等全局統計信息,這些信息直接影響實現的難度。(更多信息可自行搜索查閲)
在 Doris 的設計中,一個 segment 對應一個倒排索引的解決方案,因此在 segment 級別實施 BM25 較為簡單,系統可以基於每個 segment 的統計信息(如總文檔數 N 和文檔頻率 DF)計算每一行的得分。然而,合併小 segment 可能導致統計信息變化,從而影響 BM25 得分,造成用户評分波動,這在生產環境中不可接受。
為了避免此問題,團隊將 BM25 公式提升至 tablet 級(tablet-level)。所有全局統計信息(包括 N 和 DF)需基於整個 tablet 聚合,以保持得分結果的一致性。
以 Merge on Write / Merge on Write 為例:
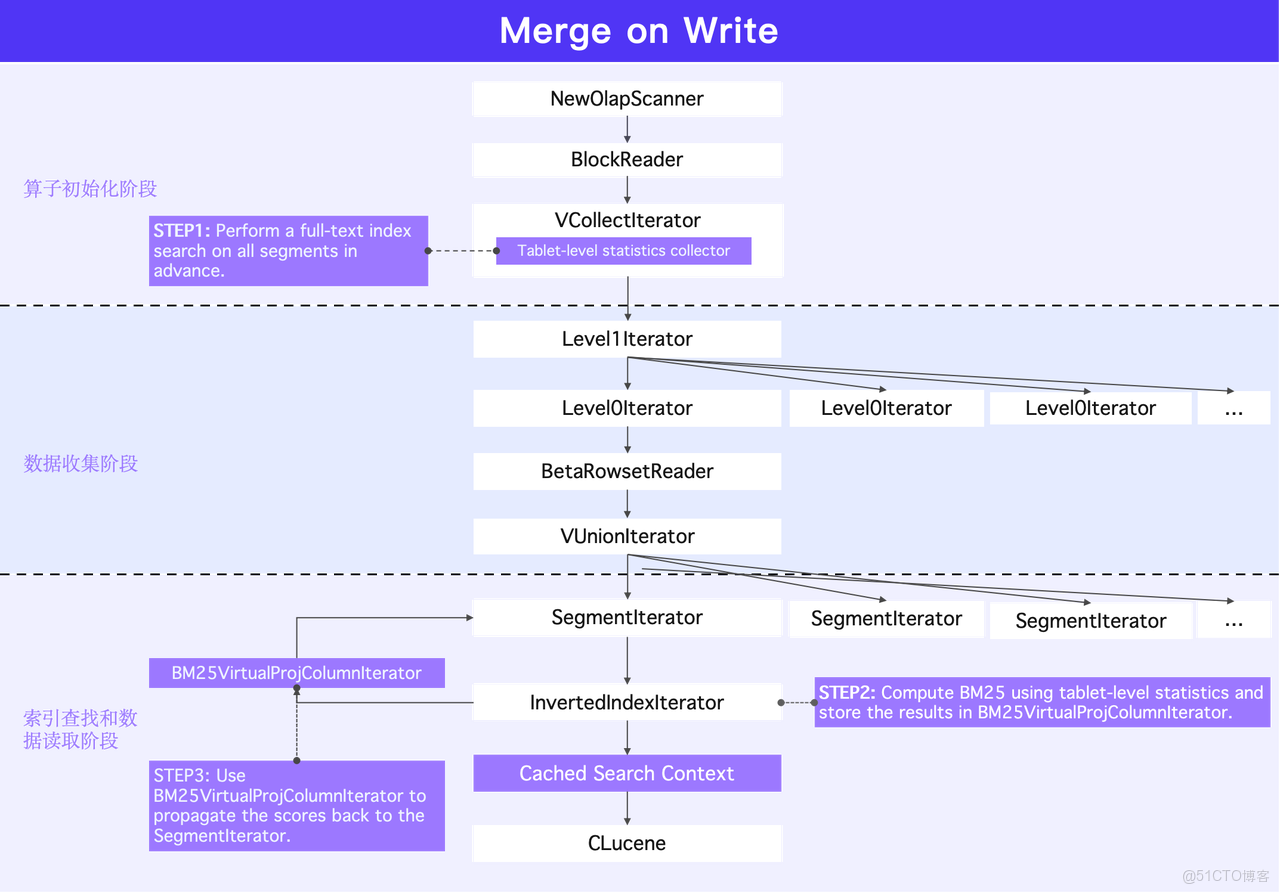
- 在 Scan 算子初始化階段:系統會預先搜索用於 BM25 計算的 tablet 級 統計信息。每個 segment 會被依次掃描,並以流式方式輸出數據塊。
- 數據收集階段:在處理每個 segment 之前,需計算完整的 tablet 級統計信息。Scan 算子初始化時,系統使用相應搜索條件訪問每個 segment 的解決方案。此過程中產生的文件操作、數據讀取和內存命中等結果構成搜索上下文信息。同時,與搜索相關的對象會被緩存,以避免重複產生 IO 開銷。
- 索引查找及數據讀取:當正式進入某個索引後,索引搜索將基於此前收集的 tablet 級統計信息,為命中的每一行計算分數。最終,計算所得的分數通過虛擬列的迭代器返回到 segment,隨數據塊輸出。
2.3 搜索框架優化
在補充了向量索引和 BM25 能力後,我們面臨一個新問題:在混合搜索框架中,涉及的函數並非傳統意義上在計算層基於輸入直接進行求值,而是必須在索引檢索的過程中計算出結果,因此需要設計一套特殊的投影下推流程,具體實現如下:

在執行計劃層,我們將相關函數替換為虛擬列,並將這些虛擬列下推至 OlapScanNode。OlapScanNode 攜帶虛擬列的信息,將其傳遞到接近索引計算與查詢塊存儲邏輯的執行路徑中。
在索引計算過程中,系統基於這些虛擬列計算向量距離分數和 BM25 相似性分數,並將結果填充回對應的 block。最終,帶有虛擬列計算結果的 block 由 Scan 算子輸出,並傳遞至下游算子,以自然銜接的執行計劃完成整個檢索流程。
三、AI Function 補齊
在 AI Function 上,主要基於 Doris 補齊了 AI_QUERY 和 TEXT_EMBEDDING 兩種函數。
3.1 AI_QUERY
該函數用於調用大模型並能較好地處理非結構化文本這類數據,將其轉化為結構化數據,再進行傳統分析。例如,對於一張客户評價表,可以讓大模型為每條評價打分並分類,如好評輸出 1、差評輸出 0,通過統計即可得出好評與差評的大致數量。
WITH reviews AS (
SELECT
AI_QUERY('volcengine/Doubao-pro-128k-240628', concat('判斷這條產品評價是好評還是差評,好評輸出1,差評輸出0:', review_txt)) AS review_type
FROM customer_reviews
) SELECT review_type, count(*) AS cnt
FROM reviews
GROUP BY review_type
3.2 TEXT_EMBEDDING
該函數主要有兩個階段:
- 數據清洗階段:在 AI 清洗過程中生成對應向量並構建向量索引。
- 數據查詢階段:此階段提供兩種使用方式。第一種是由用户的應用層代碼自行生成查詢向量,並作為參數傳入 SQL 進行搜索,該方式需傳入較長的向量 float 數組,會增加優化器的解析開銷。第二種方式是直接調用 TEXT_EMBEDDING 函數,將查詢文本傳入並執行搜索,這種方法更為便捷,且性能更佳。
SELECT
content,
APPROX_COSINE_SIMILARITY(
TEXT_EMBEDDING('volcengine/Doubao-embedding-240715', 'Doris Summit'),
content_vec_col) AS score
FROM my_table
ORDER BY score
LIMIT 7;
3.3 Python UDF 的實現
除上述標準函數外,我們基於 Doris 支持了 Python UDF,以滿足自部署模型的需求,包括 Rerank 模型、Embedding 模型、甚至大模型的訪問需求,以及依賴 Python 庫進行非結構化數據處理的需求場景。
Python UDF 的核心設計主要包含幾個關鍵點:
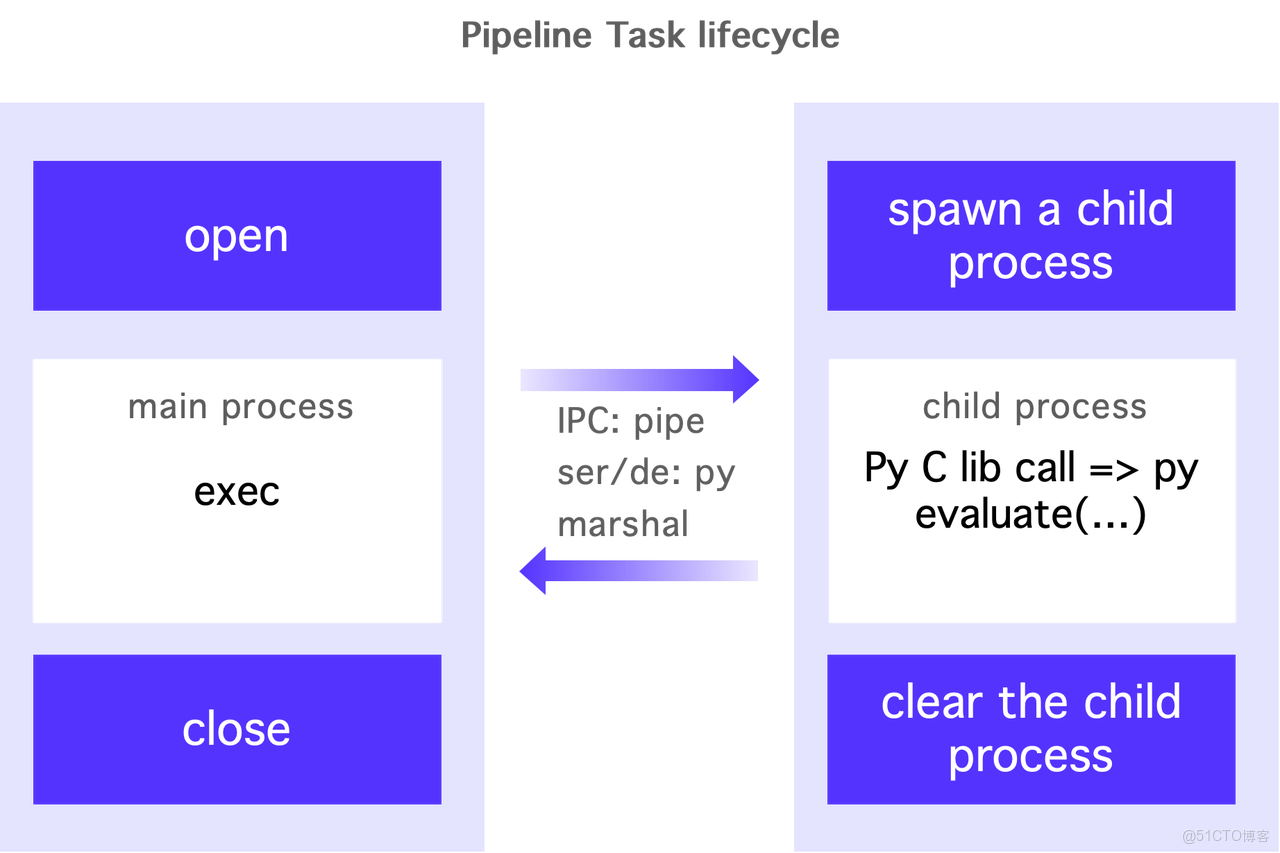
- 多進程架構:旨在解決 UDF 之間的隔離問題,避免 Python 的全局解釋器鎖(GIL)。每個 Python UDF 能通過虛擬環境(venv)實現依賴隔離。
- 生命週期綁定:執行 Python 的子進程與 Doris 的 pipeline task 生命週期綁定。當一個 pipeline task 生成時,相應的子進程也會被創建,並在任務結束時進行清理。這種設計使得併發模型與 Doris 的計算引擎密切結合,用户只需調整 Doris 的併發參數即可管理 Python UDF 的執行併發,簡化了維護工作。
- 數據傳輸和序列化:主進程與子進程之間的數據傳輸通過管道進行。支持 Python 原生對象輸入輸出的版本採用 Python 的 Marshal 機制進行序列化。
如下方代碼示例,示例中展示了混合搜索(向量+全文檢索)的應用,兩個檢索通過用户自研的 Python UDF 模型進行重排序,最終使用 Hybrid Search 進行數據攝取。在 AI Function 和 Python UDF 的加持下,用户只需通過一條簡單的 SQL 語句即可串聯整個業務搜索流程及數據處理流程,使用十分便捷。
CREATE FUNCTION predict_class(ARRAY<FLOAT>) RETURNS INT
PROPERTIES (
"file"="https://cloud-storage/obj/datamind/pyudf.zip",
"symbol"="predict_class",
"type"="PYTHON_UDF"
);
WITH channel_1 AS (
SELECT
content
FROM my_table
ORDER BY
APPROX_COSINE_SIMILARITY(py_udf_embed('Doris Summit'), content_vec_col) DESC
LIMIT 7
),
channel_2 AS (
SELECT
content
FROM my_table
WHERE MATCH_ANY(content, 'Doris Summit')
ORDER BY
BM25() DESC
LIMIT 7
)
SELECT
content
FROM (
SELECT content FROM channel_1
UNION ALL
SELECT content FROM channel_2
) t
ORDER BY py_udf_score('Doris Summit', content) DESC
LIMIT 7;
四、GraphRAG on DataMind
4.1 GraphRAG
GraphRAG 是一種結合圖數據庫與 RAG(Retrieval-Augmented Generation)技術。推動 DataMind 集成 GraphRAG 功能的原因是,我們在推廣 AI 功能時發現多個業務團隊對此有需求。與標準 RAG 相比,GraphRAG 的實現過程更為複雜,需要在基礎 AI 能力上進一步構建。
構建階段:該階段的輸入為文檔或分割成的片段(chunk)。利用大模型(AI Function)進行實體抽取——從文檔中提取出關鍵信息,實體之間的關係可以看作是圖中的邊,每條邊具有一定的權重,這些權重由大模型自動識別,提取的實體及其描述經過向量化後存儲,以構建索引。
此外,圖結構和邊的描述也會存儲在一張表中。基於該圖,系統利用 Search 發現算法(如 Lighting)進行聚類,將相似的實體歸類為一個 Search,並生成 Search 報告。
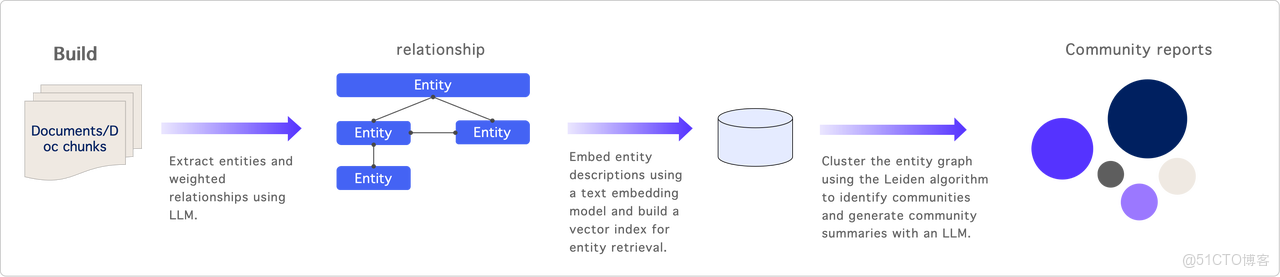
查詢階段:在檢索過程中,首先將 Query 轉換為向量,該向量用於 Search 實體,以找到與之相關的 Top-K 實體。得到 TopK 實體後,系統將召回它們相關的邊,這些邊包含與實體相關的描述和信息,以及這些實體關聯的報告和原始文檔的片段。在有限的上下文內,系統會按優先級拼接相關內容,形成最終上下文,隨後將其輸入 AI 以生成回答。

4.2 GraphRAG on DataMind
基於 Apache Doris 的 DataMind 產品上如何構建 GraphRAG 呢?整體設計分為多層,如下圖所示:
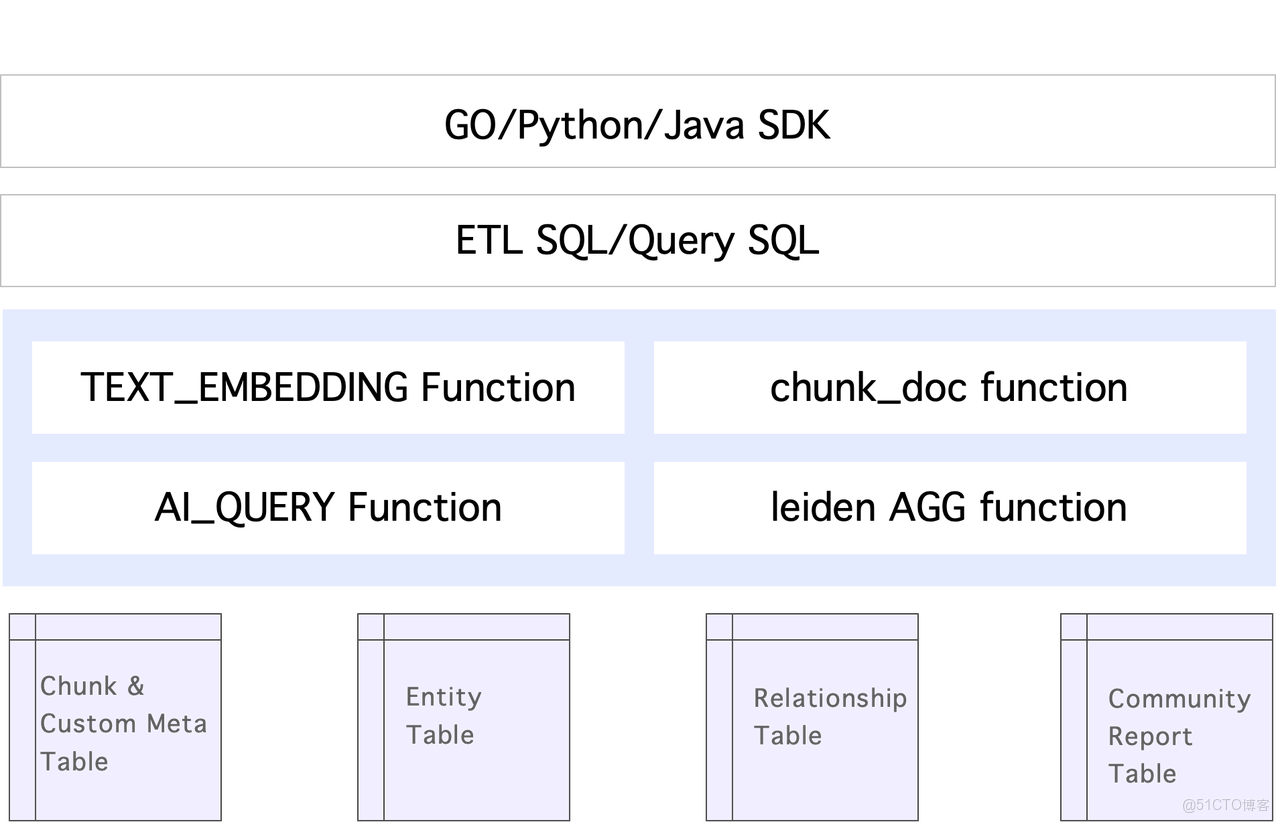
最底層是表結構的設計,包括實體表、Search 表以及用户自定義的源數據表等。在此基礎上,通過一系列函數,包含用於文檔切分的函數、Leiden 聚合函數等等,最後結合 ETL SQL、Query SQL 等,共同實現 GraphRAG 的構建與查詢流程。
由於底層 SQL 相對複雜,團隊在這些 SQL 上封裝了 Go、Python 與 Java 的 SDK,以方便用户使用。用户只需調用如 build 或 import 等接口即可完成數據導入與構建,再通過 query 接口實現查詢能力。這樣一來,應用層研發能夠更快速地接入新的 AI 能力。只需使用 Apache Doris 數據庫並結合團隊提供的 SDK,即可直接將業務流程跑通並驗證效果。
五、企業級 AI 問數 Datamind 落地方案
企業級 AI 問數是當前行業內較為經典且熱門的探索方向。行業內普遍採用 NL2SQL 直接查詢 Apache Doris 等數據庫的模式。那麼,字節是如何落地的呢?
5.1 企業 AI 問數理想架構
首先,我們基於 Doris 構建了湖倉一體的數據架構,以數據湖為中心,外部業務系統或企業內部信息系統(如 RDS、API 取數),數據經過 DTS 等工具攝入,最終沉澱在雲存儲中,呈現為傳統 Hive 的原生 Parquet 格式。隨後,數據通過 Spark 或 Flink 進行 ETL 清洗,遵循標準的 Lambda 架構,最終生成可供消費的數據,並存儲至 OLAP 引擎 Apache Doris 以實現查詢加速。
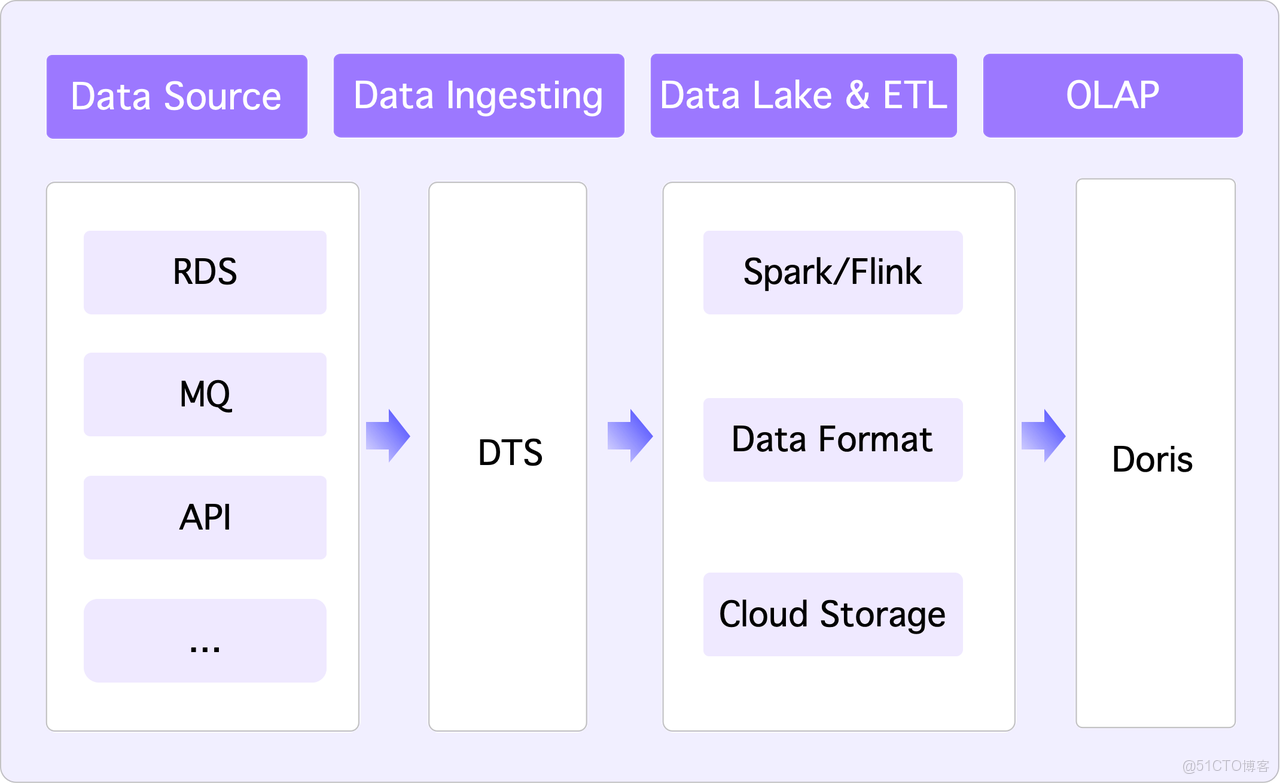
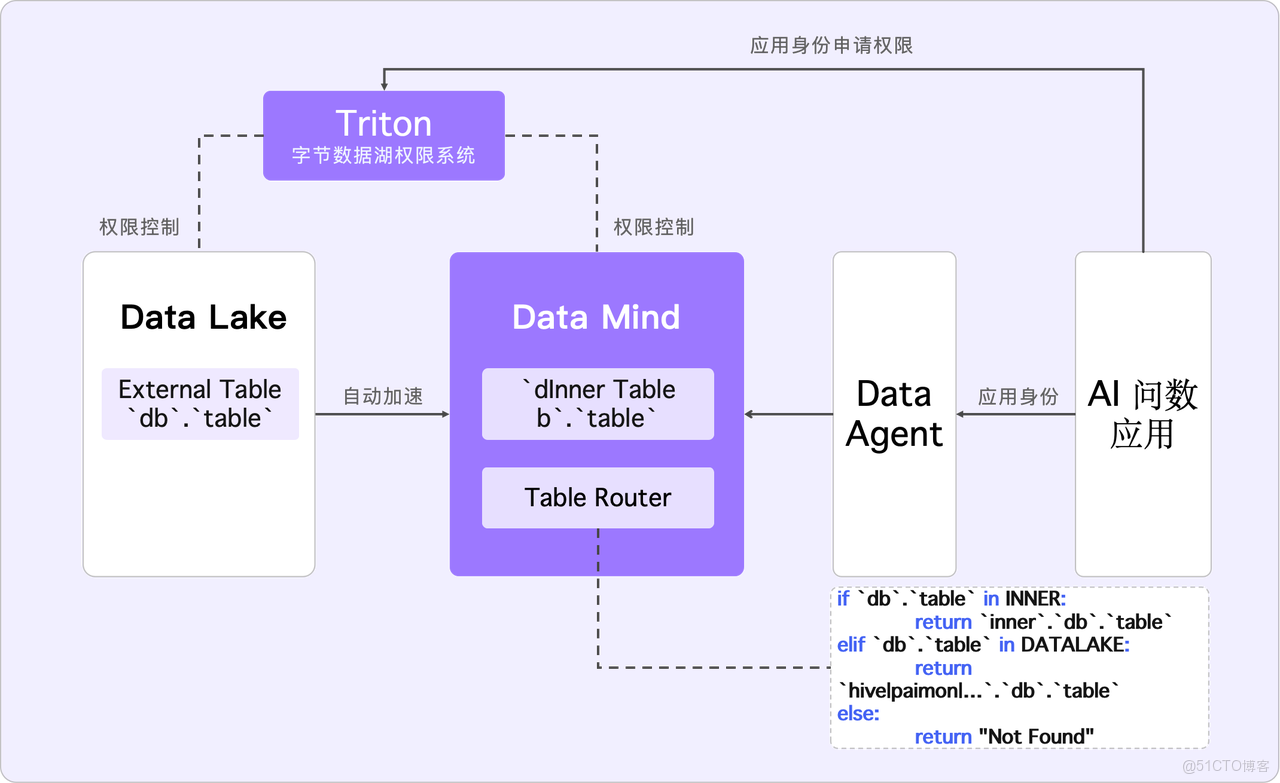
若要利用 AI 進行數據消費,以實現類似企業智能體的功能,它需要訪問所有企業信息系統的數據。因此,我們期望的理想架構處理流程應如下圖:
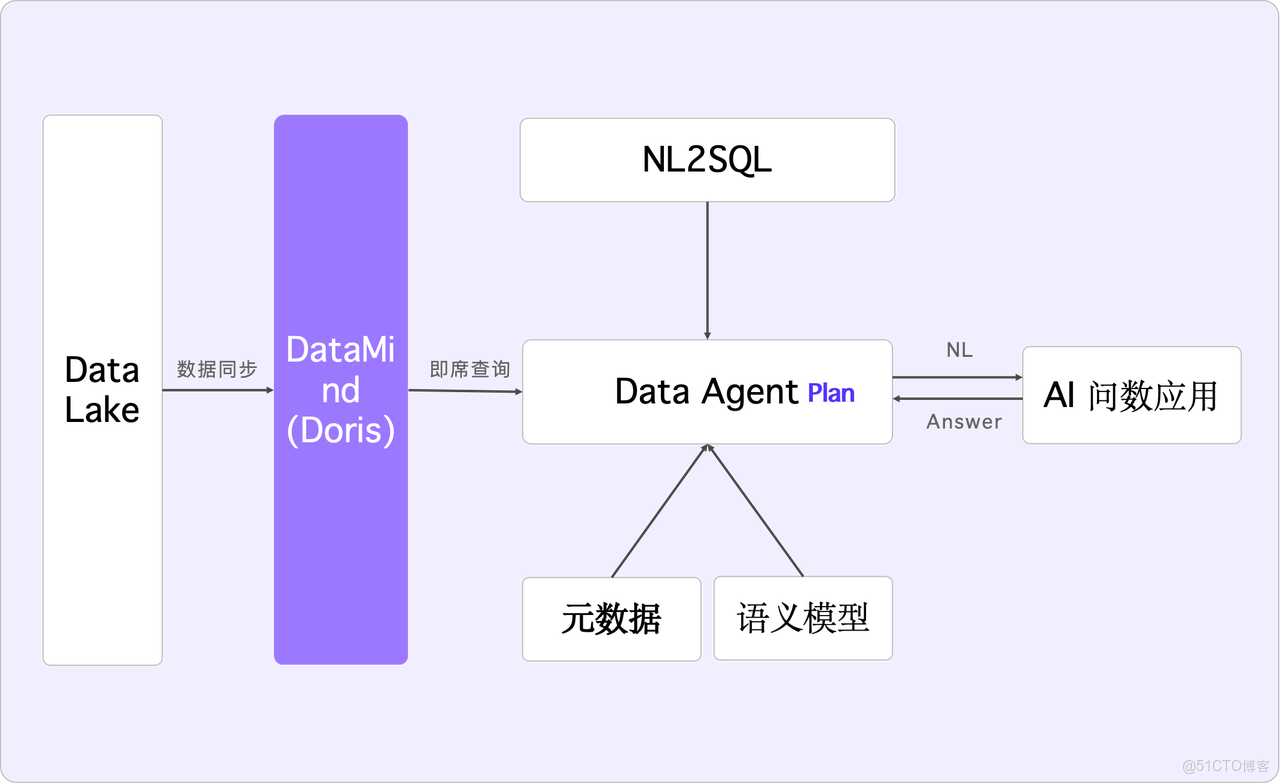
具體流程:AI 問數應用通過 Data Agent 調用 NL2SQL 這類外部工具,Data Agent 採用 Plan Execute 或 React 模型規劃執行路徑,需要元數據以及依據業務自定義的語義模型——簡單理解為表字段的描述,基於這些信息,Data Agent 生成取數 SQL,併發給 Apache Doris(即 DataMind) 加速執行,最終將數據返回到 AI 問數應用層。在這其中,Apache Doris 主要作用是將湖上的數據同步到其內部進行查詢加速。
而這種理想處理方式面臨數據安全性及查詢延遲等問題,比如:
- 數據湖中的數據量龐大,全部同步到 Apache Doris 並不現實,且敏感數據也不宜全量同步。
- 當數據加速到 DataMind 後,Apache Doris 的內表與外表存在差異。加速會影響 SQL 的 Catalog 語法,例如加速後,外表的 Catalog 名稱為 Hive,內表則為 Internal。這對 AI 生成 SQL 產生一定影響,迫使 AI 必須感知是否存在加速。
5.2 企業 AI 問數最終架構
為解決上述問題,我們進行了如下優化,具體改進為:
- 改進 Data Agent 查詢的路由機制:用户只需書寫庫表名,系統將在優化器階段自動判斷路由、補全表名。用户對於 Data Agent 的使用,只需理解數據湖中的 Schema,無需關注表是存儲在數據湖還是已加速至 Apache Doris。
- 數據湖權限系統的打通:我們的數據湖擁有獨立的權限管理系統,控制讀寫訪問。將數據加速至 Apache Doris 相當於複製一份數據,可能導致安全管控失效。為解決這一問題,我們設計了機制:即使數據同步至 Apache Doris,其權限仍受 Triton 數據湖權限系統管控,且與 Apache Doris 的賬號密碼無關。這一設計確保應用層在數據湖上申請的權限依然有效,加速後無需額外權限申請。此外,這一機制保證了即使數據同步到 Apache Doris,持有其賬號密碼的人員(如 DBA),未經原數據湖系統申請的權限仍無法訪問。
六、結束語
Doris + AI 一站式融合數據引擎 DataMind 的實現,已在字節內部應用一段時間,並在持續推廣之中,典型應用場景包括智能簡歷搜索、ByteRAG 平台、CapCut 內容治理等。且在 GraphRAG 上線後,團隊與多方客户合作實現了場景落地,例如廣告場景、代碼搜索的場景,以及近期業界關注的 PRD2Code 等研發提效場景 。


未來,我們還會在 DATA + AI 上繼續探索,搭建更加完善的企業 AI 問數架構。此外,我們將保持與 Doris 開源社區的緊密聯繫保持聯繫,積極參與共建併為社區提供反饋。