
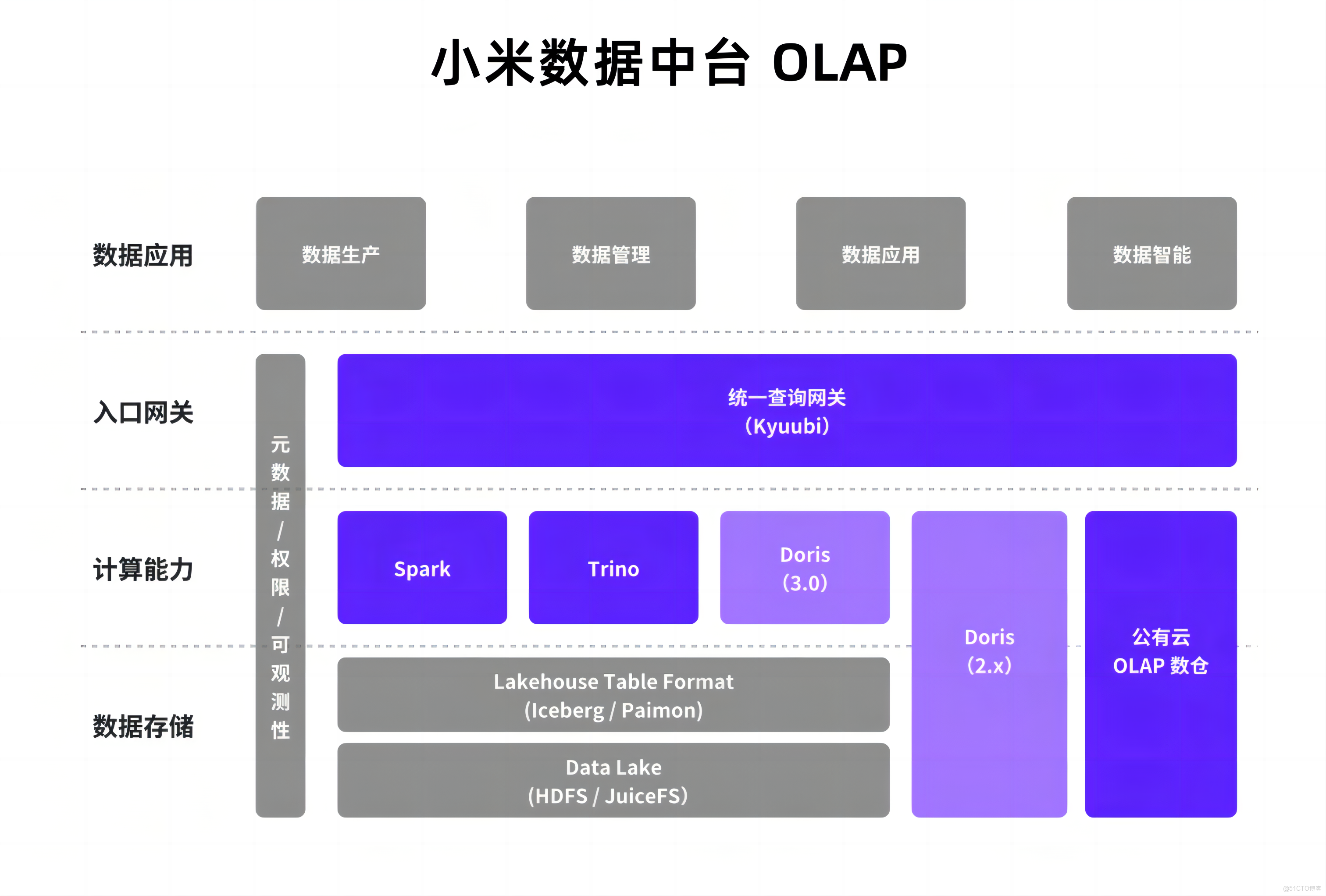
小米早在 2019 年便引入 Apache Doris 作為 OLAP 分析型數據庫之一,經過五年的技術沉澱,已形成以 Doris 為核心的分析體系,並基於 2.1 版本異步物化視圖、3.0 版本湖倉一體與存算分離等核心能力優化數據架構。本文將詳細介紹小米數據中台基於 Apache Doris 3.0 的查詢鏈路優化、性能提升、資源管理、自動化運維、可觀測等一系列應用實踐。
小米集團成立於 2010 年,是一家以智能手機、智能硬件和 IoT 平台為核心的全球領先科技企業,業務遍及全球 100 多個國家和地區。小米構建了全球最大的消費類 IoT 物聯網平台,同時持續推進“手機×AIoT”戰略。旗下產品涵蓋智能手機、電視、筆記本、可穿戴設備及生態鏈智能產品,並投資孵化眾多智能科技企業。
Apache Doris 在小米內部應用廣泛,業務涵蓋汽車、手機領域(包括手機系統應用與硬件製造)、互聯網、線上線下銷售與服務、底層平台以及新業務等多個領域,支撐着多樣化的數據分析需求。目前,Doris 集羣數量超過 40 個,管理數據規模數 PB,日均查詢量達到 5000 萬次,資源規模在近一年內增長約 80%,展現出快速發展的態勢。

小米數據中台 OLAP 發展與挑戰
01 架構演變歷程
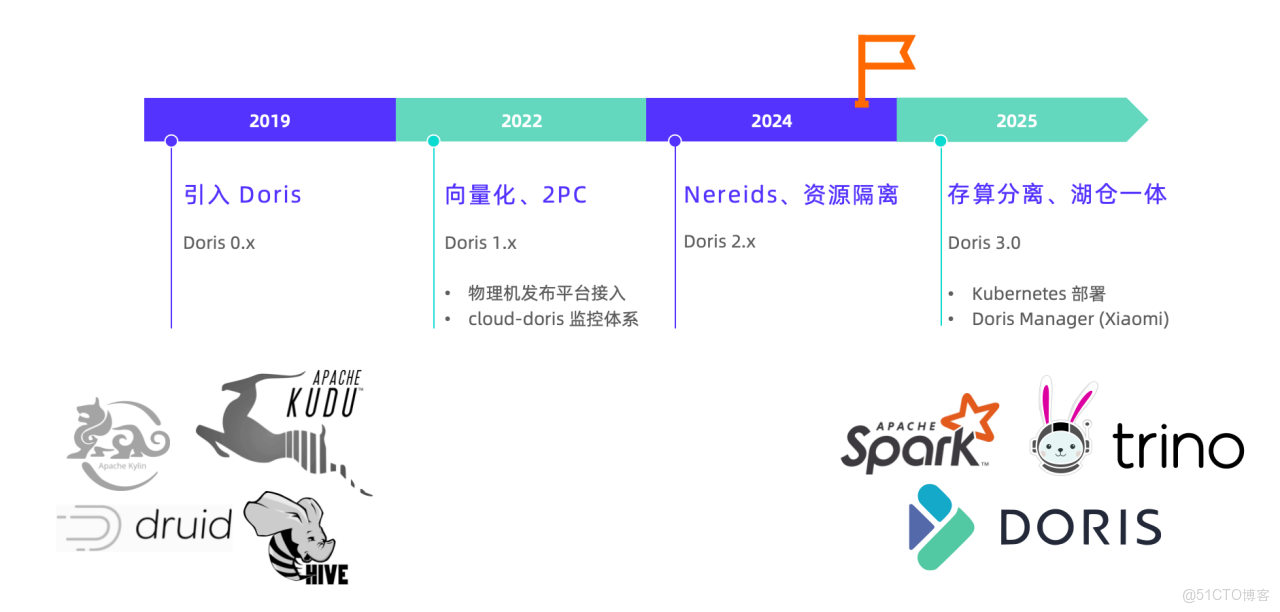
早期小米技術棧複雜多樣,數據湖體系與 OLAP 引擎眾多。自 2019 年在小米內部投入應用以來,Apache Doris 逐漸從中脱穎而出,發展成為小米數據架構的核心引擎。
一方面,Apache Doris 整合了內部複雜的 OLAP 分析體系,統一承載起原本由多系統分散提供的查詢能力;另一方面,Doris 憑藉出色的查詢性能與良好的生態兼容,配合 Trino、Spark、Iceberg、Paimon 等完成了從外倉到湖倉一體架構的關鍵升級。
2022 年起,Doris 在小米內部已形成了較為成熟的應用體系:依託內部發布平台,在物理機上實現集羣的自動化部署與運維;同時接入內部監控體系,全面保障 Doris 集羣的可觀測性與穩定性。
2025 年,我們正式引入了湖倉一體與存算分離能力成熟的 Doris 3.0 穩定版本,與 2.1 版本並行運行,並針對 Doris 3.0 在管理層面進行了重大調整:引入集羣編排系統,並基於 Doris Manager 自主開發了集羣管理系統,提供更全面、標準化的運維與可觀測性方案。
02 外倉面臨的挑戰
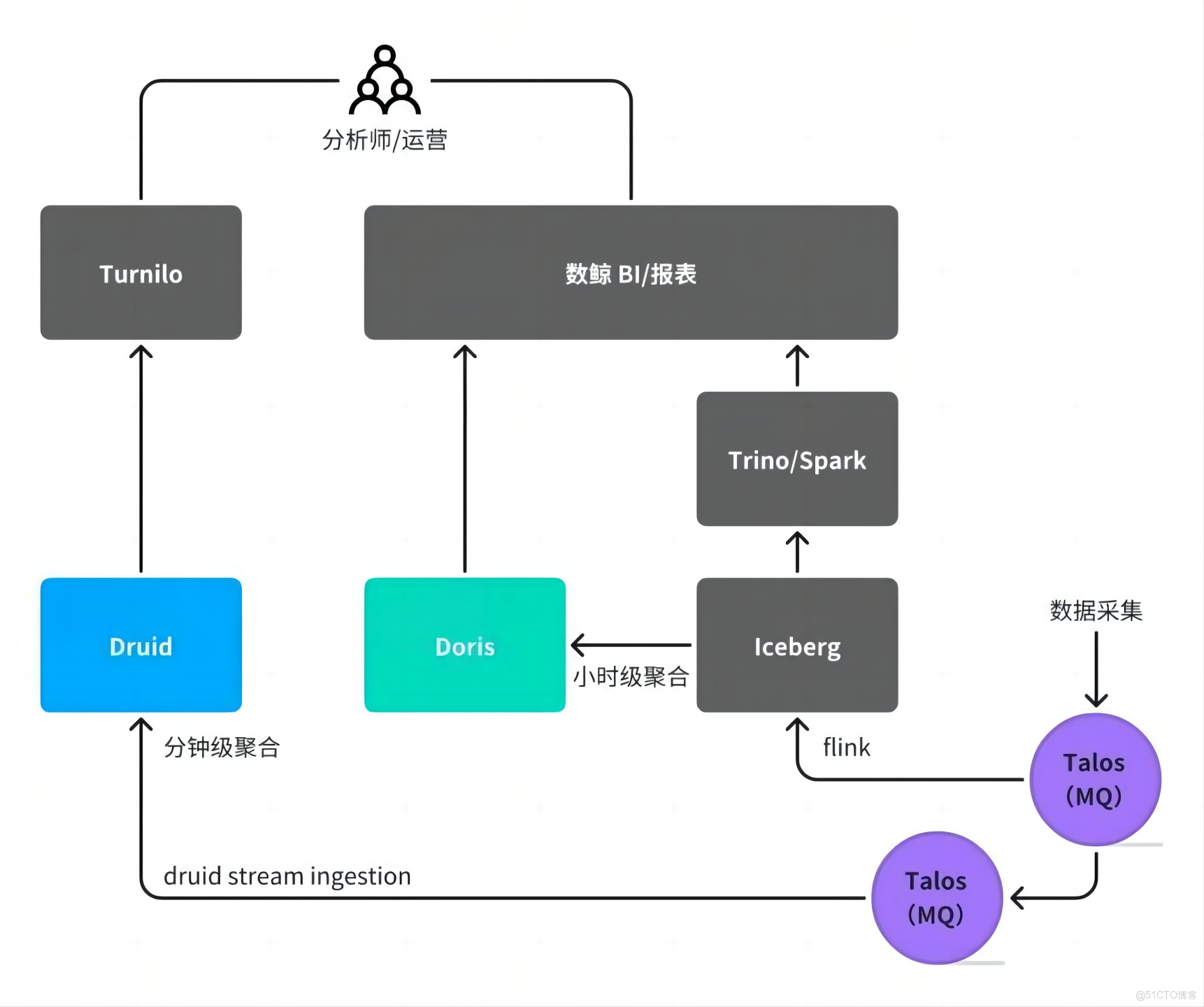
小米早期 OLAP 體系中,離線數倉視為“內倉”,而 OLAP 服務則歸為“外倉”,內外倉的數據流動依賴 Flink 或 Spark 等數據集成工具。團隊主要負責 Doris 集羣的部署與日常運維,在此過程中,我們遇到了諸多來自用户和自身的痛點問題,下面將結合業務場景介紹。
跨系統數據集成
數據通過 Flink 或 Spark 從離線的內倉抽取至 Doris,形成跨系統數據流動。這種模式帶來一系列挑戰:
- 數據冗餘:同一份數據在多個系統中存儲,增加成本;
- 口徑不一致:不同系統處理邏輯差異導致結果偏差;
- 排查困難:當 BI 看板數據出現差異時,需跨多個系統定位問題;
- 開發負擔重:業務方需自行維護 ETL 鏈路和多套查詢接口。
以廣告業務為例,其數據鏈路涉及多個存儲系統(如 Iceberg、Druid)和同步任務,分析師需根據查詢粒度選擇不同系統,心智負擔顯著。對開發側而言,需針對不同數據鏈路進行定製化開發,同時在多個系統上重複建設數據看板,導致開發工作重複、週期長,整體投入成本較高。
存算一體架構侷限
1、高可用容災
2023 年海外機房火災事件暴露了存算一體架構的脆弱性,雖然數據最終恢復,但也促使團隊重新審視數據高可用策略。針對 Doris 2.x 的高可用方案,團隊曾評估兩種路徑:
- 主從複製(CCR):依賴較新版本支持,缺乏生產驗證,主備切換複雜,客户端需雙連,恢復時間長;
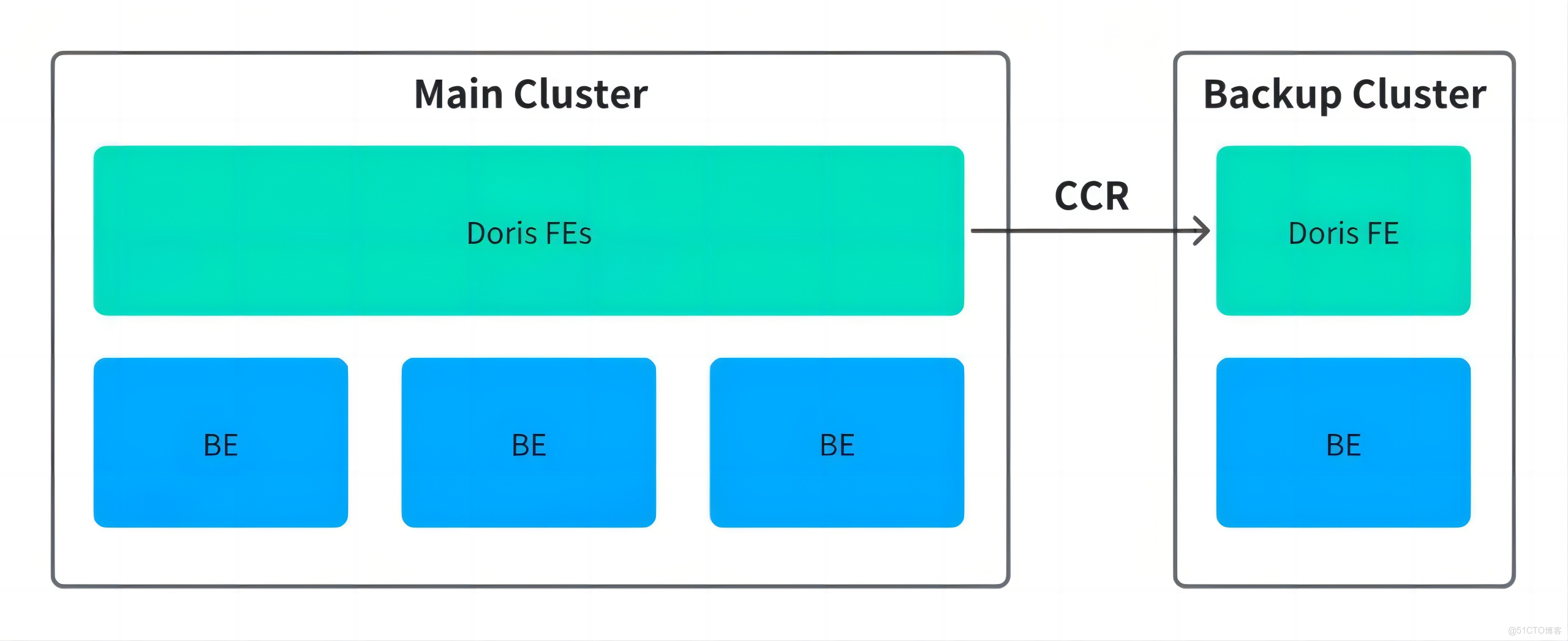
- 跨可用區副本分佈:通過 Resource Group 將副本分散至不同機房,雖可避免單點故障,但跨機房讀寫帶來性能損耗。

最終採用後者作為臨時方案,但仍未根本解決成本與可用性之間的矛盾。
2、資源利用率低
物理機部署模式下,構建一個高可用 Doris 集羣需要 3 FE + 3 BE,對於中小規模業務而言,此配置遠超實際需求,導致資源浪費嚴重。若為每個小業務獨立建集羣,將導致集羣數量激增,運維壓力劇增;若採用共享集羣,則面臨資源爭搶、隔離困難、計費模糊等問題。
直到 Apache Doris 3.0 發佈後引入存算分離版本,高可用容災與資源彈性問題得到解決,下個章節將詳細展開介紹。

集羣運維效率低
原有基於物理機的手動部署流程,從申請資源到集羣上線通常耗時一週以上。面對快速增長的業務需求,該模式已無法滿足敏捷交付要求。
Apache Doris 3.0 應用實踐與突破
基於上述挑戰,Doris 2.0 及早期版本在湖倉一體、存算分離、集羣自動化運維等方面仍有不足,而 3.0 存算分離版本帶來了諸多升級,經過一段時間的驗證,團隊規劃出 3.0 版本與早期版本並行的升級架構,並在 3.0 版本的基礎上對架構設計與使用模式進行了顯著優化。
01 Doris 3.0 核心優勢
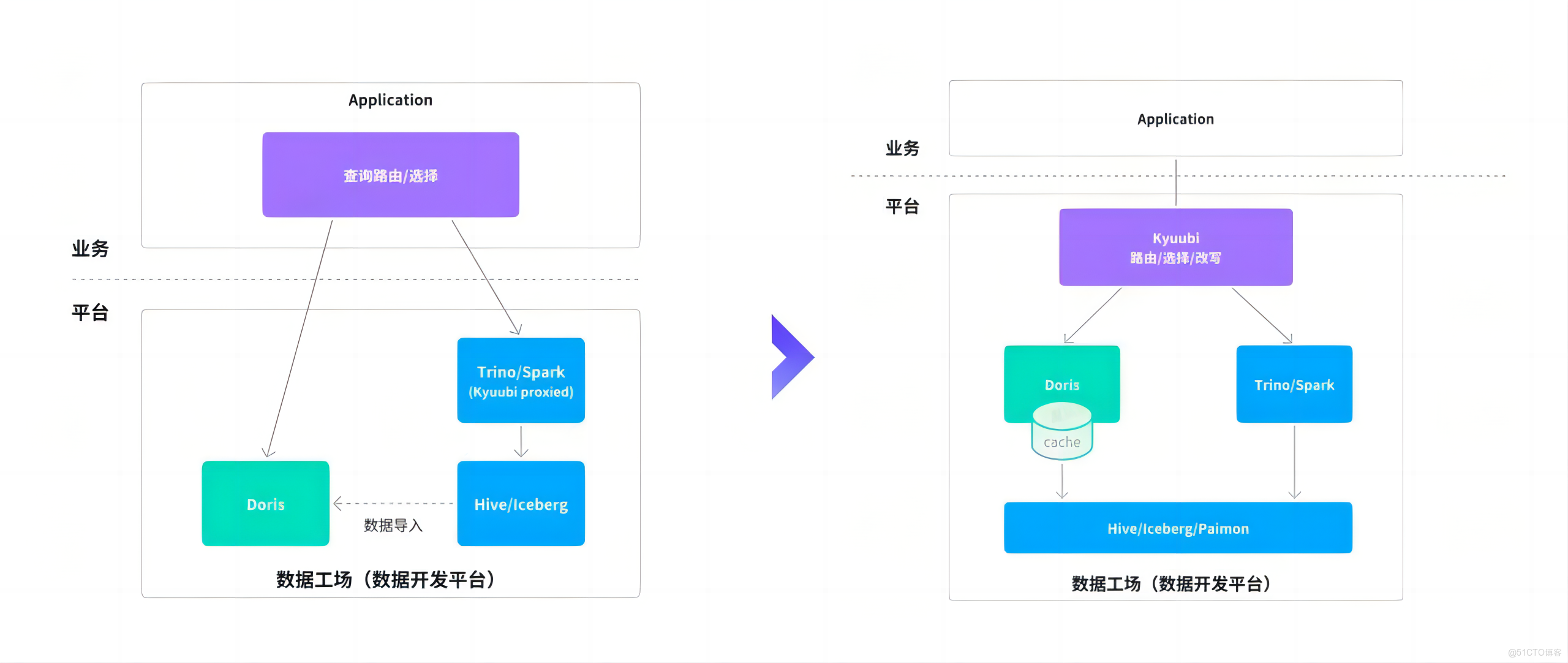
首先是 3.0 存算分離的部署模式,其主要依賴計算組進行資源隔離通過將計算層與存儲層解耦,BE 節點實現無狀態化,依託底層 Kubernetes 支持,可以實現快速彈性伸縮以滿足不同體量用户的需求。
同時,Doris 原生支持湖倉查詢能力,在存算分離模式下,能夠直接訪問外部數據湖,有效打通數據孤島。這一特性不僅顯著簡化了傳統數據鏈路,也減少了因多層複制帶來的數據冗餘,真正推動湖倉一體架構的落地實踐。
基於此,數據開發平台的整體架構發生變化:Doris 不再侷限於傳統“外倉”的角色,而是向上演進為統一的查詢引擎層,與底層 Iceberg、Paimon 等湖倉格式解耦,直接進行聯邦查詢,同時利用自身的數據緩存、物化視圖等能力對熱點數據進行加速,兼顧靈活性與高性能。
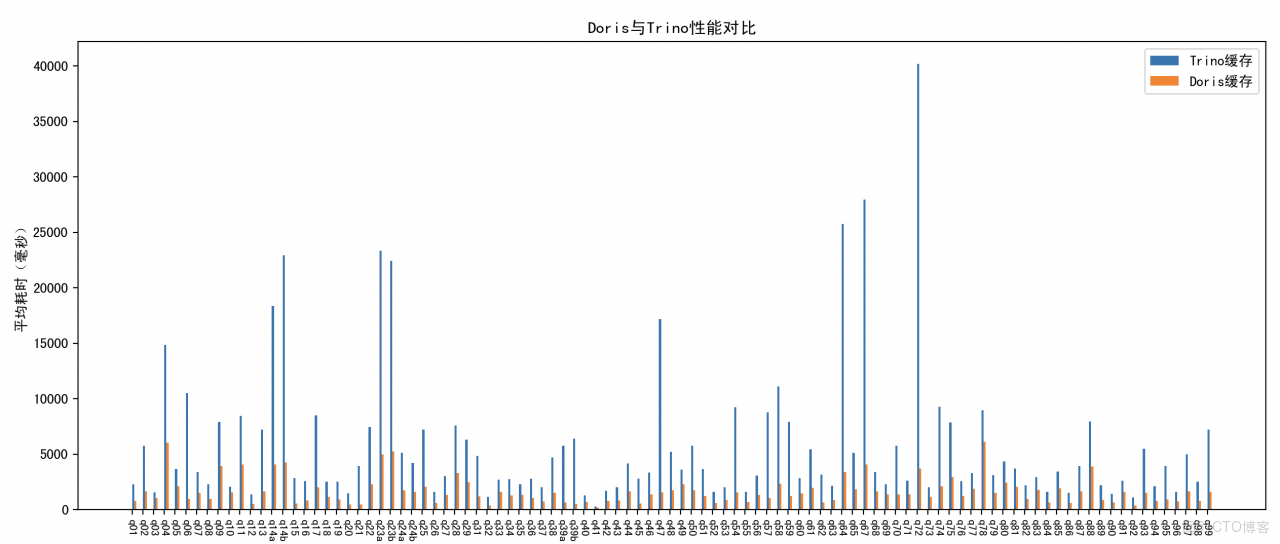
Doris vs Trino 湖倉分析能力對比:全面領先
在 TPC-DS 1TB 標準測試中,Doris 對比 Trino 在整體查詢性能上展現出全面領先的優勢。無論是複雜多表關聯、聚合分析,還是高併發場景下的響應效率,Doris 均表現出更優的執行速度和資源利用率,平均查詢耗時明顯更低,尤其適用於對查詢性能要求較高的實時分析場景。
- TPC-DS 1T 測試:Doris 對比 Trino 全面領先
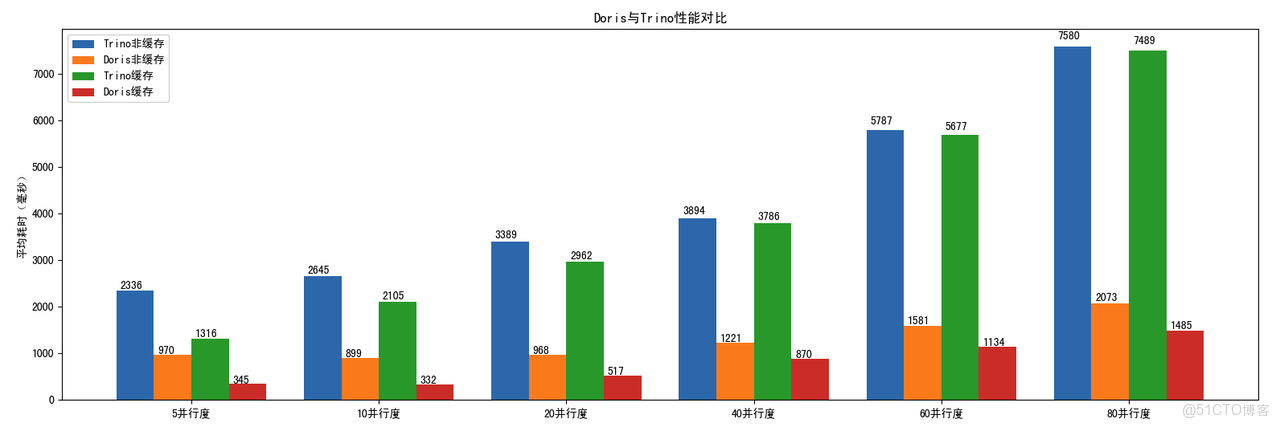
在小米內部的數據查詢場景,涵蓋多表關聯、聚合計算、過濾下推等常見操作的實際業務查詢中,Doris 對比 Trino 的數據湖查詢效率高 3~5 倍。
- 內部數據查詢場景:Doris 對比 Trino 數據湖查詢效率高 3~5 倍
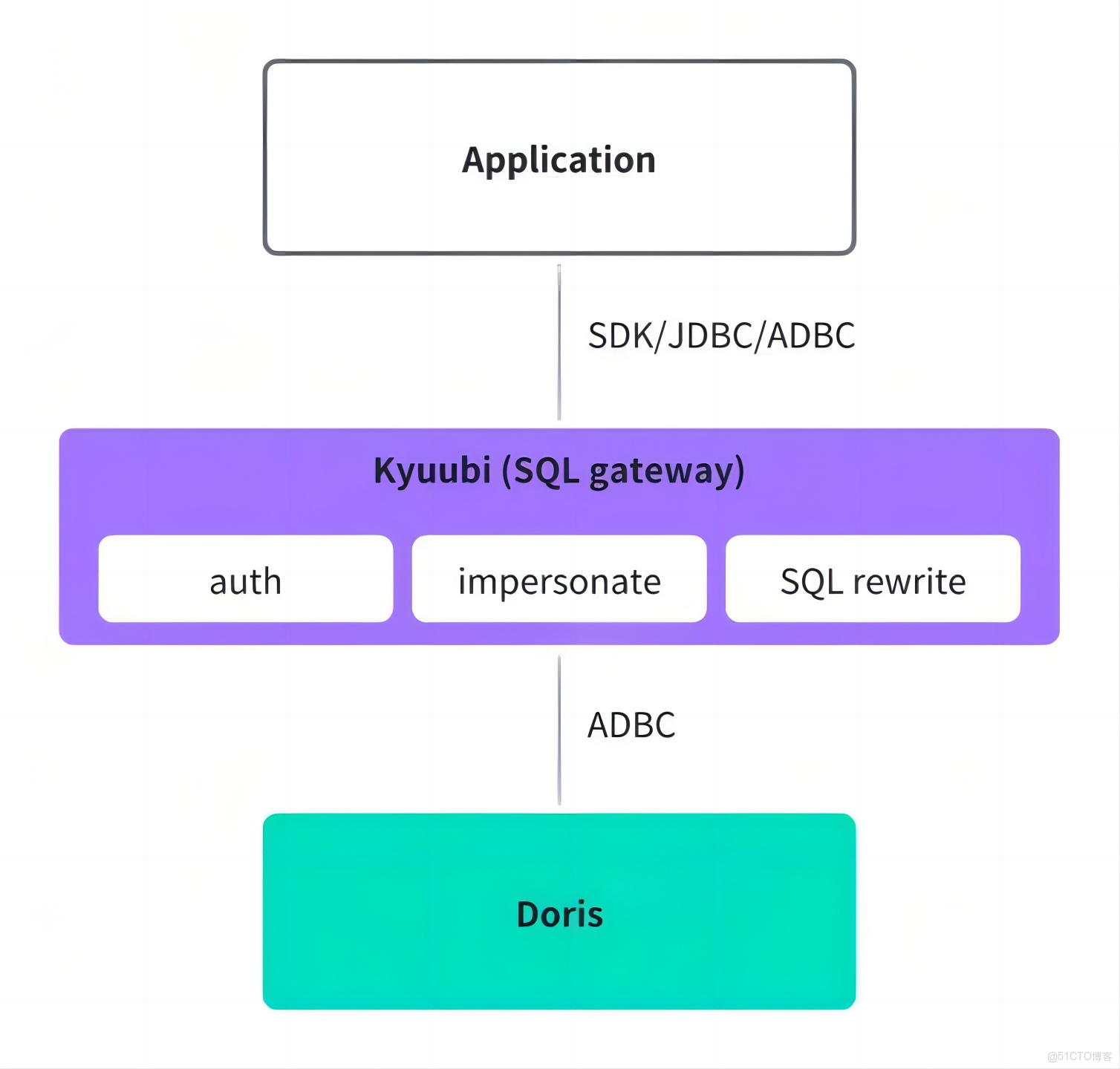
02 統一查詢網關
- 統一認證鑑權:在連接層,將不同引擎的權限和認證體系統一提升到網關層,用户通過網關統一查詢,無需擔心引擎權限問題。
- SQL 改寫:利用 Doris 的 SQL 改寫能力,將其提升到網關層,幫助用户在不同引擎間平滑切換,避免因 SQL 語句不兼容導致出錯。
- 連接協議優化:採用 Arrow Flight SQL 傳輸協議和 ADBC 連接方式,傳輸效率較 JDBC 高 10 倍以上,真實業務場景查詢耗時減少 36%,Kyuubi 實例內存用量減少 50%,代理層服務的管理效率顯著提升。
03 數據鏈路:物化視圖上卷代替導入任務
以廣告業務場景為例,面對分鐘級明細數據聚合查詢較慢的問題,常見方案是將原始明細數據聚合成小時級數據,定期導入 Doris 以提升查詢性能。這一過程需開發和維護複雜的調度任務,運維成本較高。
自 Doris 2.1 版本引入異步物化視圖能力後,只需在 Doris 中聲明物化視圖定義,系統即可自動完成從外部數據湖(如 Iceberg)增量同步、數據聚合、更新調度等全過程,無需額外開發 ETL 鏈路,也無需關注底層執行細節,顯著降低了開發與運維負擔。同時,Doris 支持物化視圖改寫能力,用户仍可使用原有 SQL 查詢原始表,系統會自動識別並將其透明改寫為對應的物化視圖,實現查詢加速。目前該功能基於增量方式實現,主要支持僅追加場景,更新場景仍處於研發狀態。

異步物化視圖能力的建表語句示例如下:
CREATE MATERIALIZED VIEW mv
BUILD DEFERRED
REFRESH INCREMENTAL
ON COMMIT
PARTITION BY (date)
DISTRIBUTED BY RANDOM BUCKETS 4
PROPERTIES ('replication_num' = '3')
AS
SELECT
date,
k1+1 AS k2,
SUM(a1) AS a2
FROM
paimon.data.table
WHERE date >= 20250222
GROUP BY 1, 2;
04 自助化、精細化的資源管理
為了優化資源管理與運維流程,我們自研了精細的 Doris Manager 集羣管理服務,將用户的運維需求轉化為自助操作,依託社區開源的 Doris Operator 在 Kubernetes 平台自動完成資源申請與釋放,實現快速的集羣變更。用户直接通過平台提交資源申請,無需等待平台申請機器、初始化、發佈和上線等步驟,以集羣擴容為例,交付週期從原先的約一週大幅縮短至分鐘級,顯著提升了運維響應速度與效率。
同時,通過 Doris Manager 集羣自動化註冊與發現能力,新集羣創建的同時向元數據中心註冊 Catalog,可自動被查詢網關識別並接入統一訪問入口,用户無需額外配置即可通過網關發起 Doris 查詢,進一步優化了使用體驗。
接入 Kubernetes 後,資源調度更加精細化,最小調度粒度從物理機級別轉變為機器核心、內存大小、磁盤容量等維度,能夠根據不同業務需求靈活調配資源,提高資源利用率,滿足多樣化的業務場景。
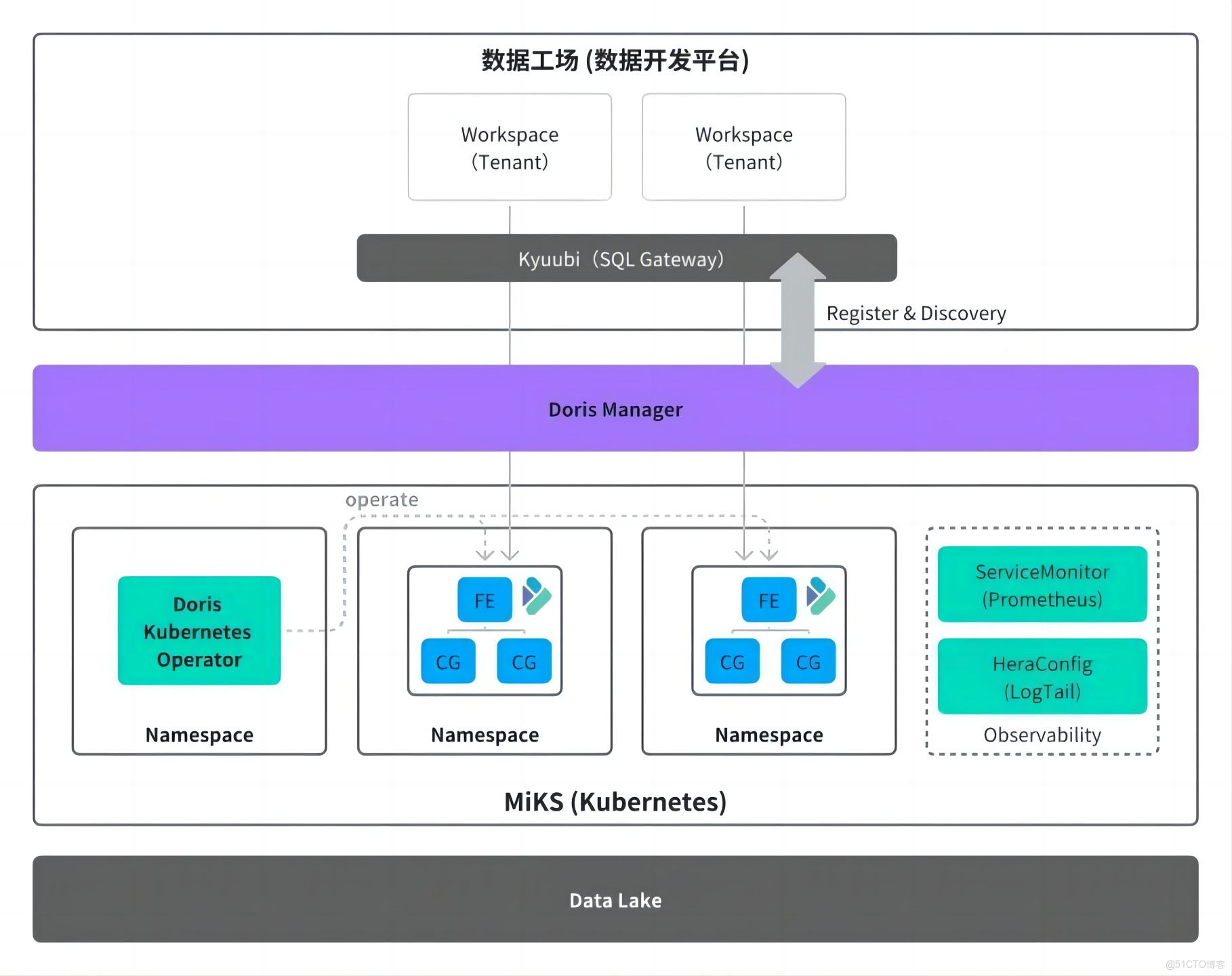
05 更完善的數據採集與可觀測性
在集羣可觀測性方面,基於 Kubernetes 的標準化組件,參照 OpenTelemetry 的規範對 Doris 的監控體系進行全面升級。通過 Prometheus 的 ServiceMonitor 機制採集 Doris 各組件的性能指標,為用户提供全面、細粒度性能監控數據。
在日誌採集方面,採用自研的 Hera(log tail 組件)實現高效採集,同時,借鑑社區的日誌檢索場景實踐,將 Doris 作為 OpenTelemetry 的存儲後端:Doris 自身運行產生的日誌經採集後,最終迴流並存儲至 Doris 內部表中,形成“日誌產生-採集-存儲-查詢”的閉環。
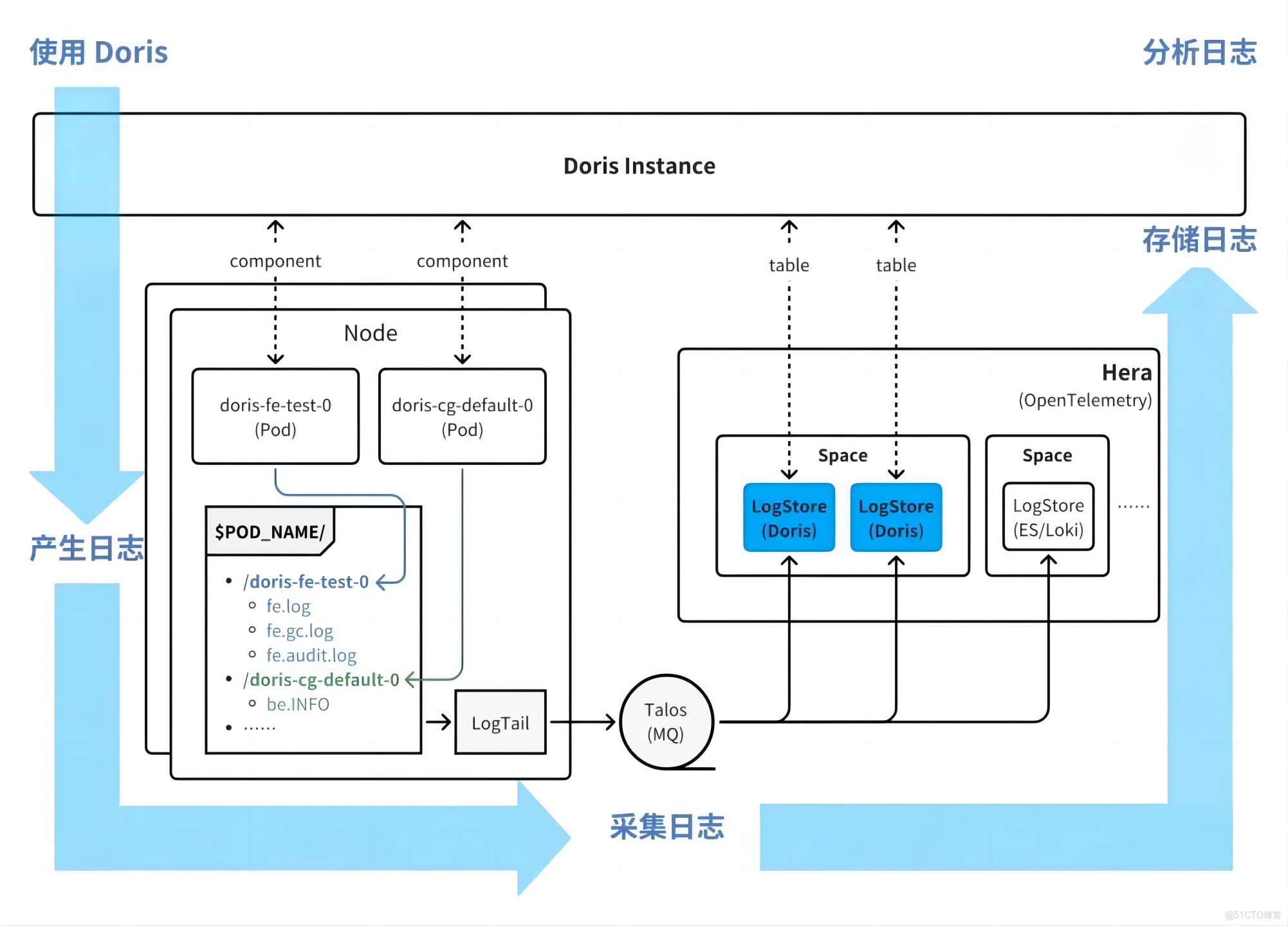
與之前僅支持基礎指標採集的 Falcon 體系相比,Hera 架構覆蓋了審計日誌、監控指標、運行日誌、Profiling 結果以及正在完善的分佈式 tracing 信息,提供更加全面的綜合診斷能力。
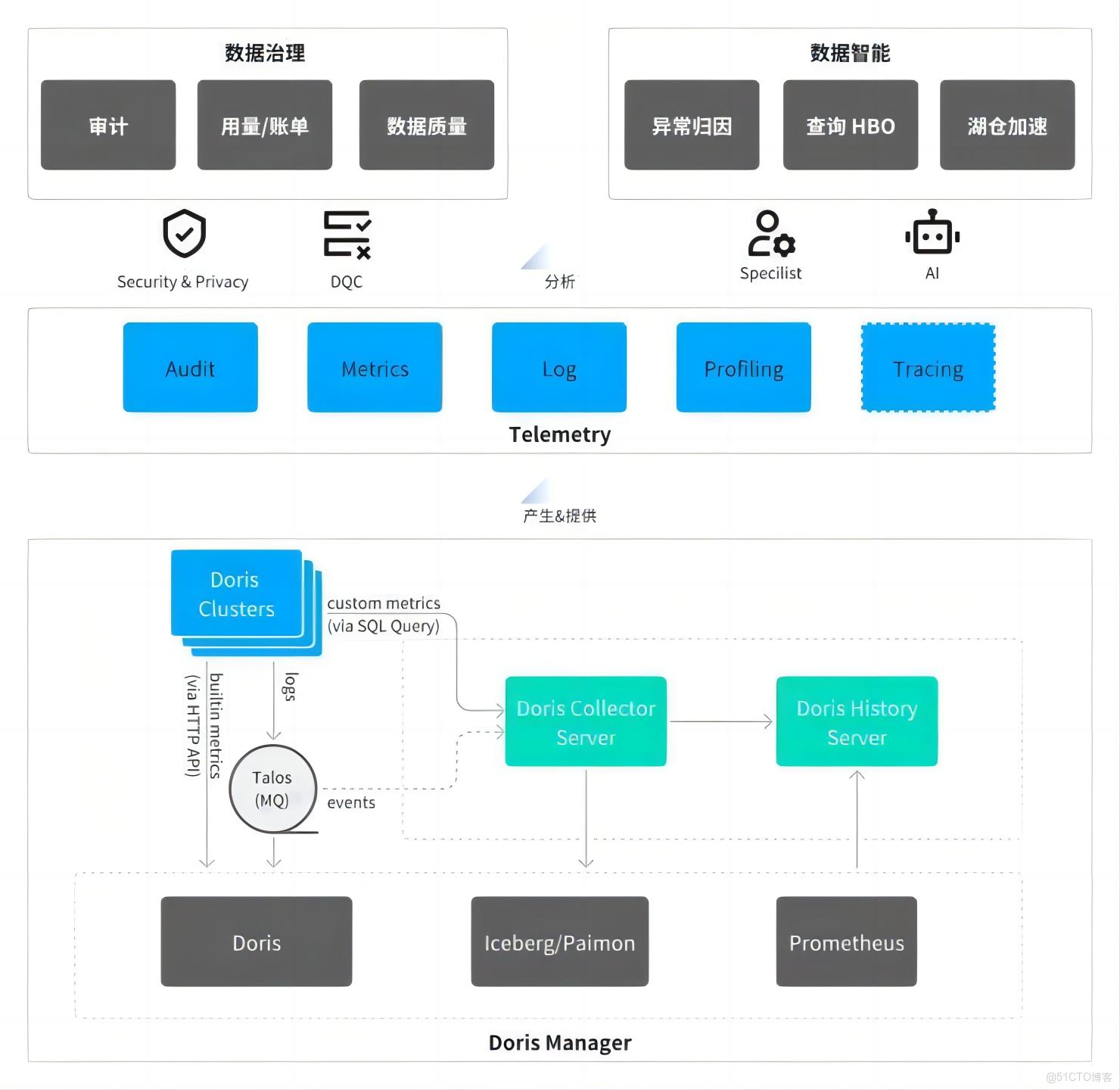
後續規劃
感謝 Doris 社區始終保持高效的版本迭代節奏與穩定性打磨,後續我們將基於以下幾方面展開工作:
- 完成 Doris 版本收斂工作:將核心功能併線至 2.1 和 3.0 版本,並統一工具鏈版本依賴以減少環境差異,最終實現開發迭代效率的顯著提升,為後續功能迭代奠定高效基礎。
- 圍繞湖倉一體能力進行深度優化:重點提升湖倉支持的完整性與穩定性,推動 Doris 存算分離架構的大規模落地,同時完善增量計算能力的覆蓋範圍,以滿足複雜場景下的實時數據處理需求。
- 拓展新場景與 AI 融合方向:孵化日誌、Tracing 等數據存儲能力,通過 AI for Doris 提升運維管理效率,並探索 Doris for AI 的反向賦能能力,構建數據平台與智能技術的雙向協同生態。