
在數據驅動決策的今天,數據的“新鮮度”已成為企業在激烈市場競爭中脱穎而出的核心競爭力。傳統的 T+1 數據處理模式,由於其固有的延遲,已無法滿足現代商業對實時性的苛刻要求。無論是為了實現毫秒級的業務庫與數據倉庫同步、動態調整運營策略,還是為了在秒級內修正錯誤數據以保障決策的準確性,強大的實時數據更新能力都顯得至關重要。
Apache Doris作為一個現代化的實時分析型數據庫,其設計的核心目標之一便是提供極致的數據新鮮度。它通過強大的數據模型和靈活的更新機制,將數據分析的延遲從天級、小時級成功壓縮至秒級,為用户構建實時、敏捷的商業決策閉環提供了堅實的基礎。
本文檔將作為一份官方指南,系統性地闡述 Apache Doris 的數據更新能力,內容涵蓋其核心原理、多樣的更新與刪除方式、典型的應用場景,以及在不同部署模式下的性能最佳實踐,旨在幫助您全面掌握並高效利用 Doris 的數據更新功能。
1. 核心概念:表模型與更新機制
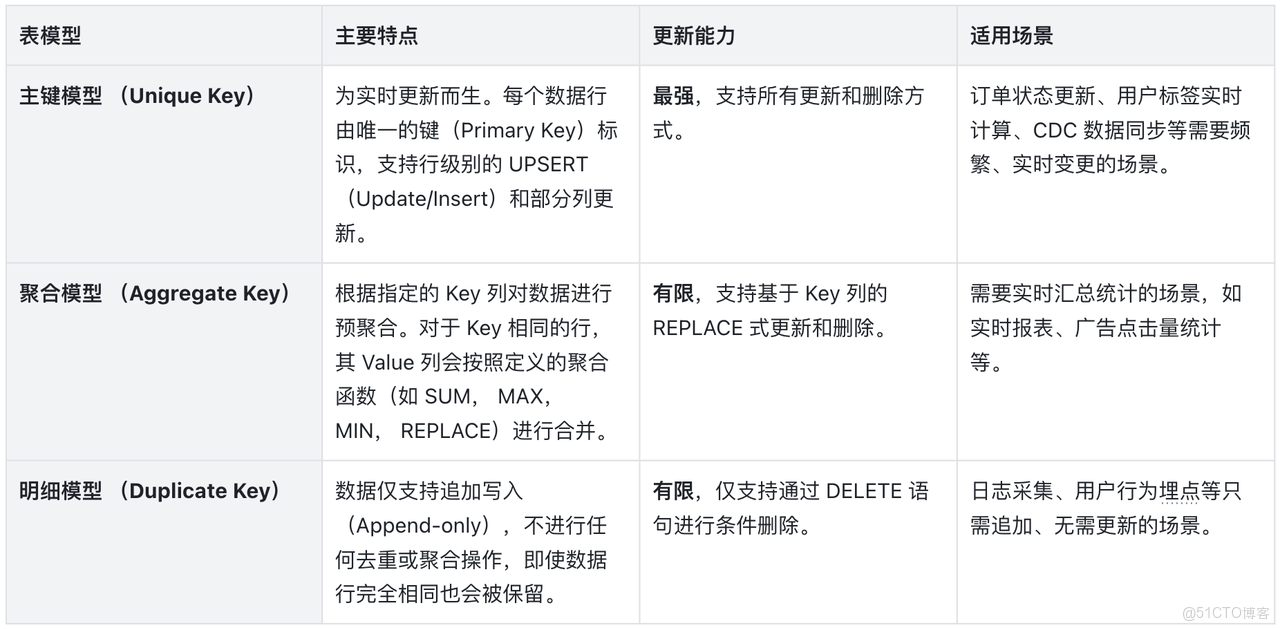
在 Doris 中,數據表的表模型(Data Model)決定了其數據組織方式和更新行為。為了支持不同的業務場景,Doris 提供了三種表模型:主鍵模型(Unique Key)、聚合模型(Aggregate Key)和明細模型(Duplicate Key)。其中,主鍵模型是實現複雜、高頻數據更新的核心。
1.1. 表模型概覽
1.2. 數據更新方式
Doris 提供了兩大類數據更新方法:通過數據導入進行更新和通過 DML 語句進行更新。
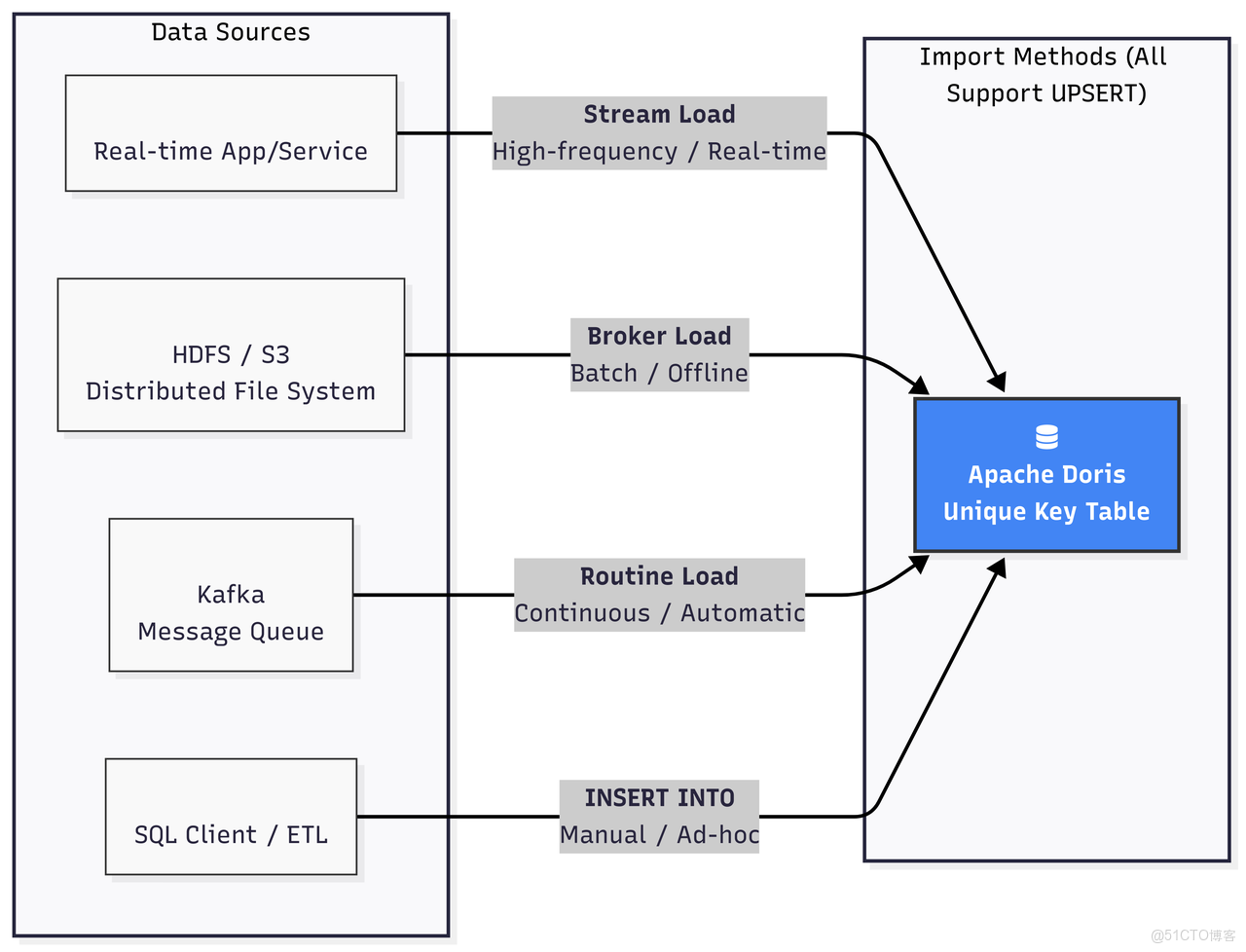
1.2.1. 通過導入進行更新 (UPSERT)
這是 Doris 推薦的高性能、高併發的更新方式,主要針對主鍵模型。所有的導入方式(Stream Load, Broker Load, Routine Load, INSERT INTO)都天然支持 UPSERT 語義。當新數據導入時,如果其主鍵已存在,Doris 會用新行數據覆蓋舊行數據;如果主鍵不存在,則插入新行。
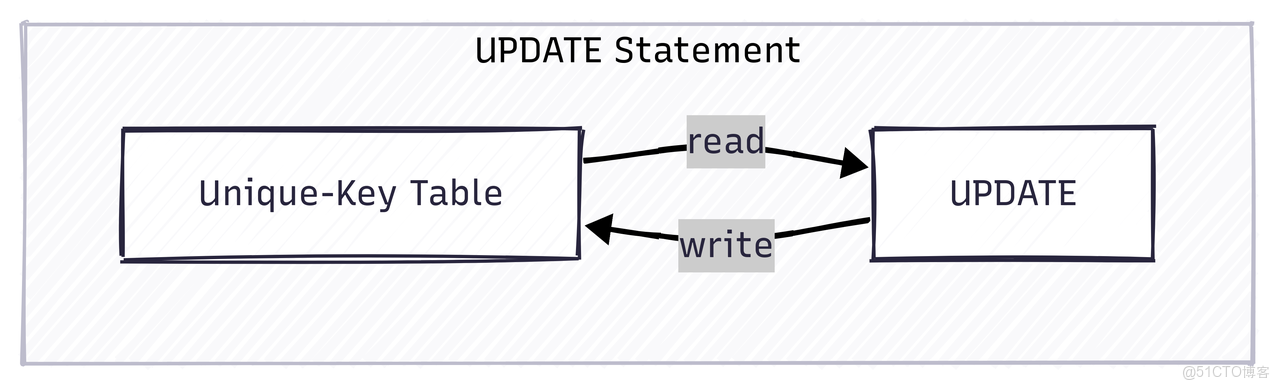
1.2.2. 通過 UPDATE DML 語句更新
Doris 支持標準的 SQL UPDATE 語句,允許用户根據 WHERE 子句指定的條件對數據進行更新。這種方式非常靈活,支持複雜的更新邏輯,例如跨表關聯更新。
-- 簡單更新
UPDATE user_profiles SET age = age + 1 WHERE user_id = 1;
-- 跨表關聯更新
UPDATE sales_records t1
SET t1.user_name = t2.name
FROM user_profiles t2
WHERE t1.user_id = t2.user_id;
注意:UPDATE 語句的執行過程是先掃描滿足條件的數據,然後將更新後的數據重新寫回表中。它適合低頻、批量的更新任務。不建議對 UPDATE 語句進行高併發操作,因為併發的 UPDATE 在涉及相同主鍵時,無法保證數據的隔離性。
1.2.3. 通過 INSERT INTO SELECT DML 語句更新
由於 Doris 默認提供了 UPSERT 的語義,因此使用INSERT INTO SELECT也可以實現類似於UPDATE的更新效果。
1.3. 數據刪除方式
與更新類似,Doris 也支持通過導入和 DML 語句兩種方式刪除數據。
1.3.1. 通過導入進行標記刪除
這是一種高效的批量刪除方法,主要用於主鍵模型。用户可以在導入數據時,增加一個特殊的隱藏列 DORIS_DELETE_SIGN。當某行的該列值為 1 或 true 時,Doris 會將該主鍵對應的數據行標記為刪除(關於 delete sign 的原理,後文會有詳細的介紹)。
// Stream Load 導入數據,刪除 user_id 為 2 的行
// curl --location-trusted -u user:passwd -H "columns:user_id, __DORIS_DELETE_SIGN__" -T delete.json http://fe_host:8030/api/db_name/table_name/_stream_load
// delete.json 內容
[
{"user_id": 2, "__DORIS_DELETE_SIGN__": "1"}
]
1.3.2. 通過 DELETE DML 語句刪除
Doris 支持標準的 SQL DELETE 語句,可以根據 WHERE 條件刪除數據。
- 主鍵模型:
DELETE語句會將滿足條件的行的主鍵重新寫入,並附帶刪除標記。因此,其性能與需要刪除的數據量成正比。主鍵模型上的DELETE語句執行原理與UPDATE語句非常相似,先通過查詢把要刪除的數據讀取出來,然後再附加刪除標記進行一次寫入。相比UPDATE語句,DELETE語句只需要寫入 Key 列和刪除標記列,相對輕量一些。 - 明細/聚合模型:
DELETE語句的實現方式是記錄一個刪除謂詞(Delete Predicate)。在查詢時,這個謂詞會作為一個運行時過濾器(Runtime Filter)來過濾掉被刪除的數據。因此,DELETE操作本身非常快,幾乎與刪除的數據量無關。但需要注意,在明細/聚合模型上進行高頻的DELETE操作會累積大量的運行時過濾器,嚴重影響後續的查詢性能。
DELETE FROM user_profiles WHERE last_login < '2022-01-01';
下表是對使用 DML 語句進行刪除的一個簡要總結:

2. 深入主鍵模型:原理與實現
主鍵模型是 Doris 實現高性能實時更新的基石。理解其內部工作原理,對於充分發揮其性能至關重要。
2.1. Merge-on-Write (MoW) vs. Merge-on-Read (MoR)
主鍵模型有兩種數據合併策略:寫時合併(MoW)和讀時合併(MoR)。自 Doris 2.1 版本起,MoW 已成為默認且推薦的實現方式。

MoW 機制通過在寫入階段付出少量代價,換取了查詢性能的巨大提升,完美契合了 OLAP 系統“重讀輕寫”的特點。
下圖簡要的介紹了 MoW 的核心機制:

2.2. 條件更新 (Sequence Column)
在分佈式系統中,數據亂序到達是一個常見問題。例如,一個訂單狀態先後變更為“已支付”和“已發貨”,但由於網絡延遲,代表“已發貨”的數據可能先於“已支付”的數據到達 Doris。
為了解決這個問題,Doris 引入了 Sequence 列機制。用户可以在建表時指定一個列(通常是時間戳或版本號)作為 Sequence 列。當處理具有相同主鍵的數據時,Doris 會比較它們的 Sequence 列的值,並始終保留 Sequence 值最大的那一行數據,從而保證了數據的最終一致性,即使數據亂序到達。
CREATE TABLE order_status (
order_id BIGINT,
status_name STRING,
update_time DATETIME
)
UNIQUE KEY(order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"function_column.sequence_col" = "update_time" -- 指定 update_time 為 Sequence 列
);
-- 1. 寫入 "已發貨" 記錄 (update_time 較大)
-- {"order_id": 1001, "status_name": "Shipped", "update_time": "2023-10-26 12:00:00"}
-- 2. 寫入 "已支付" 記錄 (update_time 較小,後到達)
-- {"order_id": 1001, "status_name": "Paid", "update_time": "2023-10-26 11:00:00"}
-- 最終查詢結果,保留了 update_time 最大的記錄
-- order_id: 1001, status_name: "Shipped", update_time: "2023-10-26 12:00:00"
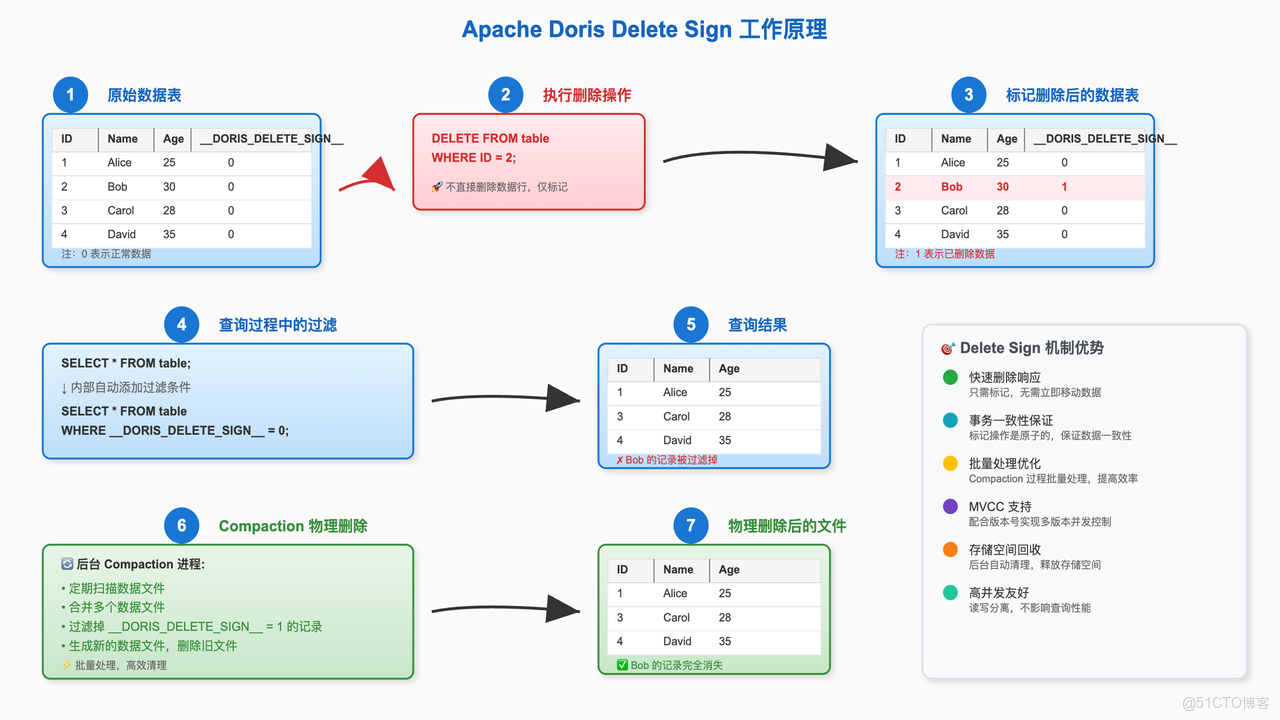
2.3. 刪除機制 DORIS_DELETE_SIGN
DORIS_DELETE_SIGN 的工作原理可以概括為“邏輯標記,後台清理”。
- 執行刪除:當用户通過導入或
DELETE語句刪除數據時,Doris 不會立即從物理文件中移除數據。相反,它會為要刪除的主鍵寫入一條新記錄,該記錄的DORIS_DELETE_SIGN列被標記為1。 - 查詢過濾:當用户查詢數據時,Doris 會在查詢計劃中自動添加一個過濾條件
WHERE DORIS_DELETE_SIGN = 0,從而在查詢結果中隱藏所有被標記為刪除的數據。 - 後台 Compaction:Doris 的後台 Compaction 進程會定期掃描數據。當它發現一個主鍵同時存在正常記錄和刪除標記記錄時,它會在合併過程中將這兩條記錄都物理地移除,最終釋放存儲空間。
這種機制確保了刪除操作的快速響應,同時通過後台任務異步完成物理清理,避免了對在線業務的性能衝擊。
下圖展示了DORIS_DELETE_SIGN 的工作原理:
2.4 部分列更新(Partial Column Update)
從 2.0 版本開始,Doris 在主鍵模型(MoW)上支持了強大的部分列更新能力。用户在導入數據時,只需提供主鍵和待更新的列,未提供的列將保持其原值不變。這極大地簡化了寬表拼接、實時標籤更新等場景的 ETL 流程。
要啓用此功能,需在創建主鍵模型表時,開啓 Merge-on-Write (MoW) 模式,並設置 enable_unique_key_partial_update 屬性為 true。或者在數據導入時配置"partial_columns"參數
CREATE TABLE user_profiles (
user_id BIGINT,
name STRING,
age INT,
last_login DATETIME
)
UNIQUE KEY(user_id)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"enable_unique_key_partial_update" = "true"
);
-- 初始數據
-- user_id: 1, name: 'Alice', age: 30, last_login: '2023-10-01 10:00:00'
-- 通過 Stream Load 導入部分更新數據,只更新 age 和 last_login
-- {"user_id": 1, "age": 31, "last_login": "2023-10-26 18:00:00"}
-- 更新後數據
-- user_id: 1, name: 'Alice', age: 31, last_login: '2023-10-26 18:00:00'
部分列更新原理概要
不同於傳統的 OLTP 數據庫,Doris 的部分列更新並非是原地的數據更新,為了讓 Doris 有更好的寫入吞吐以及查詢性能,主鍵模型的部分列更新採取了“導入時將缺失字段補齊後再整行寫入”的實現方案。如下圖所示:
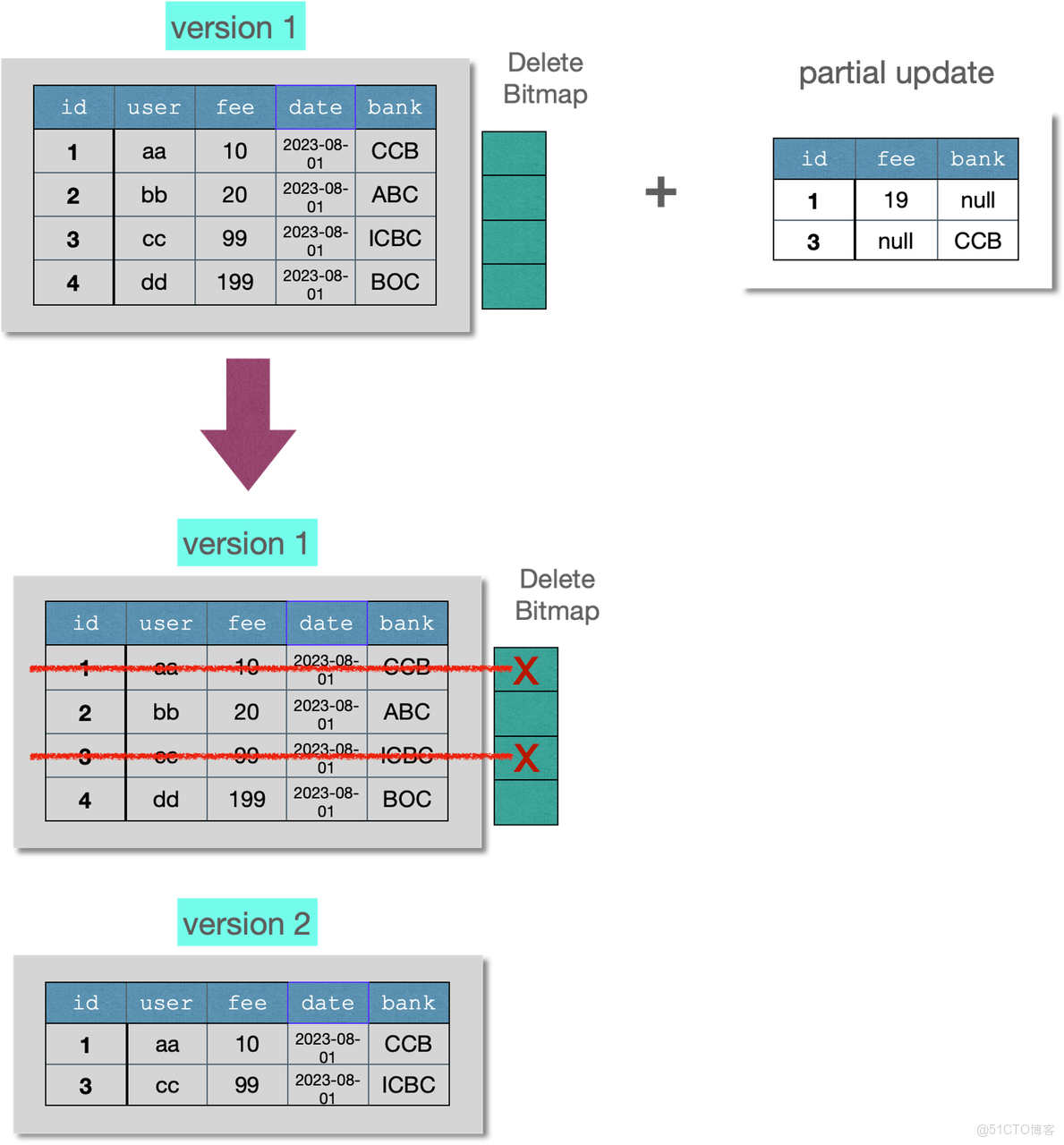
因此使用 Doris 的部分列更新存在“讀放大”和“寫放大”的影響。例如給一個 100 列的寬表更新 10 個字段,Doris 在寫入過程中需要補齊缺失的 90 個字段,假設每個字段的大小接近,則 1MB 的 10 字段更新,會在 Doris 系統中產生大約 9MB 的數據讀取(補齊缺失的字段),以及 10MB 的數據寫入(補齊整行後寫入到新的文件),也就是有大約 9 倍的讀放大和 10 倍的寫放大。
部分列更新性能建議
由於部分列更新存在讀放大和寫放大,同時 Doris 還是列存系統,在數據讀取的過程中可能會產生大量隨機 IO,因此對硬盤的隨機讀 IOPS 有較高的要求。由於傳統的機械磁盤在隨機 IO 上存在顯著瓶頸,因此如果要使用部分列更新功能進行高頻的寫入,建議使用 SSD 硬盤,最好是 nvme 接口,能夠提供最好的隨機 IO 支撐。
同時,如果表很寬,也建議開啓行存來減少隨機 IO。開啓行存後,Doris 會在列存之外額外的存儲一份行存數據,由於行存數據每一行都是連續存儲的,因此可以一次 IO 就讀取到整行數據(列存則需要 N 次 IO 才能讀取到所有缺失的字段,例如前面的 100 列寬表更新 10 列的例子,每一行需要 90 次 IO 才能讀取到所有的字段)
3. 典型應用場景
Doris 強大的數據更新能力使其能夠勝任多種要求嚴苛的實時分析場景。
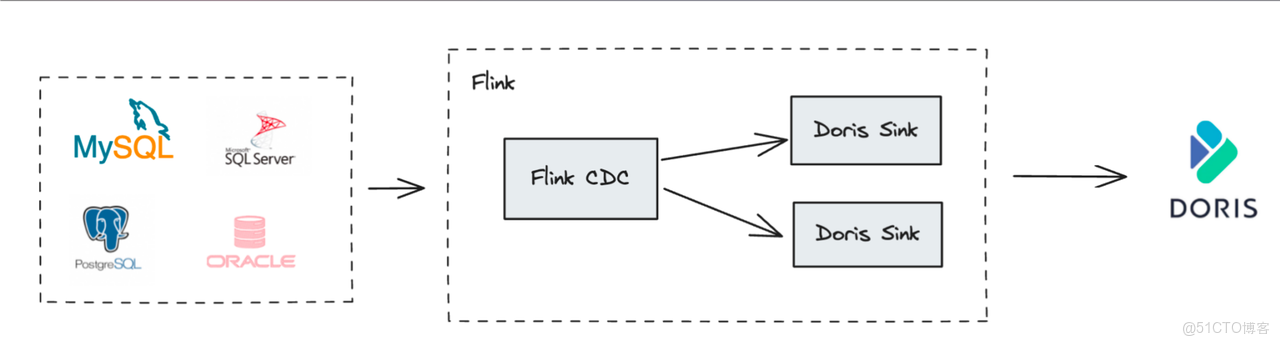
3.1. CDC 數據實時同步
通過 Flink CDC 等工具捕獲上游業務數據庫(如 MySQL, PostgreSQL, Oracle)的變更數據(Binlog),並實時寫入 Doris 的主鍵模型表,是構建實時數倉最經典的場景。
- 整庫同步:Flink Doris Connector 內部集成了 Flink CDC,可以實現從上游數據庫到 Doris 的自動化、端到端的整庫同步,無需手動建表和配置字段映射。
- 保證一致性:利用主鍵模型的
UPSERT能力處理上游的INSERT和UPDATE操作,利用DORIS_DELETE_SIGN處理DELETE操作,並結合 Sequence 列(如 Binlog 中的時間戳)處理亂序數據,完美復刻上游數據庫的狀態,實現毫秒級延遲的數據同步。
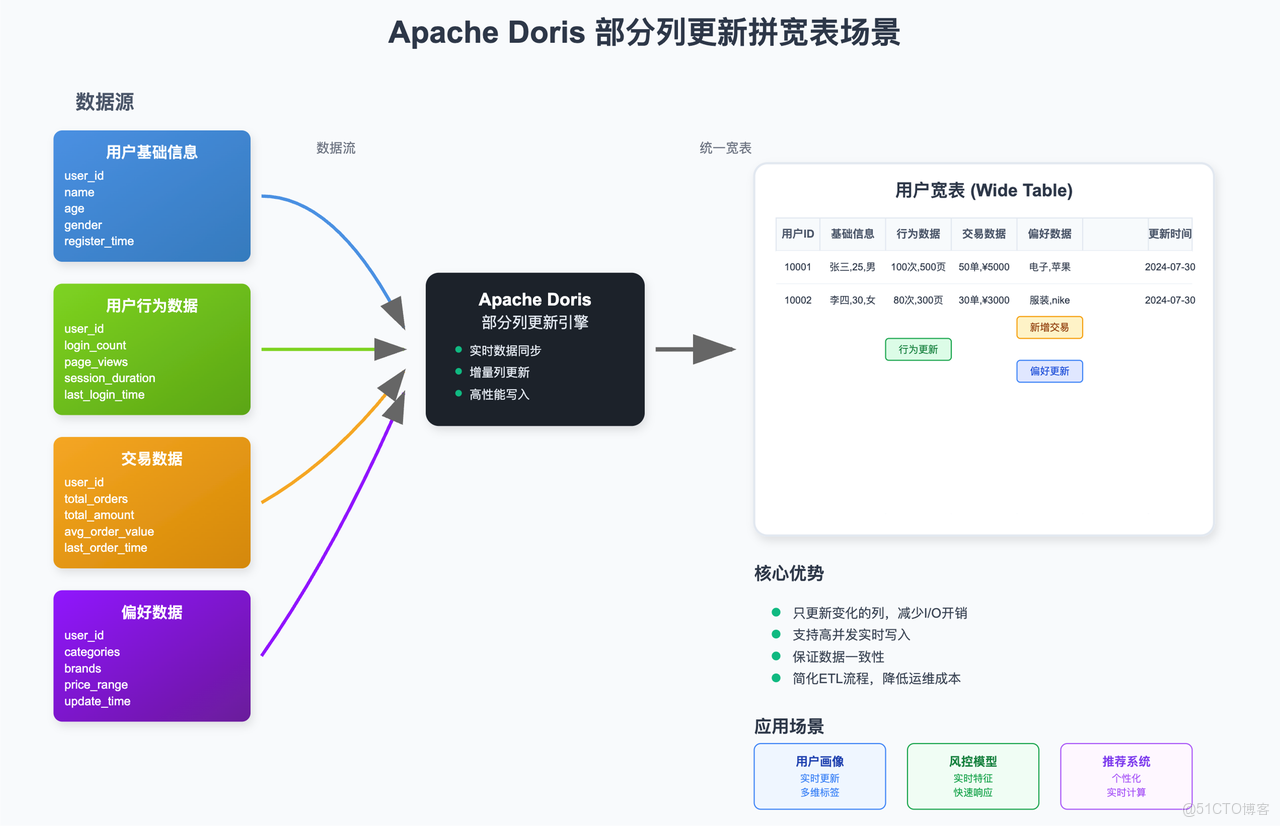
3.2. 實時寬表拼接
在很多分析場景中,需要將來自不同業務系統的數據拼接成一張用户寬表或商品寬表。傳統的方式是使用離線的 ETL 任務(如 Spark 或 Hive)定期(T+1)進行拼接,實時性差,且維護成本高。或者使用 Flink 進行實時的寬表 join 計算,將拼接後的數據寫入數據庫,這通常需要消耗大量的計算資源。
利用 Doris 的部分列更新能力,可以極大地簡化這一流程:
- 在 Doris 中創建一張主鍵模型的寬表。
- 將來自不同數據源(如用户基礎信息、用户行為數據、交易數據等)的數據流通過 Stream Load 或 Routine Load 實時寫入這張寬表。
- 每個數據流只負責更新自己相關的字段。例如,用户行為數據流只更新
page_view_count,last_login_time等字段;交易數據流只更新total_orders,total_amount等字段。
這種方式不僅將寬表的構建從離線 ETL 轉變為實時流式處理,大大提升了數據新鮮度,還因為只寫入變化的列而減少了 I/O 開銷,提升了寫入性能。
4. 最佳實踐
遵循以下最佳實踐,可以幫助您更穩定、更高效地使用 Doris 的數據更新功能。
4.1. 通用性能實踐
- 優先使用導入更新:對於高頻、大量的更新操作,應優先選擇 Stream Load, Routine Load 等導入方式,而非
UPDATEDML 語句。 - 攢批寫入:避免使用
INSERT INTO語句進行逐條的高頻寫入(如 > 100 TPS),因為每條INSERT都會產生一次事務開銷。如果必須使用,應考慮開啓 Group Commit 功能,將多個小批量提交合併成一個大事務。 - 謹慎使用高頻 DELETE:在明細模型和聚合模型上,避免高頻的
DELETE操作,以防查詢性能下降。 - 刪除分區數據時使用 TRUNCATE PARTITION:如果需要刪除整個分區的數據,應使用
TRUNCATE PARTITION,其效率遠高於DELETE。 - 串行執行 UPDATE:避免併發執行可能作用於相同數據行的
UPDATE任務。
4.2. 存算分離架構下的主鍵模型實踐
Doris 3.0 引入了先進的存算分離架構,帶來了極致的彈性和更低的成本。在該架構下,由於 BE 無狀態,因此在 Merge-on-Write 過程中,需要通過 MetaService 來維護一個全局狀態以解決導入/compaction/schema change 之間的寫寫衝突。主鍵模型的 MoW 實現依賴於一個基於 Meta Service 的分佈式表鎖來保證寫操作的一致性,如下圖所示:
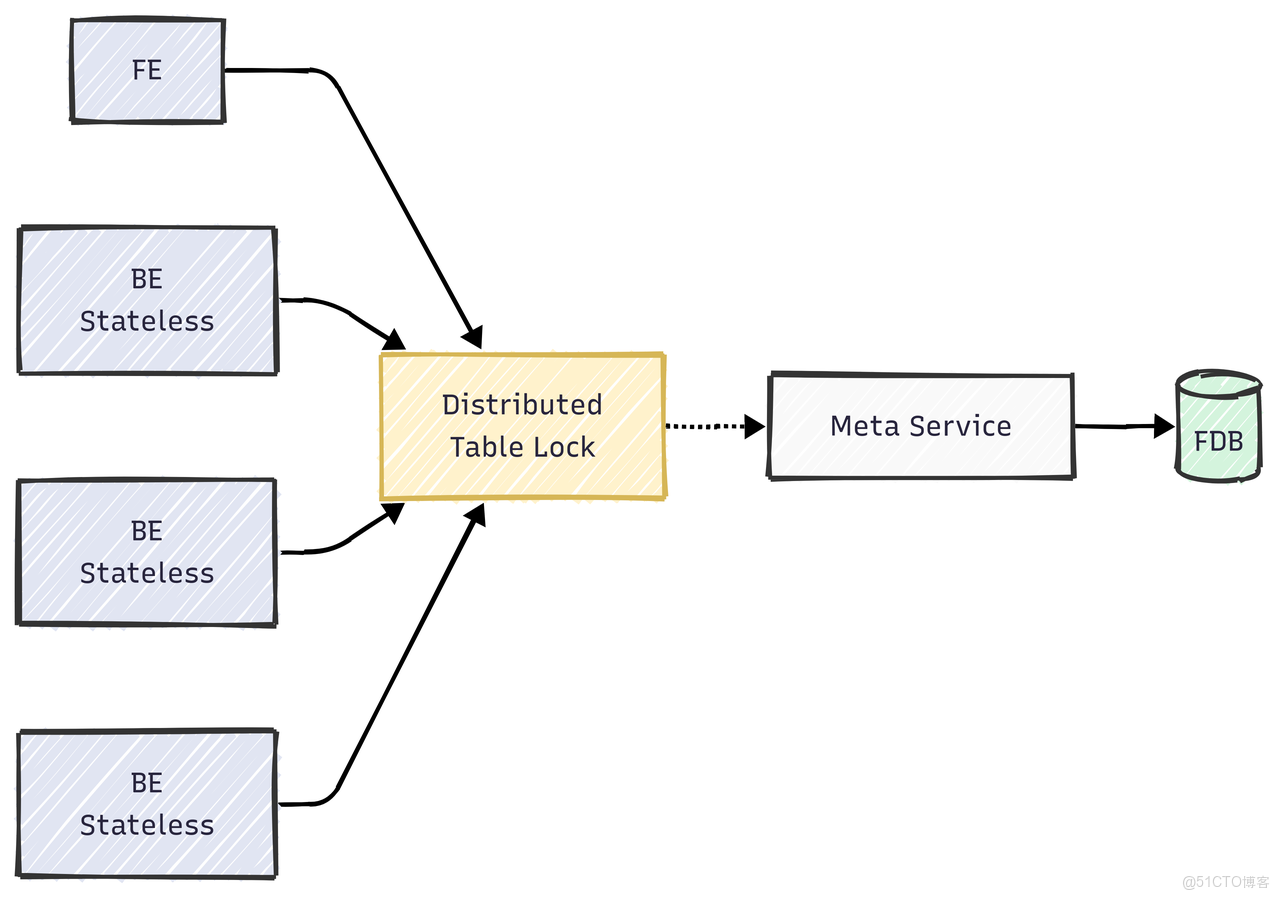
高頻的導入和 Compaction 會導致對錶鎖的頻繁競爭,因此需要特別注意以下幾點:
- 控制單表導入頻率:建議將單張主鍵表的導入頻率控制在 60 次/秒 以內。可以通過攢批、調整導入併發等方式來降低頻率。
- 合理設計分區分桶:
- 分區:利用時間分區(如按天或按小時)可以確保單次導入只更新少量分區,減少鎖競爭的範圍。
- 分桶:分桶數(Tablet 數量)應根據數據量合理設置,通常在 8-64 之間。過多的 Tablet 會加劇鎖競爭。
- 調整 Compaction 策略:在寫入壓力非常大的場景下,可以適當調整 Compaction 策略,降低 Compaction 的頻率,從而減少其與導入任務之間的鎖衝突。
- 升級到最新穩定版本:Doris 社區正在持續優化存算分離架構下的主鍵模型性能。例如,即將發佈的 3.1 版本對分佈式表鎖的實現進行了大幅優化。始終建議使用最新的穩定版本以獲得最佳性能。
結論
Apache Doris 憑藉其以主鍵模型為核心的強大、靈活且高效的數據更新能力,真正打破了傳統 OLAP 系統在數據新鮮度上的瓶頸。無論是通過高性能的導入實現 UPSERT 和部分列更新,還是利用 Sequence 列保證亂序數據的一致性,Doris 都為構建端到端的實時分析應用提供了完整的解決方案。
通過深入理解其核心原理,掌握不同更新方式的適用場景,並遵循本文檔提供的最佳實踐,您將能夠充分釋放 Doris 的潛力,讓實時數據真正成為驅動業務增長的強大引擎。