
目錄
編輯
一、Linux2.6內核進程O(1)調度隊列
二、命令行參數
三、環境變量
前言:
⏩️Linux2.6內核採用O(1)調度算法,通過雙優先級隊列(active和expired)和位圖操作實現高效進程調度。每個CPU維護runqueue結構,包含140個優先級隊列,普通進程優先級映射為100-139的數組下標。調度時通過位圖快速定位最高優先級進程,最多遍歷5次即可找到。雙隊列機制通過交換active和expired指針解決進程飢餓問題。命令行參數和環境變量是進程重要屬性:argv數組存儲命令參數,環境變量表可通過main函數或environ變量獲取,PATH變量決定可執行程序搜索路徑。Linux通過配置文件(如.bashrc)初始化環境變量,用户可臨時修改或永久保存。
一、Linux2.6內核進程O(1)調度隊列
⏩️每個CPU都有一個調度隊列:struct runqueue{};如下圖:
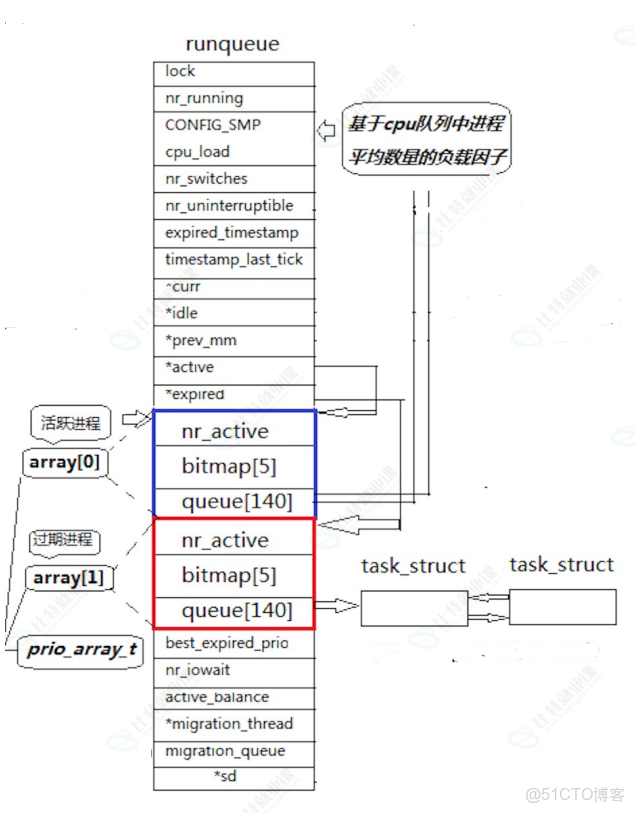
⏩️這個隊列中有個queue[140],類型是struct list_head queue;它前數組下標0到99我們是不關心的,因為他是實時優先級,後面100到139,是普通優先級,對應的優先級的梯度,優先級的範圍是:[ 60 , 99 ],60+40 = 100這不就是數組的下標嗎,還有 99 + 40 = 139 這就是數組的下標。所以優先級數字本質上是 queue 數組的下標。
⏩️那麼100到139這裏面的40個優先級的梯度都是一個個的先進先出的隊列,例如有10個進程的優先級都是111,就在下標為111的優先級梯度把進程PCB分別進入到這個隊列中,然後進行調度,請看下圖:
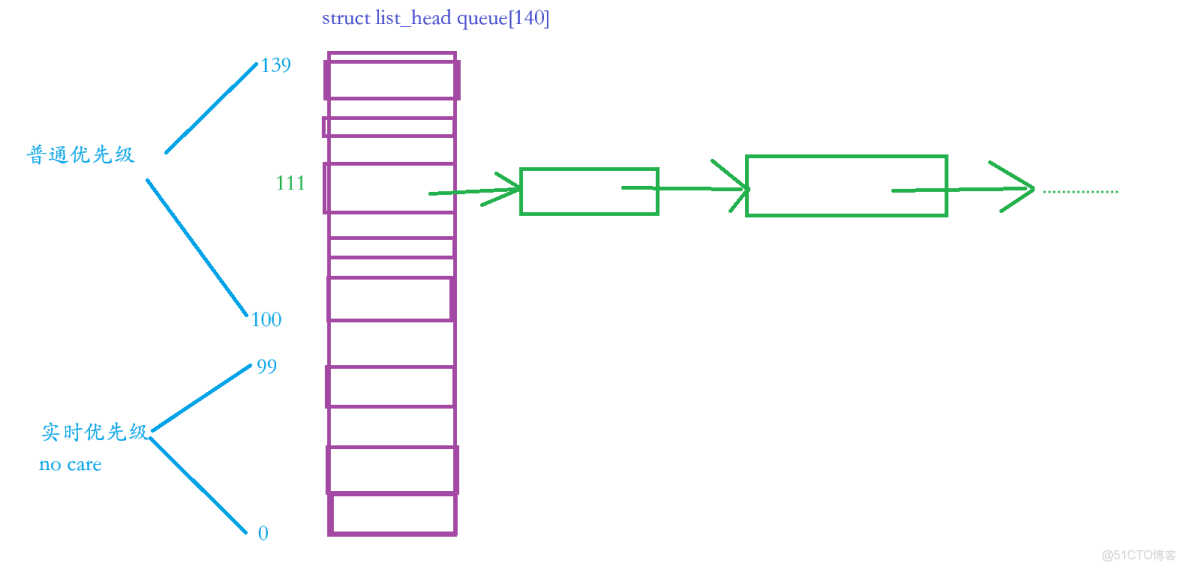
✅️結論:根據優先級選擇進程的時候,本質就是一個hash的過程,其實就是給你優先級數字,例如61,然後再 61 + 40 = 101 ,最後在 queue 中找下標為101 (hash[101])隊列裏面的第一個進程,當然 hash[101] 前提是不為空。
⏩️如果我們要找優先級最高的進程,我們是先從數組下標100開始找,不為空第一個進程就是優先級最高的,為空那就到下一個梯度 101 來找,以此類推,我們最多遍歷40次,時間複雜度為O(1),但是操作系統還是嫌慢所以弄了一大堆的比特位 000000......00000 來表示,這堆比特位的個數大於140個,從 queue 的數組下標一一對應到比特位上,例如下標為0對應到這一堆比特位的右邊第一個,139對應到這一堆比特位的的第140個,如果數組數字對應的梯度裏面不為空,則在這一堆比特位中找到對應的比特位顯示為1,反之改為0,例如:hasn[ 101 ] 不為空,則這一堆的比特位第102個比特位為1,這就是位圖操作。
⏩️那麼操作系統為什麼要轉換成位圖來找最高的優先級進程呢?
✅️答:使用位圖,我們可以使用 char* 指針來訪文8個比特位,看看能不能找得到這 8 個比特位中有其中有一個或者幾個比特位為 1 的進程,找不到那就找下一個8個比特,如果找到有一個比特位為 1 再根據比特位的個數進而確定這是哪個數組下標的進程。所以我們只要遍歷5次(我們只關心後面40個)就行找到優先級最高的進程,這不比找40次要快得多嗎?所以 runqueue 中有個 bitmap[ 5 ] 位圖操作,其中 bitmap 的類型是 long ,所以一次能訪問 32 個比特位,訪問5次可以把160個比特位訪問完,這訪問訪問比 char 更加廣。
⏩️如果 queue 數組裏面一個進程都沒有,那麼我還要去訪問位圖5次呢,所以runque裏面有個nr_active記錄進程的個數。
⏩️runqueue 把上面的操作單獨放到一個結構體中:
struct prio_arry_t
{
nr_active;
bitmap[50];
queue[140];
};⏩️問題:根據上面的內容我們可以提出一個問題,如果CPU正在執行一堆低優先級的進程,都是不斷的有高優先級的進程進來,那麼就會執行完一個優先級低的進程然後不斷的執行優先級高的進程,優先級低的進程永遠不會被執行,這就是進程調度的飢餓問題。
✅️答:我們大部分的電腦都是分時操作系統,要以較為公平的方式,在一段時間內讓所有的進程都要被CPU執行或者説獲得CPU資源。所以我們先學習下面內容之後再回答這個問題。
⏩️我們如果把一個進程的優先級從80改成81,這意味該進程的PCB要在優先級下標為120的隊列中剝離下來,移動到下標為121隊列那裏,這樣的成本太高了。那麼操作系統是怎麼優化的呢?
⏩️實際上,上面 prio_arry_t 操作系統是有兩套的,他們都放到一個叫 struct prio_arry_t arry[ 2 ] 數組裏面。
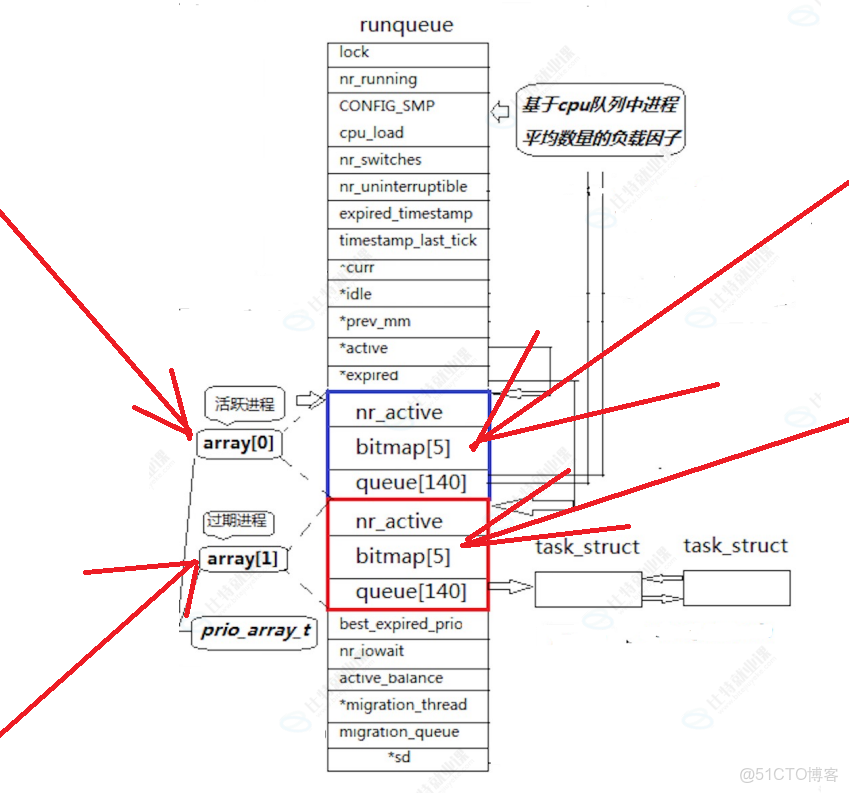
⏩️所以 requeue 隊列裏面有一個 *active 和 *expired 指針,他們指針的類型都是 struct prio_arr_t* ,active 指向 array[ 0 ],這個數組被成為活躍 140 隊列,而 expired 指向 array[ 1 ],這個數組被成為過期 140 隊列;CPU從 active 中找進程,不會從 expired 找,假設 acitive 指向的 queue 數組中下標為111有多個進程,CPU拿到第一個進程執行一段時間之後(時間片用完了),不是重新放回 active 指向的 queue 數組中下標為111的隊列中(重新入隊列),而是放到 expired 指向的 queue 數組中下標也是為111的隊列中(入隊列),如果再從 active 指向的 queue 數組下標為111的隊列中選擇進程(出隊列)來執行,一旦把 active 中 queue 數組所有的進程都調度一遍(所有的進程的時間片都用完了,但是程序還沒有執行完),就把 active 和 expired 指向的內容交換一下(swap(&active,&expired),重新從 active 中指向進程。
❌️注意:一開始 expired 指向的 queue 數組中什麼都沒有。
⏩️現在我們可以回答進程的飢餓問題了,當CPU正在執行低優先級隊列的進程的時候,不斷的有高優先級進程進來,是不會直接停止低優先級進程的,而是:當正在執行低優先級進程隊列(active 的指向的queue)的時候,即使有高優先級的進程進來是不會直接進入到 active 指向的 queue 隊列的,而是放到 expired 指向的 queue 中,當調度一輪(每個進程的時間片用完了) active 指向的進程之後,swap 之後此時就可以先運行高優先級的進程隊列了。此時就解決進程的飢餓問題了。
✅️結論:Linux 沒有進程的飢餓問題。
⏩️現在我們也能回答為什麼不能直接把一個進程的優先級直接從80改成81了,首先在 active 的 queue 中有一個進程的優先級是 80 現在要改成 81 ,如果我們直接從 active 指向的 queue 中直接就修改該進程就會導致原來的優先級為80的進程要剝離原來的隊列,然後移動到優先級為81的隊列中,這樣的代價太大了;所以Linux操作系統是怎麼做的呢?
✅️答:首先引入一個 nice 值,該進程等於 1 ,然後改進程還是按原來的優先級為 80 的隊列中調度,只要它在 active 指向的 queue 中的所有進程調度完畢(時間片用完了),準備進行 swap(&active,&expired) 時就讓該進程的優先級數字改成 81 ,然後在放到(入隊列) expired 指向的 queue 的對應優先級下標為 121 調度隊列中。
❌️注意:前面講的所有內容都是基於優先級隊列 100 到 130,他是一個分時操作和0到99的實時操作無關,也就是説實時操作沒有兩套的 prio_array_t ,他只會一個一個的把優先級從高到低的進程,執行完,就是説例如:先執行完優先級為 99 的進程(沒有時間片的概念),再執行優先級為 100 的,以此類推。執行完所有的進程之後,就執行完了,沒有什麼 active 和 expired 的交換什麼的。
⏩️詳細代碼請看Linux內核代碼:
struct rq {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
unsigned long raw_weighted_load;
#ifdef CONFIG_SMP
unsigned long cpu_load[3];
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
struct task_struct *curr, *idle;
struct mm_struct *prev_mm;
struct prio_array *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* For active balancing */
int active_balance;
int push_cpu;
struct task_struct *migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_local;
#endif
struct lock_class_key rq_lock_key;
};
/*
* These are the runqueue data structures:
*/
struct prio_array {
unsigned int nr_active;
DECLARE_BITMAP(bitmap, MAX_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_PRIO];
};二、命令行參數
⏩️問題:main 函數可以有參數嗎?
✅️答案是:可以。
#include
int main(int argc, char* argv[])
{
return 0;
}argv:指針數組,俗稱命令行參數列表
argc:指針數組有多少個參數,俗稱命令參數個數。
⏩️那麼main函數的參數個數是多少,命令函數參數是什麼呢?
#include
int main(int argc, char* argv[])
{
int i = 0;
printf("argc:%d\n",argc);
for(;i < argc; i++)
{
printf("argv[%d]->%s\n",i,argv[i]);
}
return 0;
}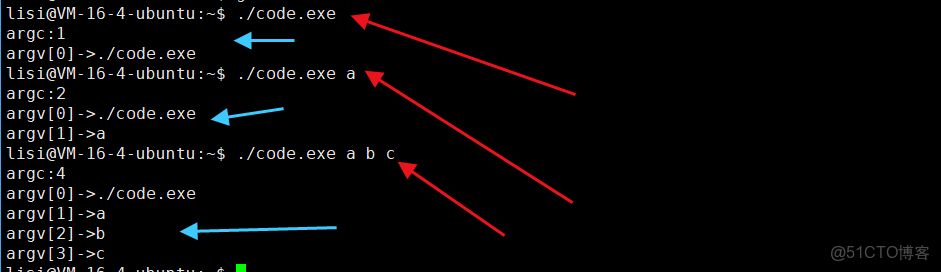
⏩️所以我們由上面的圖片可以得出結論:所謂的命令行參數個數其實就是我們輸入的命令,通過分隔符來分割的字符串個數。而命令行參數列表其實就是每個字符串的的地址。
⏩️那麼為什麼要有命令行參數呢?
#include
#include
int main(int argc, char* argv[])
{
if(argc != 2)
{
printf("該命令使用錯誤,你應該這麼做:%s -a|-b|-c|-d\n",argv[0]);
}
if(strcmp(argv[1],"-a") == 0)
{
printf("我現在執行的是該命令的的一種功能\n");
}
else if(strcmp(argv[1],"-b") == 0)
{
printf("我現在執行的是該命令的的二種功能\n");
}
else if(strcmp(argv[1],"-c") == 0)
{
printf("我現在執行的是該命令的的三種功能\n");
}
else if(strcmp(argv[1],"-d") == 0)
{
printf("我現在執行的是該命令的的四種功能\n");
}
else
{
printf("我現在執行的是該命令的的默認種功能\n");
}
return 0;
}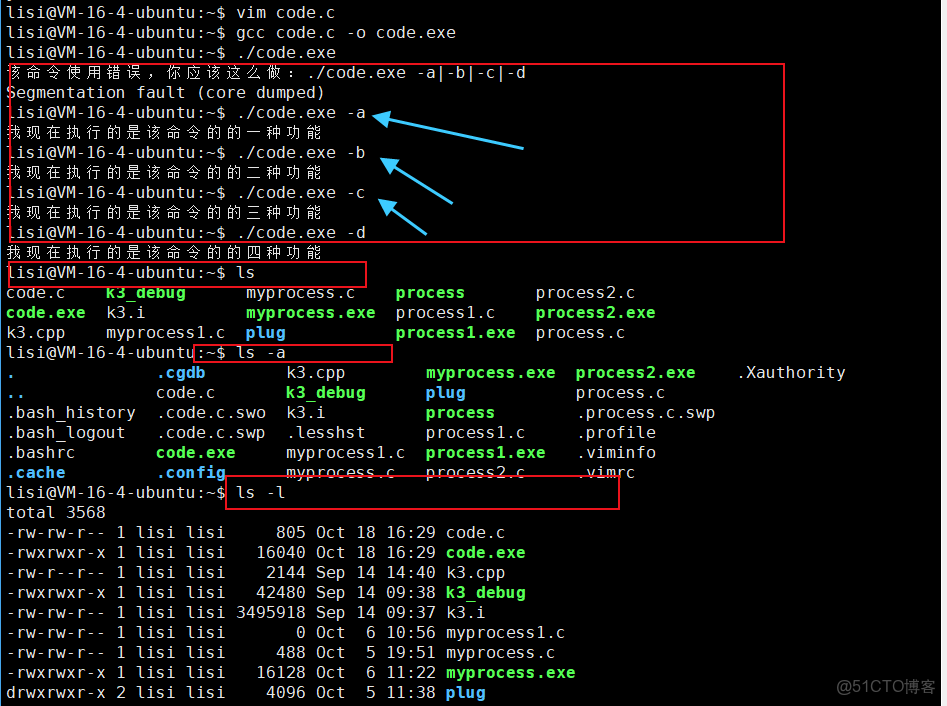
✅️答:命令行參數的本質應用,是為了實現一個命令可以根據不同的選項,實現不同的子功能,也是Linux中所有命令選項功能的實現方式。
細節1:命令行參數至少是1,argv[0] 一定會有元素,而且指向的是程序名。
細節2:選項是以空格分隔的字符串,一個字符也是字符串。
細節3:argv[argc] 表示指針數組的最後一個元素為NULL。
#include
#include
int main(int argc, char* argv[])
{
printf("argv[argc] = %s\n",argv[argc]);
return 0;
}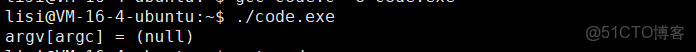
⏩️問題:vs2022或者Windows有沒有命令行參數?
✅️答:有。
⏩️問題:為什麼 cat + 文件名 可以打印文件內容?
✅️答:cat 也是C語言寫的,可以在 cat 文件裏面寫代碼(獲取到文件名,如果打開文件,最後打印文件到 XShell 黑框框裏面。
三、環境變量
⏩️問題:為什麼我們執行我們自己寫的可執行文件要帶 ./ ?
✅️答:因為Linux默認是從 /usr/bin/ 路徑來找可執行文件的,我們寫的可執行文件沒有放到這個路徑下,我們可以把這個文件複製到這個路徑,不帶 ./ 也能執行該文件。./ 是相對路徑,本質就是告訴OS,用户要執行的可以執行程序,就在當前路徑下。
⏩️問題:Linux是怎麼知道去 XShell 哪個路徑找可執行程序呢?
✅️答:因為Linux系統,會存在所謂的環境變量:PATH,他是一個全局的環境變量。我們來查看一下這個環境變量的內容是什麼?請看下面內容:
lisi@VM-16-4-ubuntu:~$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin⏩️我們可以看到 PATH 的內容是以 : 號為分隔符的一堆的路徑。所以PATH的本質是告訴Linux系統,如果用户執行可執行程序沒有指定路徑,就到該 PATH 去找。這意味着我們可以把可執行文件放到任何 PATH 的裏面的任何一條路徑,不用 ./ 就能執行可執行文件,也就意味着如果我們把我們的可執行文件的路徑,添加到 PATH 裏面,不用帶 ./ 就能執行可執行文件,具體操作看下圖:

⏩️如果想上面這麼做的話,會覆蓋原來的PATH的內容,導致一些命令執行不了,例如:ls
⏩️那麼覆蓋 PATH 之後怎麼恢復原來的路徑呢?
✅️答:退出 XShell ,重新打開 XShell。
⏩️那麼正確添加可執行文件的路徑到 PATH 的方法是什麼?

⏩️問題:Windows有沒有環境變量呢?
✅️答:有。在電腦打開控制面板查找環境變量:
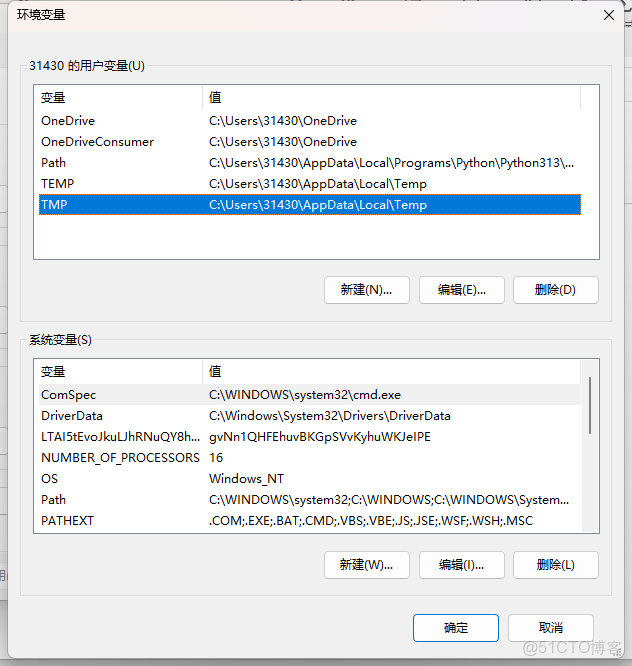
⏩️如果想像在 XShell 在 PATH 裏面添加一條路徑,實際上是在上圖的用户變量的 path 裏面添加的。關機之後我們添加的那條路徑就沒了。
⏩️我們在 XShell 輸入指令:env ,表示查找有哪些環境變量?
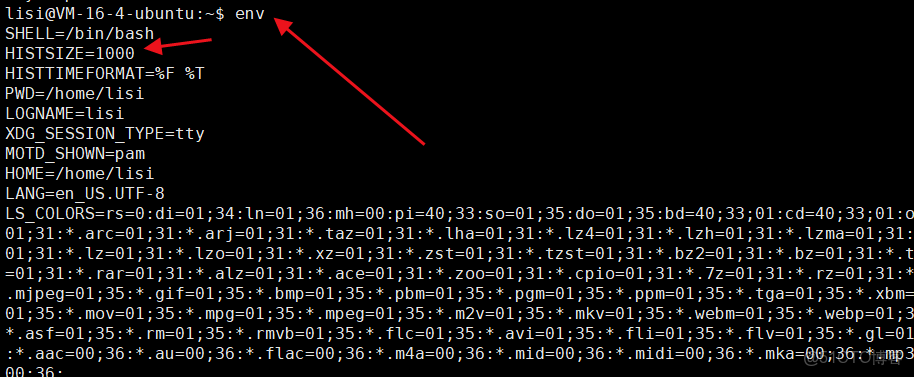
⏩️其中的 HISTSIZE 的環境變量默認的值是1000,表示記錄我們最近輸入的 1000 條指令,就像我們平常按下那個箭頭向上的鍵,可以找到歷史命令一樣。

⏩️OLDPWD是記錄最近我們待過的路徑,是什麼?例如:
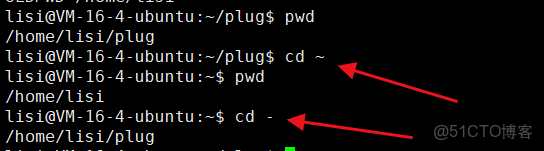
⏩️cd - 就是回到上一條路徑下。
⏩️還要很多的環境沒有解釋但是最重要是下面三條:
• PATH : 指定命令的搜索路徑
• HOME : 指定⽤⼾的主⼯作⽬錄(即⽤⼾登陸到Linux系統中時,默認的⽬錄)
• SHELL : 當前Shell,它的值通常是/bin/bash
⏩️那麼環境變量和我們平常寫代碼和進程有什麼關係嗎?
✅️答:
1.可以通過寫代碼的方式獲取到環境變量
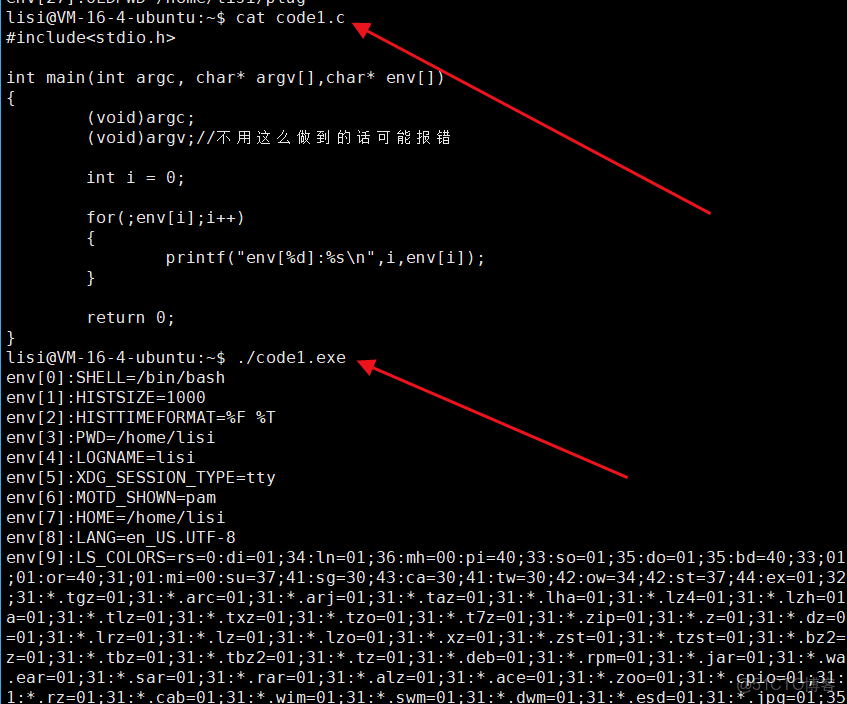
⏩️main函數有三個參數,第三個參數可以獲取到環境變量。
#include
int main(int argc, char* argv[],char* env[])
{
(void)argc;
(void)argv;//不用這麼做到的話可能報錯
int i = 0;
for(;env[i];i++)
{
printf("env[%d]:&s\n",i,env[i]);
}
return 0;
}
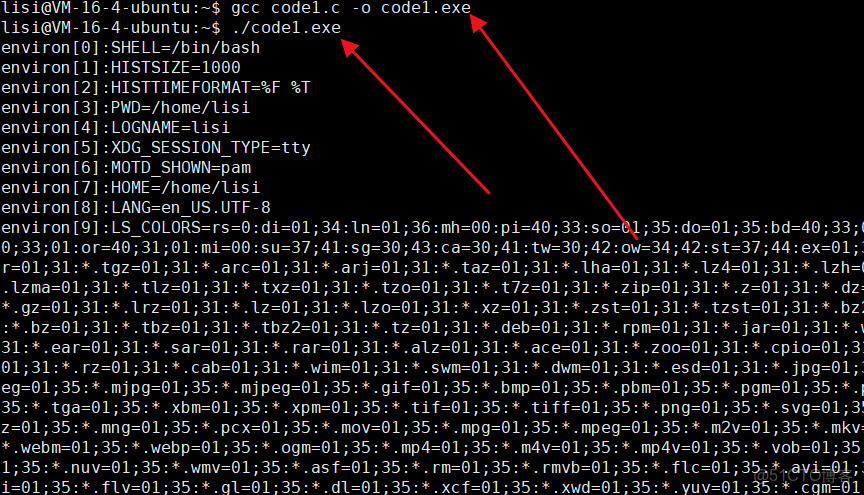
⏩️env:稱為:環境變量表,可以獲取到環境變量,跟 argv 一樣也是以 NULL 結尾。本質是把環境變量表傳遞給進程。
⏩️那麼如果沒有在main函數裏面顯示寫這三個參數,還有什麼辦法可以獲取到環境變量表嗎?
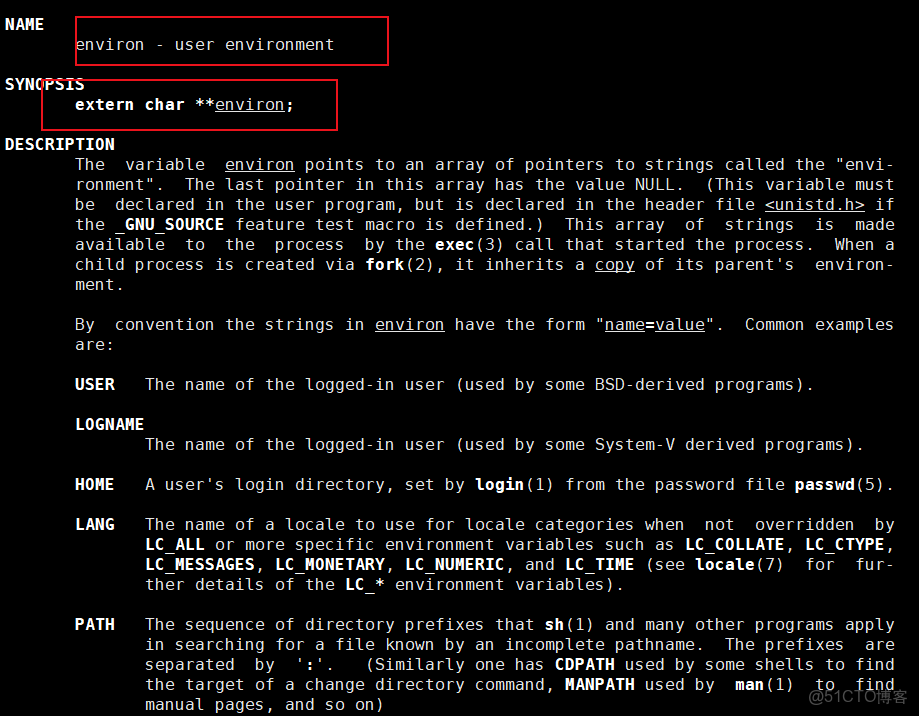
✅️答:當然有,我們可以通過庫函數裏面的 environ 變量來打印出來,他是跟 env 的使用方法也是一樣的,也是以NULL結尾。
#include
#include
int main()
{
extern char **environ;//聲明一下
int i = 0;
for(; environ[i];i++)
{
printf("environ[%d]:%s\n",i,environ[i]);
}
return 0;
}
⏩️上面的所有例子不重要,最重要的是下面這個:getenv 函數,可以通過指定環境變量的名字來獲取指定環境的內容。
#include
#include
#include
#include
int main()
{
char* whoami = getenv("USER");
if(whoami == NULL)
{
printf("沒有該環境變量");
}
else if(strcmp(whoami,"lisi") == 0)
{
printf("是我想要的whoami:%s\n",whoami);
}
else
{
return 0;
}
return 0;
}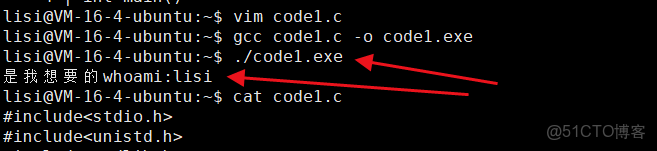
⏩️所以獲取一個環境變量的有户名和我們文件指定用户一樣的話就讓該文件執行,不是就不允許執行。這就是環境變量的用處。
⏩️那麼問題又來了,main函數的那三個參數是誰傳給main函數的呢?
✅️答:首先main函數的三個參數的內容是默認在bash內部,而bash本身就是個進程,所以這三個參數的數據保存在內存中,我們執行的命令、程序等都是 bash 的子進程,那麼父子進程的數據是共享的,所以這三個參數是bash傳的。
✅️結論:環境變量具有全局性。
⏩️那麼問題又來了,bash進程的環境變量又是從哪裏來的?
✅️答:bash 的環境變量是從 Linux 系統的配置文件中來,這就解釋了為什麼我們更改環境變量(從內存中改)之後,退出又重新登錄 XShell 恢復到原來默認的配置環境(其實就是結束bash進程,然後重新啓動該進程)。
⏩️那麼 Linux 系統的配置文件是什麼呢?在哪裏呢?
✅️答:存在在每個用户的家目錄,而且這兩個配置文件是隱藏文件分別是:.bash_profile 和 .bashrc,bash 先訪問 .bash_profile ,然後 .bash_profile 再訪問 .bashrc,最後 .bashrc 再訪問 /etc/bashrc 文件,這個文件是用 shell 腳本寫的,太複雜了,這裏就不再多説;登錄的 XShell 的時候不是要配置文件,我們可以在 .bashrc 或者 .bash_profile 文件裏面添加一些內容,例如:打印一些信息,等我們重新登錄這個用户的時候就會顯示這些信息。
❌️注意:每個用户都有自己的 bash ,這意味着每個用户都有自己的配置文件。當我們登錄用户的時候 .bashrc 和 .bash_profile 都會自動執行。這就意味着如果我們想保存自己寫的環境變量,就在 .bashrc 或者 .bash_profile 文件裏面寫入就行。
⏩️問題:那麼我們創建自己的環境變量呢?
✅️答:輸入指令:變量名(大寫)= 數字或者值,此時創建的是本地變量,在環境變量裏面是沒有該變量的,所以再輸入指令:export 該變量名,此時就能在環境變量中找到這個變量了。

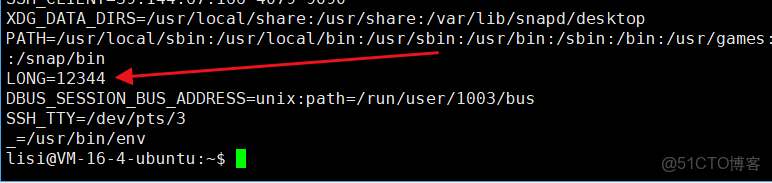
⏩️當然也可以一步到位:
❌️注意:我們是在內存改的,所以重新登錄 XShell 的時候就會默認的環境變量。
⏩️那麼怎麼刪除自己寫的環境變量呢?
✅️答:指令: unset 環境變量名。其實不刪除也行,這都是在內存裏面進行操作的。

⏩️上面我們提到了本地變量,本地變量:無法被子進程獲取,不具有全局性,只能在 bash 內部可以訪問。
⏩️本地變量的用處:在 XShell 裏面輸入指令有用,對指令的語法具有幫助。
⏩️指令:set ,可以顯示環境變量和本地變量。
⏩️存在特定路徑而且存在二進制文件的命令:普通命令。
⏩️在shell內部自己定義,bash自己內部的一次函數調用,不依賴第三方路徑:內建命令。
四、總結
⏩️本文講述進程是怎麼調度,當然這個問題也是面試常問的,我們不可以把所有的知識點都記住但是我們可以記住每個知識點的邏輯,把每個知識點串聯起來,形成完整的邏輯線有助於我們更好的記住知識點。