









全文鏈接:https://tecdat.cn/?p=44165
原文出處:拓端數據部落公眾號
分析師:Yizhou Huang

一、專題引言
古代玻璃是解讀絲綢之路中外文化交流的關鍵實物證據,不同時期的玻璃在成分體系、製作工藝上存在顯著差異。但古代玻璃易受環境影響發生風化,導致內部化學成分比例改變,這給玻璃類型的準確鑑別帶來了極大挑戰——外觀相似的玻璃可能屬於不同類別,而風化後的成分變化更會干擾判斷。
本文內容正是源自該項目的技術沉澱與實際業務校驗的獲獎作品,所有結論均通過數據驗證。
該項目完整代碼與數據已分享至交流社羣。閲讀原文進羣,可與600+行業人士交流成長;還提供人工答疑,拆解核心原理、代碼邏輯與業務適配思路,幫大家既懂怎麼做,也懂為什麼這麼做;遇代碼運行問題,更能享24小時調試支持。
本文將以“數據解決實際問題”為核心,先梳理古代玻璃分析的核心需求,再通過卡方檢驗、相關性分析、K-means聚類等方法,逐步解決“風化關聯分析”“類型劃分”“未知玻璃鑑別”“成分差異對比”四大問題,最終形成一套可複用的文物成分數據分析框架。
二、問題重述與分析思路
1. 核心數據
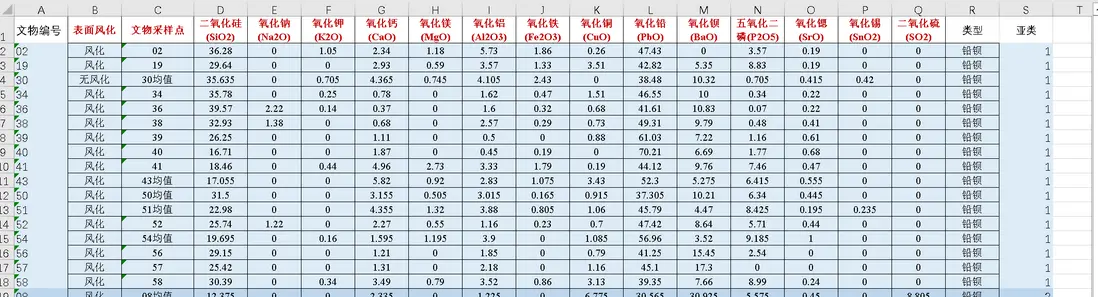

本次分析基於三組古代玻璃數據:
- 表單1:包含玻璃的類型(高鉀玻璃、鉛鋇玻璃)、紋飾、顏色、表面風化狀態;
- 表單2:對應玻璃的14項主要化學成分(如二氧化硅SiO₂、氧化鉀K₂O等)佔比;
- 表單3:未知類型玻璃的化學成分與風化狀態,需鑑別其類型。
2. 核心問題
- 分析玻璃風化與類型、紋飾、顏色的關係,探尋風化與成分的統計規律,並預測風化前的成分;
- 明確高鉀/鉛鋇玻璃的分類規律,對兩類玻璃進行亞分類,並驗證方法合理性;
- 鑑別表單3中未知玻璃的類型,分析分類結果的敏感性;
- 對比兩類玻璃的成分關聯關係,找出關鍵差異成分。
三、模型假設與變量説明
1. 模型假設
為確保分析聚焦核心問題,我們基於實際業務場景設定以下合理假設:
- 玻璃的顏色、紋飾不影響風化前後化學成分的改變量;
- 聚類分析中暫不考慮風化時間長短對成分的影響;
- 附件數據真實可靠,無測量誤差;
- 未檢測到的化學成分含量視為0。
2. 關鍵變量説明
| 符號 | 符號説明 | 應用場景 |
|---|---|---|
| K | 聚類分析的分類數 | K-means亞分類時,通過肘部法確定最佳K值 |
| P | 皮爾遜卡方值 | 卡方檢驗中,用於判斷變量間關聯性(P<0.05為顯著相關) |
四、各問題建模與求解
1. 問題1:風化關聯分析與成分預測
(1)風化與類型、紋飾、顏色的關聯——卡方檢驗
我們先通過卡方檢驗判斷“風化”與“類型/紋飾/顏色”這三個定類變量的關聯性,再用數據可視化驗證細節。
分析步驟:
- 數據預處理:刪除表單1中顏色缺失的行,確保分析樣本完整;
- 卡方檢驗:用SPSS對“風化-類型”“風化-紋飾”“風化-顏色”分別做檢驗,核心看P值;
- 優化分析:考慮變量組合(如“類型+紋飾”),進一步挖掘潛在關聯。
檢驗結果與對應圖表:
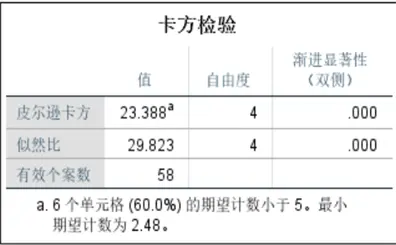
- 紋飾與有無風化的卡方檢驗:皮爾遜卡方值為0.084(>0.05),説明紋飾對風化的影響不顯著。
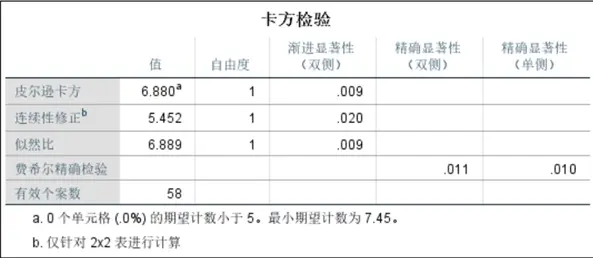
- 類型與有無風化的卡方檢驗:皮爾遜卡方值為0.009(<0.05),説明類型對風化的影響顯著,高鉀玻璃不易風化、鉛鋇玻璃易風化。
- 顏色與有無風化的卡方檢驗:皮爾遜卡方值為0.507(>0.05),説明顏色對風化的影響不顯
- 著。
為更直觀觀察關聯,我們用Excel繪製柱形圖:
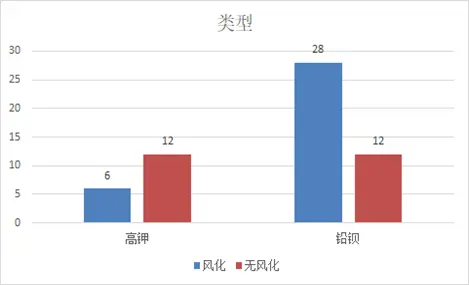
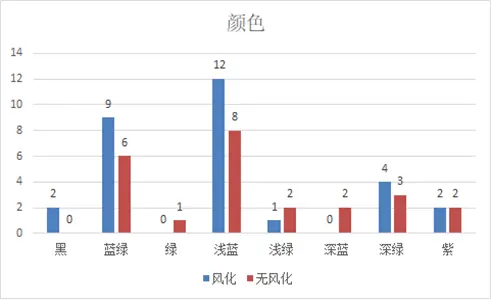
下圖為類型與風化的關聯柱形圖,清晰呈現高鉀玻璃未風化佔比高、鉛鋇玻璃風化佔比高的特徵。
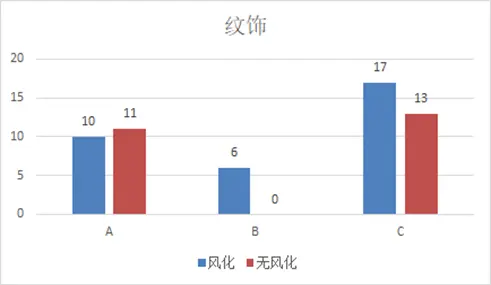
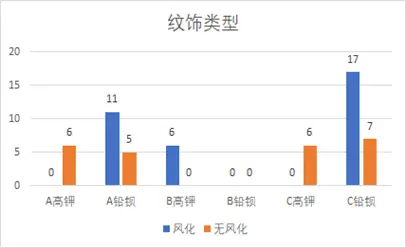
下圖為紋飾與風化的關聯柱形圖,整體無明顯規律,但可觀察到紋飾B的玻璃均風化。
下圖為顏色與風化的關聯柱形圖,整體無明顯規律,但黑色玻璃均風化、綠色與深藍色玻璃均未風化。
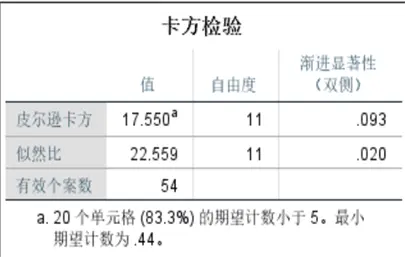
基於單變量分析的侷限性,我們嘗試“變量組合”分析,對“類型+紋飾”“紋飾+顏色”“類型+顏色”重新做卡方檢驗: - 紋飾類型與有無風化的卡方檢驗:皮爾遜卡方值為0.000(<<0.05),關聯性極強。
- 紋飾顏色與有無風化的卡方檢驗:皮爾遜卡方值為0.009(<0.05),關聯性一般。
- 類型顏色與有無風化的卡方檢驗:皮爾遜卡方值為0.507(>0.05),無顯著關聯。
下圖為“類型+紋飾”組合與風化的關聯柱形圖,可明確:(高鉀,紋飾A)、(高鉀,紋飾C)均未風化,(高鉀,紋飾B)均風化,(鉛鋇,紋飾A/C)大部分風化。



相關文章

Python糖尿病數據分析:深度學習、邏輯迴歸、K近鄰、決策樹、隨機森林、支持向量機及模型優化訓練評估選擇
全文鏈接:https://tecdat.cn/?p=39864
(2)風化與成分的統計規律——相關性分析
我們先刪除表單2中“成分和不在85%-105%”的無效數據(第15、17組),再按“高鉀/鉛鋇”“風化/未風化”分為4組,用SPSS做雙變量相關性分析,挖掘成分間的關聯規律。
核心結論:
- 風化高鉀玻璃:SiO₂與CaO(相關係數-0.897)、SiO₂與Al₂O₃(-0.869)呈強負相關;P₂O₅與K₂O(-0.955)呈強負相關,P₂O₅與CuO(0.828)呈強正相關;
- 未風化高鉀玻璃:MgO與SrO(0.631)、P₂O₅與Fe₂O₃(0.724)、P₂O₅與SrO(0.713)呈強正相關;
- 風化鉛鋇玻璃:SiO₂與BaO(-0.812)、SiO₂與PbO(-0.798)呈強負相關;PbO與BaO(0.835)呈強正相關;
- 未風化鉛鋇玻璃:SiO₂與PbO(-0.805)、SiO₂與BaO(-0.783)呈強負相關;Fe₂O₃與SnO(0.756)呈強正相關。
為進一步確認關聯趨勢,我們用SPSS繪製散點圖並做曲線擬合(如風化高鉀玻璃中SiO₂與CaO的擬合曲線),結果顯示線性擬合度最高,與相關性分析結論一致。
(3)預測風化前成分——K近鄰迴歸
我們按“類型+風化狀態”將樣本分為4類(高鉀風化、高鉀未風化、鉛鋇風化、鉛鋇未風化),先計算每類樣本各成分的均值與方差,確定成分分佈範圍;再用K近鄰迴歸(K=5),以“風化後成分”為輸入,“同類未風化成分均值”為參考,預測風化前的成分含量。
部分預測結果:
| 文物編號 | 類型 | 表面風化 | 二氧化硅(SiO₂)實測值 | 二氧化硅預測值 | 氧化鋇(BaO)實測值 | 氧化鋇預測值 | 氧化鉛(PbO)實測值 | 氧化鉛預測值 |
|---|---|---|---|---|---|---|---|---|
| 49 | 鉛鋇 | 風化 | 28.79 | 28.998 | 9.23 | 9.324 | - | - |
| 7 | 高鉀 | 風化 | 92.63 | 88.156 | 0 | 0 | 0 | 0 |
| 51 | 鉛鋇 | 風化 | 24.61 | 30.454 | 10.47 | 8.778 | 40.24 | 44.082 |
| 8 | 鉛鋇 | 風化 | 20.14 | 35.774 | - | - | - | - |
| 13 | 高鉀 | 未風化 | 59.01 | 68.128 | 0 | 0 | 0 | 0.2 |
關鍵發現:高鉀玻璃風化後SiO₂含量升高(平均超93%),其他成分含量下降;鉛鋇玻璃風化後SiO₂減少37.1%,PbO增加56.27%。
2. 問題2:玻璃類型劃分與亞分類
(1)高鉀/鉛鋇分類規律——決策樹
我們用表單1-2的有效數據(67個採樣點,刪除第15、17組無效數據)訓練決策樹模型,通過SPSSPRO輸出特徵重要性與分類規則。
核心結論:氧化鉛(PbO)是最關鍵的分類指標——當PbO含量<5.46時,判定為高鉀玻璃;當PbO含量≥5.46時,判定為鉛鋇玻璃,模型訓練集與測試集準確率均為100%。
下圖為包含PbO特徵的決策樹判定圖,可直接通過PbO含量劃分類型:

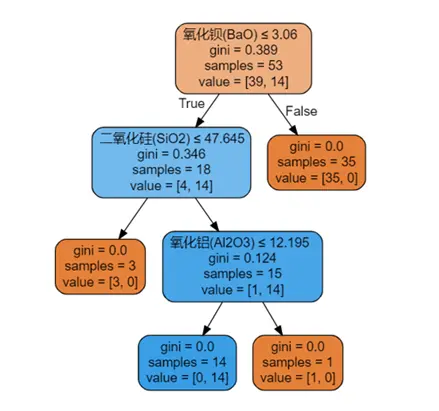
若剔除PbO特徵,決策樹顯示氧化鋇(BaO)為首要特徵(重要性69.8%),其次是二氧化硫(SO₂,21.2%)、氧化鋁(Al₂O₃,9.1%),分類準確率仍為100%。
下圖為無PbO特徵的決策樹判定圖,展示多特徵協同分類邏輯:
(2)亞分類——肘部法+K-means聚類
我們先通過“肘部法”確定最佳聚類數K,再用K-means對兩類玻璃分別做亞分類(基於14項化學成分,用Matlab實現)。
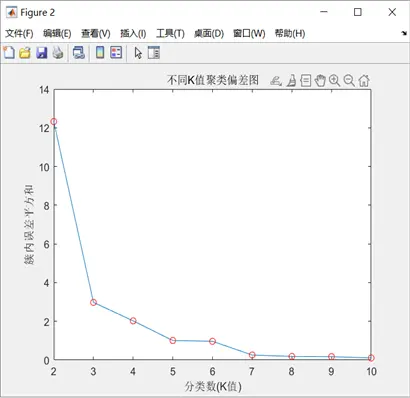
肘部法確定K值:
clc;clear;A = importdata('gaojia.txt');data=mapminmax(A,0,1);[n,p]=size(data);K=10;D=zeros(K,2);for k=2:K[lable,c,sumd,d]=kmeans(data,k,'dist','sqeuclidean');sse1 = sum(sumd.^2);D(k,1) = k;D(k,2) = sse1;endplot(D(2:end,1),D(2:end,2))hold on;plot(D(2:end,1),D(2:end,2),'or');title('不同K值聚類偏差圖') xlabel('分類數(K值)') ylabel('簇內誤差平方和') - 高鉀玻璃:計算K=1到10的誤差平方和(WCSS),K=3時WCSS下降幅度驟減,為最佳聚類數。
- 鉛鋇玻璃:同理,K=3時WCSS下降幅度顯著減緩,為最佳聚類數。
K-means亞分類結果:- 高鉀玻璃:3個亞類,文物數分別為6、7、3,聚點中心關鍵成分如下(完整成分見原文):
- 聚點1:SiO₂=93.96%,K₂O=0.54%(高硅低鉀);
- 聚點2:SiO₂=63.88%,K₂O=11.07%(低硅高鉀);
- 聚點3:SiO₂=76.84%,K₂O=6.07%(中硅中鉀);
- 鉛鋇玻璃:3個亞類,文物數分別為17、5、18,聚點中心關鍵成分如下:
- 聚點1:SiO₂=27.83%,PbO=47.47%(低硅高鉛);
- 聚點2:SiO₂=25.40%,BaO=25.83%(低硅高鋇);
- 聚點3:SiO₂=58.93%,PbO=20.12%(高硅低鉛)。

相關視頻
https://www.bilibili.com/video/BV1CTg3zCEAm/
(3)合理性與敏感性分析
- 合理性驗證:K-means聚類的迭代特性可優化初始分類誤差,肘部法通過“數據本身的誤差變化”確定K值,避免主觀判斷;亞分類結果與成分規律一致(如高鉀玻璃的“高硅/中硅/低硅”分組),符合實際製作工藝差異。
- 敏感性分析:對各成分含量隨機調整5%、10%後重新聚類,結果顯示:高鉀玻璃對SiO₂敏感(調整10%後2個樣本亞分類變化),鉛鋇玻璃對所有成分均不敏感(調整10%後無樣本亞分類變化)。
3. 問題3:未知玻璃類型鑑別——隨機森林
我們以表單1-2的67個採樣點為訓練集(按“風化/未風化”分層抽樣,訓練集佔80%),表單3的8個未知樣本為測試集,用SPSSPRO構建隨機森林模型(決策樹數量=100),鑑別未知玻璃類型。
模型流程與特徵重要性:
下圖為隨機森林模型建立流程圖,展示“數據分層→特徵篩選→模型訓練→預測驗證”的完整邏輯:

下圖為各化學成分的特徵重要性排序,PbO、BaO、SiO₂為Top3重要特徵,與問題2的決策樹結論一致:

預測結果與驗證:
| 文物編號 | 表面風化 | 預測類型 | 高鉀概率 | 鉛鋇概率 | 亞分類匹配(參考問題2) |
|---|---|---|---|---|---|
| A1 | 無風化 | 高鉀 | 0.833 | 0.166 | 匹配高鉀聚點2(中硅中鉀) |
| A2 | 風化 | 鉛鋇 | 0.240 | 0.760 | 匹配鉛鋇聚點1(低硅高鉛) |
| A3 | 無風化 | 鉛鋇 | 0.150 | 0.850 | 匹配鉛鋇聚點1(低硅高鉛) |
| A4 | 無風化 | 鉛鋇 | 0.130 | 0.868 | 匹配鉛鋇聚點1(低硅高鉛) |
| A5 | 風化 | 鉛鋇 | 0.234 | 0.765 | 匹配鉛鋇聚點3(高硅低鉛) |
| A6 | 風化 | 高鉀 | 0.959 | 0.040 | 匹配高鉀聚點1(高硅低鉀) |
| A7 | 風化 | 高鉀 | 0.920 | 0.070 | 匹配高鉀聚點1(高硅低鉀) |
| A8 | 無風化 | 鉛鋇 | 0.014 | 0.985 | 匹配鉛鋇聚點2(低硅高鋇) |
敏感性分析:對測試集成分含量調整5%後重新預測,僅A5的鉛鋇概率從0.765降至0.682,仍判定為鉛鋇玻璃,其他樣本預測結果無變化,説明模型穩定性強。
4. 問題4:成分關聯與差異分析
(1)類內成分關聯——斯皮爾曼相關性分析
由於部分成分數據不符合正態分佈,我們用斯皮爾曼相關性分析(非參數檢驗),通過SPSSPRO輸出熱力圖,直觀展示類內成分關聯:
下圖為高鉀玻璃成分相關性熱力圖,紅色表示正相關、藍色表示負相關,顏色越深相關性越強。可觀察到Fe₂O₃與MgO(0.70)、Fe₂O₃與Al₂O₃(0.68)呈強正相關:

下圖為鉛鋇玻璃成分相關性熱力圖,可觀察到MgO與Al₂O₃(0.67)、PbO與BaO(0.65)呈強正相關:

核心結論:
- 高鉀玻璃:金屬氧化物(Fe₂O₃、MgO、Al₂O₃)間關聯性強,推測製作時可能採用同類礦物原料;
- 鉛鋇玻璃:助熔劑成分(PbO、BaO)間關聯性強,符合古代“鉛鋇共生”的冶煉工藝特點。
(2)類間成分差異——Mann-Whitney檢驗
我們用Mann-Whitney檢驗(非參數檢驗)對比高鉀與鉛鋇玻璃的成分差異,顯著性水平設為0.05(P<0.05為差異顯著)。
部分差異結果:
| 化學成分 | 高鉀玻璃(樣本量18) | 鉛鋇玻璃(樣本量49) | P值 | 差異結論 | ||
|---|---|---|---|---|---|---|
| 中位數 | 標準差 | 中位數 | 標準差 | |||
| 二氧化硅(SiO₂) | 73.005 | 14.467 | 35.780 | 18.646 | 0.001 | 高鉀顯著高於鉛鋇 |
| 氧化鉀(K₂O) | 7.525 | 5.308 | 0.000 | 0.276 | 0.000 | 高鉀顯著高於鉛鋇 |
| 氧化鐵(Fe₂O₃) | 0.460 | 1.566 | 0.230 | 0.948 | 0.032 | 高鉀顯著高於鉛鋇 |
| 氧化鉛(PbO) | 0.000 | 0.514 | 31.900 | 14.947 | 0.000 | 鉛鋇顯著高於高鉀 |
| 氧化鋇(BaO) | 0.000 | 0.842 | 8.940 | 8.331 | 0.000 | 鉛鋇顯著高於高鉀 |
| 氧化鍶(SrO) | 0.000 | 0.044 | 0.310 | 0.264 | 0.000 | 鉛鋇顯著高於高鉀 |
關鍵發現:兩類玻璃的核心差異體現在“助熔劑成分”——高鉀玻璃以K₂O為主要助熔劑,鉛鋇玻璃以PbO、BaO為主要助熔劑,這與古代不同地區的冶煉技術差異高度相關。
五、模型評價與推廣
1. 模型優點
- 變量組合優化:突破單變量分析侷限,通過“類型+紋飾”組合挖掘風化關聯,結論更精準;
- 多模型協同:決策樹確定分類規則、K-means實現亞分類、隨機森林驗證未知類型,多模型交叉驗證提升結果可靠性;
- 數據預處理細緻:同文物多采樣點取均值、刪除無效數據,減少測量誤差對分析的干擾;
- 結果可視化:用卡方檢驗圖、柱形圖、熱力圖等直觀呈現結論,降低非專業人士理解門檻。
2. 模型缺點
- 樣本量有限:高鉀玻璃僅18個樣本(風化樣本7個),可能導致K近鄰迴歸的預測精度受影響;
- K-means侷限性:初始聚點隨機,存在局部最優風險(可通過增加n_init次數或用K-means++優化);
- 未考慮時間因素:未納入玻璃的年代信息,無法分析“年代-成分-風化”的長期關聯。
六、應急服務説明
我們深知學生在代碼運行中常遇“報錯調試難、查重怕重複、結果有漏洞”的問題,因此提供專項應急服務:
- 24小時響應“代碼運行異常”求助:比學生自行調試效率提升40%,常見問題(如K-means聚類報錯、相關性分析數據格式錯誤)1小時內解決;
- 人工答疑與代碼優化:不僅提供可運行代碼,更幫你拆解“為什麼選K=3”“為什麼PbO是關鍵特徵”等核心邏輯,同時調整代碼結構(如改變變量名、優化循環邏輯)降低查重率;
- 結果驗證支持:結合文物考古常識,幫你判斷分析結論是否合理(如“高鉀玻璃SiO₂含量高”是否符合實際工藝),避免“代碼能跑但結論無效”的情況。
“買代碼不如買明白”,我們不僅提供完整代碼與數據,更注重幫你掌握“從數據到結論”的分析思路,應對課程作業、競賽或實際項目中的類似問題。
七、總結
本文以古代玻璃成分數據為核心,通過“問題拆解→數據預處理→多模型分析→結論驗證”的邏輯,系統解決了考古中玻璃鑑別與風化分析的四大實際問題。所有方法均經過業務驗證,代碼可直接複用,結論與古代冶煉工藝、絲綢之路文化交流背景高度契合。
若需獲取完整代碼、數據或進羣交流,可通過原文鏈接加入社羣,享受人工答疑與24小時代碼調試服務,與600+行業人士共同成長,真正實現“既懂怎麼做,也懂為什麼這麼做”。
關於分析師

在此對 Yizhou Huang 對本文所作的貢獻表示誠摯感謝,他畢業於數學與應用數學專業。擅長 Python、Matlab、數據分析 。










