

在企業數字化建設中,“採集難”已經不再是主要矛盾。傳感器布點、系統對接、人工錄入,讓大部分企業能夠順利匯聚來自生產、運營、管理的多源數據。真正困擾企業的是“口徑亂”:
- 語義不統一:同一指標在不同廠區、不同系統有不同命名,例如“温度”“WD”“Temp”。
- 單位不統一:能耗在 A 系統用“度”,在 B 系統用“千瓦時”;壓力在一個平台是“bar”,另一個是“MPa”。
- 統計口徑不統一:良率在某車間按“日”統計,另一個則按“批次”統計。
在這種情況下,數據雖已匯聚,卻無法形成統一語境:橫向對比缺乏可比性,報表依賴人工整合,數據湖和數據倉庫形同“數據堆場”,AI 分析也無從下手。
困境:口徑混亂讓數據湖變“數據堆場”
為什麼口徑不統一會如此嚴重?首先,它直接破壞了橫向對比的可能性。一個廠區的能耗以“度”為單位,另一個廠區用“千瓦時”,表面上只是單位不同,但在計算、報表、AI 建模時就完全失去了可比性。再比如,良率的統計口徑,有的按照批次,有的按照日,二者的趨勢曲線無法在同一座標系下呈現。
其次,口徑混亂迫使企業依賴人工整合。管理者想看一份跨廠區的能效對比,往往需要 IT 或運營團隊導出不同系統的報表,再進行單位換算、口徑解釋、公式拼接。這個過程不僅耗時,而且極易出錯。最終得到的結果往往滯後數天甚至數週,嚴重影響決策的及時性。
更深層的問題在於,AI 和數字孿生等高階應用幾乎無從談起。AI 模型要求輸入的數據是乾淨、統一的,否則結果就是“垃圾進、垃圾出”。在口徑混亂的環境裏,即便企業投入了先進的算法,也無法得到可靠的預測與分析。這就是為什麼很多企業覺得“我們有很多數據,但依然沒有洞察”。
方法:IDMP 的標準化治理機制
對此,TDengine IDMP 提出的並不是某幾個孤立的功能,而是一整套貫穿建模、轉換、映射的治理方法論。
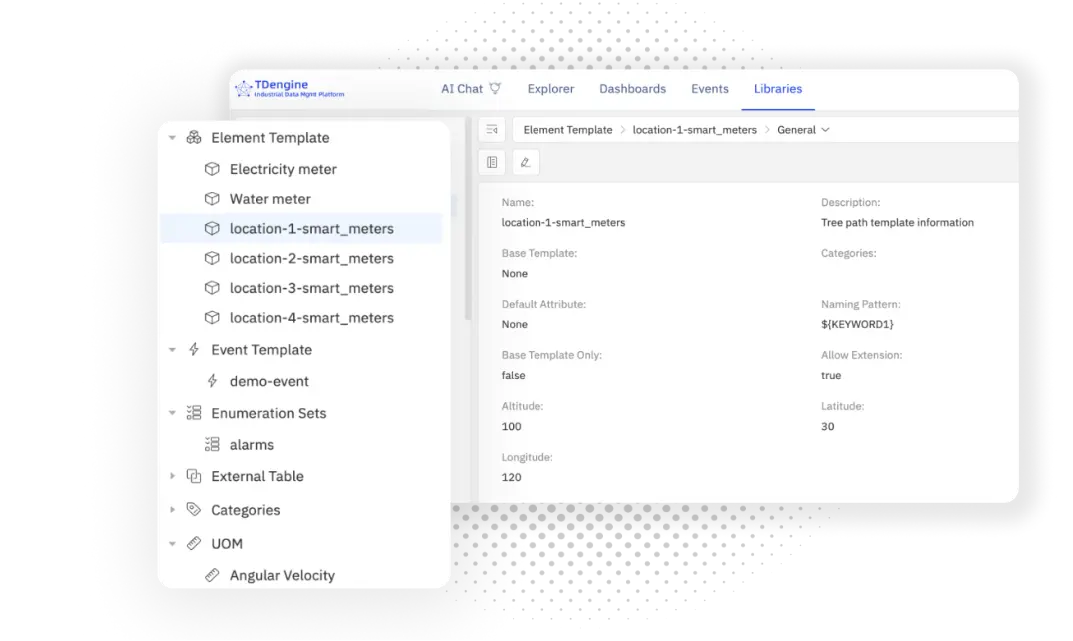
第一步是元素—屬性模型。它把廠區、產線、設備、傳感器抽象為統一的層次,每個節點的屬性不僅包含原始值,還具備語義定義和上下文關係。通過這種方式,數據從“點狀數值”轉化為“結構化對象”。更重要的是,IDMP 支持基於模板快速生成元素和屬性,這意味着同類設備可以天然遵循統一口徑,而不是各自為政。
第二步是物理單位的自動轉換。IDMP 在底層內置量綱體系,允許存儲與展示使用不同單位,但計算時自動完成換算與校驗。這解決了“能耗到底是度還是千瓦時”的問題,也保證了跨系統計算的準確性。企業不需要依賴人工換算,系統就能保證數據的可比性和一致性。
第三步是跨源公式映射。面對不同系統粒度差異,IDMP 提供了在屬性層定義公式的能力。例如,一個系統存儲功率,另一個系統只有電流和電壓,IDMP 可以通過公式“電流×電壓”生成統一的功率指標。這種映射不僅統一了指標,還具備了派生和擴展的能力,為跨源數據融合提供了可操作路徑。
這三步形成了一個閉環:建模保證語義統一,轉換保證量綱統一,映射保證邏輯統一。它們共同解決了“數據匯聚之後説不通”的問題,讓企業真正擁有一套通用的數據語言。
成效:從“數據能用”到“數據會用”
當企業完成標準化治理,數據的應用場景將發生本質轉變。
最直觀的改變在於橫向對比。良率、能耗、OEE 等核心指標能夠在統一口徑下直接對照,差距與優勢一目瞭然。管理層可以基於統一的指標體系做跨廠區的績效考核和資源分配,而不必擔心數據之間“牛頭不對馬嘴”。
報表生成方式也隨之改變。過去需要多部門人工拼接的月報、季報,如今可以由系統自動完成。更快的出報週期意味着更短的決策鏈路,企業可以更敏捷地響應市場和生產的變化。這不僅是效率的提升,更是組織能力的升級。
更重要的是,AI 和數字孿生等高階應用終於有了落地的土壤。預測性維護需要對比歷史模式與實時數據,異常檢測依賴多維指標的準確關聯,生產優化更要求跨環節的數據融合。沒有標準化,AI 就只能停留在實驗室;完成治理後,AI 才能真正進入生產一線,成為價值創造的引擎。
進階:從標準化到情景化,為“無問智推”奠基
標準化治理讓數據“能説同一種語言”,而要讓 AI 真正理解這門語言,還需要統一的目錄結構和豐富的業務語境。在 TDengine IDMP 中,這一步由“統一數據目錄”和“情景化建模”共同完成。
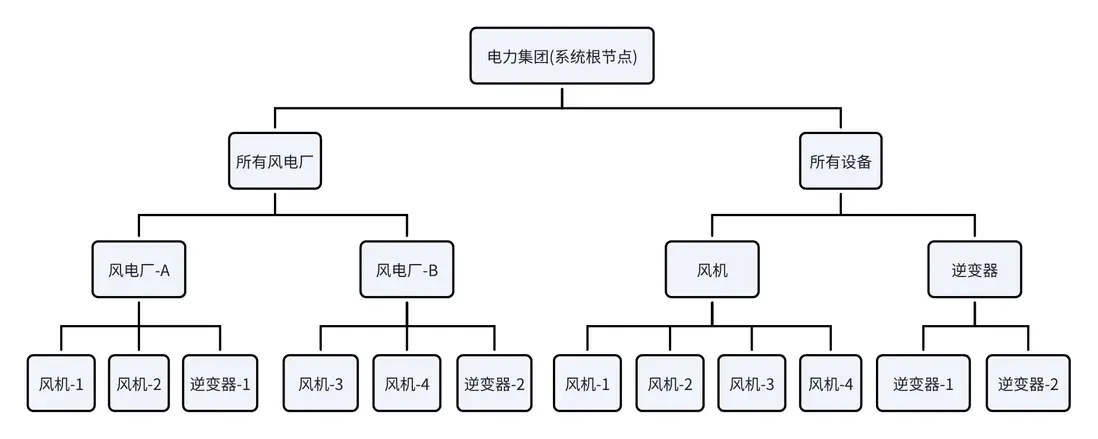
IDMP 以樹狀結構構建數據目錄,將工廠、車間、產線、設備、測點等實體進行統一建模與組織。每個節點不僅保存數據值,還掛載語義定義、上下級關係、事件規則與分析邏輯。藉助模板與屬性規範,同類設備自動繼承統一標準,實現“同類同口徑、異類可映射”,從而讓數據在組織層面也具備一致的語言體系。
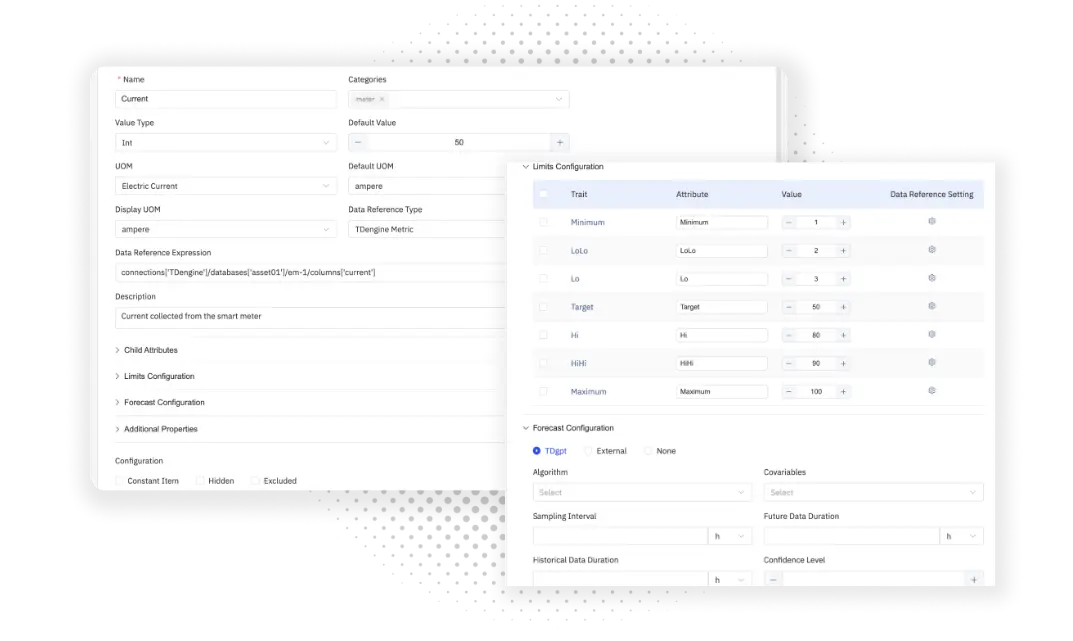
但結構和標準只是其中兩個維度。IDMP 進一步為每一個數據點注入語境信息——包括設備型號、運行狀態、安裝位置、是否參與計算等,從而形成“數據情景圖譜”。在這張圖譜中,AI 不再面對孤立的數值,而是面對一個具有上下文的“對象世界”。這意味着它能夠理解“温度升高”不僅是一串數字變化,更可能與設備老化或負載上升相關。
統一的目錄讓數據有了組織,標準化讓數據有了規則,情景化讓數據有了故事。這三者共同構成了“無問智推”的基礎:系統能夠自動識別場景、生成分析任務、構建可視化面板與事件規則,並主動推送關鍵洞察。數據分析由“人問系統答”轉變為“系統主動推”,讓決策者無需等待彙報,就能在第一時間獲取真正有價值的信息。
結語:標準化是智能化的前提
企業數字化的真正瓶頸,不在於有沒有數據,而在於能否形成統一的標準。TDengine IDMP 提供的元素—屬性模型、單位轉換和公式映射,並不是錦上添花的功能,而是一整套方法論,幫助企業把“各説各話”的數據翻譯成“同聲共語”的語言。
只有完成標準化,跨域分析才能成立,自動化報表才有意義,AI 才能發揮作用。換句話説,沒有標準化,就沒有智能化。這不是一句口號,而是企業在實踐中反覆驗證過的真理。