

引言:時序數據浪潮下的數據庫革命與選型命題
當工業生產線的傳感器每秒傳來數千條運行數據,當智能電網的電錶實時回傳億級用户的用電信息,當時序數據以“井噴式”態勢佔據全球數據總量的70%以上,傳統數據管理工具早已力不從心。2025年,全球物聯網活躍終端已達350億台,中國工業物聯網市場規模突破1.8萬億元,這些設備產生的時序數據不僅具備“高頻採集、海量存儲、實時分析、低更新率”的核心特徵,更對數據處理的性能、成本與穩定性提出了嚴苛要求。
關係型數據庫如MySQL、Oracle在面對這類數據時,暴露出高併發寫入時的鎖表瓶頸、時間維度查詢的低效以及存儲成本劇增等天然短板。曾有某特鋼企業嘗試用Oracle存儲生產設備數據,僅半年就因存儲成本飆升3倍而被迫重構系統。此時,時序數據庫(Time Series Database, TSDB)應運而生,成為解決時序數據管理難題的核心載體。
然而,當前時序數據庫市場產品林立,OpenTSDB、InfluxDB、Druid等各類產品特性各異,如何在複雜需求中精準選型,成為企業數字化轉型的關鍵命題。本文將以時序數據庫的科學分類為切入點,剖析技術演進邏輯,結合實際選型標準,聚焦國產自研標杆TDengine的創新價值,為企業時序數據庫選型提供清晰指引。
一、時序數據庫的核心分類:選型的基礎認知框架
時序數據庫的分類並非單純的技術標籤,而是與企業業務場景、IT架構、成本預算深度綁定的選型依據。從技術架構、部署模式與功能定位三個維度進行劃分,能為選型提供清晰的決策座標系。
1.1 按技術架構劃分:組裝型vs專精型,性能與依賴的權衡
技術架構直接決定數據庫的性能上限與運維複雜度,是選型的核心考量因素。當前市場主要分為兩類架構:
(1)基於開源組件封裝的“組裝型”時序數據庫
這類數據庫本質是在成熟開源組件基礎上進行二次開發,藉助現有存儲引擎實現時序數據管理能力,典型代表為OpenTSDB(依賴HBase)與Druid(依賴Hadoop生態)。其核心優勢在於兼容性強,能快速融入已有大數據架構,對於已部署Hadoop集羣的企業而言,初期接入成本較低。
但“組裝”特性也帶來了難以規避的侷限:性能受限於底層組件,如同“戴着鐐銬跳舞”。OpenTSDB因依賴HBase的列存儲特性,在多維度組合查詢時需頻繁掃描全局數據,查詢延遲常突破秒級;Druid則需依賴Zookeeper進行集羣協調,部署時需同時維護Hadoop、Zookeeper、Kafka等多個組件,某智能製造企業曾統計,Druid集羣的運維人員投入是數據庫本身部署人員的3倍。這類數據庫更適合數據規模中等、查詢場景簡單且已有成熟開源生態的企業。
(2)原生自研的“專精型”時序數據庫
為突破組件依賴的性能瓶頸,原生自研架構應運而生,InfluxDB與TDengine是該領域的代表。這類數據庫圍繞時序數據特性重構存儲引擎與計算邏輯,完全擺脱第三方組件依賴,實現“專庫專用”的性能優化。
InfluxDB通過自研的TSM(Time-Structured Merge)引擎實現高壓縮比存儲,但在設備數量突破百萬級後,元數據管理效率急劇下降;而TDengine則構建了“存儲-計算-分析”一體化原生架構,不僅規避了組件依賴,更通過數據模型創新解決了高基數場景的性能難題。在中科院成都所的捲煙廠項目選型中,正是由於排除了依賴複雜的組裝型數據庫,才為後續每秒4萬條數據的穩定處理奠定了基礎。對於高併發、高基數的工業場景,原生自研架構是更可靠的選型方向。
1.2 按部署模式劃分:傳統部署vs雲原生,彈性與成本的平衡
部署模式的選擇與企業的IT戰略緊密相關,尤其在“雲化轉型”的大趨勢下,彈性擴展能力成為關鍵選型指標。
傳統私有化部署型以早期InfluxDB、OpenTSDB為代表,需手動配置集羣節點、分配存儲資源,擴展時需停機調整,靈活性嚴重不足。這類部署模式僅適合數據規模穩定、設備增長可預測的傳統企業,在物聯網設備快速擴容的場景下已逐漸被淘汰。
雲原生分佈式部署則成為當前主流,TDengine與InfluxDB Cloud是典型代表。其核心優勢在於計算與存儲分離,支持彈性伸縮,能根據數據寫入量自動調整資源配置。TDengine更是將雲原生優勢發揮到極致,支持100+節點的大規模集羣部署,集羣啓動速度控制在1分鐘內,某能源企業通過TDengine雲原生集羣,實現了從10萬級智能電錶到500萬級的平滑擴容,期間未發生一次服務中斷。對於業務增長快、設備規模不確定的企業,雲原生部署是必然選型。
1.3 按功能定位劃分:單一存儲vs全棧方案,架構與效率的博弈
時序數據處理往往涉及採集、存儲、計算、分析等全鏈路環節,數據庫的功能定位直接決定了整體架構的複雜度。
單一存儲型數據庫僅提供基礎的存儲與查詢功能,如Prometheus,需額外集成Flink(流計算)、Redis(緩存)、Kafka(消息隊列)等工具才能形成完整解決方案。某互聯網企業的IT運維繫統曾採用“Prometheus+Redis+Flink”架構,僅數據鏈路調試就耗時2個月,後續故障排查時因組件過多,定位問題平均耗時4小時。
全棧解決方案型數據庫則內置數據採集、緩存、流計算等能力,TDengine是該領域的標杆。其無需集成第三方組件,通過內置的MQTT、Modbus協議支持,可直接對接工業傳感器,零代碼實現數據ETL;內置的緩存機制更是取代了Redis的依賴,中科院成都所的捲煙廠項目通過配置TDengine的cachemodel參數,實現了海量數據寫入時的毫秒級查詢響應。對於追求架構簡化、運維高效的企業,全棧型數據庫是更優選型。
二、行業痛點與破局點:TDengine的選型價值根基
企業在時序數據庫選型中面臨的核心痛點——高基數性能衰減、存儲成本高企、架構複雜——正是TDengine的技術突破方向。理解這些痛點與破局邏輯,才能把握選型的核心價值。
2.1 三大行業痛點:傳統TSDB的選型困境
(1)高基數場景性能懸崖
“高基數”即海量設備或指標帶來的大量時間線,是工業物聯網場景的典型特徵。傳統TSDB在設備數量突破千萬級後,查詢延遲呈指數級上升:InfluxDB在時間線達到500萬時,查詢響應時間從100ms增至2s以上;OpenTSDB更是在千萬級設備場景下頻繁出現查詢超時。某汽車製造企業的焊裝車間曾因採用傳統TSDB,設備故障預警延遲達10分鐘,導致批量產品瑕疵。

(2)存儲成本居高不下
時序數據量呈線性增長,存儲成本成為企業沉重負擔。傳統數據庫採用通用壓縮算法,壓縮比僅2:1~3:1,某石油企業的油井數據每年產生10PB原始數據,採用Oracle存儲需投入上億元採購存儲設備,且每年運維成本增長20%。
(3)架構複雜運維艱難
多組件集成的架構不僅增加部署難度,更帶來高昂的運維成本。某化工企業的生產監控系統採用“Druid+Hadoop+Zookeeper”架構,配備了5人運維團隊仍難以應對頻繁的組件兼容性問題,平均每月系統中斷2~3次。
2.2 TDengine的針對性技術突破
(1)超級表架構解決高基數難題
TDengine創新提出“超級表(Super Table)+子表”數據模型,這一設計的核心支撐正是“一個採集點一張表”的架構理念,從根源上解決了高基數場景的性能困局。在工業物聯網中,每個傳感器、智能電錶、設備模塊都是一個獨立的“採集點”,TDengine為每個採集點單獨創建一張子表,這種精細化設計與傳統TSDB將多采集點數據混存於單表的模式形成鮮明對比。
“一個採集點一張表”的創新價值體現在三個維度:其一,數據隔離性強,每個採集點的寫入、更新操作僅作用於自身子表,避免了傳統混存模式下的寫鎖競爭,某汽車焊裝車間部署後,設備數據寫入併發量提升至原來的8倍;其二,數據特徵一致性高,同一採集點的時序數據具有極強的相關性,為後續壓縮算法的高效運行奠定基礎,使單採集點數據壓縮比提升30%以上;其三,查詢定位精準,當需要調取某採集點數據時,可直接定位至對應子表,無需在海量混存數據中過濾篩選,某特鋼企業的温度傳感器數據查詢延遲從500ms降至30ms。
超級表作為同類型採集點的“模板”,定義了採集點的共性屬性(如設備型號、廠區、所屬生產線等)作為標籤(TAG),這些元數據單獨存儲並建立索引;而每個採集點的具體時序數據(如温度、壓力、電壓等)則存儲於專屬子表中。這種“元數據-業務數據”分離+“採集點-子表”一一對應的架構,使TDengine可支持10億級時間線穩定運行,某特鋼企業採用該模型後,設備數據查詢延遲從小時級縮短至5分鐘內,問題定位效率提升12倍。
(2)虛擬表技術:輕量聚合與靈活查詢的利器
除超級表外,虛擬表(Virtual Table)是TDengine另一項關鍵技術設計,它為多表聚合查詢與數據共享提供了高效解決方案。虛擬表並非物理存儲數據,而是基於用户查詢需求動態生成的“邏輯表”,其數據來源於一個或多個子表的篩選與聚合結果,僅在查詢時臨時構建,不佔用額外存儲資源。在工業場景中,當需要對多條生產線、多個車間甚至跨廠區的設備數據進行聯合分析時,傳統方式需編寫複雜的多表關聯語句,效率低下且易出錯。而TDengine的虛擬表可預先定義聚合規則(如按廠區分組、按設備類型聚合),用户直接查詢虛擬表即可獲得彙總數據,大幅簡化查詢邏輯。例如,某汽車製造企業通過創建“總裝車間設備運行虛擬表”,將車間內2000+設備的狀態數據實時聚合,運維人員查詢車間整體運行指標的響應時間從5秒縮短至300ms。同時,虛擬表支持權限精細化管控,可向不同部門開放不同虛擬表的查詢權限,在保障數據安全的前提下實現數據高效共享,避免了數據冗餘拷貝。
(3)專屬壓縮算法實現成本革命
針對時序數據的相關性特徵,TDengine開發專屬壓縮算法,結合時間戳差值編碼、數值delta編碼等技術,實現10:1~50:1的超高壓縮比。中石油油田系統採用TDengine後,存儲成本從Oracle方案的每PB 2000萬元降至100萬元以下,僅為原方案的2%~5%。同時,其支持熱數據(內存)、温數據(SSD)、冷數據(對象存儲)的分級存儲,進一步降低長期存儲成本。
針對時序數據的相關性特徵,TDengine開發專屬壓縮算法,結合時間戳差值編碼、數值delta編碼等技術,實現10:1~50:1的超高壓縮比。中石油油田系統採用TDengine後,存儲成本從Oracle方案的每PB 2000萬元降至100萬元以下,僅為原方案的2%~5%。同時,其支持熱數據(內存)、温數據(SSD)、冷數據(對象存儲)的分級存儲,進一步降低長期存儲成本。
(4)一體化架構簡化運維
TDengine將數據採集、存儲、計算、分析融為一體,內置MQTT、OPC-UA等工業協議接口,直接對接PLC、傳感器等設備;內置的流計算引擎支持滑動窗口、聚合分析等實時計算,無需集成Flink等工具。某電力企業的智能電錶項目通過TDengine,將原有“採集網關+Kafka+InfluxDB+Flink”的複雜架構簡化為單一數據庫,部署時間從1個月縮短至3天,運維人員減少70%。
TDengine將數據採集、存儲、計算、分析融為一體,內置MQTT、OPC-UA等工業協議接口,直接對接PLC、傳感器等設備;內置的流計算引擎支持滑動窗口、聚合分析等實時計算,無需集成Flink等工具。某電力企業的智能電錶項目通過TDengine,將原有“採集網關+Kafka+InfluxDB+Flink”的複雜架構簡化為單一數據庫,部署時間從1個月縮短至3天,運維人員減少70%。
三、國產標杆TDengine:技術特性與選型適配場景
作為國產時序數據庫的領軍者,TDengine的技術特性與產品矩陣形成了覆蓋全場景的選型方案,無論是中小企業的輕量化需求,還是大型企業的複雜部署,都能找到適配版本。
3.1 底層架構:為時序場景量身定製的性能基石
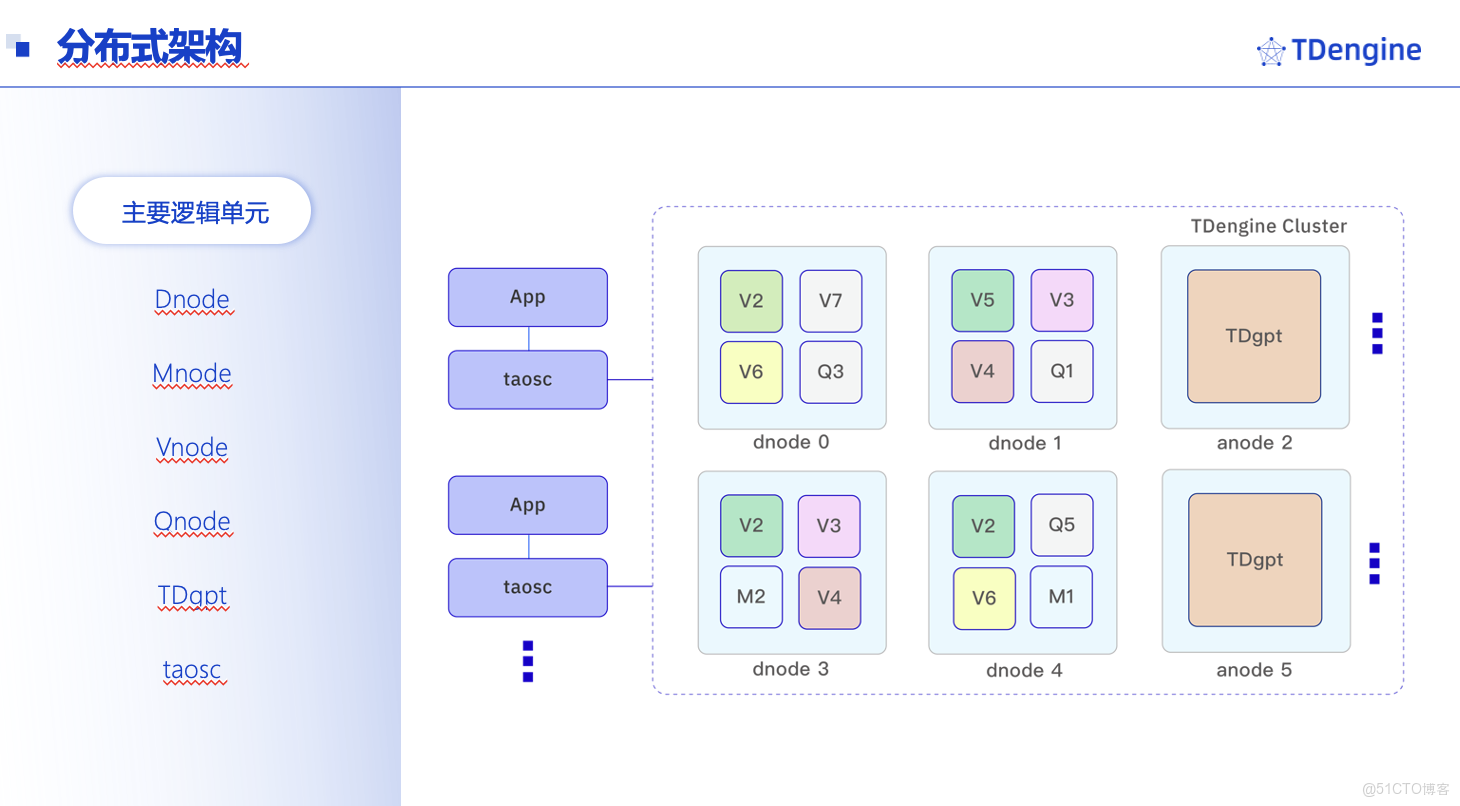
(1)分佈式設計支撐海量擴展
TDengine採用計算與存儲分離的分佈式架構,支持100+節點集羣部署,單集羣可承載10億級時間線與PB級數據。其通過Raft協議實現多副本容災,數據副本數可靈活配置,確保極端情況下的數據不丟失;WAL(Write-Ahead Log)機制則保障了高併發寫入時的數據一致性,某互聯網企業的運維繫統在每秒200萬條數據寫入場景下,仍實現99.99%的可用性。
(2)混合引擎兼顧讀寫性能
結合B樹與LSM引擎的優勢,TDengine實現了元數據查詢與數據寫入的性能平衡:B樹索引加速標籤查詢與最新數據獲取,LSM引擎則優化批量寫入性能,避免隨機IO。在中科院成都所的捲煙廠項目中,該混合引擎支撐了每秒4萬條數據的穩定寫入,同時保障了多終端同步查詢的毫秒級響應。
3.2 四大核心能力:選型的核心價值支撐
(1)極致性能:權威測試驗證的效率優勢
在國際權威的TSBS(Time Series Benchmark Suite)測試中,TDengine展現出碾壓式的性能優勢:寫入性能達到InfluxDB的10.6倍、TimescaleDB的6.7倍;複雜查詢性能更是高達InfluxDB的37倍、TimescaleDB的28.6倍。這種性能優勢在工業場景中體現為顯著的業務價值——某捲煙廠通過TDengine實現煙支質量指標的實時分析,不合格品剔除率降低15%,年節約原材料成本300萬元。
(2)開發友好:降低技術門檻的選型加分項
TDengine全面支持標準SQL,開發者無需學習新的查詢語法,可直接使用“SELECT AVG(value) FROM table WHERE ts BETWEEN ...”等熟悉語句進行數據分析;兼容Grafana、PowerBI等主流可視化工具,數據可視化配置僅需10分鐘。某新能源企業的運維團隊表示,從InfluxDB遷移至TDengine後,開發效率提升40%。
(3)AI原生:賦能智能分析的未來屬性
內置的TDgpt智能體使非專業人員也能通過自然語言生成SQL查詢,實現異常檢測、趨勢預測等AI分析能力。某光伏企業通過TDgpt生成“預測未來24小時光伏組件發電量”的SQL語句,無需AI團隊介入即可完成能源預測,支撐調度決策。
(4)國產化適配:滿足信創需求的必然選擇
TDengine完全適配鯤鵬、飛騰芯片及麒麟、統信操作系統,通過多項國產化認證,成為政企單位信創項目的首選時序數據庫。某政務雲項目在選型中,正是由於TDengine的全面國產化適配能力,從5款候選產品中脱穎而出。
3.3 產品矩陣:全場景覆蓋的選型方案
-
TDengine OSS:開源全功能版本,支持單機與集羣部署,零成本滿足開發者測試與中小企業的業務需求,社區提供完善的技術文檔與問題解答,降低入門門檻。
-
TDengine Enterprise:私有化部署的企業級版本,提供細粒度權限管控、跨地域數據同步、審計日誌等企業級特性,適合對數據安全與合規性要求高的工業、金融企業。
-
TDengine Cloud:全託管雲服務,無需部署與運維,支持按量付費,可快速對接阿里雲、騰訊雲等公有云資源,適合初創企業與雲原生架構的業務場景。
四、主流時序數據庫橫向對比:TDengine的選型競爭優勢
選型的本質是多維度對比後的最優決策。通過技術架構、性能、成本等核心維度的橫向對比,TDengine的競爭優勢清晰凸顯:
| 對比維度 | TDengine | InfluxDB | OpenTSDB | Druid | 選型適配場景 |
|---|---|---|---|---|---|
| 技術架構 | 原生自研,B樹+LSM混合引擎 | 原生自研,TSM引擎 | 依賴HBase,封裝實現 | 依賴Hadoop,Lambda架構 | TDengine適配高基數、高併發場景;其他適合簡單場景 |
| 高基數支持 | 10億級時間線,性能穩定 | 百萬級,超量後性能衰減明顯 | 千萬級,查詢靈活性低 | 千萬級,部署複雜 | 工業物聯網、智能電網等海量設備場景優先選TDengine |
| 存儲壓縮比 | 10:1~50:1 | 5:1~10:1 | 3:1~5:1 | 4:1~8:1 | PB級數據存儲場景,TDengine成本優勢顯著 |
| 部署運維成本 | 一體化架構,1人即可維護 | 需集成緩存,2人運維團隊 | 依賴HBase,3人以上團隊 | 依賴多組件,5人以上團隊 | 中小企業優先選TDengine,降低人力成本 |
| 國產化適配 | 完全適配鯤鵬/麒麟體系 | 部分適配 | 依賴開源生態,適配有限 | 適配複雜 | 信創項目唯一優選TDengine |
| TSBS寫入性能 | 10.6倍於InfluxDB | 基準值1 | 0.3倍於InfluxDB | 0.5倍於InfluxDB | 高併發寫入場景(如工業監控)首選TDengine |
五、行業實踐:TDengine的選型落地價值體現
選型的最終價值在於業務落地效果。TDengine在多個行業的成功實踐,驗證了其技術特性與業務需求的精準匹配。
5.1 工業製造:捲煙廠的實時質量管控實踐
中科院成都所的捲包智慧工藝平台需支撐多家捲煙廠的生產監控,每秒採集4萬條設備與質量數據,要求實時預警煙支重量、空頭等異常。在選型過程中,團隊對比了InfluxDB、TimescaleDB等產品,最終TDengine憑藉三大優勢勝出:
-
超級表模型支撐10萬+設備的高基數管理,標籤索引使質量指標查詢響應時間穩定在1秒內;
-
內置緩存取代Redis,簡化架構的同時實現毫秒級最新數據訪問;
-
15:1的壓縮比使存儲成本降低80%,年節約存儲費用超百萬元。
落地後,捲煙廠的煙支不合格剔除率降低15%,設備停機時間減少20%,實現了從“經驗判斷”到“數據決策”的轉型。
5.2 鋼鐵行業:特鋼企業的降本增效實踐
某特鋼企業的鍊鋼車間有5000+傳感器,實時採集温度、壓力等數據,原採用“Oracle+Redis”架構,面臨存儲成本高、查詢延遲長的問題。選型TDengine後:
-
服務器數量從100台降至3台,硬件成本減少70%;
-
數據追溯時間從2小時縮短至5分鐘,故障定位效率提升24倍;
-
分佈式架構支持多廠區數據統一管理,運維成本降低80%。
5.3 電力行業:智能電錶的負荷預測實踐
某省級電力公司負責500萬+智能電錶的數據管理,需實時採集用電數據並預測區域負荷。選型TDengine後:
-
通過MQTT協議直接對接電錶,零代碼實現數據採集,部署效率提升5倍;
-
10億級時間線支持電錶數量未來5年的擴容需求;
-
內置流計算引擎實時分析負荷數據,預測準確率提升至92%,支撐電網精準調度。
六、時序數據庫選型方法論與未來展望
結合前文分析與實踐案例,時序數據庫的選型可總結為“三明確、兩評估、一驗證”的科學方法論,同時技術演進趨勢也為未來選型提供了方向。
6.1 科學選型方法論:從需求到落地的全流程決策
-
三明確:明確業務場景(高併發寫入/複雜查詢/高基數)、明確IT架構(雲原生/私有化/信創要求)、明確成本預算(硬件/運維/擴容成本);
-
兩評估:評估技術匹配度(架構是否適配場景、性能是否滿足需求)、評估生態成熟度(文檔支持/社區活躍度/行業案例);
-
一驗證:基於真實業務數據進行POC測試,驗證寫入性能、查詢延遲、壓縮比等核心指標,避免“紙上談兵”。
按照該方法論,高基數、高併發的工業場景應優先選擇TDengine;中小規模監控場景可考慮InfluxDB;已有Hadoop生態的簡單場景可選用Druid,但需預留運維資源。
6.2 技術趨勢與未來選型方向
時序數據庫的未來將向“雲原生深化、AI融合、多模態處理”三大方向演進,這也將影響未來的選型決策:
-
雲原生深化:Serverless架構將成為主流,按需付費模式進一步降低中小企業的入門成本,TDengine Cloud已在該方向佈局;
-
AI與時序融合:時序數據的異常檢測、趨勢預測將實現“零代碼化”,TDengine的TDgpt已展現領先優勢;
-
多模態處理:支持時序數據與視頻、文本等多類型數據的融合分析,滿足工業質檢等複雜場景需求。
6.3 結語:國產時序數據庫的選型新標杆
從“跟跑”到“領跑”,TDengine通過原生架構創新、極致性能優化與全場景產品覆蓋,重新定義了時序數據庫的選型標準。對於企業而言,選擇TDengine不僅是技術方案的決策,更是把握數字經濟機遇的戰略選擇——其帶來的性能提升、成本降低與架構簡化,將成為企業數字化轉型的核心競爭力。在國產數據庫崛起的浪潮中,TDengine正以選型標杆的姿態,為千行百業的時序數據管理提供堅實底座。