









工業企業搞數字化轉型,最頭疼的莫過於 “數據基礎設施跟不上”—— 成千上萬的設備測點、實時涌來的時序數據、雲與 AI 的落地需求,選不對平台不僅白費錢,還會拖慢整個轉型節奏。今天我們就拿兩款主流工業數據平台——TDengine 與 AVEVA PI System 做深度對比,幫你理清選型思路,避開 “高價踩坑”“擴展受限” 的雷區。
先認識下兩款核心平台
關於 AVEVA PI System
作為工業數據領域的 “前輩”,PI System 最早由 OSIsoft 開發,如今歸屬於 AVEVA 旗下,也是全球應用較廣的工業數據基礎設施之一。它的核心能力是 “管好物聯數據”:實時採集中控系統、傳感器、設備的時序數據,再把這些數據整合(比如對接數千個數據源)、搭上下文模型,最後把信息給到操作員、工程師或業務系統,支撐監控與基礎分析。
關於 TDengine
TDengine 是專門針對工業場景設計的 AI 驅動型數據平台,核心由兩部分組成:
- TDengine TSDB:負責 “快準穩” 地搞定數據採集、存儲與處理,應對工業場景的高併發、大流量數據毫無壓力;
- TDengine IDMP(AI 原生工業數據管理平台):幫數據 “從無序變有用”——做語義化、標準化處理,還能直接落地 AI 分析,讓企業的時序數據不只是 “躺在庫裏”,而是真正產生價值。
6 個核心維度對比:哪款更適配你的需求?
TDengine 和 PI System 在「遠程運維監控」「實時數據支撐」「數據科學分析」「對外數據共享」等場景中可互相替代,但在設計理念和落地能力上,差異很明顯——我們從企業最關心的 6 個維度進行拆解:
1. 價格:按 “額度” 算 vs 按 “用量” 算,大規模場景成本差在哪?
工業企業動輒上萬、甚至上百萬個測點,價格是否可控直接影響選型。
- AVEVA PI System:採用 “Flex 額度購買制”——想用平台及相關服務,必須先買額度。但測點越多、數據量越大,額度消耗越快,成本很容易 “失控”,後期幾乎沒有議價空間;
- TDengine :按計算資源訂閲,用多少算多少,價格全透明——TDengine Cloud 的價目表在官網就能直接查,不用反覆和銷售溝通詢價。對大規模數據場景的企業來説,能顯著降低長期成本。
2. 雲支持:“後補雲功能” vs “雲原生架構”,部署體驗差多少?
現在企業搞數字化,幾乎離不開 “雲 + 邊緣” 的混合部署,但兩款平台的雲適配能力天差地別:
- AVEVA PI System:誕生於雲計算普及前,想上雲必須額外部署 AVEVA CONNECT(原 Data Hub),導致雲端和本地體驗割裂,跨站點部署也很複雜。而且它只支持 Windows 和 Azure,用 Linux 或 AWS 的企業直接 “勸退”;
- TDengine :天生是雲原生架構—— 既能在 Windows、Linux 邊緣節點跑,也能部署在公有云(AWS/Azure/GCP/阿里雲)、私有云或混合雲裏,甚至能直接用三大雲的全託管服務。本地和雲端體驗完全一致,還能充分利用雲的彈性擴展能力,不用額外搭 “中間件”。
3. AI 集成:“需手動搭管道” vs “內置大模型”,智能分析門檻差在哪?
工業數據的核心價值是 “預測與決策”,AI 能力直接決定平台的上限:
- AVEVA PI System:本身沒有內置 AI 或大模型功能,想做智能分析(比如設備故障預測),得自己搭數據管道,再對接第三方 AI 工具——不僅耗時耗力,還得額外投入 IT 成本,中小企業很難落地;
-
TDengine :把 AI 能力 “原生集成” 進 IDMP 裏,不用額外折騰——
- 支持 “無問智推”:不用手動設置,自動生成可視化面板和實時分析任務;
- 自帶 Chat BI:用自然語言就能查數據(比如 “查 3 號車間水泵近 7 天的壓力波動”),非技術崗也能上手;
- 內置 TDgpt:基於 AI/ML 的預測、異常檢測直接在平台裏完成,不用再對接外部系統。
4. 數據共享:“有限 API” vs “多協議分發”,實時性差在哪?
工業場景需要 “數據實時流動”,比如 AI 模型要實時取數、業務系統要實時更新,數據共享能力很關鍵:
- AVEVA PI System:靠 AVEVA CONNECT 創建自定義視圖,再通過 REST API 給外部系統傳數據,方式單一,實時性很難保證;
- TDengine :除了傳統查詢,還支持發佈 - 訂閲模式的數據分發——兼容 Kafka 協議和標準 MQTT,新數據產生後能實時推送,天生適配 AI 實時分析、業務系統實時聯動的場景。
5. 生態與開放性:“封閉生態” vs “開源內核”,會不會被 “綁定”?
企業選平台,最怕 “後期想擴展卻被廠商卡脖子”:
- AVEVA PI System:屬於封閉生態,想擴展功能、對接其他工具,幾乎只能用官方提供的組件,後期很難脱離廠商獨立升級;
- TDengine :基於開源內核,提供 JDBC、ODBC 等標準接口,能輕鬆對接 Power BI、Tableau、Grafana 等第三方工具。不用擔心 “被單一廠商綁定”,後期想換工具、做二次開發都很靈活。
6. 開發者友好性:“僅 REST API” vs “多語言客户端”,開發效率差多少?
平台好不好用,開發者最有發言權:
- AVEVA PI System:只提供 REST API,開發選擇非常有限,想對接不同語言的系統(比如 Python 數據科學庫、Java 業務系統),得自己寫適配代碼;
- TDengine :除了 REST API,還提供多語言客户端庫(Python/R/Java/C#/Go/Rust 等),附帶完整示例代碼,開發者拿過去就能直接調用。而且核心組件開源,能深入看底層邏輯,二次開發時不用 “黑箱調試”。
選型建議:該選 PI System 還是 TDengine?
客觀説,AVEVA PI System 作為工業數據平台的 “標杆”,早年確實幫很多企業搭起了數據基礎。但受限於早期架構,到了雲時代、AI 時代,它的性價比和擴展性已經沒那麼靈活了:
- 如果你的企業已經在用 PI System,且當前場景不需要雲擴展、AI 分析,沒必要急着替換,繼續用現有系統即可;
- 如果你的企業打算新建數據項目,或想升級現有基礎設施,優先考慮貼合 “雲 + AI” 趨勢的平台——畢竟數字化是長期投入,選對底層平台能少走 3 年彎路。
如果你的需求是這三類,TDengine 會更適配:
- 想充分利用雲計算、AI 技術,降低運維複雜度;
- 測點多(上萬級以上)、數據量大,希望長期控制成本;
- 不想被單一廠商綁定,需要開放的生態來對接現有工具。
它的開放生態能避免 “鎖定風險”,透明定價能控制成本,面對大規模設備接入場景,還能顯著降低總擁有成本(TCO)——簡單説,就是讓數據基礎設施既 “好用” 又 “不貴”。
核心功能對照表(一目瞭然)
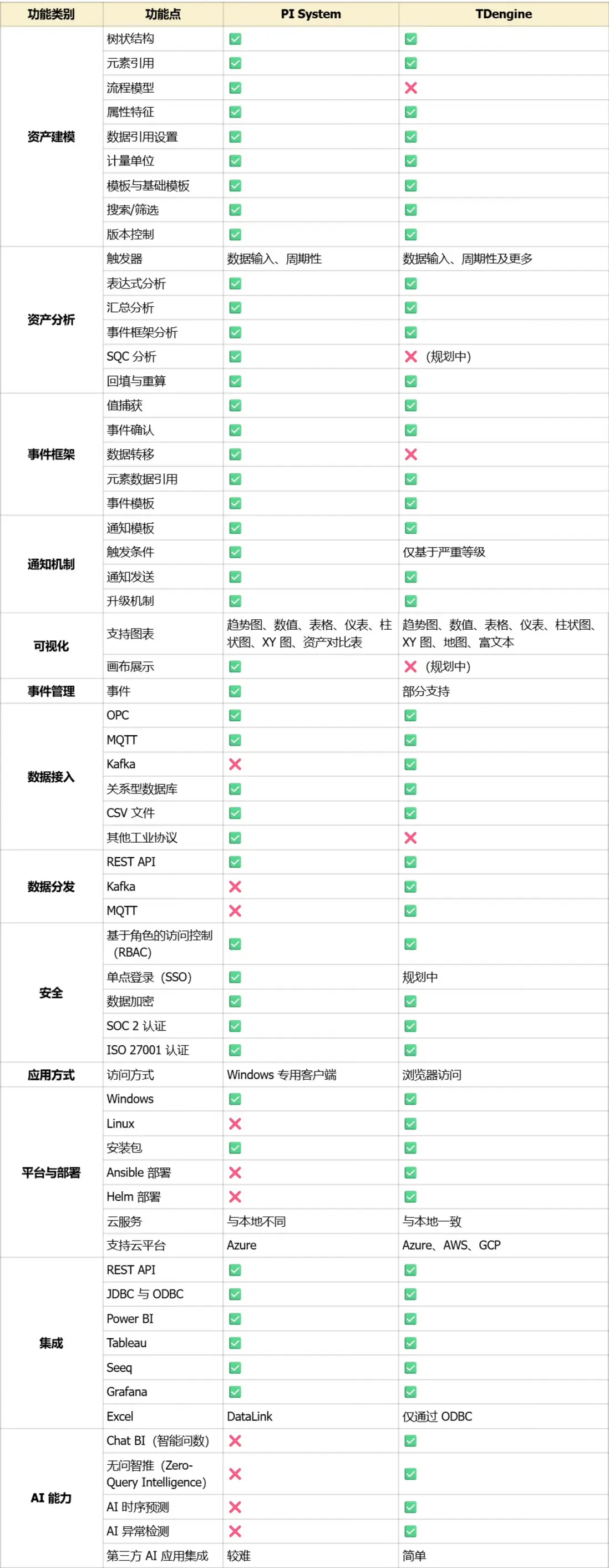
如果你的企業正在糾結工業數據平台選型,或想了解 TDengine 在具體場景(比如新能源、智能製造、油氣開採)的落地案例,歡迎留言/私信我們,我們會第一時間為你解答~






