










在 Python 開發中,處理表格數據是非常常見的任務,而 Pandas 是最常用的數據處理和分析庫。開發者經常需要將 Pandas DataFrame 導出到 Excel,以便進行報告、團隊協作或進一步的數據分析。雖然 Pandas 提供了 to_excel 方法進行基本導出,但如果需要創建格式豐富和含圖表的專業 Excel 報表,則需要藉助專業Excel庫。
本教程介紹如何在Python中使用 Spire.XLS for Python 庫將單個或多個 Pandas DataFrame 寫入到 Excel,並實現靈活的格式化與可視化設置。
Spire.XLS for Python試用下載,請聯繫慧都科技
歡迎加入Spire技術交流Q羣(125237868),與更多小夥伴一起提升文檔開發技能~
為什麼使用 Spire.XLS 導出 Pandas DataFrame 到 Excel
雖然 Pandas 提供了基本的 Excel 導出功能,但它主要用於數據輸出而非 Excel 文件處理,對格式設置、樣式應用和圖表生成等高級功能的支持有限。相比之下,Spire.XLS 是一個專為 Excel 文件創建與操作而設計的專業庫,能夠提供更靈活、更全面的控制。使用 Spire.XLS,開發者可以:
- 將多個 DataFrame 組織到同一個工作簿的不同工作表中。
- 自定義標題、字體、顏色和單元格格式,生成專業佈局。
- 自動調整列寬和行高,提高可讀性。
- 添加圖表、公式和其他 Excel 功能,而無需安裝微軟Excel或其他庫。
pip install pandas spire.xls這些庫允許你將 DataFrame 導出到 Excel,並自定義格式、插入圖表和生成結構化佈局。
將單個 Pandas DataFrame 導出到 Excel 並設置格式
導出單個 DataFrame 到 Excel 是最常見的場景。使用 Spire.XLS,不僅可以導出 DataFrame,還可以格式化標題、設置單元格樣式,並添加圖表,讓你的報表看起來更加專業。
具體實現步驟如下:
步驟 1:創建示例 DataFrame
首先,需要創建一個 DataFrame。以下是一個示例DataFrame,你可以將其替換為自己的數據。
import pandas as pd
from spire.xls import *
# 創建一個示例 DataFrame
df = pd.DataFrame({
'姓名': ['張偉', '李娜', '王強'], # 員工姓名
'部門': ['人事部', '財務部', '技術部'], # 部門
'月薪': [8000, 9500, 12000] # 月薪
})
Pandas DataFrame 導出到 Excel 的準備工作
在導出 Pandas DataFrame 到 Excel 之前,請確保已安裝pandas與Spire.XLS庫:
import pandas as pd
from spire.xls import *
# 創建一個示例 DataFrame
df = pd.DataFrame({
'姓名': ['張偉', '李娜', '王強'], # 員工姓名
'部門': ['人事部', '財務部', '技術部'], # 部門
'月薪': [8000, 9500, 12000] # 月薪
})步驟 2:創建工作簿並訪問第一個工作表
接下來,創建一個新的 Excel 工作簿,並獲取第一個工作表。給工作表命名為 "員工信息",便於理解和管理。
# 創建新工作簿
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "員工信息" # 給工作表命名步驟 3:寫入列標題並格式化
將列標題寫入 Excel 第一行,並加粗字體,同時設置淺灰色背景,使表格整潔、易於閲讀。
# 寫入列標題
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True # 設置標題加粗
cell.Style.Color = Color.get_LightGray() # 設置淺灰色背景步驟 4:寫入數據行
將 DataFrame 中的每一行數據寫入 Excel。對於數字數據,使用 NumberValue 屬性,讓 Excel 能夠識別並用於計算和繪圖;對於文本數據,則使用 Text 屬性。
# 寫入數據行
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value # 數字使用 NumberValue
else:
cell.Text = str(value) # 文本使用 Text步驟 5:應用邊框並自動調整列寬
為數據區域添加外部和內部邊框,並讓列寬自動適應內容長度,使 Excel 表格更加美觀、像專業報表。
# 應用邊框並自動調整列寬
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black()) # 外邊框
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black()) # 內邊框
usedRange.AutoFitColumns() # 自動調整列寬步驟 6:添加圖表以可視化數據
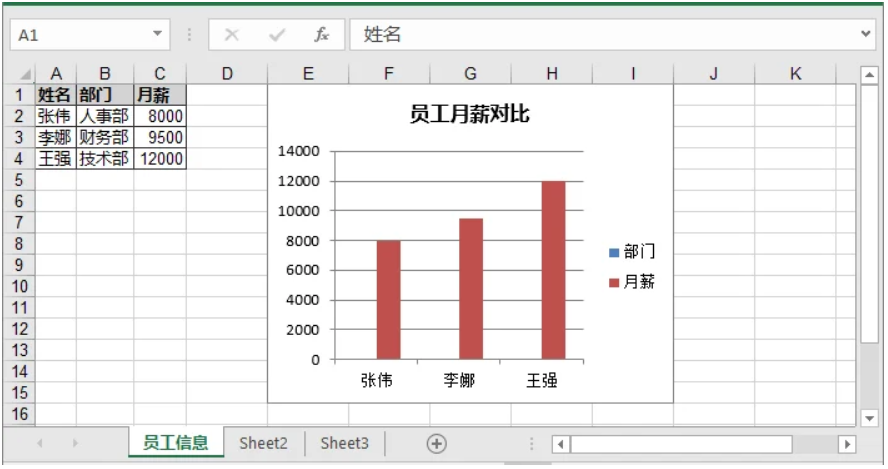
圖表能夠幫助快速理解數據趨勢。在本示例中,我們創建一個柱狀圖,用於比較各員工月薪。
# 添加圖表
chart = sheet.Charts.Add()
chart.ChartType = ExcelChartType.ColumnClustered # 設置柱狀圖
chart.DataRange = sheet.Range["A1:C4"] # 圖表數據範圍
chart.SeriesDataFromRange = False
chart.LeftColumn = 5 # 圖表左側位置
chart.TopRow = 1 # 圖表上方位置
chart.RightColumn = 10 # 圖表右側位置
chart.BottomRow = 16 # 圖表底部位置
chart.ChartTitle = "員工月薪對比" # 圖表標題
chart.ChartTitleArea.Font.Size = 12
chart.ChartTitleArea.Font.IsBold = True步驟 7:保存工作簿
最後,將工作簿保存到指定位置。
# 保存 Excel 文件
workbook.SaveToFile("員工信息報表.xlsx", ExcelVersion.Version2016)
workbook.Dispose()輸出結果:
Excel文件生成後,你可以對其進行進一步處理,例如將其轉換為 PDF,方便分享:
workbook.SaveToFile("員工信息報表.pdf", FileFormat.PDF)將多個 Pandas DataFrame 導出到同一個 Excel 文件
在生成 Excel 報表時,經常需要將多個數據集放在不同的工作表中。使用 Spire.XLS,每個 DataFrame 可以寫入獨立工作表,使相關數據清晰有序,便於分析。
具體實現步驟如下:
步驟 1:創建多個示例 DataFrame
在導出前,創建兩個 DataFrame:一個包含員工信息,另一個包含產品信息。每個 DataFrame 對應一個工作表。
import pandas as pd
from spire.xls import *
# 示例 DataFrame
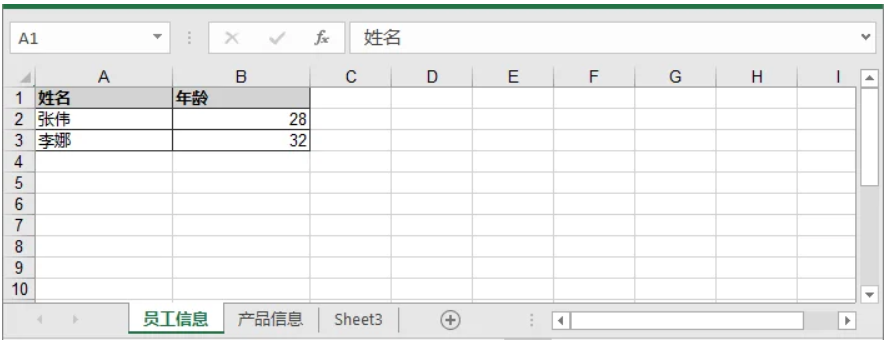
df1 = pd.DataFrame({'姓名': ['張偉', '李娜'], '年齡': [28, 32]})
df2 = pd.DataFrame({'產品': ['筆記本電腦', '手機'], '價格': [7500, 3200]})
# 將 DataFrame 與對應工作表名綁定
dataframes = [
(df1, "員工信息"),
(df2, "產品信息")
]這裏 dataframes 是一個元組列表,將每個 DataFrame 與其對應的工作表名稱關聯起來。
步驟 2:創建新工作簿
創建一個新的工作簿,用於存放DataFrame數據。新工作簿默認包含三個工作表。
# 創建新工作簿
workbook = Workbook()步驟 3:循環寫入每個 DataFrame到單獨的Excel表格
使用循環遍歷列表中的 DataFrame,將每個數據集寫入單獨的工作表。同時為數據區域添加邊框。
for i, (df, sheet_name) in enumerate(dataframes):
if i < workbook.Worksheets.Count:
sheet = workbook.Worksheets[i]
else:
sheet = workbook.Worksheets.Add()
sheet.Name = sheet_name
# 寫入標題並設置字體加粗和背景顏色
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
sheet.Columns[colIndex - 1].ColumnWidth = 15
# 寫入數據行
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# 添加邊框
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black())
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black())步驟 4:保存工作簿
將Excel文件保存到指定位置。
workbook.SaveToFile("員工與產品信息.xlsx", ExcelVersion.Version2016)
workbook.Dispose()生成結果:
將 Pandas DataFrame 寫入現有 Excel 文件
在實際工作中,有時並不希望新建 Excel 文件,而是需要將新的數據寫入已有的工作簿。使用 Spire.XLS,可以輕鬆實現這一需求:只需加載現有工作簿,添加新的工作表或訪問目標工作表,然後按照與新建工作簿相同的邏輯寫入 DataFrame 數據。
以下代碼展示瞭如何將一個Pandas DataFrame寫入到現有Excel表格:
import pandas as pd
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("員工與產品信息.xlsx")
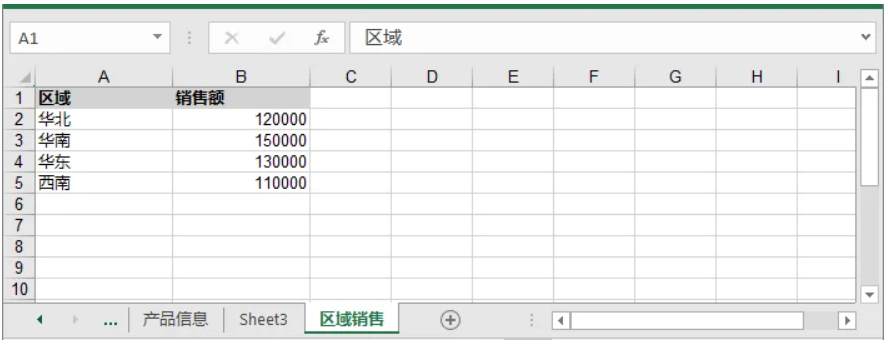
new_df = pd.DataFrame({
'區域': ['華北', '華南', '華東', '西南'],
'銷售額': [120000, 150000, 130000, 110000]
})
new_sheet = workbook.Worksheets.Add("區域銷售")
# 寫入標題
for colIndex, colName in enumerate(new_df.columns, start=1):
cell = new_sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
new_sheet.Columns[colIndex - 1].ColumnWidth = 15
# 寫入數據
for rowIndex, row in enumerate(new_df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = new_sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# 保存
workbook.SaveToFile("員工產品區域信息.xlsx", ExcelVersion.Version2016)
workbook.Dispose()生成結果:
導出 Pandas DataFrame 到 Excel的自定義選項
除了基礎導出外,還可以對導出過程進行自定義,以滿足特定報表需求。例如,可以選擇導出特定列,或者決定是否包含DataFrame索引,從而讓 Excel 文件更加整潔、易讀。
1. 選擇特定列
在實際場景中,很多時候並不需要導出 DataFrame 中的所有列。通過只導出需要的列,可以讓 Excel 報表內容更加簡潔,同時避免無關信息干擾閲讀。
下面示例演示如何只導出姓名和部門兩列:
import pandas as pd
from spire.xls import *
# 創建示例 DataFrame
df = pd.DataFrame({
'姓名': ['張偉', '李娜', '王強'],
'部門': ['人事部', '財務部', '技術部'],
'月薪': [8000, 9500, 12000]
})
# 指定需要導出的列
columns_to_export = ['姓名', '部門']
# 創建新的工作簿並獲取第一個工作表
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 寫入標題行
for colIndex, colName in enumerate(columns_to_export, start=1):
sheet.Range[1, colIndex].Text = colName
# 寫入數據行
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=1):
sheet.Range[rowIndex, colIndex].Text = value
# 保存 Excel 文件
workbook.SaveToFile("選擇列.xlsx")
workbook.Dispose()2. 包含或排除DataFrame索引
默認情況下,DataFrame 的索引不會導出到 Excel。但在一些報表中,行號或索引對數據分析非常重要。此時,可以手動將索引寫入工作表,使每一行都有明確標識。
下面示例展示如何在導出特定列的同時包含索引:
# 寫入索引標題
sheet.Range[1, 1].Text = "索引"
# 寫入索引數值(數字)
for rowIndex, idx in enumerate(df.index, start=2):
sheet.Range[rowIndex, 1].NumberValue = idx
# 寫入其他列標題,從第二列開始
for colIndex, colName in enumerate(columns_to_export, start=2):
sheet.Range[1, colIndex].Text = colName
# 寫入數據行
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=2):
if isinstance(value, (int, float)):
sheet.Range[rowIndex, colIndex].NumberValue = value
else:
sheet.Range[rowIndex, colIndex].Text = str(value)
# 保存 Excel 文件
workbook.SaveToFile("包含索引.xlsx", ExcelVersion.Version2016)
workbook.Dispose()總結
本文介紹了在 Python 中使用 Spire.XLS 將 Pandas DataFrame 導出到 Excel 的多種方法。通過示例可以看到,除了基礎的數據導出外,還可以實現標題樣式設置、數據格式化、向現有工作簿寫入數據,以及選擇特定列或包含索引等操作。這些方法讓數據分析和報表生成過程更加靈活,使開發者能夠更好地控制導出內容和展示效果,以適應不同的應用場景和業務需求。
Spire.XLS for Python試用下載,請聯繫慧都科技
歡迎加入Spire技術交流Q羣(125237868),與更多小夥伴一起提升文檔開發技能~
常見問題解答(FAQs)
問:如何在 Python 中將 Pandas DataFrame 導出到 Excel?
答: 可以使用 Spire.XLS 或類似庫將 DataFrame 寫入 Excel 文件。這樣不僅可以導出數據,還可以自定義表頭樣式、單元格格式以及添加圖表等,使報表更專業。
問:是否可以在同一個 Excel 文件中導出多個 DataFrame?
答: 可以。通過 Spire.XLS,可以將多個 DataFrame 寫入同一個工作簿的不同工作表中,從而將相關數據整合在一個文件裏,便於管理和分析。
問:如何在導出的 Excel 中設置標題和單元格樣式?
答: 可以將表頭字體加粗、設置背景顏色,調整列寬和行高,數字使用 NumberValue 屬性保存,以便 Excel 識別和計算。這些設置能讓 Excel 報表看起來更規範、易讀。
問:能在導出的 Excel 文件中添加圖表嗎?
答: 可以。Spire.XLS 支持柱狀圖、折線圖等多種圖表類型,圖表可以直接綁定 DataFrame 的數據,幫助快速展示數據趨勢或對比分析。
問:導出 Excel 文件是否必須安裝 Microsoft Excel?
答: 不需要。Spire.XLS 可以在 Python 中獨立創建和格式化 Excel 文件,無需依賴 Excel 軟件本身。
問:可以選擇導出 DataFrame 的部分列或包含索引嗎?
答: 可以。導出時可以指定需要的列,也可以選擇是否包含索引,從而生成更簡潔、針對性更強的報表。












