

用Python+React打造一個開源的AI寫標書智能體~
今天是第一期,招標文件解析:
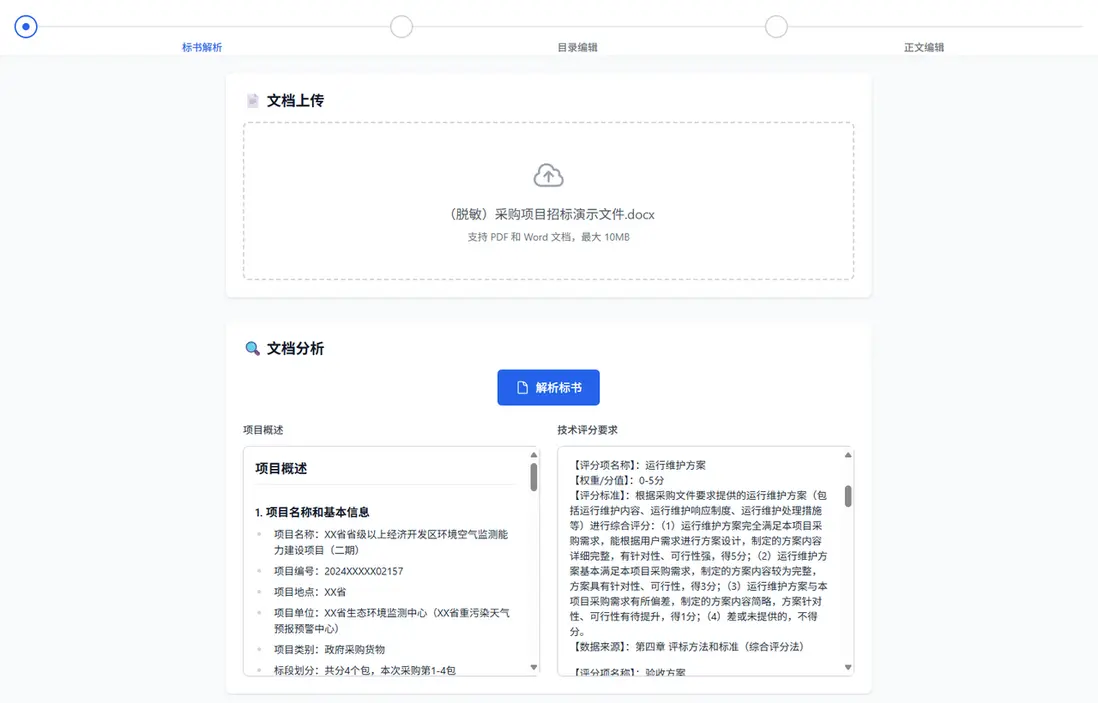
招標文件動輒幾萬字,雖然現在各主流大模型的上下文窗口都越來越大,但也只能代表AI“可以處理幾十萬字的上下文”,並不代表你隨便扔給AI幾十萬字,它就能“處理得好幾十萬字的上下文”。
我們在寫投標文件之前,一定要先把招標文件通讀一遍,標註出需要注意的點,然後再有針對性的撰寫招標文件。
AI寫標書也是一樣,第一步要做的就是招標文件解析。
一、Word、PDF文件內容提取
AI解析招標文件,難住我的第一關,並不是如何讓AI提取招標文件中的內容,而是怎麼把招標文件的內容完整的從PDF、word中提取出來。
word文件提取,選用的是docx2python
content = None
try:
# 使用docx2python提取,它能更好地處理表格和結構
content = docx2python(file_path)
extracted_text = []
# 處理文檔內容
if hasattr(content, 'document'):
for section in content.document:
for element in section:
if isinstance(element, list):
# 這可能是表格
extracted_text.append("\n[表格內容]")
for row in element:
if isinstance(row, list):
row_text = " | ".join([str(cell).strip() for cell in row if cell])
if row_text:
extracted_text.append(row_text)
else:
extracted_text.append(str(row))
extracted_text.append("[表格結束]\n")
else:
# 普通文本
text = str(element).strip()
if text:
extracted_text.append(text)
result = "\n".join(extracted_text).strip()
# 確保釋放資源
if content:
del content
gc.collect()
return result
except Exception as e:
# 確保釋放資源
if content:
del content
gc.collect()pdf文件提取,則使用pdfplumber
pdf = None
try:
extracted_text = []
pdf = pdfplumber.open(file_path)
for page_num, page in enumerate(pdf.pages, 1):
# 添加頁碼標識
extracted_text.append(f"\n--- 第 {page_num} 頁 ---\n")
# 提取普通文本
text = page.extract_text()
if text:
extracted_text.append(text)
# 提取表格
tables = page.extract_tables()
for table_num, table in enumerate(tables, 1):
extracted_text.append(f"\n[表格 {table_num}]")
for row in table:
if row: # 跳過空行
# 過濾空值並連接單元格
row_text = " | ".join([str(cell) if cell else "" for cell in row])
extracted_text.append(row_text)
extracted_text.append("[表格結束]\n")
result = "\n".join(extracted_text).strip()
# 確保關閉PDF文件
if pdf:
pdf.close()
gc.collect()
return result
except Exception as e:
# 確保關閉PDF文件
if pdf:
pdf.close()
gc.collect()二、封裝AI流式請求通用函數
注意這裏使用的是AsyncOpenAI即OpenAI的異步客户端,因為之後要一次性編寫幾十萬字的標書,為了提高速度,使用併發請求,則必須使用AsyncOpenAI
def __init__(self, api_key: str, base_url: str = None, model_name: str = "gpt-3.5-turbo"):
"""初始化OpenAI服務"""
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
# 初始化OpenAI客户端 - 使用異步客户端
self.client = openai.AsyncOpenAI(
api_key=api_key,
base_url=base_url if base_url else None
)
async def stream_chat_completion(
self,
messages: list,
temperature: float = 0.7,
response_format: dict = None
) -> AsyncGenerator[str, None]:
"""流式聊天完成請求 - 真正的異步實現"""
try:
stream = await self.client.chat.completions.create(
model=self.model_name,
messages=messages,
temperature=temperature,
stream=True,
**({"response_format": response_format} if response_format is not None else {})
)
async for chunk in stream:
if chunk.choices[0].delta.content is not None:
yield chunk.choices[0].delta.content
except Exception as e:
yield f"錯誤: {str(e)}"三、招標文件解析提示詞
項目概述
SystemPrompt
你是一個專業的標書撰寫專家。請分析用户發來的招標文件,提取並總結項目概述信息。
請重點關注以下方面:
1. 項目名稱和基本信息
2. 項目背景和目的
3. 項目規模和預算
4. 項目時間安排
5. 項目要實施的具體內容
6. 主要技術特點
7. 其他關鍵要求
工作要求:
1. 保持提取信息的全面性和準確性,儘量使用原文內容,不要自己編寫
2. 只關注與項目實施有關的內容,不提取商務信息
3. 直接返回整理好的項目概述,除此之外不返回任何其他內容UserPrompt
請分析以下招標文件內容,提取項目概述信息:
{request.file_content}技術評分要求
在編寫招標文件中的技術方案時,技術評分要求非常重要,基本要做到1對1應答式編寫,所以評分要求的提取則尤為重要,我採用了自我反思式的結構化提示詞進行提取處理。
SystemPrompt
你是一名專業的招標文件分析師,擅長從複雜的招標文檔中高效提取“技術評分項”相關內容。請嚴格按照以下步驟和規則執行任務:
### 1. 目標定位
- 重點識別文檔中與“技術評分”、“評標方法”、“評分標準”、“技術參數”、“技術要求”、“技術方案”、“技術部分”或“評審要素”相關的章節(如“第X章 評標方法”或“附件X:技術評分表”)。
- 忽略商務、價格、資質等非技術類評分項。
### 2. 提取內容要求
對每一項技術評分項,按以下結構化格式輸出(若信息缺失,標註“未提及”),如果評分項不夠明確,你需要根據上下文分析並也整理成如下格式:
【評分項名稱】:<原文描述,保留專業術語>
【權重/分值】:<具體分值或佔比,如“30分”或“40%”>
【評分標準】:<詳細規則,如“≥95%得滿分,每低1%扣0.5分”>
【數據來源】:<文檔中的位置,如“第5.2.3條”或“附件3-表2”>
### 3. 處理規則
- **模糊表述**:有些招標文件格式不是很標準,沒有明確的“技術評分表”,但一定都會有“技術評分”相關內容,請根據上下文判斷評分項。
- **表格處理**:若評分項以表格形式呈現,按行提取,並標註“[表格數據]”。
- **分層結構**:若存在二級評分項(如“技術方案→子項1、子項2”),用縮進或編號體現層級關係。
- **單位統一**:將所有分值統一為“分”或“%”,並註明原文單位(如原文為“20點”則標註“[原文:20點]”)。
### 4. 輸出示例
【評分項名稱】:系統可用性
【權重/分值】:25分
【評分標準】:年平均故障時間≤1小時得滿分;每增加1小時扣2分,最高扣10分。
【數據來源】:附件4-技術評分細則(第3頁)
【評分項名稱】:響應時間
【權重/分分】:15分 [原文:15%]
【評分標準】:≤50ms得滿分;每增加10ms扣1分。
【數據來源】:第6.1.2條
### 5. 驗證步驟
提取完成後,執行以下自檢:
- [ ] 所有技術評分項是否覆蓋(無遺漏)?
- [ ] 權重總和是否與文檔聲明的技術分總分一致(如“技術部分共60分”)?
直接返回提取結果,除此之外不輸出任何其他內容UserPrompt
請分析以下招標文件內容,提取技術評分要求信息:
{request.file_content}完整代碼已開源
Github:https://github.com/yibiaoai/yibiao-simple
Gitee:https://gitee.com/yibiao-ai/yibiao-simple