









作者 | 陳飛 中付支付大數據工程師
今天和大家分享一個 簡單但常見的 MySQL 到 MySQL 數據同步與合併場景案例,這個案例也是我在實際工作中遇到的問題,希望能拋磚引玉,歡迎有更豐富經驗的大佬一起分享交流。
- 版本要求:Apache SeaTunnel --> Apache SeaTunnel-2.3.9
場景描述

在我們的業務系統中,存在兩個 MySQL 源庫:
- source_a
- source_b
這兩個庫中存在一張表結構相同的表,但數據來自不同的業務線,兩邊都會同時產生數據,因此存在 主鍵重複 的問題。
我們的目標是將這兩個源庫的表數據 合併同步到一個目標庫(我們稱為 C 庫),以便於統一分析和查詢。
面臨的挑戰
- 兩個源庫的表結構雖然一致,但主鍵重複,需要避免衝突
- 後續可能存在字段不一致或字段新增的需求
- 同步過程需儘量實時,且不能產生重複數據
解決方案
我們採用瞭如下方式來實現這個同步與合併的方案:

在 C 庫新建目標表:
- 表結構需要覆蓋兩個源表的所有字段(當前一致,未來可能擴展)
- 增加一個額外的字段:data_source,用於標識數據來源(source_a 或 source_b)
- 不可為空的字段需要有默認值
設置聯合主鍵與唯一約束
- 使用 原主鍵 + data_source 作為聯合主鍵,確保不會因為兩個源的主鍵重複而導致衝突
使用兩個 Seatunnel 進程進行數據同步**:
- 分別使用 MySQL CDC 連接器 監聽 source_a 與 source_b
- 在每條數據中打上來源標識字段 data_source
- 使用 JDBC Sink 寫入到 C 庫
實戰演示
下面我們直接進入實戰環節,關於 SeaTunnel 的基礎知識,這裏就不再贅述,上一期的大佬已經講得非常清楚了,我們直接進入正題。
使用 MySQL CDC 前的準備工作
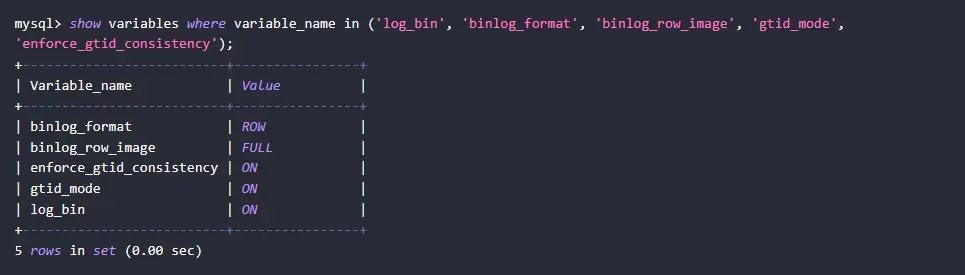
要使用 mysql-cdc 連接器,有兩個必要的前置條件:
-
MySQL 源庫需開啓 Binlog 日誌
- binlog_format 必須設置為 ROW
- binlog_row_image 設置為 FULL-- 檢查當前配置
SHOWVARIABLESLIKE'binlog_format';
SHOWVARIABLESLIKE'binlog_row_image';
-- 如果未開啓,可在 my.cnf 文件中添加以下配置:
[mysqld]
server-id = 1
log-bin = mysql-bin
binlog-format = ROW
binlog-row-image = FULL以上權限説明及設置方式可以參考官網文檔,文檔中提供了詳細的權限説明與示例,建議大家同步查閲。
- 準備擁有複製權限的賬號
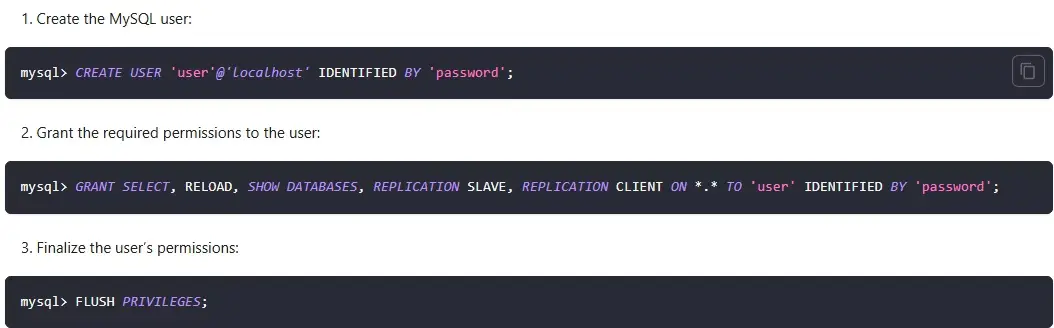
-- 創建同步賬號
CREATE USER 'cdc_user'@'%' IDENTIFIED BY 'your_password';
-- 授予必要權限
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cdc_user'@'%';
FLUSH PRIVILEGES;準備 SeaTunnel 運行包與插件
- 方式一:下載官方二進制包
適合 服務器可訪問外網 且 無需複雜定製 的場景。
- 下載地址:官方 Releases 頁面
- 需要手動添加插件及插件驅動(如 mysql-cdc, jdbc)
- 插件安裝説明可參考官方文檔:插件管理
wget "https://archive.apache.org/dist/seatunnel/${version}/apache-seatunnel-${version}-bin.tar.gz"
config/plugin_config保留需要的插件
bin/install-plugin.sh- 方式二:從 GitHub 克隆源碼自行編譯
適合對插件有特殊需求或希望獲得完整插件支持的用户。
sh ./mvnw clean install -DskipTests -Dskip.spotless=true
seatunnel-dist/target/apache-seatunnel-2.3.9-bin.tar.gz自行編譯後生成的包中默認已集成所有插件及對應依賴,無需額外操作。
本案例使用的插件:
- mysql-cdc
- jdbc
插件説明與驅動依賴也可參考對應的文檔!
Apache SeaTunnel 部署方式簡介
SeaTunnel 支持多種部署方式:
- 使用 Seatunnel 自帶引擎(Zeta)
- 作為 Spark / Flink 作業運行
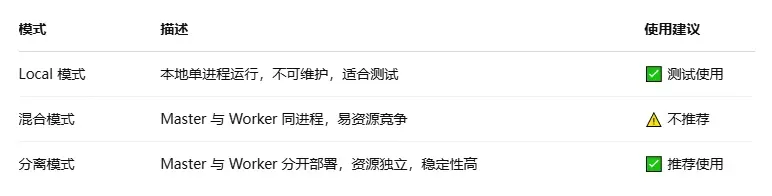
使用 Zeta 引擎時的三種模式:
配置文件結構説明
集羣搭建完成後,我們開始準備配置文件。
一般情況下,SeaTunnel 的配置文件可以分為以下四個部分:
- Env:引擎相關配置
- Source:源數據讀取配置
- Transform:數據轉換信息(可選)
- Sink:寫出目標庫的配置
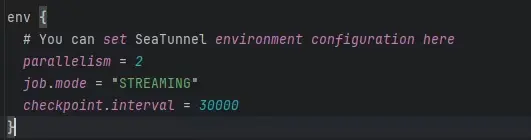
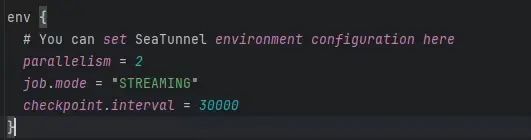
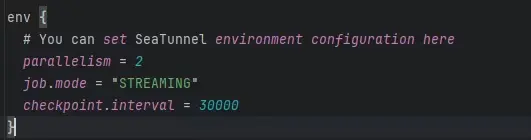
Env引擎配置
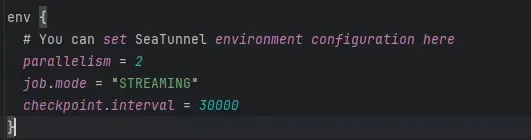
- parallelism:並行度,表示任務運行的併發度,數值越大越快,具體要結合資源情況設置。
- job.mode:作業運行模式。由於我們使用的是 mysql-cdc 插件,因此必須設置為 Streaming 模式。
- checkpoint.interval:檢查點間隔,Streaming 模式下默認是 30 秒一次,可以根據需要調整。
Source數據源配置(MySQL CDC)
使用的插件是 mysql-cdc,需要配置以下內容:
- 連接信息:包括數據庫地址、用户名、密碼等。
- 庫名與表名:可以通過 database-names 和 table-names 顯式指定,也可以使用正則表達式模糊匹配。
- startup.mode:CDC 的啓動模式,默認為“先全量後增量”,適合大多數同步場景。如需瞭解其他啓動模式的區別,可以參考官方文檔。
- server-id:MySQL 的 CDC 讀取服務 ID,雖然可以不寫,但建議明確指定,防止與已有的從庫 ID 衝突。
-
MySQL 配置建議:在使用 mysql-cdc 前,需要確保
- binlog 功能已開啓;
- binlog-format 設置為 ROW;
- binlog-row-image 設置為 FULL;
- MySQL 賬號需具備讀取 binlog、主從複製、查詢所有表等權限。
Transform數據轉換配置(可選)
在本案例中,我們需要給每條數據添加一個字段,用於標識數據來源,例如:data_source 字段,值可以是 source_a 或 source_b。
這個轉換過程使用 sql 插件實現,通過添加常量字段的方式,將數據來源信息加到每條數據中。
需要注意:
- 每個源表可以單獨指定轉換規則;
- source_table 是保留字,表示上一個處理環節中的表名。
Sink寫入配置
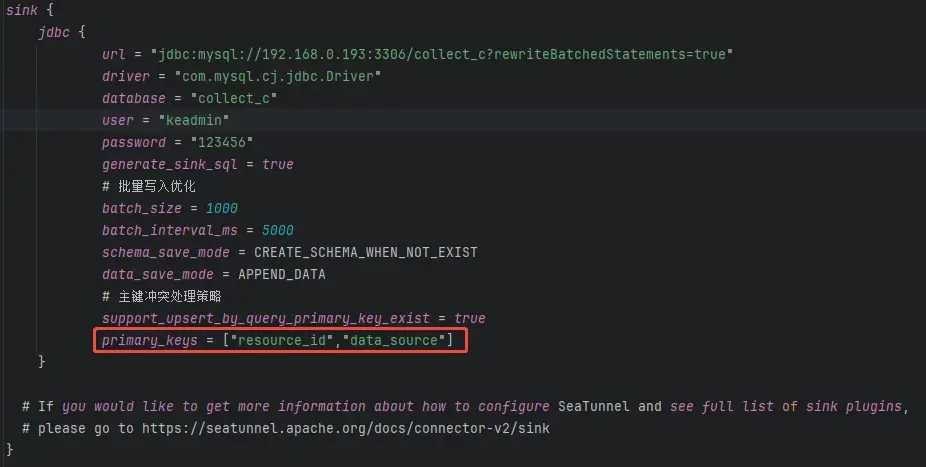
Sink 使用的是 jdbc 插件,配置項主要包括:
- 目標庫地址、驅動、用户名、密碼等連接信息;
- 根據目標表結構生成寫入 SQL;
- 如果字段或結構不一致,可以自定義寫入語句以匹配表結構。
小結
以上配置組合完成後,我們就可以實現從多個源庫(如 source_a 和 source_b)實時同步數據到目標庫的需求。在同步的同時,我們還增強了字段,使數據能夠被標識來源並統一寫入。整個流程既支持複雜數據結構,又能靈活適配業務場景,是一個適合實際生產的數據集成案例。
Sink 寫入優化與效果驗證
在配置 Sink 時,我們還可以做一些寫入性能方面的優化:
批量寫入策略
- 批量大小 和 寫入間隔:滿足任意一個條件就會觸發寫入操作。
關鍵配置參數説明
-
schema_save_mode:結構保存策略如果結構已存在則忽略;
- 如果不存在,則根據上一個環節的輸出結構自動創建。
-
data_save_mode:數據保存策略
- 這裏我們選擇的是 追加(append) 模式。
-
support_upsert_by_query_primary_key_exist:是否支持根據主鍵做 Upsert
- 本次開啓了該功能,用於支持主鍵衝突時的更新。
-
primary_keys:指定寫入數據的主鍵
- 這裏必須指定,包括原表的主鍵和我們 transform 階段新增的 data_source 字段。
提交任務
./seatunnel.sh --config ../config/demo/collect_a.config -e cluster --cluster sz-seatunnel --name collect_a --async
./seatunnel.sh --config ../config/demo/collect_b.config -e cluster --cluster sz-seatunnel --name collect_b --async
--config:指定配置文件
-e:運行模式 cluster/local
--cluster:集羣名稱,部署集羣時配置,默認是seatunnel
--name:任務名稱
--async:後台運行實際運行效果驗證
到這裏,配置部分就全部完成了。接下來我們來看下實際運行的效果:
- 當前有 a 表和 b 表,c 表為空。
- 先運行 a 的同步進程。
- 查看 c 表,已經寫入了 a 表的數據,且 data_source 字段為 source_a。
- 接着運行 b 的同步進程。
- 再查看 c 表,寫入了 b 表的數據,data_source 字段為 source_b。
- 修改一下 a 表的數據。
- 因為我們設置了批量寫入策略,這裏等個兩秒,再去看 c 表。
- 對應的數據已更新,符合預期。
到這裏整個數據同步和合並的流程就全部完成啦!非常感謝大家的聆聽 🙏,希望這個案例能為大家提供一些思路,也歡迎大家分享自己在 Apache SeaTunnel 使用中的更多經驗,我們一起交流學習!












