

公共資源速遞
5 個公共數據集:
Netflix 電影電視目錄數據集
- CytoData 血液細胞圖像數據集
- VERA 語音推理能力評測數據集
- UNO-Bench 全模態評測基準數據集
- EditReward-Bench 圖像編輯評測數據集
3 個公共教程:
- PixelReasoner-RL:像素級視覺推理模型
- VibeThinker-1.5B:小模型也可以有大智慧
- Depth-Anything-3:從任何視角恢復視覺空間
訪問官網立即使用:http://openbayes.com
公共數據集
1. Netflix 電影電視目錄數據集
Netflix 影片與劇集目錄數據集是一個涵蓋多國家、多類型影視內容的結構化目錄數據集,包含標題、類型、製作信息、時長、分級與劇情簡介等基礎字段。數據覆蓋多個國家與類型,條目數量可觀,內容分佈廣泛,可完整呈現平台的影視內容構成情況。
在線使用:
https://go.openbayes.com/0SUYR
2. CytoData 血液細胞圖像數據集
該數據集是一個面向細胞形態分析的大規模血液細胞醫學影像數據集,由 2,904 張血液塗片組成,包含共計 559,808 張單細胞圖像,其中 4,996 張樣本附帶十類血液細胞的專家分類與置信度標註。圖像由標準化臨牀系統採集,並額外設置偽影類別,用於呈現血液塗片中的常見非細胞結構。數據量大、類別清晰,能夠全面反映血細胞形態特徵。
在線使用:
https://go.openbayes.com/ktyz1
3. VERA 語音推理能力評測數據集
VERA 是一個面向語音原生推理能力評測的多任務語音數據集,包含 2,931 條語音原生推理樣本,覆蓋數學、網頁檢索、科學問題、長文本理解與事實性問答五類任務所有樣本以語音形式原生呈現,幷包含對話輪次、上下文文檔及參考答案等結構化信息。該數據集可直接用於語音模態推理研究、跨模態性能差異分析與語音智能系統能力評估。
在線使用:
https://go.openbayes.com/aag1x
4. UNO-Bench 全模態評測基準數據集
UNO-Bench 是一個統一的全模態理解與推理評測基準,面向單模態與全模態任務構建,由 1,250 條全模態樣本與 2,480 條單模態樣本構成,共覆蓋 44 類任務類型與 5 種模態組合。數據採用結構化存儲方式,包含 qid、文本內容、多模態資源路徑、任務標籤與評分字段等信息,樣本構成豐富,具備較高的跨模態可解性。
在線使用:
https://go.openbayes.com/uY74R

數據集示例
5. EditReward-Bench 圖像編輯評測數據集
EditReward-Bench 是一個面向圖像編輯獎勵模型的系統化評測基準,包含 3,072 條經專家標註的偏好對比樣本,覆蓋 4 大類、13 種圖像編輯任務。數據集中候選結果由 11 種異構圖像編輯模型生成,分佈具備多樣性與代表性,能夠全面呈現不同編輯場景與編輯類型下的圖像變化特徵。
在線使用:
https://go.openbayes.com/23Isj
公共教程
1. PixelReasoner-RL:像素級視覺推理模型
PixelReasoner-RL-v1 是 TIGER AI Lab 發佈的新一代像素級視覺語言模型,其核心以好奇心驅動強化學習為基礎,使模型能夠在像素空間中主動執行縮放、抽幀與局部聚焦等視覺操作,從而突破傳統 VLM 僅依賴文本推理的限制。藉助這種可操作式視覺推理框架,PixelReasoner 能精準捕捉圖像細節和空間關係,在處理微小目標、複雜場景與視頻內容時展現出顯著優勢。作為聚焦深度視覺理解的先進系統,它為圖像分析、視頻理解與多模態任務提供了更靈活、更細膩的智能支持。
在線運行:
https://go.openbayes.com/UKuhN
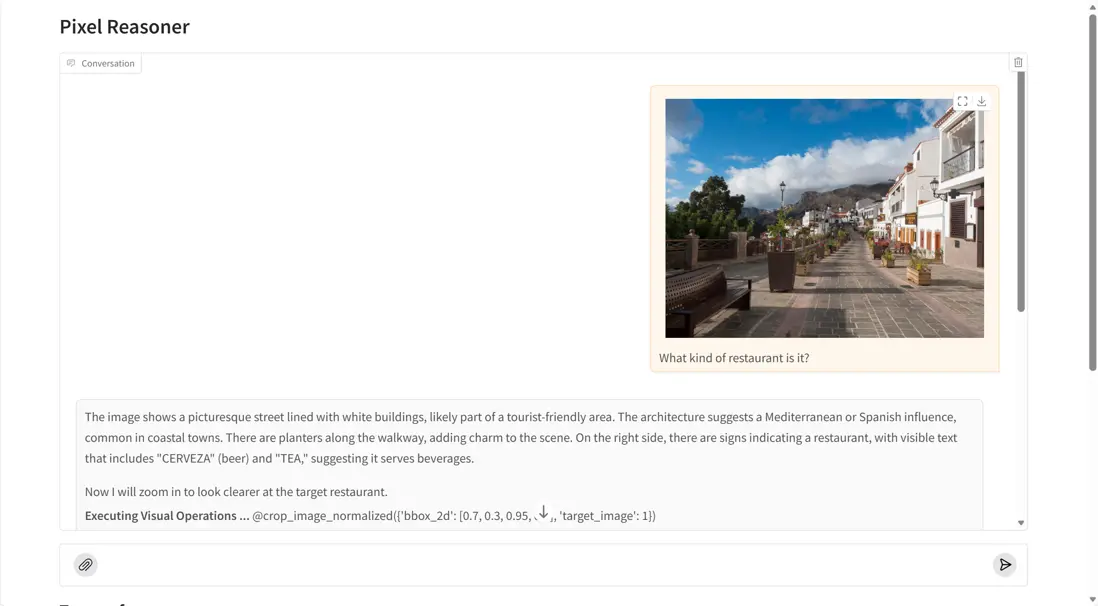
項目示例
2. VibeThinker-1.5B:小模型也可以有大智慧
VibeThinker-1.5B 是微博 AI 推出的輕量級通用大模型,其關鍵創新來自 SSP 訓練理念,通過在初始階段鼓勵模型探索多樣化推理路徑,並在後續階段以強化學習精確收斂最優策略,使其在僅 15 億參數規模下實現接近大模型的邏輯推理能力。憑藉這種“發散—收斂”式訓練機制,VibeThinker-1.5B 能構建穩定且深入的推理鏈路,為移動端應用、輕量部署與高性價比場景提供強大的智能支持。
在線運行:
https://go.openbayes.com/Jc7hC

項目示例
3. Depth-Anything-3:從任何視角恢復視覺空間
Depth-Anything-3(DA3)是 ByteDance-Seed 團隊推出的新一代視覺幾何模型,以單一 Transformer 結合深度射線表示重構三維理解流程,能夠在任意視角輸入下恢復空間一致的幾何結構,無需依賴複雜的多任務訓練設計。模型同時支持單目深度、多視圖融合、相機姿態估計與 3D 高斯生成等核心任務,並在 HiRoom、ETH3D 等基準上取得領先表現。憑藉架構極簡、任務統一、跨場景魯棒性強等優勢,DA3 能高效適配多種下游 3D 流程,成為三維重建、虛擬內容生成與空間計算中的專業級幾何理解引擎。
在線運行:
https://go.openbayes.com/TVdUR
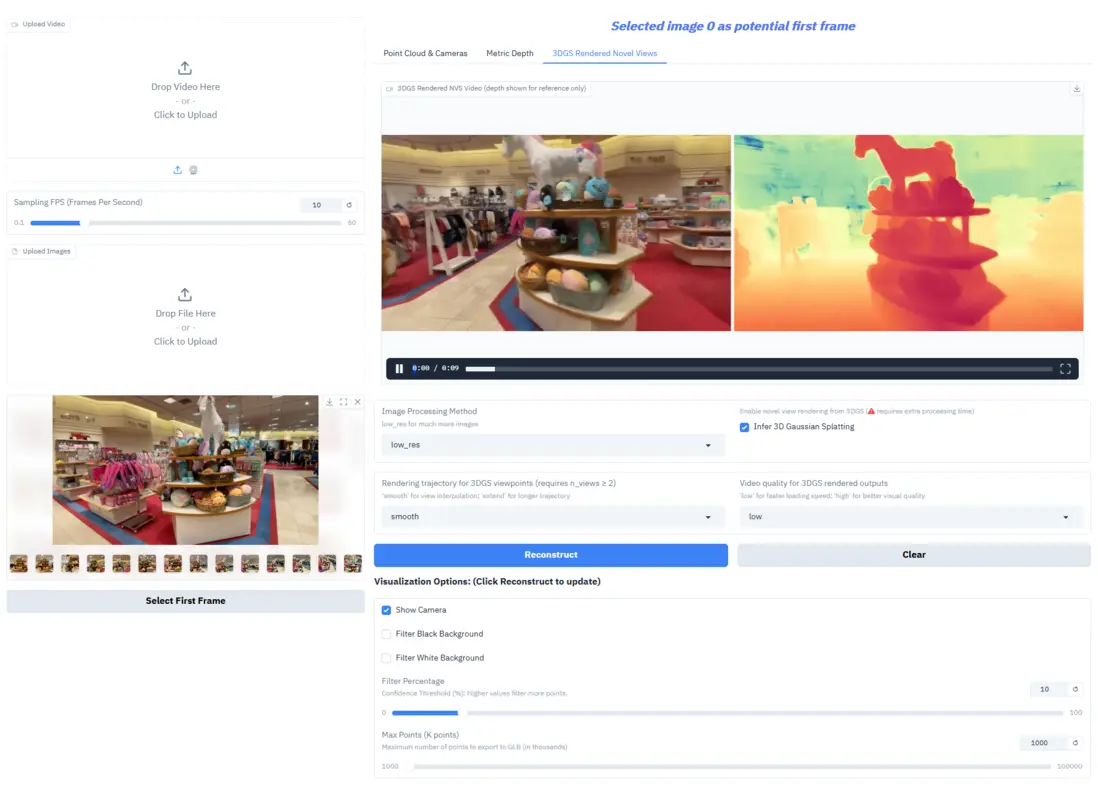
項目示例