








引言:從Gin的Context池化,揭開sync.Pool的神秘面紗
在編寫高性能的Go Web服務時,我們總是追求極致的效率。但在高併發場景下,頻繁的對象創建和銷燬是隱藏在背後的性能殺手。
在《Gin 框架核心架構解析》中,我們提到Gin會為每個HTTP請求分配一個Context對象。當你的服務每秒處理數千甚至上萬個請求時,這意味着海量的Context對象被創建,給Go的垃圾回收(GC)機制帶來了巨大壓力,從而可能導致服務響應出現短暫卡頓。
為了解決這個問題,Gin引入了對象池(Object Pool)的概念,而實現這一功能的核心武器,正是Go標準庫中的sync.Pool。
sync.Pool就像一個可以借用和歸還對象的“銀行”,它將不再使用的對象暫時存放起來,避免了頻繁的內存分配和GC開銷,顯著提升了服務的吞吐量。
那麼,sync.Pool是如何做到的?
它的內部結構是怎樣的?
在GC時又會發生什麼?
本文將帶你深入sync.Pool的源碼,徹底理解其背後的設計哲學與實現細節。
多級緩存的啓示:sync.Pool的設計哲學
要理解sync.Pool的巧妙設計,我們不妨從一個更底層的概念——CPU緩存——説起。現代計算機的CPU並非直接與主內存交互,而是通過多級緩存(L1、L2、L3)來加速數據存取。
這個多級緩存系統遵循一個核心原則:距離CPU越近的緩存,讀寫速度越快,容量越小;反之,距離越遠,速度越慢,容量越大。
當CPU需要一個數據時,它會首先從速度最快的L1緩存中查找,如果未命中,則依次向L2、L3和主內存發起請求。
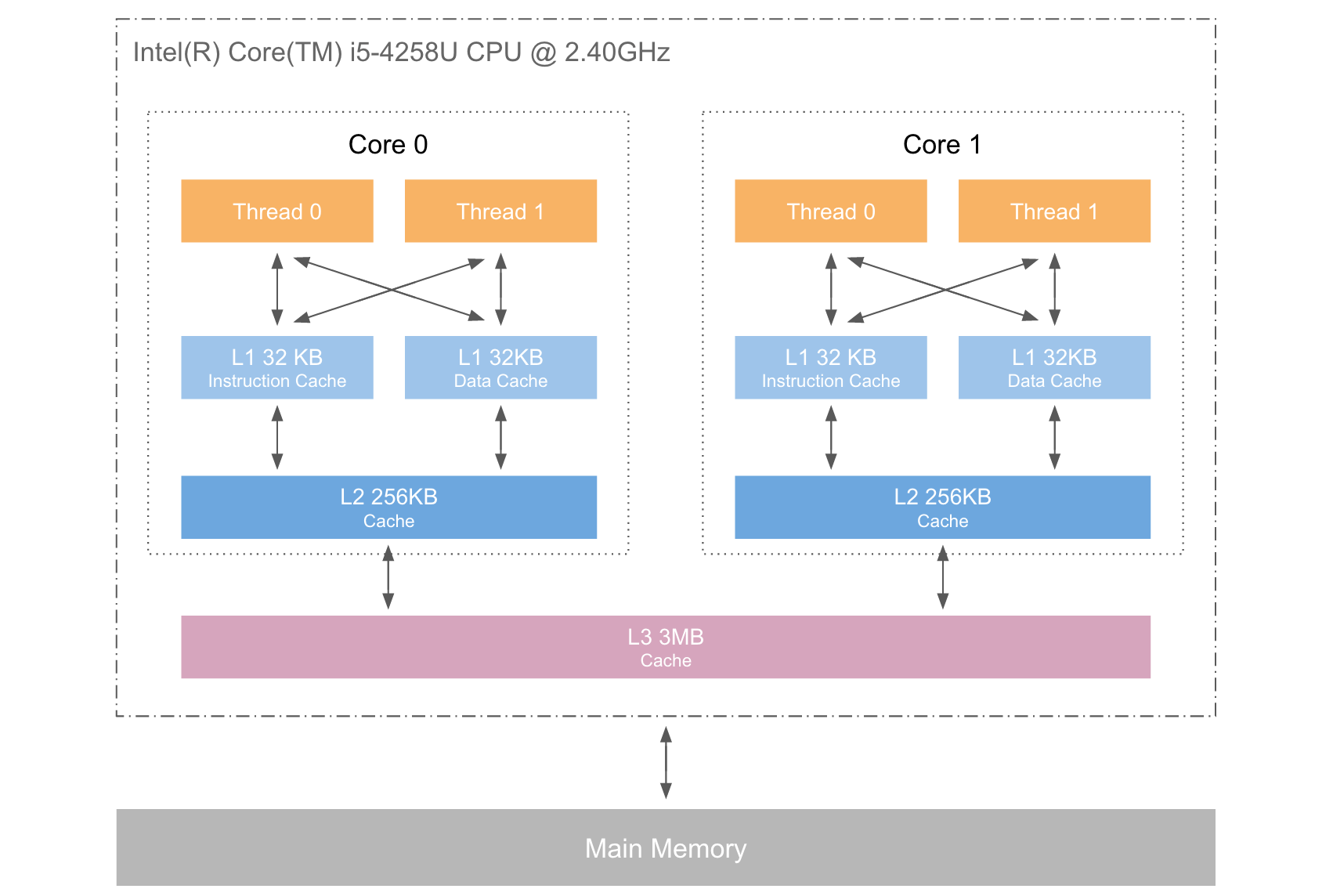
sync.Pool的設計哲學與此異曲同工。
它並非一個簡單的全局對象池,而是針對Go協程(Goroutine)的併發特性,構建了一套巧妙的分級緩存結構。這套結構旨在最大限度地減少鎖競爭,從而在併發場景下實現高效的對象複用。
sync.Pool的內部結構定義如下:
type Pool struct {
// ...
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// ...
}
local:它指向一個數組,數組的每個元素都是一個poolLocal類型。這裏的“P”代表Go調度器中的處理器(Processor),每個P都有自己獨立的poolLocal。
poolLocal的內部結構進一步揭示了sync.Pool的精妙:
type poolLocalInternal struct {
private any // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
private:這是poolLocal中的一個核心字段,它是一個私有對象槽,專屬於當前的P和與其綁定的Goroutine。Get操作會首先嚐試從這裏獲取對象,Put操作也會優先將對象放回這裏。由於是獨佔的,因此完全沒有鎖競爭。 可以將private理解為sync.Pool的一級緩存,類似於 CPU L1 緩存,存取無需加鎖,速度最快shared:這是一個更為複雜的隊列結構,其類型為poolChain。poolChain本身是一個雙向鏈表,其中每個節點都是一個poolDequeue(雙端隊列),且每個後續隊列的大小是前一個的兩倍。當一個poolDequeue裝滿後,它會分配一個新的、更大的隊列並將其添加到鏈表末尾。這種設計既保證了動態擴容,又通過尾部追加、頭部彈出(或從其他 Goroutine 的末尾“竊取”)的方式,有效分散了鎖競爭。
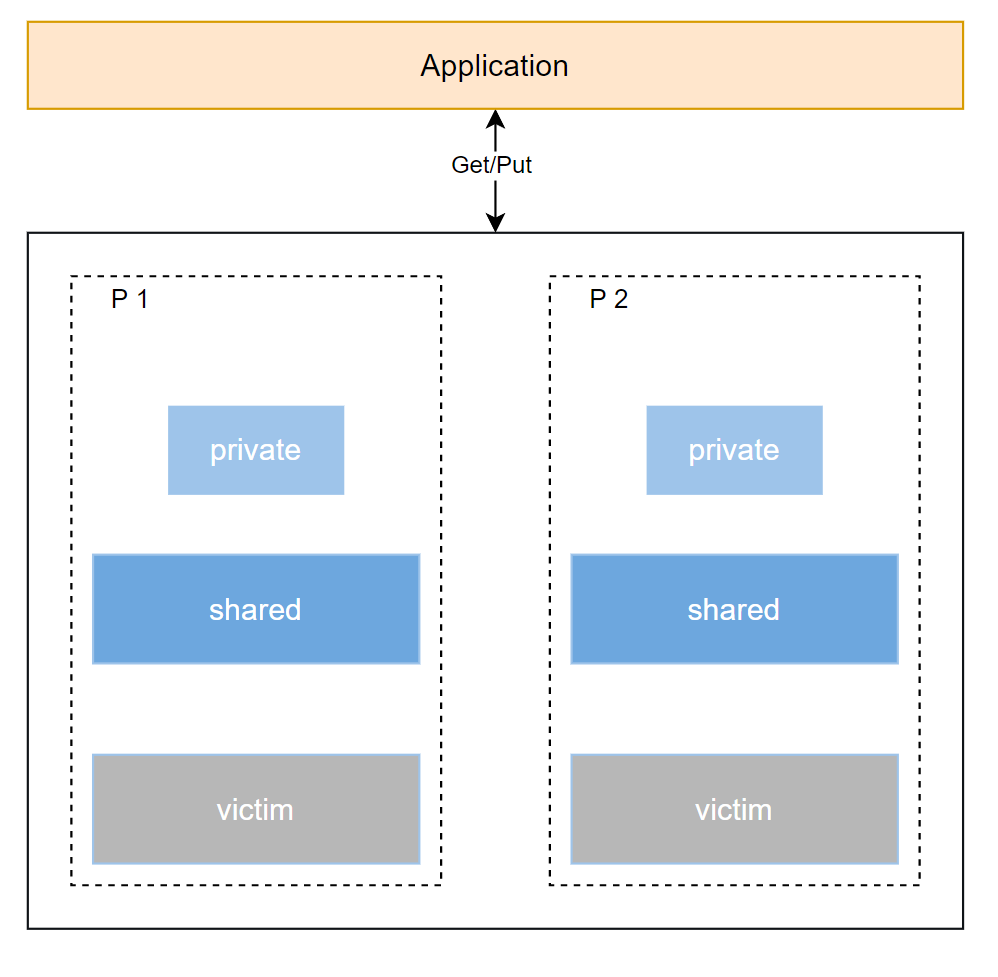
這種分級設計有效地平衡了性能和併發性。sync.Pool通過優先使用本地private緩存,最大程度地減少了鎖競爭,從而實現了在併發場景下的高效對象複用。
關於對象在這些緩存之間流轉的詳細機制,我們將在下一章Get和Put的源碼解析中逐一揭曉。
至於Pool結構體中的victim字段,它代表了sync.Pool在垃圾回收(GC)機制下的特殊設計。它的具體作用,我們將在後續章節中詳細解析,那也是sync.Pool設計中一個非常巧妙且容易被忽視的關鍵點。
三、源碼揭秘:Get與Put的舞蹈
sync.Pool 的設計精髓,在於其高效且幾乎無鎖的 Get 和 Put 操作。
通過對 runtime 包中 Go 調度器(P)的巧妙利用,它實現了每個 Goroutine 的本地緩存。
接下來,我們將逐一拆解這兩個核心函數。
3.1 Put 操作:對象的歸還
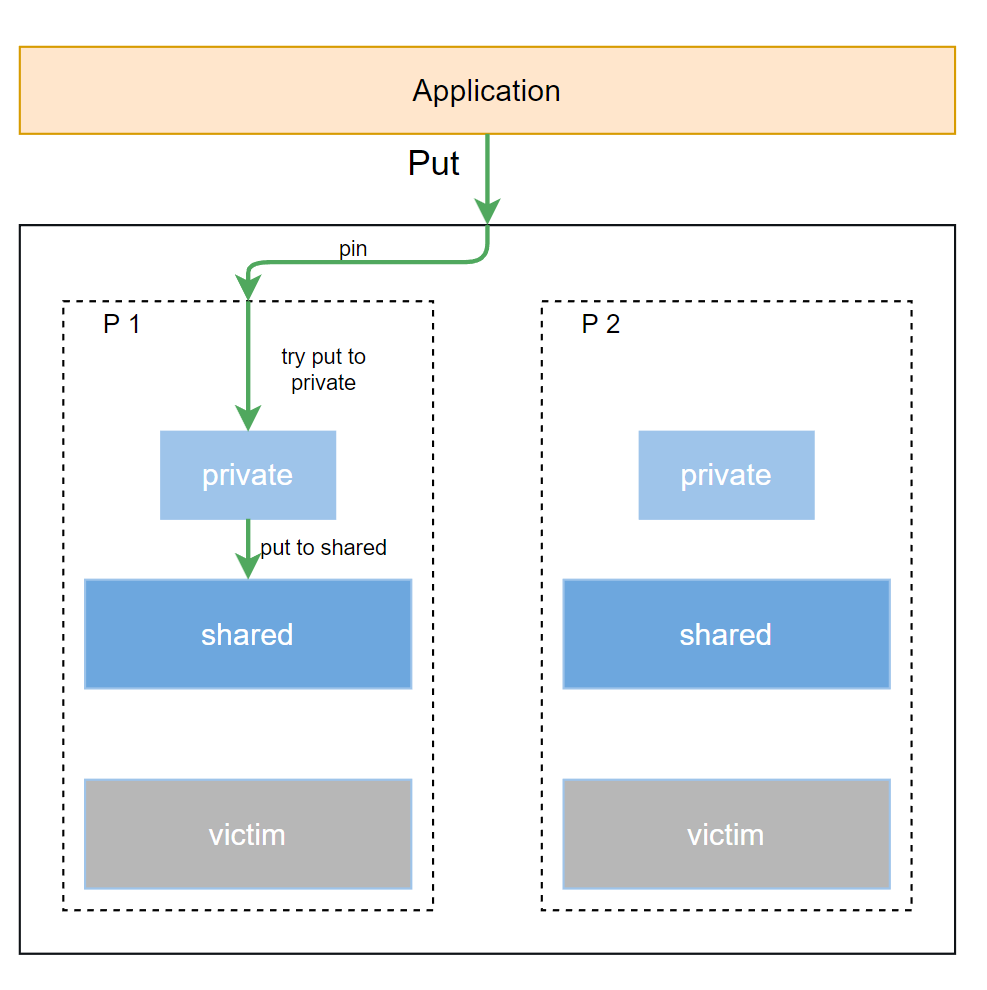
Put 函數的職責很簡單:將一個不再使用的對象放回池中。它的流程非常直接,優先將對象歸還給當前 Goroutine 所綁定的 P 的本地緩存。
func (p *Pool) Put(x any) {
if x == nil {
return
}
// ...
l := p.pin() // 獲取當前 P 的 poolLocal
if l.private == nil {
l.private = x
return
}
l.shared.pushHead(x) // 如果 private 不可用,放入 shared
}
-
第 1 步:
p.pin():這個函數是Put操作的第一步,也是最關鍵的一步。它會綁定當前的 Goroutine 到一個P(處理器)上,並返回該P對應的poolLocal結構。這個過程是無鎖的,確保了後續操作的極高性能。 -
第 2 步:檢查
private:Put操作會首先檢查poolLocal的private字段。如果private槽位為空,它會立即將對象x存入,然後返回。這個操作完全是本地的,沒有任何鎖競爭。 -
第 3 步:放入
shared:如果private槽位已被佔用,Put操作會通過l.shared.pushHead(x)將對象放入poolLocal的shared隊列的頭部。因為shared是一個雙端隊列,並且只有對應的P才會操作隊列的頭部,所以這一步同樣是無鎖的**。
這個流程簡潔而高效,大部分情況下,對象都能被快速地放回本地緩存,避免了任何鎖開銷。
3.2 Get 操作:對象的獲取
Get 函數的流程比 Put 稍微複雜,因為它需要依次嘗試從多個緩存源獲取對象。
func (p *Pool) Get() any {
// ...
l := p.pin() // 獲取當前 P 的 poolLocal
x := l.private
l.private = nil
if x == nil {
// 從 shared 獲取
x, _ = l.shared.popHead()
if x == nil {
// 從其他 P 的 pool 偷取
x = p.getSlow()
}
}
// ...
return x
}
-
第 1 步:
p.pin():與Put相同,Get操作首先獲取當前 Goroutine 綁定的P對應的poolLocal。 -
第 2 步:檢查
private:Get會首先嚐試從poolLocal的private槽位中獲取對象。如果成功,它會將該槽位清空,並直接返回對象。這個操作同樣是無鎖的。 -
第 3 步:檢查
shared:如果private槽位為空,Get會嘗試從poolLocal的shared隊列的頭部彈出對象。由於shared的popHead操作也是無鎖的,這個步驟依舊非常高效。 -
第 4 步:進入
getSlow():如果本地緩存(private和shared)都未能提供對象,Get才會進入getSlow()函數,啓動更復雜、但依然高效的無鎖竊取流程。
我們來看 getSlow 的源碼:
func (p *Pool) getSlow(pid int) any {
// 嘗試從其他 P 的 shared 隊列尾部竊取對象
size := runtime_LoadAcquintptr(&p.localSize)
locals := p.local
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 嘗試從 victim 緩存中獲取對象
size = atomic.LoadUintptr(&p.victimSize)
//... (以下代碼省略,但邏輯是先嚐試從 victim 的 private 獲取,再從 shared 竊取)
// 如果所有嘗試都失敗,返回 nil
return nil
}
getSlow 的核心流程如下:
-
竊取(Steal):
getSlow會遍歷所有其他的P,並嘗試從它們的shared隊列的尾部“竊取”對象。 -
訪問
victim池:如果竊取失敗,getSlow才會嘗試從victim池中獲取對象。這部分操作也會先嚐試從victim的private獲取,再從victim的shared隊列竊取。
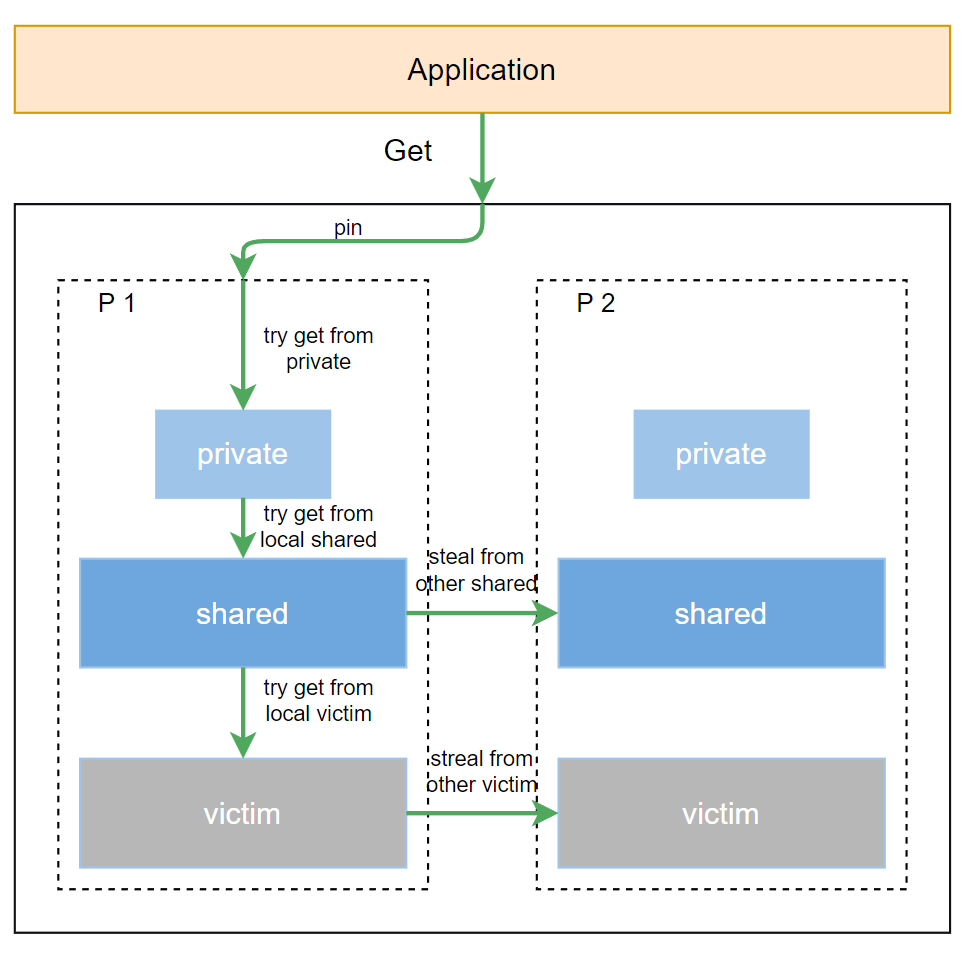
如果所有這些獲取路徑都失敗,Get 函數最終會調用 p.New() 方法來創建一個全新的對象。
Get 的流程完美地體現了“從近到遠”的緩存設計思想,將最頻繁的操作(private 和 shared 訪問)無鎖化,而將最昂貴的操作(steal 和 New)推遲到萬不得已時才執行。
PS:這裏簡單説下
shared隊列(底層是poolDequeue),該隊列被設計成一個無鎖(Lock-Free)的單生產者、多消費者(Single-Producer, Multi-Consumer, SPMC)隊列,通過CPU的原子擦操作來保證併發安全。在這裏,只有在一個P會向隊列中添加數據(單生產者),在steal時可能有多個 P 同時從尾部獲取數據(多消費者)。
四、生命週期之謎:GC與sync.Pool的愛恨情仇
在之前的內容中,我們多次提到了 sync.Pool 的一個特殊成員:victim 緩存,並預告了它與垃圾回收(GC 機制的緊密關係。
現在,是時候揭開這個“生命週期之謎”了。
為什麼 sync.Pool 不適合存儲需要長期複用的對象,比如數據庫連接?
答案就在於它並非一個永久性的對象池,而是一個輔助 GC 減壓的臨時緩存。它的緩存中的對象,隨時可能被清理。
4.1 GC 對 sync.Pool 的影響:poolCleanup 的秘密
在每次 GC 運行時,Go 運行時會執行一個特殊的 poolCleanup 函數,用於清理 sync.Pool 的緩存。
這個函數通過 runtime_registerPoolCleanup 註冊到 GC 開始時執行,但Go語言目前沒有提供穩定且公開的 API 來讓開發者直接註冊在 GC 任意階段執行的回調函數。
poolCleanup() 的核心源碼如下:
func poolCleanup() {
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// ...
oldPools, allPools = allPools, nil
}
poolCleanup() 的執行流程非常清晰:
-
清理上一輪的
victim緩存:首先,它會遍歷oldPools,將上一輪 GC 後保留的victim緩存徹底清空。這確保了對象不會被永久保留。 -
移動
local到victim:接着,它會遍歷allPools,將每個Pool的local緩存(即private和shared隊列)中的對象,整體轉移到victim緩存中,並清空local緩存。 -
更新
Pool列表:最後,它將當前allPools變為下一輪的oldPools,並清空allPools,等待新的Pool註冊。
這個機制確保了 sync.Pool 只是一個臨時性的緩存,其生命週期與兩次 GC 之間的時間段綁定。
4.2 為什麼sync.Pool需要在GC開始時進行清理?
這種設計並非缺陷,而是 Go 語言設計者深思熟慮後的結果。
如果 sync.Pool 的緩存對象永遠不被清理,那麼它將成為內存泄漏的温牀。
當程序在某個高併發階段創建了大量對象並放入池中,如果這些對象在後續低併發階段不再被使用,它們就會永遠佔用內存,無法被 GC 回收。
因此,sync.Pool 被設計為一個輔助 GC 減壓的工具。它通過在兩次 GC 之間暫時緩存對象,來減少短期、高頻的內存分配,而不是提供一個永久的對象複用方案。
4.3 使用陷阱與正確姿勢
基於對 sync.Pool 生命週期的理解,我們必須遵循以下原則來正確使用它:
- 僅用於短期、臨時性的對象:
sync.Pool最適合存儲那些在請求處理結束或函數調用後就不再需要的臨時對象,如[]byte切片、臨時緩衝、API 響應體等。這些對象的共同特點是,它們在短時間內會被高頻創建和使用,且生命週期與一次性的任務綁定。 - 不保證緩存對象一定存在:永遠不要假設從
sync.Pool中一定能Get到一個非空對象。Get方法的返回值可能是nil,此時必須使用New方法來創建新對象。 - 不要存儲需要管理生命週期的資源:如數據庫連接、文件句柄或
goroutine,這些資源需要開發者手動管理其打開和關閉,sync.Pool的 GC 清理機制無法保證它們的存活,可能導致資源泄漏。對於這類場景,應使用自定義的對象池,並配合mutex或channel來進行管理。
五、總結:sync.Pool 的設計理念與應用場景
從 Go 語言的 GC 機制出發,我們全面剖析了 sync.Pool 的設計理念,其核心思想是“通過本地緩存、無鎖竊取和 GC 輔助,最小化短期對象的內存分配開銷”。
-
設計理念:
sync.Pool巧妙地借鑑了 CPU 多級緩存的思想,通過private、shared和victim三級緩存結構,將絕大部分操作無鎖化,極大地提升了併發性能。 -
無鎖化:
Put和Get操作優先處理本地private緩存,這一過程完全沒有鎖。即使是跨 Goroutine 的“竊取”操作,也通過原子操作實現了無鎖化的popTail,保證了高效的併發。 -
GC 輔助:
sync.Pool的緩存會在每次 GC 時被清理,這使得它不適合長期存儲昂貴資源,但非常適合作為輔助 GC 減壓的工具,從而在不影響系統整體內存佔用的前提下,顯著提升高併發場景的性能。
結論:sync.Pool 是一個強大但有侷限性的工具。正確地理解其設計理念和 GC 機制,是避免性能陷阱、充分發揮其價值的關鍵。它就像一個精密的齒輪,只在特定的高頻場景下,才能與 Go 的運行時完美契合,共同打造高性能的應用
從 Gin 框架的 Context 內存優化,到 sync.Pool 內部的多級緩存、無鎖設計和 GC 機制,我們完成了一次從上層應用到底層源碼的深度探索。
如果你想了解更多關於 Go 語言的底層設計和性能優化技巧,歡迎關注微信公眾號:午夜遊魚
