

一、引言:大數據時代的數據處理挑戰
全球數據量正以指數級增長。據 Statista 統計,2010 年全球數據量僅 2ZB,2025 年預計達 175ZB。企業面臨的核心挑戰已從“如何存儲數據”轉向“如何快速分析數據”。傳統架構在處理海量數據時暴露明顯瓶頸:單點資源爭用導致查詢延遲激增,垂直擴展成本高昂(如某金融機構單台服務器擴容費用超百萬美元),且難以支持實時分析需求。
MPP 架構的歷史演進
MPP 架構並非新生事物,其發展歷程可追溯至 1980 年代:

- 第一代(1980-1995):Teradata、Tandem NonStop SQL 等開創性產品出現,主要服務於電信和金融行業的大型主機環境
- 第二代(1995-2010):Netezza、Greenplum、Vertica 等商業 MPP 數據庫崛起,引入列式存儲、壓縮等創新
- 第三代(2010-2020):AWS Redshift、Snowflake 等雲原生 MPP 產品問世,實現存算分離與彈性擴展
- 第四代(2020 至今):以 StarRocks、ClickHouse 為代表的開源 MPP 數據庫蓬勃發展,融合實時分析與 AI 能力
MPP(大規模並行處理)架構憑藉其分佈式計算能力,成為破解大數據處理難題的“效率引擎”。
二、MPP 架構的核心原理與組件
1. 定義與基本原理
MPP 架構(Massively Parallel Processing,大規模並行處理)是一種分佈式計算架構,通過將數據和計算任務分散到多個獨立節點,實現高性能數據處理。其三大核心特徵:
- 分佈式計算:單條 SQL 查詢被智能拆解為多個子任務,由不同節點並行執行。例如,一個涉及 10 億條記錄的聚合查詢,在 100 節點 MPP 集羣中,每個節點僅需處理 1000 萬條記錄,實現 “分而治之”。
- 無共享架構(Shared-Nothing):每個計算節點擁有專屬 CPU、內存和存儲資源,節點間通過高速互聯網絡協作,避免資源競爭。這與共享存儲架構(如 Oracle RAC)形成鮮明對比。
- 數據分片與本地化處理:採用哈希、範圍或混合分片策略,確保數據均勻分佈,並優先在數據所在節點執行計算(數據親和性原則),最小化網絡數據移動。
2. 核心組件協同機制
協調節點(Coordinator)負責接收客户端請求、解析 SQL、生成執行計劃並協調分佈式執行。 計算節點(Worker)執行實際數據處理任務。存儲層採用高效數據組織方式,優化 IO 性能。

- 查詢優化器:自動生成分佈式執行計劃。例如,AWS Redshift 的優化器會根據數據分佈動態調整 JOIN 順序,降低網絡傳輸開銷。
- 計算節點:採用向量化引擎(如 StarRocks)或 LLVM 編譯優化(如 ClickHouse)提升單節點處理效率。
- 存儲節點:列式存儲(Parquet/ORC 格式)結合數據分區(Partitioning)與分桶(Bucketing),實現高效壓縮與快速過濾。
三、MPP 架構的四大核心優勢
1. 高性能:線性擴展能力
MPP 架構最顯著優勢在於通過增加節點實現近乎線性的性能提升。
這種線性擴展特性使 MPP 架構能夠應對“大促”等突發流量場景。菜鳥物流分析平台在“雙 11”期間,通過動態擴展 StarRocks 集羣從 30 節點至 120 節點,平均查詢響應時間保持在 1.2 秒以內,確保實時物流決策。
關鍵技術支撐:
- 分佈式執行優化:自動識別並優化數據傾斜
- 並行度動態調整:根據數據分佈和節點負載自適應調整任務並行度
- 分佈式操作符:特殊設計的 Hash-Join、分佈式聚合算法,確保擴展效率
2. 高擴展性:存算分離實踐
雲原生 MPP 數據庫(如 Snowflake、StarRocks 等)基於存算分離架構,實現三大靈活性:
- 計算資源彈性:可在秒級動態調整計算節點數量,適應負載變化。某亞洲電商平台採用“潮汐型”資源調度策略,白天維持 64 節點集羣支撐業務查詢,夜間自動縮減至 16 節點執行 ETL 作業,計算成本降低 52%。
- 存儲無限擴展:基於對象存儲(S3、OSS、GCS)構建無限容量數據湖。Netflix 將超過 100PB 媒體分析數據存儲於 S3,通過 Snowflake 實現按需查詢,存儲成本較傳統 SAN 降低 87%。
- 多租户隔離:支持為不同業務部門分配獨立計算資源,避免各業務場景下資源利用率不足問題。
3. 高兼容性:標準 SQL 與生態集成
現代 MPP 數據庫普遍提供高度兼容的 SQL 接口,高兼容性降低了技術遷移風險。
同時,現代 MPP 平台提供豐富的連接器和 API,實現與數據科學工具等生態系統的無縫集成。
- Snowflake Snowpark 支持 Python/Java/Scala UDF 直接在 MPP 環境執行;
- Redshift 與 SageMaker 集成,支持 ML 模型訓練和推理;
- StarRocks 與開源 Iceberg/Hudi/Delta Lake 湖倉一體化,統一分析入口;
4. 高可用性:多副本與自動修復
企業級 MPP 架構通過多層次可靠性保障,確保業務連續性:
- 數據冗餘與自愈:自動維護多副本(通常 3 副本),節點故障時自動重建。
- 故障檢測與自動恢復:心跳機制快速識別故障節點(通常<10 秒),重新分配任務。
- 地理分佈式部署:支持跨區域同步複製。
- 漸進式恢復:故障後優先恢復關鍵業務查詢能力,實現業務分級可用。
四、MPP 架構與其他架構對比
1. 架構特性與性能比較
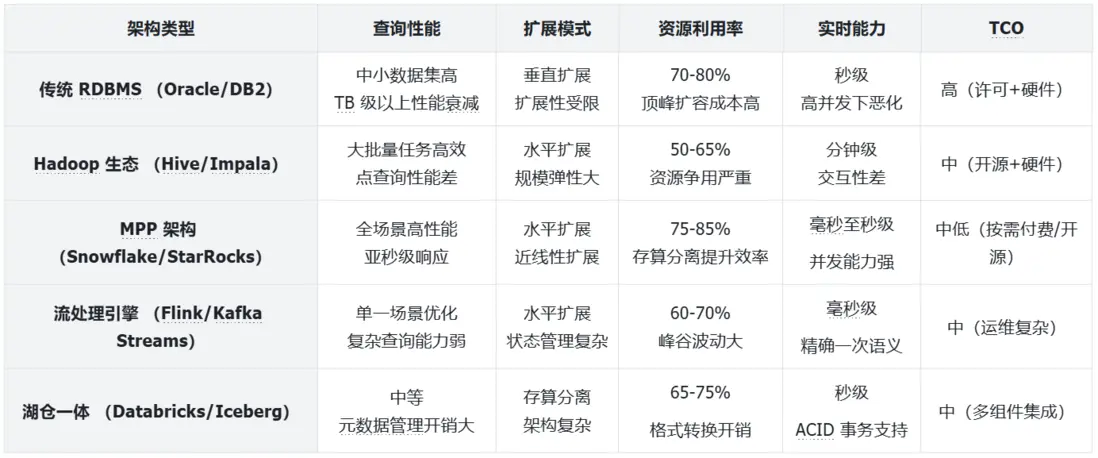
2. 不同架構的最佳適用場景
- 傳統 RDBMS:事務密集型應用、結構化數據管理、中小規模分析(<1TB);
- Hadoop 生態:非結構化數據處理、批量 ETL 作業、廉價存儲海量歷史數據;
- MPP 架構:交互式分析、實時儀表盤、高併發 BI 報表、複雜多表關聯分析;
- 流處理引擎:事件流處理、實時監控告警、連續查詢場景;
- 湖倉一體:統一數據平台、混合工作負載、數據科學與 AI/ML 場景;
不過,近年來各架構邊界日益模糊,呈現融合發展趨勢:
- MPP+流處理:StarRocks 支持 Flink 實時入湖,實現秒級數據可查詢;
- MPP+AI 加速:Snowflake Cortex、BigQuery ML 提供內置機器學習能力;
- MPP+湖倉一體:Databricks Photon、StarRocks 實現統一查詢層;
結語
MPP 架構正在重塑企業數據分析範式。從金融實時風控到廣告效果歸因,其價值已在全球頭部企業中得到驗證。隨着雲原生技術的成熟,未來 MPP 數據庫將進一步融合彈性計算、智能優化等能力,成為企業解鎖數據價值的核心基礎設施。對於技術選型者而言,需緊扣業務場景,在性能、成本、擴展性之間找到最佳平衡點,讓 MPP 架構真正成為驅動業務增長的“數據引擎”。