









本文介紹了OR算法+ML模型混合推理能力建設思路及業務背景,此場景相比常規模型推理更具特殊性和複雜性,在工程實現上面臨多維挑戰,因此本文分別從性能、穩定性和擴展性三個維度分析問題和解法,並以推理框架架構演進為線總結了過去兩年的分期迭代實踐歷程和收益,其中有一些較為通用的經驗,希望能夠給大家帶來一些幫助或啓發。
1 背景
調度系統主要職責是需要在合適的時間以合適的方式將合適的運單分給合適的騎手,承載着海量的調度規模。為追求更高用户體驗,需要在強時間約束下完成每一輪次的調度任務,對性能極度敏感;其中計算密集的運籌學算法(Operations Research,OR)和機器學習模型(Machine Learning,ML)是主要性能熱點,如OR部分計算量最大的「路徑規劃算法」和ML部分計算量最大的「送達時間預估深度學習模型(ETR)」計算量佔比60%以上,若使用遠程CPU承載此計算,集羣規模將在萬台以上,長尾問題明顯,運維壓力和資源成本難以控制。
因此,在調度系統工程架構中引入GPU硬件並通過手寫CUDA算子的方式來加速這些性能熱點,在模塊級取得了較好的加速效果[1],與此同時在系統級出現面向GPU新硬件如何高性能、高穩定性、高擴展性地實現OR+ML混合推理的新問題。圍繞這些問題,調度系統組通過近兩年的創新實踐,逐步沉澱出一套與調度系統算法特性匹配的推理框架。本文將介紹該推理框架的演進歷程,以及後續迭代計劃。

2 面臨的問題
為獲取更高系統性能,當前工程架構的設計理念是“數據本地化”和“計算本地化”,讓計算貼近存儲,因此計算密集模塊將優先使用本地GPU,實際應用過程會面臨以下問題。
2.1 性能問題
由於缺乏計算任務統一接入和全局統籌的能力,導致系統在實際應用場景會遇到分片大小差異大、卡間任務分配失衡、獨立Context頻繁切換等情形帶來調度耗時明顯增長的性能問題。
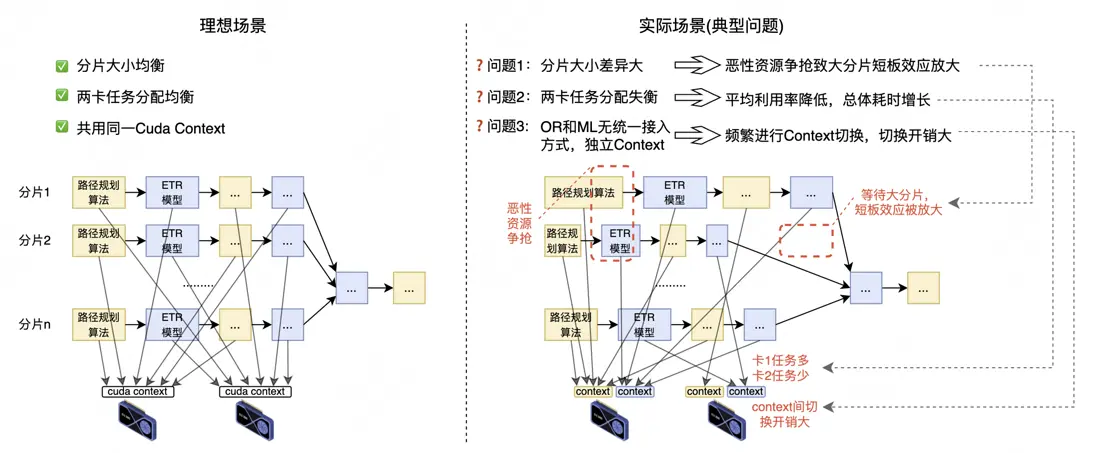
2.2 穩定性問題
在GPU上運行的異構計算任務可能會因為地址越界、ECC Error等軟硬件問題出現CUDA Exception,CUDA Exception需要進程重啓後才能恢復,否則GPU後續計算任務均會失敗。但調度服務進程重啓耗時需要10~15分鐘,雖然偶發單點重啓可通過節點冗餘保障線上服務,但當可用節點數量不足時,可能造成業務影響。因此如何縮小CUDA Exception影響半徑、縮短故障恢復時間,從而避免出現業務影響是必須要解決的穩定性保障問題。
2.3 擴展性問題
為提升GPU利用率,多個算法或者模型時分複用同一GPU,其中每個算法或模型均需要預分配顯存(3~5GB/模型,單卡總顯存24GB),雖然通過模型優化、參數共享等手段極致優化了顯存用量,但隨着算法複雜度和單量規模逐年增長,本機GPU顯存容量將會率先成為系統瓶頸。因此,如何在最小化數據傳輸延遲的約束下,靈活擴展GPU算力是不得不前置考慮的擴展性問題。
3 解決思路和方案
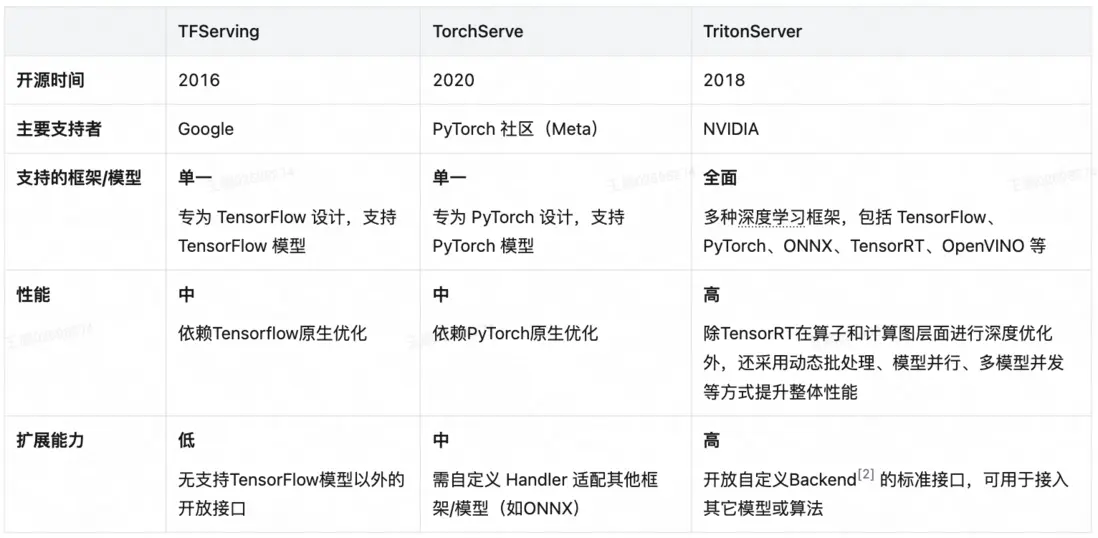
深度學習領域依託推理框架可調度計算任務實現系統性能提升、可屏蔽硬件細節實現推理與應用解耦,我們也借鑑了這一成熟解決思路。本着複用原則我們分別調研了TFServing、TorchServe、TritonServer等行業主流推理框架,其中TritonServer是英偉達近七年持續迭代並全開源的推理框架,相比TFServing、TorchServe具有支持模型範圍更廣泛、內嵌功能更全面、代碼結構更適合二次開發等優點,並且可獲得NVIDIA官方和美團內部基研團隊的技術支持,最終決定引入TritonServer推理框架並進行二次開發來解決上述性能、穩定性和擴展性問題。
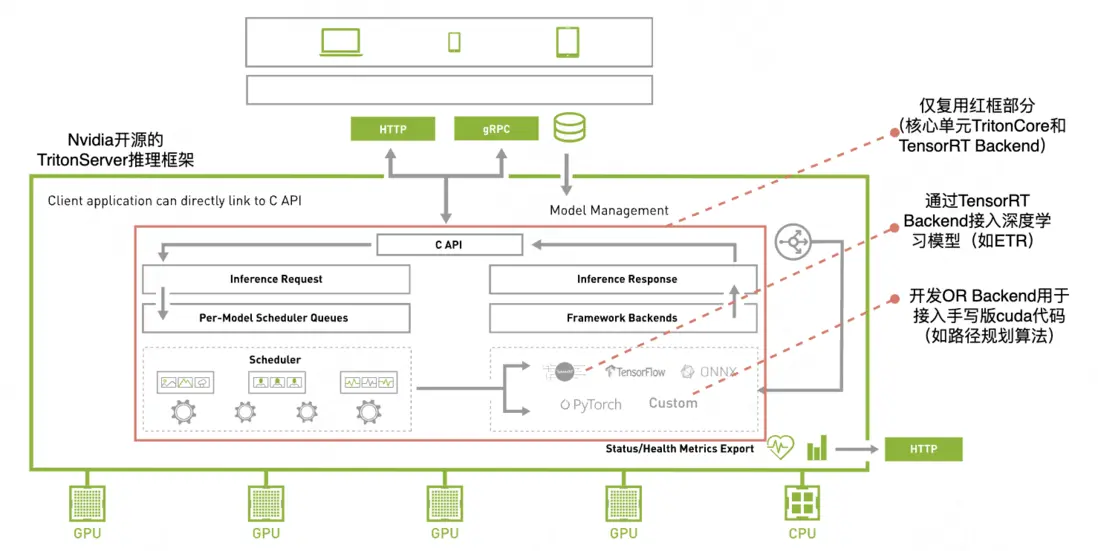
TritonServer推理框架主要包含Server、TritonCore、若干預開發的Backend、狀態監控等功能單元,通過分析和實驗發現TritonCore和TensorRT Backend複用價值高,且TritonCore提供的C-API接口易於集成,因此我們確定了以下基礎方案:基於TritonCore,通過TensorRT Backend接入深度學習模型(如ETR),開發OR Backend用於接入手寫版CUDA代碼(如路徑規劃算法)。
相比常規推理應用,基於TritonCore實現OR+ML的推理能力需要在自定義Backend開發、混合推理任務全局統籌、跨語言複雜系統設計等方面進行突破。
因此,我們將混合推理框架的建設過程拆解成三期進行,在架構上由易到難逐步迭代。

4 架構演進
4.1 進程內調用
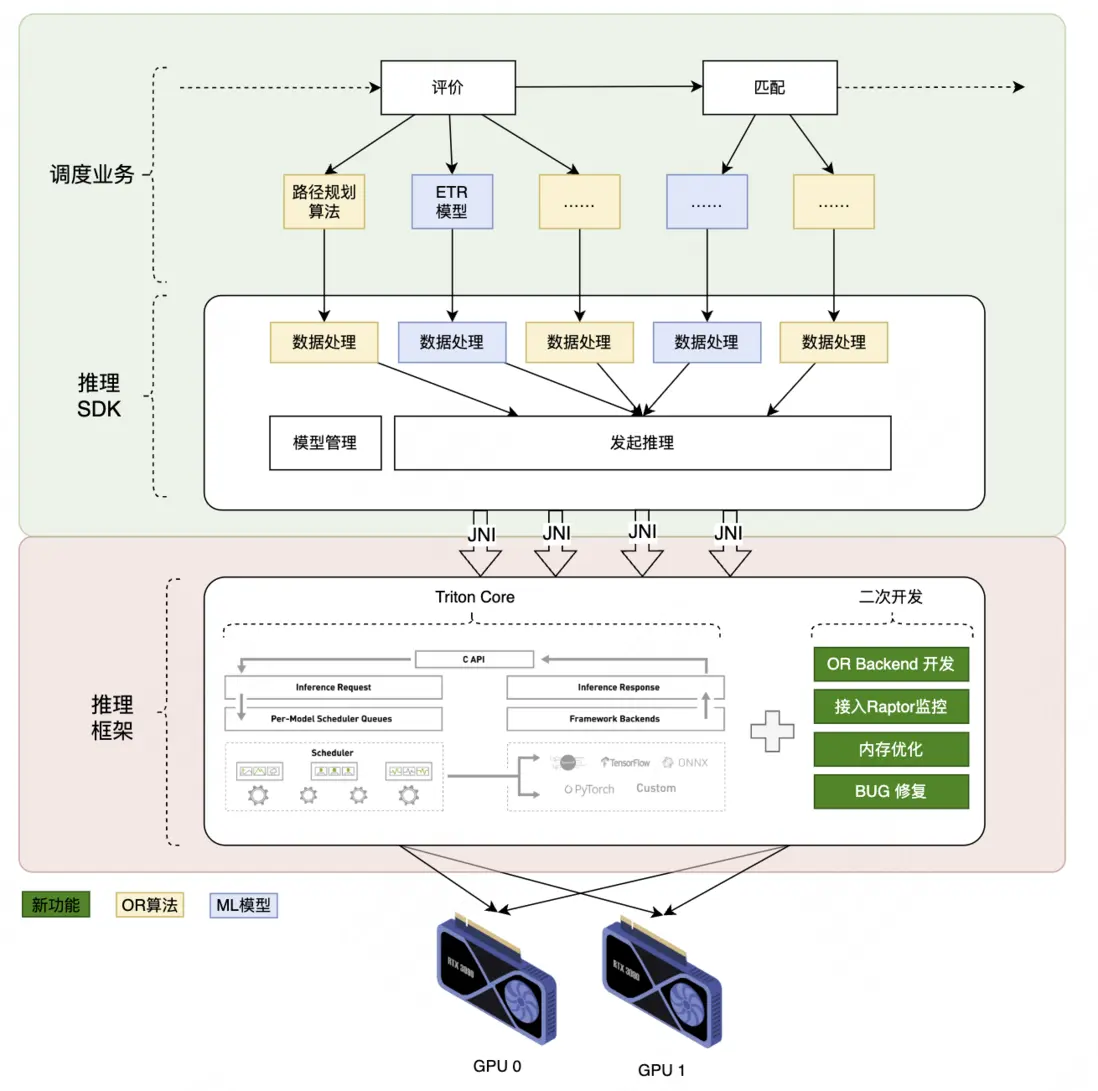
通過Java Native Interface(JNI)將TritonCore接入Java語言開發的調度業務進程,填平了跨語言鴻溝並在此基礎上進行二次開發,在功能和性能上實現突破。其核心內容如下:
1)功能突破
- 開發OR Backend,接入CUDA版路徑規劃算法,實現從0到1的突破;
- 將 TritonCore內監控模塊與美團監控平台(Raptor)打通,實現推理成功率、推理延遲等12項指標可視化;
- 利用Valgrind等工具定位到TritonCore存在內存泄漏等問題,並聯合英偉達專家修復了這些Bug。
2)性能突破
- 改進TensorRT Backend,優化ETR模型內存使用方式,實現模型推理性能超15%的提升;
- 摸索混合推理任務全局統籌策略,實現整體性能提升8%。
4.2 跨進程調用
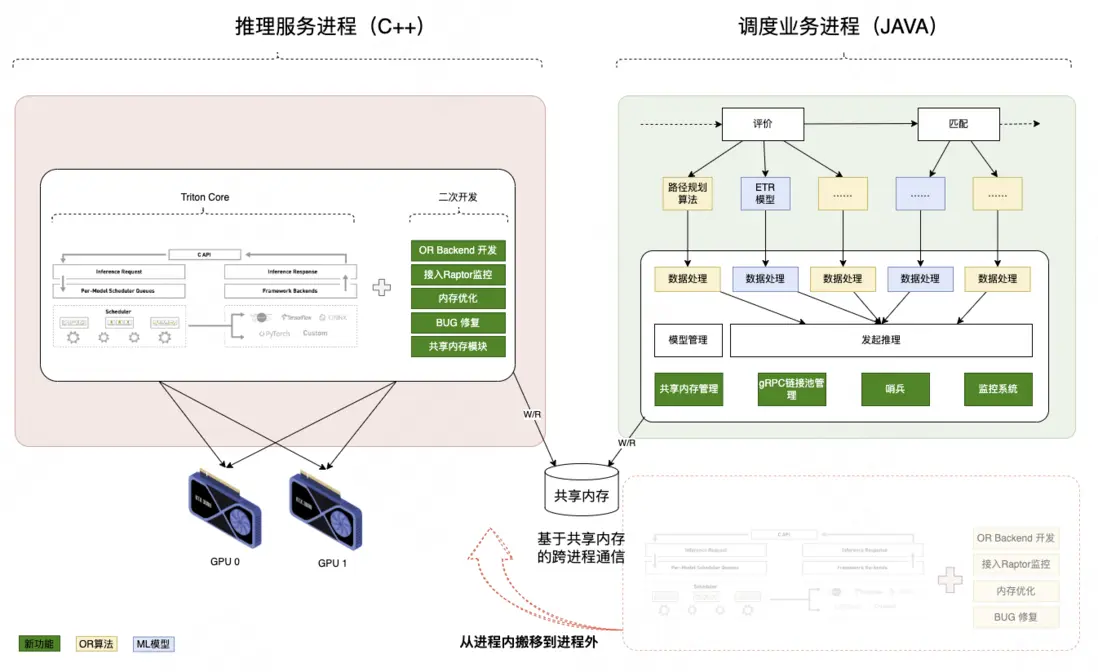
在功能和性能充分驗證基礎上,將TritonCore調用方式從進程內改造成跨進程,實現故障隔離,將異常恢復耗時從10+分鐘壓縮至10秒級。本次改造圍繞三方面展開。
1)通信框架升級
採用gRPC+SHM(共享內存)替代原有JNI,SHM負責重量級的數據面傳輸,gRPC負責輕量級的控制面通信,在保持推理性能優勢同時將調用方式升級成跨進程,當出現CUDA Exception時只需重啓推理服務進程即可恢復,最小化底層故障的影響半徑。
2)共享內存傳輸體系
- 相比純RPC的傳輸方式,共享內存技術可減少2次數據拷貝和4次序列化與反序列化的開銷,最小化跨進程數據傳輸開銷;
- 結合推理請求分片錯峯特點,將共享內存池化,最大化複用共享內存空間,在不大幅增加內存開銷的情況下即可支撐6000+ QPS高併發場景。
3)自動化運維
設計哨兵模塊實現秒級發現底層異常並自動重啓推理進程,相比進程內調用方式需要重啓調度業務進程才能恢復的方式大幅縮短故障恢復時長(10分鐘級->10秒級)。
- 調度業務進程為有狀態服務,重啓過程依賴本地緩存數據的拉取過程,通常耗時在10+分鐘;
- 推理服務進程為無狀態服務,重啓過程常規耗時約27秒,進一步優化啓動過程後耗時後僅需10~12秒。
4.3 跨節點調用
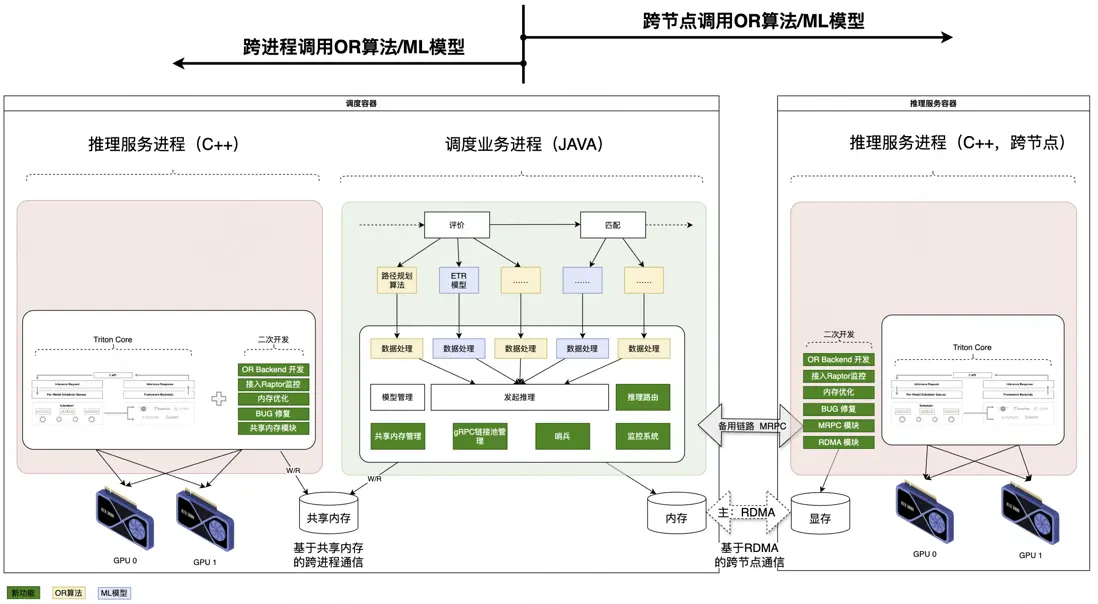
為滿足算法複雜度和單量規模逐年增長的需求,在本地跨進程調用基礎上增加跨節點調用能力,實現突破單機算力瓶頸的低時延算力擴展;核心模塊包含。
1)高性能流量路由
在流量路由模塊的設計上,借鑑Meta公司推理服務路由策略,實現與“本地跨進程+遠程跨多節點”架構適配的流量路由策略。
- 基於自適應均衡算法動態分配本地/遠程流量,應用Power-of-Two-Choices算法避免遠程節點間負載失衡,優化後同等資源的吞吐提升18%,TP99延遲縮短了25%;
- 通過哨兵監控系統實時追蹤本地推理進程的健康狀態,當檢測到本地推理進程故障時,系統自動將本地的推理請求切換到遠程集羣上,保障服務的可用性。
2)低延遲主備數據傳輸:RDMA降低傳輸延遲,MRPC兜底機制保障可用性
我們和基研高性能網絡組聯合預研驗證了RDMA技術在調度系統算力擴展場景具有大幅提升性能的可行性,正在落地開發,預計2025年Q3上線應用,屆時將在MRPC備用鏈路基礎上實現RDMA高性能數據傳輸。
- 應用GPUDirect RDMA技術,實現主機內存←→遠端GPU顯存直接透傳,端到端傳輸時延可優化60%;
- 採用MRPC作為RDMA的備用鏈路,當RDMA鏈路發生故障時,可自動降級至MRPC鏈路,保障服務的可用性。
4 未來展望
經過上述三期的架構迭代,我們逐步在功能、性能、穩定性和擴展性方面獲得收益,建成了面向履約調度場景的高性能、可伸縮的OR+ML混合推理框架。隨着GPU卡外部供給環境的變化,集羣將出現不同型號GPU卡並存的場景,不同型號GPU卡在顯存大小、計算能力等規格上存在差異,我們將針對這些差異在框架層面進一步做功,自適應硬件差異實現差異化部署,最大化全局性能。此外,我們還將在多級緩存、分佈式推理等方向進行擴展,為算法策略在加大搜索深度、擴大解空間、基於大模型解決組合優化問題等探索方向提供算力支撐。
5 參考資料
- [1] 模塊級取得了較好的加速效果:手寫CUDA版路徑規劃算法(GPU)相比原Java版實現(CPU)加速14.8倍,並在2023 Nvidia GTC上分享該成果,詳情參見《Accelerating Massive Route Planning for Food Delivery with GPU》https://www.nvidia.com/en-us/on-demand/session/gtcspring23-s5...
- [2] Backend:Backend是TritonServer中的核心組件,負責處理來自客户端的推理請求,並將這些請求轉發給相應的模型進行計算。更多詳情參見https://docs.nvidia.com/deeplearning/triton-inference-server/...
- [3] Meta公司推理服務的路由策略:https://engineering.fb.com/2024/07/10/production-engineering/...
- [4]Power-of-Two-Choices:系統會隨機選擇兩個服務器,然後通過輪詢方式獲取這兩個服務器最新負載信息,並選其中負載較低者來處理請求
閲讀更多
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024 年貨】、【2023 年貨】、【2023 年貨】、【2022 年貨】、【2021 年貨】、【2020 年貨】、【2019 年貨】、【2018 年貨】、【2017 年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明 "內容轉載自美團技術團隊"。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。







