









自9月1日,美團正式發佈 LongCat-Flash 系列模型,現已開源 LongCat-Flash-Chat 和 LongCat-Flash-Thinking 兩大版本,獲得了開發者的關注。今天 LongCat-Flash 系列再升級,正式發佈全新家族成員——LongCat-Flash-Omni。
LongCat-Flash-Omni 以 LongCat-Flash 系列的高效架構設計為基礎( Shortcut-Connected MoE,含零計算專家),同時創新性集成了高效多模態感知模塊與語音重建模塊。即便在總參數 5600 億(激活參數 270 億)的龐大參數規模下,仍實現了低延遲的實時音視頻交互能力,為開發者的多模態應用場景提供了更高效的技術選擇。
綜合評估結果表明,LongCat-Flash-Omni 在全模態基準測試中達到開源最先進水平(SOTA),同時在文本、圖像、視頻理解及語音感知與生成等關鍵單模態任務中,均展現出極強的競爭力。LongCat-Flash-Omni 是業界首個實現 “全模態覆蓋、端到端架構、大參數量高效推理” 於一體的開源大語言模型,首次在開源範疇內實現了全模態能力對閉源模型的對標,並憑藉創新的架構設計與工程優化,讓大參數模型在多模態任務中也能實現毫秒級響應,解決了行業內推理延遲的痛點。
模型已同步開源,歡迎體驗:
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-Omni
- Github:https://github.com/meituan-longcat/LongCat-Flash-Omni
技術亮點
極致性能的一體化全模態架構
LongCat-Flash-Omni 是一款擁有極致性能的開源全模態模型,在一體化框架中整合了離線多模態理解與實時音視頻交互能力。該模型採用完全端到端的設計,以視覺與音頻編碼器作為多模態感知器,由 LLM 直接處理輸入並生成文本與語音token,再通過輕量級音頻解碼器重建為自然語音波形,實現低延遲的實時交互。所有模塊均基於高效流式推理設計,視覺編碼器、音頻編解碼器均為輕量級組件,參數量均約為6億,延續了 LongCat-Flash 系列的創新型高效架構設計,實現了性能與推理效率間的最優平衡。

大規模、低延遲的音視頻交互能力
LongCat-Flash-Omni 突破 “大參數規模與低延遲交互難以兼顧” 的瓶頸,在大規模架構基礎上實現高效實時音視頻交互。該模型總參數達 5600 億(激活參數 270 億),卻依託 LongCat-Flash 系列創新的 ScMoE 架構(含零計算專家)作為 LLM 骨幹,結合高效多模態編解碼器和“分塊式音視頻特徵交織機制”,最終實現低延遲、高質量的音視頻處理與流式語音生成。模型支持 128K tokens 上下文窗口及超 8 分鐘音視頻交互,在多模態長時記憶、多輪對話、時序推理等能力上具備顯著優勢。
漸進式早期多模融合訓練策略
全模態模型訓練的核心挑戰之一是 “不同模態的數據分佈存在顯著異質性”,LongCat-Flash-Omni 採用漸進式早期多模融合訓練策略,在平衡數據策略與早期融合訓練範式下,逐步融入文本、音頻、視頻等模態,確保全模態性能強勁且無任何單模態性能退化。
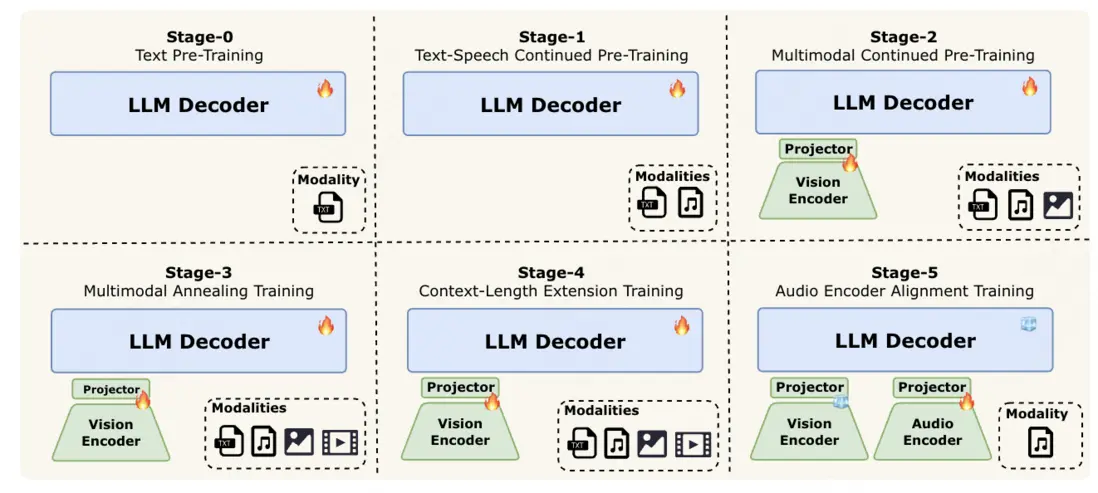
- 階段 0:大規模文本預訓練,利用成熟穩定的大語言模型為後續多模態學習奠定堅實基礎;
- 階段 1:引入與文本結構更接近的語音數據,實現聲學表徵與語言模型特徵空間的對齊,有效整合副語言信息;
- 階段 2:在 文本 - 語音對齊基礎上,融入大規模圖像 - 描述對與視覺 - 語言交織語料,實現視覺 - 語言對齊,豐富模型視覺知識;
- 階段 3:引入最複雜的視頻數據,實現時空推理,同時整合更高質量、更多樣化的圖像數據集以增強視覺理解;
- 階段 4:將模型上下文窗口從 8K 擴展至 128K tokens,進一步支持長上下文推理與多輪交互;
- 階段 5:為緩解離散語音 tokens 的信息丟失,進行音頻編碼器對齊訓練,使模型能直接處理連續音頻特徵,提升下游語音任務的保真度與穩健性。
全模態不降智,性能達到開源SOTA
經過全面的綜合評估顯示:LongCat-Flash-Omni 不僅在綜合性的全模態基準測試(如Omni-Bench, WorldSense)上達到了開源最先進水平(SOTA),其在文本、圖像、音頻、視頻等各項模態的能力均位居開源模型前列,真正實現了“全模態不降智”。

- 文本:LongCat-Flash-Omni 延續了該系列卓越的文本基礎能力,且在多領域均呈現領先性能。相較於 LongCat-Flash 系列早期版本,該模型不僅未出現文本能力的衰減,反而在部分領域實現了性能提升。這一結果不僅印證了我們訓練策略的有效性,更凸顯出全模態模型訓練中不同模態間的潛在協同價值。
- 圖像理解:LongCat-Flash-Omni 的性能(RealWorldQA 74.8分)與閉源全模態模型 Gemini-2.5-Pro 相當,且優於開源模型 Qwen3-Omni;多圖像任務優勢尤為顯著,核心得益於高質量交織圖文、多圖像及視頻數據集上的訓練成果。
- 音頻能力:從自動語音識別(ASR)、文本到語音(TTS)、語音續寫維度進行評估,Instruct Model 層面表現突出:ASR 在 LibriSpeech、AISHELL-1 等數據集上優於 Gemini-2.5-Pro;語音到文本翻譯(S2TT)在 CoVost2 表現強勁;音頻理解在 TUT2017、Nonspeech7k 等任務達當前最優;音頻到文本對話在 OpenAudioBench、VoiceBench 表現優異,實時音視頻交互評分接近閉源模型,類人性指標優於 GPT-4o,實現基礎能力到實用交互的高效轉化。
- 視頻理解:LongCat-Flash-Omni 視頻到文本任務性能達當前最優,短視頻理解大幅優於現有參評模型,長視頻理解比肩 Gemini-2.5-Pro 與 Qwen3-VL,這得益於動態幀採樣、分層令牌聚合的視頻處理策略,及高效骨幹網絡對長上下文的支持。
- 跨模態理解:性能優於 Gemini-2.5-Flash(非思考模式),比肩 Gemini-2.5-Pro(非思考模式);尤其在真實世界音視頻理解WorldSense 基準測試上,相較其他開源全模態模型展現出顯著的性能優勢,印證其高效的多模態融合能力,是當前綜合能力領先的開源全模態模型。
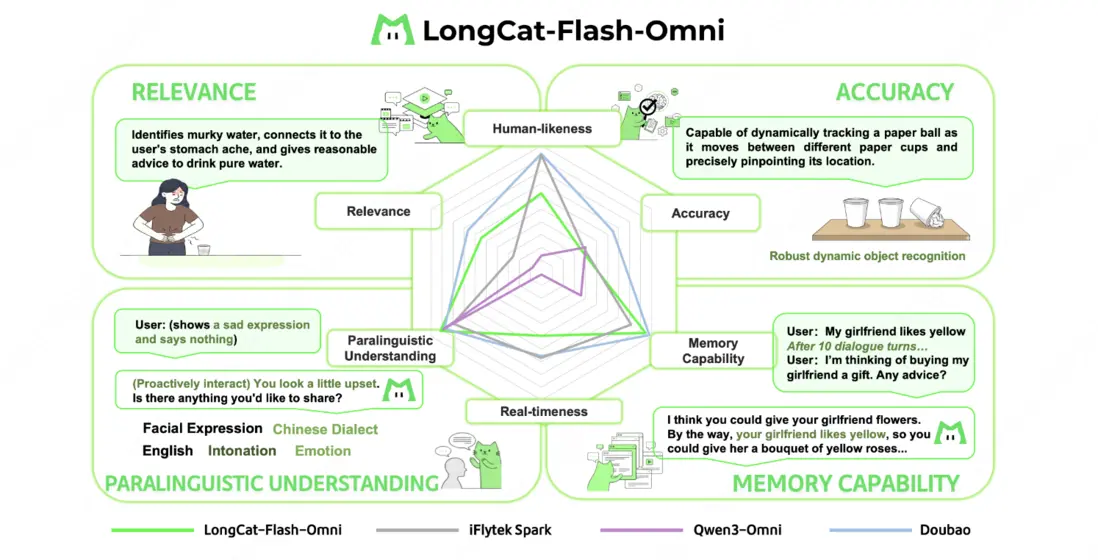
- 端到端交互:由於目前行業內尚未有成熟的實時多模態交互評估體系,LongCat 團隊構建了一套專屬的端到端評測方案,該方案由定量用户評分(250 名用户評分)與定性專家分析(10 名專家,200 個對話樣本)組成。定量結果顯示:圍繞端到端交互的自然度與流暢度,LongCat-Flash-Omni 在開源模型中展現出顯著優勢 —— 其評分比當前最優開源模型 Qwen3-Omni 高出 0.56 分;定性結果顯示:LongCat-Flash-Omni 在副語言理解、相關性與記憶能力三個維度與頂級模型持平,但是在實時性、類人性與準確性三個維度仍存在差距,也將在未來工作中進一步優化。
快來跟 LongCat 語音吧!
你可以通過 https://longcat.ai/ 體驗圖片、文件上傳和語音通話功能。
另外,我們非常激動的告訴大家,LongCat 官方 App 現已正式發佈,支持聯網搜索,還可以發起語音通話(視頻通話功能敬請期待)。您可以通過掃描下方二維碼下載使用,iOS用户可直接在APP Store中搜索“LongCat”獲取。

LongCat-Flash-Omni 在開源平台已上線,歡迎開發者們探索和使用:
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-Omni
- Github:https://github.com/meituan-longcat/LongCat-Flash-Omni
期待聽到您的反饋。
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。









