

適用版本提示:本文提及的 Data Branch 功能適用於 MatrixOne v3.0 及以上版本。
我們想解決的不是“怎麼再備份一份”,而是這三件事:隨時落一個可靠錨點、開出互不打擾的試驗枱、把變更做成可審閲/可回放的補丁。
序幕:雙線並行的一張表,怎麼不互相踩?
“今晚必須把風控規則修掉。”
“同時運營要做活動,數據得按新口徑重算。”
“你們都別動 orders 表,我先拷一份出來吧……”
這句“我先拷一份”,在很多團隊裏幾乎是條件反射:複製庫、複製表、複製到新集羣、再把一堆腳本跑一遍。
問題也跟着來:
- 拷貝很慢(數據越大越慢),而且越急越容易拷錯、漏拷
- 成本很高(存儲、帶寬、算力、時間都在燒)
- 最麻煩的是:你很難説清楚“到底改了哪些數據”,更難把它“有選擇地帶回去”
MatrixOne Data Branch 想做的,是把這件事改造成一種“像工程一樣可重複”的流程:不靠一堆臨時副本,也不靠口頭約定。
1. 先把目標説清楚:我們需要的是 5 個動作
如果把“數據變更”當成主角,那工作流裏最常用的動作其實就五個:
1) Snapshot:在你動手之前,先留一個“可回到的點”
2) Clone/Branch:從這個點開出一張“試驗枱”(隔離修改)
3) Diff:把試驗枱上的改動“講清楚”(可審閲、可追溯)
4) Merge:把“確認正確的改動”帶回主表(並處理衝突)
5) Restore:如果後悔了,回到那個點(止血優先)
在 MatrixOne 裏,這些動作都能用 SQL 串起來:CREATE SNAPSHOT、DATA BRANCH DIFF、DATA BRANCH MERGE、RESTORE ... FROM SNAPSHOT,再配合 CLONE(或新版本中的專用創建語義)把“分支表”拉出來。
2. 一段可復現的“劇情腳本”:兩條線並行修改,同步回主表
下面這套 SQL 你可以按順序跑一遍,感受它和“複製數據庫做實驗”的區別。
2.1 第一幕:主表就緒,先把“錨點”打上
drop database if exists demo_branch;
create database demo_branch;
use demo_branch;
create table orders_base (
order_id bigint primary key,
user_id bigint,
amount decimal(12,2),
risk_flag tinyint, -- 0=normal, 1=high risk
promo_tag varchar(20),
updated_at timestamp
);
insert into orders_base values
(10001, 501, 99.90, 0, null, '2025-12-01 10:00:00'),
(10002, 502, 199.00, 0, null, '2025-12-01 10:00:00'),
(10003, 503, 10.00, 0, null, '2025-12-01 10:00:00');
create snapshot sp_orders_v1 for table demo_branch orders_base;你可以把 sp_orders_v1 理解成“所有人都認可的起跑線”。後面無論怎麼折騰,都能回得來。
2.2 第二幕:開兩張試驗枱(風控線 / 活動線)
如果你的版本支持專用“創建分支表”語義,可以直接用它;如果沒有,也可以用 CLONE 方式(兩者的使用體驗是一樣的:從快照視圖拉出一張新表用於獨立改動)。
-- Option A: CLONE (works as a branch table in current versions)
create table orders_riskfix clone orders_base {snapshot='sp_orders_v1'};
create table orders_promo clone orders_base {snapshot='sp_orders_v1'};
-- Option B: if your version supports it
-- data branch create table orders_riskfix from orders_base{snapshot='sp_orders_v1'};
-- data branch create table orders_promo from orders_base{snapshot='sp_orders_v1'};[!NOTE]
技術原理小貼士:為什麼建分支這麼快?
MatrixOne 的快照和分支基於 Copy-on-Write (CoW) 機制。創建分支時,並沒有真的複製一份數據,而是建立了一個指向原數據的引用。只有當你開始修改分支表時,存儲層才會為變更的數據塊分配新空間。所以,無論原表有幾百 GB 還是 TB 級,建分支都是毫秒級的,且幾乎不佔額外存儲。
2.3 第三幕:兩條線各自修改,互不干擾
-- Risk-fix line
update orders_riskfix
set risk_flag = 1,
updated_at = '2025-12-01 10:05:00'
where order_id = 10002;
delete from orders_riskfix where order_id = 10003;
insert into orders_riskfix values
(10003, 503, 10.00, 0, 'repaired', '2025-12-01 10:06:00');
-- Promo line
update orders_promo
set promo_tag = 'double11',
amount = amount * 0.9,
updated_at = '2025-12-01 10:07:00'
where order_id in (10001, 10002);
insert into orders_promo values
(10004, 504, 39.90, 0, 'double11', '2025-12-01 10:07:30');這一步最關鍵的感受是:你不用先複製一份 TB 級數據,也不用擔心“我改表會不會把別人搞崩”。兩條線天然隔離,誰也不需要“先等等我”。
2.4 第四幕:把“改了什麼”説清楚(Diff)
為了讓 diff 可重複、可定位,一般會給分支表再打一次快照:
create snapshot sp_riskfix for table demo_branch orders_riskfix;
create snapshot sp_promo for table demo_branch orders_promo;
data branch diff orders_riskfix{snapshot='sp_riskfix'}
against orders_promo{snapshot='sp_promo'};執行結果示意(你會看到每一行具體的差異):
diff orders_riskfix against orders_promo flag order_id risk_flag promo_tag amount
orders_promo UPDATE 10001 0 double11 89.91
orders_riskfix UPDATE 10002 1 null 199.00
orders_promo UPDATE 10002 0 double11 179.10
orders_riskfix UPDATE 10003 0 repaired 10.00
orders_promo INSERT 10004 0 double11 39.90DATA BRANCH DIFF 會把兩邊的行級差異列出來(插入/刪除/更新),讓“數據變更”從口頭描述變成可以審閲的結果。
2.5 第五幕:把確認的改動帶回主表(Merge + 衝突策略)
-- Merge risk fix first
data branch merge orders_riskfix into orders_base;
-- Then try promo (choose a conflict strategy if needed)
data branch merge orders_promo into orders_base when conflict skip;
-- data branch merge orders_promo into orders_base when conflict accept;這裏的“衝突”你可以把它理解成:兩條線都動到了同一行、同一主鍵,目標表應該聽誰的。
FAIL/SKIP/ACCEPT 三種策略,讓你把“合併規則”寫進 SQL,而不是寫進微信羣裏。
2.6 第六幕:不滿意就回到起跑線(Restore)
如果合併後發現方向不對,先止血:
restore database demo_branch table orders_base from snapshot sp_orders_v1;這句 SQL 的意義不是“把你當成不會操作的人”,而是把“回退”從高風險操作變成常規動作:敢試驗,才跑得快。
2.7 第七幕:測試結束,清理環境
-- 無論是測試還是正式環境,用完即焚是好習慣
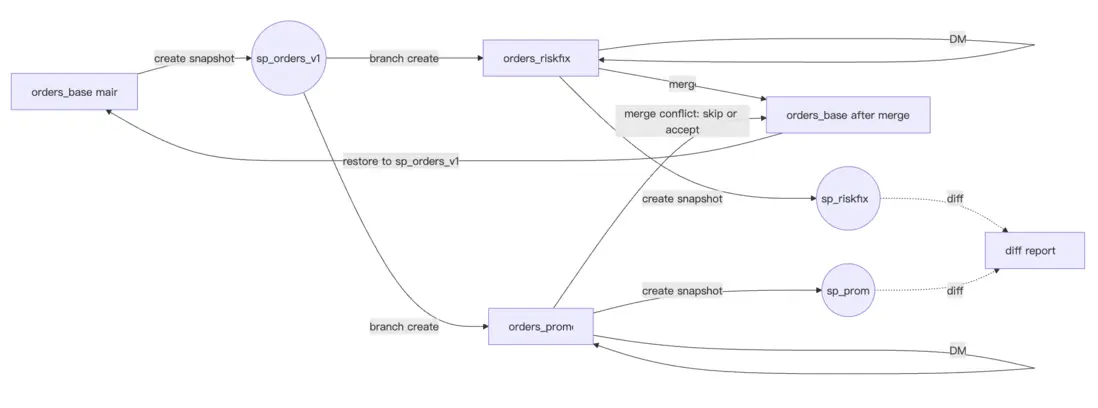
drop database demo_branch;3. 一張圖把流程連起來(主表 / 分支表 / diff / merge / restore)
4. 進階:把 diff 做成“補丁文件”,跨集羣/跨環境重放
很多團隊真正頭疼的不是“我能不能 diff/merge”,而是這些工程問題:
- 預發需要每天刷新,但不想整庫搬運
- 災備演練想驗證“能不能把關鍵變更快速補齊”
- 多集羣部署時,希望把變更從 A 端“帶到” B 端,而不是重新跑一遍腳本
Data Branch 提供了一個很實用的落點:把 diff 輸出成文件。文件就是補丁:能帶走、能存檔、能在別處回放。
4.1 把 diff 輸出到本地目錄
data branch diff branch_tbl against base_tbl output file '/tmp/diffs/';執行後系統會明確告訴你文件去哪了,以及怎麼用它:
+---------------------------------------------+-------------------------------------------------------+
| FILE SAVED TO | HINT |
+---------------------------------------------+-------------------------------------------------------+
| /tmp/diffs/diff_branch_base_20251219.sql | DELETE FROM demo_branch.orders_base, REPLACE INTO ... |
+---------------------------------------------+-------------------------------------------------------+如果是全量同步(即目標表為空),則會生成 CSV 文件:
+---------------------------------------------+-----------------------------------------------------------------------------------+
| FILE SAVED TO | HINT |
+---------------------------------------------+-----------------------------------------------------------------------------------+
| /tmp/diffs/diff_branch_base_init.csv | FIELDS ENCLOSED BY '"' ESCAPED BY '\\' TERMINATED BY ',' LINES TERMINATED BY '\n' |
+---------------------------------------------+-----------------------------------------------------------------------------------+輸出結果會告訴你文件保存位置,同時給出導入/執行提示。常見形態是兩類:
- CSV:更適合“目標為空/初始化”的全量導入
- .sql:更適合“目標非空/增量同步”的補丁回放(通常由
DELETE FROM ...+REPLACE INTO ...組成)
4.2 把 diff 直接寫到 stage(例如 S3)
Stage 是 MatrixOne 用於連接外部存儲(如 S3、HDFS 或本地文件系統)的邏輯對象。
為什麼要引入這個概念? 主要是為了安全和解耦:
- 屏蔽密鑰:無需在每次執行 SQL 時都暴露 AK/SK,管理員配置一次 Stage,開發者直接用別名即可。
- 統一路徑:將複雜的 URL 路徑封裝成簡單的對象名,像掛載磁盤一樣使用對象存儲。
create stage stage01 url =
's3://bucket/prefix?region=cn-north-1&access_key_id=xxx&secret_access_key=yyy';
data branch diff t1 against t2 output file 'stage://stage01/';+-------------------------------------------------+-------------------------------------------------------+
| FILE SAVED TO | HINT |
+-------------------------------------------------+-------------------------------------------------------+
| stage://stage01/diff_t1_t2_20251201_091329.sql | DELETE FROM test.t2, REPLACE INTO test.t2 |
+-------------------------------------------------+-------------------------------------------------------+這讓“把補丁發給另一個集羣”變得很直白:源端寫到對象存儲,目標端拿到文件即可。
4.3 回放補丁:執行 SQL 或導入 CSV
- 回放 SQL(增量):在目標集羣執行生成的
.sql文件即可(MatrixOne 兼容 MySQL 協議) - 導入 CSV(初始化):用
LOAD DATA把 CSV 導入目標表即可
[!TIP]
小技巧:不離開終端查看補丁內容
如果文件還在 Stage 上,你可以直接用 SQL 查看它的內容,確認無誤後再執行:select load_file(cast('stage://stage01/diff_t1_t2_xxx.sql' as datalink));
示意(SQL 文件回放):
mysql -h <mo_host> -P <mo_port> -u <user> -p <db_name> < diff_xxx.sql示意(CSV 導入):
load data local infile '/tmp/diffs/diff_xxx.csv'
into table demo_branch.orders_base
fields enclosed by '"' escaped by '\\' terminated by ','
lines terminated by '\n';5. 落地小抄:把它變成團隊習慣,而不是一次“炫技”
如果你準備把 Data Branch 用進真實項目,下面這幾條比“會不會寫 SQL”更重要:
- 先定命名規則:快照名、分支表名要能一眼看懂用途(例如
sp_orders_yyyymmdd_hhmm) - 關鍵表要有主鍵/唯一鍵:diff/merge 的可控性依賴於“怎麼定位一行數據”
- 把 diff 當成評審材料:讓數據變更也能做 review(尤其是高風險口徑調整)
- 先小表試流程:把“創建 → 修改 → diff → merge → restore” 跑順,再擴到核心鏈路
延伸閲讀
- MatrixOrigin, “AI 時代的數據管理新範式:Git for Data 讓數據工程化”, InfoQ 寫作社區
- “Git for Data: 像 Git 一樣管理你的數據”, InfoQ 中國
- MatrixOne CREATE SNAPSHOT
- MatrixOne RESTORE SNAPSHOT
- MatrixOne LOAD DATA
- PlanetScale Docs: Data Branching®
- lakeFS: Data Collaboration & Branching