









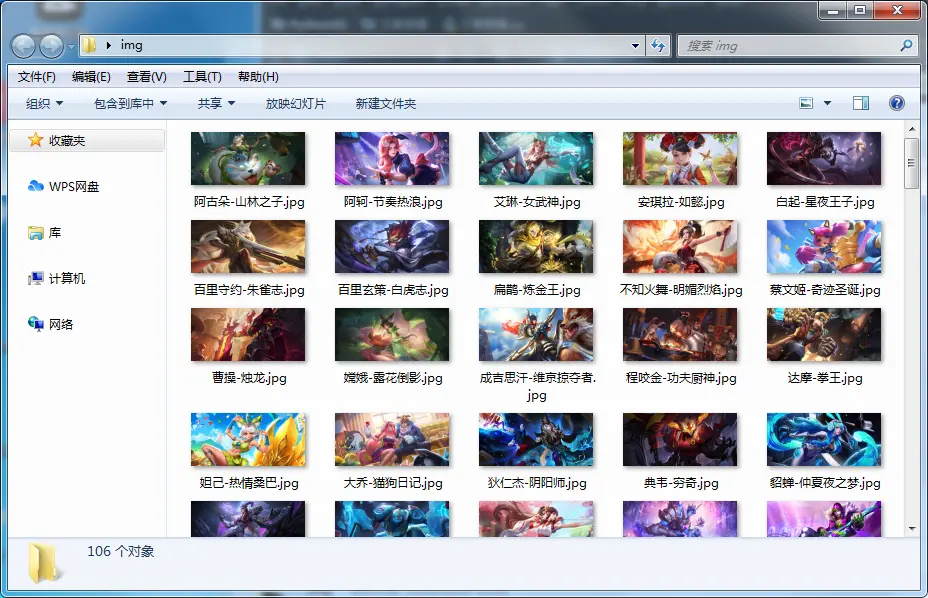
一、先看效果
二、工具
開發環境
系統:Windows7 64位
Python版本:3.6
Pycharm版本:2019.2
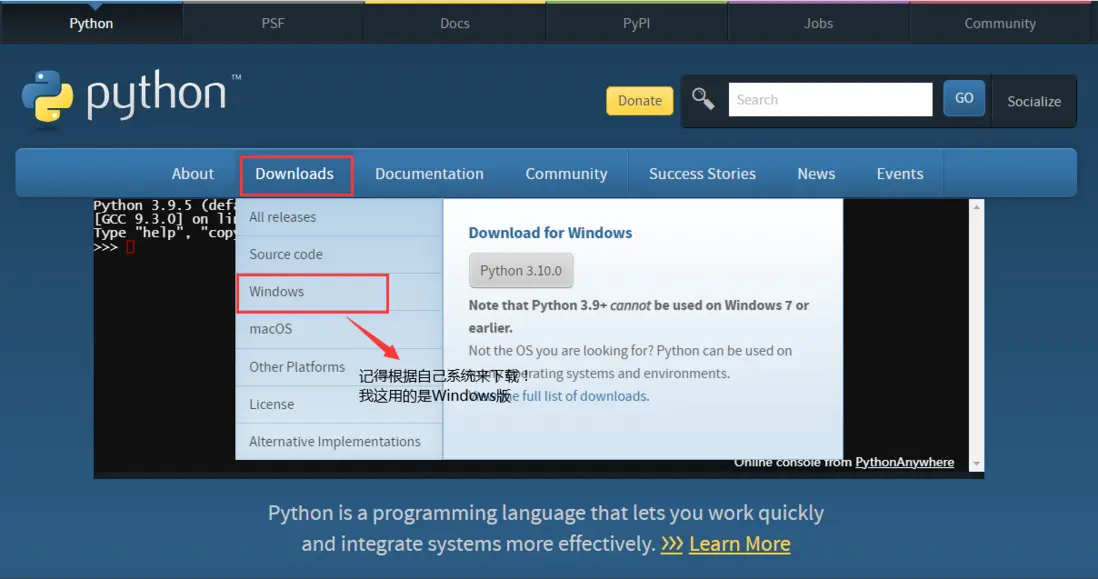
解釋器
官方網站地址是:https://www.python.org
軟件下載▼
sublime || JetBrains PyCharm Community Edition
三、進入正題
頁面分析網站:
英雄資料列表頁-英雄介紹-王者榮耀官方網站-騰訊遊戲
# requests
# json
import requests
import json
# 導入模塊
# 1.分析網頁,確定URL路徑
base_url = 'https://pvp.qq.com/web201605/js/herolist.json'
# 2.發送請求 --requests 模擬瀏覽器發送請求,獲取響應數據
res = requests.get(base_url)
data = res.text
print(data)
# 3.解析數據 --json模塊:把json字符轉Python可交互數據類型
# 3.1 轉數據類型
data_list = json.loads(data)
# print(data_list)
# 3.2解析數據
for data in data_list:
# print(data)
ename = data['ename'] # 英雄編號
cname = data['cname'] # 英雄名稱
try:
skin_name=data['skin_name'].split('|') # 切割皮膚名字用於計算多少個皮膚
except Exception as e:
print(e)
# print(ename,cname,skin_name)
# 構造所以英雄皮膚圖片url鏈接地址
# 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+英雄編號+'/'+英雄編號+'-bigskin-'+皮膚數量+'.jpg'
for skin_num in range(1,len(skin_name)+1):
skin_url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(ename)+'/'+str(ename)+'-bigskin-'+str(skin_num)+'.jpg'
# print(skin_url)
skin_data = requests.get(skin_url).content # 圖片獲取用二進制
# 4.保持數據 --保存到目標文件夾
with open('img\\'+cname+'-'+skin_name[skin_num-1]+'.jpg','wb') as f:
print('正在下載圖片:',cname+'-'+skin_name[skin_num-1])
f.write(skin_data)實踐操作圖













