
Kubeflow 的一個主要設計目標就是簡化和標準化在 Kubernetes 上進行大規模 ML 訓練的過程。它提供了一系列工具和組件,讓數據科學家和工程師能夠輕鬆地啓動、管理和監控分佈式訓練任務,而無需關心底層的 Kubernetes 集羣調度細節。

1. 核心組件:Kubeflow Training Operators
Kubeflow 不直接調度訓練任務,而是通過一組稱為 Training Operators 的自定義控制器來實現。這些 Operators 是 Kubernetes 自定義資源(CRD)的控制器,它們理解特定的分佈式訓練框架(如 TensorFlow, PyTorch, MXNet 等)的語義,並負責:
1. 根據用户提交的訓練任務定義(如 TFJob, PyTorchJob),在 Kubernetes 集羣中創建相應的 Pod。
2. 管理這些 Pod 的生命週期(啓動、健康檢查、重啓失敗的 Pod)。
3. 處理分佈式訓練的網絡配置(如設置 MASTER_ADDR, WORKER_HOSTS 等環境變量)。
4. 聚合訓練日誌和事件。
常用的 Training Operators:
• TFJob: 用於 TensorFlow 分佈式訓練。
• PyTorchJob: 用於 PyTorch 分佈式訓練。
• MXNetJob: 用於 MXNet 分佈式訓練。
• XGBoostJob: 用於 XGBoost 分佈式訓練。
• MPIJob: 一個通用的、基於 MPI (Message Passing Interface) 的 Operator,可用於支持 MPI 的任何框架(如 Horovod 訓練)。

2. 如何使用 Kubeflow 進行大規模訓練?
使用 Kubeflow 進行分佈式訓練通常分為以下幾個步驟:
步驟 1: 準備訓練代碼
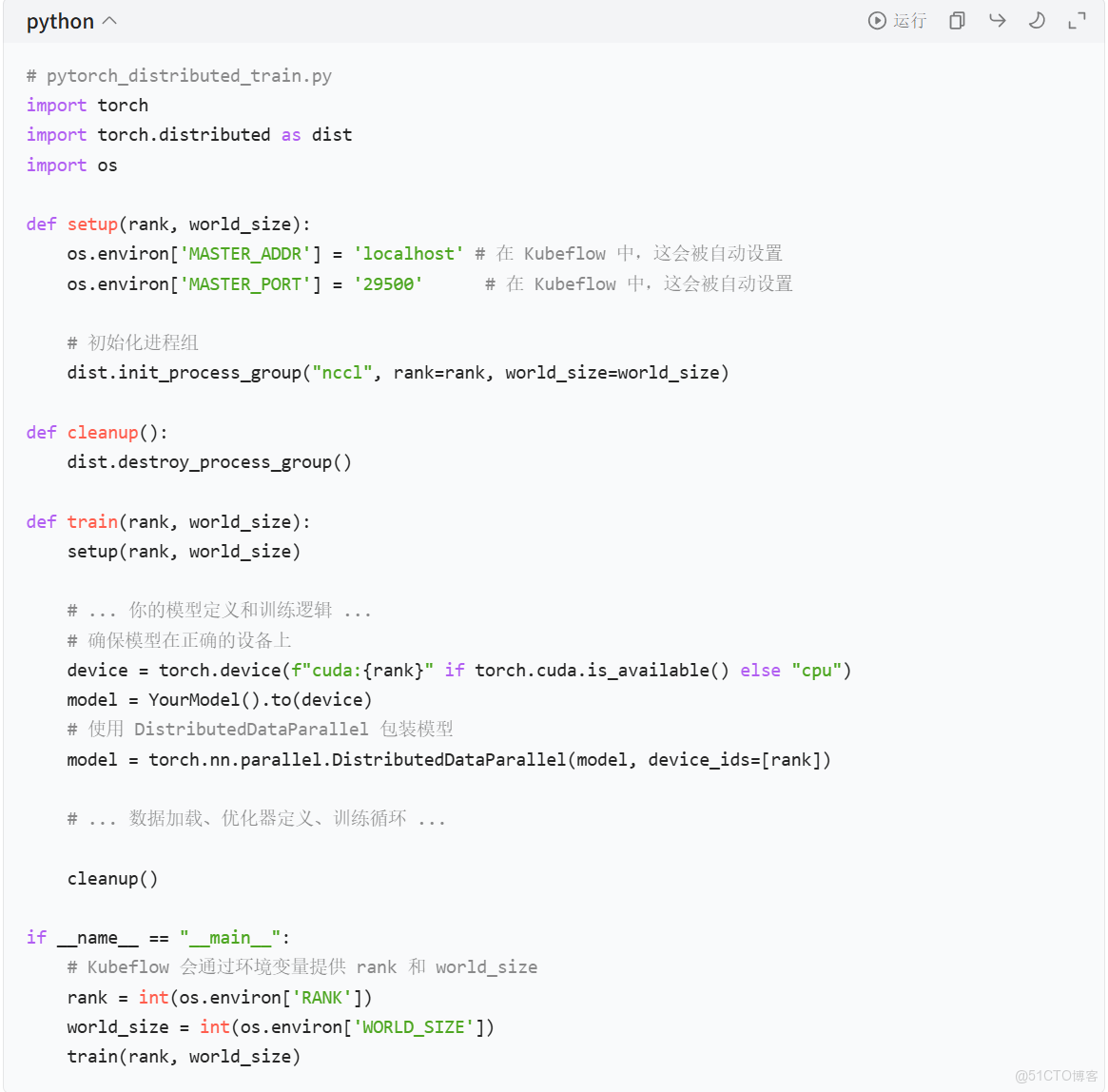
你的訓練代碼需要適配分佈式訓練框架。
• 對於 PyTorch:你需要使用 torch.distributed 包來初始化進程組,並在代碼中處理 rank 和 world_size。
步驟 2: 創建 Docker 鏡像
構建並推送到鏡像倉庫。
步驟 3: 定義 Kubeflow Training Job YAML
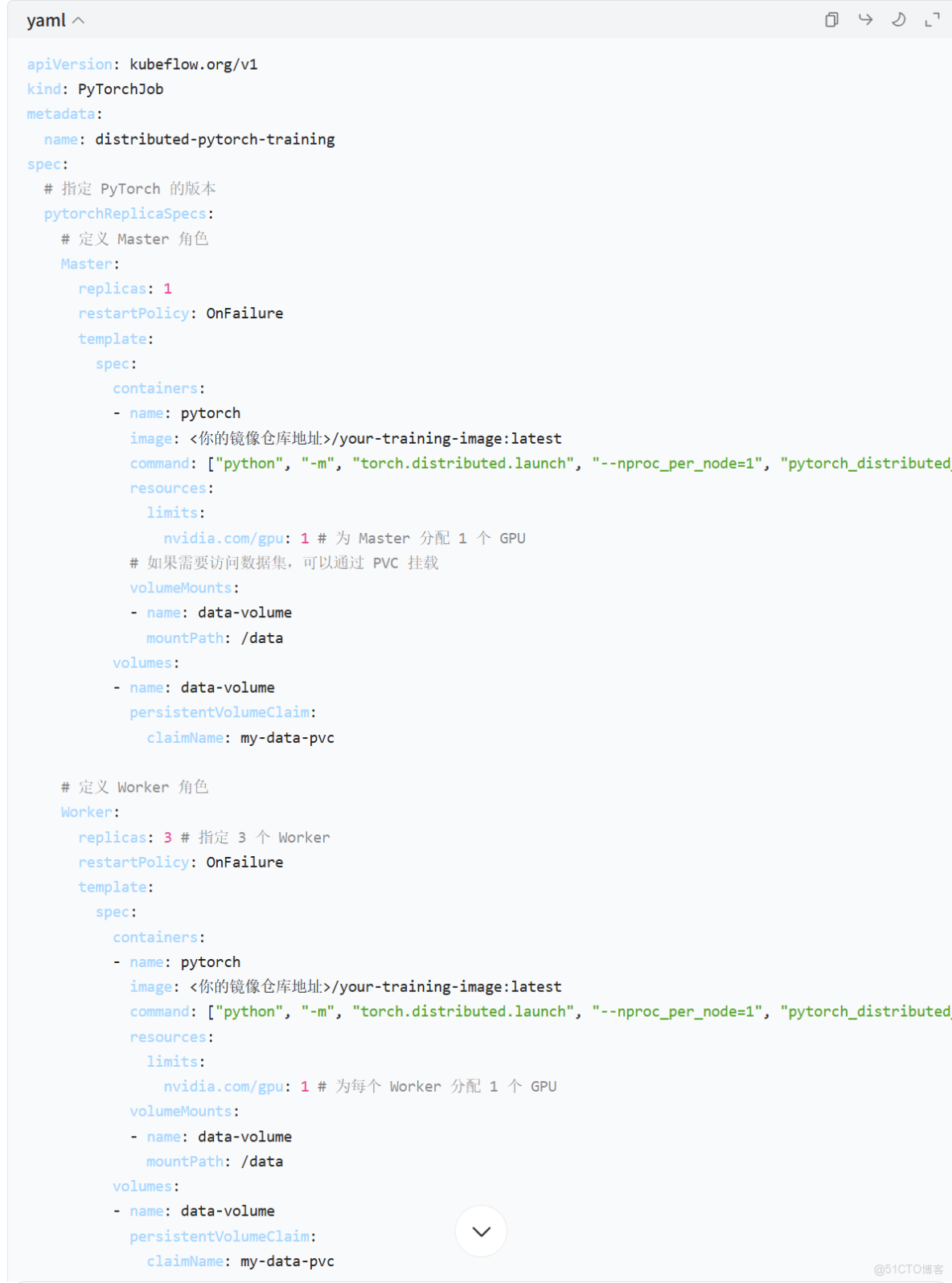
説明:
PyTorchJobCRD 定義了兩種角色:Master和Worker。Master.replicas: 1: 通常有一個 Master 進程。Worker.replicas: 3: 這裏我們請求 3 個 Worker 進程。nvidia.com/gpu: 1: 請求 GPU 資源。Kubernetes 會將這些 Pod 調度到有可用 GPU 的節點上。restartPolicy: OnFailure: 如果某個 Pod 失敗,Kubeflow 會嘗試重啓它。command: 指定了容器啓動時要執行的命令。torch.distributed.launch是 PyTorch 提供的一個啓動器,它會自動處理進程的啓動和通信。
步驟 4: 提交訓練任務
kubectl apply -f pytorch_job.yaml步驟 5: 監控訓練任務
- 查看 Job 狀態:
kubectl get pytorchjobs- 查看 Pod 狀態:
kubectl get pods -l job-name=distributed-pytorch-training- 查看訓練日誌:
# 查看 Master Pod 日誌
kubectl logs -f distributed-pytorch-training-master-0 -c pytorch
# 查看某個 Worker Pod 日誌
kubectl logs -f distributed-pytorch-training-worker-0 -c pytorch3. 大規模訓練的優勢
- 彈性伸縮: 可以輕鬆地通過修改 YAML 文件中的
replicas數量來增加或減少訓練的並行度。 - 資源高效利用: Kubernetes 的調度器會將訓練任務智能地調度到集羣中最合適的節點,避免資源浪費。
- ** fault tolerance**: Kubeflow 的 Training Operators 會自動處理失敗的訓練進程,提高了訓練任務的可靠性。
- 統一的管理界面: 可以通過 Kubeflow Dashboard 直觀地管理和監控所有訓練任務。
- 集成化: 訓練任務可以很容易地與 Kubeflow 的其他組件(如 Pipelines, Model Registry)集成,構建端到端的 MLOps 流水線。
4. 總結
5.訓練模式
在 Kubeflow 中,每個獨立的大規模訓練任務(即每個 PyTorchJob/TFJob 等 CRD 實例)都會獨立創建一套專屬的 Master 節點和 Worker 節點—— 不同模型的訓練任務之間完全隔離,不會共享 Master 或 Worker 資源。
簡單説:一個訓練任務 = 一套獨立的 Master + N 個 Worker,多模型訓練就對應多套獨立的節點組。
具體説明
1. 任務隔離的核心邏輯
Kubeflow 的訓練任務(如 PyTorchJob)是 Kubernetes 自定義資源(CRD),每個 CRD 實例會被 Kubeflow Training Operator 解析為獨立的 Deployment/Pod 組:
• 訓練任務 A(如 “ResNet-50 圖像分類訓練”):創建 1 個 task-a-master-0 Pod + 3 個 task-a-worker-0/1/2Pod;
• 訓練任務 B(如 “BERT 文本分類訓練”):創建 1 個 task-b-master-0 Pod + 4 個 task-b-worker-0/1/2/3Pod;
• 兩個任務的 Pod 名稱、資源配置、網絡通信完全隔離,互不干擾。
2. 資源分配的靈活性
每個訓練任務的 Master/Worker 數量、資源配置可以獨立定義,適配不同模型的需求:
• 小模型訓練:可配置 Worker: replicas: 2,每個 Worker 分配 1 個 GPU;
• 大模型訓練:可配置 Worker: replicas: 8,每個 Worker 分配 2 個 GPU;
• Master 節點的資源也可獨立調整(如大模型的 Master 可能需要更多內存存儲全局參數)。
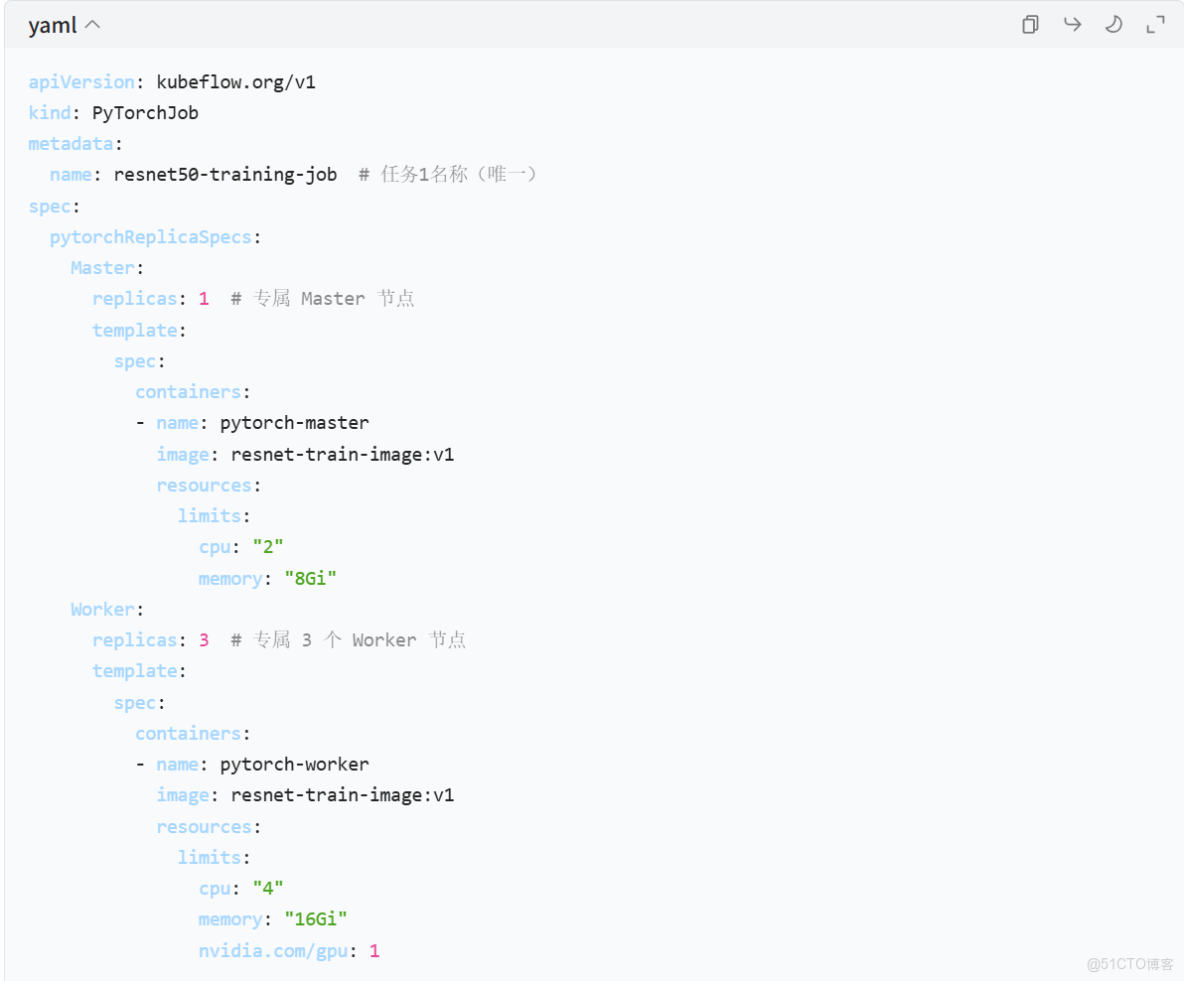
3. 示例:兩個模型訓練的 Kubeflow 配置
假設同時訓練兩個模型,各自的 YAML 配置如下:
模型 1:ResNet-50 訓練(resnet-train-job.yaml)
模型 2:BERT 訓練(bert-train-job.yaml)
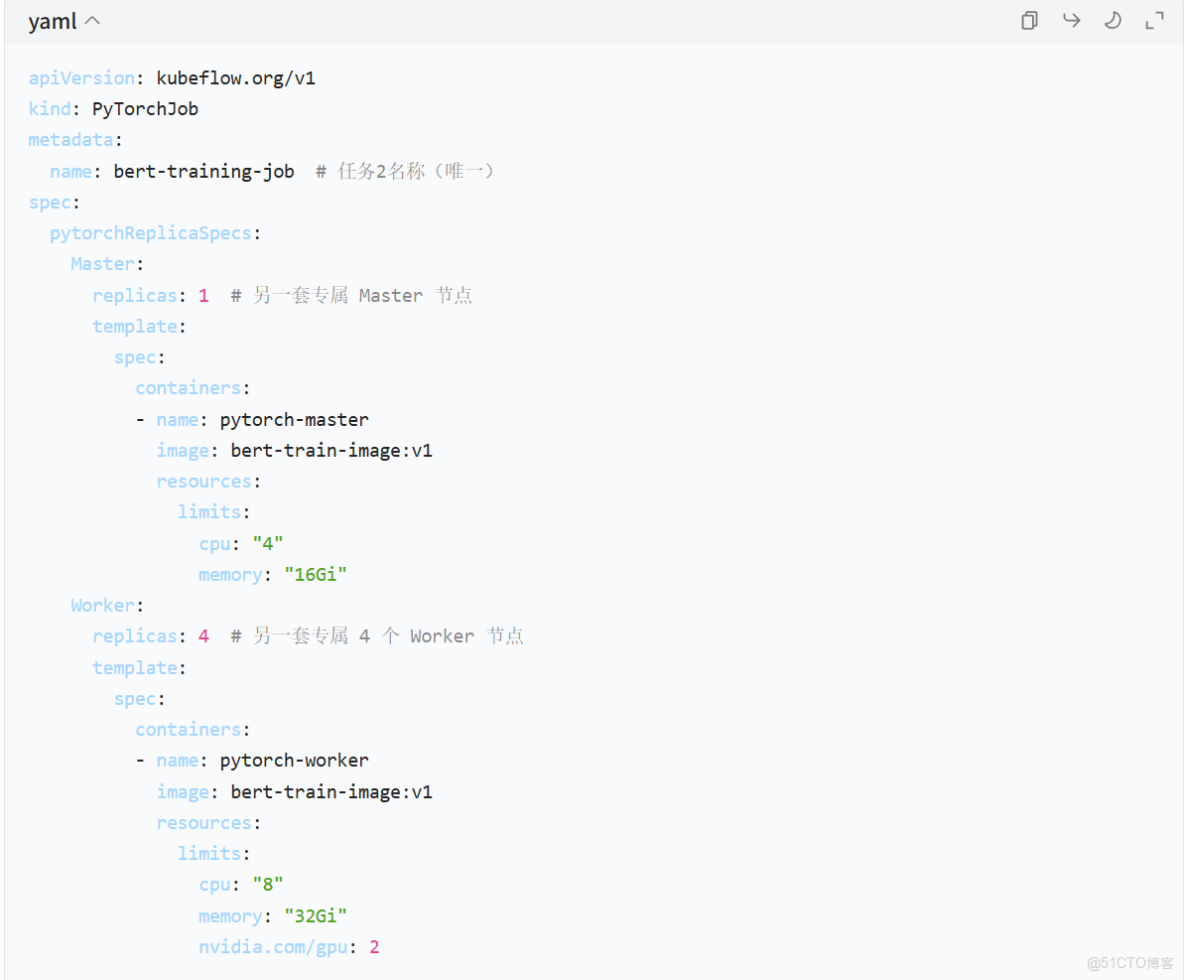
提交後,Kubernetes 集羣中會出現兩組獨立的 Pod:
- 模型 1 相關:
resnet50-training-job-master-0、resnet50-training-job-worker-0/1/2; - 模型 2 相關:
bert-training-job-master-0、bert-training-job-worker-0/1/2/3。
1. 關鍵補充:共享集羣資源,但不共享任務節點
- 所有任務的 Master/Worker 節點會共享 Kubernetes 集羣的物理資源(CPU/GPU/ 內存),由 K8s 調度器統一分配;
- 若集羣資源不足,新提交的訓練任務會進入 “Pending” 狀態,等待其他任務完成釋放資源;
- 可通過 Kubeflow 的 “命名空間(Namespace)” 或 K8s 的 “資源配額(ResourceQuota)” 為不同團隊 / 模型分配專屬資源,避免搶佔。
2、“訓練” 與 “部署” 的關係:缺一不可的閉環
大規模訓練和推理部署是 MLOps 全流程的兩個核心環節,前者是 “生產模型”,後者是 “使用模型”,形成閉環
業務需求 → 大規模訓練(集羣算力)→ 產出可部署模型 → 部署推理服務(KServe/雲廠商/邊緣設備)→ 業務調用(實時/批量)→ 監控模型性能 → 數據漂移/精度下降 → 重新大規模訓練/微調 → 迭代部署
總結
- 多模型訓練 → 多個獨立的 Kubeflow 訓練任務(
PyTorchJob/TFJob); - 每個任務 → 一套專屬的 Master 節點 + N 個 Worker 節點;
- 節點組之間完全隔離,資源配置可獨立調整,由 K8s 統一調度集羣物理資源。
