


論文名稱:Tensor Product Attention Is All You Need
發佈時間:2025年10月23日
👉一鍵直達論文
👉一鍵直達Github
👉Lab4AI大模型實驗室論文閲讀
✨研究背景
大型語言模型在處理長輸入序列時面臨顯著的計算和內存挑戰,主要瓶頸在於自迴歸解碼過程中鍵值(KV)緩存的內存開銷隨序列長度線性增長。現有方法如稀疏注意力、多查詢注意力(MQA)、分組查詢注意力(GQA)等雖能部分緩解問題,但存在性能下降、架構修改複雜或與旋轉位置編碼(RoPE)兼容性差等侷限性。
✨研究目的
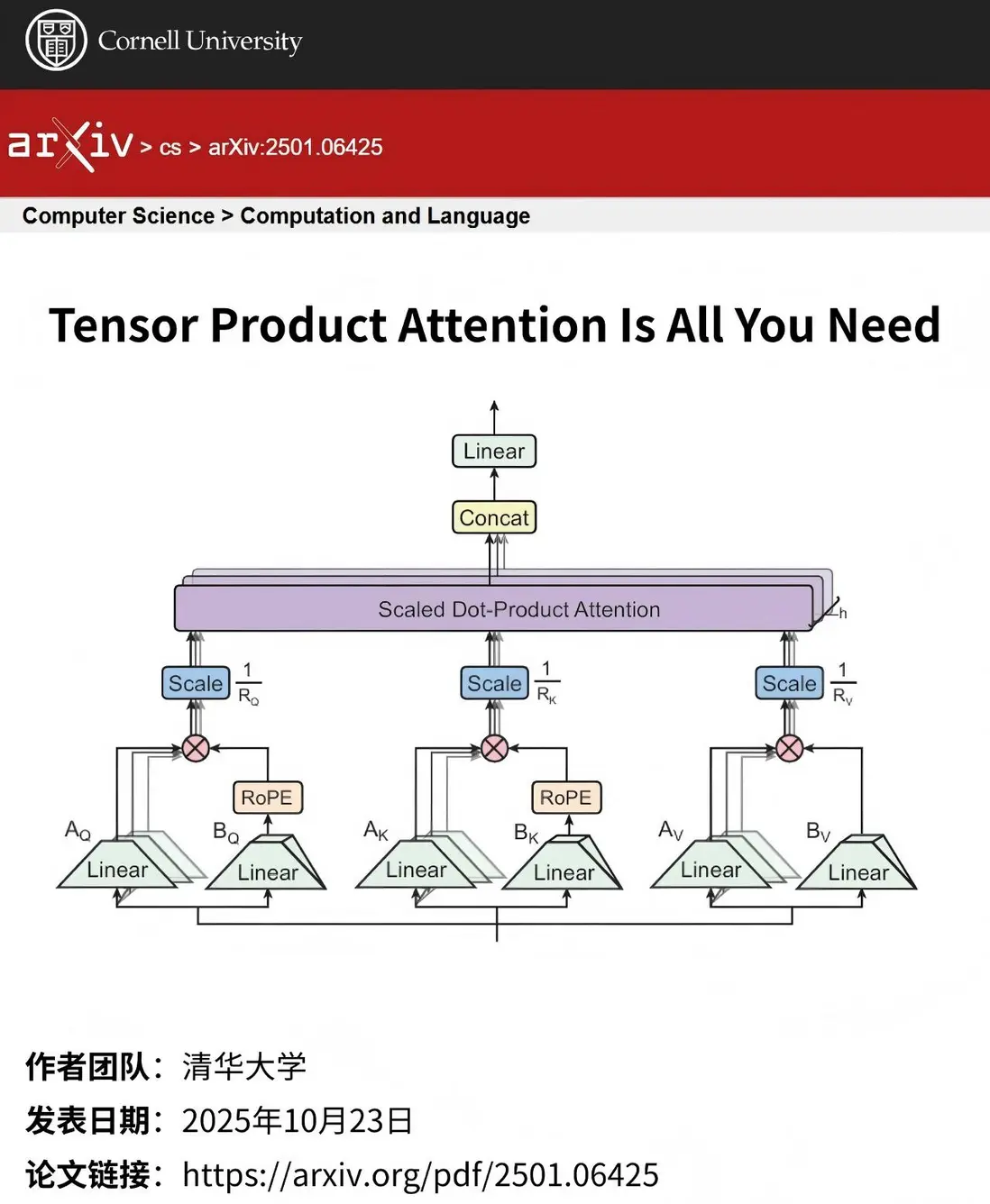
本文提出一種新型注意力機制——張量積注意力(TPA),旨在通過張量分解對查詢、鍵和值進行上下文低秩表示,顯著減少推理時的KV緩存大小,同時提升模型性能,並保持與RoPE的天然兼容性。
✨ 核心貢獻
- 提出TPA機制:通過上下文張量分解實現Q、K、V的緊湊表示,相比標準注意力機制將KV緩存減少10倍以上,且性能優於MHA、MQA、GQA和MLA。
- 統一現有注意力機制:揭示MHA、MQA和GQA均為TPA的非上下文特例。
- 引入T6架構:基於TPA的新Transformer模型,在語言建模任務中驗證其有效性。
- 無縫集成RoPE:TPA可直接替換現有模型(如LLaMA、Gemma)中的多頭注意力層。
✨總結與展望
TPA通過張量分解提供了一種高效且表達力強的注意力機制,顯著降低了長序列處理的內存需求,同時提升模型性能。未來工作可進一步探索高階張量分解、硬件優化及更廣泛的應用場景。