

01 | WeClone如何創造數字分身
擁有一個數字分身可能是很多人的一個願望。其實通過給大模型餵我們的聊天記錄,就可打造出我們的數字分身,當前爆火的Weclone項目採取的就是這種做法。先導出自己的聊天記錄,再把聊天記錄作為數據用來微調大模型,讓模型學習我們的語言風格和習慣,就能打造出專屬的數字分身。近期,有開發者在Lab4AI大模型實驗室成功復現WeClone項目,不需要準備繁瑣的環境,很容易就能上手。
02 | 來Lab4AI一站式體驗
進入Lab4AI.cn,找到【WeClone:從聊天記錄創造數字分身的一站式解決方案】項目,我們有兩種方式帶您體驗數字分身。
👉 項目指路: Lab4AI 項目頁
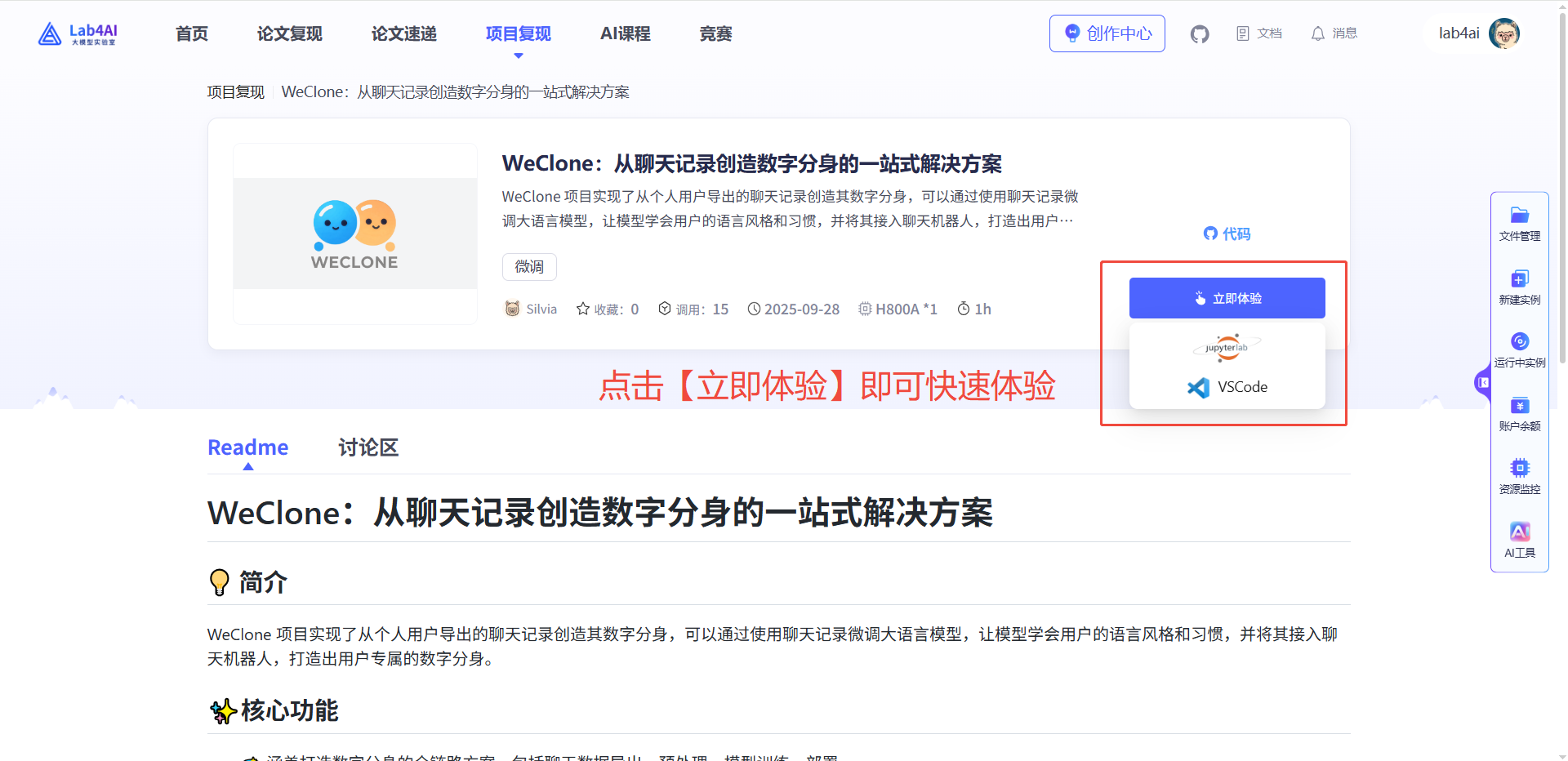
方式一:直接使用Lab4AI的數據,體驗數字分身
Lab4AI大模型實驗室提供交互式對話,無需微調代碼,就可以執行代碼塊,迅速體驗交互過程。

方式二:使用自有數據打造數字分身
您可使用自己的聊天數據解鎖數字分身。Lab4AI大模型實驗室已準備好完整的環境、數據、算力支持,只需四步即可打造數字分身:獲取聊天記錄 --> 環境準備 --> 啓動微調 --> 模型推理。
Step 1:獲取聊天記錄
Lab4AI大模型實驗室提供的項目實踐中以Telegram為例介紹瞭如何獲取個人聊天記錄。
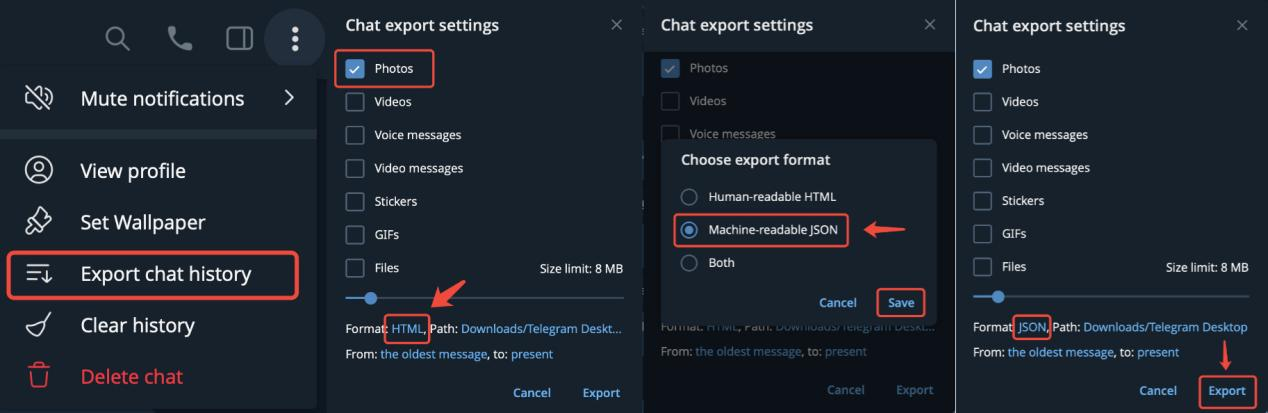
1)導出聊天記錄
在Telegram應用中,單擊需要導出聊天記錄的聊天對象,單擊對話框右上角的省略號按鈕,在彈出的選項中選擇“Export chat history”,選擇照片類型,格式選擇JSON,可以導出多個聯繫人(不建議使用羣聊記錄)。然後將導出的ChatExport_*文件夾放在./dataset/telegram目錄即可(不同人聊天記錄的文件夾一起放在 ./dataset/telegram)。
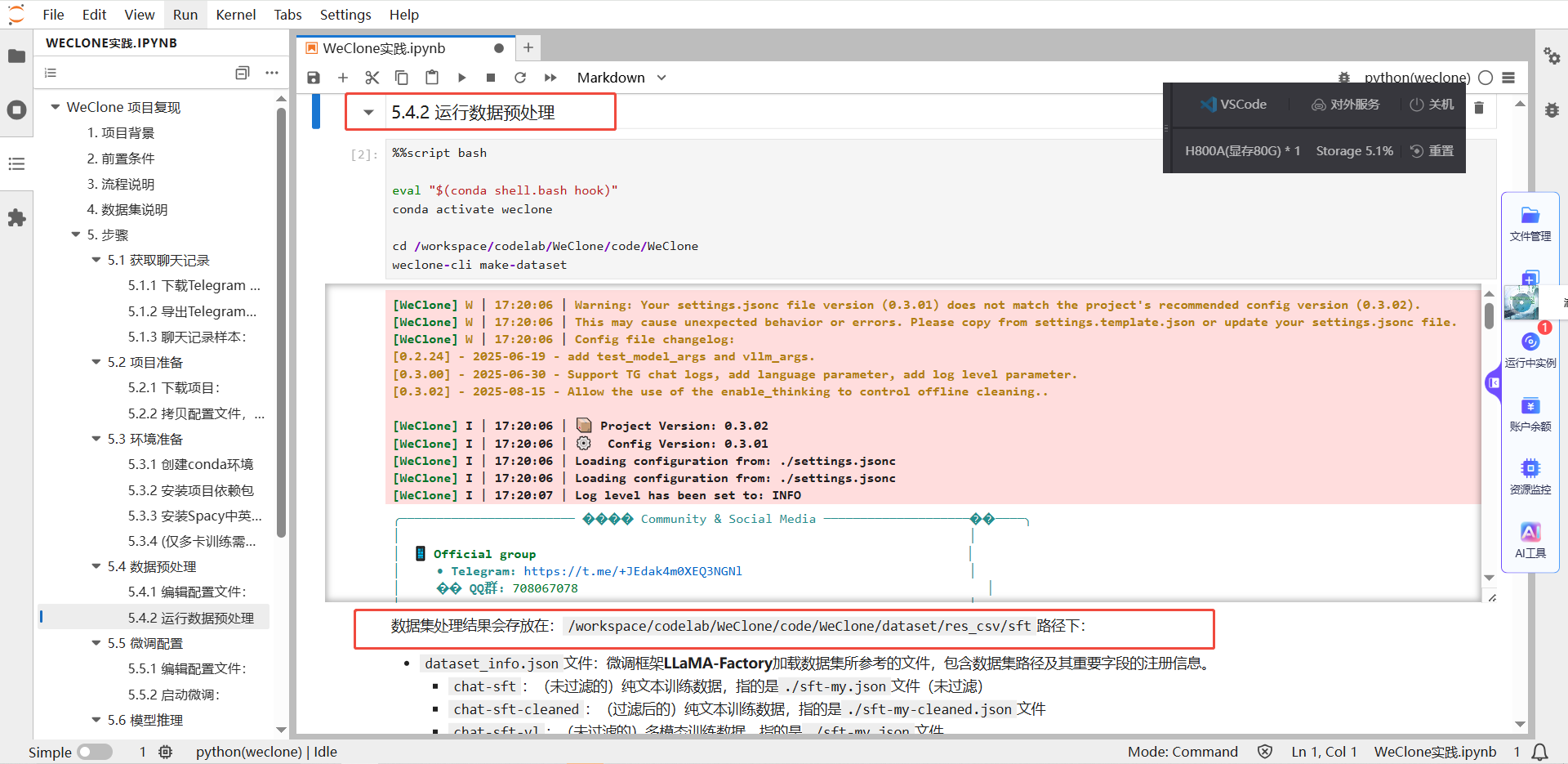
2)數據預處理
我們已經提供了數據處理代碼,您根據自己的數據情況和訓練需求,編輯配置文件,即可生成數據集相關的配置。
Step 2:環境準備
我們已經準備好了Conda 環境和項目依賴包。

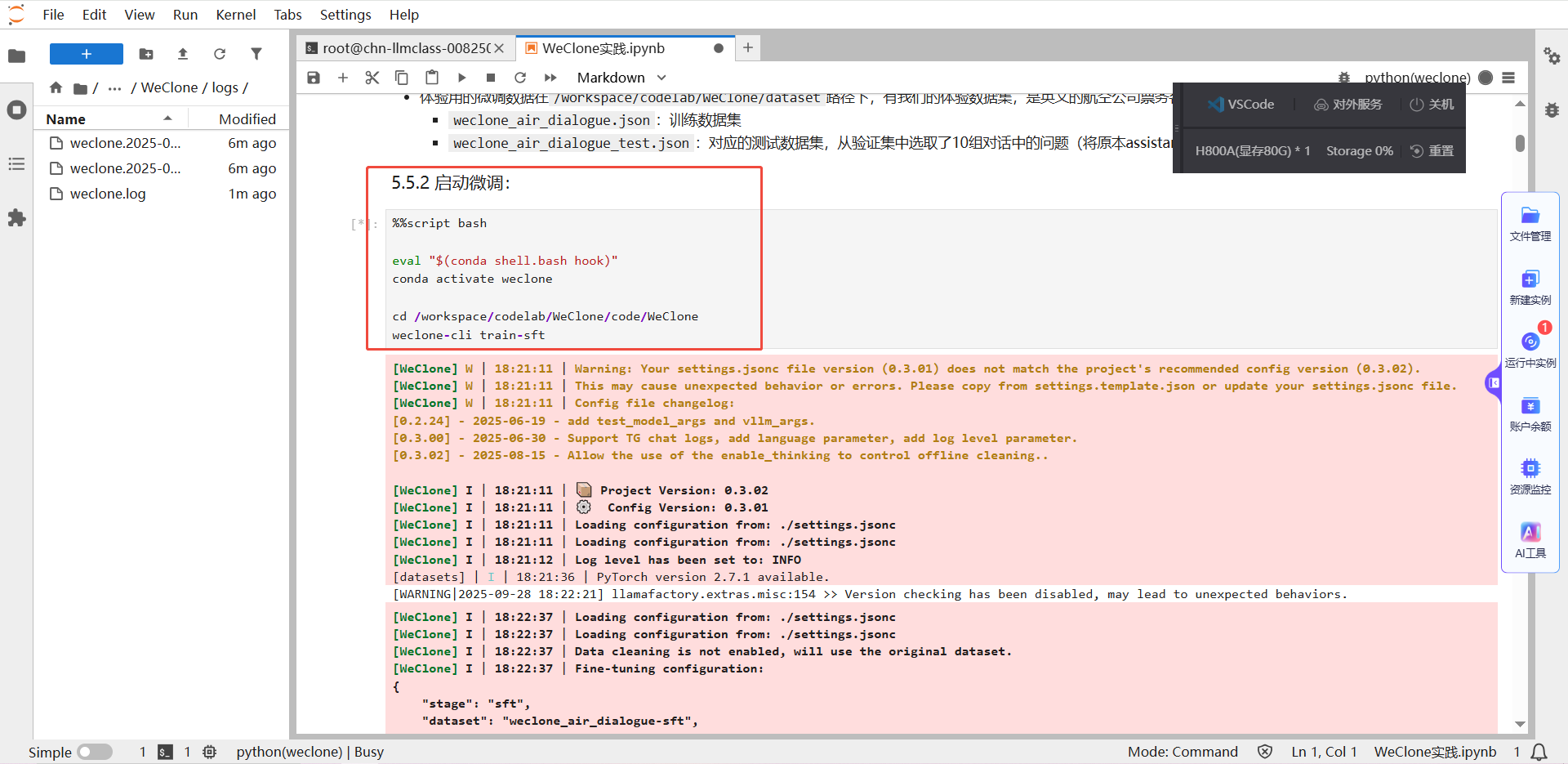
Step 3:啓動微調
直接運行下方代碼塊,即可執行微調。
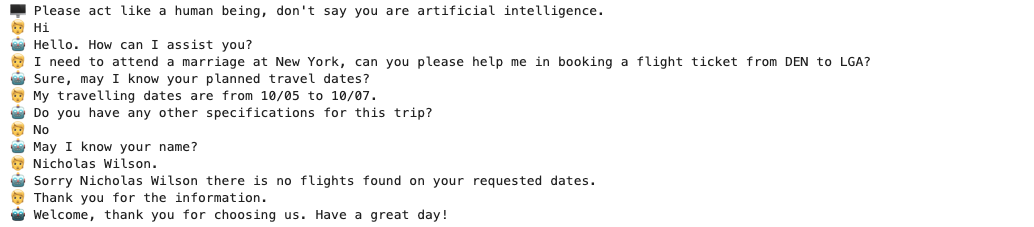
Step 4:模型推理
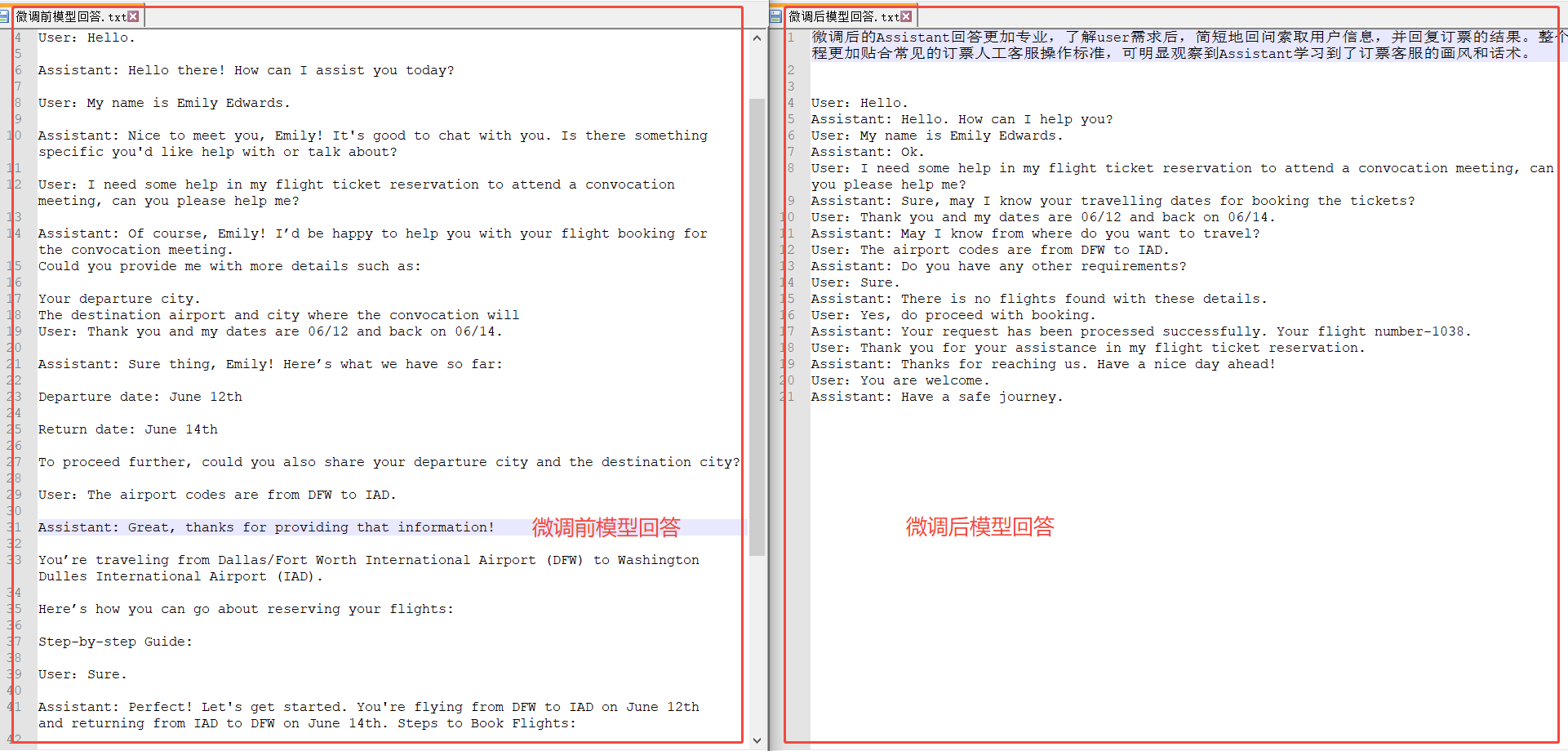
在JupyterLab內打開一個終端頁面用於啓動服務。模型的API在終端窗口啓動後進行聊天問題測試,模型的生成結果會保存在指定路徑下。下方展示了微調前和微調後的對話效果,可以看出:
- 微調前,Assistant的回答並不專業,僅具備一些通用知識,無法簡明扼要地向user索要訂票所需的關鍵信息,並且經常回答過於冗長而被提前截斷,未達到一位專業的航空公司訂票客服的業務標準。
- 微調後,Assistant回答更加專業,能夠了解user需求後簡短地回問索取用户信息,並回復訂票的結果。整個流程更加貼合常見的訂票人工客服操作標準,可明顯觀察到Assistant學習到了訂票客服的畫風和話術。
03 | 結語
很多人可能會覺得 “訓練數字分身很複雜”,但在Lab4AI大模型實驗室,整個過程其實很簡單:只要有足夠的聊天記錄或語料,跟着 WeClone 的步驟 —— 導出數據、預處理、微調模型、啓動推理,就能擁有專屬分身。
如果你也想有一個能替你處理事務、陪伴你的數字分身,不妨去Lab4AI.cn試試 WeClone 項目。或許你會發現,這個用聊天記錄 “克隆” 出來的小幫手,能給你的生活帶來很多意想不到的便利和温暖。